Google Cloud 上の PyTorch: Vertex AI で PyTorch モデルのトレーニングと調整を行う方法
Google Cloud Japan Team
※この投稿は米国時間 2021 年 9 月 9 日に、Google Cloud blog に投稿されたものの抄訳です。
ブログシリーズ「Google Cloud 上の PyTorch」の最初の記事を公開した後、Google は Google I/O 2021 で Vertex AI という Google Cloud のエンドツーエンド ML プラットフォームを発表しました。Vertex AI は、ML プロジェクトのライフサイクルを効率的に構築および管理するために Google Cloud の既存の ML サービスを 1 つのプラットフォームに統合したものです。扱うモデルのタイプを問わず、機械学習ワークフローの各段階を支援するツールが用意されており、ユーザーは機械学習に関する専門知識レベルに合わせてそれらのツールを使用できます。
このブログシリーズでは今後、Vertex AI を使用して大規模な PyTorch モデルを構築、トレーニング、デプロイする方法や、Google Cloud 上に再現可能な機械学習パイプラインを作成する方法を取り上げていきます。
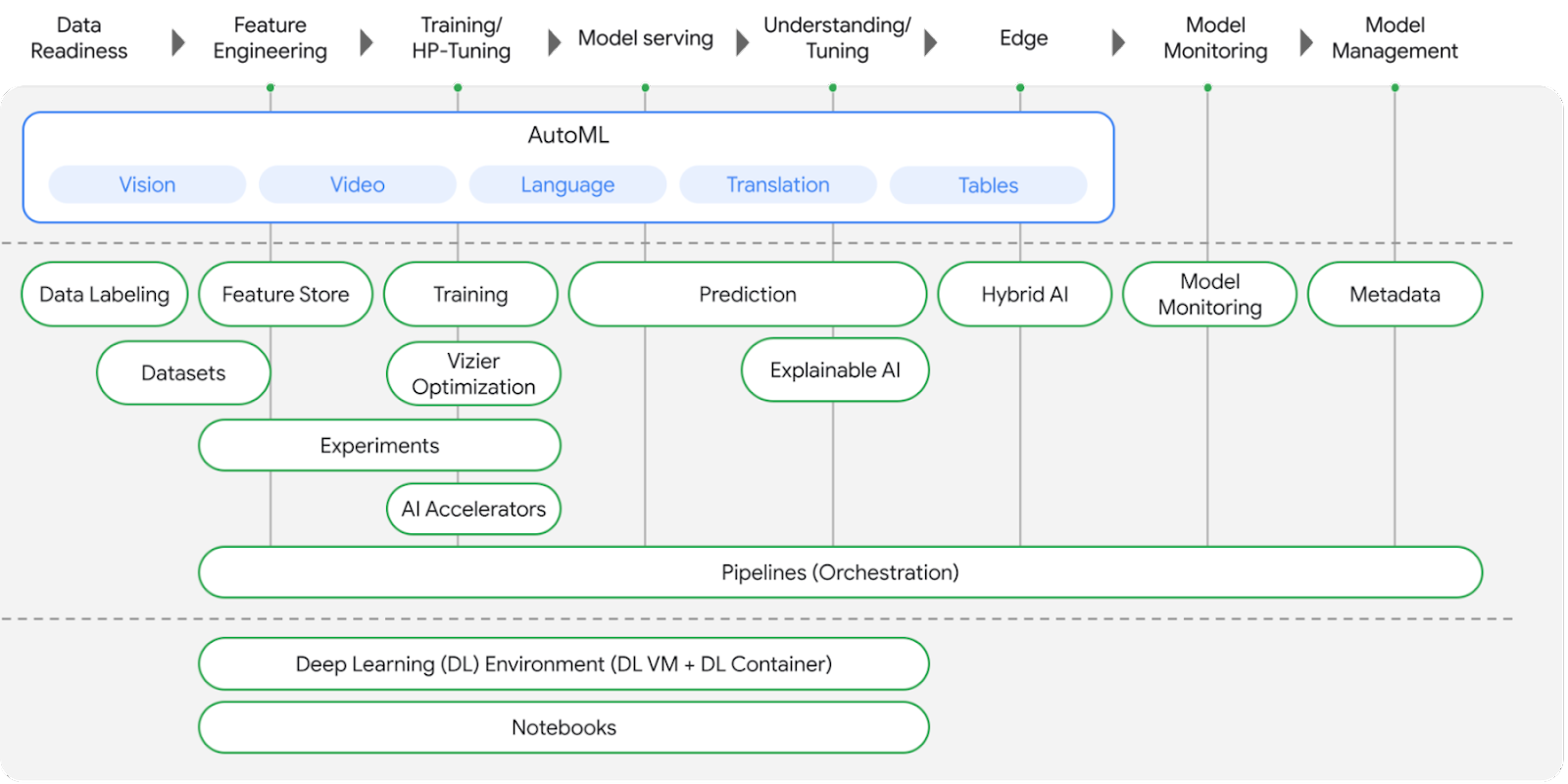
この投稿では、次の方法を紹介します。
Vertex AI トレーニングで PyTorch を使用した感情テキスト分類モデルを構築し、トレーニングする
Vertex AI ハイパーパラメータ調整を使用して、PyTorch モデルのハイパーパラメータを調整する
このブログ投稿の内容に関連するコードは、この GitHub リポジトリと Jupyter Notebook で確認できます。
さっそく始めましょう。
ユースケースとデータセット
この記事では、PyTorch を使用した感情分析タスクのために Hugging Face Transformers Library の Transformer モデル(BERT ベース)を微調整します。BERT(Bidirectional Encoder Representations from Transformers)は、ラベルなしテキストの大規模なコーパスにおいて自己教師ありの方式で事前トレーニングされた Transformer モデルです。ここでは、Notebooks 上にある IMDB 感情分類データセットを使用してテストを行います。
コンピューティングが開発およびテスト目的に制限されているノートブック インスタンスを使用することをおすすめします。ノートブックでのローカルテストが終わったら、同じ Jupyter Notebook からトレーニング ジョブを Vertex Training サービスに送信し、より大きな GPU シェイプを使用してトレーニングをスケールする方法を見ていきます。Vertex Training サービスは、インフラストラクチャをトレーニング ジョブ用にスピンアップし、トレーニングが完了したらスピンダウンすることで、トレーニング パイプラインを最適化します。ユーザーがインフラストラクチャを管理する必要はありません。
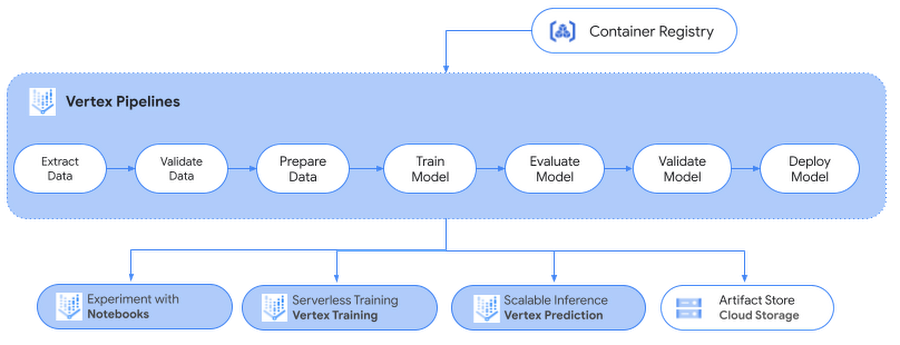
次回以降の投稿では、今回作成した PyTorch モデルを Vertex Prediction サービスにデプロイして予測を行う方法、Vertex Pipelines で ML ワークフローをサーバーレスな方法でオーケストレートして ML システムを自動化、モニタリング、管理する方法、Vertex ML Metadata を使用してワークフローのアーティファクトを保存する方法をご紹介します。
Notebooks での開発環境の作成
JupyterLab ノートブックで Notebooks を使用して PyTorch 開発環境をセットアップするには、以前の投稿のセットアップ セクションをご覧ください。
新しいノートブック インスタンスを操作するには、Google Cloud Console で ノートブック ページに移動し、新しいインスタンスの横にある [JUPYTERLAB を開く] リンクをクリックします。このリンクは、インスタンスが使用可能になるとアクティブになります。
Vertex Training での PyTorch モデルのトレーニング
Notebooks インスタンスを作成したら、テストを開始できます。このユースケースのモデルの仕様について見てみましょう。
モデルの仕様
IMDB データセットに含まれる映画レビューの感情分析を行うため、事前トレーニング済みの Hugging Face の BERT モデルを微調整します。この事前トレーニング済みの BERT モデルは、大規模な英語データのコーパスにおいて自己教師ありの方式でトレーニングされているため、言語に関する大量の情報をすでにエンコードしています。ここで必要なのは、このモデルの出力を使用して、特徴表現を感情分類タスクの特徴として少し調整することだけです。これは、大規模なトレーニング データセットで特定の自然言語処理(NLP)モデルをトレーニングすることなく、はるかに小さなデータセットで開発を迅速にイテレーションできることを意味します。
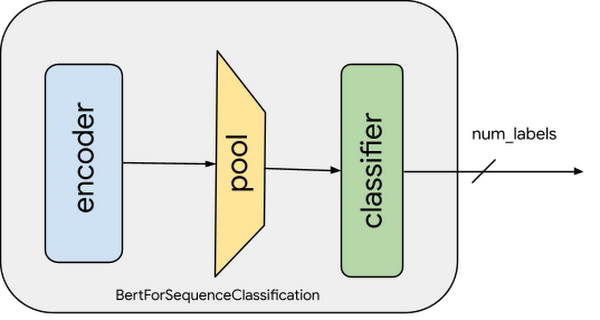
感情分類モデルをトレーニングするため、以下のことを行います。
レビューデータの前処理と変換(トークン化)
事前トレーニング済み BERT モデルの読み込みと、感情分析用の連続分類ヘッドの追加
文章分類に関する BERT モデルの微調整
以下のコード スニペットは、データを前処理して事前トレーニング済み BERT モデルを微調整する方法を示します。完全なコードと詳細な説明については、この Jupyter Notebook をご覧ください。
上のスニペットでは、エンコーダ(ベースモデルとも呼ばれる)ウェイトは凍結されていないことに注目してください。これが、事前トレーニング済みの表現の損失を防ぐために、非常に小さい学習率(2e-5)が選択される理由です。学習率と他のハイパーパラメータは、TrainingArguments オブジェクトの下でキャプチャされます。トレーニング中は、精度の指標のみキャプチャします。他の指標をキャプチャしてレポートするために、compute_metrics 関数を修正できます。
Vertex AI でのモデルのトレーニング
Notebooks インスタンスでローカルテストを行うことは可能ですが、データセットまたはモデルが大規模な場合は通常、垂直にスケーリングされたコンピューティング リソースまたは水平分散トレーニングが必要です。このタスクを行うのに最も効果的な方法は Vertex Training サービスです。これは次の理由によります。
リソースのプロビジョニングまたはプロビジョニング解除が自動的に行われる: Vertex AI でトレーニング ジョブを実行すると、コンピューティング リソースが自動的にプロビジョニングされてトレーニング タスクが行われ、トレーニング ジョブが完了するとコンピューティング リソースが確実に削除されます。
再利用性とポータビリティ: トレーニング コードをパラメータや依存関係とともにコンテナにパッケージ化し、ポータブルなコンポーネントを作成できます。このコンテナを、ハイパーパラメータの調整や各種データソースなどのさまざまなシナリオで実行できます。
大規模なトレーニング: Vertex Training で分散トレーニング ジョブを実行し、クラスタ内の複数のノードでモデルのトレーニングを並列に行えるため、トレーニング時間が短縮されます。
ロギングとモニタリング: トレーニング サービスによってジョブからのメッセージが Cloud Logging に記録され、ジョブの実行中にそれらのメッセージをモニタリングできます。
この投稿では、Vertex Training によってトレーニング ジョブをスケールする方法を示します。そのためには、コードをパッケージ化し、トレーニング ジョブをオーケストレートするトレーニング パイプラインを作成する必要があります。
Vertex AI カスタム トレーニング サービスを使用したトレーニング ジョブの実行は、次の 3 つのステップで構成されています。
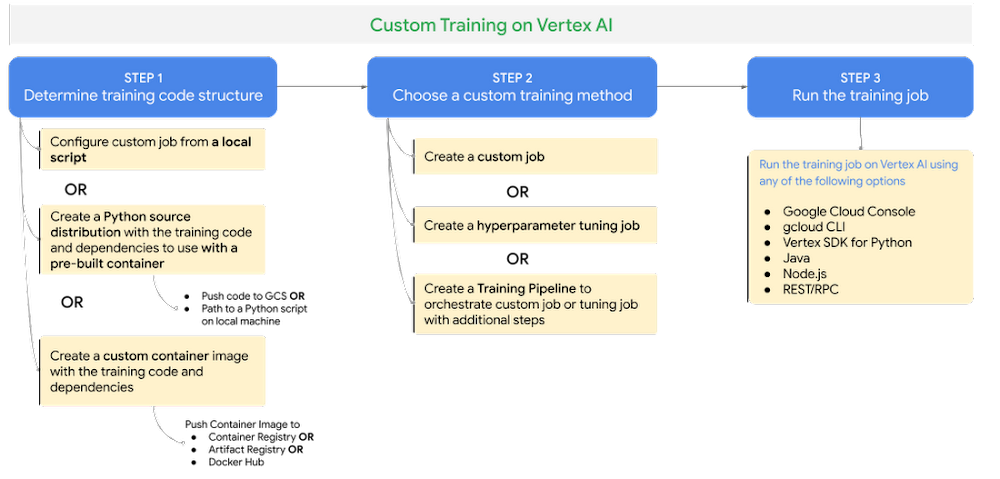
ステップ 1 - トレーニング コードの構造を決定する: トレーニング アプリケーション コードを Python ソース配布またはカスタム コンテナ イメージ(Docker)としてパッケージ化します。
ステップ 2 - カスタム トレーニング方法を選択する: Vertex Training でのトレーニング ジョブは、カスタムジョブまたはハイパーパラメータ トレーニング ジョブ、もしくはトレーニング パイプラインとして実行できます。
カスタムジョブ: カスタムジョブでは、ワーカープールの仕様(マシンタイプ、アクセラレータなど)、Python トレーニングの仕様、カスタム コンテナの仕様など、Vertex AI でトレーニング コードを実行するための設定を構成します。
ハイパーパラメータ調整ジョブ: ハイパーパラメータ調整ジョブは、目標または最適化する指標、ハイパーパラメータの値、実行するトライアルの数などのユーザーが構成した基準に基づいて、モデルのハイパーパラメータを自動的に調整します。
トレーニング パイプライン: カスタム トレーニング ジョブまたはハイパーパラメータ調整ジョブが正常に完了した後、追加のステップによってそれらのジョブをオーケストレートします。
ステップ 3 - トレーニング ジョブを実行する: gcloud CLI または任意のクライアント SDK ライブラリ(Vertex SDK for Python など)を使用して、Vertex Training で実行するトレーニング ジョブを送信できます。
カスタム トレーニング方法の詳細については、このドキュメントをご覧ください。
トレーニング アプリケーションのパッケージ化
Vertex Training でトレーニング アプリケーションを実行する前に、トレーニング アプリケーション コードと必要な依存関係をパッケージ化し、Google Cloud プロジェクトからアクセスできる Cloud Storage バケットにアップロードする必要があります。アプリケーションをパッケージ化して Vertex Training で実行する方法には、次の 2 通りがあります。
Vertex AI のビルド済みコンテナで使用するトレーニング コードと依存関係を含む Python ソース配布を作成する
カスタム コンテナを使用して Docker コンテナで依存関係をパッケージ化する
お好きな方法でトレーニング コードを構造化できます。トレーニング コードの構造化のおすすめの方法については、この GitHub リポジトリまたは Jupyter Notebook をご覧ください。
ビルド済みコンテナを使用して Vertex Training でカスタムジョブを実行する
Vertex AI には、カスタム トレーニング用のビルド済みコンテナとして実行できる Docker コンテナ イメージが用意されています。これらのコンテナには、機械学習フレームワークとフレームワーク バージョンに基づいて、トレーニング コードで使用される一般的な依存関係が含まれています。
この感情分析タスクでは、Hugging Face のデータセットを利用し、PyTorch を使用して Hugging Face Transformers Library の Transformer モデルを微調整します。PyTorch 用のビルド済みコンテナを使用し、トレーニング アプリケーション コードを Python ソース配布としてパッケージ化します。その際、トレーニング アルゴリズムに必要な標準の Python 依存関係(transformers、datasets、tqdm)を setup.py ファイルに追加します。
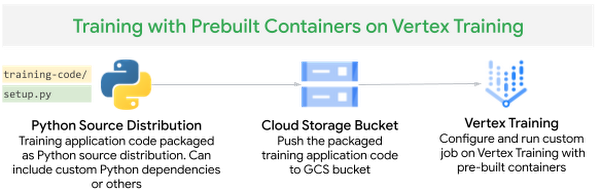
図 6. Vertex Training でのビルド済みコンテナを使用したカスタム トレーニング
setup.py 内の find_packages() 関数には、パッケージ内のトレーニング コードが依存関係として含まれています。
Vertex SDK for Python を使用してトレーニング ジョブを作成し、そのジョブを Vertex トレーニング サービスに送信します。その際、PyTorch 用のビルド済みコンテナ イメージを使用してカスタムジョブを構成し、Python ソース配布としてパッケージ化されたトレーニング コードを指定します。トレーニングを高速化するため、NVIDIA Tesla T4 GPU をトレーニング ジョブにアタッチします。
別の方法として、gcloud beta ai custom-jobs create コマンドを使用してトレーニング ジョブを Vertex AI トレーニング サービスに送信することもできます。この gcloud コマンドは、トレーニング アプリケーションを GCS バケットにステージングし、トレーニング ジョブを送信します。
コマンドに含まれる worker-pool-spec パラメータでは、カスタムジョブで使用するワーカープール構成を定義します。worker-pool-spec 内のフィールドは次のとおりです。
GPU に対応したビルド済み PyTorch v1.7 イメージでトレーニングを行うため、executor-image-uri を us-docker.pkg.dev/vertex-ai/training/pytorch-gpu.1-7:latest に設定します。
local-package-path をトレーニング コードのパスに設定します。
python-module を trainer.task に設定します。これはトレーニング アプリケーションを開始するメイン モジュールです。
accelerator-type と machine-type を使用して、アプリケーションを実行するコンピューティング タイプを設定します。
詳細については、gcloud beta ai custom-jobs create コマンドのドキュメントをご覧ください。
カスタム コンテナを使用して Vertex Training でカスタムジョブを実行する
トレーニング ジョブを実行するカスタム コンテナを作成するには、トレーニング ジョブに必要な依存関係をインストールまたは追加する Dockerfile を定義します。次に、Docker イメージをビルドし、ローカルでテストして検証した後、イメージを Container Registry に push し、カスタムジョブを Vertex Training サービスに送信します。
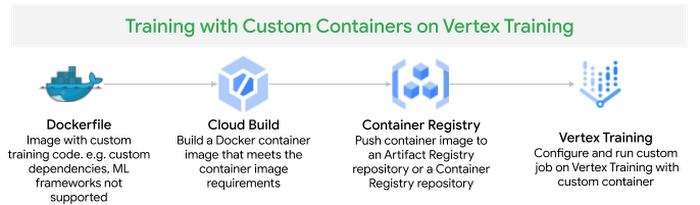
Vertex AI から提供されているビルド済み PyTorch コンテナ イメージをベースイメージとして Dockerfile を作成し、transformers、datasets、tqdm、cloudml-hypertune の依存関係をインストールして、トレーニング アプリケーション コードをコピーします。
イメージをビルドして Google Cloud Container Registry に push します。
Vertex SDK for Python を使用して、カスタム トレーニング ジョブを Vertex Training に送信します。
別の方法として、gcloudbeta ai custom-jobs create コマンドでカスタム コンテナ仕様を指定してトレーニング ジョブを Vertex AI トレーニング サービスに送信することもできます。この gcloud コマンドは、トレーニング ジョブを送信し、指定されたカスタム コンテナ イメージを使用してワーカープールを起動します。
worker-pool-spec パラメータでは、カスタムジョブで使用するワーカープール構成を定義します。worker-pool-spec 内のフィールドは次のとおりです。
container-image-uri を、Google Cloud Container Registry に push したトレーニング用のカスタム コンテナ イメージに設定します。
accelerator-type と machine-type を使用して、アプリケーションを実行するコンピューティング タイプを設定します。
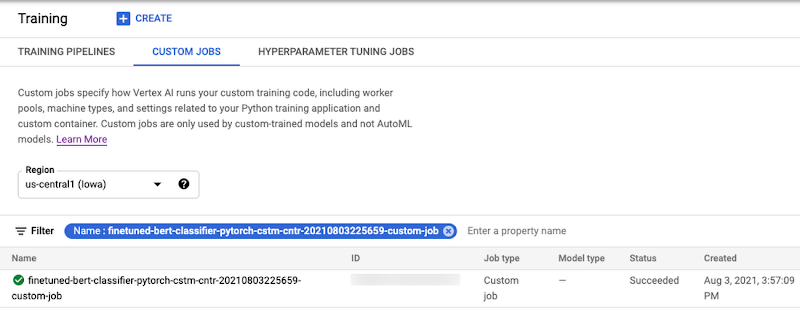
ジョブが送信されたら、下記のように Google Cloud Console または gcloud CLI コマンド gcloud beta ai custom-jobs stream-logs を使用して、トレーニング ジョブのステータスと進捗をモニタリングできます。
Vertex AI でのハイパーパラメータ調整
Transformer モデルを微調整するためのトレーニング アプリケーション コードは、学習率や重み減衰などのハイパーパラメータを使用します。トレーニング アルゴリズムの動作を制御するこれらのハイパーパラメータは、完成したモデルのパフォーマンスに大きな影響を及ぼす可能性があります。このセクションでは、Vertex Training によってこれらのハイパーパラメータの調整を自動化する方法を示します。
ハイパーパラメータ調整ジョブを Vertex Training サービスに送信するための前準備として、以前のセクションでカスタム コンテナを使用して Vertex AI で CustomJob を実行した場合と同じように、トレーニング アプリケーション コードと依存関係を Docker コンテナにパッケージ化し、そのコンテナを Google Container Registry に push します。
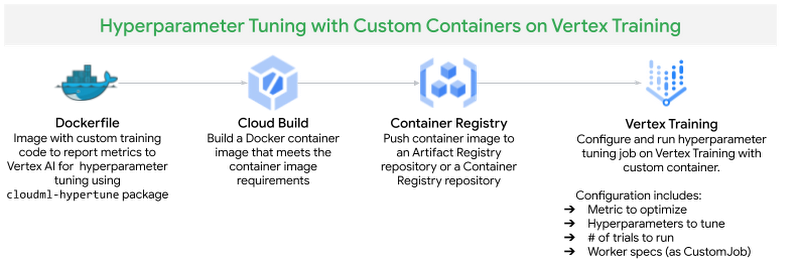
図 9. Vertex Training でのハイパーパラメータ調整
Vertex AI でのハイパーパラメータ調整の仕組み
Vertex Training サービスでハイパーパラメータ調整ジョブを実行するときの大まかな手順は次のとおりです。
モデルを調整するハイパーパラメータを、最適化する指標とともに定義します。
ハイパーパラメータと制限(実行するトライアルの最大数と並列トライアルの数)を指定して、Vertex Training サービスでトレーニング アプリケーションのトライアルを複数回実行します。
Vertex AI が各トライアルの結果を追跡し、後続のトライアルのために調整を加えます。そのためには、Python パッケージ cloudml-hypertune を使用してトレーニング アプリケーションから Vertex AI に指標を報告する必要があります。
ジョブが完了すると、すべてのトライアルのサマリーが表示され、指定した基準に基づいて最も効果的な値の構成が得られます。
調整対象のハイパーパラメータを構成および選択する方法、調整戦略を構成する方法、Vertex AI がどのようにしてハイパーパラメータ調整ジョブを最適化するかを理解するには、Vertex AI のドキュメントをご覧ください。デフォルトの調整戦略では、過去のトライアルの結果が後続のトライアルでの値の割り当てに使用されます。
ハイパーパラメータ調整のためのトレーニング アプリケーション コードの変更
Vertex AI でハイパーパラメータ調整を行う際は、次のようなハイパーパラメータ調整に固有の要件を遵守する必要があります。
ハイパーパラメータの値をトレーニング コードに渡すため、調整する各ハイパーパラメータに対応するコマンドライン引数をメイン トレーニング モジュールで定義する必要があります。それらの引数で渡された値をトレーニング アプリケーションのコード内で使用して、対応するハイパーパラメータを設定します。
トライアルの効果を評価するため、トレーニング アプリケーションから Vertex AI に指標を渡す必要があります。cloudml-hypertunePython パッケージを使用して、指標を報告できます。
以前にトレーニング アプリケーション コードで Trainer をインスタンス化したとき、ハイパーパラメータをトレーニング引数(training_args)として渡しました。これらのハイパーパラメータは、コマンドライン引数としてトレーニング モジュール trainer.task に渡された後、training_args に渡されます。トレーニング アプリケーション コードの ./python_package/trainer モジュールをご覧ください。
ハイパーパラメータ調整が有効なときに指標を Vertex AI に報告するため、評価フェーズの後に cloudml-hypertunePython パッケージを trainer オブジェクトへのコールバックとして呼び出します。trainer オブジェクトは最後の評価フェーズで計算された指標をコールバックに渡し、それが hypertune ライブラリによって Vertex AI に報告されてトライアルの評価に使用されます。
Vertex AI でのハイパーパラメータ調整ジョブの実行
ハイパーパラメータ調整ジョブを Vertex AI に送信する前に、トレーニング アプリケーションを含むカスタム コンテナ イメージを Cloud Container Registry リポジトリに push し、その後で Vertex SDK for Python を使用してジョブを Vertex AI に送信します。以前に Vertex Training サービスでカスタムジョブを実行したときと同じイメージを使用します。
トレーニング引数で hp-tune 引数を y に設定し、トレーニング アプリケーション コードから Vertex Training サービスに指標を報告できるようにします。
マシンタイプ、アクセラレータ、トレーニング アプリケーション コードを含むカスタム コンテナ仕様を定義するワーカープール仕様を指定して、CustomJob を作成します。
次に、パラメータと指標の仕様を定義します。
parameter_spec では、検索空間(検索して最適化するパラメータ)を定義します。ここでは、ハイパーパラメータのデータ型をパラメータ値仕様のインスタンスとして指定する必要があります。調整するハイパーパラメータの選択とそれらのパラメータを定義する方法については、このドキュメントをご覧ください。
metric_spec では、最適化する指標の目標を定義します。目標は、モデルの調整時にその指標の値を最大化するか最小化するかを示します。
CustomJob、metric_spec、parameter_spec、トライアル制限を指定して HyperparameterTuningJob を構成し、送信します。トライアル制限は、トレーニング サービスがトライアルを何回実行できるかを定義します。
max_trial_count: トレーニング サービスによって実行されるトライアルの最大数。まず小さい値を使用して選択したハイパーパラメータの影響を確かめてから、値を大きくします。
parallel_trial_count: 並列に実行するトライアルの数。Vertex AI は過去のトライアルの結果を後続のトライアルでの値の割り当てに使用するため、まずは小さい値から始めます。並列トライアルの数を増やすということは、これらのトライアルが開始されるときにまだ実行中のトライアルの結果を利用できないことを意味します。
search_algorithm: この学習のために指定された検索アルゴリズム。これを指定しない場合は、デフォルトでベイズ最適化が適用されます。このアルゴリズムは、パラメータ空間を検索して最適解に到達します。
ハイパーパラメータ トレーニング ジョブの構成について理解するには、このドキュメントをご覧ください。
別の方法として、gcloud beta ai hp-tuning-jobs create を使用してハイパーパラメータ調整ジョブを Vertex AI トレーニング サービスに送信することもできます。この gcloud コマンドは、ハイパーパラメータ調整ジョブを送信し、指定されたカスタム コンテナ イメージ、トライアル数、設定された基準に基づいてワーカープールで複数のトライアルを開始します。このコマンドでは、ハイパーパラメータ調整ジョブの構成を、ジョブ名を付けた YAML 形式の構成ファイルとして提供する必要があります。YAML 構成の作成と、gcloud コマンドによるジョブの送信については、この Jupyter Notebook をご覧ください。
開始されたハイパーパラメータ調整ジョブは、Cloud Console のこのページから、または gcloud CLI コマンドの gcloud beta ai custom-jobs stream-logs を使用して、モニタリングできます。
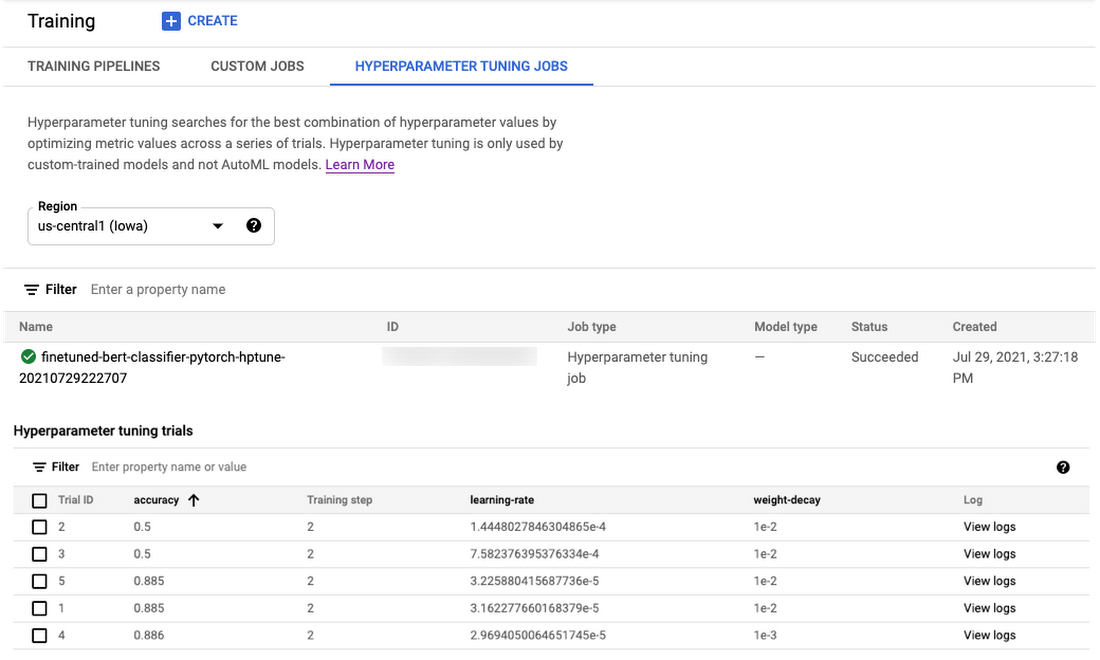
ジョブが完了した後、(Vertex Training サービスによって実行された)ハイパーパラメータ調整トライアルの結果を表示および書式設定し、最も成績が良いトライアルを選んで Vertex Prediction サービスにデプロイできます。
ローカルでの予測の実行
このトレーニング済みモデルに対して、いくつかのサンプルを使用してローカルで予測呼び出しを実行してみましょう(完全なコードについては、このノートブックをご覧ください)。このシリーズの次回の投稿では、このモデルを Vertex Prediction サービスにデプロイする方法を紹介します。
ノートブック環境のクリーンアップ
テストが終了したら、Notebooks インスタンスを停止または削除できます。さらなる料金が発生しないようにするには、Notebooks インスタンスを削除します。作業内容を保存する場合は、削除の代わりに、インスタンスの停止も選択できます。
今後の予定
この記事ではまず、PyTorch モデルの開発に使用するために Notebooks を掘り下げました。次に、Vertex Training サービス(機械学習モデルを大規模にトレーニングするためのフルマネージド サービス)を使用してモデルのトレーニングと調整を行いました。また、Vertex SDK for Python と gcloud CLI コマンドで PyTorch 用のビルド済みコンテナとカスタム コンテナを使用して、トレーニング ジョブをカスタムジョブおよびハイパーパラメータ調整ジョブとして Vertex Training に送信する方法を説明しました。
このシリーズの今後の投稿では、PyTorch モデルを Vertex Prediction サービスにデプロイする方法と、Vertex Pipelines を使用して機械学習ワークフローをオーケストレートする方法を取り上げます。このトピックに関心をお持ちの場合は、Vertex AI の機能について調べ、Google Cloud で機械学習を実装するためのベスト プラクティスに関するリファレンス ガイドを読むことをおすすめします。
参考資料
コードと付随するノートブックを含む GitHub リポジトリ
今後の情報にご注目ください。ご精読ありがとうございました。質問がある場合やチャットを希望する場合は、こちらで著者をお探しください。Rajesh [Twitter | LinkedIn] および Vaibhav [LinkedIn]。
この投稿に助力し、記事を推敲してくれた Karl Weinmeister と Jordan Totten に感謝します。
-Cloud カスタマー エンジニア 機械学習スペシャリスト Rajesh Thallam
-Cloud カスタマー エンジニア 機械学習スペシャリスト Vaibhav Singh




