Google Cloud 上の PyTorch: AI Platform 上で PyTorch モデルをトレーニングする方法
Google Cloud Japan Team
※この投稿は米国時間 2021 年 5 月 6 日に、Google Cloud blog に投稿されたものの抄訳です。
PyTorch は、Facebook により初期開発されたオープンソースの機械学習とディープ ラーニングのライブラリで、画像認識、自然言語処理、翻訳、Recommender システムなど、大規模な機械学習タスクの自動化に向けて幅広いユースケースで使用されています。PyTorch は主に研究で使用されてきましたが、近年はその使いやすさとデプロイのしやすさから、業界からも高い関心が寄せられています。
Google Cloud AI Platform は、Google Cloud におけるデータ サイエンスと機械学習向けのフルマネージドで、エンドツーエンドのプラットフォームです。AI における Google の専門的技術を活用して、AI Platform は、機械学習ワークロードを実行するための柔軟かつスケーラブルで、信頼性のあるプラットフォームを提供します。AI Platform には、パフォーマンスが最適化され、互換性がテストされているため、すぐにデプロイが可能である Deep Learning Containers を使用した PyTorch に対するサポートが組み込まれています。
このブログ投稿の新シリーズ「Google Cloud 上の PyTorch」は、PyTorch モデルを大規模に構築し、トレーニングしてデプロイする方法と Google Cloud 上に再現可能な機械学習パイプラインを作成する方法を共有することを目的としています。
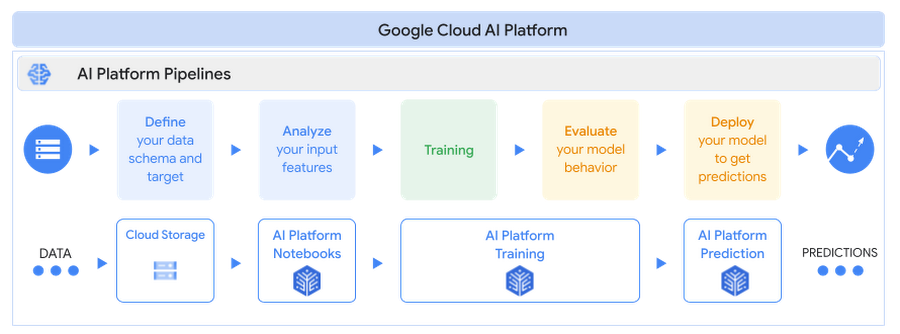
PyTorch を Google Cloud AI Platform で使用する理由
Cloud AI Platform は、PyTorch ベースのディープ ラーニング モデルをトレーニングしてデプロイするための、柔軟でスケーラブルなハードウェアと安全なインフラストラクチャを提供します。
柔軟性: AI Platform Notebooks と AI Platform Training は、ワークロードに一致するコンピューティング リソースの設計に柔軟性を与える一方、このプラットフォームにより、依存関係、ネットワーキング、詳細なモニタリングの大部分が管理されます。インフラストラクチャの心配をすることなく、モデルの構築に時間を費やすことができます。
スケーラビリティ:ビルド済み PyTorch コンテナまたはカスタム コンテナを使用して、AI Platform Notebooks でテストを実施し、GPU または TPU 上でモデルをトレーニングすることで、AI Platform Training を使用して高可用性を備えたコードをスケールします。
セキュリティ: AI Platform は、Google の情報処理ライフサイクル全体を通してセキュリティを確保するように設計された、グローバル規模の技術インフラストラクチャを活用しています。
サポート: AI Platform は、PyTorch フレームワーク サポートを含め、AI Platform と NVIDIA GPU との間で最高水準の互換性を確保するために、PyTorch と NVIDIA と緊密に連携しています。
こちらは、Google Cloud 上の PyTorch に対するサポートのクイック リファレンスです。
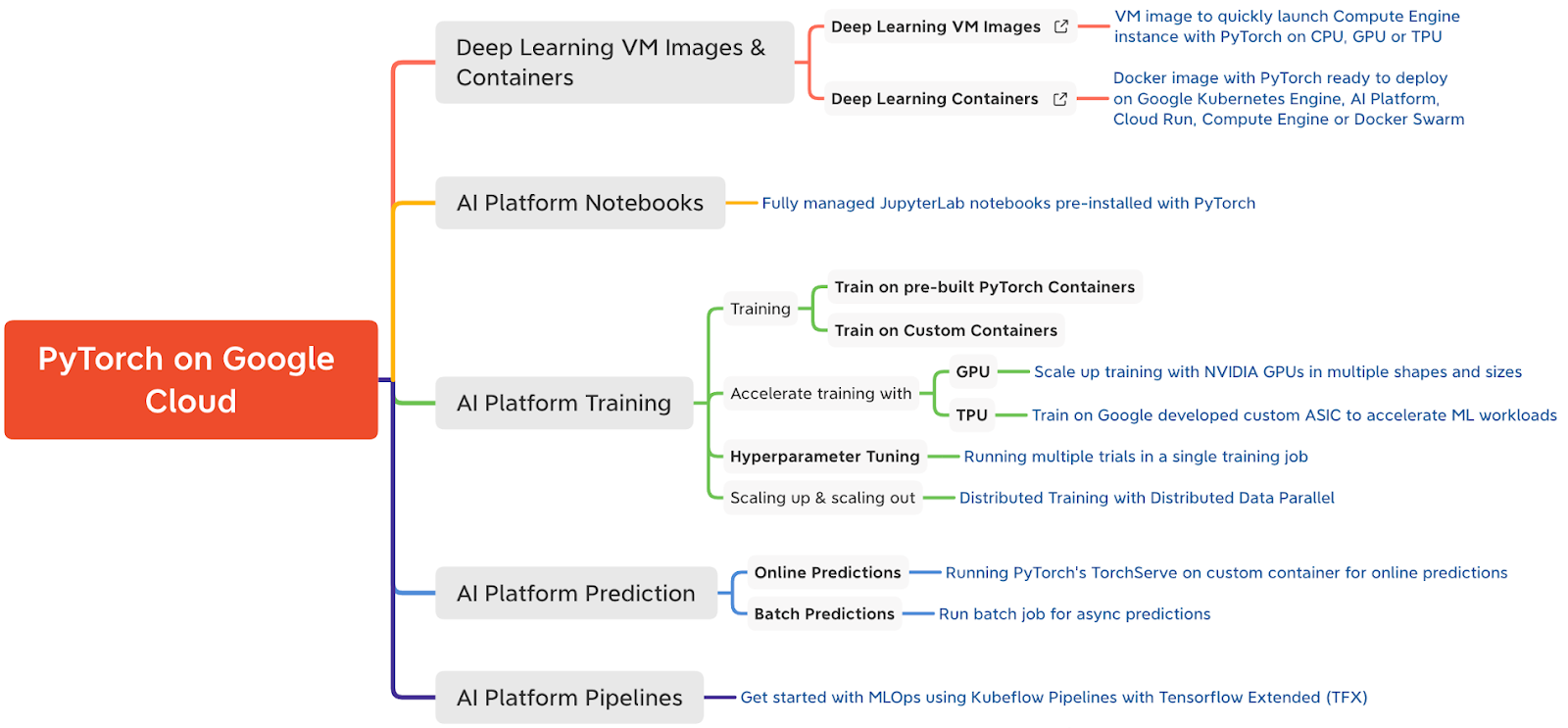
この投稿では、次の内容を取り上げます。
AI Platform Notebooks を使用した JupyterLab ノートブックへの PyTorch 開発環境の設定
PyTorch を使用した感情分類モデルの構築と AI Platform Training 上のトレーニング
GitHub リポジトリと Jupyter Notebook 上で、このブログ投稿の内容に付随するコードを確認できます。
さっそく始めましょう。
ユースケースとデータセット
PyTorch を使用した感情分析タスクのために、この記事では Huggingface Transformers Library の Transformer モデル(BERT ベース)を微調整します。BERT(Bidirectional Encoder Representations from Transformers)は、自己教師ありの方式で、ラベルなしテキストの大規模なコーパスで事前トレーニングされた Transformer モデルです。AI Platform Notebooks 上にある IMDB 感情分類データセットを使用したテストを開始します。コンピューティングが開発およびテスト用に制限されている AI Platform Notebooks インスタンスを使用することをおすすめします。Notebooks で満足のいくローカルのテストができたら、より大きな GPU シェイプのトレーニングをスケールするために、同じ Jupyter Notebook を AI Platform Training サービスに送信する方法を見ていきます。AI Platform Training サービスは、トレーニング ジョブ用にインフラストラクチャをスピンアップし、トレーニングが完了したら、インフラストラクチャをスピンダウンすることでトレーニング パイプラインを最適化するため、インフラストラクチャを管理する必要はありません。

次回の投稿では、AI Platform Prediction サービスに、PyTorch モデルをデプロイして提供する方法を紹介する予定です。
AI Platform Notebooks に開発環境を作成する
AI Platform Notebooks 上の開発環境として、JupyterLab ノートブックを使用します。始める前に、AI Platform Notebooks API を有効にした Google Cloud Platform 上にプロジェクトを設定する必要があります。
AI Platform Notebooks インスタンスを作成すると、課金されますのでご注意ください。ノートブック インスタンスが起動し、動作している時間に対してのみ料金が発生します。作業内容を保存するインスタンスを停止して、インスタンスを再起動するまでブートディスク ストレージのみ課金されるようにすることもできます。作業が完了したら、インスタンスを削除してください。
以下の方法で、AI Platform Notebooks インスタンスを作成できます。
AI Platform Deep Learning VM(DLVM)イメージのビルド済み PyTorch イメージを使用する、または
独自のパッケージを含むカスタム コンテナを使用する
ビルド済み PyTorch DLVM イメージを含む Notebooks インスタンスを作成する
AI Platform Notebooks インスタンスは、JupyterLab ノートブック環境が有効になっていて、すぐに使用できる AI Platform Deep Learning VM イメージ インスタンスです。AI Platform Notebooks は、複数の PyTorch バージョンをサポートする PyTorch イメージ ファミリーを提供します。Google Cloud Console またはコマンドライン インターフェース(CLI)から、新しいノートブック インスタンスを作成できます。NVIDIA Tesla T4 GPU へのノートブック インスタンスの作成には、gcloud CLI を使用します。Cloud Shell または Cloud SDK がインストールされている場所にある任意のターミナルから、次のコマンドを実行して、新しいノートブック インスタンスを作成します。
新しいノートブック インスタンスを操作するには、Google Cloud Console で AI Platform Notebooks ページに移動して、新しいインスタンスの横にある [JupyterLab を開く] リンクをクリックします。このリンクは、使用可能になるとアクティブになります。
PyTorch のテストに必要なライブラリの多くは、ビルド済み PyTorch DLVM イメージを含む新しいインスタンスに、すでにインストールされています。追加の依存関係をインストールするには、ノートブックのセルから %pip install <package-name> を実行します。感情分類のユースケースの場合、Hugging Face Transformers とデータセット ライブラリなど、追加のパッケージをインストールします。
カスタム コンテナを使用してノートブック インスタンスを作成する
ノートブック インスタンスに pip を使用して依存関係をインストールする代わりに、AI Platform Deep Learning Container イメージから得られた Docker コンテナ イメージ内に依存関係をパッケージ化して、カスタム コンテナを作成します。AI Platform Notebooks インスタンスや AI Platform Training ジョブの作成には、このカスタム コンテナを使用できます。ここでは、カスタム コンテナを使用したノートブック インスタンスの作成例を示します。
ベースイメージとして AI Platform Deep Learning Container イメージのいずれかを使用して(ここでは PyTorch 1.7 GPU イメージを使用)Dockerfile を作成し、必要なパッケージまたはフレームワークの実行とインストールを行います。感情分類のユースケースの場合、Transformer とデータセットを含めます。
2. ターミナルまたは Cloud Shell から Cloud Build を使用して、Dockerfile からイメージを構築し、イメージの場所 gcr.io/{project_id}/{image_name} を取得します。
3. コマンドラインで、ステップ 2 で作成したカスタム イメージを使用して、ノートブック インスタンスを作成します。
AI Platform Training 上で PyTorch モデルをトレーニングする
AI Platform Notebooks インスタンスを作成したら、テストを開始できます。このユースケースのモデルの仕様について見てみましょう。
モデルの仕様
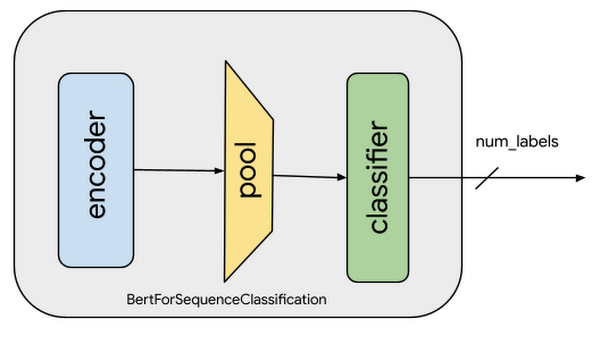
IMDB データセットの映画レビューの感情分析の場合、事前トレーニング済みの Hugging Face の BERT モデルを微調整します。微調整には、特定のタスク用にすでにトレーニングされたモデルを選び、他の同様なタスクのために調整することも含まれます。こうした調整の具体例としては、ウェイトとパラメータを含む、事前トレーニング済みモデルのすべてのレイヤ(出力レイヤを除く)の複製などがあります。次に、現在のタスクのラベルを予測する新しい出力分類レイヤを追加します。最後のステップで、出力レイヤを最初からトレーニングする一方、事前トレーニング済みモデルのすべてのレイヤのパラメータは凍結されます。これにより、事前トレーニング済みの表現から学習でき、このケースの感情分析のような具体的なタスクに対して、より関連した高次の特徴表現を「微調整」できます。
このシナリオの感情分析の場合、事前トレーニング済みの BERT モデルは、自己教師ありの方式で、大規模な英語データのコーパスでトレーニングされているため、言語に関する大量の情報をすでにエンコードしています。ここで必要なことは、感情分類タスクの特徴として、出力を使用して特徴表現を少し調整することです。これは、大規模なトレーニング データセットで特定の自然言語処理(NLP)モデルをトレーニングする代わりに、はるかに小さなデータセットで開発の反復処理を迅速に行えることを意味します。
感情分類モデルをトレーニングする場合、以下のことを行います。
レビューデータの前処理と変換(トークン化)
事前トレーニング済み BERT モデルの読み込みと、感情分析用の連続分類ヘッドの追加
文章分類用の BERT モデルの微調整
以下は、データの前処理と事前トレーニング済み BERT モデルの微調整を行うコードのスニペットです。これらのタスクの完全なコードと詳細な説明については、Jupyter Notebook を参照してください。
上のスニペットでは、エンコーダ(ベースモデルとも呼ばれる)ウェイトは凍結されていないことに注目してください。これが、事前トレーニング済みの表現の損失を防ぐために、非常に小さい学習率(2e-5)が選択される理由です。学習率と他のハイパーパラメータは、TrainingArguments オブジェクトの下でキャプチャされます。トレーニング中は、精度の指標のみキャプチャします。他の指標をキャプチャしてレポートするために、compute_metrics 関数を修正できます。
このシリーズの次回の投稿では、Cloud AI Platform ハイパーパラメータ調整サービスとの統合について詳しく見ていく予定です。
Cloud AI Platform でモデルをトレーニングする
AI Platform Notebooks インスタンスでローカルのテストを行うことは可能ですが、より大規模なデータセットまたはモデルの場合は、通常、垂直スケールのコンピューティング リソースまたは水平分散トレーニングが必要です。このタスクを行うのに最も効果的な方法は、AI Platform Training サービスです。AI Platform Training は、このタスクに必要な指定されたコンピューティング リソースの作成を処理して、トレーニング タスクを行い、トレーニング ジョブが終了したら、コンピューティング リソースの削除も確実に行います。
AI Platform Training でトレーニング アプリケーションを実行する前に、必要な依存関係を含むトレーニング アプリケーション コードがパッケージ化され、Google Cloud プロジェクトがアクセスできる Google Cloud Storage バケットにアップロードされる必要があります。アプリケーションをパッケージ化して、AI Platform Training で実行するには、次の 2 つの方法があります。
Python 設定ツールを使用して、手動でアプリケーションと Python 依存関係をパッケージ化する
カスタム コンテナを使用して Docker コンテナで依存関係をパッケージ化する
お好きな方法でトレーニング コードを構造化できます。トレーニング コードの構造化のおすすめの方法については、GitHub リポジトリまたは Jupyter Notebook を参照してください。
Python パッケージングを使用して手動で構築する
この感情分類タスクの場合、setup.py ファイルで標準 Python 依存関係(transformers、datasets、tqdm)を含むトレーニング コードをパッケージ化する必要があります。setup.py 内の find_packages() 関数には、依存関係としてパッケージにトレーニング コードが含まれています。
これで、Cloud Shell または gcloud SDK がインストールされているターミナルから、gcloud コマンドを使用して、トレーニング ジョブを Cloud AI Platform Training に送信できるようになりました。gcloud ai-platform jobs submit trainingコマンドにより、GCS バケット上でトレーニング アプリケーションがステージングされ、トレーニング ジョブが送信されます。トレーニングを加速させるため、トレーニング ジョブに NVIDIA Tesla T4 GPU を 2 つ接続しています。
カスタム コンテナを使用したトレーニング
カスタム コンテナを使用してトレーニング ジョブを作成するには、Dockerfile を定義して、トレーニング ジョブに必要な依存関係をインストールする必要があります。次に、Docker イメージをローカルで構築してテストします。これは、AI Platform Training で使用する前に、イメージを検証するためです。
トレーニング ジョブを送信する前に、Google Cloud Container Registry にイメージを push する必要があります。次に、gcloud ai-platform jobs submit training コマンドを使用して、Cloud AI Platform Training にトレーニング ジョブを送信します。
ジョブが送信されたら、Google Cloud Console または以下に示すような gcloud コマンドのいずれかを使用して、トレーニング ジョブのステータスと進捗をモニタリングできます。
Google AI Platform ジョブ コンソールから、ジョブ ステータスのモニタリングとジョブログの確認を行うこともできます。
いくつかの例を使用してローカルでトレーニングしたモデルで、予測呼び出しを実行してみましょう(完全なコードについては、ノートブックを参照してください)。このシリーズの次の投稿では、このモデルを AI Platform Prediction サービスにデプロイする方法を紹介する予定です。
ノートブック環境をクリーンアップする
テストが終了したら、AI Platform Notebooks インスタンスを停止または削除できます。さらなる料金が発生しないようにするには、AI Platform Notebooks インスタンスを削除します。作業内容を保存する場合は、削除の代わりに、インスタンスの停止も選択できます。
次のステップ
この記事では、PyTorch モデル開発用に完全にカスタマイズできる IDE として、Cloud AI Platform Notebooks を掘り下げました。次に、機械学習モデルを大規模にトレーニングするためのフルマネージド サービスである Cloud AI Platform Training サービスで、モデルをトレーニングしました。
参考資料
コードと付随するノートブックを含む GitHub リポジトリ
このシリーズの次回の投稿では、Cloud AI Platform でのハイパーパラメータ調整と、AI Platform Prediction サービスへの PyTorch モデルのデプロイを詳しく取り上げます。今回ご紹介した Cloud AI Platform の機能をぜひお試しください。
今後の情報にご注目ください。ご精読ありがとうございました。質問がある場合やチャットを希望する場合は、こちらで著者をお探しください。Rajesh [Twitter | LinkedIn] および Vaibhav [LinkedIn]。
本投稿のサポートとレビューに協力してくれた Amy Unruh と Karl Weinmeister に感謝します。
- Cloud カスタマー エンジニア、機械学習スペシャリスト Rajesh Thallam
- Cloud カスタマー エンジニア、機械学習スペシャリスト Vaibhav Singh



