Dataflow ML でリアルタイムのセマンティック検索や RAG を活用するアプリケーションを実現する方法
Reza Rokni
Dataflow Product Manager
Tabatha (Tabby) Lewis-Simo
Product Manager, AlloyDB
※この投稿は米国時間 2025 年 7 月 16 日に、Google Cloud blog に投稿されたものの抄訳です。
エンベディングは、最新のセマンティック検索アプリケーションと検索拡張生成(RAG)アプリケーションの基盤です。つまり、アプリケーションが情報をより深く概念的なレベルで理解し、扱えるようにします。この投稿では、Dataflow ML のコードを数行記述するだけでエンべディングを作成して取得し、この 2 つのユースケースを実現する方法をご紹介します。エンベディングを生成して、
AlloyDB のようなベクトル データベースに保存し、ベクトル検索機能でセマンティック検索や RAG を使ったアプリケーションを強化するための、ストリーミングとバッチの両方のアプローチを紹介します。
セマンティック検索と RAG
セマンティック検索では、単語間の根底にある関係を活用して、単純なキーワードの一致を超えた関連性の高い結果を見つけることができます。エンベディングは、テキストから動画まで、さまざまなデータのベクトル表現であり、こうした関係性を捉えます。セマンティック検索では、検索クエリに数学的に近いエンベディングを見つけます。これにより、キーワード検索では表示されなかった可能性のある、意味が近い単語や検索語句を見つけることができます。AlloyDB などのデータベースを使用すると、この非構造化検索と構造化検索を組み合わせて、関連性の高い高品質な結果を提供できます。たとえば、「過去 1 か月間に私が撮影した夕日の写真を表示して」というプロンプトには、構造化データ(撮影日が過去 1 か月以内)と非構造化データ(写真に夕日が写っていること)が含まれています。
多くの RAG アプリケーションで、エンべディングは、ナレッジベース(データベースなど)から関連するコンテキストを取得して、大規模言語モデル(LLM)のレスポンスをグラウンディングするうえで重要な役割を果たします。RAG システムは、AlloyDB などのベクトル データベースでセマンティック検索を実行したり、データベースから直接データを取得したりして、取得した結果を LLM にコンテキストとして提供できます。これにより、LLM は有益な回答を生成するために必要な情報にアクセスできます。
ナレッジ取り込みパイプライン
ナレッジ取り込みパイプラインは、自由形式の説明が記載された商品カタログ、サポート チケットのダイアログ、法的文書などの非構造化コンテンツを取り込み、エンベディングとして処理して、これらのエンベディングをベクトル データベースに push します。このナレッジのソースは、クラウド ストレージ バケット(Google Cloud Storage など)に保存されたファイルや、AlloyDB などのデータベースに保存された情報から、Google Cloud Pub/Sub または Google Cloud Managed Service for Kafka といったストリーミング ソースまで多岐にわたります。ストリーミング ソースの場合、データ自体は未加工のコンテンツ(例: 書式なしテキスト)またはドキュメントを指す URI である可能性があります。ナレッジ取り込みパイプラインを設計する際の重要な考慮事項は、バッチ形式かストリーミング形式かなど、ナレッジをどのように取り込んで処理するかです。
- ストリーミングとバッチの比較: 最新かつ関連性の高い検索結果を提供し、優れたユーザー エクスペリエンスを実現するには、ストリーミング データに対してエンべディングをリアルタイムで生成する必要があります。これは、アップロードされる新しいドキュメントや新しい商品画像など、最新の知識が大きなビジネス価値を持つ場合に有効です。バックフィルなどの時間的要件が少ないアプリケーションや運用タスクには、バッチ パイプラインが適しています。重要なのは、選択したフレームワークが、ビジネス ロジックを再実装することなく、ストリーミング処理とバッチ処理の両方をサポートできることです。
- チャンク化: データソースに関係なく、データを読み取った後には通常、情報を前処理するステップがあります。単純な未加工のテキストの場合、基本的なクリーニングで十分かもしれません。ただし、大きなドキュメントや複雑なコンテンツの場合は、チャンク化が重要なステップとなります。チャンク化は、ソースデータを管理しやすい小さな単位に分割します。最適なチャンク化戦略は、具体的なデータとアプリケーションによって異なります。
エンベディング用の Dataflows MLTransform の導入
Dataflow ML では、ストリーミングまたはバッチのナレッジ取り込みパイプラインの構築と実行のプロセス全体を簡素化する多くの機能をすぐに利用できるため、数行のコードでこれらのパイプラインを実装できます。取り込みパイプラインには通常、データソースからの読み取り、データの事前処理、エンべディングの準備、最後に正しい形式のスキーマをベクトル データベースに書き込むという 4 つのフェーズがあります。 MLTransform の新機能では、チャンク化、エンベディングの生成、Vertex モデルまたは Bring Your Own(BYO)モデルの使用、AlloyDB などのデータベースにエンベディングを永続化するための専用のライターがサポートされます。
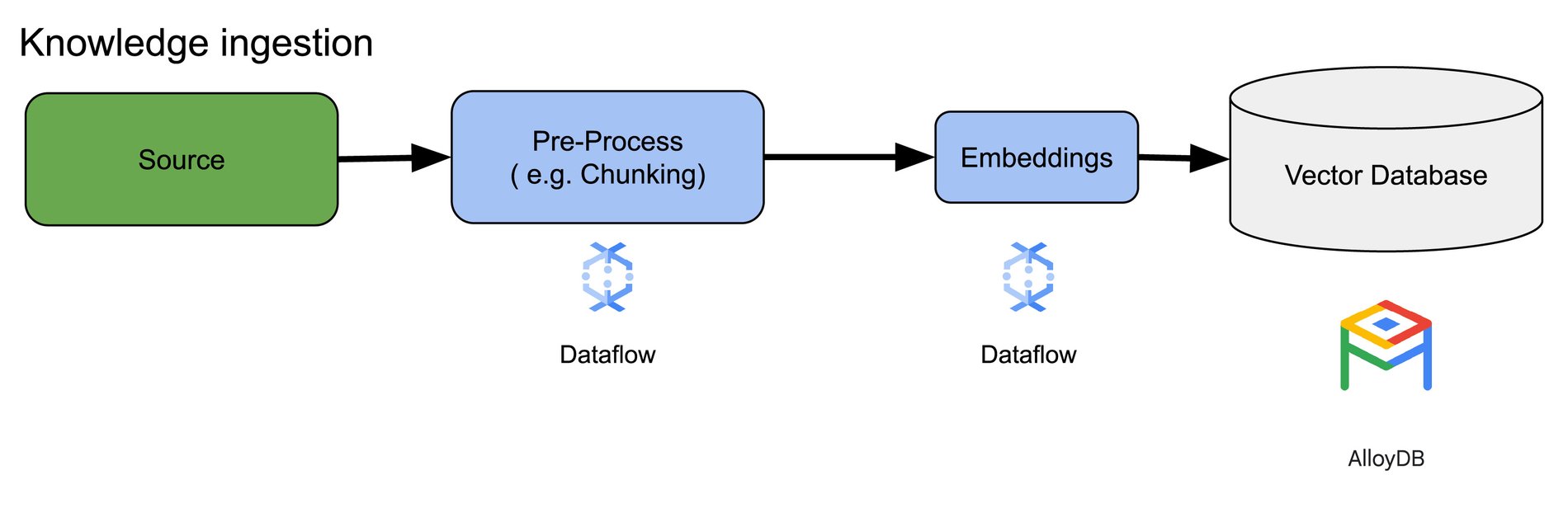
Dataflow を使用したナレッジの取り込み
Dataflow の新しい MLTransform 機能を使用すると、チャンク化、エンべディングの生成、AlloyDB へのエンべディングの保存というフローを数行のコードで実現できます。
重要な点として、Dataflow ML では、上記のエンべディング ステップで、Vertex AI エンべディングや他のモデルガーデンのモデルを利用できるほか、Dataflow ワーカーでホストされている「Bring Your Own Model(BYOM)」も利用できます。
上記の例では、要素ごとに 1 つのチャンクが作成されますが、代わりに LangChain を使用してチャンク化することもできます。
AlloyDB を使用した完全な動作例については、Dataflow を使用して AlloyDB のリアルタイム ベクトル エンベディング パイプラインを構築するをご覧ください。
RAG 向けの Dataflow 拡充変換の導入
RAG ユースケースをサポートするために、Dataflow の拡充変換機能も強化され、データベースから結果を検索できるようになりました。これにより、ベクトル データベースに保存された情報をローコード パイプラインで利用できる非同期アプリケーションをバッチモードまたはストリーム モードで作成できます。これにより、運用データでアプリケーションを拡充して、埋め込みやフィルタとして利用できるようになるため、ベクトルを別々のストレージ ソリューションに保存する必要がなくなります。
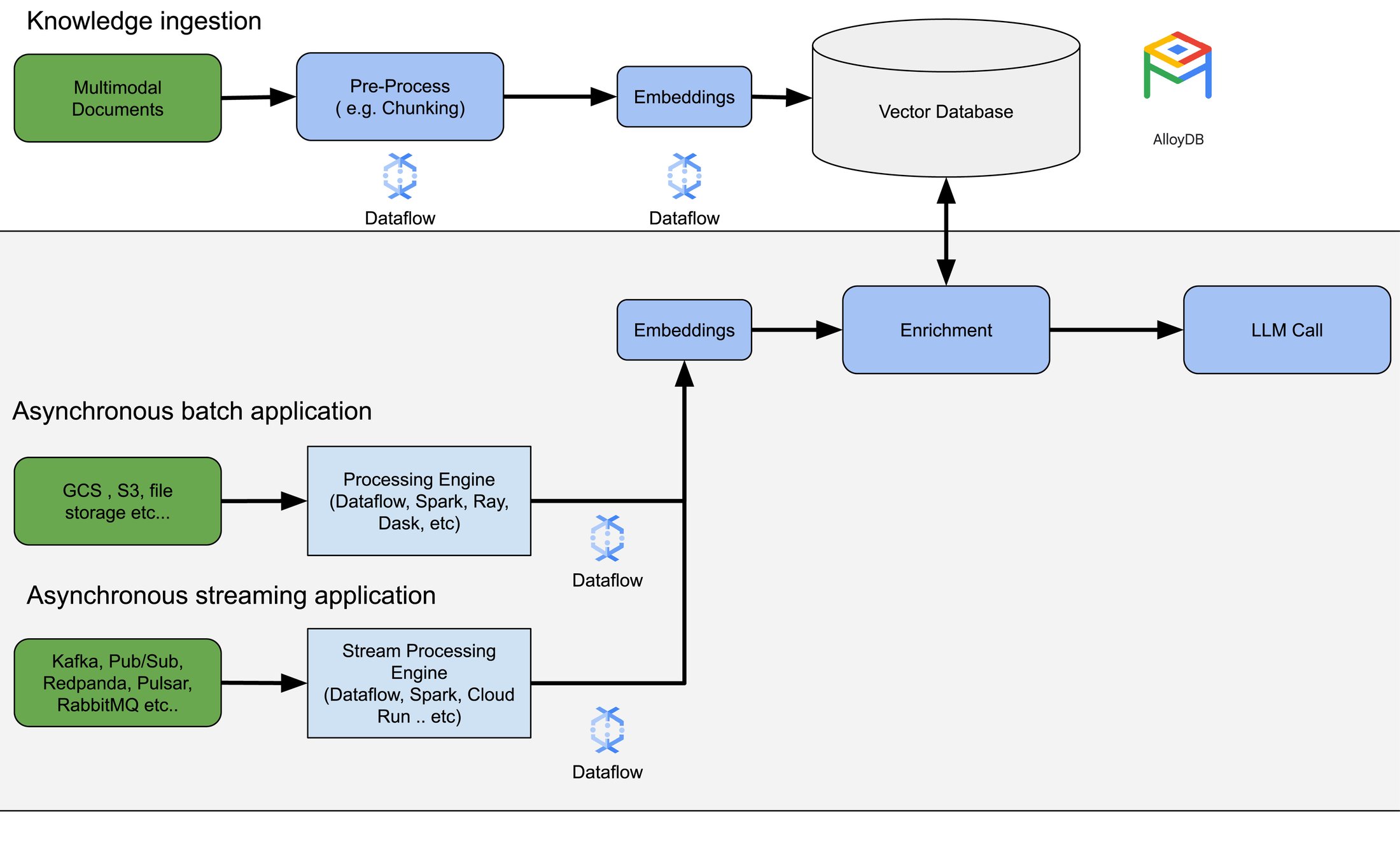
Dataflow を使用した RAG アプリケーションの構築
使ってみる
これらのシンプルなコード スニペットで、ベクトル データベースへの入力に必要なソースデータの取り込みと準備だけでなく、大量のデータと受信情報を処理することを目的としたストリーミング アプリケーションやバッチ アプリケーションで、その情報を利用する方法も示しました。実際の詳細な例については、サンプルをご覧ください。詳細な例や Colab については、Dataflow ML のドキュメントをご覧ください。ぜひ AlloyDB でベクトル検索を使ってみてください。30 日間の AlloyDB の無料トライアルもお試しいただけます。
このブログ投稿の執筆に協力してくれた Dataflow ML エンジニアリングの Claude van der Merwe に心より感謝します。
ー Dataflow プロダクト マネージャー、Reza Rokni
ー AlloyDB プロダクト マネージャー、Tabatha Lewis-Simo