Vertex AI の Gemini Live API に関するデベロッパー ガイド

Shubham Saboo
Senior AI Product Manager
Zack Akil
Developer Relations Engineer
Try Gemini 3.1 Pro
Our most intelligent model available yet for complex tasks on Gemini Enterprise and Vertex AI
Try now※この投稿は米国時間 2025 年 12 月 13 日に、Google Cloud blog に投稿されたものの抄訳です。
単一の WebSocket 接続を通じて、AI アプリやエージェントに、人間のような自然なインターフェースを与えることができます。
このたび、Google は最新の Gemini 2.5 Flash ネイティブ音声モデルを搭載した Gemini Live API の一般提供を Vertex AI で開始したことを発表しました。これは単なるモデルのアップグレードではありません。柔軟性に欠けるマルチステージの音声システムから、単一のリアルタイムかつ感情を認識するマルチモーダルな会話アーキテクチャへの根本的な脱却です。
次世代のマルチモーダル AI アプリケーションの構築において、これが何を意味するのか、デベロッパーの皆様に詳しくご紹介します。この投稿では、Gemini Live API を最大限に活用する方法を理解するのに役立つ、2 つのテンプレートと 3 つの参考デモを取り上げます。
新しい音声基盤としての Gemini Live API
これまで、会話型 AI の構築には、音声入力(STT)、大規模言語モデル(LLM)、テキスト読み上げ(TTS)の高レイテンシ パイプラインを組み合わせる必要がありました。この逐次プロセスが、不自然なターン テイキングの遅延を生み、会話が自然に感じられない原因となっていました。
Gemini Live API は、統合された低レイテンシのネイティブ音声アーキテクチャにより、エンジニアリングのアプローチを根本的に変えます。
-
ネイティブ音声処理: Gemini 2.5 Flash ネイティブ音声モデルは、単一の低レイテンシ モデルを通じて、生の音声をネイティブに処理します。この統合は、レイテンシを劇的に短縮する中核的な技術革新です。
-
リアルタイムのマルチモダリティ: この API は、音声、テキスト、視覚のモダリティを統合的に処理するよう設計されています。エージェントは、音声入力と同時に、ユーザーが共有するグラフやライブ動画フィードなどの視覚データに基づいたトピックについて会話することができます。
次世代の会話機能
Gemini Live API は、AI エージェントの新しい標準を定義する、プロダクション レディな機能スイートを提供します。
-
感情認識対話(感情的な知性): モデルは、生の音声をネイティブに処理することで、トーン、感情、ペースなどの微妙な音響的なニュアンスを解釈できます。これにより、エージェントは緊張したサポート通話を自動的に沈静化したり、適切な共感的トーンを選択したりできます。
-
プロアクティブ音声(よりスマートな割り込み): この機能は、単純な音声アクティビティ検出(VAD)を超えたものです。ライブデモでご紹介したように、エージェントがいつ応答し、いつ静かな聞き手に徹するべきかをインテリジェントに判断するよう設定できます。これにより、受動的なリスニングが求められる場面で不要な割り込みを防ぎ、真に自然な対話を実現できます。
-
ツールの使用: デベロッパーは、関数呼び出しや Google 検索によるグラウンディングなどのツールを、リアルタイムの会話にシームレスに統合できます。これにより、エージェントは最新の実世界の知識を取得し、音声や視覚的な入力に基づいて複雑なアクションを即座に実行できます。
-
継続的なメモリ: エージェントは、すべてのモダリティにわたって、長く継続的なコンテキストを維持できます。
-
エンタープライズ グレードの安定性: 一般提供が開始となったことで、本番環境ワークロードに必要な高可用性が提供されます。これには、エージェントが世界中のユーザーに対して応答性と信頼性を維持できるようにする、マルチリージョン対応などが含まれます。

デベロッパー向けクイックスタート: 利用方法
低レイテンシのリアルタイム音声がもたらす力を体験する最も簡単な方法は、データの流れを理解することです。リクエストを行い待機する REST API とは異なり、Gemini Live API では双方向ストリームを管理する必要があります。
Gemini Live API のフロー
コードに入る前に、本番環境のアーキテクチャを可視化しておくことが重要です。プロトタイピングでは直接接続も可能ですが、ほとんどのエンタープライズ アプリケーションでは、安全なプロキシフローが必要です: ユーザー向けアプリ -> バックエンド サーバー -> Gemini Live API(Google バックエンド)
このアーキテクチャでは、フロントエンドがメディア(マイクやカメラ)をキャプチャして、安全なバックエンドにストリーミングします。バックエンドは、Vertex AI の Gemini Live API への永続的な WebSocket 接続を管理します。これにより、機密性の高い認証情報がサーバーから漏洩することを防ぎ、データが Google に流れる前に、ビジネス ロジックの注入、会話の状態の保持、アクセス制御の管理が可能になります。
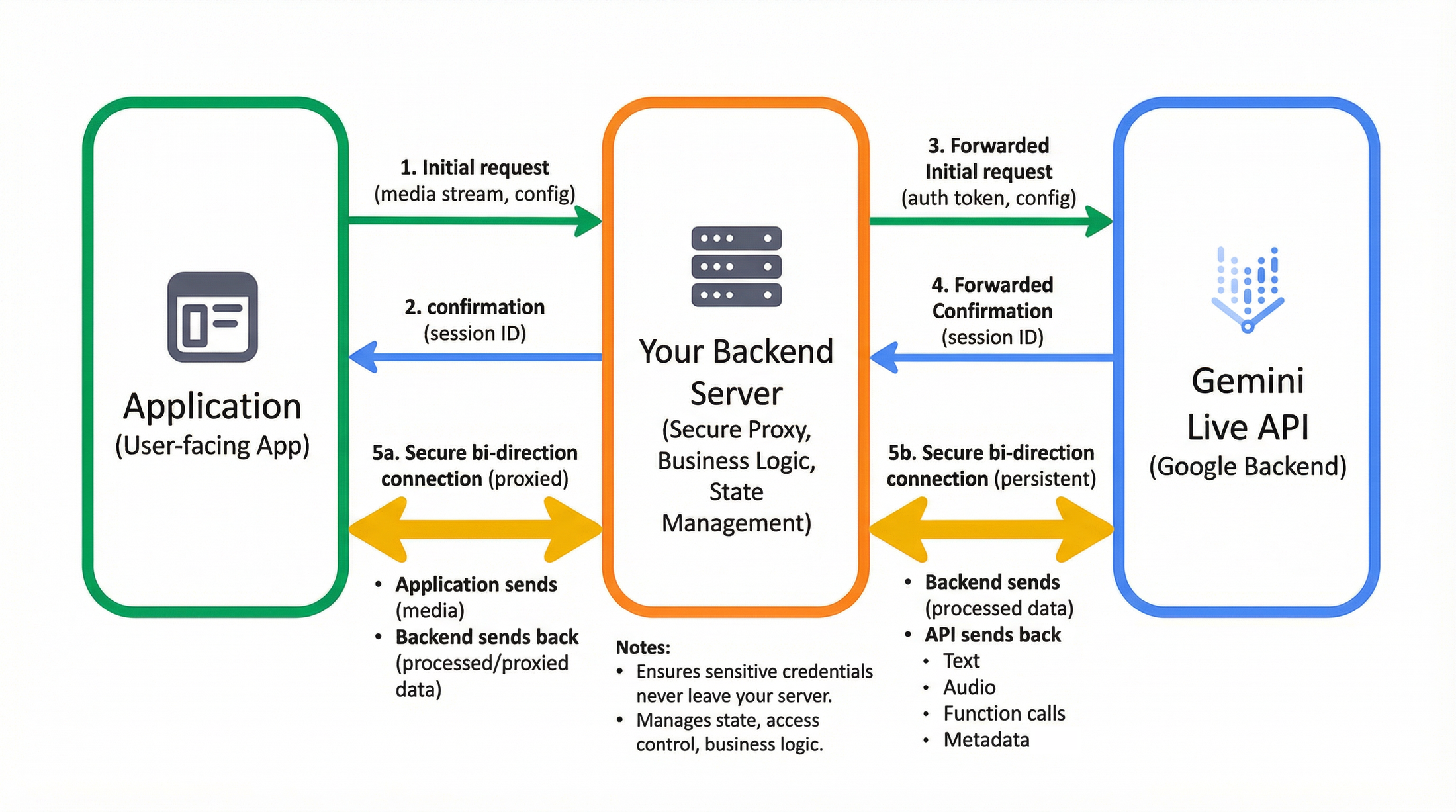
すぐに使用を開始できるよう、2 つの異なるクイックスタート テンプレートをリリースしました。1 つは生のプロトコルを理解するためのもの、もう 1 つは最新のコンポーネントベース開発向けのものです。
オプション A: Vanilla JS テンプレート(依存関係なし)
最適な用途: フレームワークのオーバーヘッドなしで、生の WebSocket の実装とメディア処理を理解する。
このテンプレートは WebSocket handshake とメディア ストリーミングを処理し、ロジックを構築するためのまっさらな土台を提供します。
プロジェクト構造:
コア実装: ステートフルな WebSocket 接続を介して gemini-live-2.5-flash-native-audio モデルとやり取りします。
Vanilla JS デモの実行:
詳細な手順を解説した動画に沿って進めてください。
上級者向けのヒント: 生の音声のデバッグ 生の PCM 音声ストリームは扱いにくいことがあります。音声チャンクの検証や Base64 文字列のテストが必要な場合に備え、リポジトリに PCM Audio Debugger を用意しています。
オプション B: React デモ(モジュール式で最新)
最適な用途: 複雑な UI を含む、スケーラブルで本番環境対応のアプリケーションを構築する。
堅牢なエンタープライズ アプリケーションを構築する場合は、React スターターが役立ちます。高性能かつ低レイテンシの音声処理を実現するため、AudioWorklets を使用したモジュール式アーキテクチャを提供します。
機能:
-
リアルタイム ストリーミング: React の状態管理を使用した Gemini への音声と動画のストリーミング。
-
AudioWorklets: 専用の音声処理スレッドに capture.worklet.js と playback.worklet.js を使用します。
-
安全なプロキシ: Python バックエンドが Google Cloud 認証を処理します。
プロジェクト構造:
React デモの実行:
詳細な手順を解説した動画に沿って進めてください。
パートナーとの統合
特定の電話通信環境やウェブ リアルタイム通信環境で、よりシンプルな開発プロセスを希望する場合は、Daily、Twilio、LiveKit、Voximplant とのサードパーティ パートナー統合を利用できます。これらのプラットフォームは、ウェブ リアルタイム通信プロトコルを介して Gemini Live API を統合しているため、ネットワーク スタックを自ら管理することなく、既存の音声および動画ワークフローにこれらの機能を直接組み込むことができます。
Gemini Live API: 3 つのプロダクション レディなデモ
いずれかのテンプレートで基盤を構築した後、それをどのようにプロダクトへとスケールすればよいでしょうか。Gemini Live API の 3 つの異なる「スーパーパワー」を紹介するデモを構築しました。
1. リアルタイムかつプロアクティブなアドバイザー エージェント
真に自然な会話型 AI を構築するための鍵は、単なる chatbot ではなく、パートナーを作成することにあります。この特殊なアプリケーションは、会話を聞き、提供されたナレッジベースに基づいて関連する分析情報を提示するビジネス アドバイザーの構築方法を示します。
このアプリケーションは、プロフェッショナル エージェントにとって重要な 2 つの機能、動的な知識注入とデュアル インタラクション モードを実演します。
-
シナリオ: アドバイザーがビジネス ミーティングに参加します。アドバイザーは、ユーザーが UI で定義した注入データ(収益統計、従業員数)にアクセスできます。
デュアルモード:
-
サイレント モード: アドバイザーは発話せずに会話を聞き、show_modal ツールを介して視覚情報を「プッシュ」します。会話を遮らずデータだけを提示し、目立たずに支援してもらいたい場合に最適です。
-
アウトスポークン モード: アドバイザーが丁寧に口頭で介入し、音声による応答と視覚データを組み合わせてアドバイスを提供します。
-
割り込み制御: このデモでは、activity_handling 構成を使用して、ユーザーが誤ってアドバイザーを遮ってしまうことを防ぎます。これにより、必要に応じて複雑なアドバイスを最後まで確実にユーザーに届けることができます。
-
ツールの使用: カスタムの show_modal ツールを使用して、構造化された情報をユーザーに表示します。

リアルタイム アドバイザー エージェントの実装に関するソースコード全体については、GitHub リポジトリをご覧ください。
2. マルチモーダル カスタマー サポート エージェント
カスタマー サポート エージェントは、「見て」そして「聞いて」得た情報に基づき行動できなければなりません。このデモでは、音声ストリームにコンテキストに基づいたアクションと感情認識対話を重ね合わせ、問題を即座に解決できるサポート エージェントを作成しています。
このアプリケーションは、エージェントがユーザーと同じものを見て、声のトーンを理解し、問題解決のためにアクションを即座に実行できる、未来的なカスタマー サポートのやり取りをシミュレートします。ユーザーは返品する商品について説明する必要はなく、カメラに商品を見せるだけで、エージェントが、この視覚的入力と感情の理解を組み合わせ、実際のアクションにつなげます。
-
マルチモーダル理解: エージェントは、ユーザーの要望を聞きつつ、ユーザーが提示した商品を視覚的に確認します(返品商品の確認など)。
-
共感的な応答: 感情認識対話を使用して、エージェントはユーザーの感情(不満、混乱)を検出し、共感を持って応答するためにトーンを調整します。
-
アクションの実行とツールの使用: 単にチャットするだけでなく、process_refund(トランザクション ID の処理)や connect_to_human(複雑な問題の転送)などのカスタムツールを使用して、実際に問題を解決します。
-
リアルタイムのインタラクション: WebSocket 経由で Gemini Live API を使用した低レイテンシの音声インタラクション。

マルチモーダル カスタマー サポート エージェントの実装に関するソースコード全体については、GitHub リポジトリをご覧ください。
3. リアルタイムのビデオゲーム アシスタント
ゲームは、コパイロットがいるともっと楽しくなります。このデモでは、単なるチャットを超え、ゲームプレイを見守りながら、ユーザーのスタイルに適応する真のコンパニオンとなるリアルタイム ゲームガイドを構築します。
この React アプリケーションは、スクリーン キャプチャとマイクの音声を同時にモデルにストリーミングするため、エージェントはゲームの状態を即座に把握できます。このアプリケーションは、3 つの高度な機能を実演します。
-
マルチモーダル認識: エージェントが第二の目のように機能し、画面を分析して、見落としがちな敵や戦利品、パズルのヒントを見つけます。
-
ペルソナの切り替え: 謎めいたヒントをくれる「賢者の魔法使い」から、戦術的な指示を出す「SF ロボット」や「司令官」まで、エージェントのペルソナを動的に切り替えることができます。これは、システム指示によって、アシスタントの音声やスタイルを即座に変更できることを示しています。
-
Google 検索グラウンディング: エージェントがリアルタイムの情報を取得し、最新の攻略情報やヒントを提供するため、新しいレベルで行き詰まることはありません。

リアルタイム ビデオゲーム アシスタントの実装に関するソースコード全体については、GitHub リポジトリをご覧ください。
今すぐ利用開始
-
今すぐお試し: Vertex AI Studio で Gemini Live API をぜひお試しください。
-
構築を開始: Vertex AI の Gemini Live API にアクセスして、チャットボットの枠を超え、真にインテリジェントで、応答性が高く、共感的なユーザー エクスペリエンスを構築しましょう。
-
コードを入手: すべてのデモとクイックスタートは、Google の公式 GitHub リポジトリで入手できます。
-シニア AI プロダクト マネージャー、Shubham Saboo
-デベロッパー リレーションズ エンジニア、Zack Akil



