モデル適応をマスターする: Google Cloud でのファインチューニング ガイド

Drew Brown
Developer Advocate
※この投稿は米国時間 2026 年 2 月 12 日に、Google Cloud blog に投稿されたものの抄訳です。
AI アプリケーションを構築している場合、プロンプトをテストしたり、エージェントを試してみたりするかもしれません。しかし、プロトタイプから本番環境に移行するにつれて、モデルの整合性が十分でないという、よくある壁にぶつかることがあります。
Gemini は非常に優れた汎用基盤モデルですが、ブランドのスタイルガイドに沿った回答をより一貫して生成したい場合や、API がカスタムの非標準 JSON 形式で毎回フォーマットされるようにしたい場合もあるでしょう。多くの場合は、プロンプト エンジニアリングとコンテキスト内学習だけで必要な結果を得ることができます。しかし、より専門性の高い本番環境要件に移行するにつれて、モデルの能力をさらに引き出したいと考えるかもしれません。そこでファインチューニングの出番です。
ファインチューニングでは、Gemini 2.5 Flash などの汎用モデルや Llama などのオープンソース モデルを、特定のドメインに適応させることができます。独自の例を含むキュレートされたデータセットでモデルをトレーニングすることで、次のことが可能になります。
-
整合性を確保する: 特定の回答スタイルや非標準のデータ形式を毎回返すことができます。
-
効率を高める: 一部のタスクでは、ファインチューニングされた、より小さく、安価で、レイテンシの低いモデルでも同様のパフォーマンスを実現できます。
-
特化する: トレーニング データが少ない分野では、ファインチューニングによって精度が向上し、ハルシネーションが減少します。
Google は、プロダクション レディな AI シリーズの一環として、Google Cloud における 2 つの異なるファインチューニング オプションをカバーする 2 つの新しいハンズオンラボをリリースします。1 つは Vertex AI のフルマネージド エクスペリエンス、もう 1 つは Google Kubernetes Engine(GKE)の自由にカスタマイズ可能なパスです。
オプション 1: Vertex AI を使用したマネージドパス
多くのデベロッパーにとって、目標はインフラストラクチャのオーバーヘッドをできるだけ抑えながらモデルのパフォーマンスを向上させることです。すぐにモデル適応を実現できる「ボタン」があったら便利でしょう。
Vertex AI には、Gemini などのモデルをファインチューニングするためのフルマネージド サービスが用意されています。GPU のプロビジョニング、チェックポイントの管理、複雑なトレーニング ループの記述について心配する必要はありません。データを指定してパラメータを構成するだけで、残りの処理は Vertex AI が行います。
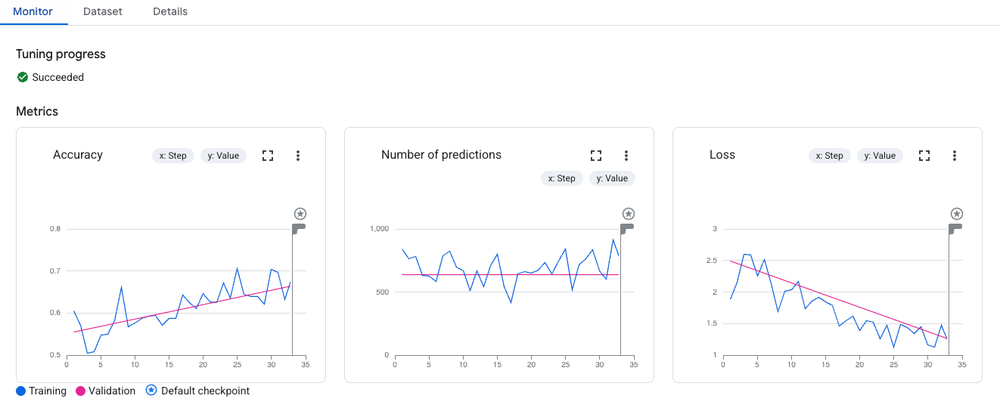
最初の新しい Codelab では、軽量で効率性の高いモデルである Gemini 2.5 Flash をファインチューニングする方法をご紹介します。Vertex AI SDK for Python を使用した教師ありファインチューニング(SFT)のワークフロー全体を知ることができます。
学習内容
-
データ準備: Gemini で想定される JSONL 形式に元データを変換する方法。
-
ベースライン: 改善を定量化するために、まずベースモデルを評価する方法。
-
チューニング: わずか数行の Python でチューニング ジョブを起動する方法。
-
評価: ROUGE などの自動指標を使用して、新しいチューニング済みモデルをベースモデルと比較する方法。
オプション 2: GKE を使用したカスタムパス
本番環境の要件によっては、完全な制御が必要になることがあります。Llama、Mistral、Gemma などのオープンソース モデルを使用している場合、特定の重みを調整したり、カスタム トレーニング ライブラリを使用したり、特定のハードウェア構成で実行したりする必要があります。
Google Kubernetes Engine(GKE)は、そのために最適なプラットフォームです。Google のスケーラブルなインフラストラクチャのメリットを享受しながら、独自の GPU リソースと環境を管理し、AI ワークロードを柔軟にオーケストレートできます。
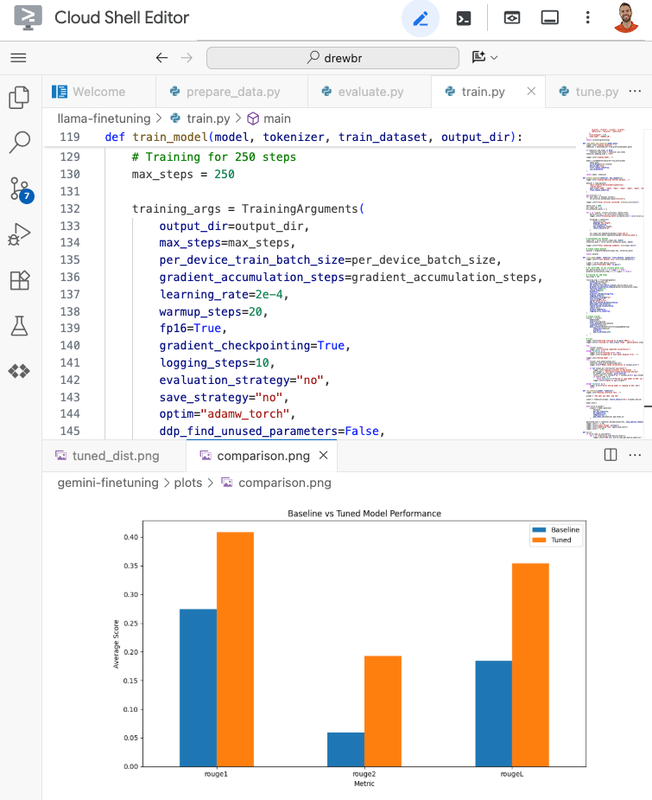
2 つ目のファインチューニング Codelab では、Kubernetes における MLOps の基本を学びます。LoRA(Low-Rank Adaptation)と呼ばれる手法を使用して Llama 2 をファインチューニングします。LoRA では、事前トレーニング済みモデルの重みが固定され、目的に合わせてチューニングされた、より小さいトレーニング可能なパラメータ レイヤが注入されるため、多くのモデルを効率的にファインチューニングできます。これにより、トレーニングが必要なパラメータの数が大幅に減り、より小さく、費用対効果の高いアクセラレータで巨大なモデルをファインチューニングできるようになります。
学習内容
-
インフラストラクチャ: GPU ノードプール(特に NVIDIA L4 GPU を使用)で GKE クラスタをプロビジョニングする方法。
-
効率性: LoRA を使用して、膨大な費用をかけなくても 70 億パラメータ モデルをファインチューニングできる方法。
-
セキュリティ: Workload Identity を使用して、サービス アカウントキーを管理しなくても Cloud Storage に安全にアクセスできる方法。
-
コンテナ化: 再現可能な実行のために、PyTorch トレーニング コードを Docker コンテナにパッケージ化する方法。
どのパスを選択すべきか?
-
Vertex AI は、迅速なイテレーションが必要であり、マネージド サービスを希望し、Google の強力な Gemini モデルを基盤として構築する場合に選択できます。
-
GKE を選択できるのは、詳細なカスタマイズが必要な場合、オープンソース エコシステム(Hugging Face、Llama など)にコミットしている場合、またはトレーニングを既存の Kubernetes ベースのプラットフォームに緊密に統合する必要がある場合です。
どちらのパスを選んでも同じ目的地、つまり汎用モデルでは決して実現できないレベルでビジネスを理解した、本番環境対応のモデルに到達できます。
プロトタイプから本番環境へ
これらのラボは、Google の公式な学習プログラムである「Google Cloud でのプロダクション レディな AI」の一部です。有望なプロトタイプから堅牢な本番環境グレードの AI アプリケーションへの移行に役立つコンテンツについては、カリキュラム全体をご覧ください。
ハッシュタグ #ProductionReadyAI で成果を共有し、仲間とつながりましょう。ぜひご活用ください。
- デベロッパー アドボケイト、Drew Brown



