Gemini を使用してコードサンプルを大規模に生成する際の 7 つの技術的なポイント

Nim Jayawardena
Senior Developer Relations Engineer
Adam Ross
Staff Developer Relations Engineer
※この投稿は米国時間 2026 年 2 月 12 日に、Google Cloud blog に投稿されたものの抄訳です。
生成 AI を使用したコードの作成はよく知られたタスクですが、別の課題として、生成 AI を利用してプロダクション レディな教育コンテンツを作成することが挙げられます。Google Cloud プロダクトの説明に利用できるリソースの幅を広げる作業に Gemini を活用し始めたとき、既存の汎用的な生成 AI 搭載アプリやツールだけでは不十分で、ユースケースに合わせた専用のシステムが必要であることに気づきました。
解決しようとしていた問題
Google Cloud には 100 以上のプロダクトがあります。各プロダクトには、JavaScript、Python、Go、Java などの言語のクライアント ライブラリを使用して作成、操作、クエリできる独自のリソースセットがあります。Google のチームは、開発者がこれらのクライアント ライブラリを使用する方法を学ぶためのサンプルコードを用意しています。
例として、@google-cloud/storage-control Node.js クライアント ライブラリを使用して Google Cloud Storage の「フォルダ」リソースを一覧表示する方法を示すサンプルがあります。
近年、Google は生成 AI を活用してこれらのサンプルを開発しています。これは驚くことではありません。しかし、2024 年後半に、より体系的なアプローチを取り始め、チームが高品質なサンプルを迅速に作成できるよう、専用のツールセットを開発しました。これらのツールは、Vertex AI の Gemini と Genkit(生成 AI ツール開発用のオープンソース フレームワーク)を活用した、一連の決定論的な自動化と AI ワークフローで構成されています。
このブログ投稿では、まずサンプル生成システムのアーキテクチャの概要を説明し、次に開発プロセスから得られた 7 つの技術的なポイントをご紹介します。
サンプル生成アーキテクチャ
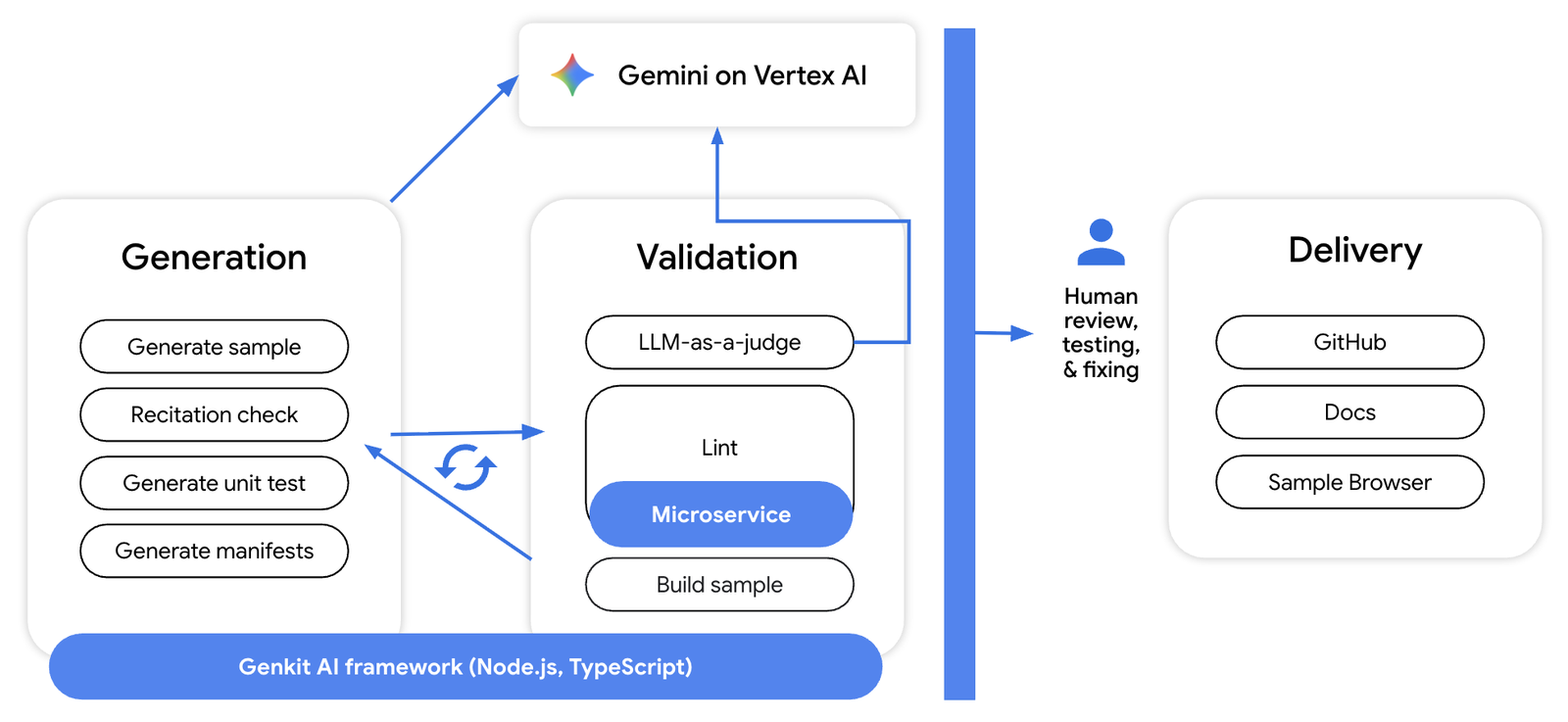
このシステムは、次のサブシステムで構成されています。
-
生成: このサブシステムは Gemini を使用して、サンプル ファイルと、単体テストや依存関係マニフェスト(package.json や requirements.txt など)といったその他の必要なアーティファクトを作成します。
-
検証: 生成されたコードは、検証サブシステムによって「LLM-as-a-judge」と決定論的ツール(linter など)を組み合わせて評価され、クラウド スタイルや言語固有のベスト プラクティスなどのカテゴリでコードにスコアが付けられます。そのフィードバックは生成システムに送り返され、サンプルが改良されます。
-
デリバリー: 生成されたサンプル(および単体テストなどの関連するアーティファクト)は、人間によるレビューとテストを経て、GitHub リポジトリ、サンプル ブラウザ、その他の docs.cloud.google.com ページに公開されます。
このようなアーキテクチャを踏まえ、開発プロセスから得られた7 つの技術的なポイントをご紹介します。
7 つの技術的なポイント
これらの知見は、基本的なプロンプト エンジニアリングを超えて、プロダクション レディな生成 AI システムを構築およびスケーリングするための実用的なロードマップとなります。
ポイント 1: 分解する
私たちが当初 Gemini にもたらしていた問題は、問題が大きすぎることでした。
各サンプル ファイルは 50~100 行程度です。システムの初期バージョンでは、1 回のプロンプトで Gemini がファイル コンテンツの大部分を生成することを想定していました。しかし、特に私たちのユースケースではコードの各行が非常に細かくなるため、Gemini(2.5)ではこの問題が大きすぎることがわかりました。Gemini が指示から逸脱するケースは数多くありました。下の画像で、左側のコードには Gemini が生成したコード(具体的には約 20 行のコード)が含まれており、右側のコードには、私たちが実際に臨んでいたコード行が含まれています。2 つのコードチャンクの間には、不要なコメントや不要な process.exit() 呼び出しなど、多くの差分(つまり違い)があることがわかります。
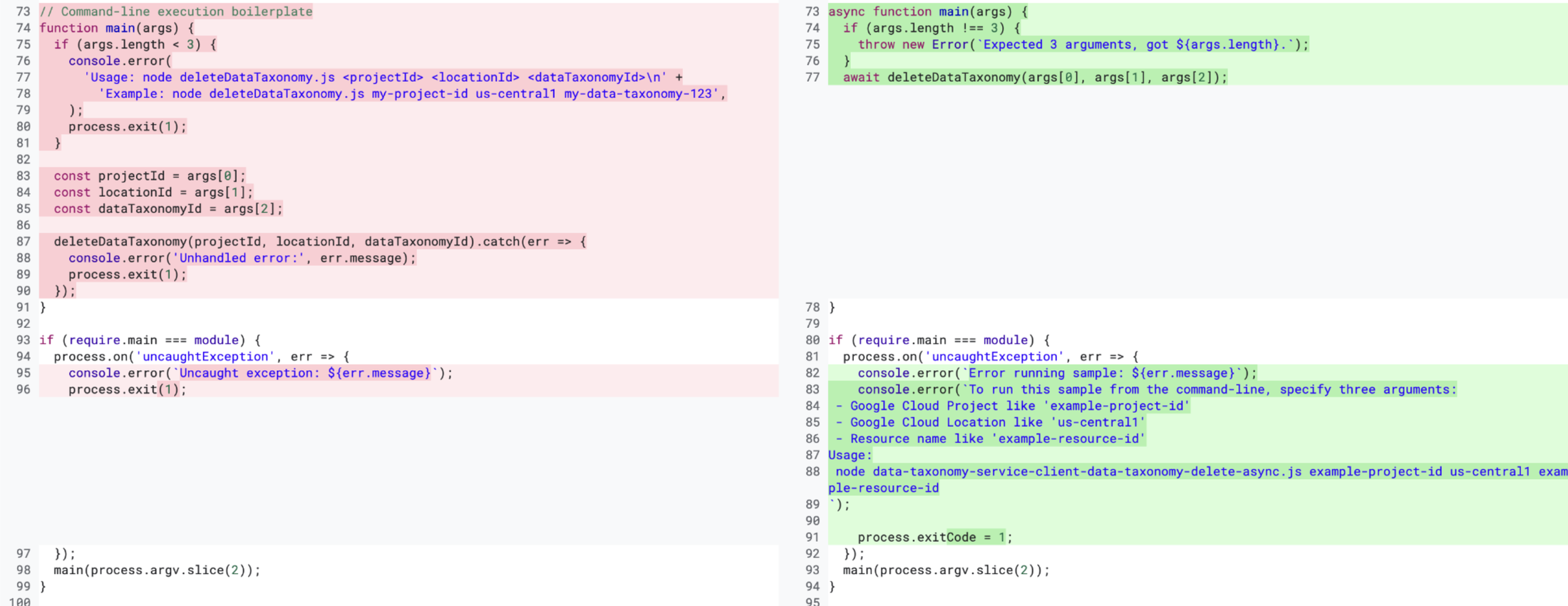
問題をより小さなサブ問題に分ける必要があることは明らかでした。分解が必要だったのです。私たちの場合、サンプル ファイルを複数のパーツに分割しました。サンプル ファイルは、次の要素で構成されています。
-
スニペット: 開発者にとって役立つ、サンプル ファイルの教育的パーツ
-
CLI ロジック: ユーザーがコマンドライン インターフェースを使用してサンプル ファイルを呼び出すことを可能にする
サンプルを意味のあるパーツに分割し、各パーツに個別の生成プロンプトを割り当てることで、LLM のハルシネーションと指示からの逸脱を大幅に減らすことができました。
重要なポイント 2: 決定論を採用する
発生した問題が決定論的に簡単に解決できる場合は、決定論的に解決します。
発生した特定の問題を解決しようとするとき、最初に Gemini を思い浮かべてしまうという、視野狭窄のような状態に陥りやすい時期もありました。LLM の導入ではなく、自動化の導入というより大きな目標を忘れてしまうこともありました。発生した問題の多くを解決する、既存の確実な決定論的方法があることを忘れがちでした。
現在でも、ファイルに Apache ライセンス ヘッダーを追加する、依存関係マニフェスト(package.json ファイルなど)を生成する、LLM で生成されたコードの lint 関連の問題を自動修正する、lint 関連のフィードバックを生成して Gemini に送り返すなど、システムが決定論的に行うことはたくさんあります。
ポイント 3: プロンプトを具体的に記述する
プロンプトは具体的に記述し、暗黙の前提を明示します。もちろん、これはプロンプト エンジニアリングの基本です。しかし、その重要性は過言ではありません。
具体的に記述することは特に重要でした。なぜなら、開発者が記述する他のほとんどの種類のコードとは異なり、サンプルコードには次のような特長があるからです。
-
多くのオーディエンスがおり、その多くはプログラミング初心者である
-
教育目的で存在している。主なオーディエンスは、コードが実行されるマシンではなく人間です。
-
異なるプロダクト間で一貫している必要がある。どのサンプルも同じ開発者が書いたようにする必要があります。
そのため、ユーザーが読む可能性のあるすべての行を計画的に作成する必要があります。
プロンプトで数十もの異なるルールを明示する必要がありました。たとえば、私たちがワンショットの例として作成したサンプルでは「projectId」パラメータのデフォルト値を設定していないのに、Gemini は設定しました。Gemini にそうしないよう明示的に指示する必要がありました。
プロンプトを具体的に記述することで、次のことも可能になりました。
-
検証システムのフィードバックに埋め込まれていた指示の一部をシフトレフトする必要がありました。つまり、最初の世代のプロンプトの初期バージョンでは、モデルが検証システムからのフィードバックを通じて後で学習する重要な指示がモデルに与えられていませんでした。
-
人間が生成するサンプルの種類に関する専門知識を深める必要がありました。つまり、チームとしてこれまで体系的に回答したことのないサンプルに関する質問に答える必要があったのです。サンプルについて 100 以上の異なる設計上の決定事項について合意に達しました。
ポイント 4: 評価者を評価する
一般的に、評価システムは生成システムよりも信頼できますが、評価システムも慎重に評価する必要があります。
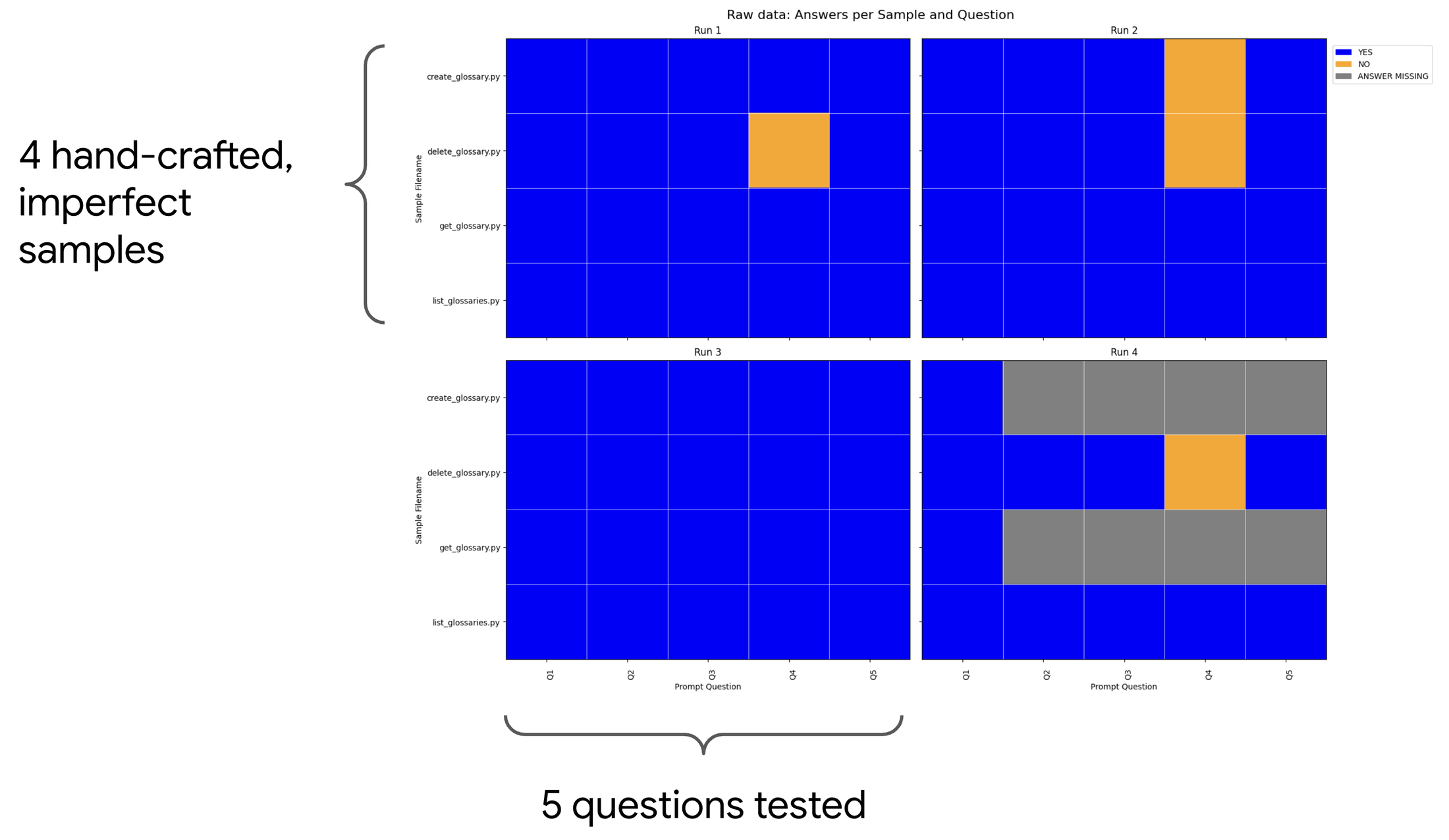
生成評価モデルがうまく機能するのは、人間と同じように、LLM は一般的に、評価対象のコンテンツを作成するよりも、コンテンツを評価する方が得意だからです。しかし、評価システム(または検証システム)の信頼性を高めるために、(LLM-as-a-judge LLM の評価プロンプトから得られた)いくつかの質問に対する Gemini の回答と、手作業で作成したデータセットを比較しました。私たちは、LLM-as-a-judge の質問の一部について、不完全なサンプルとそれに関連する正解を手作業で作成しました。下の図では、4 つの不完全なサンプルで 5 つの質問が評価されています。黄色(薄い色)の正方形は、Gemini が正しく回答できなかった質問を表しています。LLM が確実には回答できない「危うい」質問を特定できました。このプロセスにより、これらの「危うい」質問を破棄し、評価プロンプト全体を改良することができました。
ポイント 5: 他の側面もスケーリングする
システムの LLM 以外の側面もスケーリングできるようにします。
chat bot やコードの自動補完とは異なり、私たちのユースケースでは Gemini からの即時のフィードバックは必要ありません。単一のサンプル、検証フィードバック、および単体テストなどの関連するアーティファクトの生成が完了するまで、1 分ほど待つ余裕がありました。さらに、Gemini は、生成した数百ものサンプルの中でも、ユースケースの費用を低く抑えてくれました。そのため、Google のシステムの LLM 関連の側面はうまくスケーリングできました。
しかし、プロセスの最終工程は同じようにはうまくいきませんでした。サンプルを公開する準備には、サンプルあたり約 5~15 分かかりました。各サンプルの人間によるレビューとエンドツーエンドのテストが含まれるため、このプロセスが最大のボトルネックとなりました。
ポイント 6: 最終的な出力をエンドツーエンドでテストする
コードが機能しない場合は、公開できません。
そのため、公開するサンプルをエンドツーエンドでテストすることが重要でした。これは、おそらく教訓というよりは、チームとしてたどり着いた哲学的なコンセンサスです。
私たちが公開するコードは、ユーザーが実行することを想定して設計されています。ユーザーと同じような状況で自分たちが実行できるのでなければ、ユーザーにとって役に立つことが実証されたサンプルを提供することはできません。当初から、手書きのサンプルは、公開前に手動またはプログラムでエンドツーエンド テストを行っています。サンプルの作成方法を変えても、サンプルの品質が低下してはなりません。
DORA は、この「信頼するが検証はする」アプローチを「成熟した AI 導入」の兆候として説明しています。厳格なエンドツーエンド テストは、私たちのためだけでなく、サンプルを利用する開発者の信頼を維持するために不可欠です。
ポイント 7: 優れたエンジニアリングを行う
確立されたエンジニアリングのベスト プラクティスを適用すれば、他のすべては後からついてきます。
よく考えてみると、上述したポイントの多くは、LLM を大規模に使用してコンテンツやコードを生成する分野に特有のものではありません。これらのシステムを構築する際に下した、プラスの影響をもたらすエンジニアリング上の決定の多くは、LLM とはまったく関係がなく、上記のポイントでも言及されていません。
まとめ
高品質な教育用コードサンプルを大規模に生成する過程で、成功の鍵は強力な LLM だけではないことがわかりました。Gemini と Genkit が必要な生成能力を提供してくれましたが、真のブレークスルーは、専門的なエンドツーエンドのシステムを構築したことによってもたらされました。問題を分解すること、決定論を採用すること、エンドツーエンドのテスト、パイプライン全体のスケールなど、ここで説明した 7 つのポイントは、LLM と確立されたエンジニアリング プラクティスを組み合わせた、信頼性が高くスケーラブルな生成システムを構築する方法を示しています。
- シニア デベロッパー リレーションズ エンジニア、Nim Jayawardena
- スタッフ デベロッパー リレーションズ エンジニア、Adam Ross



