Orchestrating PyTorch ML Workflows on Vertex AI Pipelines
Rajesh Thallam
Solutions Architect, Generative AI Solutions
Previously in the PyTorch on Google Cloud series, we trained, tuned and deployed a PyTorch text classification model using Training and Prediction services on Vertex AI. In this post, we will show how to automate and monitor a PyTorch based ML workflow by orchestrating the pipeline in a serverless manner using Vertex AI Pipelines. Let’s get started!
Why Pipelines?
Before we dive in, first, let’s understand why pipelines are needed for ML workflows? As seen previously, training and deploying a PyTorch based model encapsulates a sequence of tasks such as processing data, training a model, hyperparameter tuning, evaluation, packaging the model artifacts, model deployment and retraining cycle. Each of these steps have different dependencies and if the entire workflow is treated as a monolith, it can quickly become unwieldy.

As the ML systems and processes begin to scale, you might want to share your ML workflow with others on your team to execute the workflows or contribute to the code. Without a reliable, reproducible process, this can become difficult. With pipelines, each step in the ML process runs in its own container. This lets you develop steps independently and track the input and output from each step in a reproducible way allowing to iterate experiments effectively. Automating these tasks and orchestrating them across multiple services enables repeatable and reproducible ML workflows that can be shared between different teams such as data scientists, data engineers.
Pipelines are also a key component to MLOps when formalizing training and deployment operationalization to automatically retrain, deploy and monitor models. For example, triggering a pipeline run when new training data is available, retraining a model when performance of the model starts decaying and more such scenarios.
Orchestrating PyTorch based ML workflows with Vertex AI Pipelines
PyTorch based ML workflows can be orchestrated on Vertex AI Pipelines, which is a fully managed and serverless way to automate, monitor, and orchestrate a ML workflow on Vertex AI platform. Vertex AI Pipelines is the most effective way to orchestrate, automate and share ML workflows on Google Cloud for the following reasons:
Reproducible and shareable workflows: A Vertex AI pipeline can be defined with Kubeflow Pipelines (KFP) v2 SDK, an easy to use open source Python based library. The compiled pipelines can be version controlled with the git tool of choice and shared among the teams. This allows reproducibility and reliability of ML workflows while automating the pipeline. Pipelines can also be authored with Tensorflow Extended (TFX) SDK.
Streamline operationalizing ML models: Vertex AI Pipelines automatically logs metadata using Vertex ML Metadata service to track artifacts, lineage, metrics, visualizations and pipeline executions across ML workflows. This enables data scientists to track experiments as they try new models or new features. By storing the reference to the artifacts in Vertex ML Metadata, the lineage of ML artifacts can be analyzed — such as datasets and models, to understand how an artifact was created and consumed by downstream tasks, what parameters and hyperparameters were used to create the model.
Serveless, scalable and cost effective: Vertex AI Pipelines is entirely serverless allowing ML engineers to focus on ML solutions rather than on infrastructure tasks (provisioning, maintaining, deploying cluster etc). When a pipeline is uploaded and submitted, the service handles provisioning and scaling of the infrastructure required to run the pipeline. This means pay only for the resources used for running the pipeline.
NOTE: You can also orchestrate PyTorch based ML workflows on Google Cloud using open source Kubeflow Pipelines (KFP) which is a core component in the OSS Kubeflow project for building and deploying portable, scalable ML workflows based on Docker containers. The OSS KFP backend runs on a Kubernetes cluster such as Google Kubernetes Engine (GKE). The OSS KFP includes the pre-built PyTorch KFP components SDK for different ML tasks such as data loading, model training, model profiling and many more. Refer to this blog post for exploring further on orchestrating PyTorch based ML workflow on OSS KFP.
In this post, we will define a pipeline using KFP SDK v2 to automate and orchestrate the model training, tuning and deployment workflow of the PyTorch text classification model covered previously. With KFP SDK v2, component and pipeline authoring is simplified and has first class support for metadata logging and tracking making it easier to track metadata and artifacts produced by the pipelines.
Following is the high level flow to define and submit a pipeline on Vertex AI Pipelines:
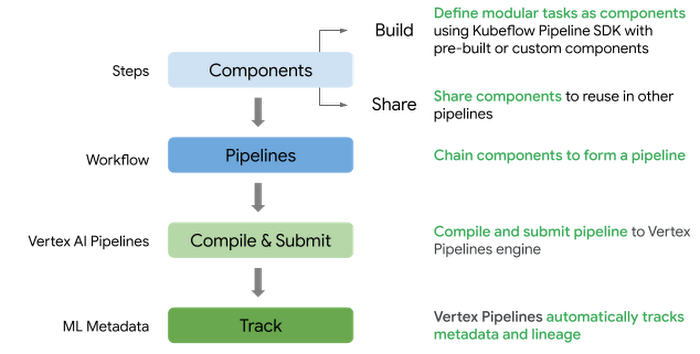
Define pipeline components involved in training and deploying a PyTorch model
Define a pipeline by stitching the components in the workflow including pre-built Google Cloud components and custom components
Compile and submit the pipeline to Vertex AI Pipelines service to run the workflow
Monitor the pipeline and analyze the metrics and artifacts generated
This post builds on the training and serving code from the previous posts. You can find the accompanying code and notebook for this blog post on the GitHub repository.
Concepts of a Pipeline
Let's look at the terminology and concepts used in KFP SDK v2. If you are familiar with KFP SDK, skip to the next section - “Defining the Pipeline for PyTorch based ML workflow”.
Component: A component is a self-contained set of code performing a single task in a ML workflow, for example, training a model. A component interface is composed of inputs, outputs and a container image that the component’s code runs in - including an executable code and environment definition.
Pipeline: A pipeline is composed of modular tasks defined as components that are chained together via inputs and outputs. Pipeline definition includes configuration such as parameters required to run the pipeline. Each component in a pipeline executes independently and the data (inputs and outputs) is passed between the components in a serialized format.
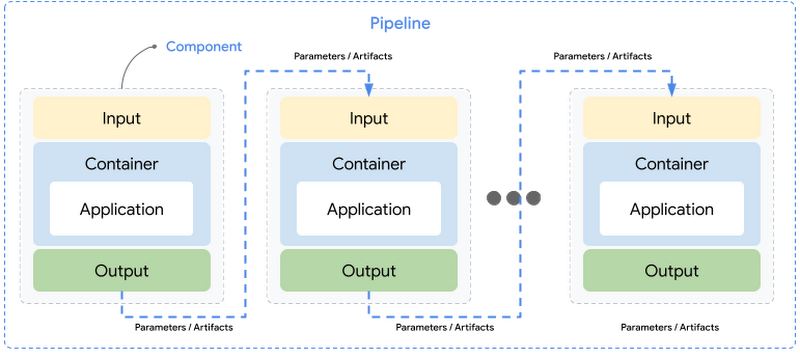
Inputs & Outputs: Component’s inputs and outputs must be annotated with data type, which makes input or output a parameter or an artifact.
Parameters: Parameters are inputs or outputs to support simple data types such as
str,int,float,bool,dict,list. Input parameters are always passed by value between the components and are stored in the Vertex ML Metadata service.Artifacts: Artifacts are references to the objects or files produced by pipeline runs that are passed as inputs or outputs. Artifacts support rich or larger data types such as datasets, models, metrics, visualizations that are written as files or objects. Artifacts are defined by name, uri and metadata which is stored automatically in the Vertex ML Metadata service and the actual content of artifacts refers to a path in the Cloud Storage bucket. Input artifacts are always passed by reference.
Learn more about KFP SDK v2 concepts here.
Defining the Pipeline for PyTorch based ML workflow
Now that pipeline concepts are familiar, let's look at building a pipeline for the PyTorch based text classification model. The following pipeline schematic shows high level steps involved including input and outputs:
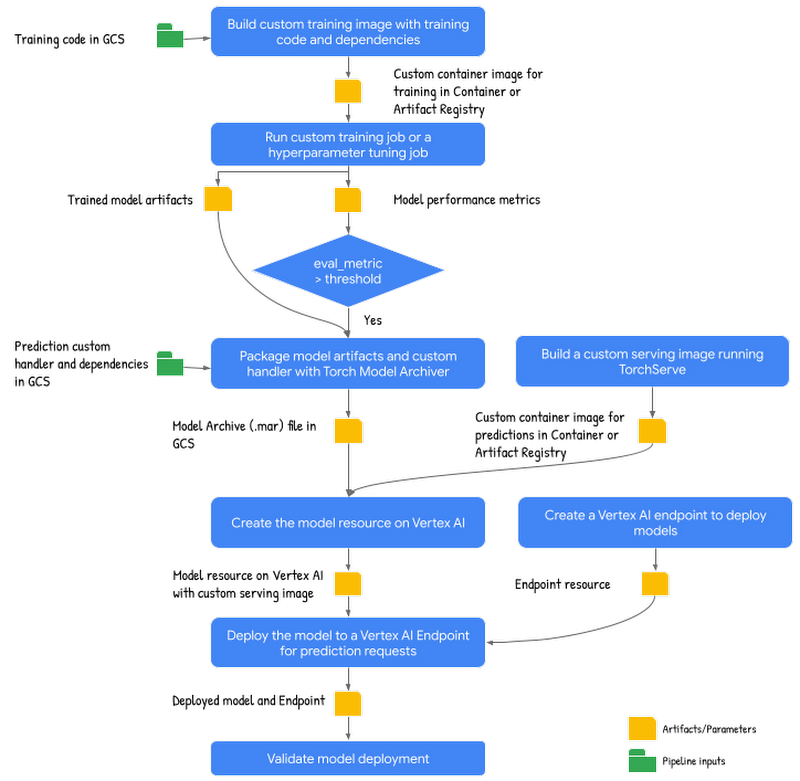
Following are the steps in the pipeline:
Build custom training image: This step builds a custom training container image from the training application code and associated Dockerfile with the dependencies. The output from this step is the Container or Artifact registry URI of the custom training container.
Run the custom training job to train and evaluate the model: This step downloads and preprocesses training data from IMDB sentiment classification dataset on HuggingFace, then trains and evaluates a model on the custom training container from the previous step. The step outputs Cloud Storage path to the trained model artifacts and the model performance metrics.
Package model artifacts: This step packages trained model artifacts including custom prediction handler to create a model archive (.mar) file using Torch Model Archiver tool. The output from this step is the location of the model archive (.mar) file on GCS.
Build custom serving image: The step builds a custom serving container running TorchServe HTTP server to serve prediction requests for the models mounted. The output from this step is the Container or Artifact registry URI to the custom serving container.
Upload model with custom serving container: This step creates a model resource using the custom serving image and model archive file (.mar) from the previous step.
Create an endpoint: This step creates a Vertex AI Endpoint to provide a service URL where the prediction requests are sent.
Deploy model to endpoint for serving: This step deploys the model to the endpoint created that creates necessary compute resources (based on the machine spec configured) to serve online prediction requests.
Validate deployment: This step sends test requests to the endpoint and validates the deployment.
There are couple of things to note about the pipeline here:
The pipeline starts with building a training container image, because the text classification model we are working on has data preparation and pre-processing steps in the training code itself. When working with your own datasets, you can include data preparation or pre-processing tasks as a separate component from the model training.
Building custom training and serving containers can be done either as part of the ML pipeline or within the existing CI/CD pipeline (Continuous Integration/ Continuous Delivery). In this post, we chose to include building custom containers as part of the ML pipeline. In a future post, we will go in depth on CI/CD for ML pipelines and models.
Please refer to the accompanying notebook for the complete definition of pipeline and component spec.
Component specification
With this pipeline schematic, the next step is to define the individual components to perform the steps in the pipeline using KFP SDK v2 component spec. We use a mix of pre-built components from Google Cloud Pipeline Components SDK and custom components in the pipeline.
Let's look into the component spec for one of the steps - building the custom training container image. Here we are defining a Python function-based component where the component code is defined as a standalone python function. The function accepts Cloud Storage path to the training application code along with project and model display name as input parameters and outputs the Container Registry (GCR) URI to the custom training container. The function runs a Cloud Build job that pulls the training application code and the Dockerfile and builds the custom training image which is pushed to Container Registry (or Artifact Repository). In the previous post, this step was performed in the notebook using docker commands and now this task is automated by self-containing the step within a component and including it in a pipeline.There are a few things to notice about the component spec:
The standalone function defined is converted as a pipeline component using the @kfp.v2.dsl.component decorator.
All the arguments in the standalone function must have data type annotations because KFP uses the function’s inputs and outputs to define the component’s interface.
By default Python 3.7 is used as the base image to run the code defined. You can configure the @component decorator to override the default image by specifying base_image, install additional python packages using packages_to_install parameter and write the compiled component as a YAML file using output_component_file to share or reuse the component.
The inputs and outputs in the standalone function above are defined as Parameters, which are simple data types representing values. Inputs and outputs can be Artifacts representing any files or objects generated during the component execution. These arguments are annotated as an kfp.dsl.Input or kfp.dsl.Output artifact. For example, the component specification for creating Model Archive file refers to the model artifacts generated in the training job as the input - Input[Model] in the following snippet:
Refer here for the artifact types in KFP v2 SDK and here for the artifact types for Google Cloud Pipeline Components.
For component specs of other steps in the pipeline, refer to the accompanying notebook.
Pipeline definition
After defining the components, the next step is to build the pipeline definition describing how input and output parameters and artifacts are passed between the steps. The following code snippet shows the components chained together:
Let’s unpack this code and understand a few things:
The pipeline is defined as a standalone Python function annotated with the @kfp.dsl.pipeline decorator, specifying the pipeline's name and the root path where the pipeline's artifacts are stored.
The pipeline definition consists of both pre-built and custom defined components
Pre-built components from Google Cloud Pipeline Components SDK are defined for steps calling Vertex AI services such as submitting custom training job (custom_job.CustomTrainingJobOp), uploading a model (ModelUploadOp), creating an endpoint (EndpointCreateOp) and deploying a model to the endpoint (ModelDeployOp)
Custom components are defined for steps to build custom containers for training (build_custom_train_image), get training job details (get_training_job_details), create mar file (generate_mar_file) and serving (build_custom_serving_image) and validating the model deployment task (make_prediction_request). Refer to the notebook for custom component specification for these steps.
A component’s inputs can be set from the pipeline's inputs (passed as arguments) or they can depend on the output of other components within this pipeline. For example, ModelUploadOp depends on custom serving container image URI from build_custom_serving_image task along with the pipeline’s inputs such as project id, serving container routes and ports.
kfp.dsl.Condition is a control structure with a group of steps which runs only when the condition is met. In this pipeline, model deployment steps run only when the trained model performance exceeds the set threshold. If not, those steps are skipped.
Each component in the pipeline runs within its own container image. You can specify machine type for each pipeline step such as CPU, GPU and memory limits. By default, each component runs as a Vertex AI CustomJob using an e2-standard-4 machine.
By default, pipeline execution caching is enabled. Vertex AI Pipelines service checks to see whether an execution of each pipeline step exists in Vertex ML metadata. It uses a combination of pipeline name, step’s inputs, output and component specification. When a matching execution already exists, the step is skipped and thereby reducing costs. Execution caching can be turned off at task level or at pipeline level.
To learn more about building pipelines, refer to the building Kubeflow pipelines section, and follow the samples and tutorials.
Compiling and submitting the Pipeline
Pipeline must be compiled for executing on Vertex AI Pipeline services. When a pipeline is compiled, the KFP SDK analyzes the data dependencies between the components to create a directed acyclic graph. The compiled pipeline is in JSON format with all information required to run the pipeline.Pipeline is submitted to Vertex AI Pipelines by defining a PipelineJob using Vertex AI SDK for Python client, passing necessary pipeline inputs.
When the pipeline is submitted, the logs show a link to view the pipeline run on Google Cloud Console or access the run by opening Pipelines dashboard on Vertex AI.

Here is the runtime graph of the pipeline for the PyTorch text classification model:
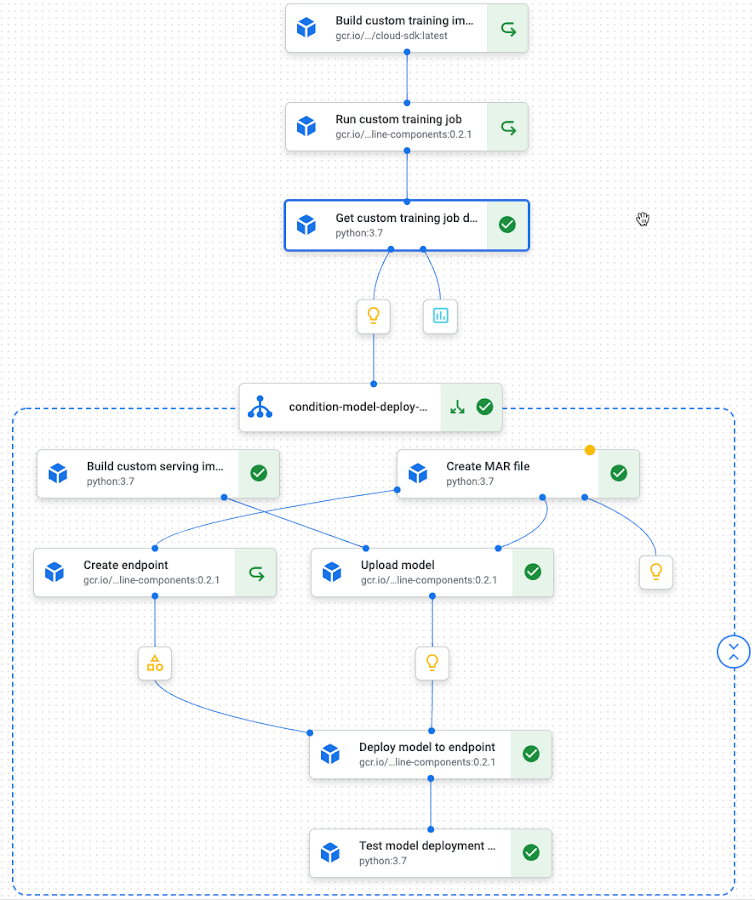
Pipeline runtime graph
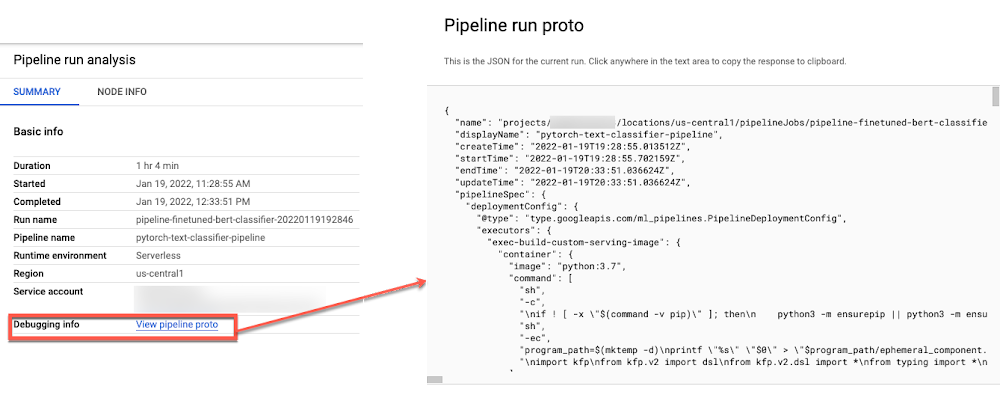
Monitoring the Pipeline
The pipeline run page shows the run summary as well details about individual steps including step inputs and outputs generated such as Model, Artifacts, Metrics, Visualizations.
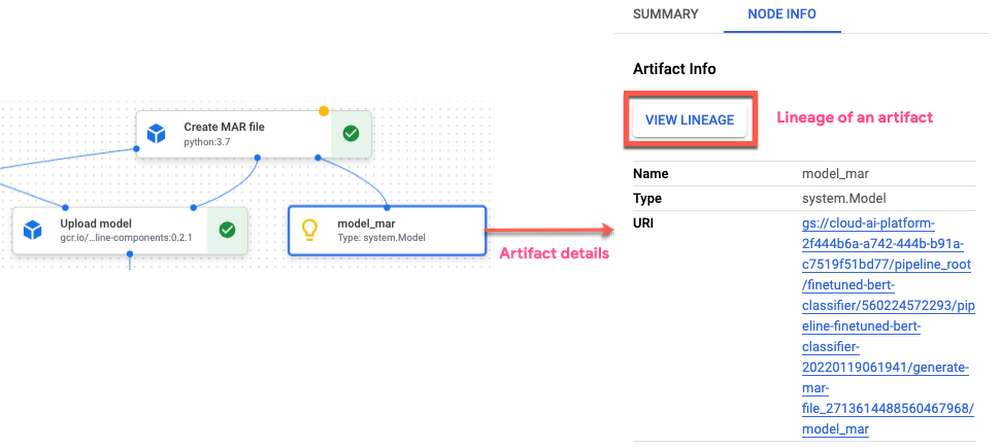
Vertex AI Pipelines automatically tracks pipeline execution information in Vertex ML Metadata including metadata and artifacts thereby enabling comparison across pipeline runs and the lineage of ML artifacts.

You can compare across pipeline runs such as inputs, parameters, metrics and visualizations from the Vertex AI Pipelines dashboard. You can also use aiplatform.get_pipeline_df() method from the Vertex AI SDK to fetch pipeline execution metadata for a pipeline as a Pandas dataframe.

Cleaning up resources
After you are done experimenting, you can either stop or delete the Notebooks instance. If you want to save your work, you can choose to stop the instance. When you stop an instance, you are charged only for the persistent disk storage.
To clean up all Google Cloud resources created in this post, you can delete the individual resources created:
Training Jobs
Model
Endpoint
Cloud Storage Bucket
Container Images
Pipeline runs
Follow the Cleaning Up section in the Jupyter Notebook to delete the individual resources.
What’s next?
This post continues from the training and deploying of the PyTorch based text classification model on Vertex AI and shows how to automate a PyTorch based ML workflow using Vertex AI Pipelines and Kubeflow Pipelines v2 SDK. As the next steps, you can work through this pipeline example on Vertex AI or perhaps orchestrate one of your own PyTorch models.
References
Samples and tutorials to learn more about Vertex AI Pipelines
GitHub repository with code and accompanying notebook
Stay tuned. Thank you for reading! Have a question or want to chat? Find Rajesh on Twitter or LinkedIn.
Thanks to Vaibhav Singh, Karl Weinmeister and Jordan Totten for helping and reviewing the post.




