Kubeflow Pipelines と Vertex Pipelines 上の PyTorch を使用したスケーラブルな ML ワークフロー
Google Cloud Japan Team
※この投稿は米国時間 2021 年 9 月 11 日に、Google Cloud blog に投稿されたものの抄訳です。
はじめに
MLOps は、ML システム開発と ML システム オペレーションの統合を目的とする ML エンジニアリングの文化と手法です。重要な MLOps デザイン パターンは、ML ワークフローを形式化する機能です。ML ワークフローの再現、追跡、分析、共有などが可能となります。
Pipelines フレームワークはこのパターンをサポートし、MLOps ストーリーのバックボーンとなります。このフレームワークにより、ML ワークフローのオーケストレーションによる ML システムの自動化、モニタリング、管理が簡単になります。
この記事では、PyTorch ベースの ML ワークフローの例を 2 つの Pipelines フレームワーク上で示します。Kubeflow プロジェクトの一部である OSS Kubeflow Pipelines、および Vertex Pipelines です。また、Kubeflow Pipelines リポジトリに追加されたPyTorch の新しいコンポーネントについても説明します。
さらに、KFP SDK の v2 を必要とする Vertex Pipelines の例では、KFP v2 の「互換モード」を使用してどのように OSS Kubeflow Pipelines インストール上でも実行できるようになったかを示します。
Google Cloud Platform 上の PyTorch
PyTorch は、大規模にデプロイされている複雑な ML ワークフローを使用して、急速に進化し続けています。多くの企業が、自律走行から、創薬、外科用インテリジェンス、農業にまでいたる AI を利用したソリューションに PyTorch を革新的な手法で使用しています。大規模に運用されているこのような実際の各種ソリューションでの MLOps とエンドツーエンド ライフサイクルの管理が依然として課題となっています。
新しくリリースされた Vertex AI は、統合型 MLOps プラットフォームです。データ サイエンティストと ML エンジニアは、このプラットフォームを使用してテストをスピードアップし、モデルをより短い期間でデプロイして、より効果的に管理できます。プラットフォームには AutoML と AI Platform が含まれており、MLOps に特化したいくつかの新プロダクトとあわせて統合型 API、クライアント ライブラリ、ユーザー インターフェースに集約されます。
Google Cloud Platform と Vertex AI は、PyTorch に最適です。PyTorch では Vertex AI のトレーニングとサービス、PyTorch ベースのディープ ラーニングの VM イメージとコンテナ、および PyTorch XLA がサポートされています。
この投稿では、PyTorch ベースの ML ワークフローの例を 2 つの Pipelines フレームワークに従ってさらに示します。Kubeflow プロジェクトの一部である OSS Kubeflow Pipelines と Vertex Pipelines です。どの例でも、オープンソースの Python KFP(Kubeflow Pipelines)SDK を使用します。これにより、PyTorch コンポーネントを簡単に定義および使用できます。
どちらの Pipelines フレームワークにも、ML 関連のタスクのビルド済みコンポーネントが各種備わっています。コンポーネント(パイプラインの手順)の簡単なオーサリングとパイプライン コントロール フロー(ループや条件など)の提供、パイプライン実行中のメタデータの自動的なロギング、ステップ実行のキャッシュ保存のサポートなどです。
どちらのフレームワークでも、PyTorch ベースのパイプライン コンポーネントの構築と使用、および PyTorch ベースのワークフローの作成と実行が簡単にできます。
Kubeflow Pipelines
Kubeflow オープンソース プロジェクトには Kubeflow Pipelines(KFP)が含まれます。これは、Docker コンテナをベースとした、移植可能でスケーラブルな機械学習(ML)ワークフローの構築とデプロイ用のプラットフォームです。オープンソースの Kubeflow Pipelines バックエンドは、GKE や Google がホストする Kubernetes などの Kubernetes クラスタ上で実行されます。Kubeflow の他の部分を必要としない場合は、KFP バックエンド「スタンドアロン」を CLI や GCP Marketplace を介してインストールできます。
この記事で紹介する OSS KFP の例では、複数の異なるワークフローを示し、Kubeflow Pipelines GitHub リポジトリで新しく提供されるようになったいくつかのコンポーネントが含まれます。これらの例は、分散トレーニング用の基盤となる Kubernetes クラスタの活用と、モニタリングとプロファイリング用の TensorBoard サーバーの使用方法などを示しています。
Vertex Pipelines
Vertex Pipelines は、Vertex AI の一部で、オープンソース KFP からそれぞれのバックエンドを使用します。自動化され、スケーラブル、サーバーレス、かつ優れた費用対効果を持ち、ご利用いただいた分だけお支払いいただきます。Vertex Pipelines は Vertex AI ML Ops ストーリーのバックボーンであり、ML フレームワークを使用して ML ワークフローの構築および実行を簡略化します。サーバーレスであり GCP と Vertex AI ツールおよびサービスとシームレスな統合を実現しているため、インフラストラクチャやクラスタのメンテナンスを行うことなくパイプラインの構築と実行に集中できます。
Vertex Pipelines はメタデータを自動でロギングしてアーティファクト、リネージ、指標、実行を ML ワークフローを通してトラッキングし、Cloud IAM、VPC-SC、CMEK など、エンタープライズ クラスのセキュリティ管理のサポートを提供しています。
この投稿で紹介する Vertex Pipelines の例では、OSS KFP の例とともに基盤となる PyTorch モジュールを示し、Vertex AI サービスの使用が容易になる、ビルド済みの Google Cloud パイプライン コンポーネントの使用について説明します。Vertex Pipelines には KFP SDK の v2 が必要です。KFP v2 の「互換モード」を使用して、OSS KFP インストール上で KFP V2 のサンプルを実行できるようになっており、その実行方法についても説明します。
Kubeflow Pipelines 上の PyTorch: PyTorch KFP コンポーネント SDK
Google と Facebook を使ったコラボレーションにより、PyTorch を使用して Kubeflow Pipelines 上で大規模な ML ワークフローを実現するための数多くの技術的な成果を発表しています。これには、以下の機能を備えた PyTorch Kubeflow Pipelines コンポーネント SDK が含まれます。
データの読み込みと前処理
トレーニング ループとして PyTorch Lightning を使用したモデル トレーニング
新しい PyTorch Tensorboard Profiler を使用したモデルのプロファイリングと可視化
カナリア ロールアウト、自動スケーリングと Prometheus モニタリングで TorchServe と KFServing を使用したモデルのデプロイと提供
Captum を使用したモデルの解釈可能性
KFP 用の PyTorch ジョブ オペレータを使用した分散トレーニング
Ax/BoTorch を使用したハイパーパラメータの調整
アーティファクト リネージのトラッキング用の ML メタデータ
MinIO を使用したクラウドに依存しないアーティファクトのストレージ コンポーネント
コンピュータ ビジョンと NLP ワークフローは以下で使用可能です。
クラウドまたはオンプレミスにデプロイされたオープンソースの Kubeflow Pipelines
サーバーレス パイプライン ソリューション用の Google Cloud Vertex AI Pipelines
まず、すべての前提条件を使用して KFP クラスタを設定し、こちらの PyTorch サンプルからいずれかのサンプルを採用します。サンプル ノートブックとパイプラインの完全なサンプルは、以下で使用可能です。
注: すべてのサンプルは、トレーニングと推論用に CPU または GPU を使用して、オンプレミスと任意のクラウドの両方での実行が想定されます。MinIO は、クラウドに依存しないストレージ ソリューションとして使用されます。カスタム TensorBoard イメージは、PyTorch Profiler の表示のために使用されます。
Kubeflow Pipelines 上の PyTorch: BERT NLP サンプル
BERT サンプル ノートブックについて順に説明します。
PyTorch NLP モデルのトレーニング
実行するすべてのタスクで KFP パイプラインを定義することから開始します。各タスクは、構成可能なパラメータとともにコンポーネント YAML を使用して定義されます。すべてのテンプレートは こちらで入手できます。トレーニング コンポーネントは、入力として PyTorch Lightning スクリプトおよび入力データとパラメータを受け取り、モデル チェックポイント、Tensorboard Profiler トレース、混同行列やアーティファクト トラッキングなどの指標用のメタデータを返します。
トレーニング用に GPU を使用している場合は、GPU を 0 より大きい値に設定し、デフォルトのアクセラレータ タイプとして「ddp」を使用します。クラスタ用に GPU の上限とノードセレクタ制約も指定する必要があります。
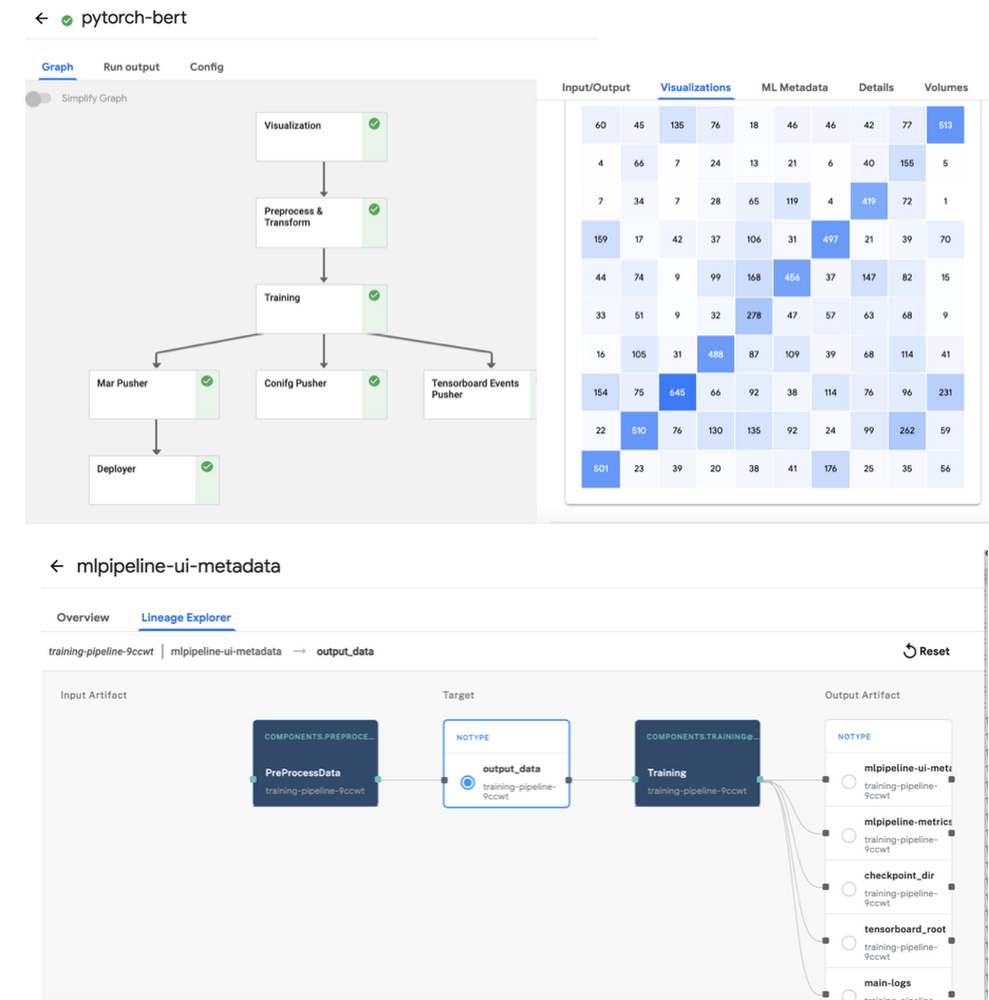
PyTorch Tensorboard Profiler 用のトレースを生成するには、「profiler=pytorch」を script_args で設定します。混同行列は、すべての入出力とパイプライン実行の詳細ログとともに、KFP アーティファクト ストアの ML メタデータの一部としてログに記録されます。パイプライン グラフとリネージ エクスプローラでこれらを表示できます(以下の図 2 を参照)。キャッシュ保存はデフォルトで有効になっているため、同じ入力を使用して同じパイプラインを再度実行すると、結果は KFP キャッシュから取得されます。
template_mapping.json の構成ファイルは、テンプレートからのコンポーネント YAML ファイルの生成、およびスクリプト名とすべてのコードを含む Docker コンテナの設定に使用されます。独自のパイプライン用に同様の Docker コンテナを作成できます。
PyTorch Tensorboard Profiler を使用したデバッグ
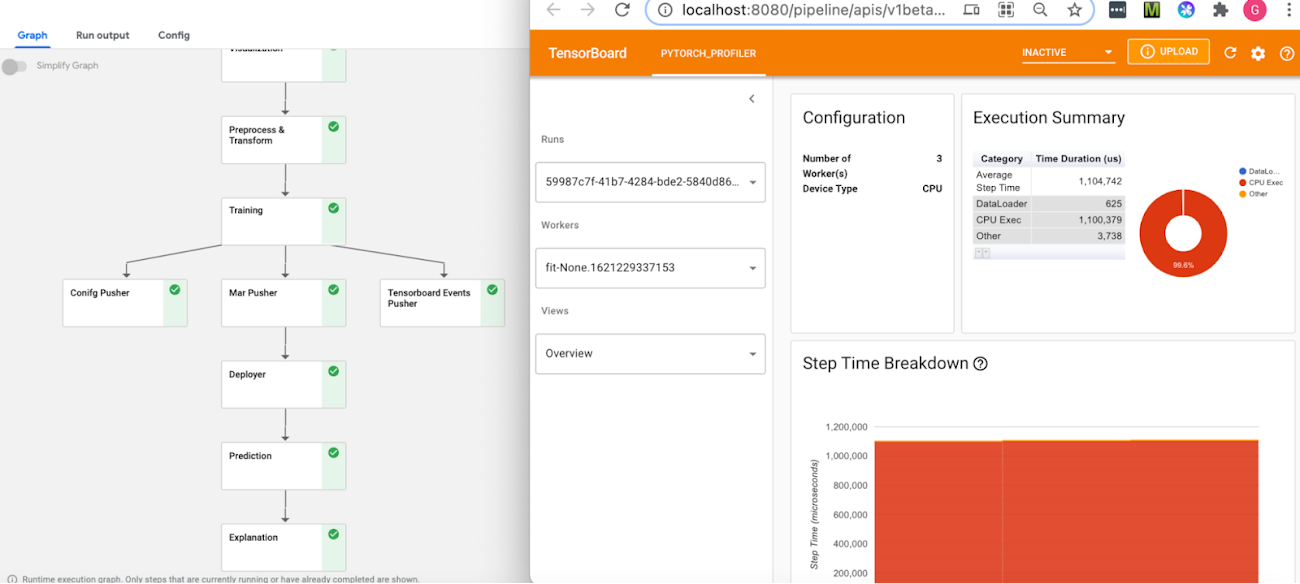
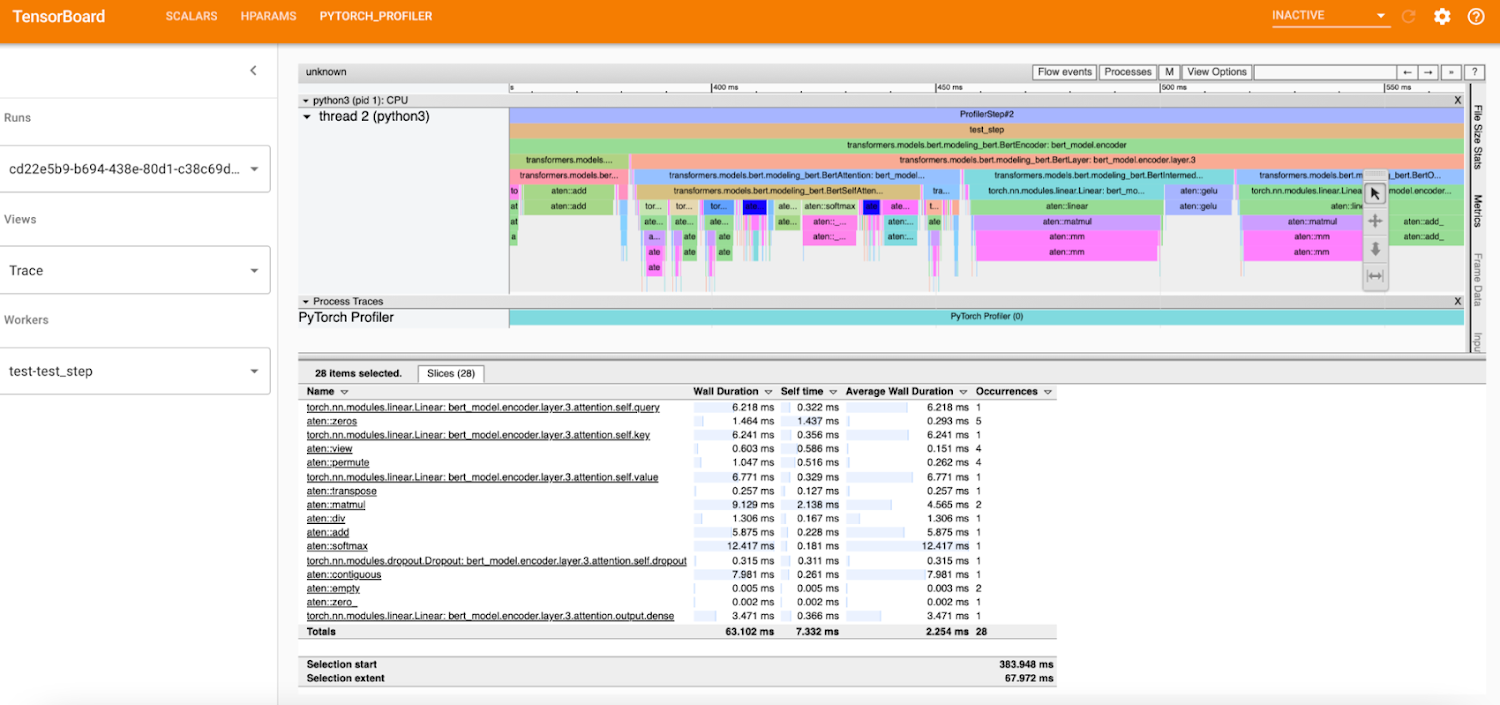
PyTorch Tensorboard Profiler は、データの読み込みの非効率、GPU の使用率低下、SM の効率、CPU-GPU スラッシングなどのパフォーマンスのボトルネックに対する分析情報を提供し、パフォーマンスの問題のデバッグに非常に役立ちます。Profiler 1.9 ブログで最新情報をご確認ください。
KFP パイプラインでは、Tensorboard Visualization コンポーネントを通じて、PyTorch Tensorboard Profiler でトレースが使用可能になるため、このコンポーネントはトレーニングの実行開始前に作成されます。プロファイラ トレースは、パイプライン実行 ID の下の TensorBoard / ログバケットに保存され、トレーニング手順の完了後に表示可能となります。「TensorBoard の起動」ボタンをクリックすると、パイプラインの Visualization コンポーネントから Tensorboard にアクセスできます。下記のように、Tensboard の PyTorch Profiler ビューで全トレースを使用できます。
カスタム Docker コンテナは、PyTorch Profiler プラグインに使用され、TENSORBOARD_IMAGE パラメータを設定して、イメージ名を指定できます。
TorchServe で KFServing を使用したモデル提供
予測を実行するための PyTorch のモデル提供は、KFServing と TorchServe の統合を介して行われます。Prediction API と Explanation API、自動スケーリングを使用したカナリア ロールアウト、Prometheus と Grafana を使用したモニタリングをサポートしています。
NLP BERT モデルでは、bert_handler.py で、モデルの読み込み、予測の実行、前処理と後処理の実行に関するロジックにより TorchServe カスタム ハンドラが定義されます。トレーニング コンポーネントは、モデルファイルをモデル アーカイブ ツール パッケージとして生成します。これにより TorchServe にデプロイされます。minIO op は、deployment op で使用されるモデル アーカイブ ツールと TorchServe 構成プロパティの作成に使用されます。モデルをデプロイするには、関連する値を使用した KFServing 推論 YAML の設定が必要なだけです。たとえば、GPU 推論の場合、モデルのストレージ ロケーションと GPU の数を渡します。
モデルの解釈可能性のための Captum の使用
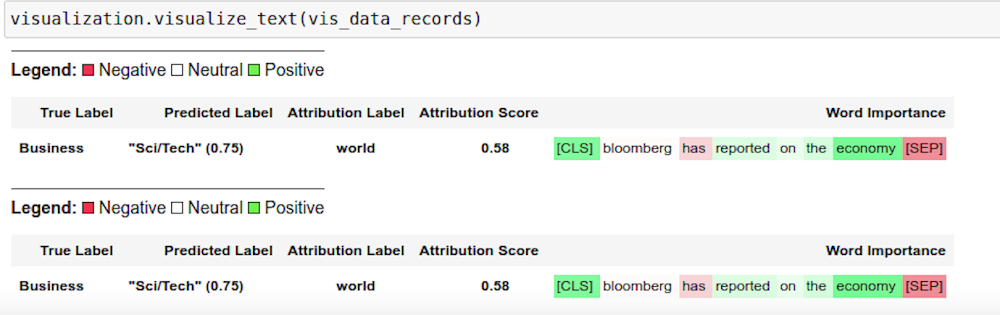
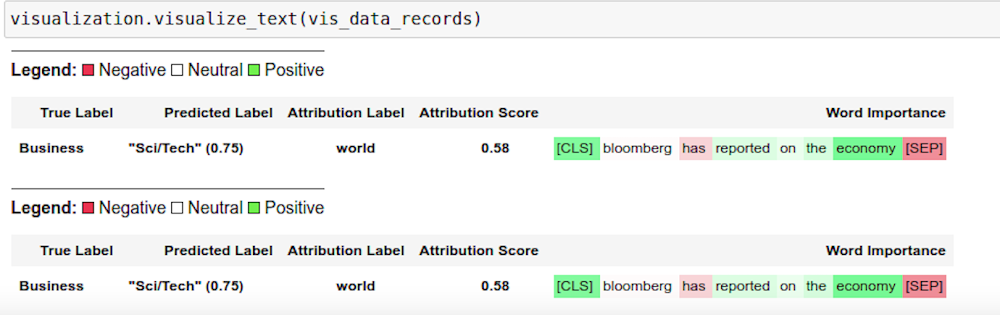
Captum.ai は、PyTorch 用のモデルの解釈可能性のライブラリです。NLP サンプルでは、KFServing と TorchServe の Explanation API を使用して、解釈可能性のためのモデルの分析情報を取得します。explain handler は、explain エンドポイントを介して呼び出される IntegratedGradient 計算ロジックを定義し、解釈可能性の出力を含む JSON レスポンスを返します。結果は Captum 分析情報を使用してノートブックにレンダリングされます。
これにより、ワードの重要性を色分けした図解が表示されます。
PyTorch ジョブ オペレータを使用した分散トレーニング
Kubeflow PyTorch ジョブ オペレータが分散トレーニングに使用され、マスターノードとワーカーノード用のジョブ仕様を入力として受け取ります。pytorch-launcher コンポーネントを介して他のパラメータをカスタマイズするオプションも備えています。
Kubeflow Pipelines 上の PyTorch: CIFAR10 HPO サンプル
Ax/BoTorch を使用したハイパーパラメータの最適化
Ax は、PyTorch 用の適応型のテスト プラットフォームで、BoTorch は、ベイズ最適化のライブラリです。組み合わせてハイパーパラメータの最適化に使用されます。
この使用方法は CIFAR10-HPO ノートブックで説明されています。まず、ax_generate_trials component を使用して最適化するパラメータについてのテスト トライアルを生成します。
次に、ax_train_component を使用してトライアルを同時に実行します。
最後に、ax_complete_trials component を使用して結果を処理し、ハイパーパラメータ検索から最適なパラメータを取得します。
最適なパラメータは、ax_complete トライアルの入出力のセクションに表示されています(次の図に示すとおり)。

Vertex Pipelines 上の PyTorch: CIFAR10 画像分類のサンプル
この記事での Vertex Pipelines のサンプルでは KFP SDK も使用され、Vertex AI サービスへの簡単なアクセスをサポートする Google Cloud パイプライン コンポーネントの使用も含まれます。Vertex Pipelines には KFP SDK の v2 が必要です。したがって、これらのサンプルは、上記の OSS KFP v1 ベースのサンプルとは異なりますが、コンポーネントでは同様のデータ処理とトレーニング基底クラスが一部共有されています。KFP v2 の「互換モード」を使用して、OSS KFP インストール上で KFP V2 のサンプルを実行できるようになっており、その実行方法についても説明します。
サンプルの PyTorch Vertex Pipelines ノートブックでは、1 つのパイプラインの 2 つのバリアントを示します。そのパイプラインで行われるのは、データ前処理の実行、PyTorch CIFAR10 resnet モデルのトレーニング、そのモデルの archive フォーマットへの転換、Torchserve サービス提供コンテナの構築、Vertex AI カスタム予測用に構成されたモデルコンテナのアップロード、そのモデルのサービス提供コンテナをエンドポイントにデプロイして、Vertex AI で予測リクエストを提供できるようにすることです。サンプルでは、Torchserve サービス提供コンテナが Vertex AI 予測サービスと互換性のある KFServing サービス エンベロープを使用するように構成されています。
PyTorch 画像分類モデルのトレーニング
ノートブック内の 2 つのパイプライン バリアントの違いはトレーニングの手順にあります。1 つのバリアントは、ステップノード上の単一 GPU トレーニングを行います。これは、Vertex Pipelines のステップノード上で直接トレーニング ジョブを実行します。パイプラインのステップ インスタンスを構成して、ノード インスタンスに必要なリソースを提供する方法を指定できます。KFP パイプライン定義のこの部分では、パイプラインでトレーニング ステップ用に 1 つの Nvidia V100 を使用するように指定する構成を示します。
ノートブックでの他のサンプル バリアントでは、Vertex AI SDK を使用して、Vertex AI のカスタム トレーニングのサポートを介したマルチ GPU の単一ノード トレーニングが示されています。
「カスタム トレーニング」パイプラインの手順で、カスタムジョブが定義され、PyTorch トレーニング コードのコンテナ イメージの URL が渡されます。
次に、カスタム トレーニング ジョブが実行され、マシンタイプとアクセラレータ タイプ、およびアクセラレータの数が指定されます。
PyTorch のビルド済みのトレーニング コンテナも使用可能ですが、このサンプルでは、PyTorch v1.8 を使用しています。執筆時点でビルド済みのセットには入っていませんでした。
KFP パイプラインの定義
サンプル KFP v2 パイプラインの一部のステップは Python 関数ベースのカスタム コンポーネントから構築されます。これらのステップにより、パイプラインのインタラクティブな開発が容易になります。サンプル ノートブック内で定義されていますが、その他のステップは ビルド済みのコンポーネントを使用して定義されており、Vertex AI や他のサービスの操作を容易にしています。モデルのアップロード、エンドポイントの作成、モデルのエンドポイントへのデプロイのステップなどです。
カスタム コンポーネントに含まれるパイプラインのステップでは、トレーニング済みの PyTorch モデルとモデルファイルからモデル アーカイブが作成され、モデル アーカイブ ファイルとサービス提供している config.properties を使用した Torchserve コンテナ イメージが構築されます。Torchserve のビルドステップでは、コンテナ イメージの作成にCloud Build が使用されます。
これらのパイプライン コンポーネントの定義は、サンプル ノートブックに示すように、.yaml ファイルにコンパイルできます。.yaml コンポーネントの定義は移植可能です。バージョン管理に配置して共有し、他のパイプライン定義の用途でのパイプライン ステップの作成に使用できます。
KFP パイプラインの大まかな定義は、次のようになります。(詳細な定義については、ノートブックをご覧ください)。パイプライン ステップの一部では、入力として他のステップの出力が使用されます。ビルド済みの google_cloud_pipeline_components により、Vertex AI サービスへのアクセスが簡単になります。ModelDeployOp ステップは、GPU インスタンス上のトレーニング済みモデルを提供するように構成されることに注意してください。
Vertex Pipelines サンプルの 1 つのパイプライン グラフを以下に示します。
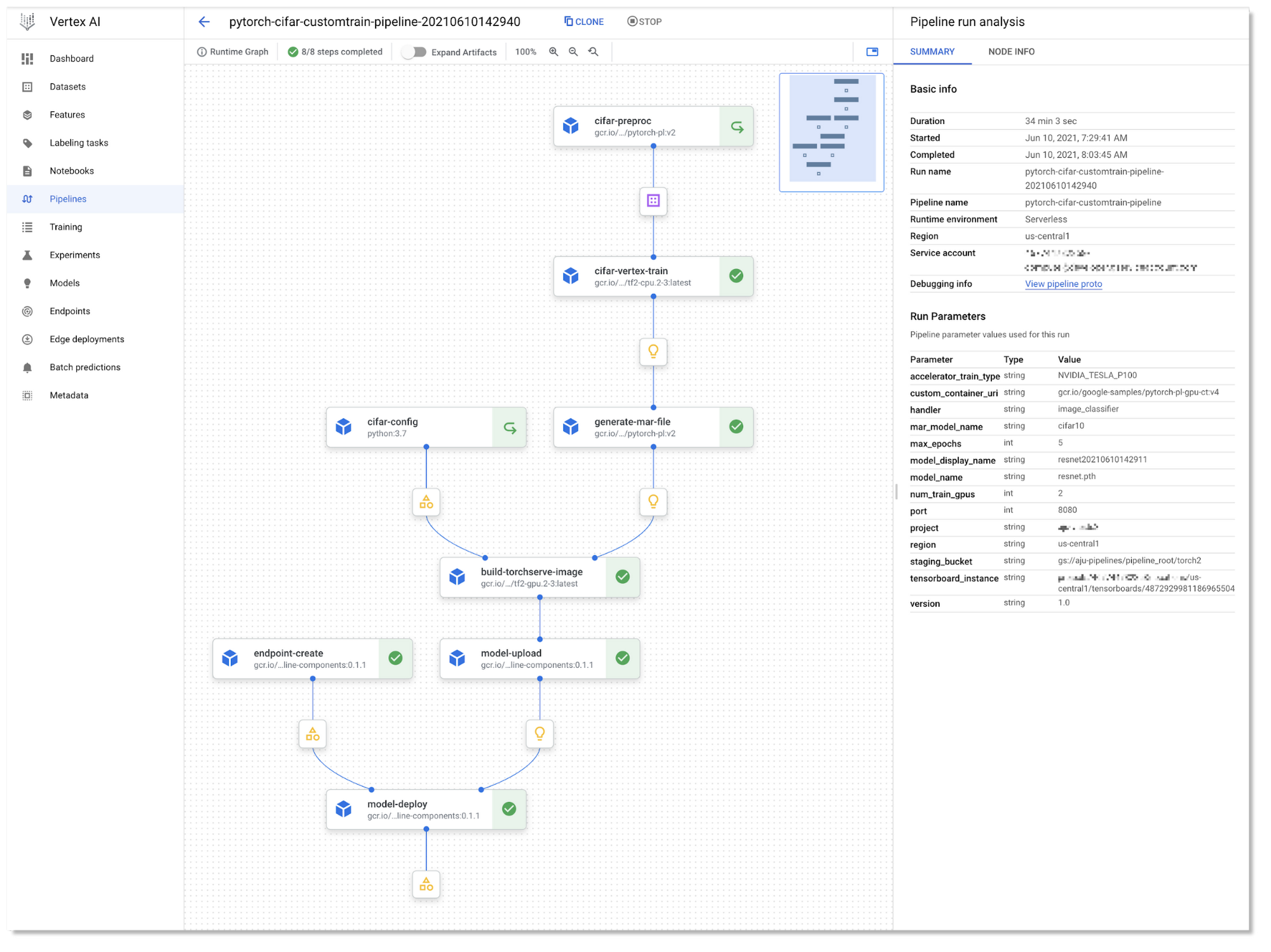
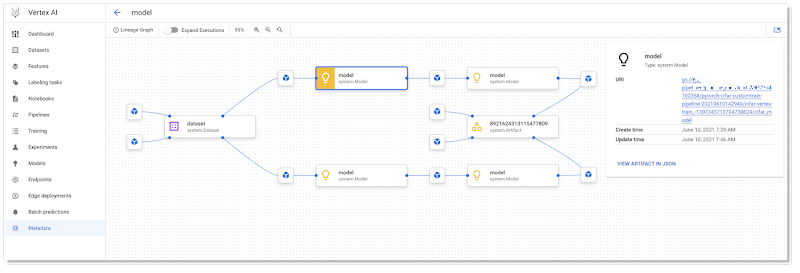
パイプラインが実行されると、実行に関するメタデータ(アーティファクト、実行、イベントを含む)が自動的に Vertex ML Metadata サーバーにロギングされます。UI の一部である Pipelines Lineage Tracker は、ロギングされたメタデータを使用して、パイプライン実行のアーティファクト中心のビューをレンダリングし、ステップ実行によってアーティファクトが接続される方法を示します。このビューでは、複数のパイプライン実行で同じアーティファクトが使用されるケースを簡単に追跡できます。(ここで、パイプラインはキャッシュ保存を活用することができ、多くの場合、複数のパイプライン実行は同じキャッシュ保存されたステップの出力を使用できます。)
KFP v2 の「互換モード」を使用して、OSS KFP インストールでパイプラインを実行する
OSS KFP インストール上で上記の Vertex サンプル内の同じ KFP v2 パイプラインを実行できるようになりました。Kubeflow Pipelines SDK v2 互換モードでは、v2 の新しいパイプライン セマンティックスを使用して、ML メタデータにメタデータをロギングするというメリットを活用できます。互換モードとは、1 つのプラットフォーム上でパイプラインを開発し、他のプラットフォーム上で実行できることを意味します。
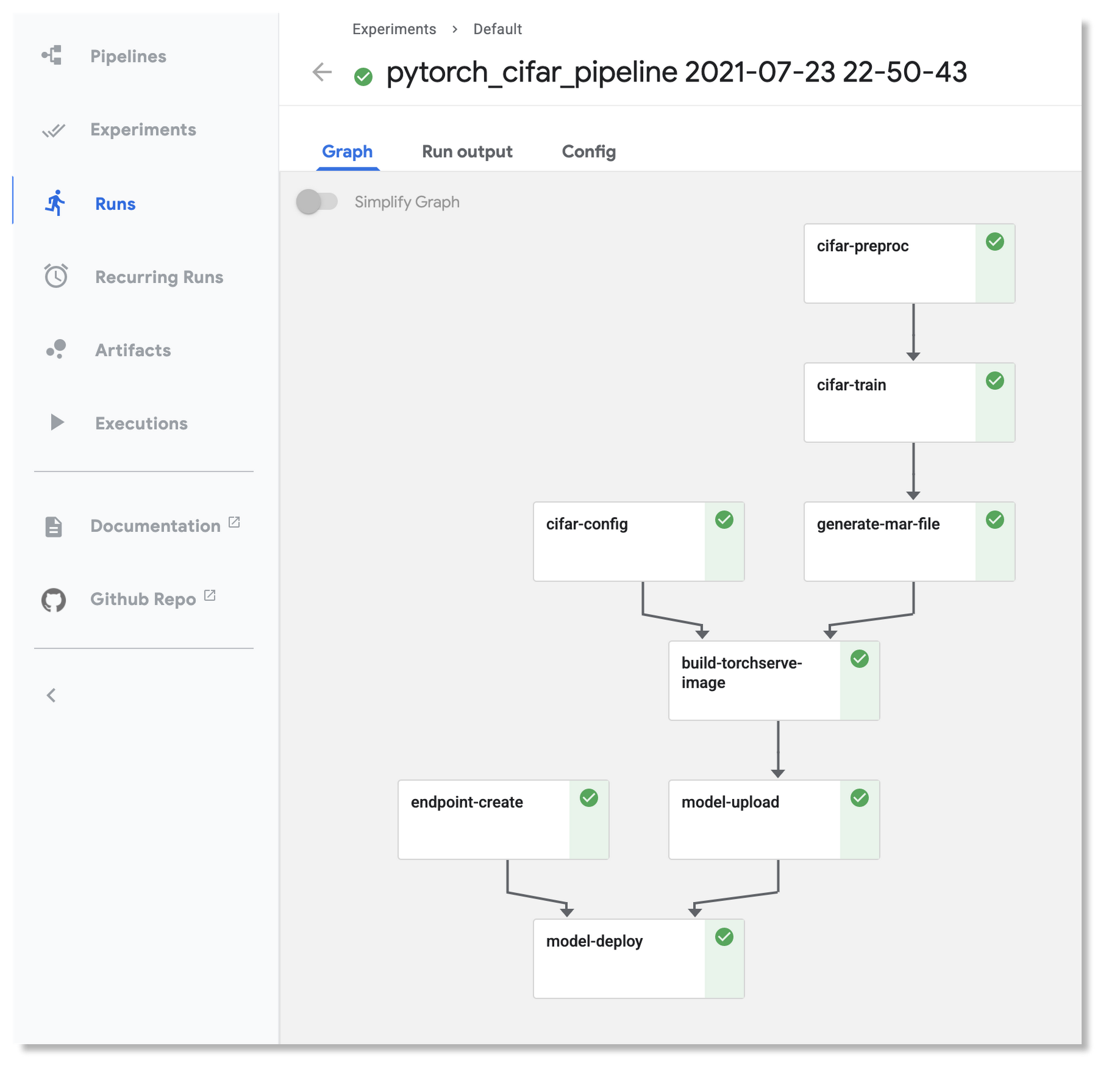
Vertex Pipelines で実行され、OSS KFP インストール上でも実行されている上記の同じパイプラインのパイプライン グラフを以下に示します。上記の図での Vertex Pipelines グラフと比較すると、同じ構造であることがわかります。
サンプルの README にインストールの方法についての詳細が記載されています。PyTorch Vertex Pipelines ノートブックのサンプルには、設定終了後に OSS KFP パイプラインを起動する方法を示しているセクションがあります。
次のステップ
この投稿では、OSS Kubeflow Pipelines と Vertex Pipelines の両方で実行されている、PyTorch を使用したスケーラブルな ML ワークフローの構築方法のいくつかのサンプルを示しました。Kubeflow と Vertex AI により GCP 上での PyTorch の使用が簡単になります。また、PyTorch ベースの ML ワークフローの作成がさらに簡単になるいくつかの新しい PyTorch KFP コンポーネントを発表しました。また、KFP SDK の v2 を必要とする Vertex Pipelines サンプルが KFP v2 の「互換モード」を使用して、どのように OSS Kubeflow Pipelines インストール上でも実行できるようになったかを示しました。
こちらとこちらのサンプルを確認して、ご意見やご感想をお聞かせください。PyTorch フォーラム上でのフィードバックや、Kubeflow Pipelines GitHub リポジトリ上での問題報告ができます。
謝辞
この記事の作成に協力してくれた、Pavel Dournov、Henry Tappen、Yuan Gong、Jagadeesh Jaganathan、Srinath Suresh、Alexey Volkov、Karl Weinmeister、Vaibhav Singh、Vertex Pipelines チームに感謝します。
- スタッフ デベロッパー アドボケイト Amy Unruh
- AI パートナー エンジニアリング リード、Facebook Geeta Chauhan



