このチュートリアルでは、多変量時系列モデルを使用して、複数の入力特徴の過去の値に基づいて、特定の列の将来の値を予測する方法について説明します。
このチュートリアルでは、複数の時系列の予測を行います。予測値は、指定された 1 つ以上の列の値ごとに、各時点について計算されます。たとえば、天気を予測しようとして、州データを含む列を指定した場合、予測データには、州 A のすべての時間ポイントの予測値、州 B のすべての時間ポイントの予測値(以下同様)が含まれます。天気を予測しようとして、州と都市のデータを含む列を指定した場合、予測データには、州 A と都市 A のすべての時間ポイントの予測値、州 A と都市 B のすべての時間ポイントの予測値(以下同様)が含まれます。
このチュートリアルでは、公開されている bigquery-public-data.iowa_liquor_sales.sales テーブルと bigquery-public-data.covid19_weathersource_com.postal_code_day_history テーブルのデータを使用します。bigquery-public-data.iowa_liquor_sales.sales テーブルには、アイオワ州の複数の都市から収集された酒類販売データが含まれます。bigquery-public-data.covid19_weathersource_com.postal_code_day_history テーブルには、世界中の気温や湿度などの過去の気象データが含まれます。
このチュートリアルを読む前に、多変量モデルを使用して 1 つの時系列を予測するをお読みになることをおすすめします。
データセットを作成する
ML モデルを保存する BigQuery データセットを作成します。
コンソール
Google Cloud コンソールで、[BigQuery] ページに移動します。
[エクスプローラ] ペインで、プロジェクト名をクリックします。
[アクションを表示] > [データセットを作成] をクリックします。
[データセットを作成する] ページで、次の操作を行います。
[データセット ID] に「
bqml_tutorial」と入力します。[ロケーション タイプ] で [マルチリージョン] を選択してから、[US(米国の複数のリージョン)] を選択します。
残りのデフォルトの設定は変更せず、[データセットを作成] をクリックします。
bq
新しいデータセットを作成するには、--location フラグを指定した bq mk コマンドを使用します。使用可能なパラメータの一覧については、bq mk --dataset コマンドのリファレンスをご覧ください。
データの場所が
USに設定され、BigQuery ML tutorial datasetという説明の付いた、bqml_tutorialという名前のデータセットを作成します。bq --location=US mk -d \ --description "BigQuery ML tutorial dataset." \ bqml_tutorial
このコマンドでは、
--datasetフラグの代わりに-dショートカットを使用しています。-dと--datasetを省略した場合、このコマンドはデフォルトでデータセットを作成します。データセットが作成されたことを確認します。
bq ls
API
定義済みのデータセット リソースを使用して datasets.insert メソッドを呼び出します。
{ "datasetReference": { "datasetId": "bqml_tutorial" } }
BigQuery DataFrames
このサンプルを試す前に、BigQuery DataFrames を使用した BigQuery クイックスタートの手順に沿って BigQuery DataFrames を設定してください。詳細については、BigQuery DataFrames のリファレンス ドキュメントをご覧ください。
BigQuery に対する認証を行うには、アプリケーションのデフォルト認証情報を設定します。詳細については、ローカル開発環境の ADC の設定をご覧ください。
入力データテーブルを作成する
モデルのトレーニングと評価に使用できるデータのテーブルを作成します。このテーブルは、bigquery-public-data.iowa_liquor_sales.sales テーブルと bigquery-public-data.covid19_weathersource_com.postal_code_day_history テーブルの列を結合して、酒類販売店で注文される商品の種類と数に天気がどのような影響を与えるかを分析します。また、モデルの入力変数として使用できる次の列も作成します。
date: 注文の日付。store_number: 注文した店舗を一意に識別する番号item_number: 注文された商品を一意に識別する番号bottles_sold: 関連商品の注文された本数temperature: 注文日における店舗の平均気温humidity: 注文日における店舗の平均湿度
入力データテーブルを作成するには、次の操作を行います。
Google Cloud コンソールで、[BigQuery] ページに移動します。
クエリエディタに次のクエリを貼り付け、[実行] をクリックします。
CREATE OR REPLACE TABLE `bqml_tutorial.iowa_liquor_sales_with_weather` AS WITH sales AS ( SELECT DATE, store_number, item_number, bottles_sold, SAFE_CAST(SAFE_CAST(zip_code AS FLOAT64) AS INT64) AS zip_code FROM `bigquery-public-data.iowa_liquor_sales.sales` AS sales WHERE SAFE_CAST(zip_code AS FLOAT64) IS NOT NULL ), aggregated_sales AS ( SELECT DATE, store_number, item_number, ANY_VALUE(zip_code) AS zip_code, SUM(bottles_sold) AS bottles_sold, FROM sales GROUP BY DATE, store_number, item_number ), weather AS ( SELECT DATE, SAFE_CAST(postal_code AS INT64) AS zip_code, avg_temperature_air_2m_f AS temperature, avg_humidity_specific_2m_gpkg AS humidity, FROM `bigquery-public-data.covid19_weathersource_com.postal_code_day_history` WHERE country = 'US' AND SAFE_CAST(postal_code AS INT64) IS NOT NULL ) SELECT aggregated_sales.date, aggregated_sales.store_number, aggregated_sales.item_number, aggregated_sales.bottles_sold, weather.temperature AS temperature, weather.humidity AS humidity FROM aggregated_sales LEFT JOIN weather ON aggregated_sales.zip_code=weather.zip_code AND aggregated_sales.DATE=weather.DATE;
時系列モデルを作成する
時系列モデルを作成して、2022 年 9 月 1 日より前の bqml_tutorial.iowa_liquor_sales_with_weather テーブル内の日付ごとに、店舗 ID と商品 ID の組み合わせごとに販売された本数を予測します。予測時に評価する特徴として、各日の店舗の平均気温と湿度を使用します。bqml_tutorial.iowa_liquor_sales_with_weather テーブルには、商品番号と店舗番号の組み合わせが約 100 万個あります。つまり、予測する時系列が 100 万個あるということです。
次の手順でモデルを作成します。
Google Cloud コンソールで、[BigQuery] ページに移動します。
クエリエディタに次のクエリを貼り付け、[実行] をクリックします。
CREATE OR REPLACE MODEL `bqml_tutorial.multi_time_series_arimax_model` OPTIONS( model_type = 'ARIMA_PLUS_XREG', time_series_id_col = ['store_number', 'item_number'], time_series_data_col = 'bottles_sold', time_series_timestamp_col = 'date' ) AS SELECT * FROM `bqml_tutorial.iowa_liquor_sales_with_weather` WHERE DATE < DATE('2022-09-01');
クエリが完了するまでに約 38 分かかります。完了後、
multi_time_series_arimax_modelモデルにアクセスできます。クエリはCREATE MODELステートメントを使用してモデルを作成するため、クエリの結果は表示されません。
モデルを使用してデータを予測する
ML.FORECAST 関数を使用して、将来の時系列値を予測します。
次の GoogleSQL クエリの STRUCT(5 AS horizon, 0.8 AS confidence_level) 句は、5 個の将来の時点を予測し、信頼度レベル 80% の予測間隔を生成するように指示します。
ML.FORECAST 関数の入力データのデータ シグネチャは、モデルの作成に使用したトレーニング データのデータ シグネチャと同じです。bottles_sold 列は、モデルが予測しようとしているデータであるため、入力に含まれません。
次の手順でモデルを使用し、データを予測します。
Google Cloud コンソールで、[BigQuery] ページに移動します。
クエリエディタに次のクエリを貼り付け、[実行] をクリックします。
SELECT * FROM ML.FORECAST ( model `bqml_tutorial.multi_time_series_arimax_model`, STRUCT (5 AS horizon, 0.8 AS confidence_level), ( SELECT * EXCEPT (bottles_sold) FROM `bqml_tutorial.iowa_liquor_sales_with_weather` WHERE DATE>=DATE('2022-09-01') ) );
結果は次のようになります。
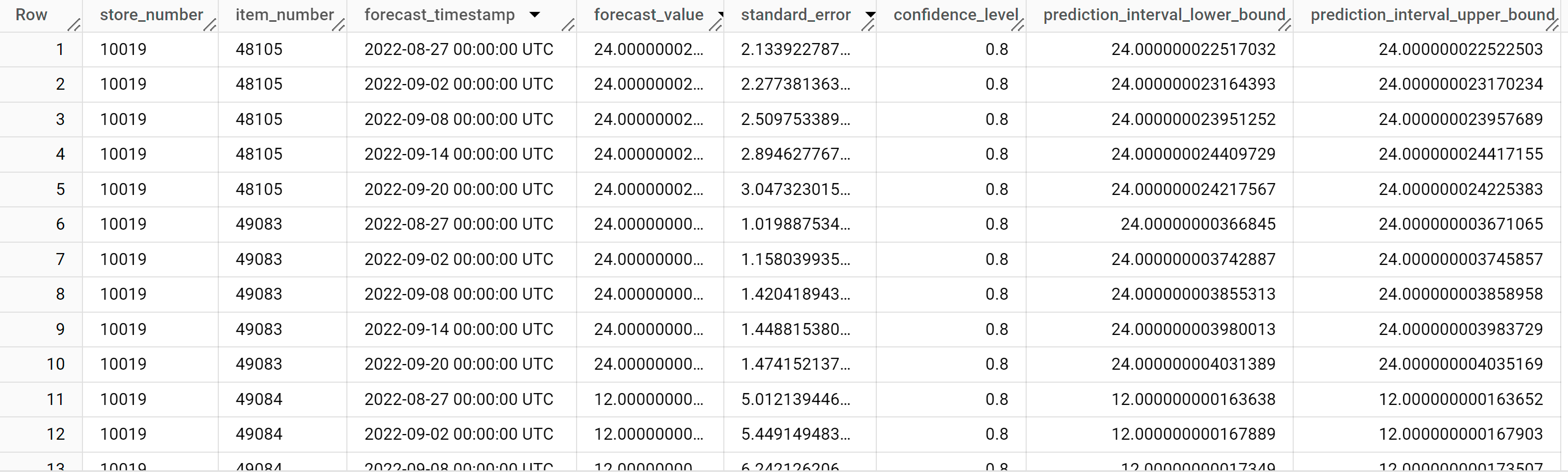
出力行は、まず
store_number値によって、次にitem_ID値によって、その後forecast_timestamp列の値を使った時系列順に並べられます。時系列予測では、prediction_interval_lower_bound列とprediction_interval_upper_bound列の値で表される予測間隔は、forecast_value列の値と同じくらい重要です。forecast_value値は予測間隔の中間点です。予測間隔は、standard_error列とconfidence_level列の値によって異なります。出力列の詳細については、
ML.FORECASTをご覧ください。
予測結果を説明する
ML.EXPLAIN_FORECAST 関数を使用すると、予測データに加えて説明可能性の指標を取得できます。ML.EXPLAIN_FORECAST 関数は、将来の時系列値を予測し、時系列の個別のコンポーネントをすべて返します。
ML.FORECAST 関数と同様に、ML.EXPLAIN_FORECAST 関数で使用される STRUCT(5 AS horizon, 0.8 AS confidence_level) 句は、30 個の将来の時点を予測し、信頼度 80% の予測間隔を生成するように指示します。
ML.EXPLAIN_FORECAST 関数は、過去のデータと予測データの両方を提供します。予測データのみを表示するには、クエリに time_series_type オプションを追加し、オプション値として forecast を指定します。
モデルの結果を説明する手順は次のとおりです。
Google Cloud コンソールで、[BigQuery] ページに移動します。
クエリエディタに次のクエリを貼り付け、[実行] をクリックします。
SELECT * FROM ML.EXPLAIN_FORECAST ( model `bqml_tutorial.multi_time_series_arimax_model`, STRUCT (5 AS horizon, 0.8 AS confidence_level), ( SELECT * EXCEPT (bottles_sold) FROM `bqml_tutorial.iowa_liquor_sales_with_weather` WHERE DATE >= DATE('2022-09-01') ) );
結果は次のようになります。
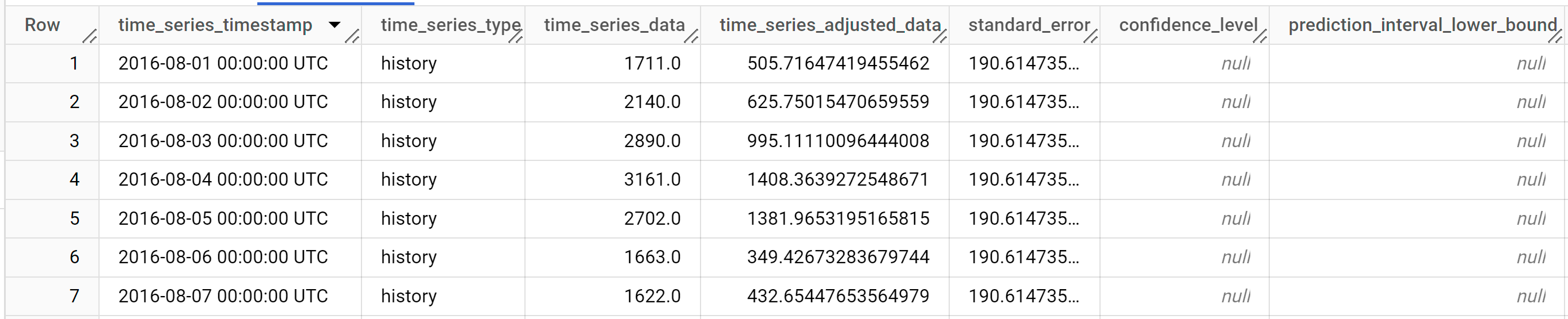
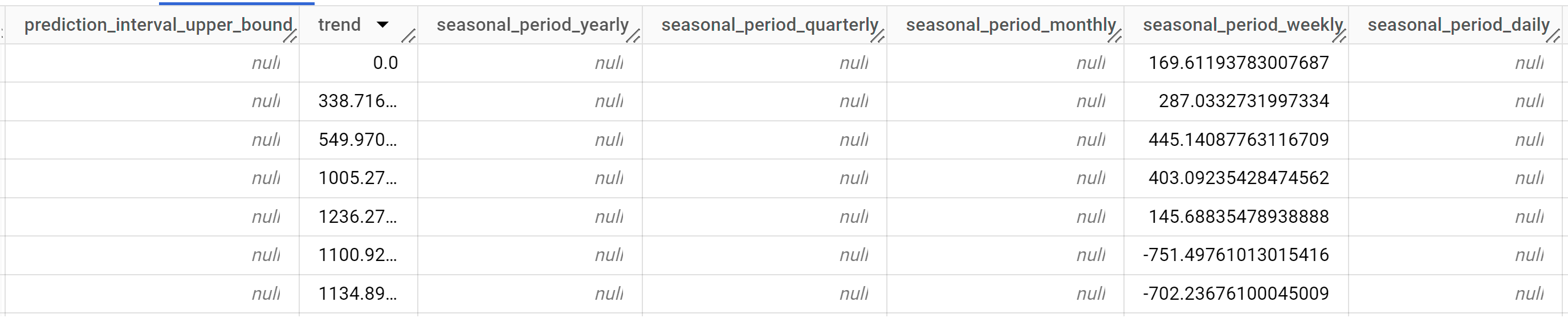
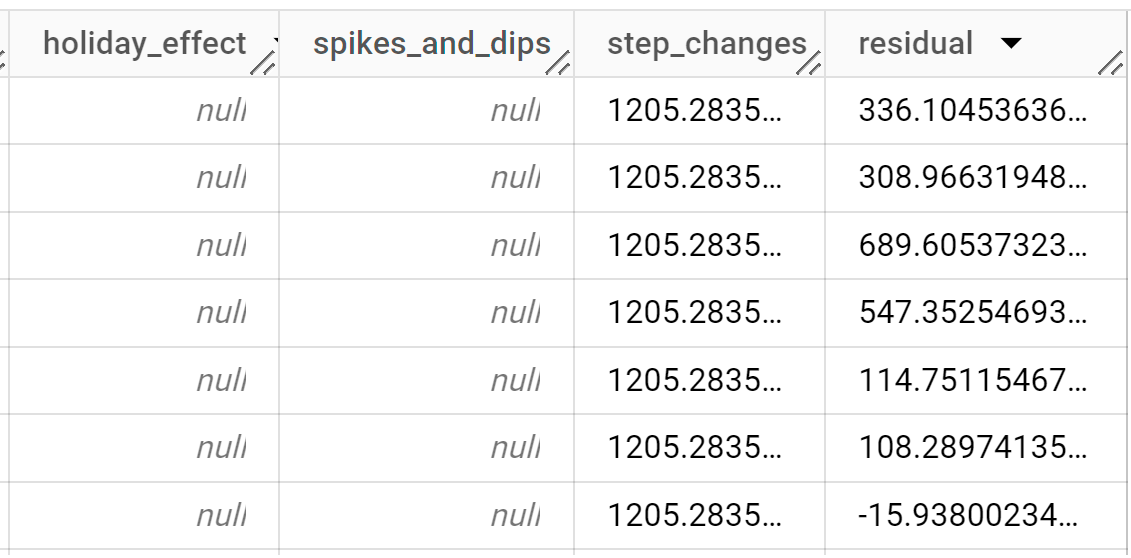
出力行は、
time_series_timestamp列の値で時系列順に表示されます。出力列の詳細については、
ML.EXPLAIN_FORECASTをご覧ください。
予測の精度を評価する
モデルがトレーニングされていないデータでモデルを実行して、モデルの予測精度を評価します。これを行うには、ML.EVALUATE 関数を使用します。ML.EVALUATE 関数は、各時系列を個別に評価します。
次の GoogleSQL クエリでは、2 番目の SELECT ステートメントで将来の特徴を含むデータを提供します。このデータは、実際のデータと比較して将来の値を予測するために使用されます。
モデルの精度を評価する手順は次のとおりです。
Google Cloud コンソールで、[BigQuery] ページに移動します。
クエリエディタに次のクエリを貼り付け、[実行] をクリックします。
SELECT * FROM ML.EVALUATE ( model `bqml_tutorial.multi_time_series_arimax_model`, ( SELECT * FROM `bqml_tutorial.iowa_liquor_sales_with_weather` WHERE DATE >= DATE('2022-09-01') ) );
結果は次のようになります。
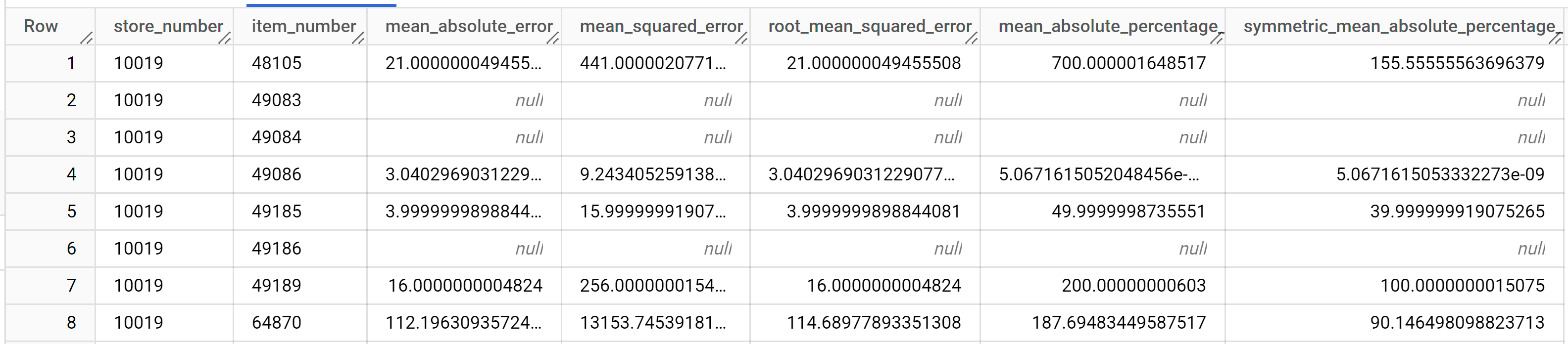
出力列の詳細については、
ML.EVALUATEをご覧ください。
モデルを使用して異常を検出する
ML.DETECT_ANOMALIES 関数を使用して、トレーニング データの異常を検出します。
次のクエリでは、STRUCT(0.95 AS anomaly_prob_threshold) 句により、ML.DETECT_ANOMALIES 関数は 95% の信頼度で異常なデータポイントを特定します。
トレーニング データ内の異常を検出する手順は次のとおりです。
Google Cloud コンソールで、[BigQuery] ページに移動します。
クエリエディタに次のクエリを貼り付け、[実行] をクリックします。
SELECT * FROM ML.DETECT_ANOMALIES ( model `bqml_tutorial.multi_time_series_arimax_model`, STRUCT (0.95 AS anomaly_prob_threshold) );
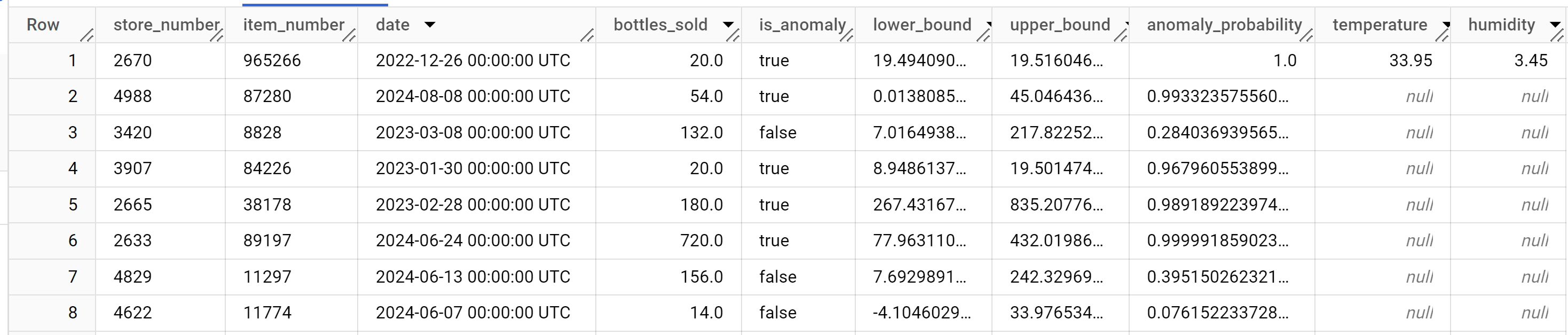
結果は次のようになります。
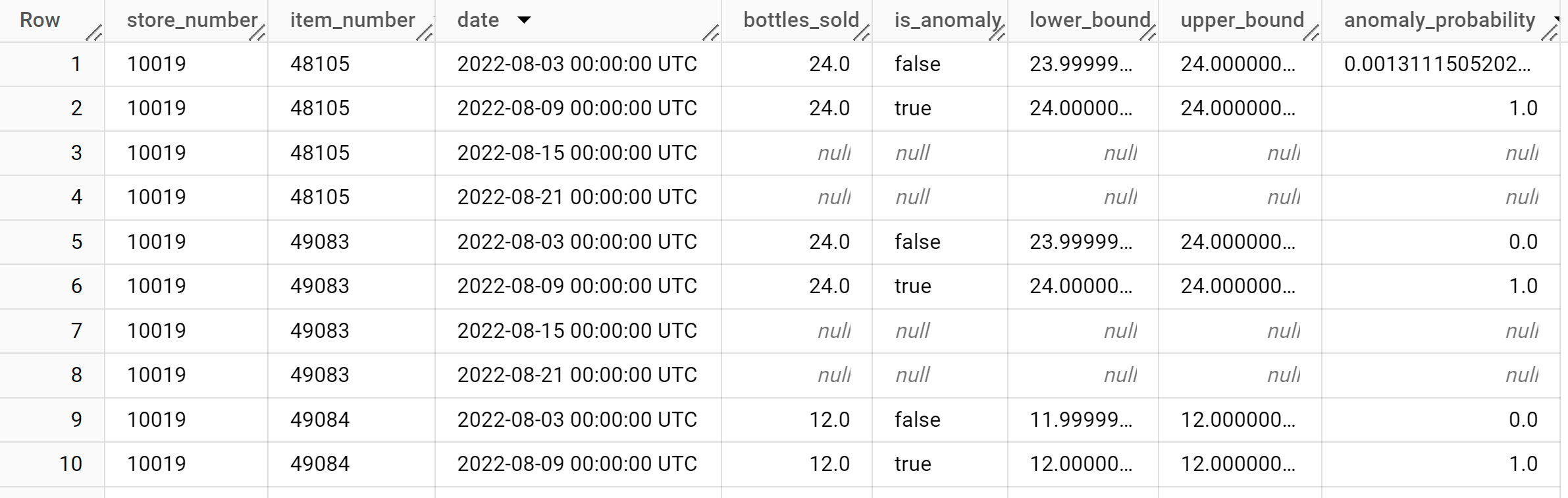
結果の
anomaly_probability列は、特定のbottles_sold列値が異常である可能性を示します。出力列の詳細については、
ML.DETECT_ANOMALIESをご覧ください。
新しいデータの異常を検出する
ML.DETECT_ANOMALIES 関数に入力データを渡して、新しいデータの異常を検出します。新しいデータのデータ シグネチャは、トレーニング データと同じである必要があります。
新しいデータの異常を検出する手順は次のとおりです。
Google Cloud コンソールで、[BigQuery] ページに移動します。
クエリエディタに次のクエリを貼り付け、[実行] をクリックします。
SELECT * FROM ML.DETECT_ANOMALIES ( model `bqml_tutorial.multi_time_series_arimax_model`, STRUCT (0.95 AS anomaly_prob_threshold), ( SELECT * FROM `bqml_tutorial.iowa_liquor_sales_with_weather` WHERE DATE >= DATE('2022-09-01') ) );
結果は次のようになります。