ソリューション ガイド: Oracle on Bare Metal Solution に対する Google Cloud のバックアップと DR
概要
Bare Metal Solution 環境内で Oracle データベースの復元力を実現するには、データベースのバックアップと障害復旧のための明確な戦略が必要です。この要件を満たすため、Google Cloud のソリューション アーキテクト チームは Google Cloud バックアップと DR サービスについて広範なテストを実施し、その結果をこのガイドにまとめました。ここでは、バックアップと DR サービスを使用して、Bare Metal Solution 環境内で Oracle データベースのバックアップと復元のオプションをデプロイ、構成、最適化するための最適な方法を紹介します。また、テスト結果のパフォーマンスの数値も提供しますので、実際の環境と比較するベンチマークとして使用できます。このガイドは、バックアップ管理者、Google Cloud 管理者、Oracle DBA の方に役立ちます。
背景
2022 年 6 月、ソリューション アーキテクト チームは、企業顧客向けに Google Cloud Backup and DR の概念実証(PoC)のデモを開始しました。この成功条件を満たすため、50 TB の Oracle データベースを 24 時間以内に復元する必要がありました。
この目標には多くの課題がありましたが、この概念実証の関係者の大半は、この目標を達成可能と判断し、概念実証を進めるべきだという結論に達しました。バックアップと DR のエンジニアリング チームのこれまでのテストデータから、これらの目標が達成可能であることが示され、リスクは比較的低いと判断しました。また、テスト結果をお客様と共有することで、お客様が概念実証を進めることに前向きになれるようにしました。
概念実証では、Bare Metal Solution 環境で複数の要素(Oracle、 Google Cloud Backup and DR、ストレージ、リージョン拡張リンク)を正常に構成する方法を習得しました。習得したベスト プラクティスに従うことで、お客様の固有の環境でも目標を実現することができます。
このドキュメントの全体的な結果を理解するうえで「道のりは異なるかも知れない」という前提に立つことは非常に良いことです。Google では、習得したこと、重視すべきこと、避けるべきこと、期待するパフォーマンスや成果が得られない場合に調査すべき項目に関する知識を共有することを目標としています。このガイドが、提案されたソリューションの信頼性を高め、要件を満たすことに役立つことができれば幸いです。
アーキテクチャ
図 1 は、Bare Metal Solution 環境で実行されている Oracle データベースを保護するために、バックアップと DR をデプロイする際に構築する必要があるインフラストラクチャの簡略図を示しています。
図 1: Bare Metal Solution 環境の Oracle データベースでバックアップと DR を使用するためのコンポーネント

図からわかるように、このソリューションには次のコンポーネントが必要です。
- Bare Metal Solution リージョン拡張 - Google Cloud データセンターに隣接するサードパーティのデータセンターで Oracle データベースを稼働し、既存のオンプレミス ソフトウェア ライセンスを使用できるようにします。
- バックアップと DR のサービス プロジェクト - バックアップ/リカバリ アプライアンスをホストし、Cloud Storage バケットに Bare Metal Solution と Google Cloud のワークロードをバックアップできるようにします。
- Compute サービス プロジェクト - Compute Engine VM を実行するロケーションを提供します。
- バックアップと DR サービス - バックアップと障害復旧を保守するためのバックアップと DR の管理コンソールを提供します。
- ホスト プロジェクト - 共有 VPC 内にリージョン サブネットを作成し、バックアップと DR サービス、バックアップ/リカバリ アプライアンス、Cloud Storage バケット、Compute Engine VM に Bare Metal Solution リージョン拡張を接続できるようにします。
Backup and DR をインストールする Google Cloud
バックアップと DR のソリューションが機能するには、少なくとも次の 2 つのコンポーネントが必要です。
- バックアップと DR の管理コンソール -Google Cloud コンソールからバックアップを作成、管理できる HTML 5 UI と API エンドポイント。
- バックアップ/リカバリ アプライアンス – バックアップの実行でタスクワーカーとして機能し、タイプのタスクをマウントして復元します。
Google Cloud は、バックアップと DR の管理コンソールを管理します。管理コンソールをサービス プロデューサー プロジェクト(Google Cloud 管理側)にデプロイし、バックアップ/リカバリ アプライアンスをサービス ユーザー プロジェクト(ユーザー側)にデプロイする必要があります。Backup and DR の詳細については、Backup and DR のデプロイの設定と計画をご覧ください。サービス プロデューサーとサービス ユーザーの定義については、Google Cloud 用語集をご覧ください。
始める前に
Google Cloud バックアップと DR サービスをインストールするには、デプロイを開始する前に、次の構成手順を完了しておく必要があります。
- プライベート サービス アクセス接続を有効にします。インストールを始める前に、この接続を確立しておく必要があります。プライベート サービス アクセス サブネットがすでに構成されている場合でも、少なくとも
/23サブネットが必要です。たとえば、プライベート サービス アクセスの接続用に/24サブネットがすでに構成されている場合は、/23サブネットを追加することをおすすめします。また、/20サブネットを追加すると、後でサービスを追加できます。 - バックアップ/リカバリ アプライアンスをデプロイする VPC ネットワークでアクセスされるように Cloud DNS を構成します。これにより、非公開または公開ルックアップで googleapis.com が正しく解決されるようになります。
- ネットワークのデフォルト ルートとファイアウォール ルールを構成して、
*.googleapis.com(パブリック IP 経由)または TCP ポート 443 上のprivate.googleapis.com(199.36.153.8/30)への下り(外向き)トラフィック、または0.0.0.0/0の明示的な下り(外向き)を許可します。ここでも、バックアップ/リカバリ アプライアンスをインストールする VPC ネットワーク内のルートとファイアウォールを構成する必要があります。望ましいオプションとして、プライベート Google アクセスを使用することをおすすめします。詳細については、プライベート Google アクセスの構成をご覧ください。 - コンシューマ プロジェクトで次の API を有効にします。
- Compute Engine API
- Cloud Key Management Service(KMS)API
- Cloud Resource Manager API(ホスト プロジェクト用、使用中の場合はサービス プロジェクト用)
- Identity and Access Management API
- Workflows API
- Cloud Logging API
- 組織のポリシーを有効にしている場合は、次のように構成されていることを確認します。
constraints/cloudkms.allowedProtectionLevelsにSOFTWAREまたはALLが含まれている。
- 次のファイアウォール ルールを構成します。
- Compute Engine VPC のバックアップ/リカバリ アプライアンスからポート TCP-5106 の Linux ホスト(エージェント)への上り(内向き)。
- iSCSI でブロックベースのバックアップ ディスクを使用する場合、Bare Metal Solution の Linux ホスト(エージェント)から Compute Engine VPC のバックアップ/リカバリ アプライアンスのポート TCP-3260 への下り(外向き)。
- NFS または dNFS ベースのバックアップ ディスクを使用する場合、Bare Metal Solution の Linux ホスト(エージェント)から Compute Engine VPC のバックアップ/リカバリ アプライアンスの次のポートへの下り(外向き)。
- TCP/UDP-111(rpcbind)
- TCP/UDP-756(status)
- TCP/UDP-2049(nfs)
- TCP/UDP-4001(mountd)
- TCP/UDP-4045(nlockmgr)
- Google Cloud DNS を構成して、Bare Metal Solution のホスト名とドメインを解決し、Bare Metal Solution サーバー、VM、バックアップと DR サービスなど、Compute Engine ベースのリソース間での名前解決に矛盾がないようにします。
バックアップと DR の管理コンソールをインストールする
- Backup and DR Service API がまだ有効になっていない場合は有効にします。
Google Cloud コンソールで、ナビゲーション メニューを使用して [オペレーション] セクションに移動し、[バックアップと DR] を選択します。
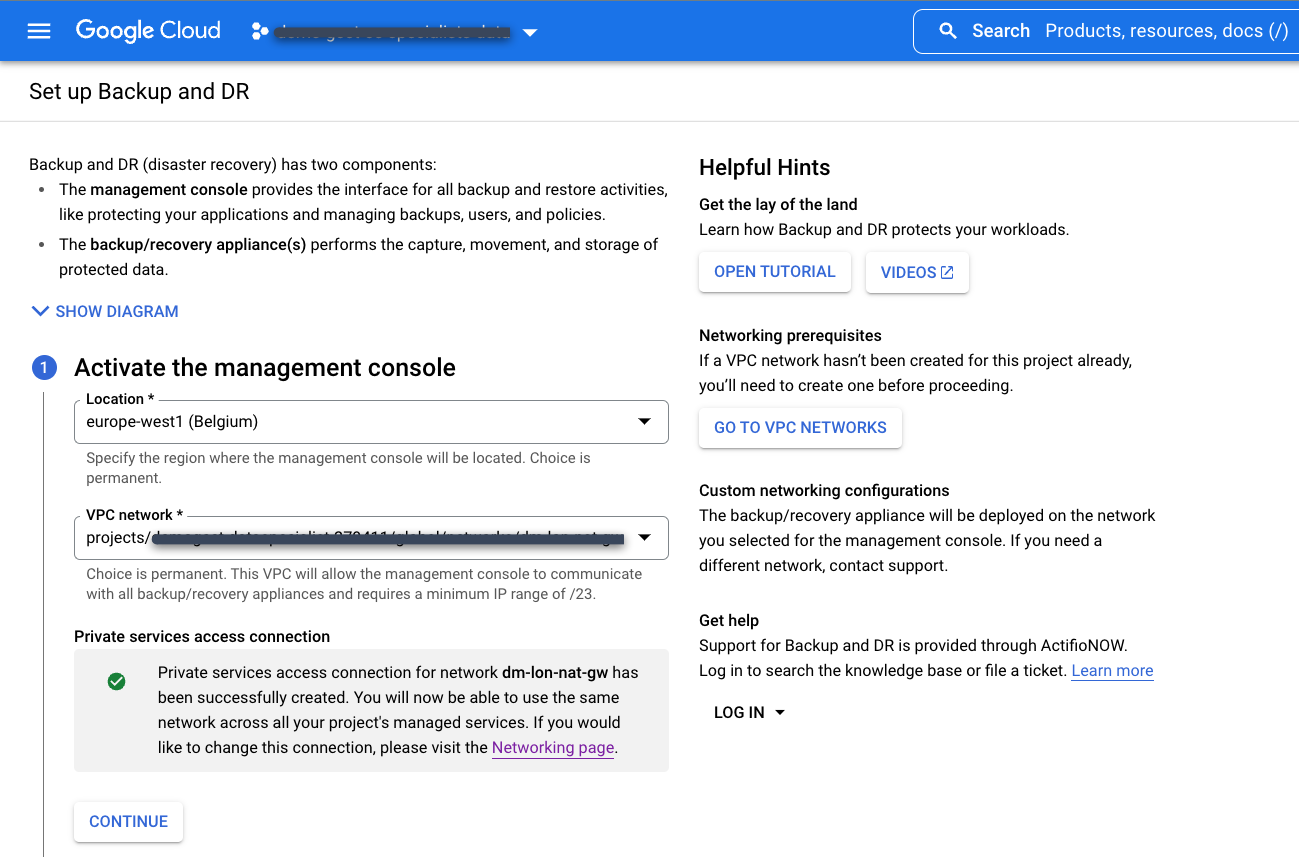
前に作成した既存のプライベート サービス アクセス接続を選択します。
バックアップと DR の管理コンソールのロケーションを選択します。これは、バックアップと DR 管理コンソールのユーザー インターフェースをサービス プロデューサー プロジェクトにデプロイするリージョンです。 Google Cloud は、管理コンソール リソースを所有して維持します。
バックアップと DR サービスに接続するサービス コンシューマー プロジェクトの VPC ネットワークを選択します。これは、一般に共有 VPC またはホスト プロジェクトです。
1 時間経過してデプロイが完了すると、次の画面が表示されます。
![[バックアップと DR] ページが表示されています。ここからバックアップと DR の管理コンソールにログインできます。](https://cloud.google.com/static/bare-metal/docs/solutions/oracle/images/backup-and-dr-management-console-log-in.png?hl=ja)
バックアップ / リカバリ アプライアンスをインストールする
[バックアップと DR] ページで、[Log in to the Management Console] をクリックします。
https://bmc-PROJECT_NUMBER-GENERATED_ID-dot-REGION.backupdr.googleusercontent.com/
バックアップと DR の管理コンソールのメインページで、[アプライアンス] ページに移動します。
https://bmc-PROJECT_NUMBER-GENERATED_ID-dot-REGION.backupdr.googleusercontent.com/#clusters
バックアップ / リカバリ アプライアンスの名前を入力します。デプロイが開始すると、名前の末尾に自動的に乱数が追加されます。 Google Cloud
バックアップ/リカバリ アプライアンスをインストールするコンシューマー プロジェクトを選択します。
優先するリージョン、ゾーン、サブネットワークを選択します。
ストレージの種類を選択します。概念実証では標準永続ディスクを選択し、本番環境では SSD 永続ディスクを選択することをおすすめします。
[Begin Installation] ボタンをクリックします。バックアップと DR の管理コンソールと最初のバックアップ/リカバリ アプライアンスの両方をデプロイするには、1 時間ほどかかります。
最初のインストール プロセスが完了したら、別のバックアップ/リカバリ アプライアンスを他のリージョンまたはゾーンに追加できます。
Google Cloud Backup and DR を構成する
このセクションでは、バックアップと DR サービスを構成してワークロードを保護するために必要な手順について説明します。
サービス アカウントの構成
バージョン 11.0.2(2022 年 12 月リリースのバックアップと DR)では、1 つのサービス アカウントでバックアップ/リカバリ アプライアンスを実行し、Cloud Storage バケットにアクセスして、Compute Engine 仮想マシン(VM)を保護します(このドキュメントでは説明しません)。
サービス アカウントのロール
Google Cloud バックアップと DR では、ユーザーとサービス アカウントの認証と認可に Google Cloud Identity and Access Management(IAM)を使用します。事前定義ロールを使用すると、さまざまなバックアップ機能を有効にできます。最も重要なものは次の 2 つです。
- バックアップと DR の Cloud Storage オペレーター - このロールは、Cloud Storage バケットに接続するバックアップ/リカバリ アプライアンスが使用するサービス アカウントに割り当てます。このロールを使用すると、Compute Engine スナップショット バックアップ用の Cloud Storage バケットを作成できます。また、ワークロードを復元するために、エージェント ベースの既存のバックアップ データを含むバケットにアクセスできます。
- バックアップと DR の Compute Engine オペレーター - バックアップ/リカバリ アプライアンスが使用するサービス アカウントにこのロールを割り当て、Compute Engine 仮想マシン用の永続ディスクのスナップショットを作成します。このロールは、スナップショットを作成するだけでなく、同じソース プロジェクトまたは代替プロジェクト内の VM を復元することもできます。
サービス アカウントを見つけるには、コンシューマ/サービス プロジェクトでバックアップ/リカバリ アプライアンスを実行している Compute Engine VM を表示し、[API と ID の管理] に表示されているサービス アカウントの値を確認します。
バックアップ/リカバリ アプライアンスに適切な権限を付与するには、[Identity and Access Management] ページに移動し、次の Identity and Access Management のロールをバックアップ/リカバリ アプライアンスのサービス アカウントに付与します。
- Backup and DR Cloud Storage オペレーター
- バックアップと DR の Compute Engine オペレーター(省略可)
ストレージ プールを構成する
ストレージ プールは、データを物理的な保存場所に保管します。最近のデータ(1 ~ 14 日)には永続ディスクを、長期保存(日、週、月、年)には Cloud Storage を使用します。
Cloud Storage
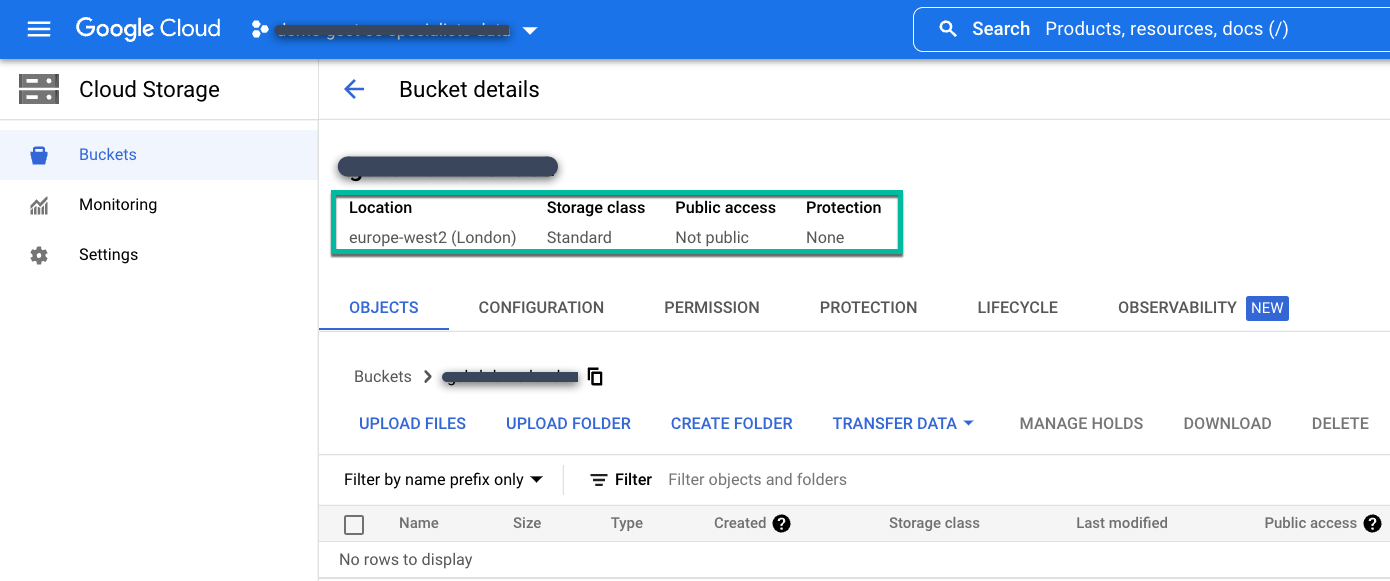
バックアップ データを保存するロケーションに、リージョンまたはマルチリージョンの標準バケットを作成します。
Cloud Storage バケットを作成する手順は次のとおりです。
- Cloud Storage の [バケット] ページで、バケットに名前を付けます。
- ストレージのロケーションを選択します。
- ストレージ クラス(Standard、Nearline、または Coldline)を選択します。
- Nearline Storage または Coldline Storage を選択する場合は、[アクセス制御] モードを [きめ細かい管理] に設定します。Standard Storage の場合は、デフォルトのアクセス制御モードである [均一] を受け入れます。
最後に、追加のデータ保護オプションを構成せずに、[作成] をクリックします。
次に、このバケットをバックアップ / リカバリ アプライアンスに追加します。バックアップと DR の管理コンソールに移動します。
https://bmc-PROJECT_NUMBER-GENERATED_ID-dot-REGION.backupdr.googleusercontent.com/
[管理] > [ストレージ プール] メニュー項目を選択します。
https://bmc-PROJECT_NUMBER-GENERATED_ID-dot-REGION.backupdr.googleusercontent.com/#pools
![バックアップと DR の管理コンソール ページ。[管理] > [ストレージ プール] メニューが表示されています。](/static/bare-metal/docs/solutions/oracle/images/backup-and-dr-manage-storage-pools.png)
右端のオプション [+ Add OnVault Pool] をクリックします。
https://bmc-PROJECT_NUMBER-GENERATED_ID-dot-REGION.backupdr.googleusercontent.com/#addonvaultpool
- [プール名] に名前を入力します。
- [プールタイプ] に [Cloud Storage] を選択します。
- Cloud Storage バケットに接続するアプライアンスを選択します。
- Cloud Storage バケットの名前を入力します。
[保存] をクリックします。
![[Add OnVault Pool] ダイアログ ボックスが表示されたバックアップと DR の管理コンソール ページ。](https://cloud.google.com/static/bare-metal/docs/solutions/oracle/images/backup-and-dr-add-onvault-pool.png?hl=ja)
永続ディスク スナップショット プール
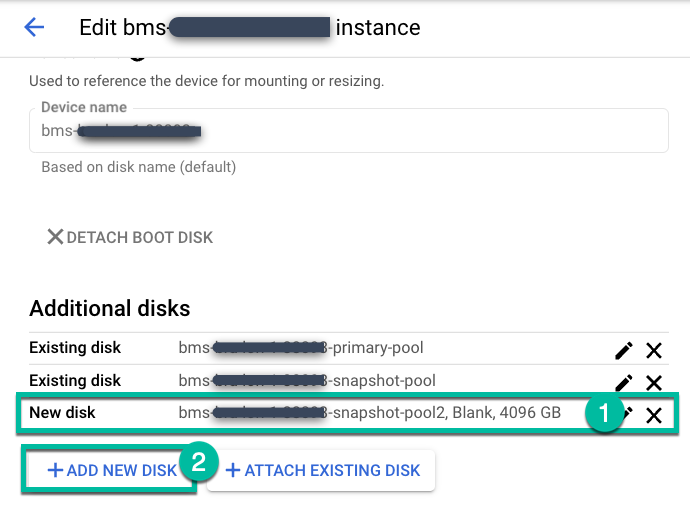
バックアップ/リカバリ アプライアンスを標準または SSD のオプションでデプロイした場合、永続ディスクのスナップショット プールはデフォルトで 4 TB になります。ソース データベースまたはファイル システムでより大きなプールが必要な場合は、デプロイされたバックアップ/リカバリ アプライアンスの設定を編集して新しい永続ディスクを追加し、新しいカスタムプールを作成するか、別のデフォルト プールを構成します。
[管理] > [アプライアンス] ページに移動します。
https://bmc-PROJECT_NUMBER-GENERATED_ID-dot-REGION.backupdr.googleusercontent.com/#clusters
バックアップ サーバー インスタンスを編集し、[+ 新しいディスクを追加] をクリックします。
- ディスクに名前を付けます。
- 空白のディスクタイプを選択します。
- 必要に応じて、標準、バランス、SSD のいずれかを選択します。
- 必要なディスクサイズを入力します。
[保存] をクリックします。
バックアップと DR の管理コンソールで、[管理] > [アプライアンス] ページに移動します。
https://bmc-PROJECT_NUMBER-GENERATED_ID-dot-REGION.backupdr.googleusercontent.com/#clusters
アプライアンス名を右クリックし、メニューから [Configure Appliance] を選択します。
![バックアップと DR の管理コンソール ページ。[アプライアンス] ページに [Configure Appliance] メニュー オプションが表示されています。](https://cloud.google.com/static/bare-metal/docs/solutions/oracle/images/backup-and-dr-configure-appliance.png?hl=ja)
既存のスナップショット プールにディスクを追加するか(拡張)、新しいプールを作成できます(ただし、同じプールに異なる種類の Persistent Disk を混在させないでください)。拡張する場合は、拡張するプールの右上のアイコンをクリックします。
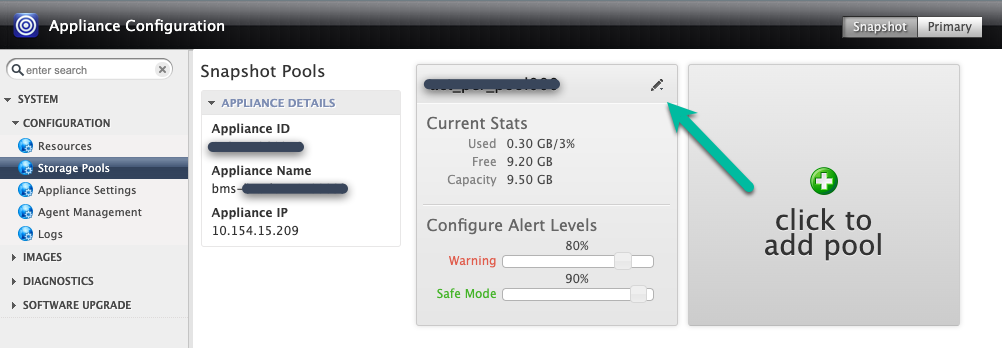
この例では、[Click to add pool] オプションを使用して新しいプールを作成します。このボタンをクリックした後、次のページが開くまで 20 秒ほどかかります。
![バックアップと DR の管理コンソール ページ。[Click to add pool] ボタンをクリックして、新しいスナップショット プールを作成する方法を表示しています。](https://cloud.google.com/static/bare-metal/docs/solutions/oracle/images/backup-and-dr-snapshot-add-pool.png?hl=ja)
このステップでは、新しいプールを構成します。
- プールに名前を付け、緑色の [+] アイコンをクリックしてディスクをプールに追加します。
- [送信] をクリックします。
- プロンプトが表示されたら、[PROCEED] と大文字で入力して続行します。
[確認] をクリックします。
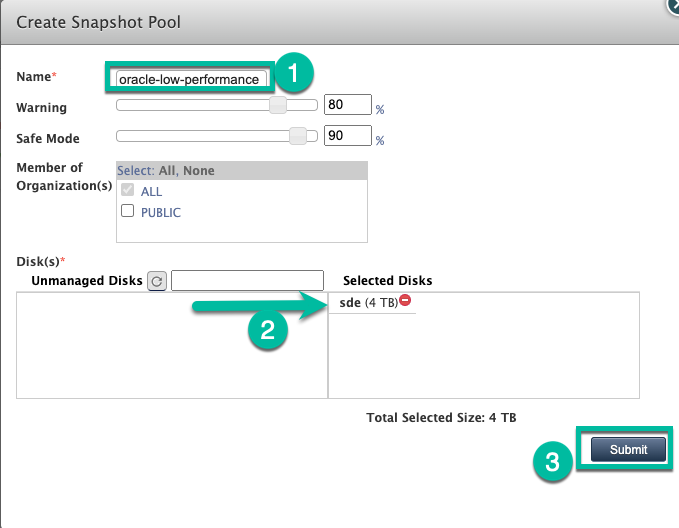
これで、プールが拡張されるか、永続ディスクを使用して作成されます。
バックアップ プランを構成する
バックアップ プランを使用すると、データベース、VM、ファイル システムをバックアップするための 2 つの重要な要素を構成できます。バックアップ プランにはプロファイルとテンプレートが組み込まれています。
- プロファイルを使用すると、バックアップのタイミングとバックアップ データの保持期間を指定できます。
- テンプレートには、バックアップ タスクに使用するバックアップ/リカバリ アプライアンスとストレージ プール(永続ディスク、Cloud Storage など)を決定できる構成項目が用意されています。はバックアップ タスクに使用する必要があります。
プロフィールを作成
バックアップと DR の管理コンソールで、[バックアップ プラン] > [プロファイル] ページに移動します。
https://bmc-PROJECT_NUMBER-GENERATED_ID-dot-REGION.backupdr.googleusercontent.com/#manageprofiles
2 つのプロファイルがすでに作成されています。1 つのプロファイルを Compute Engine VM スナップショット用に使用し、もう 1 つのプロファイルを編集して Bare Metal Solution バックアップ用に使用できます。複数のプロファイルを作成できます。これは、バックアップに異なるディスク階層を必要とする多くのデータベースをバックアップする場合に役立ちます。たとえば、SSD(高パフォーマンス)用のプールと標準永続ディスク(標準パフォーマンス)用のプールを 1 つずつ作成できます。プロファイルごとに異なるスナップショット プールを選択できます。
LocalProfile という名前のデフォルト プロファイルを右クリックし、[編集] を選択します。
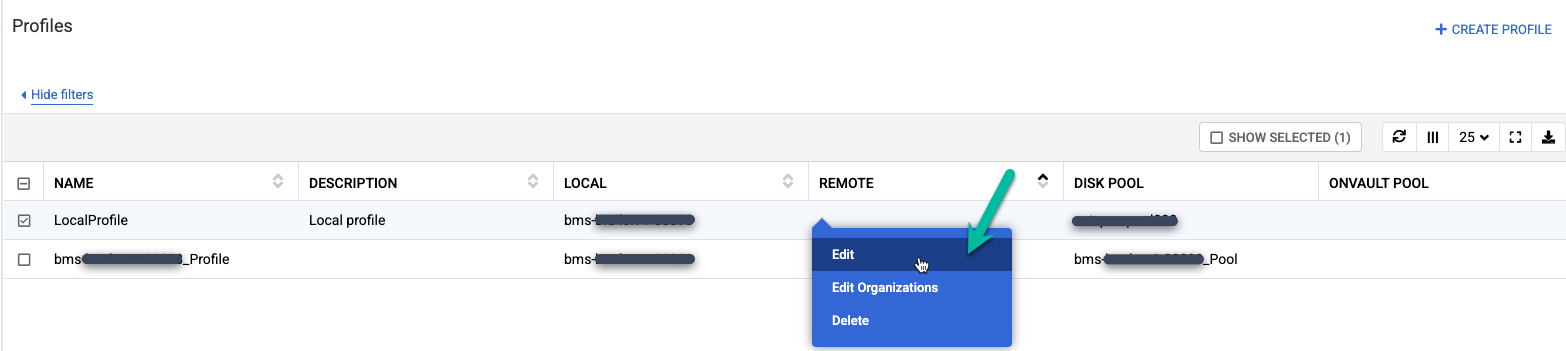
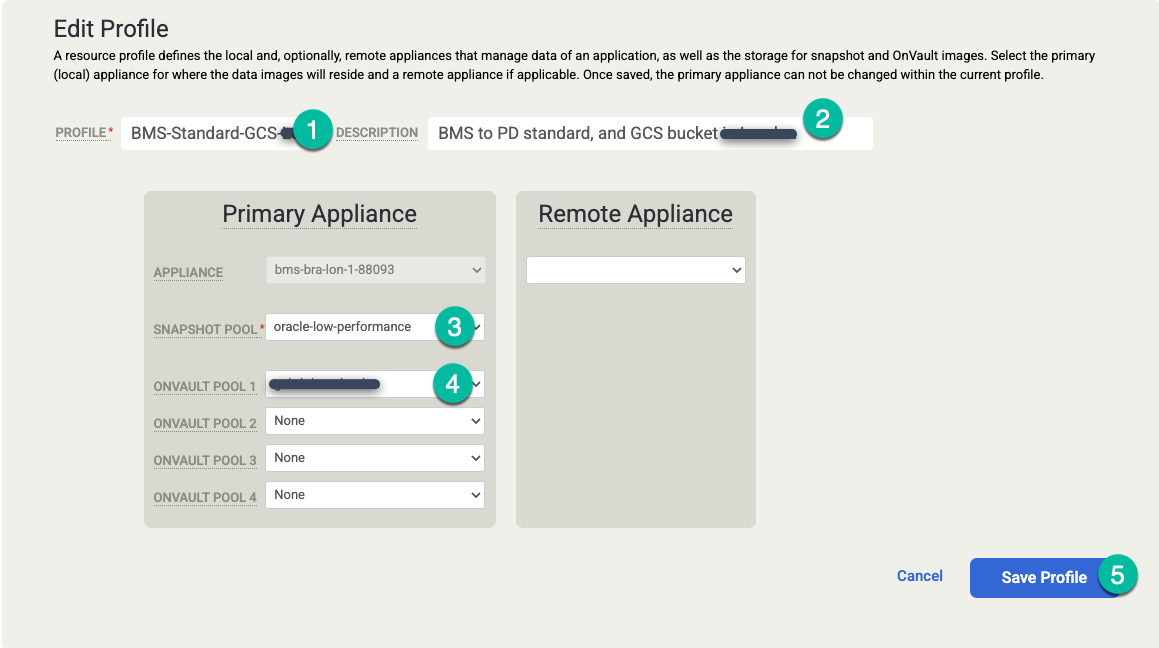
次のように変更します。
- よりわかりやすい名前と説明を使用して、プロファイルの設定を更新します。使用するディスク階層、Cloud Storage バケットの配置場所、このプロファイルの用途を説明する情報などを指定できます。
- スナップショット プールを、展開したプールまたは先ほど作成した新しいプールに変更します。
- このプロファイルに OnVault プール(Cloud Storage バケット)を選択します。
[Save Profile] をクリックします。
テンプレートを作成する
バックアップと DR の管理コンソールで、[バックアップ プラン] > [テンプレート] メニューに移動します。
https://bmc-PROJECT_NUMBER-GENERATED_ID-dot-REGION.backupdr.googleusercontent.com/#managetemplates
[+ テンプレートを作成] をクリックします。
- テンプレートに名前を付けます。
- [Allow overrides on policy settings] で [Yes] を選択します。
- このテンプレートの説明を追加します。
[テンプレートを保存] をクリックします。
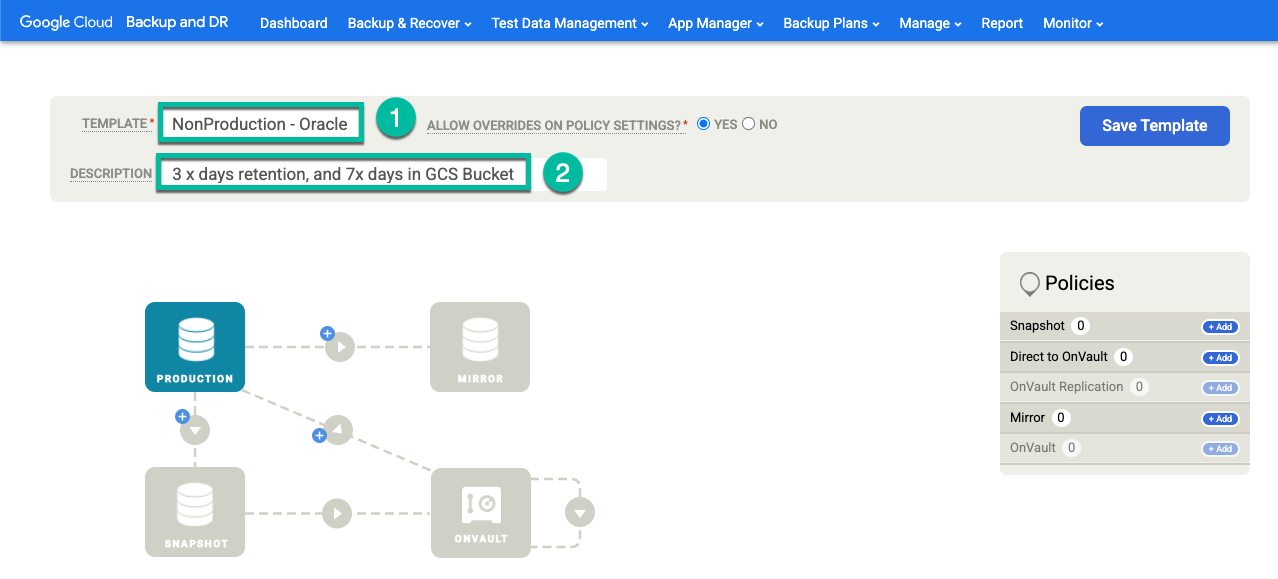
テンプレートで、次のように構成します。
- 右側の [ポリシー] セクションで、[+ 追加] をクリックします。
- ポリシー名を指定します。
- ポリシーを実行する曜日のチェックボックスを選択するか、デフォルト(Everyday)のままにします。
- その期間内に実行するジョブのウィンドウを編集します。
- 保持期間を選択します。
[Advanced Policy Settings] をクリックします。
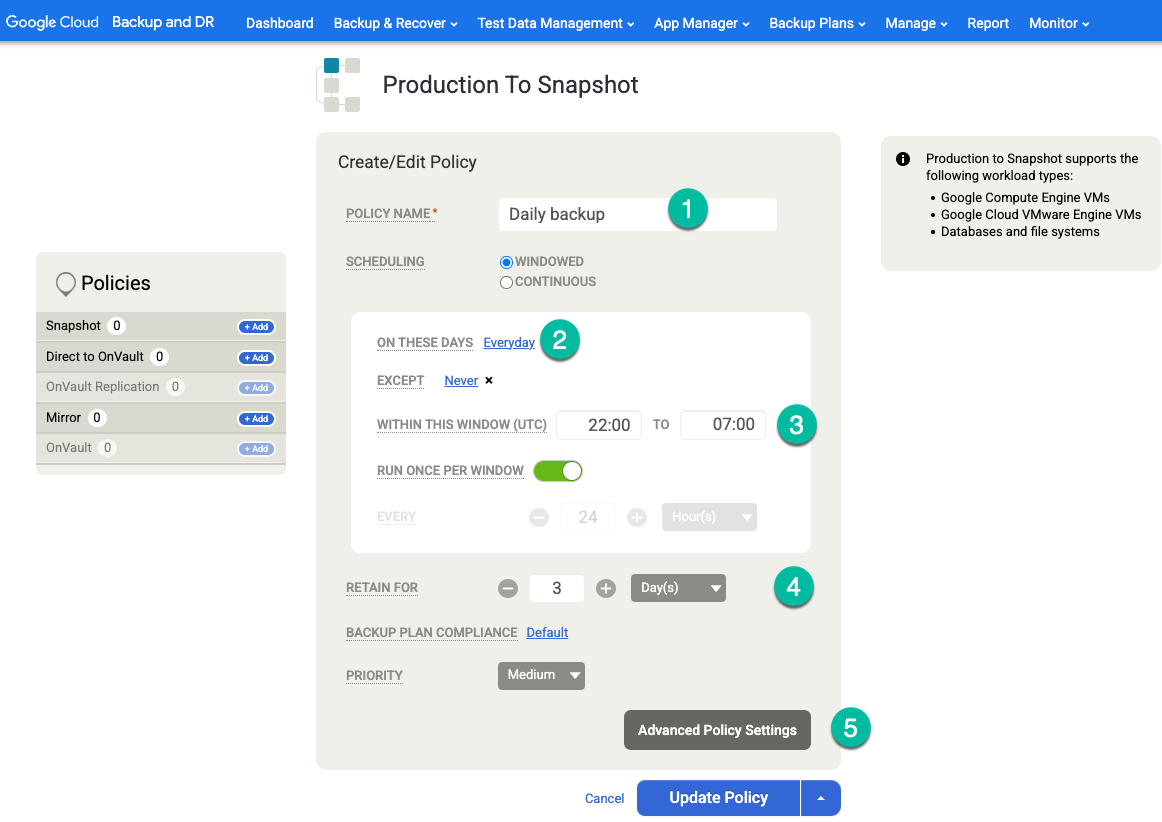
アーカイブログのバックアップを定期的に(たとえば 15 分ごと)実行し、アーカイブログを Cloud Storage に複製する場合は、次のポリシー設定を有効にする必要があります。
- 必要に応じて、[Truncate/Purge Log after Backup] を [Truncate] に設定します。
- 必要に応じて、[Enable Database Log Backup] を [Yes] に設定します。
- [RPO (Minutes)] に、目的のアーカイブログ バックアップ間隔を設定します。
- [Log Backup Retention Period (in Days)] に、目的の保持期間に設定します。
- [Replicate Logs (Uses Streamsnap Technology)] を [No] に設定します。
- Cloud Storage バケットにログを送信する場合は、[Send Logs to OnVault Pool] を [Yes] に設定します。送信しない場合は、[No] を選択します。
[変更を保存] をクリックします。
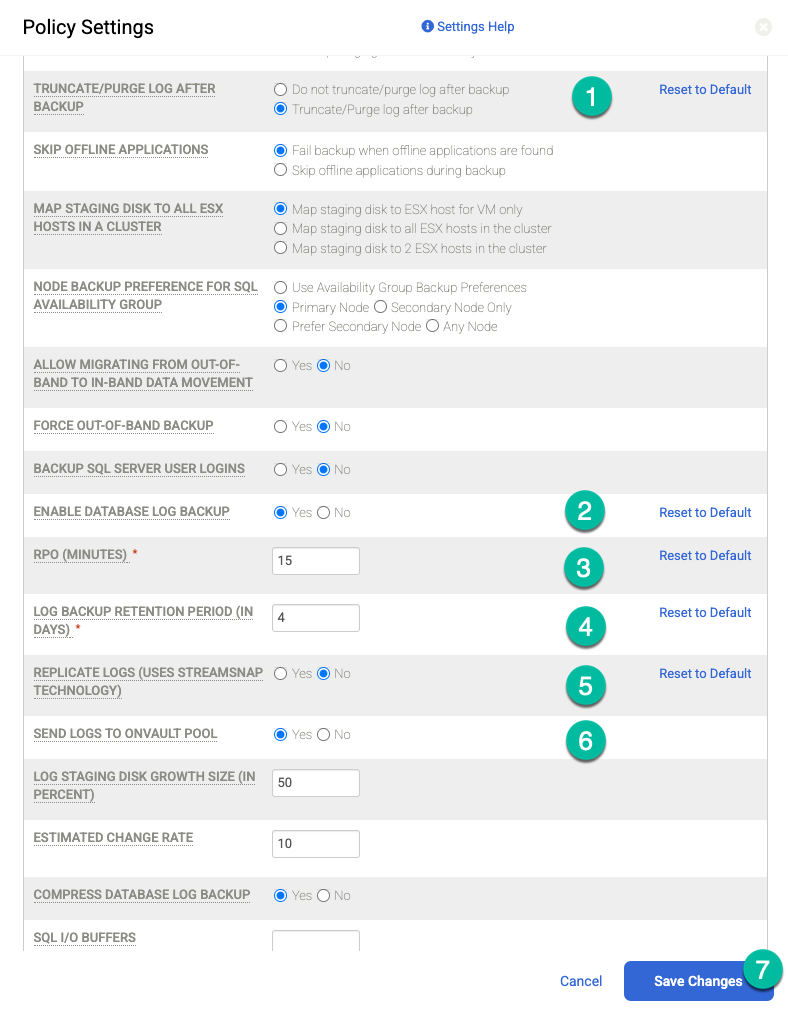
[ポリシーの更新] をクリックして、変更を保存します。
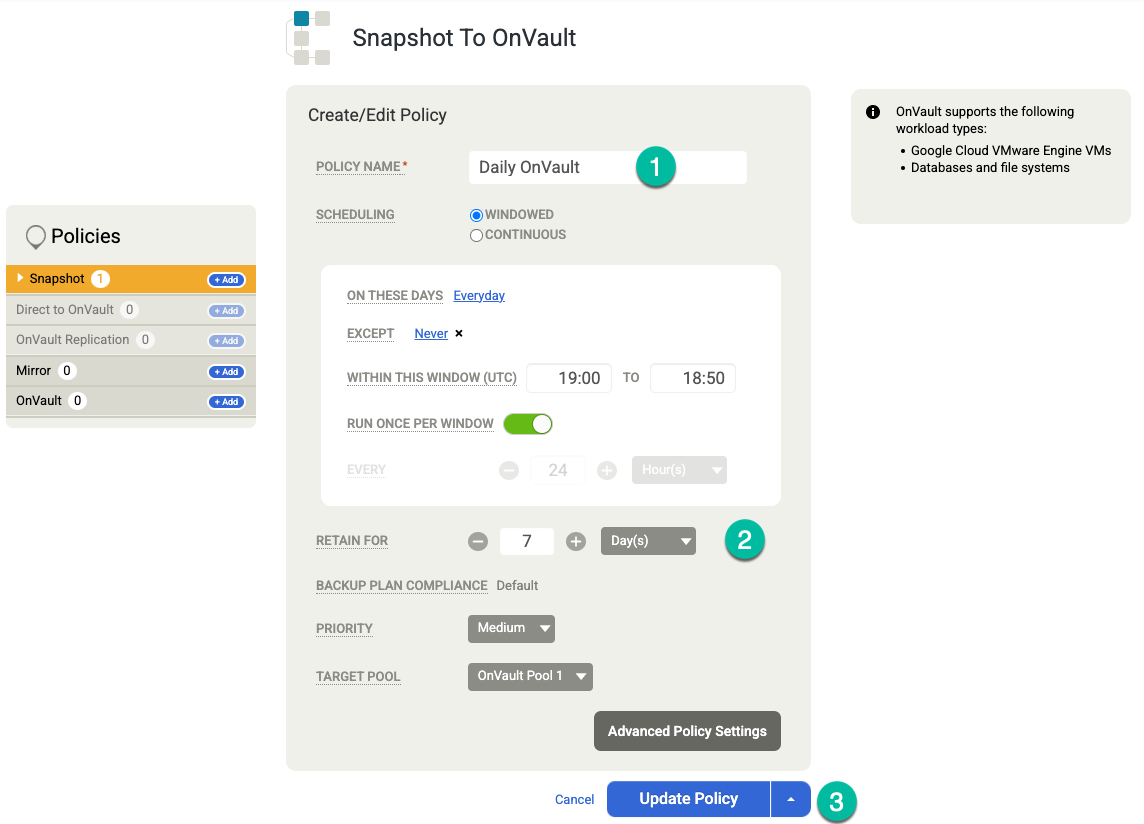
右側の [OnVault] で、次の操作を行います。
- [+ 追加] をクリックします。
- ポリシー名を追加します。
- [保持期間] を日、週、月、年で設定します。
[ポリシーの更新] をクリックします。
(省略可)保持オプションを追加する必要がある場合は、週単位、月単位、年単位の保持期間に追加のポリシーを作成します。別の保持ポリシーを追加する手順は次のとおりです。
- 右側の [OnVault] で、[+ 追加] をクリックします。
- ポリシー名を追加します。
- [On These Days] の値を、このジョブをトリガーする日に変更します。
- [保持期間] を [Days, Weeks, Months]、または [年] で設定します。
[ポリシーの更新] をクリックします。
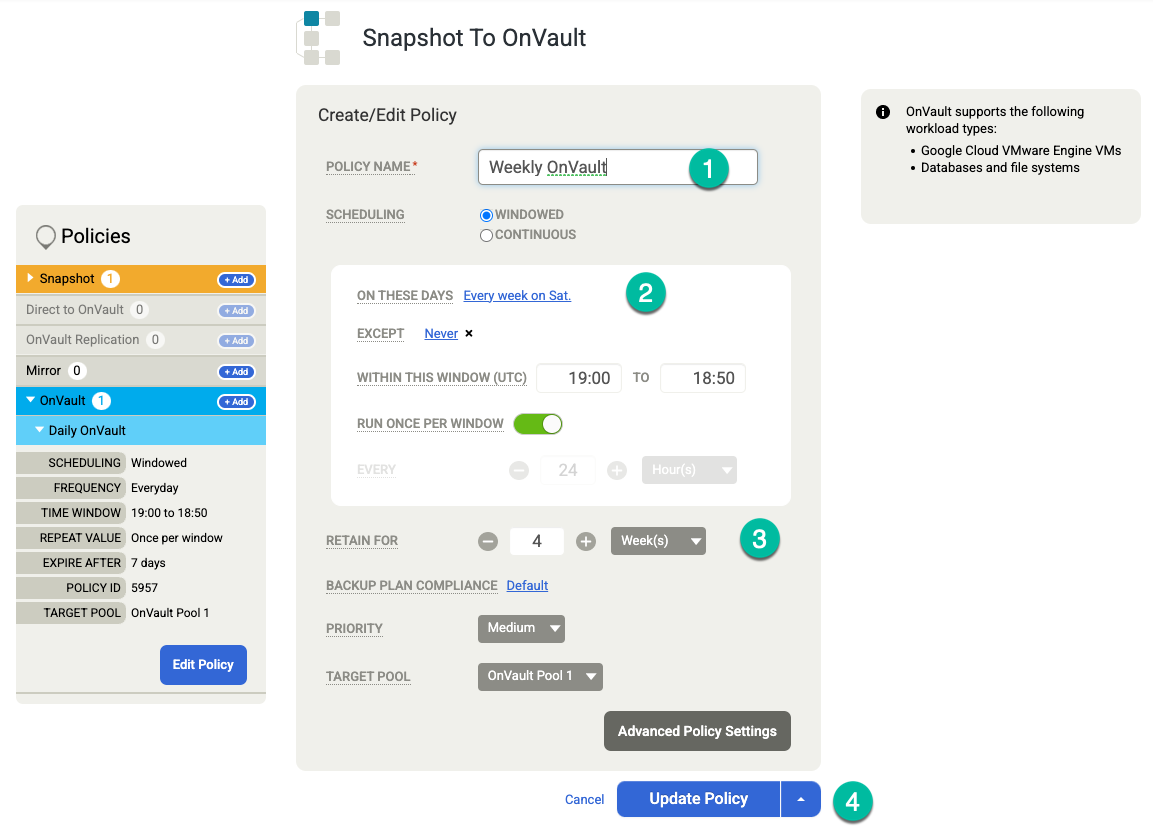
[テンプレートを保存] をクリックします。次の例は、永続ディスク階層で 3 日間、OnVault ジョブで 7 日間、合計 4 週間バックアップを保持するスナップショット ポリシーを示しています。週次バックアップは土曜日の夜に行われます。
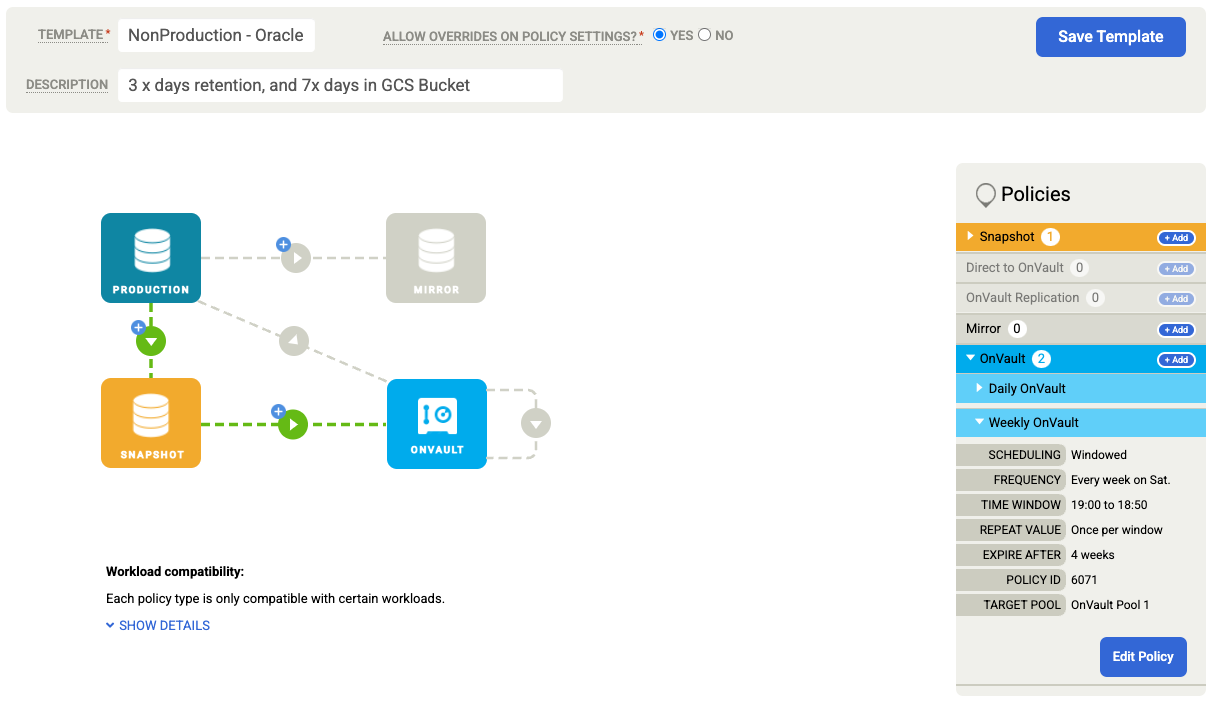
Oracle データベースをバックアップする
Google Cloud バックアップと DR のアーキテクチャは、アプリケーションで整合性のある永久増分方式で Oracle を Google Cloudにバックアップします。また、マルチテラバイトの Oracle データベースを直ちに復旧し、クローンを作成できます。
Google Cloud Backup and DR では、次の Oracle API が使用されます。
- RMAN イメージコピー API - データファイルの物理構造がすでに存在しているため、データファイルのイメージコピーを高速に復元できます。リカバリ マネージャー(RMAN)ディレクティブ BACKUP AS COPY により、データベース全体のすべてのデータファイルのイメージコピーが作成され、データファイル形式が保持されます。
- ASM と CRS API - Automatic Storage Management(ASM)と Cluster Ready Services(CRS)API を使用して、ASM バックアップ ディスク グループを管理します。
- RMAN アーカイブログ バックアップ API - この API は、アーカイブログを生成し、ステージング ディスクにバックアップして、本番環境のアーカイブの場所からパージします。
Oracle ホストを構成する
Oracle ホストの設定手順には、エージェントのインストール、バックアップと DR へのホストの追加、ホストの構成、Oracle データベースの検出などがあります。すべてを完了した後、バックアップと DR で Oracle データベースのバックアップを実行できます。
バックアップ エージェントをインストールする
バックアップと DR エージェントのインストールは比較的簡単です。エージェントは、ホストの初回使用時にのみインストールします。その後のアップグレードは、 Google Cloud コンソールのバックアップと DR のユーザー インターフェースから実行できます。エージェントのインストールを行うには、root ユーザーでログインするか、sudo 認証セッションに移動する必要があります。インストールを完了するためにホストを再起動する必要はありません。
ユーザー インターフェースまたは [管理] > [アプライアンス] ページからバックアップ エージェントをダウンロードします。
https://bmc-PROJECT_NUMBER-GENERATED_ID-dot-REGION.backupdr.googleusercontent.com/#clusters
バックアップ/リカバリ アプライアンスの名前を右クリックして、[Configure Appliance] を選択します。新しいブラウザ ウィンドウが開きます。
![バックアップと DR の管理コンソール ページ。[Configure Appliance] メニュー項目の選択方法を示しています。](https://cloud.google.com/static/bare-metal/docs/solutions/oracle/images/backup-and-dr-configure-appliance-2.png?hl=ja)
[Linux 64 Bit] アイコンをクリックして、ブラウザ セッションをホストするコンピュータにバックアップ エージェントをダウンロードします。scp(セキュアコピー)を使用して、ダウンロードしたエージェント ファイルを Oracle ホストに移動してインストールします。
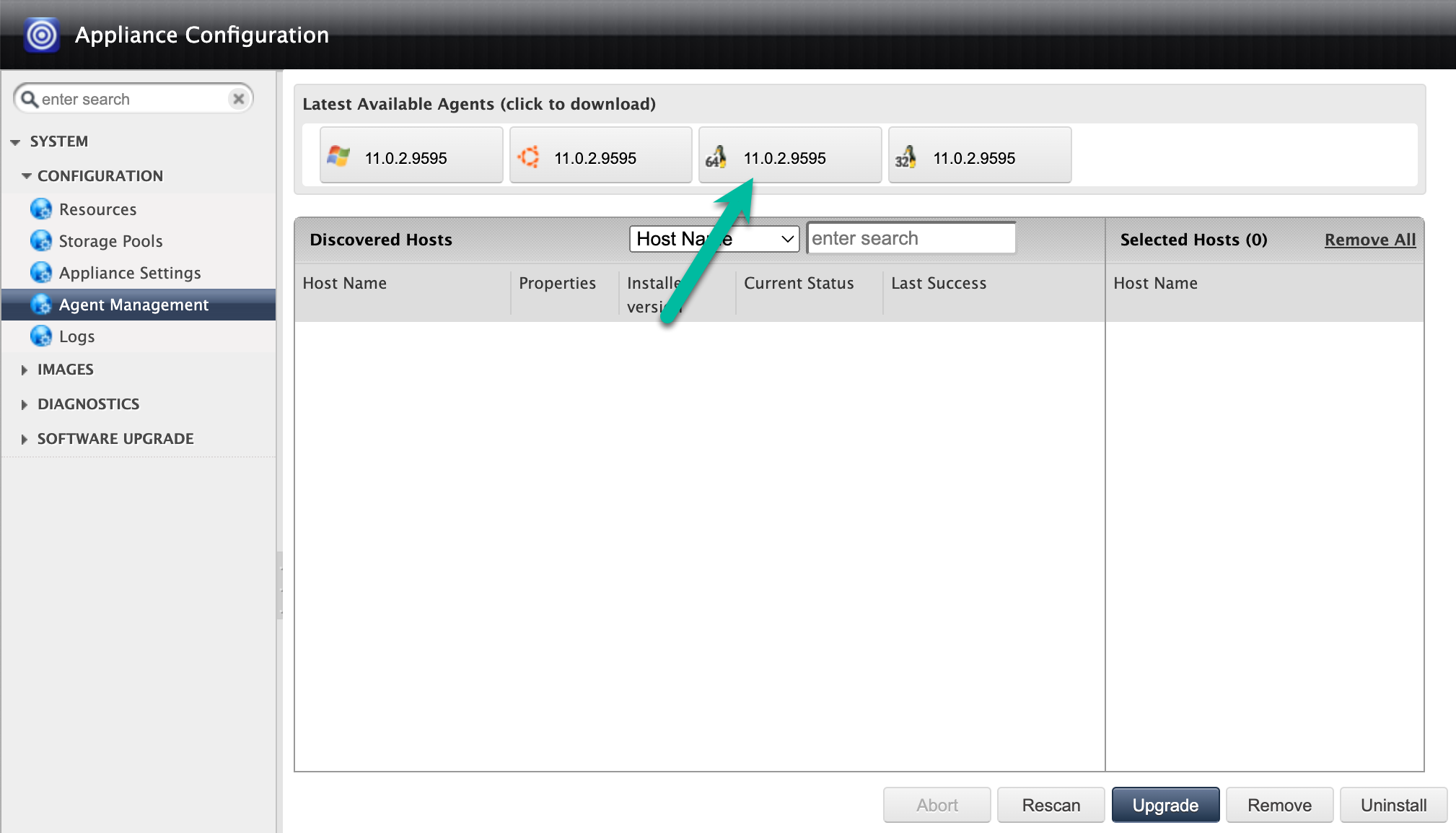
また、バックアップ エージェントを Cloud Storage バケットに保存して、ダウンロードを有効にし、
wgetまたはcurlコマンドで Linux ホストにエージェントを直接ダウンロードすることもできます。curl -o agent-Linux-latestversion.rpm https://storage.googleapis.com/backup-agent-images/connector-Linux-11.0.2.9595.rpm
rpm -ivhコマンドを使用してバックアップ エージェントをインストールします。自動生成された秘密鍵をコピーすることは非常に重要です。バックアップと DR の管理コンソールを使用して、秘密鍵をホスト メタデータに追加する必要があります。
コマンドの出力は、次のようになります。
[oracle@host `~]# sudo rpm -ivh agent-Linux-latestversion.rpm Verifying... ################################# [100%] Preparing... ################################# [100%] Updating / installing… 1:udsagent-11.0.2-9595 ################################# [100%] Created symlink /etc/systemd/system/multi-user.target.wants/udsagent.service → /usr/lib/systemd/system/udsagent.service. Action Required: -- Add this host to Backup and DR management console to backup/recover workloads from/to this host. You can do this by navigating to Manage->Hosts->Add Host on your management console. -- A secret key is required to complete this process. Please use b010502a8f383cae5a076d4ac9e868777657cebd0000000063abee83 (valid for 2 hrs) to register this host. -- A new secret key can be generated later by running: '/opt/act/bin/udsagent secret --reset --restart
iptablesコマンドを使用する場合は、バックアップ エージェント ファイアウォール(TCP 5106)と Oracle サービス(TCP 1521)のポートを開きます。sudo iptables -A INPUT -p tcp --dport 5106 -j ACCEPT sudo iptables -A INPUT -p tcp --dport 1521 -j ACCEPT sudo firewall-cmd --permanent --add-port=5106/tcp sudo firewall-cmd --permanent --add-port=1521/tcp sudo firewall-cmd --reload
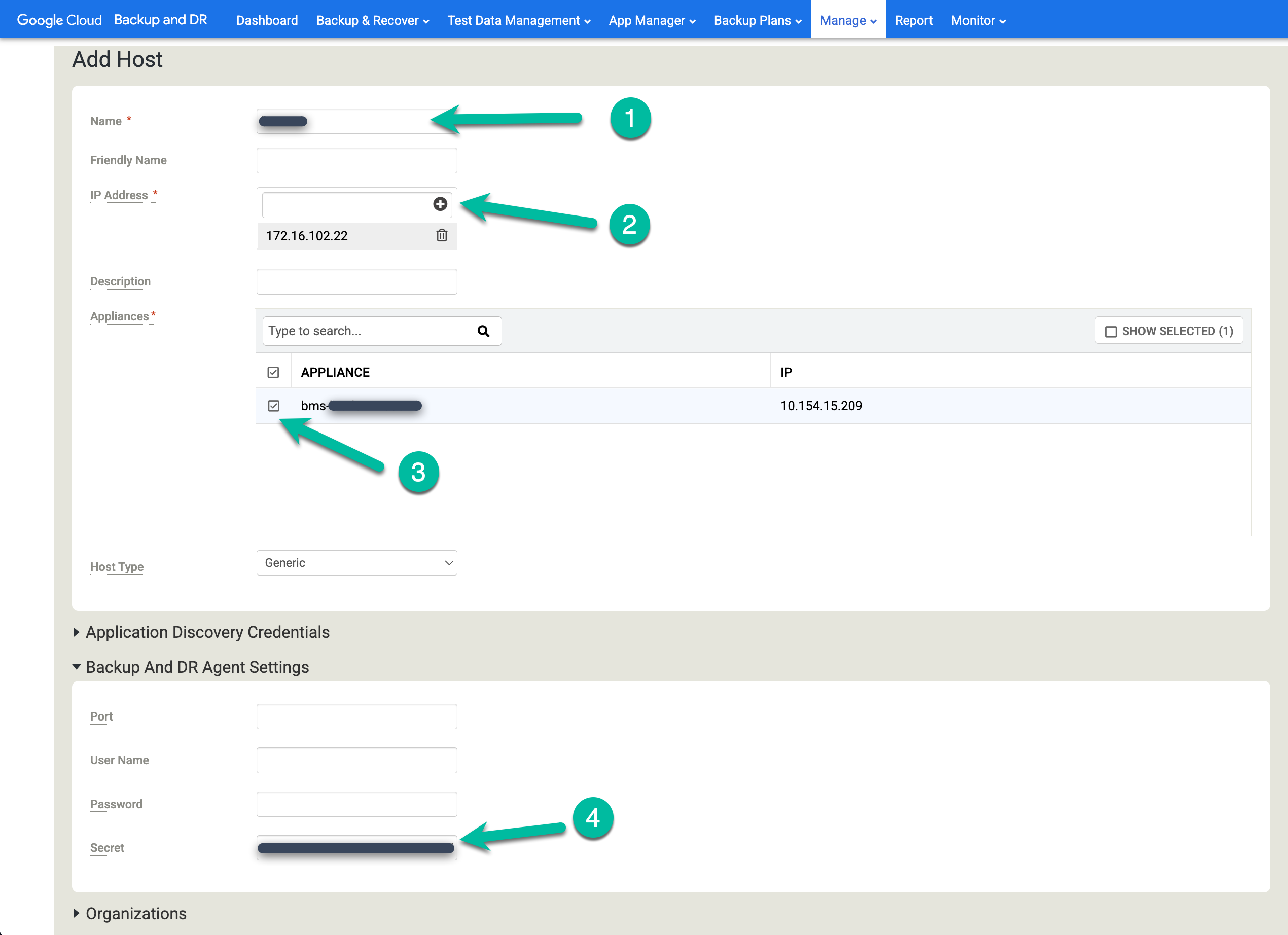
バックアップと DR にホストを追加する
バックアップと DR の管理コンソールで、[管理] > [ホスト] に移動します。
https://bmc-PROJECT_NUMBER-GENERATED_ID-dot-REGION.backupdr.googleusercontent.com/#hosts
- [+ ホストを追加] をクリックします。
- ホスト名を追加します。
- ホストの IP アドレスを追加し、[+] ボタンをクリックして構成を確認します。
- ホストを追加するアプライアンスをクリックします。
- 秘密鍵を貼り付けます。このタスクは、バックアップ エージェントをインストールして秘密鍵が生成されてから 2 時間以内に行う必要があります。
[追加] をクリックしてホストを保存します。
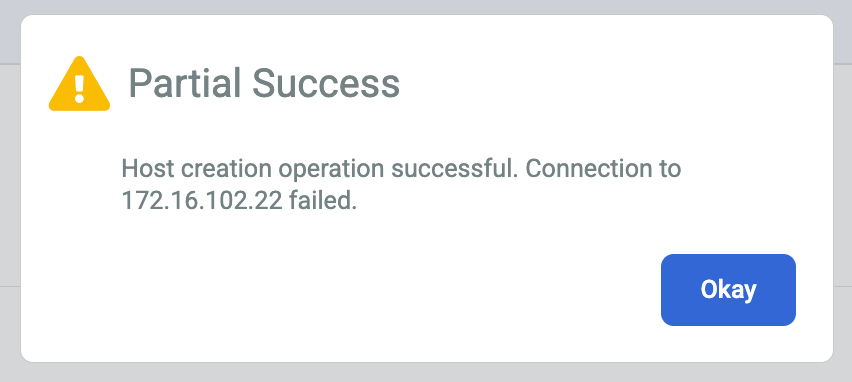
エラーまたは「部分的に成功」というメッセージが表示された場合は、次の回避策をお試しください。
バックアップ エージェント暗号化の秘密鍵がタイムアウトした可能性があります。秘密鍵をホストから 2 時間以内に追加しなかった場合に発生します。次のコマンドライン構文を使用して、Linux ホストで新しい秘密鍵を生成できます。
/opt/act/bin/udsagent secret --reset --restart
バックアップ/リカバリ アプライアンスとホストにインストールされているエージェント間の通信を許可するファイアウォールが正しく構成されていない可能性があります。手順に沿って、バックアップ エージェント ファイアウォールと Oracle サービスのポートを開きます。
Linux ホストのネットワーク タイム プロトコル(ntp)が正しく構成されていない可能性があります。NTP の設定が正しいことを確認します。
根本的な問題を修正すると、[証明書のステータス] が「なし」から「有効」に変わります。

ホストを構成する
バックアップと DR の管理コンソールで、[管理] > [ホスト] に移動します。
https://bmc-PROJECT_NUMBER-GENERATED_ID-dot-REGION.backupdr.googleusercontent.com/#hosts
Oracle データベースをバックアップする Linux ホストを右クリックし、[編集] を選択します。
[Staging Disk Format] をクリックし、[NFS] を選択します。
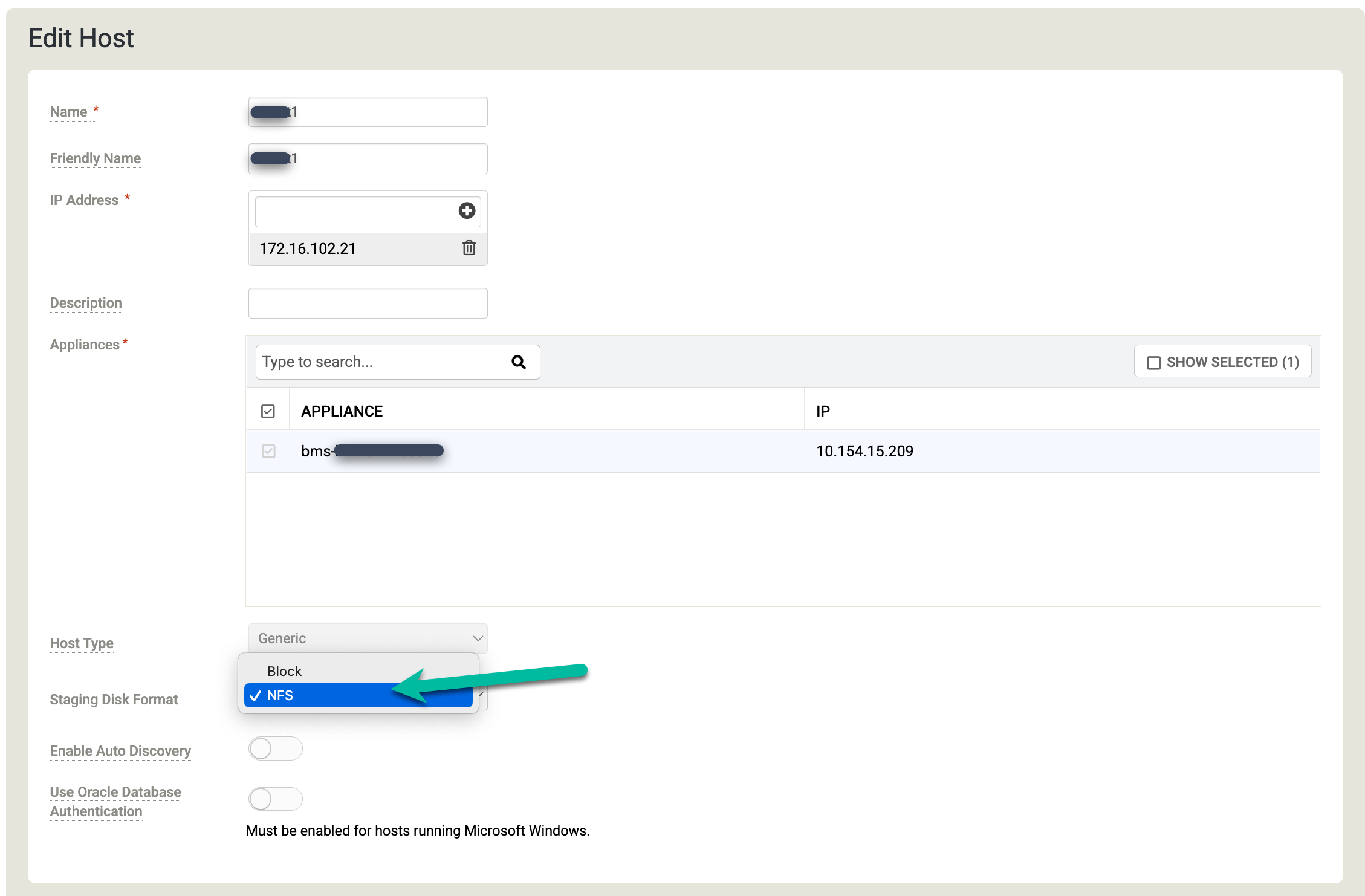
[Discovered Applications] セクションまで下にスクロールし、[Discover Applications] をクリックして、アプライアンスからエージェントへの検出プロセスを開始します。
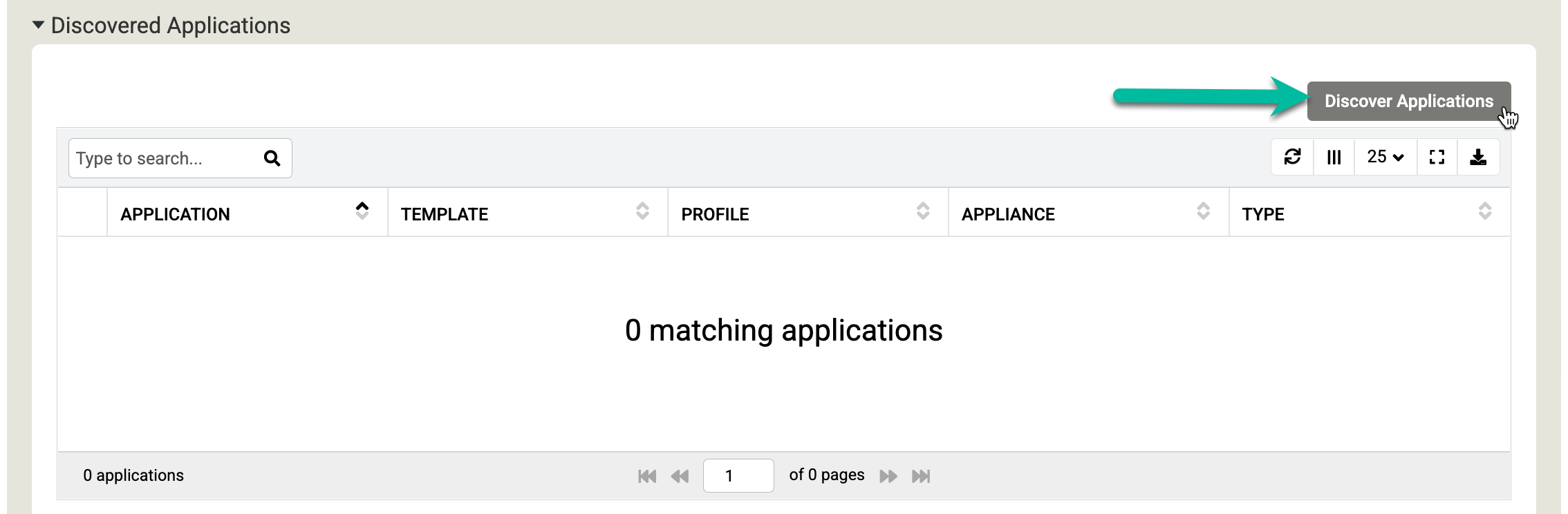
[検出] をクリックしてプロセスを開始します。検出プロセスには最大 5 分かかります。完了すると、検出されたファイル システムと Oracle データベースがアプリケーション ウィンドウに表示されます。
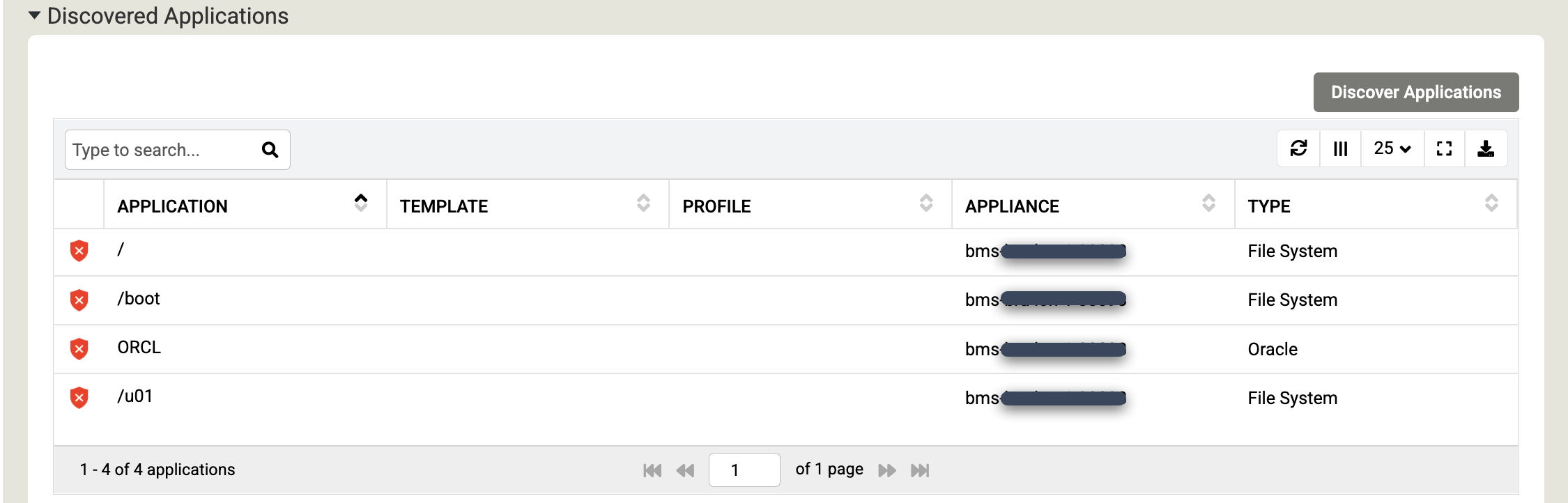
[保存] をクリックして、ホストの変更を更新します。
Linux ホストを準備する
Linux OS ベースのホストに iSCSI または NFS ユーティリティ パッケージをインストールすることで、バックアップ データを書き込むデバイスにステージング ディスクをマッピングできます。iSCSI ユーティリティと NFS ユーティリティをインストールするには、次のコマンドを使用します。一方または両方のユーティリティを使用できますが、この手順を行うと、必要なときに必要な情報を取得できます。
iSCSI ユーティリティをインストールするには、次のコマンドを実行します。
sudo yum install -y iscsi-initiator-utils
NFS ユーティリティをインストールするには、次のコマンドを実行します。
sudo yum install -y nfs-utils
Oracle データベースを準備する
このガイドでは、Oracle インスタンスとデータベースがすでに設定、構成されていることを前提としています。 Google Cloud Backup and DR は、ファイル システム、ASM、Real Application Clusters(RAC)、その他の多くの構成で実行されているデータベースの保護をサポートしています。詳細については、Oracle データベースのバックアップと DR をご覧ください。
バックアップ ジョブを開始する前に、いくつかの項目を構成する必要があります。一部のタスクは省略可能ですが、最適なパフォーマンスを得るため、次の設定を行うことをおすすめします。
- SSH を使用して Linux ホストに接続し、su 権限のある Oracle ユーザーとしてログインします。
Oracle 環境を特定のインスタンスに設定します。
. oraenv ORACLE_SID = [ORCL] ? The Oracle base remains unchanged with value /u01/app/oracle
sysdbaアカウントを使用して SQL*Plus に接続します。sqlplus / as sysdba
次のコマンドを使用して、ARCHIVELOG モードを有効にします。コマンドの出力は次のようになります。
SQL> shutdown Database closed. Database dismounted. ORACLE instance shut down. SQL> startup mount ORACLE instance started. Total System Global Area 2415918600 bytes Fixed Size 9137672 bytes Variable Size 637534208 bytes Database Buffers 1761607680 bytes Redo Buffers 7639040 bytes Database mounted. SQL> alter database archivelog; Database altered. SQL> alter database open; Database altered. SQL> archive log list; Database log mode Archive Mode Automatic archival Enabled Archive destination /u01/app/oracle/product/19c/dbhome_1/dbs/arch Oldest online log sequence 20 Next log sequence to archive 22 Current log sequence 22 SQL> alter pluggable database ORCLPDB save state; Pluggable database altered.
Linux ホストの Direct NFS を構成します。
cd $ORACLE_HOME/rdbms/lib make -f [ins_rdbms.mk](http://ins_rdbms.mk/) dnfs_on
ブロック変更のトラッキングを構成します。まず、この機能が有効かどうかを確認します。次の例では、ブロック変更のトラッキングが無効になっています。
SQL> select status,filename from v$block_change_tracking; STATUS FILENAME ---------- ------------------------------------------------------------------ DISABLED
SQL> alter database enable block change tracking using file +ASM_DISK_GROUP_NAME/DATABASE_NAME/DBNAME.bct; Database altered.
ファイル システムを使用する場合は、次のコマンドを実行します。
SQL> alter database enable block change tracking using file '$ORACLE_HOME/dbs/DBNAME.bct';; Database altered.
ブロックの変更のトラッキングが有効になっていることを確認します。
SQL> select status,filename from v$block_change_tracking; STATUS FILENAME ---------- ------------------------------------------------------------------ ENABLED +DATADG/ORCL/CHANGETRACKING/ctf.276.1124639617
Oracle データベースを保護する
バックアップと DR の管理コンソールで、[App Manager] > [アプリケーション] ページに移動します。
https://bmc-PROJECT_NUMBER-GENERATED_ID-dot-REGION.backupdr.googleusercontent.com/#applications
保護する Oracle データベース名を右クリックし、メニューから [Manage Backup Plan] を選択します。
使用するテンプレートとプロファイルを選択し、[Apply Backup Plan] をクリックします。
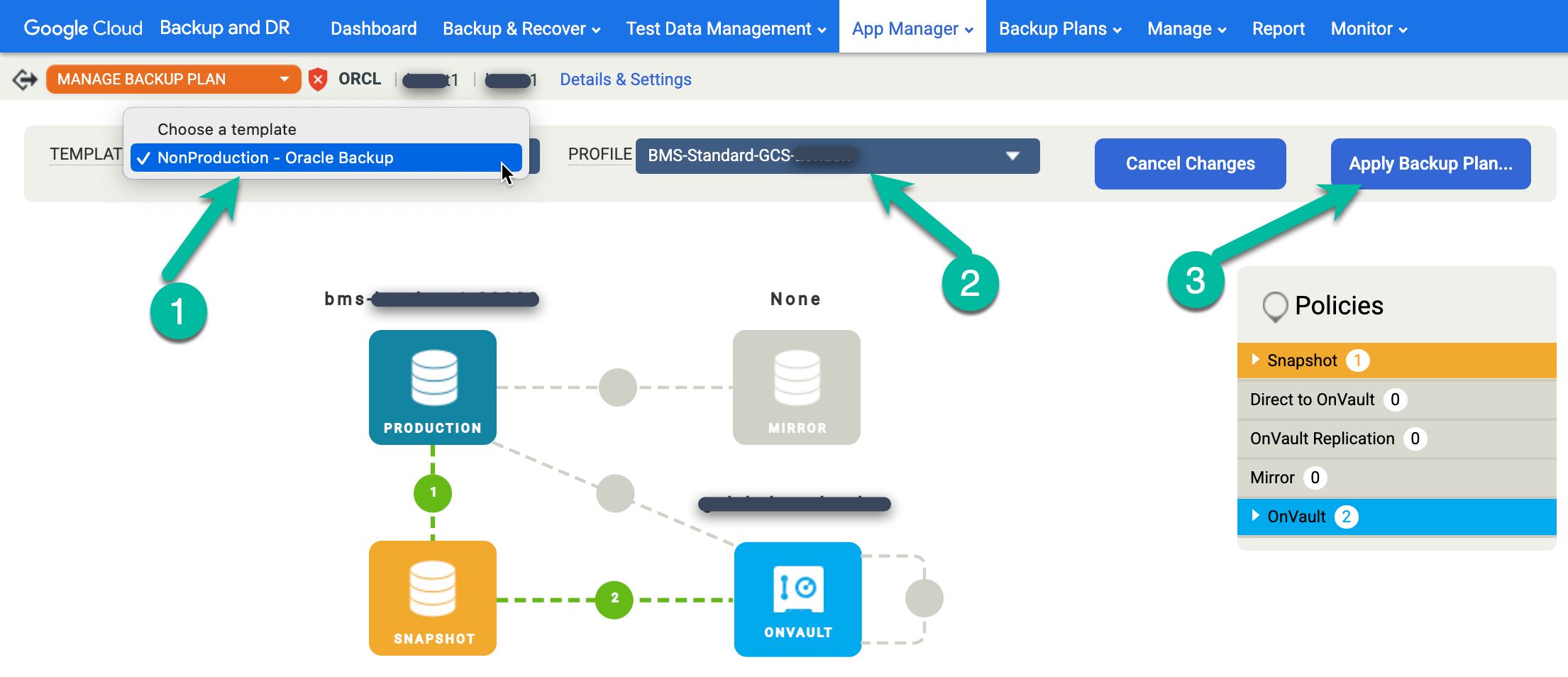
プロンプトが表示されたら、Oracle と RMAN に固有の構成に必要な詳細設定を行います。完了したら、[バックアップ プランを適用] をクリックします。
たとえば、チャネル数のデフォルトは 2 です。そのため、CPU コアの数が多い場合は、並列バックアップ オペレーションのチャネル数を増やすと、より大きな値に設定できます。
詳細設定について詳しくは、Oracle データベースのアプリケーションの詳細と設定を構成するをご覧ください。
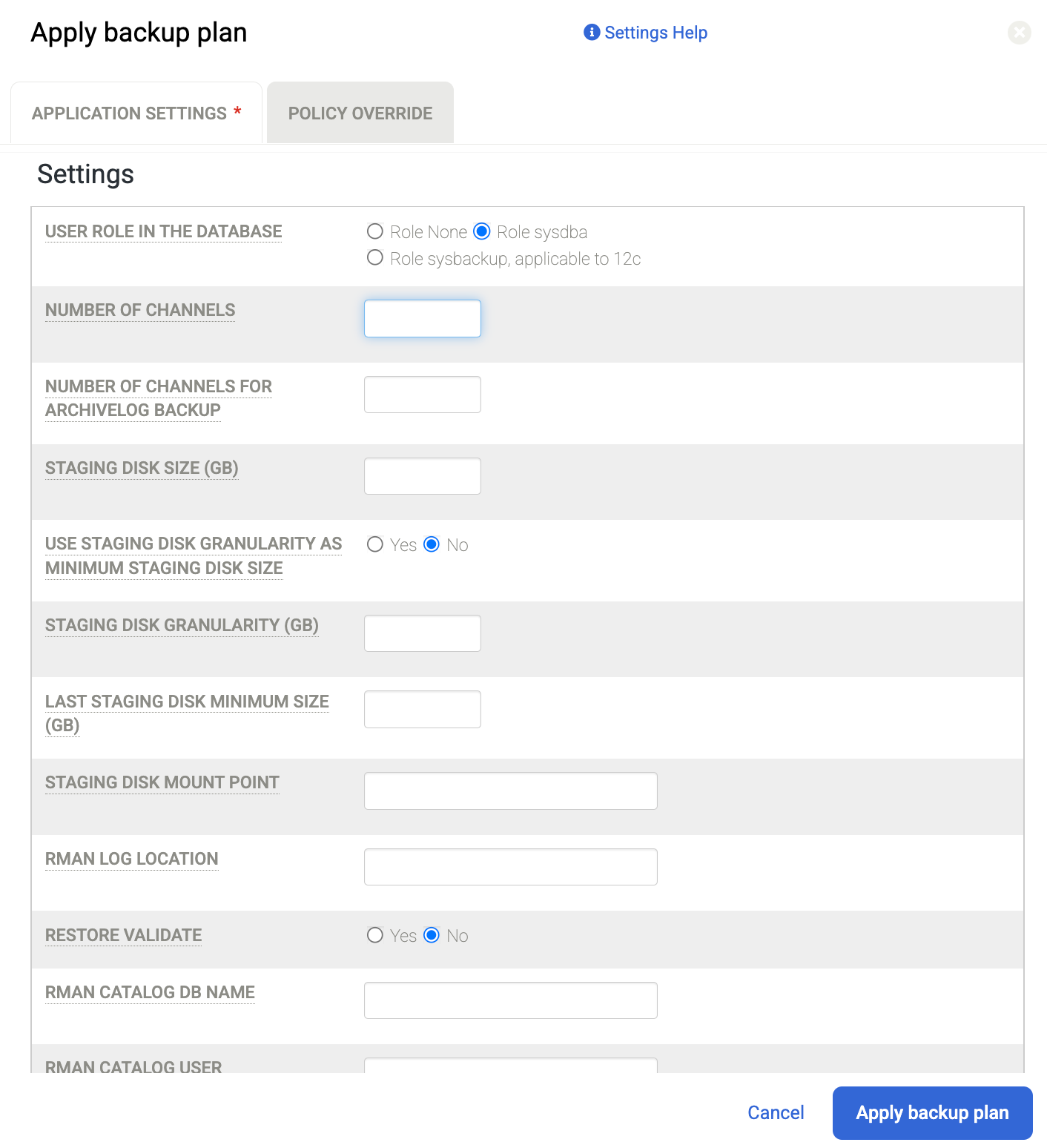
これらの設定に加えて、ステージング ディスクがバックアップ アプライアンスからホストにディスクをマッピングする際に使用するプロトコルを変更できます。[管理] > [ホスト] ページに移動し、編集するホストを選択します。[Staging Disk Format to Guest] のオプションをオンにします。デフォルトでは、[ブロック] 形式が選択されています。これは、iSCSI 経由でステージング ディスクをマッピングします。それ以外の場合は、[NFS] に変更すると、ステージング ディスクは NFS プロトコルを使用します。
デフォルトの設定はデータベースの形式によって異なります。ASM を使用する場合、システムは iSCSI を使用してバックアップの ASM ディスク グループを送信します。ファイル システムを使用する場合、バックアップは iSCSI を使用してファイル システムに送信されます。NFS または直接 NFS(dNFS)を使用する場合は、ステージング ディスクのホスト設定を NFS に変更する必要があります。デフォルトの設定を使用する場合、すべてのバックアップ ステージング ディスクはブロック ストレージ形式と iSCSI を使用します。
バックアップ ジョブを開始する
バックアップと DR の管理コンソールで、[App Manager] > [アプリケーション] ページに移動します。
https://bmc-PROJECT_NUMBER-GENERATED_ID-dot-REGION.backupdr.googleusercontent.com/#applications
保護する Oracle データベースを右クリックし、メニューから [Manage Backup Plan] を選択します。
右側の [スナップショット] メニューをクリックし、[今すぐ実行] をクリックします。これにより、オンデマンド バックアップ ジョブが開始されます。
![バックアップと DR の管理コンソール ページ。[スナップショット] メニューをクリックしてスナップショットをキャプチャする方法を示しています。](https://cloud.google.com/static/bare-metal/docs/solutions/oracle/images/backup-and-dr-snapshot.png?hl=ja)
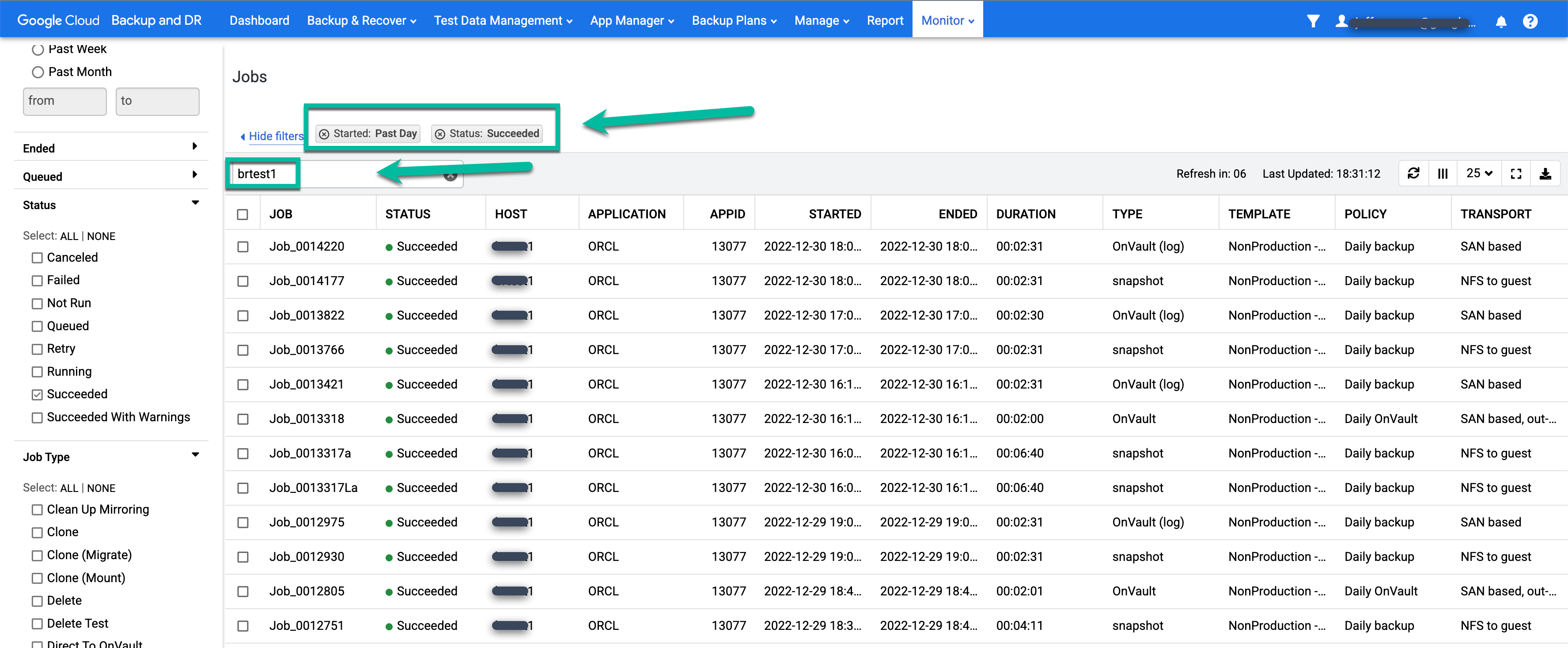
バックアップ ジョブのステータスをモニタリングするには、[監視] > [ジョブ] メニューに移動してジョブ ステータスを表示します。ジョブがジョブリストに表示されるまで 5~10 秒ほどかかることがあります。実行中のジョブの例を次に示します。

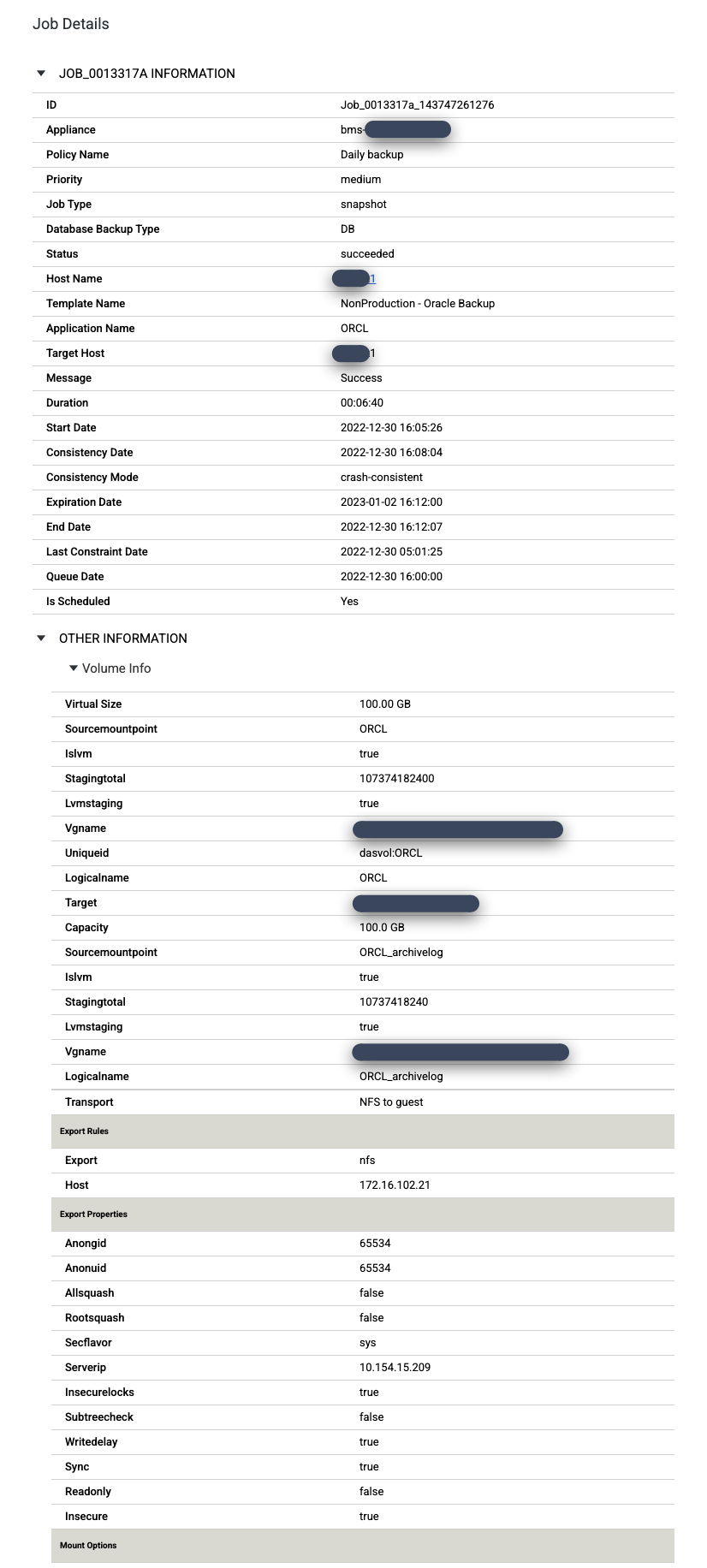
ジョブが成功した場合、メタデータを使用して特定のジョブの詳細を表示できます。
- フィルタを適用し、検索キーワードを追加して、目的のジョブを見つけます。次の例では、「成功」フィルタと「24 時間以内」フィルタを使用し、test1 ホストを検索します。
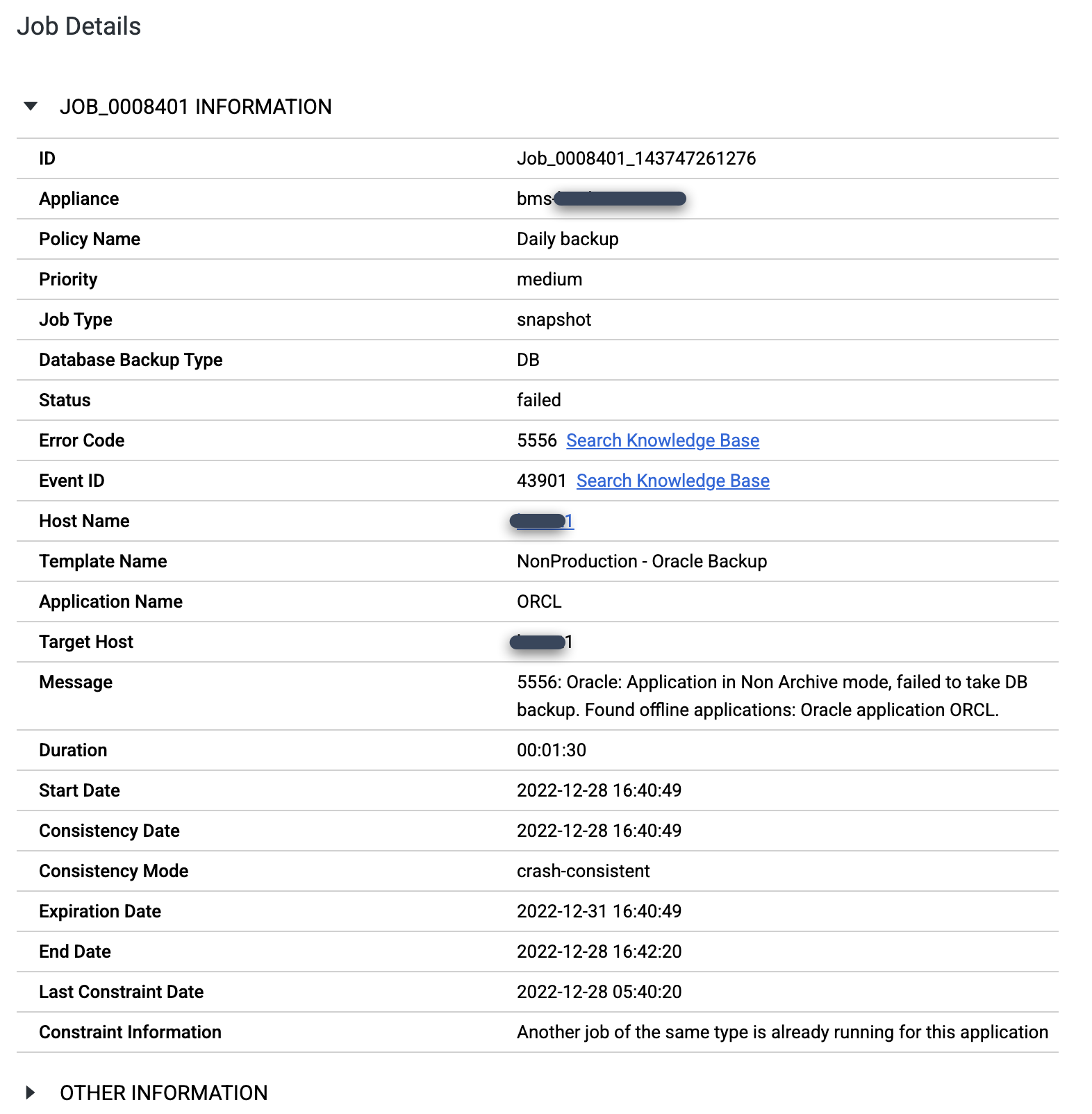
特定のジョブを詳しく調べるには、[ジョブ] 列のジョブをクリックします。新しいウィンドウが開きます。次の例に示すように、各バックアップ ジョブは大量の情報をキャプチャします。
Oracle データベースのマウントと復元
Google Cloud バックアップと DR には、Oracle データベースのコピーにアクセスするためのさまざまな機能があります。主な方法は次の 2 つです。
- アプリ対応のマウント
- 復元(マウントと移行、従来の復元)
これらの方法にはそれぞれ異なる利点があるため、ユースケース、パフォーマンス要件、データベース コピーの保持期間に応じて、使用する方法を選択する必要があります。以下のセクションでは、各機能の推奨事項を示します。
アプリ対応のマウント
マウントを使用すると、Oracle データベースの仮想コピーにすばやくアクセスできます。パフォーマンスが重要ではなく、データベース コピーの有効期間が数時間から数日間の場合は、マウントを構成できます。
マウントの主なメリットは、追加のストレージを大量に消費しないことです。マウントはバックアップ ディスク プールのスナップショットを使用します。バックアップ プールは、永続ディスクのスナップショット プールまたは Cloud Storage の OnVault プールです。仮想コピー スナップショット機能を使用すると、データを最初にコピーする必要がないため、データへのアクセス時間を最小限に抑えることができます。バックアップ ディスクはすべての読み取りを処理し、スナップショット プール内のディスクはすべての書き込みを保存します。その結果、仮想コピーのマウントは迅速にアクセスできます。また、バックアップ ディスクのコピーは上書きされません。マウントは、本番環境に移行する前にスキーマの変更や更新を検証する必要がある開発、テスト、DBA アクティビティに最適です。
Oracle データベースをマウントする
バックアップと DR の管理コンソールで、[Backup and Recover] > [復元] ページに移動します。
https://bmc-PROJECT_NUMBER-GENERATED_ID-dot-REGION.backupdr.googleusercontent.com/#recover/selectapp
[アプリケーション] リストで、マウントするデータベースを見つけて、データベース名を右クリックし、[次へ] をクリックします。
![バックアップと DR の管理コンソール ページ。[Backup and Recover] ページでデータベースを見つける方法を示しています。](https://cloud.google.com/static/bare-metal/docs/solutions/oracle/images/backup-and-dr-find-database.png?hl=ja)
[Timeline Ramp View] が表示され、使用可能なすべてのポイントインタイム イメージが表示されます。長期保存のイメージがランプビューに表示されない場合は、前にスクロールして表示します。デフォルトでは、常に最新のイメージが選択されます。
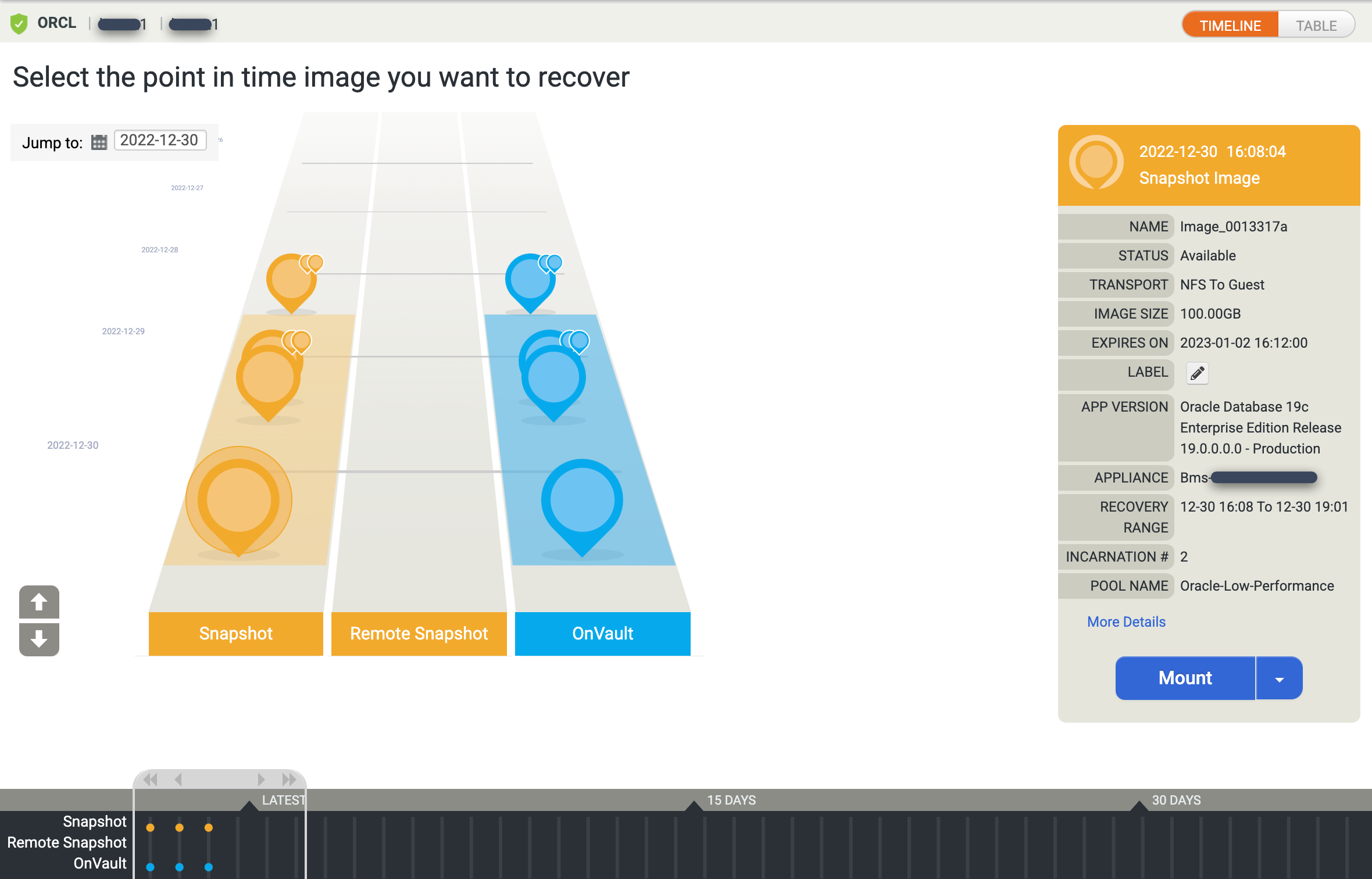
ポイントインタイム イメージのテーブルビューを表示するには、[テーブル] オプションをクリックしてビューを変更します。
![バックアップと DR の管理コンソール ページ。[テーブル] タブをクリックしてポイントインタイム バックアップ イメージをテーブルに表示する方法が表示されています。](https://cloud.google.com/static/bare-metal/docs/solutions/oracle/images/backup-and-dr-table-view.png?hl=ja)
目的のイメージを見つけて、[マウント] を選択します。
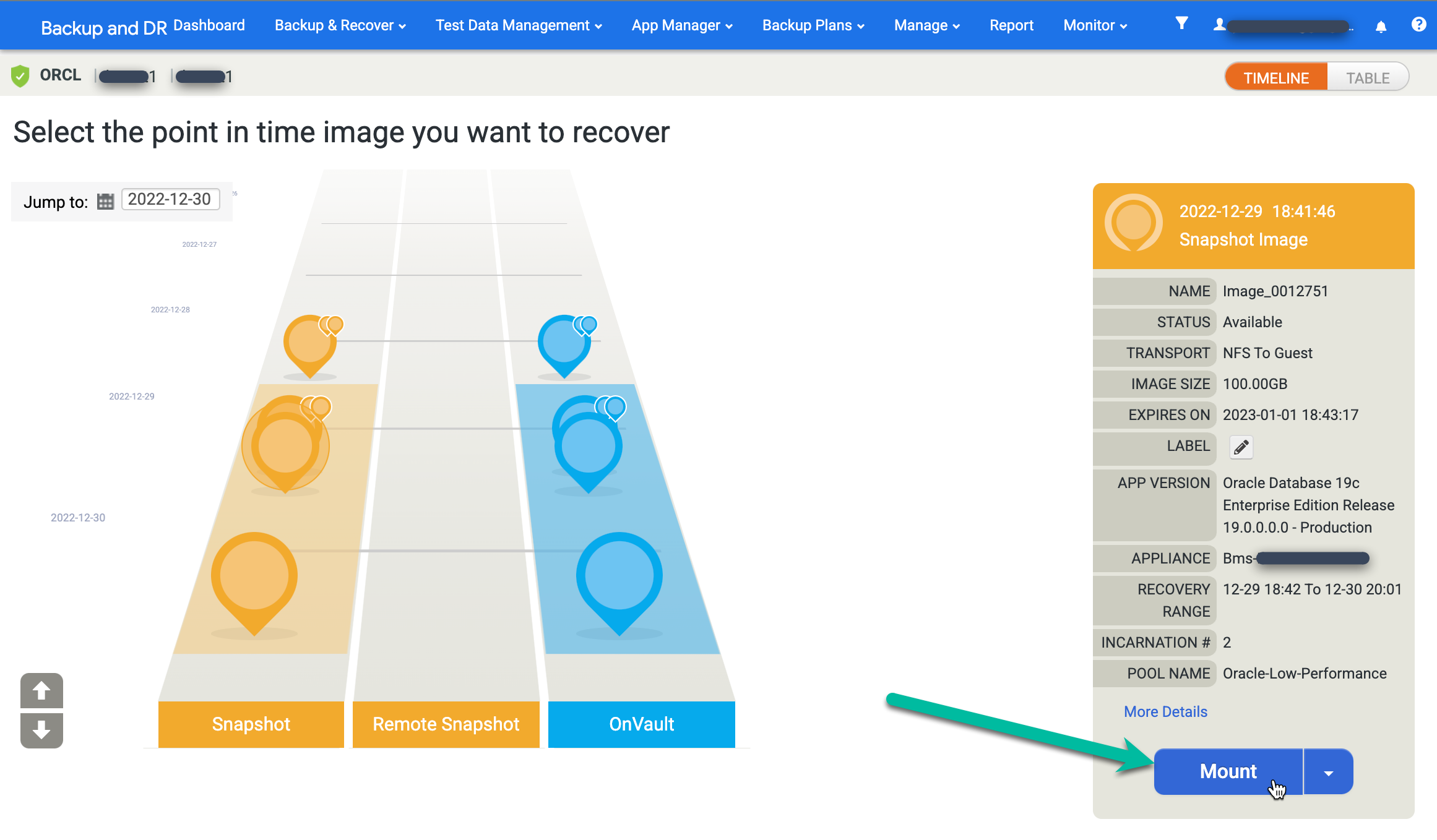
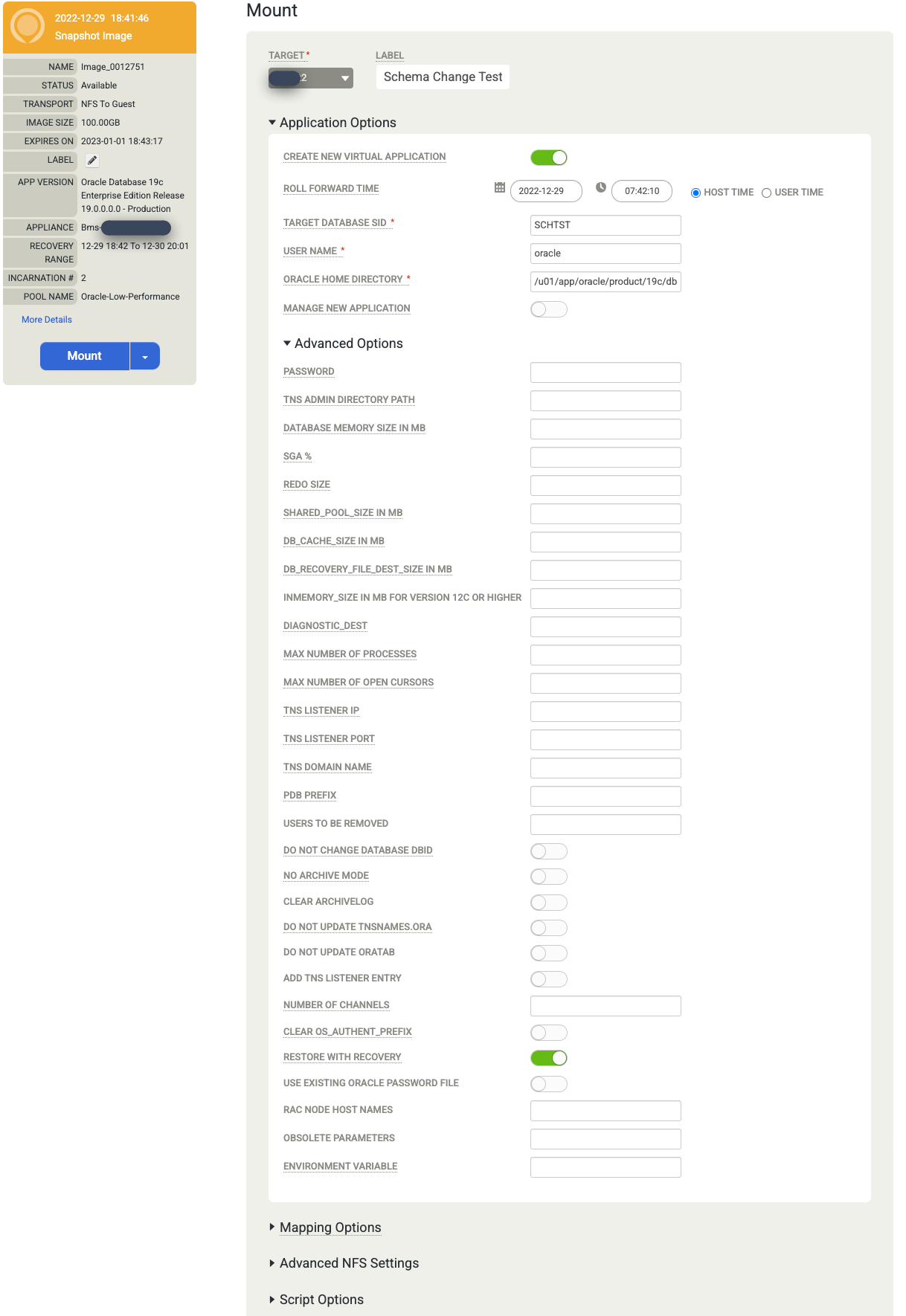
マウントするデータベースの [Application Options] を選択します。
- プルダウン メニューからターゲット ホストを選択します。以前に追加したホストは、このリストに表示されます。
- (省略可)ラベルを入力します。
- [Target Database SID] フィールドに、ターゲット データベースの識別子を入力します。
- ユーザー名を oracle に設定します。この名前が認証の OS ユーザー名になります。
- Oracle ホーム ディレクトリを入力します。この例では、
/u01/app/oracle/product/19c/dbhome_1を使用します。 - データベース ログをバックアップするように構成すると、[Roll Forward Time] が使用可能になります。クロック/タイムセレクタをクリックし、ロール フォワード ポイントを選択します。
- デフォルトでは [Restore with Recovery] が有効になっています。このオプションは、データベースをマウントして開きます。
情報の入力が完了したら、[送信] をクリックしてマウント プロセスを開始します。
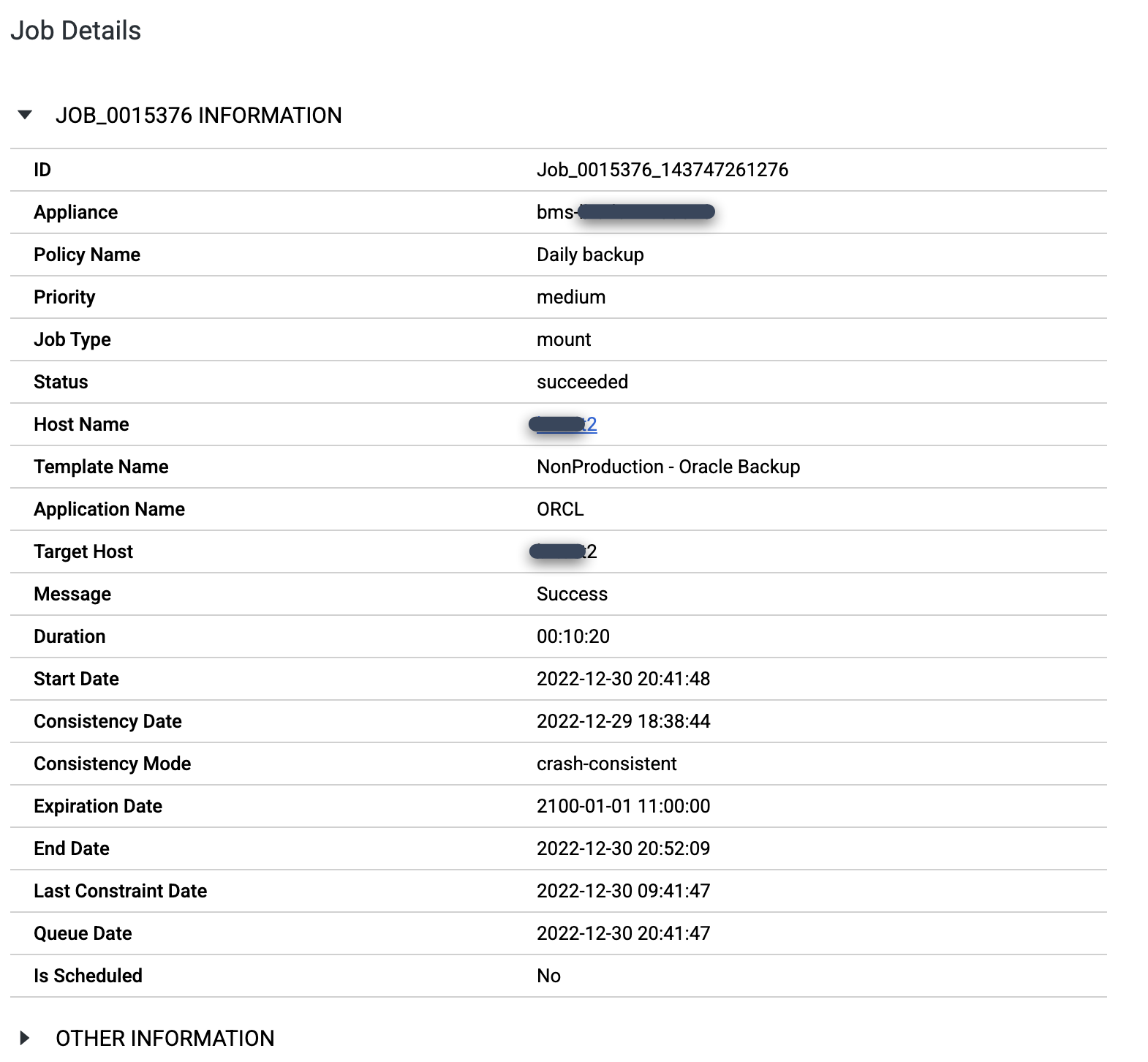
ジョブの進捗と成功をモニタリングする
実行中のジョブをモニタリングするには、[監視] > [ジョブ] ページに移動します。
https://bmc-PROJECT_NUMBER-GENERATED_ID-dot-REGION.backupdr.googleusercontent.com/#jobs
このページには、ステータスとジョブの種類が表示されます。
![[監視] > [ジョブ] ページを示すバックアップと DR の管理コンソール ページ。](/static/bare-metal/docs/solutions/oracle/images/backup-and-dr-monitor-jobs.png)
マウントジョブが完了したら、[Job Number] をクリックして、ジョブの詳細を表示できます。
作成した SID の pmon プロセスを表示するには、ターゲット ホストにログインして
ps -ef |grep pmonコマンドを実行します。次の出力例では、SCHTEST データベースは稼働しており、プロセス ID は 173953 です。[root@test2 ~]# ps -ef |grep pmon oracle 1382 1 0 Dec23 ? 00:00:28 asm_pmon_+ASM oracle 56889 1 0 Dec29 ? 00:00:06 ora_pmon_ORCL oracle 173953 1 0 09:51 ? 00:00:00 ora_pmon_SCHTEST root 178934 169484 0 10:07 pts/0 00:00:00 grep --color=auto pmon
Oracle データベースのマウントを解除する
データベースの使用が終了したら、データベースのマウントを解除して削除する必要があります。マウントされたデータベースを見つける方法は 2 つあります。
[App Manager] > [Active Mounts] ページに移動します。
https://bmc-PROJECT_NUMBER-GENERATED_ID-dot-REGION.backupdr.googleusercontent.com/#activemounts
このページには、現在使用中でマウントされたアプリケーション(ファイル システムとデータベース)のグローバル ビューが表示されます。
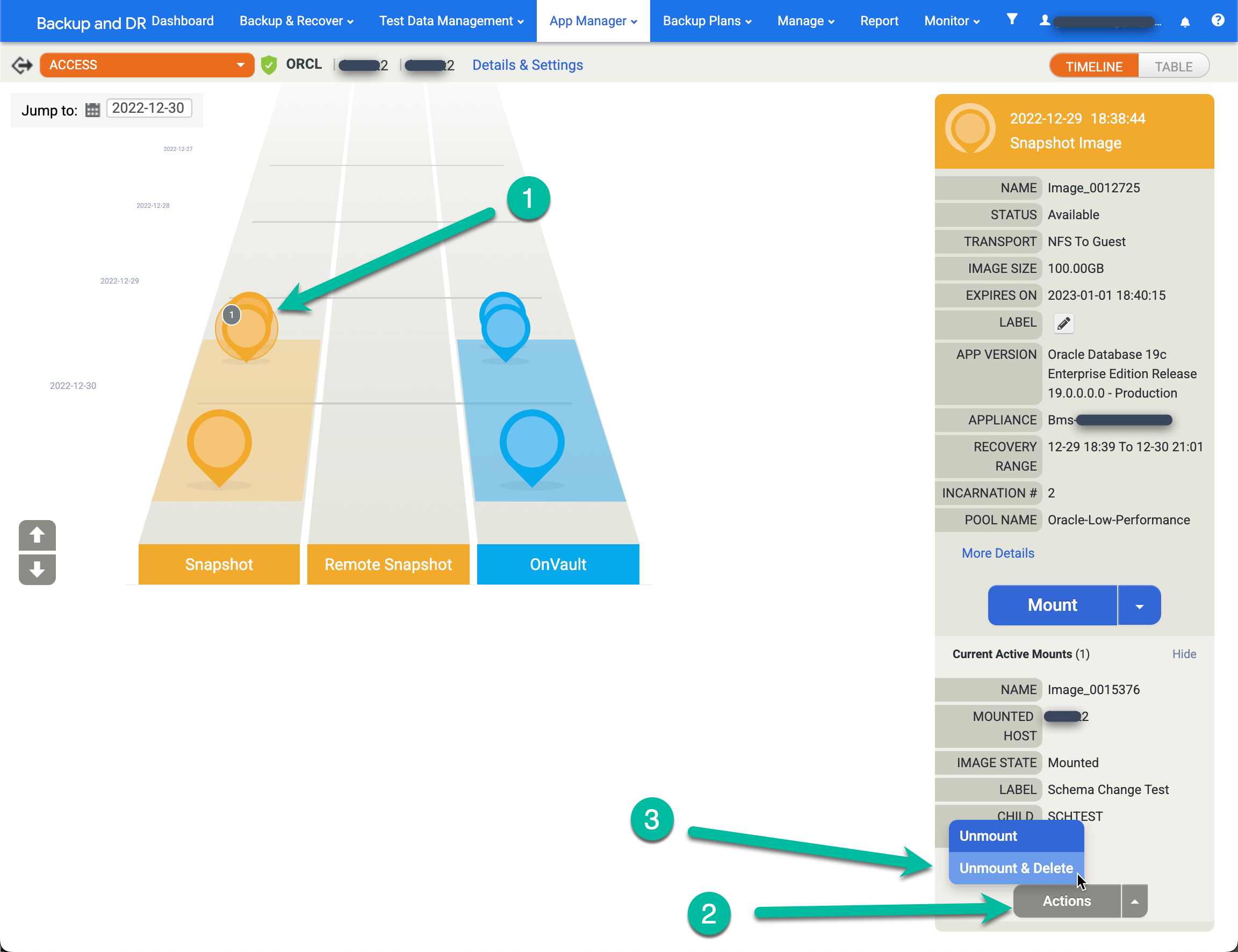
クリーンアップするマウントを右クリックし、メニューから [Unmount and Delete] を選択します。この操作でバックアップ データは削除されません。ターゲット ホストと、データベース用に保存されている書き込みを含むスナップショット キャッシュ ディスクから、仮想マウントされたデータベースのみを削除します。
![バックアップと DR の管理コンソール ページ。[App Manager ] の [Active Mounts] ページにある [Unmount and Delete ] メニューが表示されています。](https://cloud.google.com/static/bare-metal/docs/solutions/oracle/images/backup-and-dr-unmount-and-delete.png?hl=ja)
[App Manager] > [アプリケーション] ページに移動します。
https://bmc-PROJECT_NUMBER-GENERATED_ID-dot-REGION.backupdr.googleusercontent.com/#applications
- ソースアプリ(データベース)を右クリックして、[アクセス] を選択します。
- 左側のランプに、灰色の円が表示されます。円の中の数字は、この時点からのアクティブなマウントの数を示しています。そのイメージをクリックすると、新しいメニューが表示されます。
- [操作] をクリックします。
- [Unmount and Delete] をクリックします。
- [送信] をクリックし、次の画面でこの操作を確定します。
数分後、ターゲット ホストからデータベースが削除され、すべてのディスクがクリーンアップされて削除されます。この操作を行うと、アクティブなマウントの REDO ディスクへの書き込みに使用されているスナップショット プール内のディスク容量が解放されます。
マウントされていないジョブは、他のジョブと同じようにモニタリングできます。[監視] > [ジョブ] メニューに移動して、マウント解除されたジョブの進行状況をモニタリングし、ジョブが完了したことを確認します。
https://bmc-PROJECT_NUMBER-GENERATED_ID-dot-REGION.backupdr.googleusercontent.com/#jobs
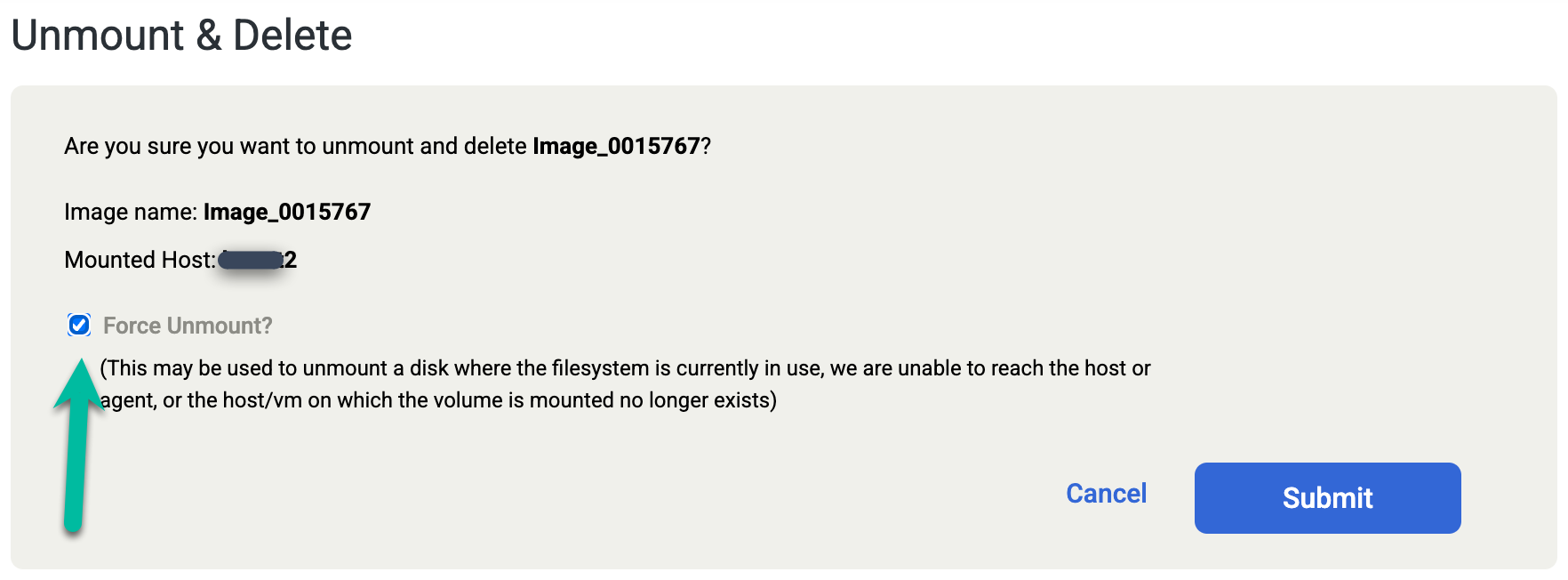
誤って Oracle データベースを手動で削除した場合、または [Unmount and Delete] ジョブを実行する前にデータベースをシャットダウンした場合は、[Unmount and Delete] ジョブを再度実行し、確認画面で [Force Unmount] オプションを選択します。この操作により、REDO ステージング ディスクがターゲット ホストから強制的に削除され、スナップショット プールからディスクが削除されます。
復元
問題や破損が発生し、バックアップ ファイルからローカルホストにデータベースのすべてのファイルをコピーする必要がある場合は、復元を使用して本番環境データベースを復元します。復元は通常、障害タイプのイベントの後に行うか、非本番環境のテストコピーで行います。通常、そのような場合は、以前のファイルがソースホストにコピーされてからデータベースを再起動する必要があります。ただし、 Google Cloud バックアップと DR では、復元機能(ファイルのコピーとデータベースの開始)だけでなく、マウントと移行の機能もサポートしています。この機能では、データベースをマウントするので(アクセスまでの時間が短くなります)、データベースがマウントされてアクセス可能になっている間にデータファイルをローカルマシンにコピーできます。マウントと移行機能は、目標復旧時間(RTO)が低い場合に有用です。
マウントと移行
マウントと移行ベースの復元には 2 つのフェーズがあります。
- フェーズ 1 - 復元マウント フェーズでは、マウントされたコピーからすぐにデータベースにアクセスできます。
- フェーズ 2 - 復元移行フェーズでは、データベースがオンラインである間に、本番環境のストレージの場所にデータベースを移行します。
復元マウント - フェーズ 1
このフェーズでは、バックアップ/リカバリ アプライアンスによって提供される特定のイメージからデータベースに即座にアクセスできます。
- 選択したバックアップ イメージのコピーがターゲット データベース サーバーにマッピングされ、ソース データベースのバックアップ形式に基づいて ASM またはファイル システム レイヤに提示されます。
- RMAN API を使用して、次のタスクを行います。
- 制御ファイルと REDO ログファイルを指定のローカル制御ファイルに復元し、ファイルを ASM ディスク グループまたはファイル システムに再配置します。
- データベースを、バックアップ/リカバリ アプライアンスによって提示されたイメージのコピーに切り替えます。
- 使用可能なすべてのアーカイブログを指定のリカバリ ポイントにロール フォワードします。
- データベースを読み取り / 書き込みモードで開きます。
- データベースが、バックアップ/リカバリ アプライアンスによって提供されるバックアップ イメージのマッピングされたコピーから実行されます。
- データベースの制御ファイルと REDO ログファイルは、ターゲットで選択したローカル本番環境ストレージの場所(ASM ディスク グループまたはファイル システム)に配置されます。
- 復元マウント オペレーションが正常に完了すると、データベースを本番環境オペレーションで使用できるようになります。Oracle オンライン データファイル移動 API を使用すると、データベースとアプリケーションの稼働中にデータを本番環境のストレージの場所(ASM ディスク グループまたはファイル システム)に戻すことができます。
復元移行 - フェーズ 2
データベースのデータファイルを本番環境のストレージにオンラインで移動します。
- データの移行はバックグラウンドで実行されます。Oracle オンライン データファイル移動 API を使用してデータを移行します。
- バックアップと DR によって提示されたバックアップ イメージのコピーのデータファイルを、選択したターゲット データベース ストレージ(ASM ディスク グループまたはファイル システム)に移動します。
- 移行ジョブが完了すると、バックアップと DR によって提示されたバックアップ イメージのコピー(ASM ディスク グループまたはファイル システム)がターゲットから削除されてマッピングが解除され、データベースが本番環境のストレージから実行されます。
マウントの復元と移行の詳細については、即時復元用の Oracle バックアップ イメージをマウントしてターゲットに移行するをご覧ください。
Oracle データベースを復元する
バックアップと DR の管理コンソールで、[Backup and Recover] > [復元] ページに移動します。
https://bmc-PROJECT_NUMBER-GENERATED_ID-dot-REGION.backupdr.googleusercontent.com/#recover/selectapp
[アプリケーション] リストで、復元するデータベースの名前を右クリックし、[次へ] を選択します。
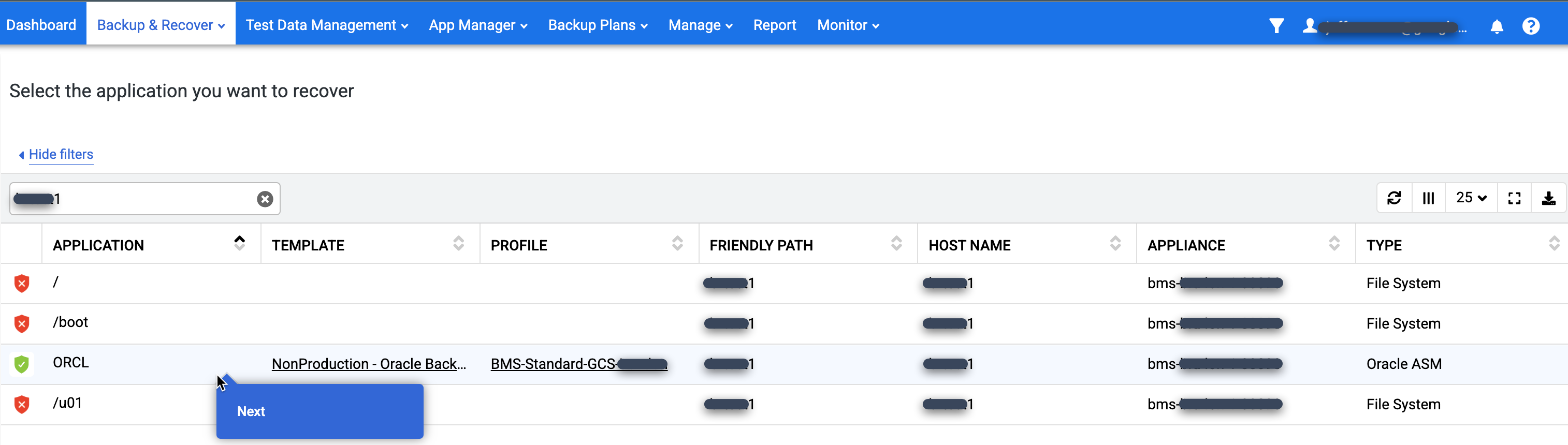
[Timeline Ramp View] が表示され、利用可能なすべてのポイントインタイム イメージが表示されます。ランプに表示されない長期保存のイメージを表示する必要がある場合は、スクロールして戻ることができます。デフォルトでは、常に最新のイメージが選択されます。
イメージを復元するには、[マウント] メニューをクリックして [復元] を選択します。
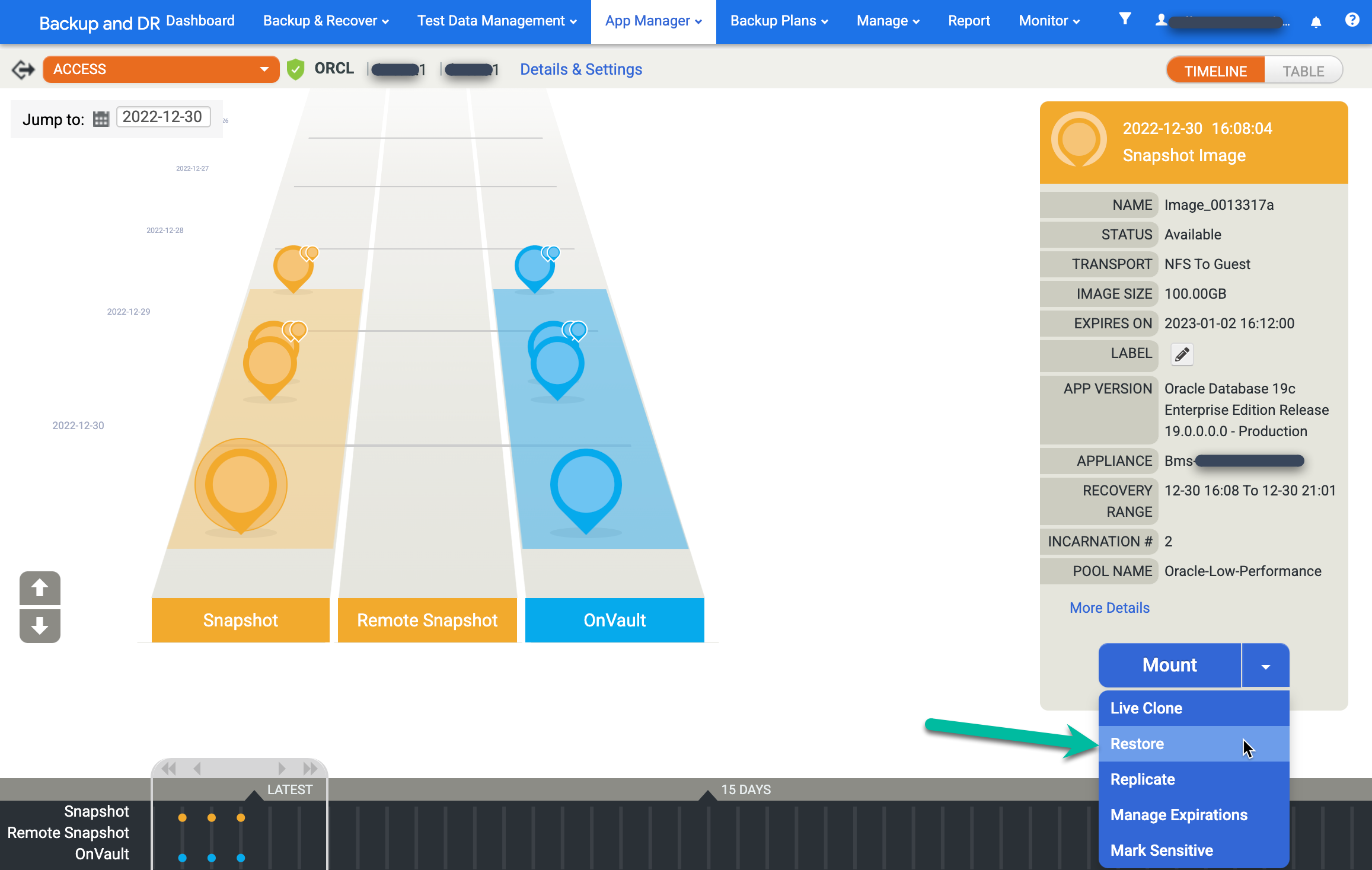
復元オプションを選択します。
- [Roll Forward Time] を選択します。時計をクリックして、目的の時刻を選択します。
- Oracle に使用するユーザー名を入力します。
- データベース認証を使用する場合は、パスワードを入力します。
ジョブを開始するには、[送信] をクリックします。
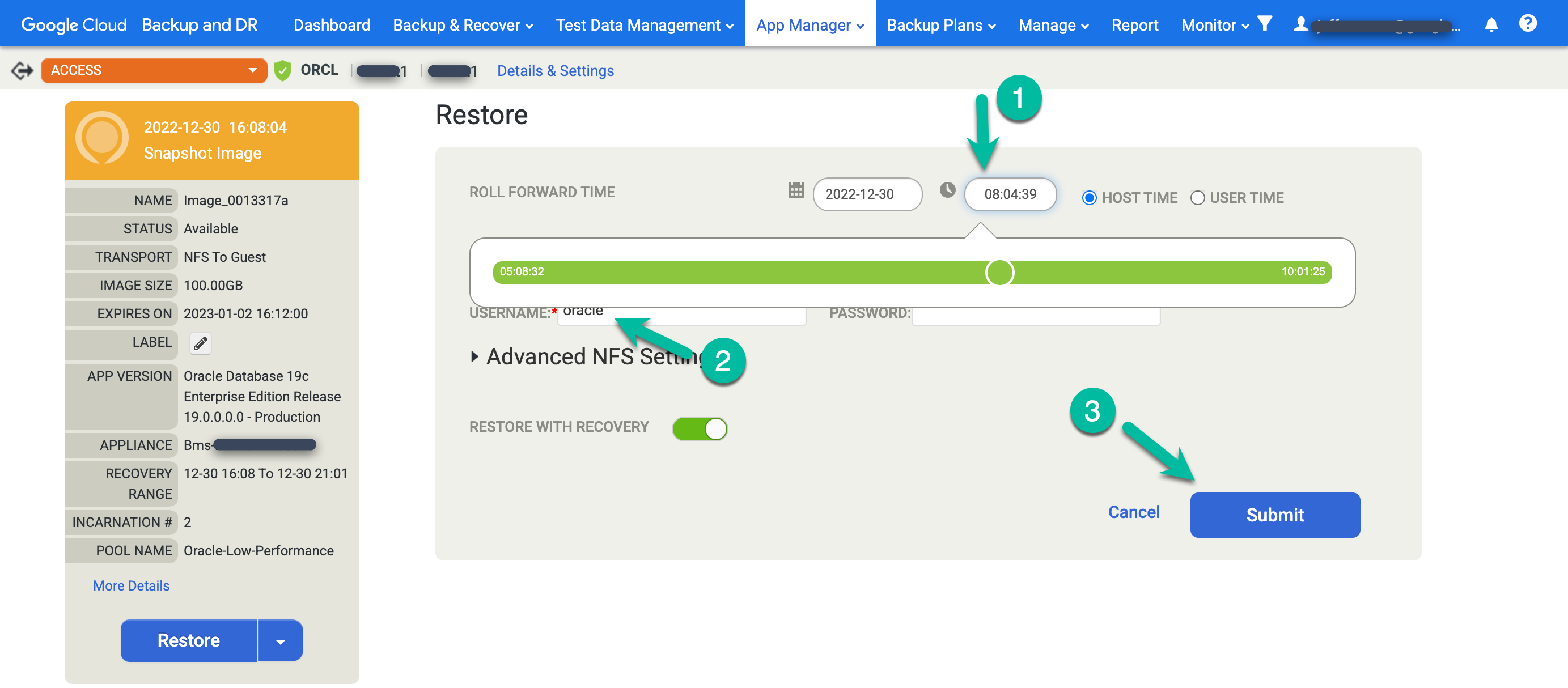
「DATA LOSS」と入力して、ソース データベースの上書きを確認し、[確認] をクリックします。
ジョブの進捗と成功をモニタリングする
ジョブをモニタリングするには、[監視] > [ジョブ] ページに移動します。
https://bmc-PROJECT_NUMBER-GENERATED_ID-dot-REGION.backupdr.googleusercontent.com/#jobs
ジョブが完了したら、[Job Number] をクリックして、ジョブの詳細とメタデータを確認します。
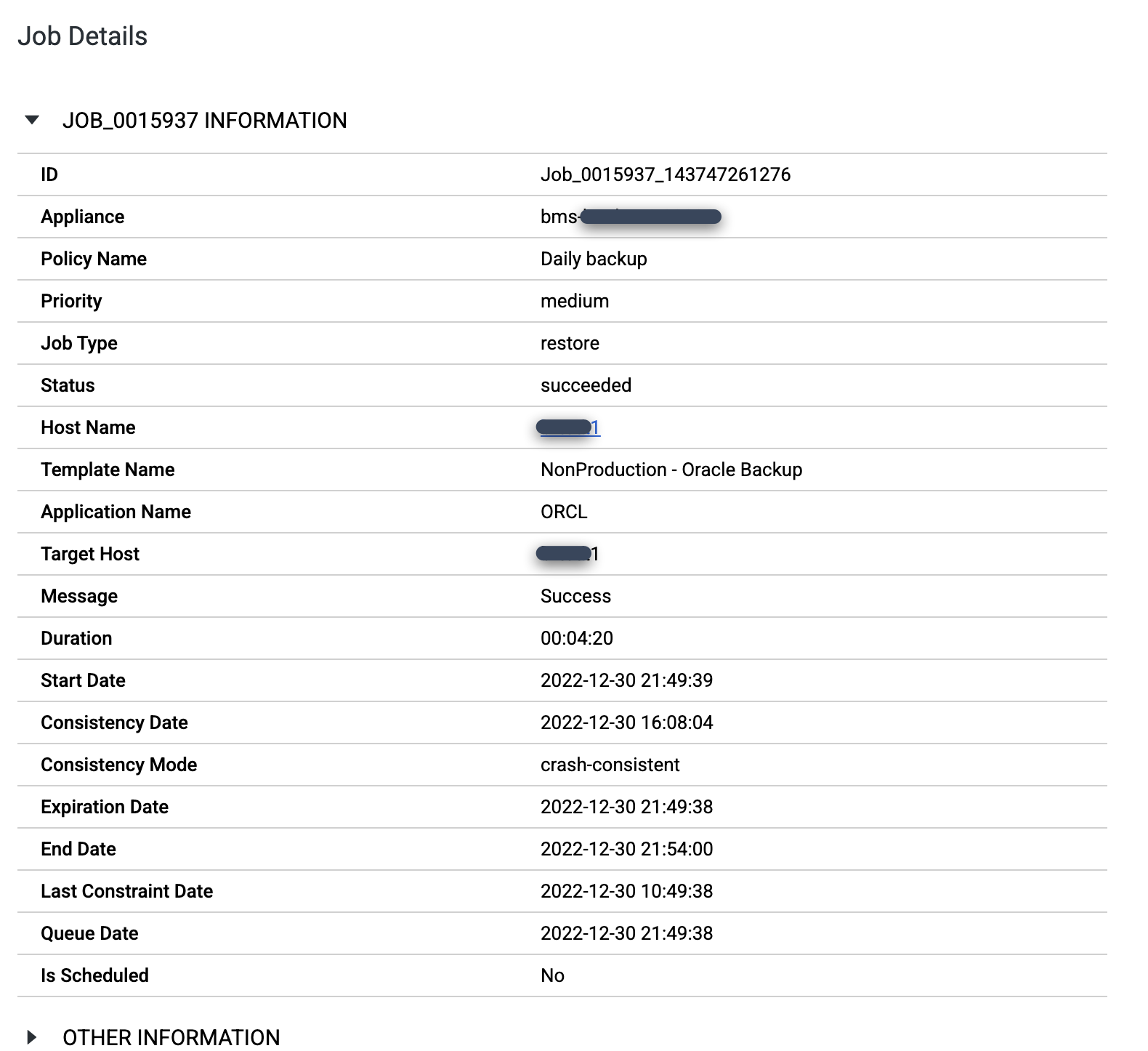
復元されたデータベースを保護する
データベースの復元ジョブが完了した後、復元後のデータベースは自動的にバックアップされません。つまり、以前にバックアップ プランがあったデータベースを復元しても、バックアップ プランはデフォルトで有効になりません。
バックアップ プランが実行されていないことを確認するには、[App Manager] > [アプリケーション] ページに移動します。
https://bmc-PROJECT_NUMBER-GENERATED_ID-dot-REGION.backupdr.googleusercontent.com/#applications
リストで、復元されたデータベースを見つけます。保護アイコンが緑色から黄色に変わっています。これは、データベースのバックアップ ジョブの実行がスケジューリングされていないことを示します。
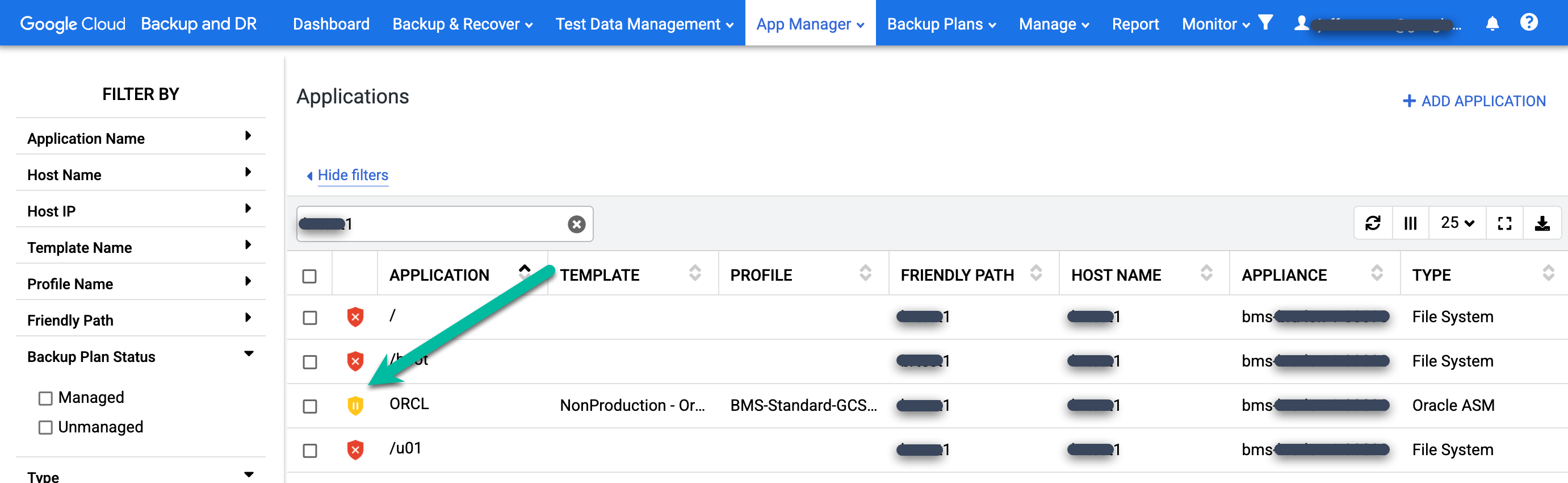
復元されたデータベースを保護するには、保護するデータベースの [アプリケーション] 列を確認します。データベース名を右クリックし、[Manage Backup Plan] を選択します。
![バックアップと DR の管理コンソール ページ。[アプリケーション] ページから [Manage Backup Plan] メニュー項目を選択する方法が示されています。](https://cloud.google.com/static/bare-metal/docs/solutions/oracle/images/backup-and-dr-manage-backup-plan.png?hl=ja)
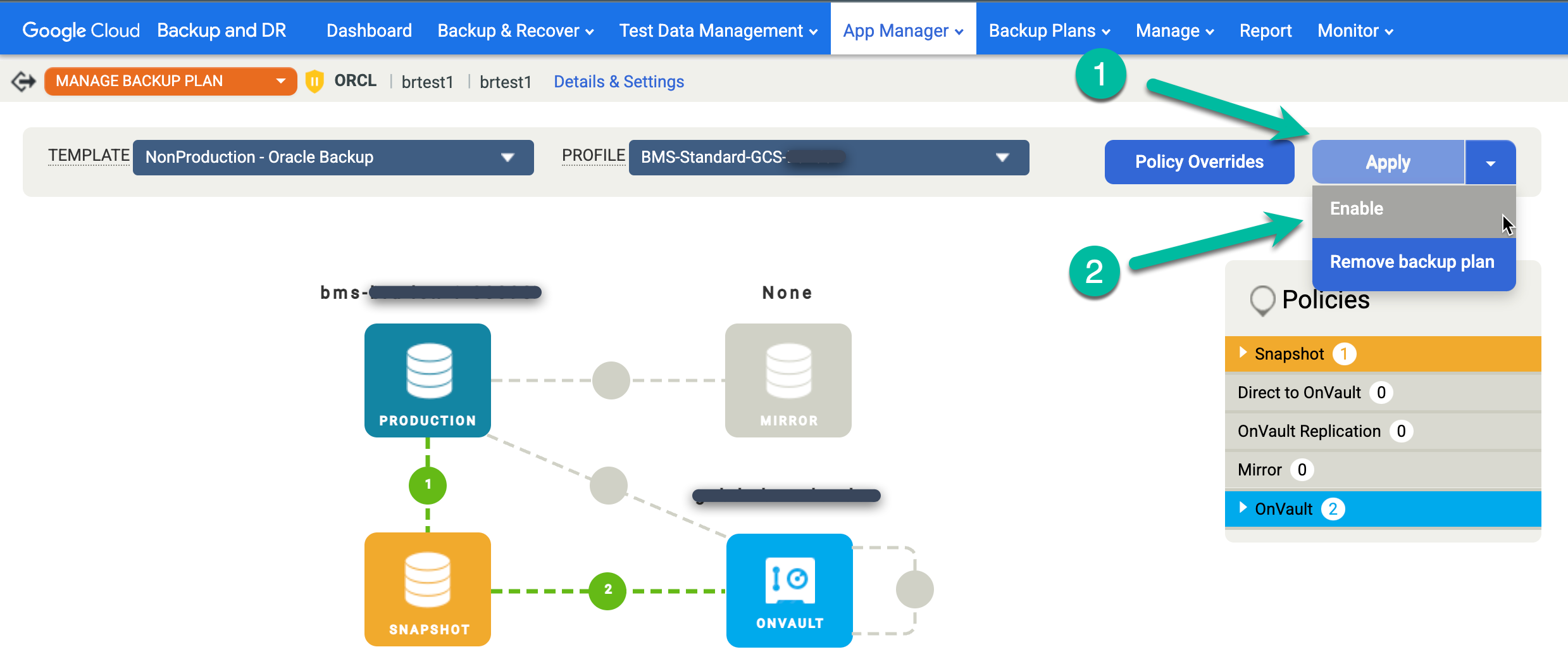
復元されたデータベースでスケジュールされたバックアップ ジョブを再度有効にします。
- [適用] メニューをクリックし、[有効にする] を選択します。
Oracle の詳細設定を確認し、[Enable backup plan] をクリックします。
トラブルシューティングと最適化
このセクションでは、Oracle バックアップのトラブルシューティング、システムの最適化、RAC 環境と Data Guard 環境の調整を検討する際に役立つヒントをいくつか紹介します。
Oracle バックアップのトラブルシューティング
Oracle の構成には、バックアップ タスクの成功に必要な依存関係がいくつか含まれています。以下では、Oracle インスタンス、リスナー、データベースを構成して正常に稼働させる方法について説明します。
保護するサービスとインスタンスの Oracle リスナーが構成され、実行されていることを確認するには、
lsnrctl statusコマンドを実行します。[oracle@test2 lib]$ lsnrctl status LSNRCTL for Linux: Version 19.0.0.0.0 - Production on 29-DEC-2022 07:43:37 Copyright (c) 1991, 2021, Oracle. All rights reserved. Connecting to (ADDRESS=(PROTOCOL=tcp)(HOST=)(PORT=1521)) STATUS of the LISTENER ------------------------ Alias LISTENER Version TNSLSNR for Linux: Version 19.0.0.0.0 - Production Start Date 23-DEC-2022 20:34:17 Uptime 5 days 11 hr. 9 min. 20 sec Trace Level off Security ON: Local OS Authentication SNMP OFF Listener Parameter File /u01/app/19c/grid/network/admin/listener.ora Listener Log File /u01/app/oracle/diag/tnslsnr/test2/listener/alert/log.xml Listening Endpoints Summary... (DESCRIPTION=(ADDRESS=(PROTOCOL=tcp)(HOST=test2.localdomain)(PORT=1521))) (DESCRIPTION=(ADDRESS=(PROTOCOL=ipc)(KEY=EXTPROC1521))) Services Summary... Service "+ASM" has 1 instance(s). Instance "+ASM", status READY, has 1 handler(s) for this service... Service "+ASM_DATADG" has 1 instance(s). Instance "+ASM", status READY, has 1 handler(s) for this service... Service "ORCL" has 1 instance(s). Instance "ORCL", status READY, has 1 handler(s) for this service... Service "ORCLXDB" has 1 instance(s). Instance "ORCL", status READY, has 1 handler(s) for this service... Service "f085620225d644e1e053166610ac1c27" has 1 instance(s). Instance "ORCL", status READY, has 1 handler(s) for this service... Service "orclpdb" has 1 instance(s). Instance "ORCL", status READY, has 1 handler(s) for this service... The command completed successfully
Oracle データベースが ARCHIVELOG モードで構成されていることを確認します。データベースが別のモードで実行されている場合、次のようなエラーコード 5556 メッセージと失敗したジョブが表示されることがあります。
export ORACLE_HOME=ORACLE_HOME_PATH export ORACLE_SID=DATABASE_INSTANCE_NAME export PATH=$ORACLE_HOME/bin:$PATH sqlplus / as sysdba SQL> set tab off SQL> archive log list; Database log mode Archive Mode Automatic archival Enabled Archive destination +FRA Oldest online log sequence 569 Next log sequence to archive 570 Current log sequence 570
Oracle データベースでブロック変更の追跡を有効にします。ソリューションの機能に必須ではありませんが、ブロック変更のトラッキングを有効にすると、変更されたブロックを計算するために大量の後処理を行う必要がなくなるため、バックアップ ジョブの時間を短縮できます。
SQL> select status,filename from v$block_change_tracking; STATUS FILENAME ---------- ------------------------------------------------------------------ ENABLED +DATADG/ORCL/CHANGETRACKING/ctf.276.1124639617
データベースが
spfileを使用していることを確認します。sqlplus / as sysdba SQL> show parameter spfile NAME TYPE VALUE ------------------ ----------- ------------ spfile string +DATA/ctdb/spfilectdb.ora
Oracle データベース ホストに対して Direct NFS(dnfs) を有効にします。必須ではありませんが、Oracle データベースのバックアップと復元を最短で行う必要がある場合は、dnfs を使用することをおすすめします。スループットをさらに改善するには、ホストごとにステージング ディスクを変更し、Oracle に対して dnfs を有効にします。
Oracle データベース ホストを解決するために tnsnames を構成します。この設定を含めないと、RMAN コマンドが失敗することがよくあります。出力の例を次に示します。
[oracle@test2 lib]$ tnsping ORCL TNS Ping Utility for Linux: Version 19.0.0.0.0 - Production on 29-DEC-2022 07:55:18 Copyright (c) 1997, 2021, Oracle. All rights reserved. Used parameter files: Used TNSNAMES adapter to resolve the alias Attempting to contact (DESCRIPTION = (ADDRESS = (PROTOCOL = TCP)(HOST = test2.localdomain)(PORT = 1521)) (CONNECT_DATA = (SERVER = DEDICATED) (SERVICE_NAME = ORCL))) OK (0 msec)
SERVICE_NAMEフィールドは RAC 構成に重要です。サービス名は、クラスタと通信する外部リソースにシステムをアドバタイズするために使用されるエイリアスを表します。保護されたデータベースの [詳細と設定] オプションで、[Advanced Setting for Oracle Service Name] を使用します。バックアップ ジョブを実行するノードで使用するサービス名を入力します。Oracle データベースは、データベース認証にのみサービス名を使用します。データベースは OS 認証にサービス名を使用しません。たとえば、データベース名は CLU1_S、インスタンス名は CLU1_S です。
Oracle サービス名がリストにない場合は、
$ORACLE_HOME/network/adminまたは$GRID_HOME/network/adminにある tnsnames.ora ファイルに次のエントリを追加して、サーバーにサービス名エントリを作成します。CLU1_S = (DESCRIPTION = (ADDRESS = (PROTOCOL = TCP)(HOST =
)(PORT = 1521)) (CONNECT_DATA = (SERVER = DEDICATED) (SERVICE_NAME = CLU1_S) ) ) tnsnames.ora ファイルが標準以外の場所にある場合は、[Application Details and Settings] ページでファイルの絶対パスを指定します(Oracle データベースのアプリケーションの詳細と設定を構成するを参照)。
データベースのサービス名エントリが正しく構成されていることを確認します。Oracle Linux にログインして Oracle 環境を構成します。
TNS_ADMIN=TNSNAMES.ORA_FILE_LOCATION tnsping CLU1_S
データベース ユーザー アカウントを確認して、バックアップと DR アプリケーションへの接続に問題がないことを確認します。
sqlplus act_rman_user/act_rman_user@act_svc_dbstd as sysdba
Oracle データベースのアプリケーションの詳細と設定を構成するで説明されている [Application Details and Settings] ページで、作成したサービス名(CLU1_S)を [Oracle Service Name] フィールドに入力します。
![[Application Details and Settings] の [Oracle Service Name] フィールドの場所を示す、バックアップと DR のダイアログ ボックス。](https://cloud.google.com/static/bare-metal/docs/solutions/oracle/images/backup-and-dr-oracle-service-name.png?hl=ja)
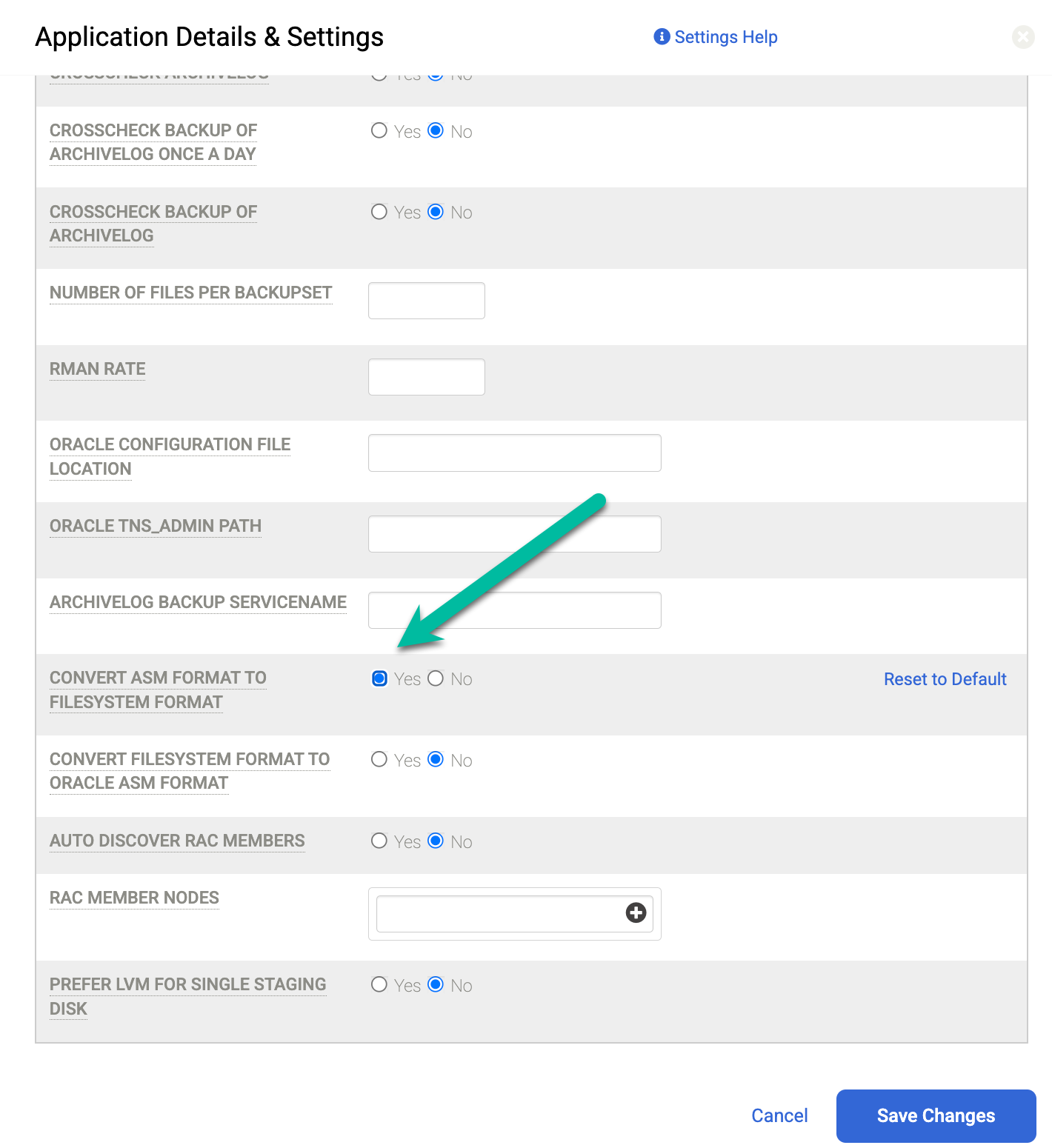
エラーコード 870 は、NFS ステージング ディスク上の ASM による ASM バックアップはサポートされていないことを表しています。このエラーが表示された場合は、保護するインスタンスの [詳細と設定] で正しい設定が構成されていません。この構成ミスにより、ホストはステージング ディスクに NFS を使用しますが、ソース データベースは ASM で実行されます。
![ASM データベースを使用する NFS ホストのステージング ディスクの構成ミスを示す、バックアップと DR のダイアログ ボックス。この問題を解決するには、[Convert ASM to Filesystem] の設定を [Yes] に変更します。](https://cloud.google.com/static/bare-metal/docs/solutions/oracle/images/backup-and-dr-error-code-870.png?hl=ja)
この問題を解決するには、[Convert ASM Format to Filesystem Format] フィールドを [Yes] に設定します。この設定を変更したら、バックアップ ジョブを再実行します。
エラーコード 15 は、バックアップと DR システムがバックアップ ホストに接続できなかったことを表しています。このエラーが表示された場合は、次の 3 つの問題のいずれかが発生しています。
- バックアップ/リカバリ アプライアンスとエージェントをインストールしたホストの間のファイアウォールで、TCP ポート 5106(エージェントのリスニング ポート)が許可されていない。
- エージェントがインストールされていない。
- エージェントは実行されていない。
この問題を解決するには、必要に応じてファイアウォール設定を再構成し、エージェントが機能していることを確認します。根本原因を修正したら、
service udsagent statusコマンドを実行します。次の出力例は、バックアップと DR のエージェント サービスが正しく実行されていることを示しています。[root@test2 ~]# service udsagent status Redirecting to /bin/systemctl status udsagent.service udsagent.service - Google Cloud Backup and DR service Loaded: loaded (/usr/lib/systemd/system/udsagent.service; enabled; vendor preset: disabled) Active: active (running) since Wed 2022-12-28 05:05:45 UTC; 2 days ago Process: 46753 ExecStop=/act/initscripts/udsagent.init stop (code=exited, status=0/SUCCESS) Process: 46770 ExecStart=/act/initscripts/udsagent.init start (code=exited, status=0/SUCCESS) Main PID: 46789 (udsagent) Tasks: 8 (limit: 48851) Memory: 74.0M CGroup: /system.slice/udsagent.service ├─46789 /opt/act/bin/udsagent start └─60570 /opt/act/bin/udsagent start Dec 30 05:11:30 test2 su[150713]: pam_unix(su:session): session closed for user oracle Dec 30 05:11:30 test2 su[150778]: (to oracle) root on none
バックアップのログメッセージは問題の診断に役立ちます。ログには、バックアップ ジョブが実行されるソースホストでアクセスできます。Oracle データベース バックアップの場合、
/var/act/logディレクトリには次の 2 つのメイン ログファイルがあります。- UDSAgent.log -Google Cloud API リクエスト、実行中のジョブ統計などの詳細を記録する Backup and DR エージェントのログ。
- SID_rman.log – すべての RMAN コマンドを記録する Oracle RMAN ログ。
Oracle のその他の考慮事項
Oracle データベースのバックアップと DR を実装する場合は、Data Guard と RAC をデプロイする際の次の考慮事項に注意してください。
Data Guard に関する考慮事項
プライマリとスタンバイの両方の Data Guard ノードをバックアップできます。ただし、スタンバイ ノードからのみデータベースを保護する場合は、データベースのバックアップ時に OS 認証ではなく Oracle データベース認証を使用する必要があります。
RAC に関する考慮事項
ステージング ディスクが NFS モードに設定されている場合、バックアップと DR ソリューションは、RAC データベース内の複数のノードからの同時バックアップをサポートしていません。複数の RAC ノードからの同時バックアップを必要とする場合は、ステージング ディスク モードとしてブロック(iSCSI)を使用し、これをホストごとに設定します。
ASM を使用する Oracle RAC データベースの場合は、共有ディスクにスナップショット制御ファイルを配置する必要があります。この構成を確認するには、RMAN に接続して show all コマンドを実行します。
rman target / RMAN> show all
CONFIGURE RETENTION POLICY TO REDUNDANCY 1; # default CONFIGURE BACKUP OPTIMIZATION OFF; # default CONFIGURE DEFAULT DEVICE TYPE TO DISK; # default CONFIGURE CONTROLFILE AUTOBACKUP OFF; # default CONFIGURE CONTROLFILE AUTOBACKUP FORMAT FOR DEVICE TYPE DISK TO '%F'; # default CONFIGURE DEVICE TYPE DISK PARALLELISM 1 BACKUP TYPE TO BACKUPSET; # default CONFIGURE SNAPSHOT CONTROLFILE NAME TO '/mnt/ctdb/snapcf_ctdb.f';
RAC 環境では、スナップショット制御ファイルを共有 ASM ディスク グループにマッピングする必要があります。ファイルを ASM ディスク グループに割り当てるには、Configure Snapshot Controlfile Name コマンドを使用します。
CONFIGURE SNAPSHOT CONTROLFILE NAME TO '+/snap_ .f';
推奨事項
要件によっては、ソリューション全体に影響する特定の機能を決めなければならないことがあります。一部の決定は料金に影響を与える可能性があります。その結果、パフォーマンスに影響する可能性があります。たとえば、バックアップ/リカバリ アプライアンスのスナップショット プールに標準永続ディスク(pd-standard)を選択するのか、パフォーマンス永続ディスク(pd-ssd)を選択するのかという決定がこれに該当します。
このセクションでは、Oracle データベースのバックアップ スループットのパフォーマンスを最適化するためのおすすめの方法を説明します。
最適なマシンタイプと永続ディスクタイプを選択する
ファイル システムやデータベースなどのアプリケーションでバックアップ/リカバリ アプライアンスを使用する場合は、ホスト インスタンスのデータが Compute Engine インスタンス間で転送される速度に基づいてパフォーマンスを測定できます。
- Compute Engine 永続ディスク デバイスの速度は、マシンタイプ、インスタンスに接続しているメモリの総量、インスタンスの vCPU 数という 3 つの要素に基づきます。
- インスタンス内の vCPU の数によって、Compute Engine インスタンスに割り当てられるネットワーク速度が決まります。速度の範囲は、1 Gbps(共有 vCPU の場合)から 16 Gbps(8 個以上の vCPU の場合)までです。
- これらの上限により、 Google Cloud Backup and DR では、バックアップ/リカバリ アプライアンスの標準サイズ マシンタイプにデフォルトで e2-standard-16 を使用します。これを出発点として、次の 3 つのディスク割り当ての選択肢があります。
選択肢 |
プールディスク |
最大持続書き込み |
最大持続読み取り |
最小 |
10 GB |
なし |
なし |
標準 |
4,096 GB |
400 MiB/秒 |
1,200 MiB/秒 |
SSD |
4,096 GB |
1,000 MiB/秒 |
1,200 MiB/秒 |
Compute Engine インスタンスは、接続されている永続ディスクに割り当てられたネットワークの最大 60% を I/O に使用し、その他の使用のために 40% を予約します。詳細については、パフォーマンスに影響するその他の要因をご覧ください。
推奨事項: e2-standard-16 マシンタイプと最小 4,096 GB の PD-SSD を選択すると、バックアップ/リカバリ アプライアンスの最適なパフォーマンスが得られます。2 つ目の選択として、バックアップ/リカバリ アプライアンスに n2-standard-16 マシンタイプを選択できます。このオプションでは、10 ~ 20% の範囲のパフォーマンス上のメリットが得られますが、追加のコストがかかります。これがユースケースに該当する場合は、Cloud カスタマーケアにお問い合わせください。
スナップショットを最適化する
単一のバックアップ/リカバリ アプライアンスの生産性を向上させるには、複数のソースから同時にスナップショット ジョブを実行します。これにより、各ジョブの速度が低下します。ただし、十分な数のジョブを使用すると、スナップショット プール内の Persistent Disk ボリュームの永続書き込みの上限に到達する場合があります。
ステージング ディスクに iSCSI を使用する場合、1 つの大きなインスタンスを 300 ~ 330 MB/秒の持続書き込み速度でバックアップ/リカバリ アプライアンスにバックアップできます。テストでは、ソースホストとバックアップ/リカバリ アプライアンスの両方を最適なサイズで構成し、それらが同じリージョンとゾーンにあると想定した場合、スナップショットで 2 TB から最大 80 TB まで可能であることがわかりました。
適切なステージング ディスクを選択する
高いパフォーマンスとスループットが必要な場合は、Oracle データベースのバックアップに使用するステージング ディスクとして Direct NFS を使用すると、iSCSI よりも大きなメリットが得られます。Direct NFS は TCP 接続の数を統合し、スケーラビリティとネットワーク パフォーマンスを向上させます。
Oracle データベースで Direct NFS を有効にする場合は、十分な移行元 CPU(8 個の vCPU と 8 個の RMAN チャネルなど)を構成し、Bare Metal Solution リージョン拡張と Google Cloudの間に 10 GB のリンクを確立します。これにより、700 ~ 900+ MB/秒のスループットで単一の Oracle データベースをバックアップできます。RMAN の復元速度も Direct NFS のメリットを享受できます。スループット レベルが 850 MB/秒以上の範囲になる場合があります。
コストとスループットのバランスを取る
コスト削減のため、すべてのバックアップ データは圧縮形式でバックアップ/リカバリ アプライアンス スナップショット プールに保存されます。この点もよく理解しておく必要があります。この圧縮のメリットによるパフォーマンスのオーバーヘッドはわずかです。ただし、暗号化されたデータ(TDE)または高度に圧縮されたデータセットの場合、わずかではあるものの、スループットにある程度の影響が発生します。
ネットワークとバックアップ サーバーのパフォーマンスに影響する要因を理解する
次の項目は、Oracle on Bare Metal Solution と Google Cloudのバックアップ サーバー間のネットワーク I/O に影響します。
フラッシュ ストレージ
Google Cloud Persistent Disk と同様に、Bare Metal Solution システムにストレージを提供するフラッシュ ストレージ アレイは、ホストに割り当てるストレージの量に基づいて I/O 機能を向上させます。割り当てるストレージが多いほど I/O が向上します。一貫した結果を得るには、8 TB 以上のフラッシュ ストレージをプロビジョニングすることをおすすめします。
ネットワーク レイテンシ
Google Cloud バックアップと DR のバックアップ ジョブは、Bare Metal Solution ホストと Google Cloudのバックアップ/リカバリ アプライアンス間のネットワーク レイテンシの影響を受けます。レイテンシのわずかな増加によって、バックアップと復元の時間が大きく変わる可能性があります。Compute Engine ゾーンが異なると、Bare Metal Solution ホストへのネットワーク レイテンシも異なります。バックアップ/リカバリ アプライアンスの最適な配置について、各ゾーンでテストすることをおすすめします。
使用されるプロセッサの数
Bare Metal Solution サーバーには、いくつかのサイズがあります。利用可能な CPU に合わせて RMAN チャネルをスケーリングし、大規模なシステムからの通信速度を高速化することをおすすめします。
Cloud Interconnect
Bare Metal Solution と Google Cloud 間のハイブリッド相互接続には、5 Gbps、10 Gbps、2x10 Gbps など、いくつかのサイズが用意されています。デュアル 10 GB オプションにより、完全なパフォーマンスが提供されます。バックアップと復元のオペレーション用に、専用の相互接続リンクを構成することもできます。このオプションは、同じリンクを通過する可能性のあるデータベース トラフィックやアプリケーション トラフィックからバックアップ トラフィックを分離する場合や、バックアップと復元のオペレーションが重要で、目標復旧時点(RPO)と目標復旧時間(RTO)を確実に満たすために帯域幅全体を保証する場合におすすめします。
次のステップ
Google Cloud Backup and DR に関する次のリンクもご覧ください。
- Google Cloud Backup and DR の設定に関する追加手順については、Backup and DR プロダクトのドキュメントをご覧ください。
- プロダクトのインストールと機能のデモについては、Google Cloud のバックアップと DR の動画再生リストをご覧ください。
- Google Cloud Backup and DR の互換性については、サポート マトリックス: バックアップと DR をご覧ください。サポートされているバージョンの Linux と Oracle データベース インスタンスを実行していることを確認することは重要です。
- Oracle データベースの保護に関する追加の手順については、Oracle データベースのバックアップと DR と検出された Oracle データベースを保護するをご覧ください。
- NFS、CIFS、ext3、ext4 などのファイル システムは、Google Cloud Backup and DR でも保護できます。使用可能なオプションを確認するには、バックアップ プランを適用してファイル システムを保護するをご覧ください。
- Google Cloud バックアップと DR のアラートを有効にするには、ログベースのアラートを構成すると Google Cloud のバックアップと DR のアラート通知設定の動画をご覧ください。
- サポートケースを登録するには、Cloud カスタマーケアにお問い合わせください。