本文說明以Google Cloud 實作的管道範例,該管道會執行傾向模型。適用於建立及部署機器學習模型的資料工程師、機器學習工程師或行銷科學團隊。本文假設您瞭解機器學習概念,並熟悉 Google Cloud、BigQuery、Vertex AI Pipelines、Python 和 Jupyter 筆記本。此外,本文也假設您已瞭解 Google Analytics 4 和 BigQuery 中的原始資料匯出功能。
您使用的管道會採用 Google Analytics 範例資料。這個管道會使用 BigQuery ML 和 XGBoost 建構多個模型,並透過 Vertex AI Pipelines 執行管道。本文說明訓練、評估及部署模型的程序。本文也會說明如何自動執行整個程序。
完整的管道程式碼位於 GitHub 存放區的 Jupyter 筆記本中。
什麼是傾向模擬?
傾向模型會預測消費者可能採取的動作。舉例來說,傾向模型可預測哪些消費者可能購買產品、註冊服務,甚至是流失,不再是品牌的活躍客戶。
傾向模型會為每位消費者輸出介於 0 到 1 之間的分數,代表消費者採取該動作的可能性。促使機構採用傾向模型的主要原因之一,是需要更充分運用第一方資料。就行銷用途而言,最佳的傾向模型會納入線上和離線來源的信號,例如網站分析和顧客關係管理資料。
本示範使用 BigQuery 中的 GA4 範例資料。針對您的用途,您可能需要考慮其他離線信號。
機器學習運作如何簡化機器學習管道
大多數機器學習模型都不會用於實際工作環境。模型結果會產生洞察資料,而資料科學團隊完成模型後,機器學習工程或軟體工程團隊通常需要使用 Flask 或 FastAPI 等架構,將模型包裝在程式碼中,以供正式環境使用。這個程序通常需要使用新架構建構模型,也就是說,資料必須重新轉換。這項工作可能需要數週或數月,因此許多模型無法投入生產。
機器學習作業 (MLOps) 對於從機器學習專案獲取價值至關重要,而 MLOps 現在已成為資料科學機構不斷發展的技能組合。為協助機構瞭解這項價值, Google Cloud 發布了 MLOps 實務指南,提供 MLOps 總覽。
運用 MLOps 原則和 Google Cloud,您可以使用自動程序將模型推送至端點,大幅簡化手動程序。本文介紹的工具和程序,說明如何從頭到尾掌握管道,協助您將模型投入正式環境。如前所述,機器學習運作從業人員指南文件提供水平解決方案,以及使用機器學習運作和 Google Cloud可執行的作業大綱。
什麼是 Vertex AI Pipelines?
Vertex AI Pipelines 可讓您執行使用 Kubeflow Pipelines SDK 或 TensorFlow Extended (TFX) 建構的機器學習 pipeline。如果沒有 Vertex AI,您必須自行設定及維護 Kubernetes 叢集,才能大規模執行這兩種開放原始碼架構。Vertex AI Pipelines 可解決這項挑戰。這項代管服務會視需要擴大或縮減規模,且不需要持續維護。
Vertex AI Pipelines 流程的每個步驟都包含獨立容器,可接收輸入內容或以構件形式產生輸出內容。舉例來說,如果程序中的某個步驟會建構資料集,則輸出內容就是資料集構件。這個資料集構件可用於下一個步驟的輸入內容。由於每個元件都是獨立的容器,因此您必須為管道的每個元件提供資訊,例如基礎映像檔的名稱和任何依附元件的清單。
管道建構程序
本文所述範例使用 Jupyter 筆記本建立管道元件,並編譯、執行及自動化這些元件。如先前所述,筆記本位於 GitHub 存放區。
您可以使用 Vertex AI Workbench 使用者自行管理的筆記本執行個體執行筆記本程式碼,該執行個體會為您處理驗證作業。您可以使用 Vertex AI Workbench 處理筆記本,建立機器、建構筆記本,以及連線至 Git。(Vertex AI Workbench 包含更多功能,但本文未涵蓋這些功能)。
管道執行完成後,Vertex AI Pipelines 會產生類似下方的圖表:
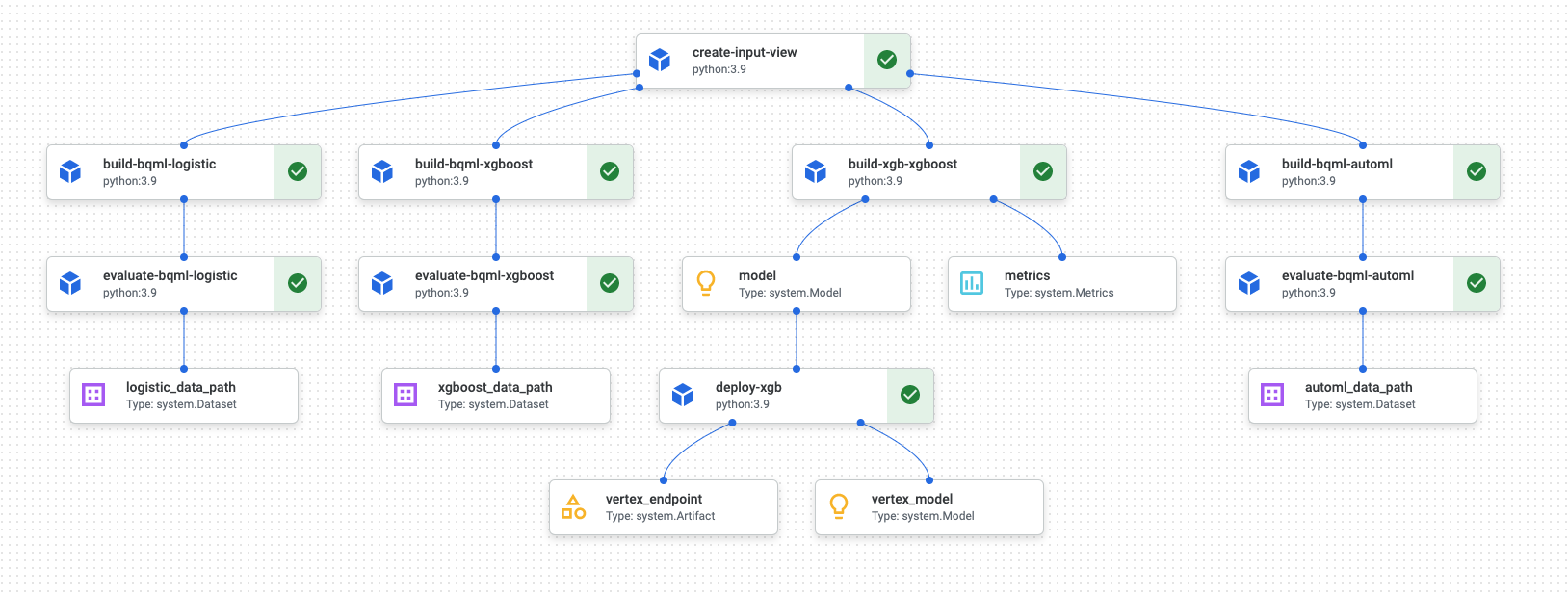
上圖是有向非循環圖 (DAG)。建構及檢查 DAG 是瞭解資料或機器學習管道的關鍵步驟。DAG 的主要屬性是元件會朝單一方向流動 (在本例中為由上而下),且不會發生週期性情況,也就是父項元件不會依附於子項元件。部分元件可平行發生,其他元件則有依附元件,因此會依序發生。
各項元件中的綠色核取方塊表示程式碼已順利執行。如有錯誤,系統會顯示紅色驚嘆號。您可以點選圖表中的各個元件,查看作業的詳細資料。
本文的這一節包含 DAG 圖表,可做為管道建構的每個元件藍圖。下列清單提供各個元件的相關說明。
如 DAG 圖所示,完整管道會執行下列步驟:
create-input-view:這個元件會建立 BigQuery 檢視區塊。這個元件會從 Cloud Storage bucket 複製 SQL,並填入您提供的參數值。這個 BigQuery 檢視畫面是輸入資料集,pipeline 中後續的所有模型都會使用這個資料集。build-bqml-logistic:這個管道會使用 BigQuery ML 建立邏輯迴歸模型。這個元件完成後,您就能在 BigQuery 主控台中查看新模型。您可以使用這個模型物件查看模型成效,並在稍後建構預測。evaluate-bqml-logistic:管道會使用這個元件,為邏輯迴歸建立精確度/召回率曲線 (DAG 圖表中的logistic_data_path)。這個構件會儲存在 Cloud Storage bucket 中。build-bqml-xgboost:這個元件會使用 BigQuery ML 建立 XGBoost 模型。這個元件完成後,您可以在 BigQuery 控制台中查看新的模型物件 (system.Model)。您可以使用這個物件查看模型成效,並在稍後建構預測。evaluate-bqml-xgboost:這個元件會為 XGBoost 模型建立名為xgboost_data_path的精確度/召回率曲線。這個構件會儲存在 Cloud Storage bucket 中。build-xgb-xgboost:管道會建立 XGBoost 模型。這個元件使用 Python 而非 BigQuery ML,因此您可以瞭解建立模型的不同方法。這個元件完成後,會將模型物件和效能指標儲存在 Cloud Storage 值區中。deploy-xgb:這個元件會部署 XGBoost 模型。系統會建立端點,允許批次或線上預測。您可以在 Vertex AI 控制台頁面的「模型」分頁中探索端點。端點會自動調度資源,以符合流量需求。build-bqml-automl:管道會使用 BigQuery ML 建立 AutoML 模型。這個元件完成後,您可以在 BigQuery 控制台中查看新的模型物件。您可以使用這個物件查看模型成效,並在稍後建立預測。evaluate-bqml-automl:這個管道會為 AutoML 模型建立精確度/召回率曲線。構件會儲存在 Cloud Storage bucket 中。
請注意,這個程序不會將 BigQuery ML 模型推送至端點。這是因為您可以直接從 BigQuery 中的模型物件產生預測結果。決定要使用 BigQuery ML 還是其他程式庫來建構解決方案時,請考量預測的產生方式。如果每日批次預測符合您的需求,留在 BigQuery 環境中可簡化工作流程。不過,如果您需要即時預測,或是您的情境需要其他程式庫的功能,請按照本文中的步驟,將儲存的模型推送至端點。
費用
在本文件中,您會使用下列 Google Cloud的計費元件:
如要根據預測用量估算費用,請使用 Pricing Calculator。
事前準備
- Sign in to your Google Cloud account. If you're new to Google Cloud, create an account to evaluate how our products perform in real-world scenarios. New customers also get $300 in free credits to run, test, and deploy workloads.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
- 在 Google Cloud 控制台中,選取要建立筆記本的專案。
前往 Vertex AI Workbench 頁面。
在「User-managed notebooks」(由使用者管理的筆記本) 分頁中,按一下「New Notebook」(新增筆記本)。
在筆記本類型清單中,選擇 Python 3 筆記本。
在「New notebook」對話方塊中,按一下「Advanced Options」,然後在「Machine type」下方,選取要使用的機器類型。如果不確定,請選擇「n1-standard-1 (1 個 cVPU,3.75 GB RAM)」。
點選「建立」。
筆記本環境需要一些時間才能建立完畢。
建立筆記本後,請選取筆記本,然後按一下「Open Jupyterlab」。
瀏覽器會開啟 JupyterLab 環境。
如要啟動終端機分頁,請依序選取「File」>「New」>「Launcher」。
按一下「啟動器」分頁中的「終端機」圖示。
在終端機中,複製
mlops-on-gcpGitHub 存放區:git clone https://github.com/GoogleCloudPlatform/cloud-for-marketing/
指令完成後,您會在檔案瀏覽器中看到
cloud-for-marketing資料夾。- 建立 Cloud Storage bucket,供筆記本儲存管道構件。值區名稱不得重複。
- 在
cloud-for-marketing/marketing-analytics/predicting/kfp_pipeline/資料夾中,開啟Propensity_Pipeline.ipynb筆記本。 - 在筆記本中,將
PROJECT_ID變數的值設為要執行管道的 Google Cloud 專案 ID。 - 將
BUCKET_NAME變數的值設為您剛才建立的值區名稱。 - 已建立輸入資料集。
- 使用 BigQuery ML 和 Python 的 XGBoost 訓練多個模型。
- 分析模型結果。
- 部署 XGBoost 模型。
- In the Google Cloud console, go to the Manage resources page.
- In the project list, select the project that you want to delete, and then click Delete.
- In the dialog, type the project ID, and then click Shut down to delete the project.
- 如要瞭解如何使用 MLOps 建立適用於正式環境的機器學習系統,請參閱機器學習運作從業人員指南。
- 如要瞭解 Vertex AI,請參閱 Vertex AI 說明文件。
- 如要瞭解 Kubeflow Pipelines,請參閱 KFP 說明文件。
- 如要瞭解 TensorFlow Extended,請參閱 TFX 使用手冊。
- 如要瞭解適用於 Google Cloud中 AI 和機器學習工作負載的架構原則和建議,請參閱 Well-Architected Framework 中的AI 和機器學習觀點。
- 如要查看更多參考架構、圖表和最佳做法,請瀏覽 Cloud 架構中心。
這個情境的 Jupyter 筆記本
建立及建構管道的相關工作會內建在 GitHub 存放區的 Jupyter 筆記本中。
如要執行這些工作,請取得筆記本,然後依序執行筆記本中的程式碼儲存格。本文所述流程假設您在 Vertex AI Workbench 中執行筆記本。
開啟 Vertex AI Workbench 環境
首先,將 GitHub 存放區複製到 Vertex AI Workbench 環境。
設定筆記本
您必須先設定筆記本,才能執行。筆記本需要 Cloud Storage 值區來儲存管道構件,因此請先建立該值區。
本文的其餘部分會說明有助於瞭解管道運作方式的重要程式碼片段。如需完整實作方式,請參閱 GitHub 存放區。
建立 BigQuery 檢視表
管道的第一步是產生輸入資料,用於建構每個模型。這個 Vertex AI Pipelines 元件會產生 BigQuery 檢視區塊。為簡化建立檢視區塊的程序,系統已在 GitHub 的文字檔中產生並儲存部分 SQL。
每個元件的程式碼都會先裝飾 (透過屬性修改父類別或函式) Vertex AI Pipelines 元件類別。接著,程式碼會定義 create_input_view 函式,這是管道中的一個步驟。
這項函式需要多項輸入內容。目前部分值已硬式編碼至程式碼中,例如開始日期和結束日期。自動化管道時,您可以修改程式碼以使用適當的值 (例如使用 CURRENT_DATE 函式取得日期),也可以更新元件,將這些值做為參數,而非保留硬式編碼。您也必須將 ga_data_ref 的值變更為 GA4 表格的名稱,並將 conversion 變數的值設為轉換。(本範例使用公開的 GA4 範例資料。)
以下列出 create-input-view 元件的程式碼。
@component( # this component builds a BigQuery view, which will be the underlying source for model packages_to_install=["google-cloud-bigquery", "google-cloud-storage"], base_image="python:3.9", output_component_file="output_component/create_input_view.yaml", ) def create_input_view(view_name: str, data_set_id: str, project_id: str, bucket_name: str, blob_path: str ): from google.cloud import bigquery from google.cloud import storage client = bigquery.Client(project=project_id) dataset = client.dataset(data_set_id) table_ref = dataset.table(view_name) ga_data_ref = 'bigquery-public-data.google_analytics_sample.ga_sessions_*' conversion = "hits.page.pageTitle like '%Shopping Cart%'" start_date = '20170101' end_date = '20170131' def get_sql(bucket_name, blob_path): from google.cloud import storage storage_client = storage.Client() bucket = storage_client.get_bucket(bucket_name) blob = bucket.get_blob(blob_path) content = blob.download_as_string() return content def if_tbl_exists(client, table_ref): ... else: content = get_sql() content = str(content, 'utf-8') create_base_feature_set_query = content. format(start_date = start_date, end_date = end_date, ga_data_ref = ga_data_ref, conversion = conversion) shared_dataset_ref = client.dataset(data_set_id) base_feature_set_view_ref = shared_dataset_ref.table(view_name) base_feature_set_view = bigquery.Table(base_feature_set_view_ref) base_feature_set_view.view_query = create_base_feature_set_query.format(project_id) base_feature_set_view = client.create_table(base_feature_set_view)
建構 BigQuery ML 模型
建立檢視區塊後,請執行名為 build_bqml_logistic 的元件,建構 BigQuery ML 模型。這個筆記本區塊是核心元件。使用您在第一個區塊中建立的訓練檢視區塊,建構 BigQuery ML 模型。在本範例中,筆記本使用邏輯迴歸。
如要瞭解可用的模型類型和超參數,請參閱 BigQuery ML 參考資料說明文件。
以下列出這個元件的程式碼。
@component( # this component builds a logistic regression with BigQuery ML packages_to_install=["google-cloud-bigquery"], base_image="python:3.9", output_component_file="output_component/create_bqml_model_logistic.yaml" ) def build_bqml_logistic(project_id: str, data_set_id: str, model_name: str, training_view: str ): from google.cloud import bigquery client = bigquery.Client(project=project_id) model_name = f"{project_id}.{data_set_id}.{model_name}" training_set = f"{project_id}.{data_set_id}.{training_view}" build_model_query_bqml_logistic = ''' CREATE OR REPLACE MODEL `{model_name}` OPTIONS(model_type='logistic_reg' , INPUT_LABEL_COLS = ['label'] , L1_REG = 1 , DATA_SPLIT_METHOD = 'RANDOM' , DATA_SPLIT_EVAL_FRACTION = 0.20 ) AS SELECT * EXCEPT (fullVisitorId, label), CASE WHEN label is null then 0 ELSE label end as label FROM `{training_set}` '''.format(model_name = model_name, training_set = training_set) job_config = bigquery.QueryJobConfig() client.query(build_model_query_bqml_logistic, job_config=job_config)
使用 XGBoost 而非 BigQuery ML
上一節說明的元件使用 BigQuery ML。筆記本的下一節會說明如何直接在 Python 中使用 XGBoost,而不是使用 BigQuery ML。
您會執行名為 build_bqml_xgboost 的元件,建構元件來執行標準 XGBoost 分類模型,並進行格線搜尋。接著,程式碼會將模型儲存為您建立的 Cloud Storage bucket 中的構件。這個函式支援輸出構件的其他參數 (metrics 和 model),Vertex AI Pipelines 需要這些參數。
@component( # this component builds an xgboost classifier with xgboost packages_to_install=["google-cloud-bigquery", "xgboost", "pandas", "sklearn", "joblib", "pyarrow"], base_image="python:3.9", output_component_file="output_component/create_xgb_model_xgboost.yaml" ) def build_xgb_xgboost(project_id: str, data_set_id: str, training_view: str, metrics: Output[Metrics], model: Output[Model] ): ... data_set = f"{project_id}.{data_set_id}.{training_view}" build_df_for_xgboost = ''' SELECT * FROM `{data_set}` '''.format(data_set = data_set) ... xgb_model = XGBClassifier(n_estimators=50, objective='binary:hinge', silent=True, nthread=1, eval_metric="auc") random_search = RandomizedSearchCV(xgb_model, param_distributions=params, n_iter=param_comb, scoring='precision', n_jobs=4, cv=skf.split(X_train,y_train), verbose=3, random_state=1001 ) random_search.fit(X_train, y_train) xgb_model_best = random_search.best_estimator_ predictions = xgb_model_best.predict(X_test) score = accuracy_score(y_test, predictions) auc = roc_auc_score(y_test, predictions) precision_recall = precision_recall_curve(y_test, predictions) metrics.log_metric("accuracy",(score * 100.0)) metrics.log_metric("framework", "xgboost") metrics.log_metric("dataset_size", len(df)) metrics.log_metric("AUC", auc) dump(xgb_model_best, model.path + ".joblib")
建立端點
您會執行名為 deploy_xgb 的元件,使用上一節的 XGBoost 模型建構端點。這個元件會採用先前的 XGBoost 模型構件、建構容器,然後部署端點,同時提供端點網址做為構件,方便您查看。完成這個步驟後,系統會建立 Vertex AI 端點,您可以在 Vertex AI 的控制台頁面中查看該端點。
@component( # Deploys xgboost model packages_to_install=["google-cloud-aiplatform", "joblib", "sklearn", "xgboost"], base_image="python:3.9", output_component_file="output_component/xgboost_deploy_component.yaml", ) def deploy_xgb( model: Input[Model], project_id: str, vertex_endpoint: Output[Artifact], vertex_model: Output[Model] ): from google.cloud import aiplatform aiplatform.init(project=project_id) deployed_model = aiplatform.Model.upload( display_name="tai-propensity-test-pipeline", artifact_uri = model.uri.replace("model", ""), serving_container_image_uri="us-docker.pkg.dev/vertex-ai/prediction/xgboost-cpu.1-4:latest" ) endpoint = deployed_model.deploy(machine_type="n1-standard-4") # Save data to the output params vertex_endpoint.uri = endpoint.resource_name vertex_model.uri = deployed_model.resource_name
定義管道
如要定義管道,請根據先前建立的元件定義各項作業。如果元件中未明確呼叫這些管道元素,您就可以指定管道元素的順序。
舉例來說,筆記本中的下列程式碼會定義管道。在本例中,程式碼需要 build_bqml_logistic_op 元件在 create_input_view_op 元件之後執行。
@dsl.pipeline( # Default pipeline root. You can override it when submitting the pipeline. pipeline_root=PIPELINE_ROOT, # A name for the pipeline. name="pipeline-test", description='Propensity BigQuery ML Test' ) def pipeline(): create_input_view_op = create_input_view( view_name = VIEW_NAME, data_set_id = DATA_SET_ID, project_id = PROJECT_ID, bucket_name = BUCKET_NAME, blob_path = BLOB_PATH ) build_bqml_logistic_op = build_bqml_logistic( project_id = PROJECT_ID, data_set_id = DATA_SET_ID, model_name = 'bqml_logistic_model', training_view = VIEW_NAME ) # several components have been deleted for brevity build_bqml_logistic_op.after(create_input_view_op) build_bqml_xgboost_op.after(create_input_view_op) build_bqml_automl_op.after(create_input_view_op) build_xgb_xgboost_op.after(create_input_view_op) evaluate_bqml_logistic_op.after(build_bqml_logistic_op) evaluate_bqml_xgboost_op.after(build_bqml_xgboost_op) evaluate_bqml_automl_op.after(build_bqml_automl_op)
編譯及執行管道
現在可以編譯及執行管道。
筆記本中的下列程式碼會將 enable_caching 值設為 true,藉此啟用快取。啟用快取後,系統不會重新執行先前已順利完成的元件。啟用快取時,執行速度會更快,使用的資源也會減少,因此這個旗標在測試管道時特別實用。
compiler.Compiler().compile( pipeline_func=pipeline, package_path="pipeline.json" ) TIMESTAMP = datetime.now().strftime("%Y%m%d%H%M%S") run = pipeline_jobs.PipelineJob( display_name="test-pipeine", template_path="pipeline.json", job_id="test-{0}".format(TIMESTAMP), enable_caching=True ) run.run()
自動執行管道
在這個階段,您已啟動第一個管道。您可以在控制台的 Vertex AI Pipelines 頁面查看這項工作的狀態。您可以觀看每個容器的建構和執行過程。您也可以點選各個元件,追蹤該元件的錯誤。
如要排定管道時間,請建構 Cloud Run 函式,並使用類似於 Cron 工作的排程器。
如以下程式碼片段所示,筆記本最後一個部分的程式碼會排定管道每天執行一次:
from kfp.v2.google.client import AIPlatformClient api_client = AIPlatformClient(project_id=PROJECT_ID, region='us-central1' ) api_client.create_schedule_from_job_spec( job_spec_path='pipeline.json', schedule='0 * * * *', enable_caching=False )
在實際工作環境中使用完成的管道
完成的管道已執行下列工作:
您也使用 Cloud Run 函式和 Cloud Scheduler 每天執行,自動化處理管道。
筆記本中定義的管道是為了說明如何建立各種模型。您不會在實際運作情境中執行目前建構的管道。不過,您可以將這個管道做為指南,並視需要修改元件。舉例來說,您可以編輯特徵建立程序,充分運用資料、修改日期範圍,甚至建立替代模型。您也可以從這些圖示中選擇最符合生產需求的模型。
當管道準備好用於實際工作環境時,您可能會實作其他工作。舉例來說,您可以導入主導/挑戰者模型,每天建立新模型,並根據新資料為新模型 (挑戰者) 和現有模型 (主導者) 評分。只有在新模型的成效優於目前模型時,您才會將新模型投入生產。如要監控系統進度,您也可以記錄每天的模型成效,並以視覺化方式呈現成效趨勢。
清除所用資源
後續步驟
貢獻者
作者:Tai Conley | 雲端客戶工程師
其他貢獻者:Lars Ahlfors | Cloud 客戶工程師