Este documento descreve um exemplo de um pipeline implementado em Google Cloud que realiza a modelagem de propensão. Destina-se a engenheiros de dados, engenheiros de aprendizagem automática ou equipas de ciência de marketing que criam e implementam modelos de aprendizagem automática. O documento pressupõe que conhece os conceitos de aprendizagem automática e que está familiarizado com o Google Cloud, BigQuery, as Vertex AI Pipelines, o Python e os blocos de notas Jupyter. Também pressupõe que tem conhecimentos sobre o Google Analytics 4 e a funcionalidade de exportação não processada no BigQuery.
O pipeline com o qual trabalha usa dados de exemplo do Google Analytics. O pipeline cria vários modelos através do BigQuery ML e do XGBoost, e executa o pipeline através dos Vertex AI Pipelines. Este documento descreve os processos de preparação, avaliação e implementação dos modelos. Também descreve como pode automatizar todo o processo.
O código do pipeline completo está num bloco de notas do Jupyter num repositório do GitHub.
O que é a modelagem de propensão?
A modelagem de propensão prevê ações que um consumidor pode realizar. Os exemplos de modelagem de propensão incluem a previsão de que consumidores têm probabilidade de comprar um produto, inscrever-se num serviço ou até abandonar e deixar de ser um cliente ativo de uma marca.
O resultado de um modelo de propensão é uma pontuação entre 0 e 1 para cada consumidor, em que esta pontuação representa a probabilidade de o consumidor realizar essa ação. Um dos principais fatores que impulsionam as organizações para a modelagem de propensão é a necessidade de fazer mais com os dados originais. Para exemplos de utilização de marketing, os melhores modelos de propensão incluem sinais de origens online e offline, como as estatísticas do site e os dados de CRM.
Esta demonstração usa dados de exemplo do GA4 que estão no BigQuery. Para o seu exemplo de utilização, recomendamos que considere sinais offline adicionais.
Como o MLOps simplifica os seus pipelines de ML
A maioria dos modelos de ML não é usada na produção. Os resultados do modelo geram estatísticas e, frequentemente, depois de as equipas de ciência de dados terminarem um modelo, uma equipa de engenharia de ML ou de engenharia de software tem de o envolver em código para produção através de uma framework, como Flask ou FastAPI. Este processo requer frequentemente que o modelo seja criado numa nova estrutura, o que significa que os dados têm de ser transformados novamente. Este trabalho pode demorar semanas ou meses e, por isso, muitos modelos não chegam à produção.
As operações de aprendizagem automática (MLOps) tornaram-se importantes para obter valor dos projetos de aprendizagem automática, e as MLOps são agora um conjunto de competências em evolução para as organizações de ciência de dados. Para ajudar as organizações a compreender este valor, Google Cloud publicou um guia para profissionais de MLOps que oferece uma vista geral das MLOps.
Se usar os princípios de MLOps e Google Cloud, pode enviar modelos para um ponto final através de um processo automático que remove grande parte da complexidade do processo manual. As ferramentas e o processo descritos neste documento abordam uma forma de ter controlo total do seu pipeline, o que ajuda a colocar os seus modelos em produção. O documento do guia para profissionais mencionado anteriormente oferece uma solução horizontal e um resumo do que é possível fazer com o MLOps e o Google Cloud.
O que são os Vertex AI Pipelines?
O Vertex AI Pipelines permite-lhe executar pipelines de ML criados com o Kubeflow Pipelines SDK ou o TensorFlow Extended (TFX). Sem o Vertex AI, a execução de qualquer uma destas frameworks de código aberto em grande escala requer a configuração e a manutenção dos seus próprios clusters do Kubernetes. O Vertex AI Pipelines resolve este desafio. Uma vez que é um serviço gerido, é dimensionado para cima ou para baixo conforme necessário e não requer manutenção contínua.
Cada passo no processo do Vertex AI Pipelines consiste num contentor independente que pode receber entradas ou produzir saídas sob a forma de artefactos. Por exemplo, se um passo no processo criar o seu conjunto de dados, a saída é o artefacto do conjunto de dados. Este artefacto do conjunto de dados pode ser usado como entrada para o passo seguinte. Uma vez que cada componente é um contentor separado, tem de fornecer informações para cada componente do pipeline, como o nome da imagem base e uma lista de dependências.
O processo de criação do pipeline
O exemplo descrito neste documento usa um bloco de notas do Jupyter para criar os componentes do pipeline e para os compilar, executar e automatizar. Conforme mencionado anteriormente, o bloco de notas está num repositório do GitHub.
Pode executar o código do bloco de notas através de uma instância de blocos de notas geridos pelo utilizador do Vertex AI Workbench, que processa a autenticação por si. O Vertex AI Workbench permite-lhe trabalhar com blocos de notas para criar máquinas, criar blocos de notas e estabelecer ligação ao Git. (O Vertex AI Workbench inclui muitas mais funcionalidades, mas estas não são abordadas neste documento.)
Quando a execução do pipeline termina, é gerado um diagrama semelhante ao seguinte no Vertex AI Pipelines:
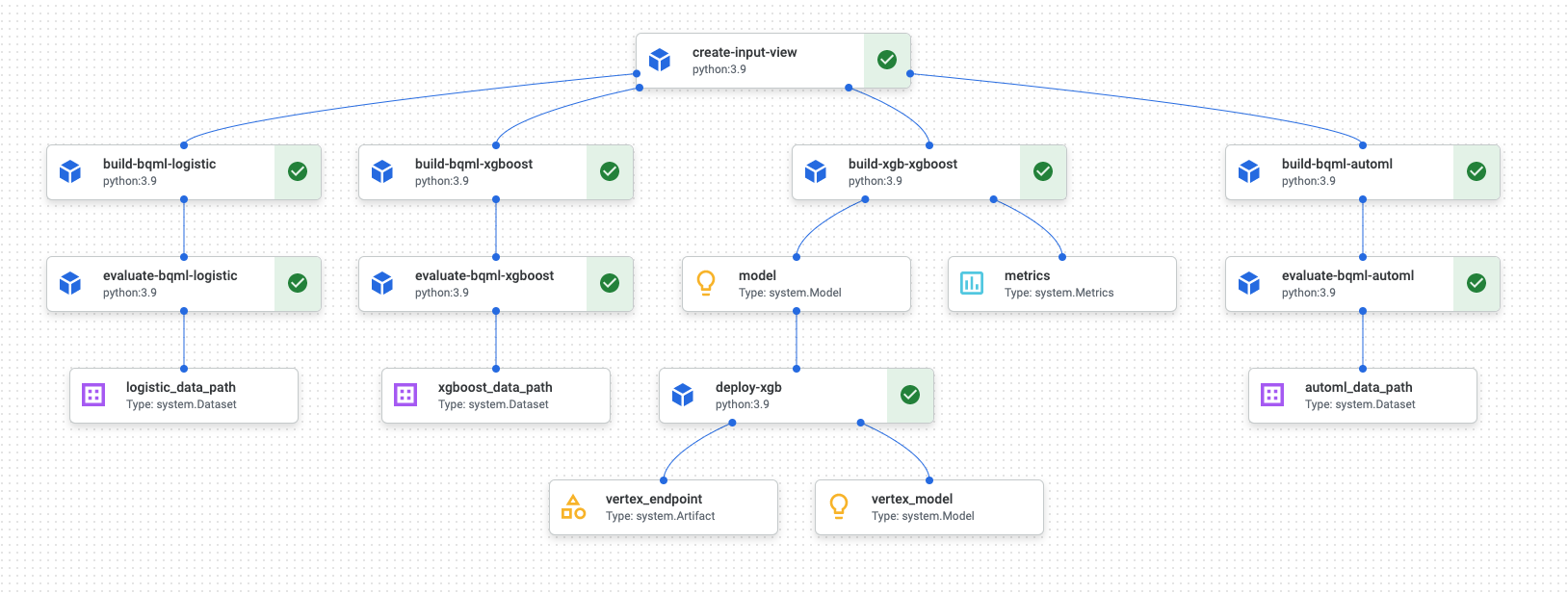
O diagrama anterior é um gráfico acíclico dirigido (DAG). A criação e a revisão do DAG são um passo central para compreender o seu pipeline de dados ou de ML. Os principais atributos dos DAGs são que os componentes fluem numa única direção (neste caso, de cima para baixo) e que não ocorre nenhum ciclo, ou seja, um componente principal não depende do respetivo componente secundário. Alguns componentes podem ocorrer em paralelo, enquanto outros têm dependências e, por isso, ocorrem em série.
A caixa de verificação verde em cada componente significa que o código foi executado corretamente. Se ocorrerem erros, é apresentado um ponto de exclamação vermelho. Pode clicar em cada componente no diagrama para ver mais detalhes da tarefa.
O diagrama DAG está incluído nesta secção do documento para servir como um projeto para cada componente criado pelo pipeline. A lista seguinte fornece uma descrição de cada componente.
O pipeline completo executa os seguintes passos, conforme mostrado no diagrama DAG:
create-input-view: este componente cria uma vista do BigQuery. O componente copia o SQL de um contentor do Cloud Storage e preenche os valores dos parâmetros que indicar. Esta vista do BigQuery é o conjunto de dados de entrada usado para todos os modelos mais tarde no pipeline.build-bqml-logistic: O pipeline usa o BigQuery ML para criar um modelo de regressão logística. Quando este componente estiver concluído, pode ver um novo modelo na consola do BigQuery. Pode usar este objeto de modelo para ver o desempenho do modelo e, mais tarde, criar previsões.evaluate-bqml-logistic: O pipeline usa este componente para criar uma curva de precisão/recolha (logistic_data_pathno diagrama DAG) para a regressão logística. Este artefacto está armazenado num contentor do Cloud Storage.build-bqml-xgboost: este componente cria um modelo XGBoost através do BigQuery ML. Quando este componente estiver concluído, pode ver um novo objeto de modelo (system.Model) na consola do BigQuery. Pode usar este objeto para ver o desempenho do modelo e, mais tarde, criar previsões.evaluate-bqml-xgboost: este componente cria uma curva de precisão/recolha denominadaxgboost_data_pathpara o modelo XGBoost. Este artefacto está armazenado num contentor do Cloud Storage.build-xgb-xgboost: o pipeline cria um modelo XGBoost. Este componente usa Python em vez do BigQuery ML para que possa ver abordagens diferentes para criar o modelo. Quando este componente estiver concluído, armazena um objeto de modelo e métricas de desempenho num contentor do Cloud Storage.deploy-xgb: este componente implementa o modelo XGBoost. Cria um ponto final que permite previsões em lote ou online. Pode explorar o ponto final no separador Modelos na página da consola do Vertex AI. O ponto final é dimensionado automaticamente para corresponder ao tráfego.build-bqml-automl: o pipeline cria um modelo do AutoML através do BigQuery ML. Quando este componente estiver concluído, é possível ver um novo objeto de modelo na consola do BigQuery. Pode usar este objeto para ver o desempenho do modelo e, mais tarde, para criar previsões.evaluate-bqml-automl: O pipeline cria uma curva de precisão/recolha para o modelo do AutoML. O artefacto é armazenado num contentor do Cloud Storage.
Tenha em atenção que o processo não envia os modelos do BigQuery ML para um ponto final. Isto deve-se ao facto de poder gerar previsões diretamente a partir do objeto do modelo no BigQuery. Ao decidir entre usar o BigQuery ML e usar outras bibliotecas para a sua solução, considere como as previsões têm de ser geradas. Se uma previsão em lote diária satisfizer as suas necessidades, permanecer no ambiente do BigQuery pode simplificar o seu fluxo de trabalho. No entanto, se precisar de previsões em tempo real ou se o seu cenário precisar de funcionalidades que se encontram noutra biblioteca, siga os passos descritos neste documento para enviar o modelo guardado para um ponto final.
Custos
Neste documento, usa os seguintes componentes faturáveis do Google Cloud:
Para gerar uma estimativa de custos com base na sua utilização projetada,
use a calculadora de preços.
Antes de começar
- Sign in to your Google Cloud account. If you're new to Google Cloud, create an account to evaluate how our products perform in real-world scenarios. New customers also get $300 in free credits to run, test, and deploy workloads.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
- Na Google Cloud consola, selecione o projeto onde quer criar o bloco de notas.
Aceda à página do Vertex AI Workbench.
No separador Blocos de notas geridos pelo utilizador, clique em Novo bloco de notas.
Na lista de tipos de blocos de notas, escolha um bloco de notas Python 3.
Na caixa de diálogo Novo bloco de notas, clique em Opções avançadas e, de seguida, em Tipo de máquina, selecione o tipo de máquina que quer usar. Se não tiver a certeza, escolha n1-standard-1 (1 cVPU, 3,75 GB de RAM).
Clique em Criar.
Demora alguns momentos até que o ambiente do bloco de notas seja criado.
Quando o notebook for criado, selecione-o e, de seguida, clique em Abrir Jupyterlab.
O ambiente JupyterLab é aberto no seu navegador.
Para iniciar um separador do terminal, selecione Ficheiro > Novo > Launcher.
Clique no ícone Terminal no separador Launcher.
No terminal, clone o repositório do GitHub
mlops-on-gcp:git clone https://github.com/GoogleCloudPlatform/cloud-for-marketing/
Quando o comando terminar, vê a pasta
cloud-for-marketingno explorador de ficheiros.- Crie um contentor do Cloud Storage onde o bloco de notas pode armazenar artefactos do pipeline. O nome do contentor tem de ser exclusivo a nível global.
- Na pasta
cloud-for-marketing/marketing-analytics/predicting/kfp_pipeline/, abra o notebookPropensity_Pipeline.ipynb. - No bloco de notas, defina o valor da variável
PROJECT_IDpara o ID do projeto onde quer executar o pipeline. Google Cloud - Defina o valor da variável
BUCKET_NAMEpara o nome do contentor que acabou de criar. - Criou um conjunto de dados de entrada.
- Preparou vários modelos com o BigQuery ML e o XGBoost do Python.
- Resultados do modelo analisados.
- Implementou o modelo XGBoost.
- In the Google Cloud console, go to the Manage resources page.
- In the project list, select the project that you want to delete, and then click Delete.
- In the dialog, type the project ID, and then click Shut down to delete the project.
- Para saber como usar o MLOps para criar sistemas de ML preparados para produção, consulte o Guia prático do MLOps.
- Para saber mais sobre o Vertex AI, consulte a documentação do Vertex AI.
- Para saber mais sobre o Kubeflow Pipelines, consulte a documentação do KFP.
- Para saber mais sobre o TensorFlow Extended, consulte o manual do utilizador do TFX.
- Para uma vista geral dos princípios e recomendações de arquitetura específicos das cargas de trabalho de IA e ML no Google Cloud, consulte aperspetiva de IA e ML no Well-Architected Framework.
- Para ver mais arquiteturas de referência, diagramas e práticas recomendadas, explore o Centro de arquitetura na nuvem.
O Jupyter Notebook para este cenário
As tarefas de criação e compilação do pipeline estão incorporadas num bloco de notas do Jupyter que se encontra num repositório do GitHub.
Para realizar as tarefas, recebe o bloco de notas e, em seguida, executa as células de código no bloco de notas pela ordem indicada. O fluxo descrito neste documento pressupõe que está a executar os blocos de notas no Vertex AI Workbench.
Abra o ambiente do Vertex AI Workbench
Comece por clonar o repositório do GitHub num ambiente do Vertex AI Workbench.
Configure as definições dos notebooks
Antes de executar o bloco de notas, tem de o configurar. O bloco de notas requer um contentor do Cloud Storage para armazenar artefactos do pipeline, pelo que começa por criar esse contentor.
O resto deste documento descreve fragmentos de código importantes para compreender o funcionamento do pipeline. Para a implementação completa, consulte o repositório do GitHub.
Crie a visualização do BigQuery
O primeiro passo no pipeline gera os dados de entrada, que vão ser usados para criar cada modelo. Este componente do Vertex AI Pipelines gera uma visualização de propriedade do BigQuery. Para simplificar o processo de criação da vista, algum SQL já foi gerado e guardado num ficheiro de texto no GitHub.
O código de cada componente começa por decorar (modificar uma classe principal ou uma função através de atributos) a classe de componentes do Vertex AI Pipelines. O código
define então a função create_input_view, que é uma etapa no pipeline.
A função requer várias entradas. Alguns destes valores estão atualmente
codificados no código, como a data de início e a data de fim. Quando automatiza o seu pipeline, pode modificar o código para usar valores adequados (por exemplo, usar a função CURRENT_DATE para uma data) ou pode atualizar o componente para usar estes valores como parâmetros, em vez de os manter codificados. Também tem de alterar o valor de ga_data_ref para o nome da sua tabela do GA4 e definir o valor da variável conversion para a sua conversão. (Este exemplo usa os dados de exemplo públicos do GA4.)
A seguinte listagem mostra o código do componente create-input-view.
@component( # this component builds a BigQuery view, which will be the underlying source for model packages_to_install=["google-cloud-bigquery", "google-cloud-storage"], base_image="python:3.9", output_component_file="output_component/create_input_view.yaml", ) def create_input_view(view_name: str, data_set_id: str, project_id: str, bucket_name: str, blob_path: str ): from google.cloud import bigquery from google.cloud import storage client = bigquery.Client(project=project_id) dataset = client.dataset(data_set_id) table_ref = dataset.table(view_name) ga_data_ref = 'bigquery-public-data.google_analytics_sample.ga_sessions_*' conversion = "hits.page.pageTitle like '%Shopping Cart%'" start_date = '20170101' end_date = '20170131' def get_sql(bucket_name, blob_path): from google.cloud import storage storage_client = storage.Client() bucket = storage_client.get_bucket(bucket_name) blob = bucket.get_blob(blob_path) content = blob.download_as_string() return content def if_tbl_exists(client, table_ref): ... else: content = get_sql() content = str(content, 'utf-8') create_base_feature_set_query = content. format(start_date = start_date, end_date = end_date, ga_data_ref = ga_data_ref, conversion = conversion) shared_dataset_ref = client.dataset(data_set_id) base_feature_set_view_ref = shared_dataset_ref.table(view_name) base_feature_set_view = bigquery.Table(base_feature_set_view_ref) base_feature_set_view.view_query = create_base_feature_set_query.format(project_id) base_feature_set_view = client.create_table(base_feature_set_view)
Crie o modelo do BigQuery ML
Depois de criar a visualização de propriedade, execute o componente denominado build_bqml_logistic para
criar um modelo do BigQuery ML. Este bloco do notebook é um componente
essencial. Usando a visualização de preparação que criou no primeiro bloco, cria um modelo do BigQuery ML. Neste exemplo, o bloco de notas usa a regressão logística.
Para obter informações sobre os tipos de modelos e os hiperparâmetros disponíveis, consulte a documentação de referência do BigQuery ML.
A seguinte lista mostra o código deste componente.
@component( # this component builds a logistic regression with BigQuery ML packages_to_install=["google-cloud-bigquery"], base_image="python:3.9", output_component_file="output_component/create_bqml_model_logistic.yaml" ) def build_bqml_logistic(project_id: str, data_set_id: str, model_name: str, training_view: str ): from google.cloud import bigquery client = bigquery.Client(project=project_id) model_name = f"{project_id}.{data_set_id}.{model_name}" training_set = f"{project_id}.{data_set_id}.{training_view}" build_model_query_bqml_logistic = ''' CREATE OR REPLACE MODEL `{model_name}` OPTIONS(model_type='logistic_reg' , INPUT_LABEL_COLS = ['label'] , L1_REG = 1 , DATA_SPLIT_METHOD = 'RANDOM' , DATA_SPLIT_EVAL_FRACTION = 0.20 ) AS SELECT * EXCEPT (fullVisitorId, label), CASE WHEN label is null then 0 ELSE label end as label FROM `{training_set}` '''.format(model_name = model_name, training_set = training_set) job_config = bigquery.QueryJobConfig() client.query(build_model_query_bqml_logistic, job_config=job_config)
Use o XGBoost em vez do BigQuery ML
O componente ilustrado na secção anterior usa o BigQuery ML. A secção seguinte dos blocos de notas mostra como usar o XGBoost diretamente em Python, em vez de usar o BigQuery ML.
Executa o componente denominado build_bqml_xgboost para criar o componente para executar um modelo de classificação XGBoost padrão com uma pesquisa de grelha. Em seguida, o código guarda o modelo como um artefacto no contentor do Cloud Storage que criou.
A função suporta parâmetros adicionais (metrics e model) para artefactos de saída. Estes parâmetros são necessários para os Vertex AI Pipelines.
@component( # this component builds an xgboost classifier with xgboost packages_to_install=["google-cloud-bigquery", "xgboost", "pandas", "sklearn", "joblib", "pyarrow"], base_image="python:3.9", output_component_file="output_component/create_xgb_model_xgboost.yaml" ) def build_xgb_xgboost(project_id: str, data_set_id: str, training_view: str, metrics: Output[Metrics], model: Output[Model] ): ... data_set = f"{project_id}.{data_set_id}.{training_view}" build_df_for_xgboost = ''' SELECT * FROM `{data_set}` '''.format(data_set = data_set) ... xgb_model = XGBClassifier(n_estimators=50, objective='binary:hinge', silent=True, nthread=1, eval_metric="auc") random_search = RandomizedSearchCV(xgb_model, param_distributions=params, n_iter=param_comb, scoring='precision', n_jobs=4, cv=skf.split(X_train,y_train), verbose=3, random_state=1001 ) random_search.fit(X_train, y_train) xgb_model_best = random_search.best_estimator_ predictions = xgb_model_best.predict(X_test) score = accuracy_score(y_test, predictions) auc = roc_auc_score(y_test, predictions) precision_recall = precision_recall_curve(y_test, predictions) metrics.log_metric("accuracy",(score * 100.0)) metrics.log_metric("framework", "xgboost") metrics.log_metric("dataset_size", len(df)) metrics.log_metric("AUC", auc) dump(xgb_model_best, model.path + ".joblib")
Crie um ponto final
Executa o componente denominado deploy_xgb para criar um ponto final através do modelo XGBoost da secção anterior. O componente usa o artefacto do modelo XGBoost anterior, cria um contentor e, em seguida, implementa o ponto final, ao mesmo tempo que fornece o URL do ponto final como um artefacto para que o possa ver. Quando este passo estiver concluído, é criado um ponto final da Vertex AI e pode ver o ponto final na página da consola da Vertex AI.
@component( # Deploys xgboost model packages_to_install=["google-cloud-aiplatform", "joblib", "sklearn", "xgboost"], base_image="python:3.9", output_component_file="output_component/xgboost_deploy_component.yaml", ) def deploy_xgb( model: Input[Model], project_id: str, vertex_endpoint: Output[Artifact], vertex_model: Output[Model] ): from google.cloud import aiplatform aiplatform.init(project=project_id) deployed_model = aiplatform.Model.upload( display_name="tai-propensity-test-pipeline", artifact_uri = model.uri.replace("model", ""), serving_container_image_uri="us-docker.pkg.dev/vertex-ai/prediction/xgboost-cpu.1-4:latest" ) endpoint = deployed_model.deploy(machine_type="n1-standard-4") # Save data to the output params vertex_endpoint.uri = endpoint.resource_name vertex_model.uri = deployed_model.resource_name
Defina o pipeline
Para definir o pipeline, define cada operação com base nos componentes que criou anteriormente. Em seguida, pode especificar a ordem dos elementos da pipeline se não forem chamados explicitamente no componente.
Por exemplo, o código seguinte no bloco de notas define um pipeline. Neste caso, o código requer que o componente build_bqml_logistic_op seja executado após o componente create_input_view_op.
@dsl.pipeline( # Default pipeline root. You can override it when submitting the pipeline. pipeline_root=PIPELINE_ROOT, # A name for the pipeline. name="pipeline-test", description='Propensity BigQuery ML Test' ) def pipeline(): create_input_view_op = create_input_view( view_name = VIEW_NAME, data_set_id = DATA_SET_ID, project_id = PROJECT_ID, bucket_name = BUCKET_NAME, blob_path = BLOB_PATH ) build_bqml_logistic_op = build_bqml_logistic( project_id = PROJECT_ID, data_set_id = DATA_SET_ID, model_name = 'bqml_logistic_model', training_view = VIEW_NAME ) # several components have been deleted for brevity build_bqml_logistic_op.after(create_input_view_op) build_bqml_xgboost_op.after(create_input_view_op) build_bqml_automl_op.after(create_input_view_op) build_xgb_xgboost_op.after(create_input_view_op) evaluate_bqml_logistic_op.after(build_bqml_logistic_op) evaluate_bqml_xgboost_op.after(build_bqml_xgboost_op) evaluate_bqml_automl_op.after(build_bqml_automl_op)
Compile e execute a pipeline
Agora, pode compilar e executar o pipeline.
O código seguinte no bloco de notas define o valor enable_caching como verdadeiro para ativar a colocação em cache. Quando o armazenamento em cache está ativado, as execuções anteriores em que um componente foi concluído com êxito não são executadas novamente. Esta flag é útil, especialmente, quando está a testar o pipeline, porque quando o armazenamento em cache está ativado, a execução é concluída mais rapidamente e usa menos recursos.
compiler.Compiler().compile( pipeline_func=pipeline, package_path="pipeline.json" ) TIMESTAMP = datetime.now().strftime("%Y%m%d%H%M%S") run = pipeline_jobs.PipelineJob( display_name="test-pipeine", template_path="pipeline.json", job_id="test-{0}".format(TIMESTAMP), enable_caching=True ) run.run()
Automatize o pipeline
Nesta fase, lançou o primeiro pipeline. Pode verificar a página Vertex AI Pipelines na consola para ver o estado desta tarefa. Pode ver a criação e a execução de cada contentor. Também pode acompanhar os erros de componentes específicos nesta secção clicando em cada um deles.
Para agendar o pipeline, cria uma função do Cloud Run e usa um agendador semelhante a uma tarefa cron.
O código na última secção do bloco de notas agenda a execução do pipeline uma vez por dia, conforme mostrado no seguinte fragmento do código:
from kfp.v2.google.client import AIPlatformClient api_client = AIPlatformClient(project_id=PROJECT_ID, region='us-central1' ) api_client.create_schedule_from_job_spec( job_spec_path='pipeline.json', schedule='0 * * * *', enable_caching=False )
Use o pipeline concluído em produção
O pipeline concluído realizou as seguintes tarefas:
Também automatizou o pipeline através de funções do Cloud Run e do Cloud Scheduler para execução diária.
O pipeline definido no bloco de notas foi criado para ilustrar formas de criar vários modelos. Não executaria o pipeline tal como está atualmente criado num cenário de produção. No entanto, pode usar este pipeline como um guia e modificar os componentes de acordo com as suas necessidades. Por exemplo, pode editar o processo de criação de funcionalidades para tirar partido dos seus dados, modificar os intervalos de datas e, talvez, criar modelos alternativos. Também escolheria o modelo entre os ilustrados que melhor satisfaz os seus requisitos de produção.
Quando o pipeline estiver pronto para produção, pode implementar tarefas adicionais. Por exemplo, pode implementar um modelo campeão/desafiador, em que é criado um novo modelo todos os dias e tanto o novo modelo (o desafiador) como o existente (o campeão) são classificados com base em novos dados. Só coloca o novo modelo em produção se o respetivo desempenho for melhor do que o desempenho do modelo atual. Para monitorizar o progresso do seu sistema, também pode manter um registo do desempenho do modelo de cada dia e visualizar o desempenho das tendências.
Limpar
O que se segue?
Colaboradores
Autor: Tai Conley | Cloud Customer Engineer
Outro colaborador: Lars Ahlfors | Cloud Customer Engineer