En este documento se describe un ejemplo de una canalización implementada en Google Cloud que realiza modelización de la propensión. Está pensada para ingenieros de datos, ingenieros de aprendizaje automático o equipos de ciencia de marketing que crean y despliegan modelos de aprendizaje automático. En este documento se presupone que conoces los conceptos de aprendizaje automático y que estás familiarizado con Google Cloud, BigQuery, Vertex AI Pipelines, Python y los cuadernos de Jupyter. También se presupone que conoce Google Analytics 4 y la función de exportación sin procesar de BigQuery.
La canalización con la que trabajas usa datos de muestra de Google Analytics. La canalización crea varios modelos con BigQuery ML y XGBoost, y tú la ejecutas con Vertex AI Pipelines. En este documento se describen los procesos de entrenamiento, evaluación y despliegue de los modelos. También se describe cómo puede automatizar todo el proceso.
El código completo de la canalización se encuentra en un cuaderno de Jupyter en un repositorio de GitHub.
¿Qué es la modelización de la propensión?
Los modelos de propensión predicen las acciones que pueden llevar a cabo los consumidores. Entre los ejemplos de modelización de la propensión se incluyen la predicción de qué consumidores es probable que compren un producto, se suscriban a un servicio o incluso dejen de ser clientes activos de una marca.
El resultado de un modelo de propensión es una puntuación entre 0 y 1 para cada consumidor, donde esta puntuación representa la probabilidad de que el consumidor realice esa acción. Uno de los principales factores que impulsan a las organizaciones a adoptar modelos de propensión es la necesidad de sacar más partido a los datos propios. En los casos prácticos de marketing, los mejores modelos de propensión incluyen señales de fuentes online y offline, como las analíticas del sitio y los datos del CRM.
En esta demostración se usan datos de muestra de GA4 que están en BigQuery. En tu caso, puede que te interese tener en cuenta señales offline adicionales.
Cómo simplifican las operaciones de aprendizaje automático tus flujos de procesamiento de aprendizaje automático
La mayoría de los modelos de aprendizaje automático no se usan en producción. Los resultados del modelo generan estadísticas y, con frecuencia, después de que los equipos de ciencia de datos terminan un modelo, un equipo de ingeniería de aprendizaje automático o de ingeniería de software debe envolverlo en código para la producción mediante un framework como Flask u FastAPI. Este proceso suele requerir que el modelo se cree en un nuevo marco, lo que significa que los datos deben volver a transformarse. Este trabajo puede llevar semanas o meses, por lo que muchos modelos no llegan a la fase de producción.
Las operaciones de aprendizaje automático (MLOps) se han convertido en un elemento importante para obtener valor de los proyectos de aprendizaje automático. Además, MLOps es ahora un conjunto de habilidades en evolución para las organizaciones de ciencia de datos. Para ayudar a las organizaciones a comprender este valor, Google Cloud ha publicado una guía para profesionales sobre MLOps que ofrece una descripción general de esta metodología.
Si usas los principios de MLOps y Google Cloud, puedes enviar modelos a un endpoint mediante un proceso automático que elimina gran parte de la complejidad del proceso manual. Las herramientas y el proceso descritos en este documento proponen un enfoque para gestionar tu canalización de principio a fin, lo que te ayudará a poner tus modelos en producción. En la guía para profesionales que hemos mencionado anteriormente se ofrece una solución horizontal y un resumen de lo que se puede hacer con MLOps y Google Cloud.
¿Qué es Vertex AI Pipelines?
Vertex AI Pipelines te permite ejecutar las canalizaciones de aprendizaje automático que se han creado con el SDK de Kubeflow Pipelines o con TensorFlow Extended (TFX). Sin Vertex AI, para ejecutar cualquiera de estos frameworks de código abierto a gran escala, debes configurar y mantener tus propios clústeres de Kubernetes. Vertex AI Pipelines resuelve este problema. Como se trata de un servicio gestionado, se amplía o se reduce según sea necesario y no requiere mantenimiento continuo.
Cada paso del proceso de Vertex AI Pipelines consta de un contenedor independiente que puede recibir entradas o generar salidas en forma de artefactos. Por ejemplo, si un paso del proceso crea tu conjunto de datos, la salida es el artefacto del conjunto de datos. Este artefacto de conjunto de datos se puede usar como entrada en el siguiente paso. Como cada componente es un contenedor independiente, debes proporcionar información sobre cada componente de la canalización, como el nombre de la imagen base y una lista de las dependencias.
Proceso de compilación de la canalización
En el ejemplo descrito en este documento se usa un cuaderno de Jupyter para crear los componentes de la canalización, así como para compilarlos, ejecutarlos y automatizarlos. Como se ha indicado anteriormente, el cuaderno se encuentra en un repositorio de GitHub.
Puedes ejecutar el código del cuaderno con una instancia de cuaderno gestionado por el usuario de Vertex AI Workbench, que se encarga de la autenticación. Vertex AI Workbench te permite trabajar con cuadernos para crear máquinas, compilar cuadernos y conectarte a Git. Vertex AI Workbench incluye muchas más funciones, pero no se tratan en este documento.
Cuando finalice la ejecución del flujo de procesamiento, se generará un diagrama similar al siguiente en Vertex AI Pipelines:
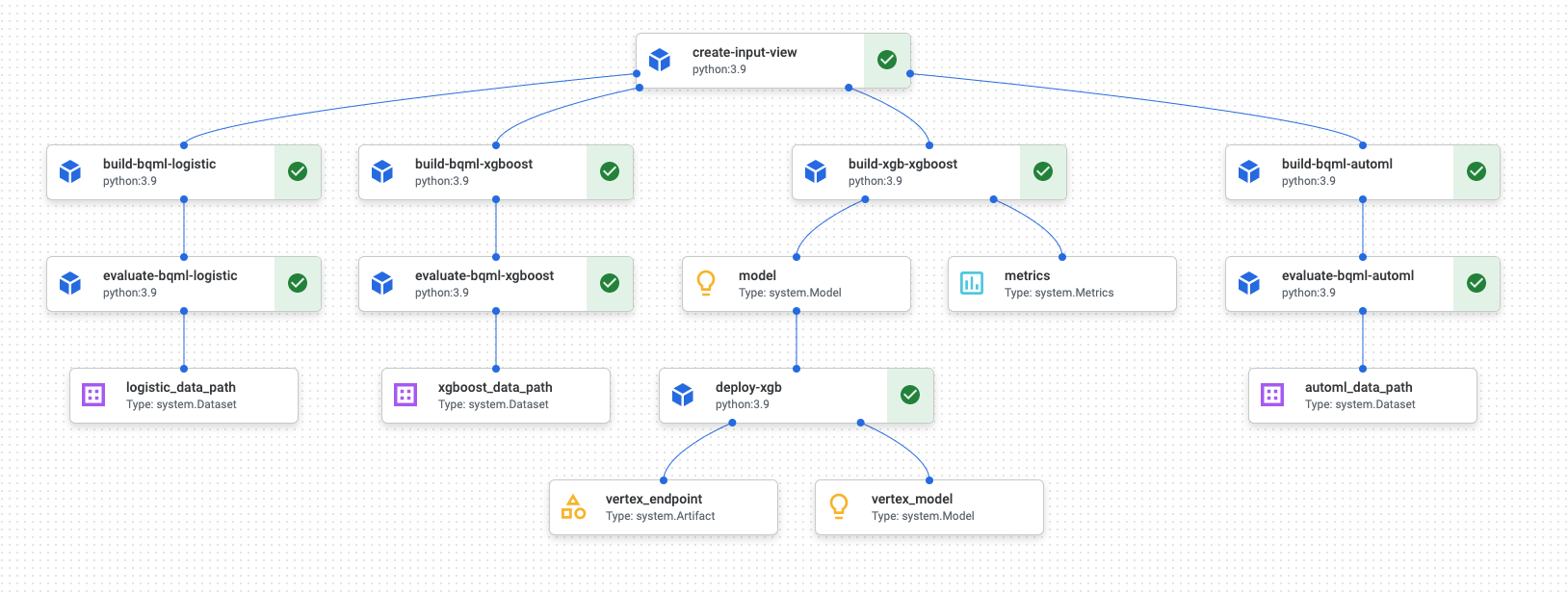
El diagrama anterior es un grafo acíclico dirigido (DAG). Crear y revisar el DAG es un paso fundamental para comprender tu flujo de procesamiento de datos o de aprendizaje automático. Los atributos clave de los DAGs son que los componentes fluyen en una sola dirección (en este caso, de arriba abajo) y que no se produce ningún ciclo, es decir, un componente superior no depende de su componente secundario. Algunos componentes pueden producirse en paralelo, mientras que otros tienen dependencias y, por lo tanto, se producen en serie.
La casilla verde de cada componente indica que el código se ha ejecutado correctamente. Si se han producido errores, verás un signo de exclamación rojo. Puedes hacer clic en cada componente del diagrama para ver más detalles del trabajo.
El diagrama de DAG se incluye en esta sección del documento para que sirva de plano técnico de cada componente que crea la canalización. En la siguiente lista se describe cada componente.
La canalización completa realiza los siguientes pasos, tal como se muestra en el diagrama de DAG:
create-input-view: este componente crea una vista de BigQuery. El componente copia SQL de un segmento de Cloud Storage y rellena los valores de los parámetros que proporciones. Esta vista de BigQuery es el conjunto de datos de entrada que se usa en todos los modelos posteriores de la canalización.build-bqml-logistic: la canalización usa BigQuery ML para crear un modelo de regresión logística. Cuando se complete este componente, se podrá ver un nuevo modelo en la consola de BigQuery. Puedes usar este objeto de modelo para ver el rendimiento del modelo y, más adelante, para crear predicciones.evaluate-bqml-logistic: el flujo de procesamiento usa este componente para crear una curva de precisión y recuperación (logistic_data_pathen el diagrama de DAG) para la regresión logística. Este artefacto se almacena en un segmento de Cloud Storage.build-bqml-xgboost: este componente crea un modelo XGBoost mediante BigQuery ML. Cuando se complete este componente, podrás ver un objeto de modelo nuevo (system.Model) en la consola de BigQuery. Puede usar este objeto para ver el rendimiento del modelo y, más adelante, para crear predicciones.evaluate-bqml-xgboost: este componente crea una curva de precisión/recuerdo llamadaxgboost_data_pathpara el modelo XGBoost. Este artefacto se almacena en un segmento de Cloud Storage.build-xgb-xgboost: la canalización crea un modelo XGBoost. Este componente usa Python en lugar de BigQuery ML para que puedas ver diferentes enfoques para crear el modelo. Cuando este componente se completa, almacena un objeto de modelo y métricas de rendimiento en un segmento de Cloud Storage.deploy-xgb: este componente implementa el modelo XGBoost. Crea un endpoint que permite hacer predicciones online o por lotes. Puedes consultar el endpoint en la pestaña Modelos de la página de la consola de Vertex AI. El endpoint se escala automáticamente para adaptarse al tráfico.build-bqml-automl: La canalización crea un modelo de AutoML con BigQuery ML. Cuando se complete este componente, se podrá ver un nuevo objeto de modelo en la consola de BigQuery. Puedes usar este objeto para ver el rendimiento del modelo y, más adelante, para crear predicciones.evaluate-bqml-automl: La canalización crea una curva de precisión/recall para el modelo de AutoML. El artefacto se almacena en un segmento de Cloud Storage.
Ten en cuenta que el proceso no envía los modelos de BigQuery ML a un endpoint. Esto se debe a que puedes generar predicciones directamente a partir del objeto del modelo que está en BigQuery. Cuando decidas si usar BigQuery ML u otras bibliotecas para tu solución, ten en cuenta cómo se deben generar las predicciones. Si una predicción por lotes diaria satisface tus necesidades, puedes simplificar tu flujo de trabajo permaneciendo en el entorno de BigQuery. Sin embargo, si necesitas predicciones en tiempo real o si tu situación requiere funciones que se encuentran en otra biblioteca, sigue los pasos que se indican en este documento para enviar tu modelo guardado a un endpoint.
Costes
En este documento, se utilizan los siguientes componentes facturables de Google Cloud:
Para generar una estimación de costes basada en el uso previsto,
utiliza la calculadora de precios.
Antes de empezar
- Sign in to your Google Cloud account. If you're new to Google Cloud, create an account to evaluate how our products perform in real-world scenarios. New customers also get $300 in free credits to run, test, and deploy workloads.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
- En la Google Cloud consola, selecciona el proyecto en el que quieras crear el cuaderno.
Ve a la página Vertex AI Workbench.
En la pestaña Notebooks gestionados por el usuario, haz clic en Nuevo cuaderno.
En la lista de tipos de cuaderno, elige un cuaderno de Python 3.
En el cuadro de diálogo Nuevo cuaderno, haz clic en Opciones avanzadas y, a continuación, en Tipo de máquina, selecciona el tipo de máquina que quieras usar. Si no lo tienes claro, elige n1-standard-1 (1 cVPU, 3,75 GB de RAM).
Haz clic en Crear.
El entorno del cuaderno tardará unos instantes en crearse.
Cuando se haya creado el cuaderno, selecciónalo y haz clic en Abrir JupyterLab.
El entorno de JupyterLab se abre en tu navegador.
Para abrir una pestaña de terminal, selecciona Archivo > Nuevo > Launcher.
Haz clic en el icono Terminal de la pestaña Menú de aplicaciones.
En el terminal, clona el repositorio de GitHub
mlops-on-gcp:git clone https://github.com/GoogleCloudPlatform/cloud-for-marketing/
Cuando se complete el comando, verás la carpeta
cloud-for-marketingen el explorador de archivos.- Crea un segmento de Cloud Storage donde el cuaderno pueda almacenar los artefactos de la canalización. El nombre del segmento debe ser único de forma global.
- En la carpeta
cloud-for-marketing/marketing-analytics/predicting/kfp_pipeline/, abre el cuadernoPropensity_Pipeline.ipynb. - En el cuaderno, asigna a la variable
PROJECT_IDel ID del Google Cloud proyecto en el que quieras ejecutar la canalización. - Asigna a la variable
BUCKET_NAMEel nombre del bucket que acabas de crear. - Se ha creado un conjunto de datos de entrada.
- Entrenó varios modelos con BigQuery ML y con XGBoost de Python.
- Resultados del modelo analizados.
- Se ha desplegado el modelo XGBoost.
- In the Google Cloud console, go to the Manage resources page.
- In the project list, select the project that you want to delete, and then click Delete.
- In the dialog, type the project ID, and then click Shut down to delete the project.
- Para obtener información sobre cómo usar MLOps para crear sistemas de aprendizaje automático listos para producción, consulta la guía para profesionales de MLOps.
- Para obtener información sobre Vertex AI, consulta la documentación de Vertex AI.
- Para obtener información sobre Kubeflow Pipelines, consulta la documentación de KFP.
- Para obtener información sobre TensorFlow Extended, consulta la guía de usuario de TFX.
- Para obtener una descripción general de los principios y las recomendaciones de arquitectura específicos de las cargas de trabajo de IA y aprendizaje automático en Google Cloud, consulta la sección Perspectiva de IA y aprendizaje automático del framework Well-Architected.
- Para ver más arquitecturas de referencia, diagramas y prácticas recomendadas, consulta el centro de arquitectura de Cloud.
El cuaderno de Jupyter de este caso práctico
Las tareas para crear y compilar la canalización están integradas en un cuaderno de Jupyter que se encuentra en un repositorio de GitHub.
Para realizar las tareas, obtén el cuaderno y, a continuación, ejecuta las celdas de código del cuaderno en orden. En el flujo descrito en este documento se presupone que ejecutas los cuadernos en Vertex AI Workbench.
Abrir el entorno de Vertex AI Workbench
Para empezar, clona el repositorio de GitHub en un entorno de Vertex AI Workbench.
Configurar los ajustes de los cuadernos
Antes de ejecutar el cuaderno, debes configurarlo. El cuaderno requiere un segmento de Cloud Storage para almacenar los artefactos de la canalización, por lo que debes empezar creando ese segmento.
En el resto de este documento se describen fragmentos de código importantes para entender cómo funciona la canalización. Para ver la implementación completa, consulta el repositorio de GitHub.
Crear la vista de BigQuery
El primer paso de la canalización genera los datos de entrada, que se usarán para crear cada modelo. Este componente de Vertex AI Pipelines genera una vista de BigQuery. Para simplificar el proceso de creación de la vista, se ha generado y guardado código SQL en un archivo de texto en GitHub.
El código de cada componente empieza por decorar (modificar una clase o función principal mediante atributos) la clase del componente Vertex AI Pipelines. A continuación, el código define la función create_input_view, que es un paso de la canalización.
La función requiere varias entradas. Algunos de estos valores están codificados de forma rígida en el código, como la fecha de inicio y la fecha de finalización. Cuando automatiza su canalización, puede modificar el código para usar los valores adecuados (por ejemplo, usar la función CURRENT_DATE para una fecha) o actualizar el componente para que tome estos valores como parámetros en lugar de mantenerlos codificados. También debe cambiar el valor de ga_data_ref por el nombre de su tabla de GA4 y asignar a la variable conversion el valor de su conversión. En este ejemplo se usan los datos de muestra públicos de GA4.
En el siguiente listado se muestra el código del componente create-input-view.
@component( # this component builds a BigQuery view, which will be the underlying source for model packages_to_install=["google-cloud-bigquery", "google-cloud-storage"], base_image="python:3.9", output_component_file="output_component/create_input_view.yaml", ) def create_input_view(view_name: str, data_set_id: str, project_id: str, bucket_name: str, blob_path: str ): from google.cloud import bigquery from google.cloud import storage client = bigquery.Client(project=project_id) dataset = client.dataset(data_set_id) table_ref = dataset.table(view_name) ga_data_ref = 'bigquery-public-data.google_analytics_sample.ga_sessions_*' conversion = "hits.page.pageTitle like '%Shopping Cart%'" start_date = '20170101' end_date = '20170131' def get_sql(bucket_name, blob_path): from google.cloud import storage storage_client = storage.Client() bucket = storage_client.get_bucket(bucket_name) blob = bucket.get_blob(blob_path) content = blob.download_as_string() return content def if_tbl_exists(client, table_ref): ... else: content = get_sql() content = str(content, 'utf-8') create_base_feature_set_query = content. format(start_date = start_date, end_date = end_date, ga_data_ref = ga_data_ref, conversion = conversion) shared_dataset_ref = client.dataset(data_set_id) base_feature_set_view_ref = shared_dataset_ref.table(view_name) base_feature_set_view = bigquery.Table(base_feature_set_view_ref) base_feature_set_view.view_query = create_base_feature_set_query.format(project_id) base_feature_set_view = client.create_table(base_feature_set_view)
Crear el modelo de BigQuery ML
Una vez creada la vista, ejecuta el componente llamado build_bqml_logistic para crear un modelo de BigQuery ML. Este bloque del cuaderno es un componente principal. Con la vista de entrenamiento que has creado en el primer bloque, se crea un modelo de BigQuery ML. En este ejemplo, el cuaderno usa una regresión logística.
Para obtener información sobre los tipos de modelos y los hiperparámetros disponibles, consulta la documentación de referencia de BigQuery ML.
En la siguiente lista se muestra el código de este componente.
@component( # this component builds a logistic regression with BigQuery ML packages_to_install=["google-cloud-bigquery"], base_image="python:3.9", output_component_file="output_component/create_bqml_model_logistic.yaml" ) def build_bqml_logistic(project_id: str, data_set_id: str, model_name: str, training_view: str ): from google.cloud import bigquery client = bigquery.Client(project=project_id) model_name = f"{project_id}.{data_set_id}.{model_name}" training_set = f"{project_id}.{data_set_id}.{training_view}" build_model_query_bqml_logistic = ''' CREATE OR REPLACE MODEL `{model_name}` OPTIONS(model_type='logistic_reg' , INPUT_LABEL_COLS = ['label'] , L1_REG = 1 , DATA_SPLIT_METHOD = 'RANDOM' , DATA_SPLIT_EVAL_FRACTION = 0.20 ) AS SELECT * EXCEPT (fullVisitorId, label), CASE WHEN label is null then 0 ELSE label end as label FROM `{training_set}` '''.format(model_name = model_name, training_set = training_set) job_config = bigquery.QueryJobConfig() client.query(build_model_query_bqml_logistic, job_config=job_config)
Usar XGBoost en lugar de BigQuery ML
El componente ilustrado en la sección anterior usa BigQuery ML. En la siguiente sección de los cuadernos se muestra cómo usar XGBoost directamente en Python en lugar de usar BigQuery ML.
Ejecuta el componente llamado build_bqml_xgboost para crear el componente que ejecuta un modelo de clasificación XGBoost estándar con una búsqueda de cuadrícula. A continuación, el código guarda el modelo como un artefacto en el segmento de Cloud Storage que has creado.
La función admite parámetros adicionales (metrics y model) para los artefactos de salida. Vertex AI Pipelines requiere estos parámetros.
@component( # this component builds an xgboost classifier with xgboost packages_to_install=["google-cloud-bigquery", "xgboost", "pandas", "sklearn", "joblib", "pyarrow"], base_image="python:3.9", output_component_file="output_component/create_xgb_model_xgboost.yaml" ) def build_xgb_xgboost(project_id: str, data_set_id: str, training_view: str, metrics: Output[Metrics], model: Output[Model] ): ... data_set = f"{project_id}.{data_set_id}.{training_view}" build_df_for_xgboost = ''' SELECT * FROM `{data_set}` '''.format(data_set = data_set) ... xgb_model = XGBClassifier(n_estimators=50, objective='binary:hinge', silent=True, nthread=1, eval_metric="auc") random_search = RandomizedSearchCV(xgb_model, param_distributions=params, n_iter=param_comb, scoring='precision', n_jobs=4, cv=skf.split(X_train,y_train), verbose=3, random_state=1001 ) random_search.fit(X_train, y_train) xgb_model_best = random_search.best_estimator_ predictions = xgb_model_best.predict(X_test) score = accuracy_score(y_test, predictions) auc = roc_auc_score(y_test, predictions) precision_recall = precision_recall_curve(y_test, predictions) metrics.log_metric("accuracy",(score * 100.0)) metrics.log_metric("framework", "xgboost") metrics.log_metric("dataset_size", len(df)) metrics.log_metric("AUC", auc) dump(xgb_model_best, model.path + ".joblib")
Crear un endpoint
Ejecuta el componente llamado deploy_xgb para crear un endpoint con el modelo XGBoost de la sección anterior. El componente toma el artefacto del modelo XGBoost anterior, crea un contenedor y, a continuación, implementa el endpoint. También proporciona la URL del endpoint como artefacto para que puedas verla. Cuando se complete este paso, se habrá creado un endpoint de Vertex AI y podrás verlo en la página de la consola de Vertex AI.
@component( # Deploys xgboost model packages_to_install=["google-cloud-aiplatform", "joblib", "sklearn", "xgboost"], base_image="python:3.9", output_component_file="output_component/xgboost_deploy_component.yaml", ) def deploy_xgb( model: Input[Model], project_id: str, vertex_endpoint: Output[Artifact], vertex_model: Output[Model] ): from google.cloud import aiplatform aiplatform.init(project=project_id) deployed_model = aiplatform.Model.upload( display_name="tai-propensity-test-pipeline", artifact_uri = model.uri.replace("model", ""), serving_container_image_uri="us-docker.pkg.dev/vertex-ai/prediction/xgboost-cpu.1-4:latest" ) endpoint = deployed_model.deploy(machine_type="n1-standard-4") # Save data to the output params vertex_endpoint.uri = endpoint.resource_name vertex_model.uri = deployed_model.resource_name
Definir el flujo de procesamiento
Para definir la canalización, debes definir cada operación en función de los componentes que hayas creado anteriormente. A continuación, puedes especificar el orden de los elementos de la canalización si no se llaman explícitamente en el componente.
Por ejemplo, el siguiente código del cuaderno define una canalización. En este caso, el código requiere que el componente build_bqml_logistic_op se ejecute después del componente create_input_view_op.
@dsl.pipeline( # Default pipeline root. You can override it when submitting the pipeline. pipeline_root=PIPELINE_ROOT, # A name for the pipeline. name="pipeline-test", description='Propensity BigQuery ML Test' ) def pipeline(): create_input_view_op = create_input_view( view_name = VIEW_NAME, data_set_id = DATA_SET_ID, project_id = PROJECT_ID, bucket_name = BUCKET_NAME, blob_path = BLOB_PATH ) build_bqml_logistic_op = build_bqml_logistic( project_id = PROJECT_ID, data_set_id = DATA_SET_ID, model_name = 'bqml_logistic_model', training_view = VIEW_NAME ) # several components have been deleted for brevity build_bqml_logistic_op.after(create_input_view_op) build_bqml_xgboost_op.after(create_input_view_op) build_bqml_automl_op.after(create_input_view_op) build_xgb_xgboost_op.after(create_input_view_op) evaluate_bqml_logistic_op.after(build_bqml_logistic_op) evaluate_bqml_xgboost_op.after(build_bqml_xgboost_op) evaluate_bqml_automl_op.after(build_bqml_automl_op)
Compilar y ejecutar el flujo de procesamiento
Ahora puedes compilar y ejecutar la canalización.
El siguiente código del cuaderno asigna el valor true a enable_caching para habilitar el almacenamiento en caché. Si el almacenamiento en caché está habilitado, no se volverán a ejecutar las ejecuciones anteriores en las que un componente se haya completado correctamente. Esta marca es útil, sobre todo cuando se prueba la canalización, ya que, si la caché está habilitada, la ejecución se completa más rápido y usa menos recursos.
compiler.Compiler().compile( pipeline_func=pipeline, package_path="pipeline.json" ) TIMESTAMP = datetime.now().strftime("%Y%m%d%H%M%S") run = pipeline_jobs.PipelineJob( display_name="test-pipeine", template_path="pipeline.json", job_id="test-{0}".format(TIMESTAMP), enable_caching=True ) run.run()
Automatizar el flujo de trabajo
En este punto, ya has iniciado la primera canalización. Puedes consultar el estado de este trabajo en la página Vertex AI Pipelines de la consola. Puedes ver cómo se compila y se ejecuta cada contenedor. También puede monitorizar los errores de componentes específicos de esta sección haciendo clic en cada uno de ellos.
Para programar la canalización, crea una función de Cloud Run y usa un programador similar a una tarea cron.
El código de la última sección del cuaderno programa la ejecución de la canalización una vez al día, como se muestra en el siguiente fragmento de código:
from kfp.v2.google.client import AIPlatformClient api_client = AIPlatformClient(project_id=PROJECT_ID, region='us-central1' ) api_client.create_schedule_from_job_spec( job_spec_path='pipeline.json', schedule='0 * * * *', enable_caching=False )
Usar la canalización terminada en producción
La canalización completada ha realizado las siguientes tareas:
También has automatizado la canalización mediante funciones de Cloud Run y Cloud Scheduler para que se ejecute a diario.
La canalización definida en el cuaderno se creó para mostrar cómo crear varios modelos. No ejecutarías la canalización tal como está configurada en un escenario de producción. Sin embargo, puedes usar esta canalización como guía y modificar los componentes para adaptarlos a tus necesidades. Por ejemplo, puede editar el proceso de creación de funciones para aprovechar sus datos, modificar los intervalos de fechas y, quizás, crear modelos alternativos. También deberás elegir el modelo que mejor se adapte a tus requisitos de producción de entre los que se muestran.
Cuando la canalización esté lista para la producción, puedes implementar tareas adicionales. Por ejemplo, puedes implementar un modelo de campeón/retador, en el que cada día se crea un modelo nuevo y tanto el modelo nuevo (el retador) como el modelo actual (el campeón) se puntúan con datos nuevos. Solo pones en producción el nuevo modelo si su rendimiento es mejor que el del modelo actual. Para monitorizar el progreso de tu sistema, también puedes registrar el rendimiento del modelo de cada día y visualizar las tendencias de rendimiento.
Limpieza
Siguientes pasos
Colaboradores
Autor: Tai Conley | Ingeniero de clientes de Cloud
Otro colaborador: Lars Ahlfors | Ingeniero de clientes de Cloud