Nous vous recommandons de concevoir votre maillage de données de sorte qu'il se prête à une grande variété de cas d'utilisation pour la consommation de données. Ce document décrit les cas d'utilisation les plus courants relatifs à la consommation de données dans une organisation. Il explique également les informations que les utilisateurs de données doivent prendre en compte pour déterminer le produit de données adapté à leur cas d'utilisation, ainsi que la manière dont ils vont découvrir et utiliser ces produits de données. En intégrant ces facteurs, les organisations s'assurent de disposer des conseils et des outils adéquats pour répondre aux besoins des utilisateurs de données.
Ce document fait partie d'une série qui décrit comment implémenter un maillage de données sur Google Cloud. Nous partons du principe que vous avez lu et que vous connaissez les concepts décrits sur la page Architecture et fonctions dans un maillage de données et Créer un maillage de données moderne et distribué avec Google Cloud.
La série se compose des parties suivantes :
- Architecture et fonctions d'un maillage de données
- Concevoir une plate-forme de données en libre-service pour un maillage de données
- Créer des produits de données dans un maillage de données
- Découvrir et consommer des produits de données dans un maillage de données (ce document)
La conception d'une couche de consommation de données, en particulier la façon dont les utilisateurs basés sur un domaine vont exploiter les produits de données, dépend des exigences des utilisateurs de données. Nous partons du principe que les utilisateurs de données ciblent un cas d'utilisation précis. Nous présumons ainsi qu'ils ont identifié les données dont ils ont besoin, et qu'ils sont à même d'effectuer une recherche dans le catalogue central de produits de données pour y accéder. Si ces données ne figurent pas dans le catalogue ou ne sont pas dans l'état souhaité (par exemple, si l'interface n'est pas appropriée ou si les contrats de niveau de service sont insuffisants), l'utilisateur doit contacter le producteur de données.
L'utilisateur peut également contacter le centre d'excellence (COE) du maillage de données pour obtenir des conseils sur le domaine le plus adapté à la production de ce produit de données. L'utilisateur peut aussi demander comment envoyer sa requête. Si vous évoluez au sein d'une organisation de grande taille, un processus en libre-service doit être défini, permettant de mettre en évidence les demandes de produits de données.
Les utilisateurs de données exploitent les produits de données via les applications qu'ils exécutent. Le type d'insights requis permet de choisir la conception de l'application consommant les données. Lors du développement de la conception de l'application, les utilisateurs de données identifient également leur utilisation préférée des produits de données. Ils définissent la confiance à accorder à la fiabilité de ces données. Les utilisateurs de données peuvent ensuite établir une vue sur les interfaces des produits de données et les contrats de niveau de service requis par l'application.
Cas d'utilisation relatifs à la consommation des données
Pour que les utilisateurs de données créent des applications de données, les sources peuvent être un ou plusieurs produits de données et, éventuellement, les données issues du domaine de l'utilisateur de données. Comme décrit sur la page Créer des produits de données dans un maillage de données, des produits de données analytiques peuvent être créés à partir de produits de données basés sur différents dépôts de données physiques.
Bien que la consommation de données puisse intervenir dans le même domaine, les modèles de consommation les plus courants sont ceux qui recherchent le produit de données adapté, quel que soit le domaine, en tant que source de l'application. Lorsque ce produit de données adapté existe, mais dans un autre domaine, le modèle de consommation impose de configurer le mécanisme suivant pour accéder aux données et les utiliser, entre différents domaines. La consommation de produits de données créés dans des domaines autres que le domaine consommateur est décrite dans la section Étapes de la consommation des données.
Architecture
Le schéma suivant présente un exemple de scénario dans lequel les utilisateurs exploitent des produits de données via différentes interfaces, comprenant les ensembles de données et les API autorisés.
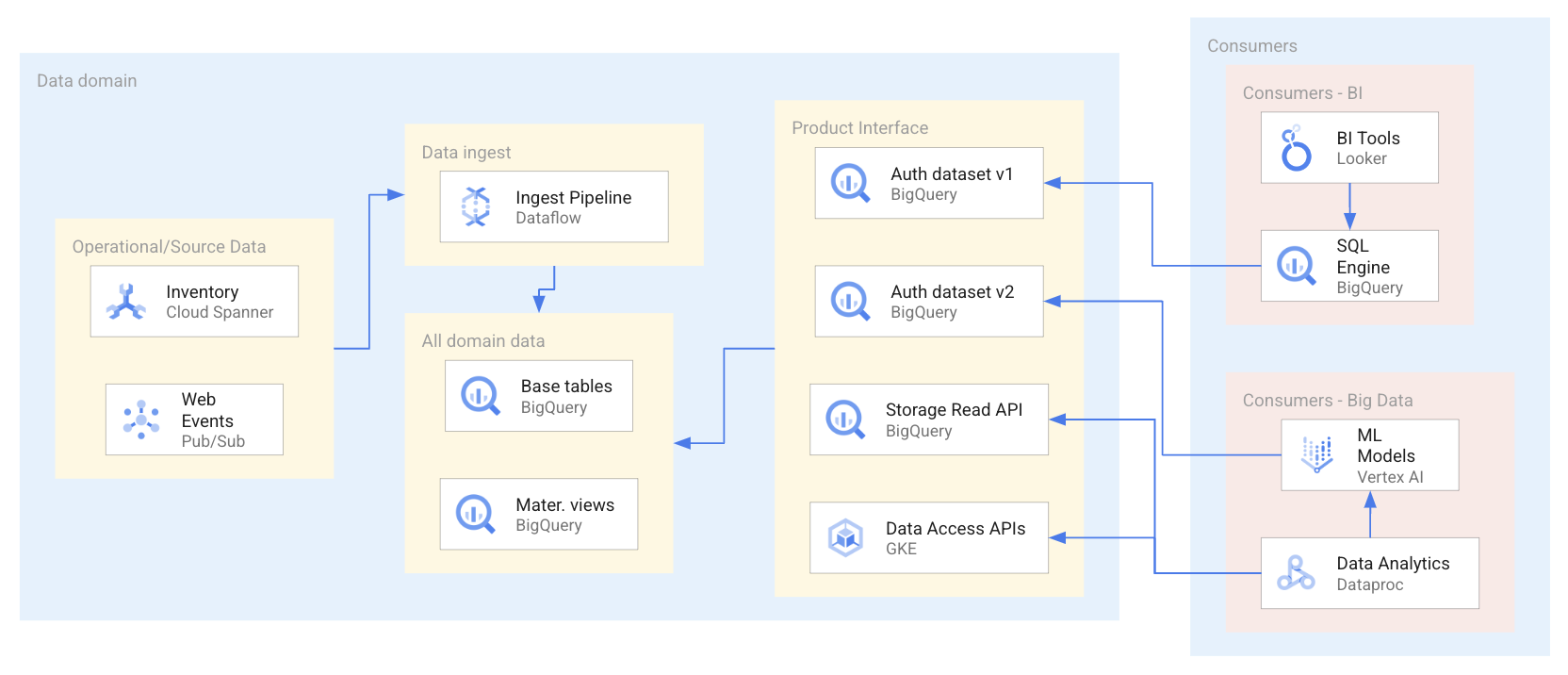
Comme le montre le schéma ci-dessus, le producteur de données a exposé quatre interfaces de produits de données : deux ensembles de données autorisés BigQuery, un ensemble de données BigQuery exposé par l'API BigQuery Storage Read et les API d'accès aux données hébergées sur Google Kubernetes Engine. Lorsqu'ils utilisent des produits de données, les utilisateurs de données exploitent toute une gamme d'applications qui interrogent les ressources de données qu'ils contiennent, ou y accèdent directement. Pour ce scénario, les utilisateurs de données accèdent aux ressources de données de deux manières différentes, selon leurs besoins spécifiques d'accès aux données. En premier lieu, Looker utilise BigQuery SQL pour interroger un ensemble de données autorisé. Avec la deuxième méthode, Dataproc accède directement à un ensemble de données via l'API BigQuery et traite les données ingérées pour entraîner un modèle de machine learning (ML).
L'utilisation d'une application de consommation de données n'entraîne pas toujours la création d'un rapport ou d'un tableau de bord d'informatique décisionnelle (BI). La consommation des données d'un domaine peut également entraîner des modèles de ML qui enrichissent les produits analytiques, qui sont utilisés dans l'analyse de données ou qui font partie de processus opérationnels, par exemple la détection des fraudes.
Voici quelques cas d'utilisation courants de la consommation de produits de données :
- Rapports BI et analyse de données : dans ce cas, les applications de données sont conçues pour consommer des données provenant de plusieurs produits de données. Par exemple, les utilisateurs de l'équipe de gestion de la relation client (CRM) ont besoin d'accéder aux données de plusieurs domaines, tels que les ventes, les clients et la finance. L'application CRM développée par ces utilisateurs de données peut avoir besoin d'interroger une vue autorisée BigQuery dans un domaine et d'extraire des données d'une API de lecture Cloud Storage dans un autre domaine. Au niveau des utilisateurs de données, les facteurs d'optimisation influant sur leur interface de consommation préférée sont les coûts de calcul et tout traitement de données supplémentaire requis après l'interrogation du produit de données. Dans les cas d'utilisation de l'informatique décisionnelle et de l'analyse de données, les vues autorisées BigQuery sont probablement les plus couramment utilisées.
- Cas d'utilisation de la data science et de l'entraînement de modèles : dans ce cas, l'équipe consommant les données utilise les produits de données d'autres domaines pour enrichir son propre produit de données analytiques, tel qu'un modèle de ML. En utilisantGoogle Cloud Serverless pour Apache Spark pour Spark, Google Cloud fournit des fonctionnalités de prétraitement des données et d'extraction de caractéristiques permettant d'enrichir les données avant d'exécuter des tâches de ML. Il est essentiel de disposer d'une quantité suffisante de données d'entraînement à un coût raisonnable et de savoir qu'elles sont appropriées. Dans une optique de maîtrise des coûts, les interfaces de consommation préférées sont probablement les API de lecture directe. Il est possible pour une équipe consommant des données de créer un modèle de ML en tant que produit de données. Cette équipe consommant des données devient alors une nouvelle équipe de production de données.
- Processus d'opérateur : la consommation fait partie des processus opérationnels au sein du domaine consommant des données. Par exemple, un utilisateur de données au sein d'une équipe chargée de traiter les fraudes peut utiliser des données de transaction, provenant de sources de données opérationnelles dans le domaine du marchand. En utilisant une méthode d'intégration de données telle que la capture des données modifiées, ces données de transaction sont interceptées quasiment en temps réel. Vous pouvez ensuite utiliser Pub/Sub afin de définir un schéma pour ces données, et exposer ces informations sous forme d'événements. Dans ce cas, les interfaces appropriées seraient les données exposées en tant que sujets Pub/Sub.
Étapes de la consommation des données
Les producteurs de données documentent leur produit de données dans le catalogue central, en intégrant des conseils sur les modalités d'utilisation de ces données. Pour une organisation comportant plusieurs domaines, cette approche de la documentation crée une architecture différente du pipeline traditionnel ELT/ETL, où les processeurs créent des sorties qui ne sont pas soumises aux limites des domaines d'activité. Pour créer un cycle de vie de consommation des données, les utilisateurs d'un maillage de données doivent disposer d'une couche de détection et de consommation bien conçue. Cette couche doit inclure les éléments suivants :
Étape 1 : découvrir les produits de données via la recherche déclarative et l'exploration des spécifications des produits de données : les utilisateurs de données sont libres de rechercher n'importe quel produit de données enregistré par les producteurs de données dans le catalogue central. Pour tous les produits de données, le tag du produit de données spécifie comment formuler les requêtes d'accès aux données, ainsi que le mode de consommation des données à partir de l'interface de produit de données requise. Les champs des tags de produits de données sont exploitables dans l'index des applications de recherche. Les interfaces de produits de données mettent en œuvre les URI de données, ce qui signifie que les données n'ont pas besoin d'être déplacées vers une zone de consommation distincte pour les clients des services. Dans les cas où les données en temps réel ne sont pas nécessaires, les utilisateurs de données interrogent les produits de données et créent des rapports avec les résultats générés.
Étape 2 : explorer les données via l'accès interactif aux données et le prototypage : les utilisateurs de données exploitent des outils interactifs tels que BigQuery Studio et les notebooks Jupyter pour interpréter et tester les données afin d'affiner les requêtes dont ils ont besoin pour l'utilisation en production. Les requêtes interactives permettent aux utilisateurs de données d'explorer des dimensions plus récentes des données et d'améliorer l'exactitude des insights générés dans les scénarios de production.
Étape 3 : consommer le produit de données via une application, avec un accès programmatique et en conditions de production :
- Rapports d'informatique décisionnelle. Les rapports et les tableaux de bord en quasi-temps réel ou par lot constituent le groupe le plus courant de cas d'utilisation requis par les utilisateurs de données analytiques. Les rapports peuvent nécessiter un accès aux produits inter-données pour faciliter la prise de décision. Par exemple, une plate-forme de données client nécessite d'interroger de manière programmatique les produits de données correspondant aux commandes et à la CRM, selon une approche planifiée. Les résultats d'une telle approche fournissent au client une vue globale sur les utilisateurs professionnels qui exploitent les données.
- Modèle d'IA/de ML pour la prédiction par lot et en temps réel. Les data scientists utilisent les principes MLOps courants pour créer et diffuser des modèles de ML qui consomment des produits de données mis à disposition par les équipes en charge de ces produits. Les modèles de ML fournissent des fonctionnalités d'inférence en temps réel pour les cas d'utilisation transactionnels, tels que la détection des fraudes. De même, avec l'analyse exploratoire des données, les utilisateurs de données peuvent enrichir les données sources. Par exemple, l'analyse exploratoire des données sur les ventes et les campagnes marketing montre parmi les clients les segments démographiques pour lesquels des chiffres d'affaires maximaux sont attendus, et auprès desquels des campagnes devraient par conséquent être menées.
Étapes suivantes
- Consultez une mise en œuvre de référence de l'architecture de maillage de données.
- Obtenez davantage d'informations sur BigQuery.
- Documentez-vous sur Vertex AI.
- Documentez-vous sur la data science dans Dataproc.
- Pour découvrir d'autres architectures de référence, schémas et bonnes pratiques, consultez le Centre d'architecture cloud.