Dans un maillage de données, une plate-forme de données en libre-service permet aux utilisateurs de générer de la valeur à partir de données en leur permettant de créer, de partager et d'utiliser des produits de données de manière autonome. Pour tirer pleinement parti de ces avantages, nous vous recommandons de doter votre plate-forme de données en libre-service des fonctions décrites dans ce document.
Ce document fait partie d'une série qui décrit comment implémenter un maillage de données sur Google Cloud. Nous partons du principe que vous avez lu et que vous connaissez les concepts décrits dans les pages Créer un maillage de données moderne et distribué avec Google Cloud et Architecture et fonctions dans un maillage de données.
La série se compose des parties suivantes :
- Architecture et fonctions d'un maillage de données
- Concevoir une plate-forme de données en libre-service pour un maillage de données (ce document)
- Créer des produits de données dans un maillage de données
- Découvrir et consommer des produits de données dans un maillage de données
Les équipes en charge des plates-formes de données créent généralement des plates-formes centrales de données en libre-service, comme décrit dans ce document. L'équipe concernée crée les solutions et les composants que les équipes des domaines (producteurs de données et consommateurs de données) peuvent utiliser à la fois pour créer et consommer des produits de données. Les équipes des domaines représentent les parties fonctionnelles d'un maillage de données. En créant ces composants, l'équipe en charge de la plate-forme de données assure une expérience de développement fluide et simplifie la création, le déploiement et la gestion de produits de données, lesquels sont sécurisés et interopérables.
À terme, l'équipe en charge de la plate-forme de données doit permettre aux équipes des domaines d'agir plus rapidement. Elle contribue ainsi à accroître l'efficacité des équipes des domaines en leur fournissant un ensemble limité d'outils répondant à leurs besoins. En fournissant ces outils, l'équipe en charge de la plate-forme de données évite à l'équipe des domaines d'avoir à créer et à charger ces outils elle-même. Les choix d'outils doivent être personnalisables en fonction des besoins pour ne pas imposer une méthode de travail rigide aux équipes des domaines de données.
L'équipe chargée de la plate-forme de données ne doit pas se concentrer sur la création de solutions personnalisées pour les orchestrateurs de pipelines de données ou sur les systèmes d'intégration et de déploiement continus (CI/CD). Des solutions telles que les systèmes CI/CD sont facilement disponibles en tant que services cloud gérés, comme Cloud Build. L'utilisation de services cloud gérés peut réduire les coûts opérationnels pour l'équipe chargée de la plate-forme de données et lui permettre de se concentrer sur les besoins spécifiques des équipes des domaines de données en tant qu'utilisateurs de la plate-forme. Avec des coûts opérationnels réduits, l'équipe en charge de la plate-forme de données peut se concentrer sur le traitement des besoins spécifiques des équipes chargées des domaines de données.
Architecture
Le schéma suivant illustre les composants d'architecture d'une plate-forme de données en libre-service. Le schéma montre également comment ces composants peuvent aider les équipes lors du développement et de l'utilisation des produits de données sur l'ensemble du maillage de données.

Comme le montre le schéma précédent, la plate-forme de données en libre-service fournit les éléments suivants :
Solutions de plate-forme : ces solutions sont constituées de composants modulables permettant de provisionner des projets et des ressources Google Cloud que les utilisateurs sélectionnent et assemblent dans différentes combinaisons pour répondre à leurs exigences spécifiques. Au lieu d'interagir directement avec les composants, les utilisateurs de la plate-forme peuvent interagir avec les solutions de la plate-forme pour atteindre un objectif spécifique. Les équipes chargées du domaine des données doivent concevoir des solutions de plate-forme pour résoudre les problèmes courants et les zones de frictions qui ralentissent le développement et la consommation des produits de données. Par exemple, les équipes en charge des domaines de données qui s'intègrent au maillage de données peuvent utiliser un modèle IaC (infrastructure-as-code). L'utilisation de modèles IaC permet de créer rapidement un ensemble de projetsGoogle Cloud dotés des autorisations IAM (Identity and Access Management) standards, de la mise en réseau, des règles de sécurité et des API Google Cloudpertinentes pour le développement de produits de données. Nous recommandons que chaque solution soit accompagnée d'une documentation comme un guide de démarrage et des exemples de code. Les solutions de plate-forme de données et leurs composants doivent être sécurisés et conformes par défaut.
Services communs : ces services fournissent la visibilité, la gestion, le partage et l'observabilité des produits de données. Ils favorisent la confiance des clients dans les produits de données et constituent un moyen efficace pour les producteurs de données d'alerter les consommateurs en cas de problème lié à leurs produits de données.
Les solutions et services communs de plate-forme de données peuvent inclure les éléments suivants :
- Modèles IaC permettant de configurer des environnements d'espace de travail de développement de produits de données de base, comprenant les éléments suivants :
- IAM
- Journalisation et surveillance
- Mise en réseau
- Garde-fous pour la sécurité et la conformité
- Ajout de tags aux ressources pour l'attribution de la facturation
- Stockage, transformation et publication des produits de données
- Enregistrement des produits de données, catalogage et ajout de tags aux métadonnées
- Modèles IaC qui respectent les garde-fous de sécurité organisationnelles et les bonnes pratiques pouvant être utilisées pour déployer des ressources Google Cloud dans des espaces de travail de développement de produits de données existants
- Modèles d'application et de pipeline de données peuvent être utilisés pour amorcer de nouveaux projets ou comme référence pour des projets existants. Exemples de modèles de ce type :
- Utilisation des bibliothèques et des frameworks communs
- Intégration avec les outils de journalisation, de surveillance et d'observabilité des plates-formes
- Outils de compilation et de test
- Gestion des configurations
- Packaging et pipelines CI/CD pour le déploiement
- Authentification, déploiement et gestion des identifiants
- Services communs permettant de fournir l'observabilité et la gouvernance des produits de données, pouvant inclure les éléments suivants :
- Tests de disponibilité permettant d'afficher l'état général des produits de données
- Métriques personnalisées permettant de fournir des indicateurs utiles sur les produits de données
- Assistance opérationnelle de l'équipe centrale permettant aux équipes chargées des consommateurs de données d'être informées des modifications apportées aux produits de données qu'elles utilisent
- Tableaux de données des produits permettant de visualiser les performances des produits concernés
- Un catalogue de métadonnées pour la découverte des produits de données
- Un ensemble défini de règles de calcul pouvant être appliquées à l'ensemble du maillage de données
- Une place de marché de données pour faciliter le partage de données entre les équipes des domaines
La section Créer des composants et des solutions de plate-forme à l'aide de modèles IaC décrit les avantages des modèles IaC pour exposer et déployer des produits de données. La section Fournir des services communs explique pourquoi il est utile de fournir aux équipes des domaines des composants d'infrastructure communs qui ont été créés et gérés par l'équipe chargée de la plate-forme de données.
Créer des composants et des solutions de plate-forme à l'aide de modèles IaC
L'objectif des équipes chargées des plates-formes de données est de configurer des plates-formes de données en libre-service afin d'exploiter plus efficacement les données. Pour créer ces plates-formes, elles créent et fournissent aux équipes des domaines des modèles d'infrastructure approuvés, sécurisés et en libre-service. Les équipes des domaines utilisent ces modèles pour déployer leurs environnements de développement et de consommation de données. Les modèles IaC permettent aux équipes chargées de la plate-forme de données d'atteindre cet objectif et d'assurer l'évolutivité. L'utilisation de modèles IaC approuvés et de confiance simplifie le processus de déploiement des ressources pour les équipes des domaines en leur permettant de réutiliser des pipelines CI/CD existants. Cette approche permet aux équipes des domaines de se lancer rapidement et de devenir productives dans le maillage de données.
Les modèles IaC peuvent être créés à l'aide d'un outil IaC. Bien qu'il existe plusieurs outils IaC, dont Cloud Config Connector, Pulumi, Chef et Ansible, ce document fournit des exemples d'outils IaC basés sur Terraform. Terraform est un outil IaC Open Source qui permet à l'équipe en charge de la plate-forme de données de créer efficacement des composants et des solutions composables de plate-forme pour les ressourcesGoogle Cloud . À l'aide de Terraform, l'équipe en charge de la plate-forme de données écrit du code qui spécifie l'état final souhaité et laisse l'outil déterminer comment atteindre cet état. Cette approche déclarative permet à l'équipe de la plate-forme de données de traiter les ressources d'infrastructure comme des artefacts immuables pour le déploiement dans tous les environnements. Cela permet également de réduire le risque d'incohérences entre les ressources déployées et le code déclaré dans le contrôle de la source (appelées écarts de configuration). Les écarts de configuration provoqués par des modifications ad hoc et manuelles de l'infrastructure entravent le déploiement sûr et reproductible des composants IaC dans les environnements de production.
Les modèles IaC courants pour les composants de plate-forme composable incluent l'utilisation de modules Terraform pour déployer des ressources telles qu'un ensemble de données BigQuery, un bucket Cloud Storage ou une base de données Cloud SQL. Les modules Terraform peuvent être combinés dans des solutions de bout en bout pour le déploiement de projets Google Cloud complets, y compris les ressources pertinentes déployées à l'aide des modules composables. Vous trouverez des exemples de modules Terraform dans les plans Terraform pour Google Cloud.
Chaque module Terraform doit par défaut respecter les garde-fous de sécurité et les règles de conformité utilisées par votre organisation. Ces garde-fous et ces règles peuvent également être exprimés sous forme de code et être automatisés à l'aide d'outils de validation de conformité automatisés, tels que l'outil de validation des règles de Google Cloud.
Votre organisation doit tester en continu les modules Terraform fournis par la plate-forme, en utilisant les mêmes garde-fous de conformité automatisés que ceux utilisés pour promouvoir les modifications en production.
Pour rendre les composants et les solutions IaC visibles et consommables pour les équipes des domaines disposant d'une expérience minimale avec Terraform, nous vous recommandons d'utiliser des services tels que Service Catalog. Les utilisateurs ayant des exigences de personnalisation importantes doivent être autorisés à créer leurs propres solutions de déploiement à partir des mêmes modèles Terraform composables que ceux utilisés par les solutions existantes.
Lorsque vous utilisez Terraform, nous vous recommandons de suivre les bonnes pratiques de Google Cloud, comme indiqué dans Bonnes pratiques d'utilisation de Terraform.
Pour illustrer comment Terraform permet de créer des composants de plate-forme, les sections suivantes décrivent des exemples d'utilisation de Terraform pour exposer des interfaces de consommation et consommer un produit de données.
Exposer une interface de consommation
Une interface de consommation d'un produit de données est un ensemble de garanties sur les paramètres opérationnels et de qualité des données fournis par l'équipe en charge des domaines de données afin de permettre aux autres équipes de découvrir et d'utiliser leurs produits de données. Chaque interface de consommation inclut également un modèle d'assistance et une documentation produit. Un produit de données peut présenter différents types d'interfaces de consommation, telles que des API ou des flux, comme décrit dans la section Créer des produits de données dans un maillage de données. L'interface de consommation la plus courante peut être un ensemble de données autorisé, une vue autorisée ou une fonction autorisée BigQuery. Cette interface expose une table virtuelle en lecture seule, exprimée sous la forme d'une requête dans le maillage de données. L'interface n'accorde pas d'autorisations de lecteur pour accéder directement aux données sous-jacentes.
Google fournit un exemple de module Terraform permettant de créer des vues autorisées sans accorder aux équipes des autorisations sur les ensembles de données autorisés sous-jacents. Le code suivant de ce module Terraform accorde ces autorisations IAM sur la vue autorisée dataset_id :
module "add_authorization" {
source = "terraform-google-modules/bigquery/google//modules/authorization"
version = "~> 4.1"
dataset_id = module.dataset.bigquery_dataset.dataset_id
project_id = module.dataset.bigquery_dataset.project
roles = [
{
role = "roles/bigquery.dataEditor"
group_by_email = "ops@mycompany.com"
}
]
authorized_views = [
{
project_id = "view_project"
dataset_id = "view_dataset"
table_id = "view_id"
}
]
authorized_datasets = [
{
project_id = "auth_dataset_project"
dataset_id = "auth_dataset"
}
]
}
Si vous devez autoriser des utilisateurs à accéder à plusieurs vues, accorder l'accès à chaque vue autorisée peut être à la fois chronophage et plus difficile à gérer. Plutôt que de créer plusieurs vues autorisées, vous pouvez utiliser un ensemble de données autorisé pour autoriser automatiquement toutes les vues créées dans cet ensemble autorisé.
Utiliser un produit de données
Pour la plupart des cas d'utilisation analytiques, les modèles de consommation sont déterminés par l'application dans laquelle les données sont utilisées. L'utilisation principale d'un environnement de consommation fourni de manière centralisée consiste à explorer les données avant qu'elles ne soient utilisées dans l'application consommatrice. Comme indiqué dans la section Découvrir et consommer des produits dans un maillage de données, SQL est la méthode la plus couramment utilisée pour interroger des produits de données. Pour cette raison, la plate-forme de données doit fournir aux utilisateurs une application SQL pour l'exploration des données.
Selon le cas d'utilisation analytique, vous pourrez peut-être utiliser Terraform pour déployer l'environnement de consommation des utilisateurs de données. Par exemple, la data science est un cas d'utilisation courant pour les consommateurs de données. Vous pouvez utiliser Terraform pour déployer des notebooks gérés par l'utilisateur Vertex AI à utiliser comme environnement de développement de data science. À partir des notebooks de data science, les utilisateurs de données peuvent utiliser leurs identifiants pour se connecter au maillage de données afin d'explorer les données auxquelles ils ont accès et de développer des modèles de ML basés sur ces données.
Pour découvrir comment déployer et sécuriser un environnement de notebook sur Google Cloudà l'aide de Terraform, consultez Créer et déployer des modèles d'IA générative et de machine learning dans une entreprise.
Fournir des services communs
En plus des composants et des solutions IaC en libre-service, l'équipe de la plate-forme de données peut également prendre en charge la création et la gestion de services communs de plate-forme partagée utilisés par plusieurs équipes chargées des domaines de données. Les services tiers de plate-forme partagée incluent des logiciels tiers auto-hébergés, tels que des outils de visualisation d'informatique décisionnelle ou un cluster Kafka. Dans Google Cloud, l'équipe chargée de la plate-forme de données peut choisir de gérer les ressources telles que Dataplex Universal Catalog et les récepteurs Cloud Logging pour le compte des équipes des domaines de données. La gestion des ressources pour les équipes chargées des domaines de données permet à l'équipe de la plate-forme de données de simplifier la gestion centralisée des règles et l'audit au sein de l'organisation.
Les sections suivantes présentent l'utilisation de Dataplex Universal Catalog pour la gestion et la gouvernance centralisées dans un maillage de données sur Google Cloud, ainsi que l'implémentation de fonctionnalités d'observabilité des données dans un maillage de données.
Dataplex Universal Catalog pour la gouvernance des données
Dataplex Universal Catalog fournit une plate-forme de gestion des données qui vous aide à créer des domaines de données indépendants au sein d'un maillage de données couvrant l'organisation. Dataplex Universal Catalog vous permet de maintenir des contrôles centralisés pour la gouvernance et la surveillance des données sur plusieurs domaines.
Avec Dataplex Universal Catalog, une organisation peut organiser logiquement ses données (sources de données compatibles) et les artefacts associés tels que le code, les notebooks et les journaux dans un lac Dataplex Universal Catalog qui représente un domaine de données. Dans le schéma suivant, un domaine de vente utilise Dataplex Universal Catalog pour organiser ses éléments, y compris les métriques de qualité et les journaux, dans des zones Dataplex Universal Catalog.
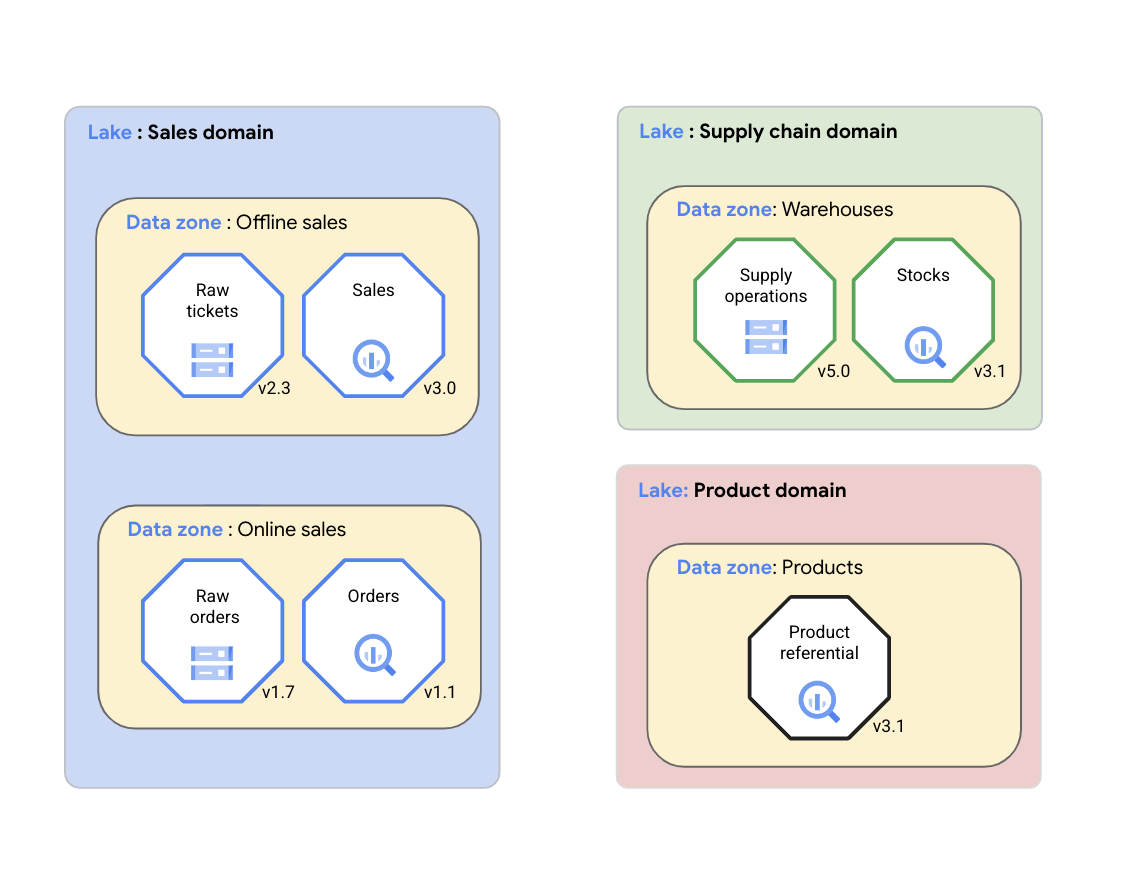
Comme indiqué dans le schéma précédent, Dataplex Universal Catalog peut être utilisé pour gérer les données de domaine dans les éléments suivants :
- Dataplex Universal Catalog permet aux équipes chargées des domaines de données de gérer de manière cohérente leurs éléments de données dans un groupe logique appelé lac Dataplex Universal Catalog. L'équipe chargée des domaines de données peut organiser ses éléments Dataplex Universal Catalog dans le même lac Dataplex Universal Catalog sans déplacer physiquement les données ni les stocker dans un seul système de stockage. Les éléments Dataplex Universal Catalog peuvent référencer des buckets Cloud Storage et des ensembles de données BigQuery stockés dans plusieurs projets Google Cloud , à l'exception du projetGoogle Cloud contenant le lac Dataplex Universal Catalog. Les éléments Dataplex Universal Catalog peuvent être structurés ou non, ou être stockés dans un lac de données ou un entrepôt de données analytiques. Le schéma présente des lacs de données pour le domaine des ventes, le domaine de la chaîne d'approvisionnement et le domaine des produits.
- Les zones Dataplex Universal Catalog permettent à l'équipe chargée des domaines de données d'organiser davantage les éléments de données en sous-groupes plus petits au sein du même lac Dataplex Universal Catalog et d'ajouter des structures qui capturent les aspects clés du sous-groupe. Par exemple, les zones Dataplex Universal Catalog peuvent être utilisées pour regrouper les éléments de données associés dans un produit de données. Le regroupement d'éléments de données dans une seule zone Dataplex Universal Catalog permet aux équipes appartenant au domaine de données de gérer de manière cohérente les règles d'accès et les règles de gouvernance des données dans la zone en tant que produit de données unique. Le schéma présente les zones de données pour les ventes hors ligne, les ventes en ligne, les entrepôts de chaîne d'approvisionnement et les produits.
Les lacs et les zones Dataplex Universal Catalog permettent à une organisation d'unifier les données distribuées et de les organiser en fonction du contexte métier. Cette organisation constitue la base des activités comme la gestion des métadonnées, la configuration des règles de gouvernance et la surveillance de la qualité des données. Ces activités permettent à l'organisation de gérer ses données distribuées à grande échelle, par exemple dans un maillage de données.
Observabilité des données
Chaque domaine de données doit implémenter ses propres mécanismes de surveillance et d'alerte, dans l'idéal via une approche standardisée. Chaque domaine peut appliquer les pratiques de surveillance décrites dans la section Concepts de la surveillance des services, en effectuant les ajustements nécessaires sur les domaines de données. L'observabilité est un sujet vaste et dépasse le cadre de ce document. Cette section ne traite que des modèles utiles dans les implémentations de maillages de données.
Pour les produits comportant plusieurs consommateurs de données, fournir des informations en temps réel à chaque consommateur sur l'état du produit peut devenir un fardeau opérationnel. Les solutions de base, telles que la gestion manuelle de la distribution des e-mails, sont généralement sujettes aux erreurs. Elles sont utiles pour informer les consommateurs des indisponibilités planifiées, des lancements de produits à venir et des abandons, mais elles ne fournissent pas d'informations opérationnelles en temps réel.
Les services centraux peuvent jouer un rôle important dans la surveillance de l'état et de la qualité des produits dans le maillage de données. Bien que ce ne soit pas une condition préalable à une mise en œuvre réussie du maillage de données, l'implémentation de fonctionnalités d'observabilité peut améliorer la satisfaction des producteurs et des consommateurs, et réduire les coûts généraux d'exploitation et d'assistance. Le schéma suivant illustre une architecture d'observabilité d'un maillage de données basée sur Cloud Monitoring.

Les sections suivantes décrivent les composants présentés dans le schéma, soit :
- Tests de disponibilité permettant d'afficher l'état général des produits de données.
- Métriques personnalisées fournissant des indicateurs utiles sur les produits de données.
- Assistance opérationnelle par l'équipe en charge de la plate-forme de données centrale afin d'alerter les consommateurs de données des modifications apportées aux produits de données qu'ils utilisent.
- Tableaux de données de produits et tableaux de bord affichant les performances des produits de données.
Tests de disponibilité
Les produits de données peuvent créer des applications personnalisées simples qui mettent en œuvre des tests de disponibilité. Ces vérifications peuvent servir d'indicateurs de l'état général du produit. Par exemple, si l'équipe de produit de données découvre une baisse soudaine de la qualité des données de son produit, elle peut marquer ce produit comme étant non opérationnel. Les tests de disponibilité proches du temps réel sont particulièrement importants pour les consommateurs de données qui ont conçu des produits qui reposent sur la disponibilité constante des données dans le produit de données en amont. Les producteurs de données doivent créer leurs tests de disponibilité pour inclure la vérification de leurs dépendances en amont, fournissant ainsi une vision précise de l'état des produits aux utilisateurs.
Les consommateurs de données peuvent inclure des tests de disponibilité de produit dans leur traitement. Par exemple, une tâche Composer qui génère un rapport basé sur les données fournies par un produit de données peut, en première étape, valider si le produit est à l'état "En cours d'exécution". Nous recommandons que votre application de test de disponibilité renvoie une charge utile structurée dans le corps de message de sa réponse HTTP. Cette charge utile structurée doit indiquer s'il y a un problème, l'origine du problème sous une forme lisible et, si possible, la durée estimée de restauration du service. Cette charge utile structurée peut également fournir des informations plus précises sur l'état du produit. Par exemple, elle peut contenir les informations d'état de chacune des vues de l'ensemble de données autorisé exposé en tant que produit.
Métriques personnalisées
Les produits de données peuvent disposer de différentes métriques personnalisées pour mesurer leur utilité. Les équipes de producteurs de données peuvent publier ces métriques personnalisées dans des projets Google Cloud spécifiques à leur domaine. Pour créer une expérience de surveillance unifiée pour tous les produits de données, un projet central de surveillance du maillage de données peut être autorisé à accéder à ces projets spécifiques à un domaine.
Chaque type d'interface de consommation de produit de données possède des métriques différentes afin de mesurer son utilité. Les métriques peuvent également être spécifiques au domaine d'activité. Par exemple, les métriques des tables BigQuery exposées via des vues ou via l'API Storage Read peuvent être les suivantes :
- Nombre de lignes
- Fraîcheur des données (exprimée en nombre de secondes avant l'heure de mesure)
- Niveau de qualité des données
- Données disponibles. Cette métrique peut indiquer que les données sont disponibles pour une requête. Vous pouvez également utiliser les tests de disponibilité mentionnés précédemment dans ce document.
Ces métriques peuvent être affichées comme des indicateurs de niveau de service (SLI) pour un produit particulier.
Pour les flux de données (implémentés en tant que sujets Pub/Sub), cette liste peut être les métriques Pub/Sub standards, disponibles via des sujets.
Assistance opérationnelle de l'équipe chargée de la plate-forme de données centrale
L'équipe chargée de la plate-forme de données centrale peut exposer des tableaux de bord personnalisés pour afficher différents niveaux de détails aux consommateurs de données. Un tableau de bord d'état simple qui répertorie les produits dans l'état de maillage de données et de disponibilité de ces produits peut permettre de répondre à plusieurs requêtes d'utilisateur final.
L’équipe centrale peut également servir de hub de notifications pour informer les consommateurs des événements divers des produits de données qu’ils utilisent. En règle générale, ce hub est constitué en créant des règles d'alerte. La centralisation de cette fonction peut réduire le travail devant être effectué par chaque équipe de producteurs de données. La création de ces règles ne nécessite pas de connaître les domaines de données et permet d'éviter les goulots d'étranglement dans la consommation des données.
Un état terminal idéal pour la surveillance du maillage de données consiste à exposer les SLI et les objectifs de niveau de service (SLO) du produit lorsque celui-ci devient disponible. L'équipe centrale peut ensuite déployer automatiquement les alertes correspondantes à l'aide de la surveillance des services avec l'API Monitoring.
Tableaux de données des produits
Dans le cadre de l'accord de gouvernance central, les quatre fonctions d'un maillage de données peuvent définir les critères pour créer les tableaux de données pour les produits de données. Ces tableaux de données peuvent devenir une mesure objective des performances du produit de données.
De nombreuses variables utilisées pour calculer les tableaux de données correspondent au pourcentage de temps pendant lequel les produits de données répondent à leur SLO. Les critères utiles peuvent être le pourcentage de temps de disponibilité, le niveau moyen de qualité des données et le pourcentage de produits dont le niveau d'actualisation des données est inférieur à un certain seuil. Pour calculer ces métriques automatiquement à l'aide du langage de requête Prometheus (PromQL), les métriques personnalisées et les résultats des tests de disponibilité du projet central de surveillance doivent être suffisants.
Étapes suivantes
- Obtenez davantage d'informations sur BigQuery.
- Découvrez Dataplex.
- Pour découvrir d'autres architectures de référence, schémas et bonnes pratiques, consultez le Centre d'architecture cloud.