Pour garantir la conformité aux cas d'utilisation des utilisateurs de données, il est essentiel que les produits de données d'un maillage de données soient conçus et créés avec soin. La conception d'un produit de données commence par la définition de la manière dont les consommateurs de données l'utiliseront et par la manière dont il sera exposé aux consommateurs. Les produits de données d'un maillage sont basés sur un datastore (par exemple, un entrepôt de données de domaine ou un lac de données). Lorsque vous créez des produits de données dans un maillage de données, nous vous recommandons d'envisager certains facteurs clés tout au long de ce processus. Ces considérations sont décrites dans ce document.
Ce document fait partie d'une série qui décrit comment implémenter un maillage de données sur Google Cloud. Nous partons du principe que vous avez lu et que vous connaissez les concepts décrits sur la page Architecture et fonctions dans un maillage de données et Créer un maillage de données moderne et distribué avec Google Cloud.
La série se compose des parties suivantes :
- Architecture et fonctions d'un maillage de données
- Concevoir une plate-forme de données en libre-service pour un maillage de données
- Créer des produits de données dans un maillage de données (ce document)
- Découvrir et consommer des produits de données dans un maillage de données
Lors de la création de produits de données à partir d'un entrepôt de données, nous recommandons aux producteurs de données de concevoir soigneusement les interfaces d'analyse (consommation) pour ces produits. Ces interfaces de consommation constituent un ensemble de garanties sur les paramètres opérationnels et de qualité des données, ainsi qu'un modèle d'assistance et une documentation produit. Le coût de la modification des interfaces de consommation est généralement élevé, car le producteur de données et, éventuellement, les utilisateurs de données multiples peuvent modifier leurs processus et applications de consommation. Étant donné que les utilisateurs de données sont plus susceptibles de se trouver dans des unités organisationnelles distinctes de celles des producteurs de données, la coordination des modifications peut s'avérer difficile.
Les sections suivantes fournissent des informations générales sur les éléments à prendre en compte lors de la création d'un entrepôt de domaine, de la définition des interfaces de consommation et de l'exposition de ces interfaces aux utilisateurs de données.
Créer un entrepôt de données de domaine
Il n'existe pas de différence fondamentale entre la création d'un entrepôt de données autonome et la création d'un entrepôt de données de domaine à partir duquel l'équipe du producteur de données crée des produits de données. La seule différence réelle entre les deux est que la dernière présente un sous-ensemble de ses données via les interfaces de consommation.
Dans de nombreux entrepôts de données, les données brutes ingérées à partir de sources opérationnelles de données sont soumises au processus d'enrichissement et de vérification de la qualité des données. Dans les lacs de données gérés par Dataplex Universal Catalog, les données organisées sont généralement stockées dans des zones sélectionnées. Une fois la sélection terminée, un sous-ensemble de données doit être prêt pour une utilisation externe au domaine via plusieurs types d'interfaces. Pour définir ces interfaces de consommation, une organisation doit fournir un ensemble d'outils aux équipes de domaines qui entament l'adoption d'un maillage de données. Ces outils permettent aux producteurs de données de créer des produits de données en libre-service. Pour connaître les pratiques recommandées, consultez la page Concevoir une plate-forme de données en libre-service.
De plus, les produits de données doivent répondre aux exigences de gouvernance des données définies de manière centralisée. Ces exigences ont une incidence sur la qualité des données, leur disponibilité et leur gestion. Comme ces exigences renforcent la confiance des utilisateurs dans les produits de données et favorisent leur utilisation, leurs avantages surpassent largement les contraintes liées à leur implémentation.
Définir les interfaces de consommation
Nous recommandons aux producteurs de données d'utiliser plusieurs types d'interfaces plutôt que de définir une ou deux interfaces. Chaque type d'interface en analyse de données présente des avantages et des inconvénients, et il n'existe pas d'interface unique qui soit parfaite pour tous les cas. Lorsque les producteurs de données évaluent la pertinence de chaque type d'interface, ils doivent prendre en compte les éléments suivants :
- Possibilité d'effectuer le traitement des données nécessaire.
- Évolutivité nécessaire pour les cas d'utilisation actuels et futurs des données.
- Performances requises par les utilisateurs de données.
- Coût de développement et de maintenance.
- Coût d'exécution de l'interface.
- Compatibilité avec les langages et les outils utilisés par votre organisation.
- Compatibilité avec la séparation du stockage et du calcul.
Par exemple, si l'exigence métier consiste à pouvoir exécuter des requêtes analytiques sur un ensemble de données à l'échelle du pétaoctet, la seule interface pratique est une vue BigQuery. Toutefois, si les exigences doivent fournir des données de streaming en temps quasi réel, une interface basée sur Pub/Sub est plus appropriée.
La plupart de ces interfaces ne vous obligent pas à copier ou à répliquer des données existantes. La plupart d'entre eux vous permettent également de séparer le stockage et le calcul, une fonctionnalité essentielle des outils d'analyseGoogle Cloud . Les utilisateurs des données exposées via ces interfaces traitent les données à l'aide des ressources de calcul disponibles. Les producteurs de données n'ont pas besoin de provisionner une infrastructure supplémentaire.
Il existe une grande variété d'interfaces de consommation. Les interfaces suivantes sont celles les plus couramment utilisées dans un maillage de données et sont décrites dans les sections suivantes :
- Vues et fonctions autorisées
- API de lecture directe
- Données sous forme de flux
- API d'accès aux données
- Blocs Looker
- Modèles de machine learning (ML)
La liste des interfaces de ce document n'est pas exhaustive. Il existe également d'autres options que vous pouvez envisager pour vos interfaces de consommation (par exemple, BigQuery Sharing (anciennement Analytics Hub)). Toutefois, ces autres interfaces n'entrent pas dans le cadre de ce document.
Vues et fonctions autorisées
Dans la mesure du possible, les produits de données doivent être exposés via des vues autorisées et des fonctions autorisées, y compris des fonctions à valeur de table. Les ensembles de données autorisés constituent un moyen pratique d'autoriser automatiquement plusieurs vues. L'utilisation de vues autorisées empêche l'accès direct aux tables de base et permet d'optimiser les tables et les requêtes sous-jacentes, sans affecter les utilisations de ces vues. Les utilisateurs de cette interface utilisent SQL pour interroger les données. Le diagramme suivant illustre l'utilisation d'ensembles de données autorisés en tant qu'interface de consommation.
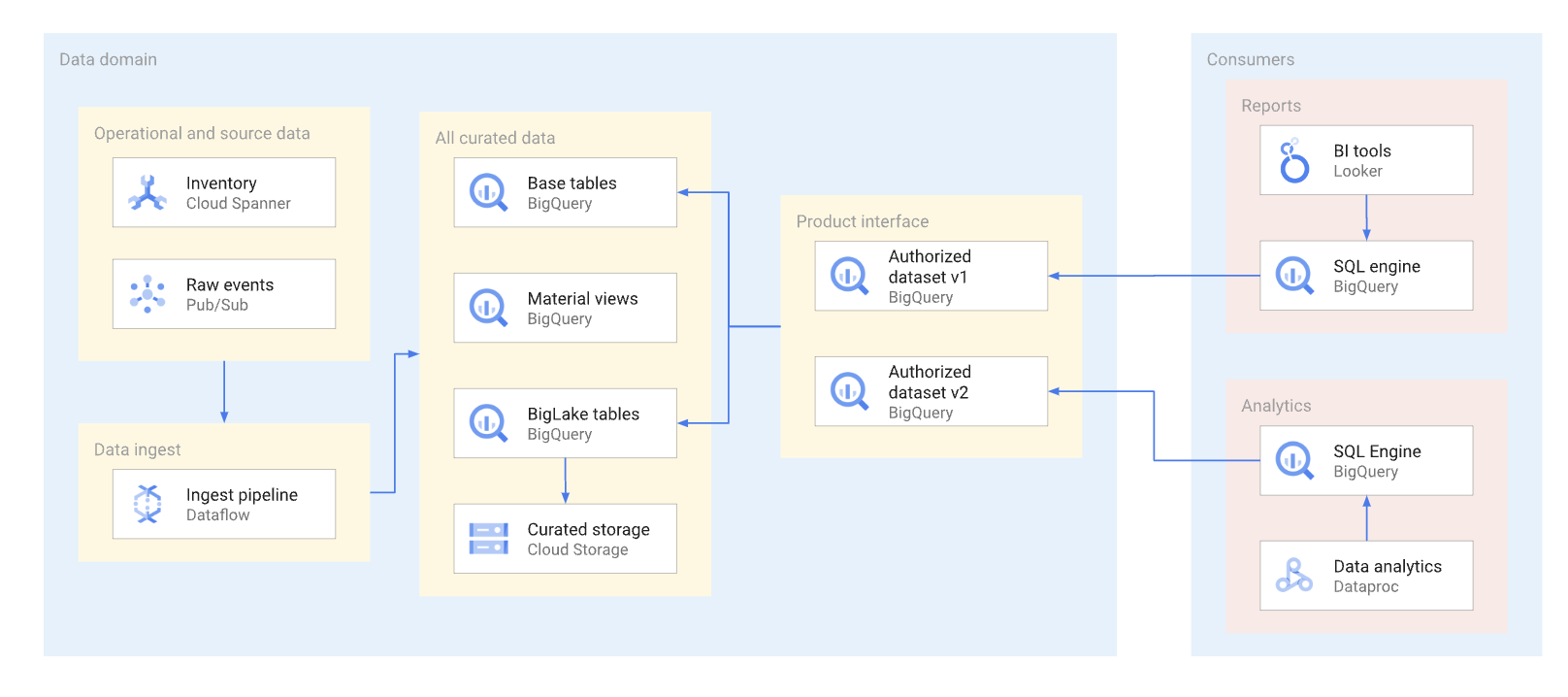
La gestion des versions simples des interfaces est facilitée pour les ensembles de données et les vues autorisés. Comme le montre le schéma suivant, les producteurs de données peuvent adopter deux approches de gestion des versions principales :
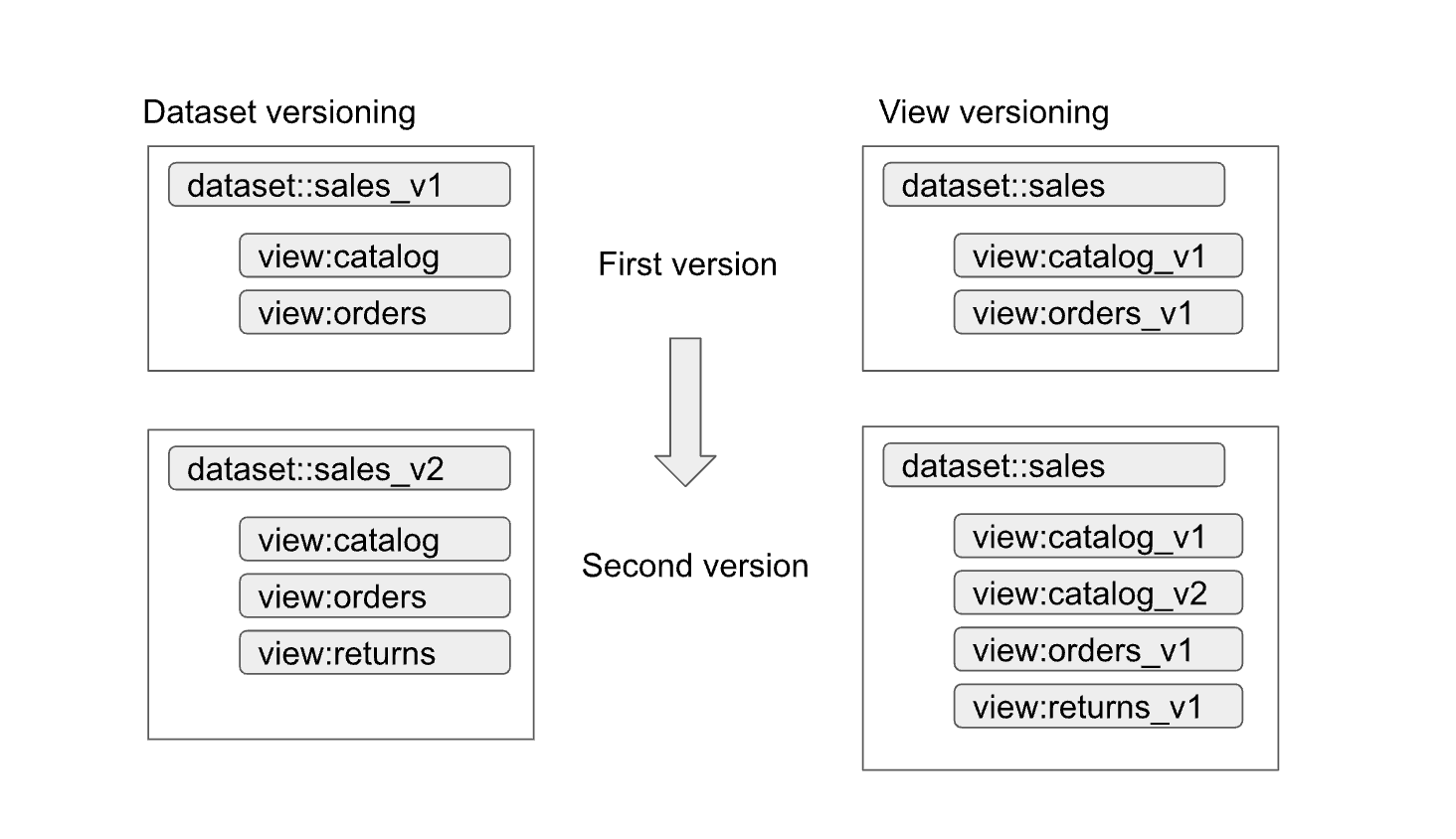
Les approches peuvent être résumées comme suit :
- Gestion des versions d'ensembles de données : dans cette approche, vous gérez le nom des ensembles de données.
Vous ne gérez pas les versions des vues et des fonctions au sein de l'ensemble de données. Vous conservez les mêmes noms pour les vues et les fonctions, quelle que soit la version. Par exemple, la première version d'un ensemble de données de ventes est définie dans un ensemble de données nommé
sales_v1avec deux vues,catalogetorders. Pour sa deuxième version, l'ensemble de données des ventes a été renommésales_v2, et toutes les vues précédentes de l'ensemble de données conservent leur nom précédent, mais ont de nouveaux schémas. La deuxième version de l'ensemble de données peut également être associée à de nouvelles vues ou supprimer l'une des vues précédentes. - Gestion des versions des vues : dans cette approche, les vues de l'ensemble de données comprennent des versions gérées plutôt que l'ensemble de données. Par exemple, l'ensemble de données des ventes conserve le nom de
sales, quelle que soit la version. Toutefois, les noms des vues dans l'ensemble de données changent pour refléter chaque nouvelle version de la vue (par exemple,catalog_v1,catalog_v2,orders_v1,orders_v2etorders_v3).
La meilleure approche de gestion des versions pour votre organisation dépend des stratégies de votre organisation et du nombre de vues rendues obsolètes avec la mise à jour des données sous-jacentes. Cette gestion est optimale lorsqu'une mise à jour majeure est nécessaire, et que la plupart des vues doivent changer. La gestion des versions entraîne une diminution du nombre de vues portant le même nom dans différents ensembles de données, mais peut également générer des ambiguïtés, par exemple pour savoir si une jointure entre les ensembles de données fonctionne correctement. Une approche hybride peut être un bon compromis. Dans une approche hybride, les modifications de schéma compatibles sont autorisées dans un seul ensemble de données, et les modifications incompatibles nécessitent un nouvel ensemble de données.
Remarques concernant les tables BigLake
Les vues autorisées peuvent être créées non seulement sur des tables BigQuery, mais également sur des tables BigLake. Les tables BigLake permettent aux utilisateurs d'interroger les données stockées dans Cloud Storage à l'aide de l'interface SQL de BigQuery. Les tables BigLake permettent un contrôle d'accès précis sans que les utilisateurs de données n'aient besoin d'autorisations en lecture pour le bucket Cloud Storage sous-jacent.
Les producteurs de données doivent tenir compte des points suivants pour les tables BigLake :
- La conception des formats de fichiers et la disposition des données influencent les performances des requêtes. Les formats basés sur des colonnes, comme Parquet ou ORC, sont généralement plus performants pour les requêtes analytiques que les formats JSON ou CSV.
- Une configuration partitionnée Hive vous permet d'éliminer des partitions et d'accélérer les requêtes qui utilisent des colonnes de partitionnement.
- Le nombre de fichiers et les performances de requête préférées pour la taille de fichier doivent également être pris en compte lors de la phase de conception.
Si les requêtes utilisant des tables BigLake ne répondent pas aux exigences du contrat de niveau de service (SLA) pour l'interface et ne peuvent pas être ajustées, nous vous recommandons les actions suivantes :
- Pour les données qui doivent être exposées au consommateur de données, convertissez-les en stockage BigQuery.
- Redéfinissez les vues autorisées pour utiliser les tables BigQuery.
En règle générale, cette approche n'affecte pas les utilisateurs de données et ne nécessite aucune modification de leurs requêtes. Les requêtes dans l'espace de stockage BigQuery peuvent être optimisées à l'aide de techniques qui ne sont pas possibles avec les tables Bigtable. Par exemple, avec le stockage BigQuery, les clients peuvent interroger des vues matérialisées dont le partitionnement et le clustering sont différents de ceux des tables de base. Ils peuvent également utiliser BigQuery BI Engine.
API de lecture directe
Bien que nous ne recommandions généralement pas aux producteurs de données d'accorder un accès direct en lecture aux tables de base, il peut parfois être pratique d'autoriser un tel accès pour des raisons telles que les performances et les coûts. Dans ce cas, il est important de veiller à la stabilité du schéma de la table.
Deux options s'offrent à vous pour accéder directement aux données d'un entrepôt classique. Les producteurs de données peuvent utiliser l'API de lecture BigQuery Storage ou les API JSON ou XML de Cloud Storage. Le schéma suivant illustre deux exemples de clients utilisant ces API. L'un est un cas d'utilisation du machine learning (ML) et l'autre est une tâche de traitement de données.
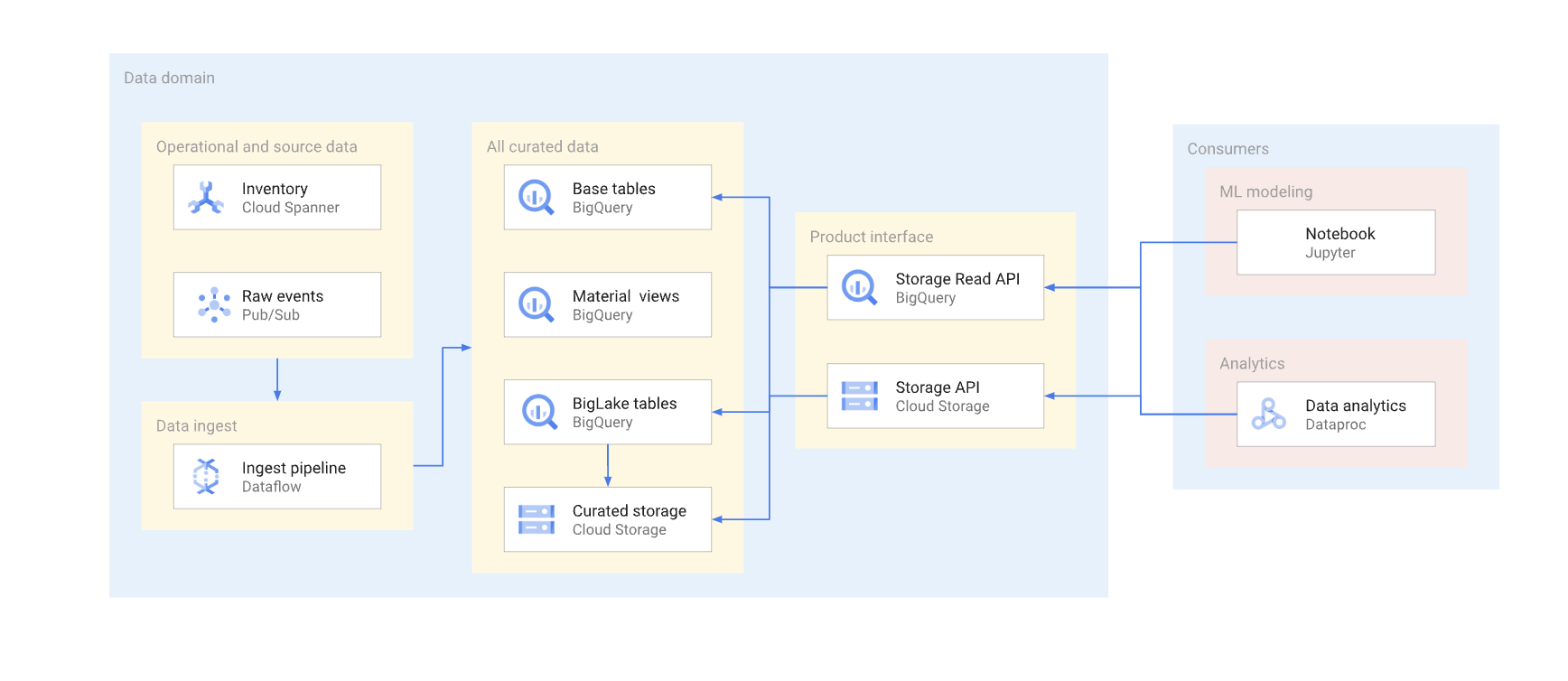
La gestion des versions dans une interface de lecture directe est complexe. En règle générale, les producteurs de données doivent créer une autre table avec un schéma différent. Ils doivent également conserver deux versions de la table jusqu'à ce que tous les utilisateurs de données de la version obsolète migrent vers la nouvelle. Si les utilisateurs peuvent tolérer la perturbation de la recréation de la table et du passage au nouveau schéma, il est possible d'éviter la duplication des données. Dans les cas où les modifications de schéma sont rétrocompatibles, la migration de la table de base peut être évitée. Par exemple, vous n'avez pas besoin de migrer la table de base si seules de nouvelles colonnes sont ajoutées et que les données de ces colonnes sont remplies pour toutes les lignes.
Voici un récapitulatif des différences entre l'API Read et l'API Cloud Storage. En règle générale, dans la mesure du possible, nous recommandons aux producteurs de données d'utiliser l'API BigQuery pour les applications analytiques.
API Storage Read : l'API Storage Read permet de lire des données dans des tables BigQuery et des tables BigLake. Cette API est compatible avec le filtrage et le contrôle d'accès précis. Elle peut être une bonne option pour les utilisateurs de l'analyse de données stable ou du ML.
API Cloud Storage : les producteurs de données peuvent avoir besoin de partager un bucket Cloud Storage spécifique avec les utilisateurs de données. Par exemple, les producteurs de données peuvent partager le bucket si les utilisateurs de données ne peuvent pas utiliser l'interface SQL pour une raison quelconque ou s'ils ont des formats de données non compatibles avec l'API Storage Read.
En général, nous ne recommandons pas aux producteurs de données d'autoriser l'accès direct via les API de stockage, car l'accès direct ne permet pas de filtrage ni de contrôle d'accès précis. Cependant, l'approche d'accès direct peut être un choix viable pour les ensembles de données stables de petite taille (gigaoctets).
Le fait d'autoriser l'accès de Pub/Sub au bucket permet aux utilisateurs de données de copier facilement les données dans leurs projets et de les traiter. En général, nous vous déconseillons de copier des données si cela peut être évité. L'utilisation de plusieurs copies des données augmente le coût de stockage et augmente les coûts de maintenance et de suivi de la traçabilité.
Données sous forme de flux
Un domaine peut exposer les données en streaming en les publiant dans un sujet Pub/Sub. Les abonnés qui souhaitent utiliser les données créent des abonnements pour consommer les messages publiés sur ce sujet. Chaque abonné reçoit et consomme des données de manière indépendante. Le schéma suivant illustre un exemple de ces flux de données.
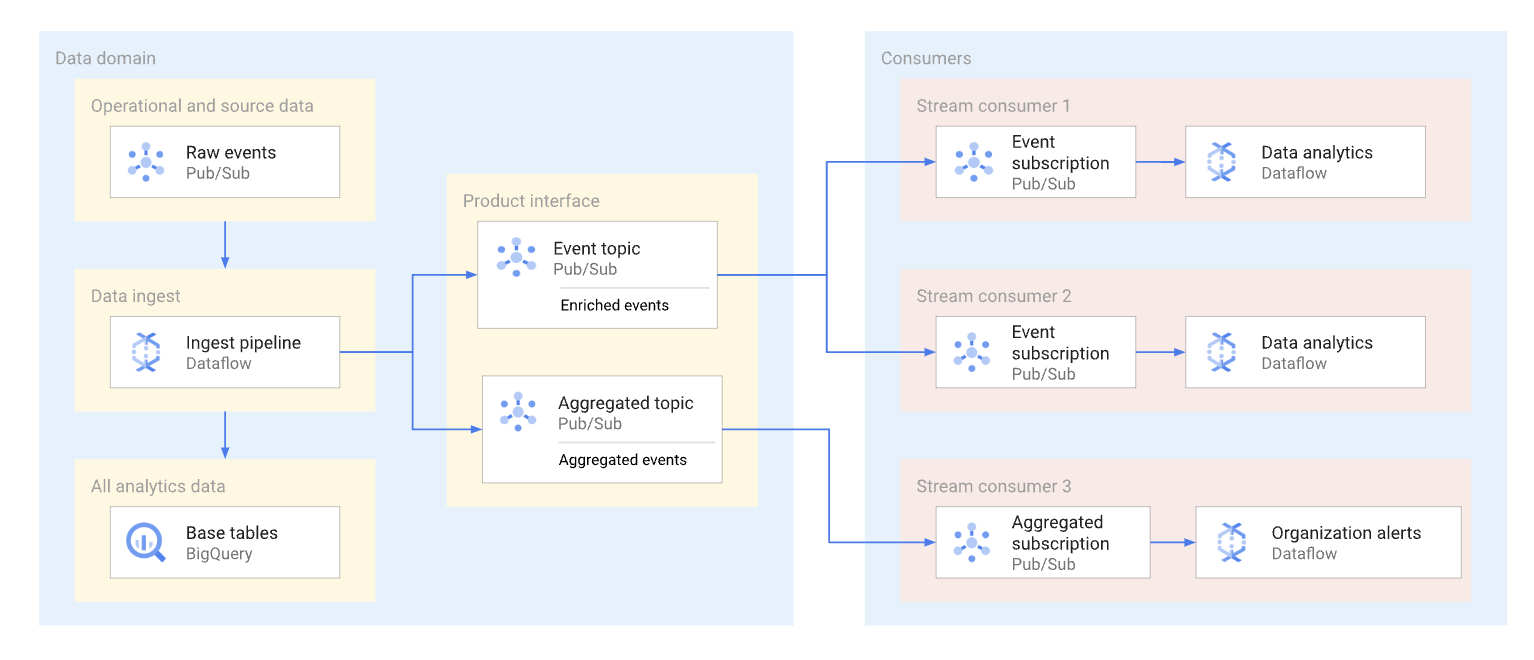
Dans le schéma, le pipeline d'ingestion lit les événements bruts, les enrichit (les sélectionne) et enregistre ces données organisées dans le datastore d'analyse (table de base BigQuery). En parallèle, le pipeline publie les événements enrichis dans un sujet dédié. Ce sujet est utilisé par plusieurs abonnés, dont chacun peut éventuellement filtrer ces événements pour n'obtenir que ceux qui les concernent. Le pipeline regroupe et publie également les statistiques d'événements dans son propre sujet pour être traitées par un autre consommateur de données.
Voici des exemples de cas d'utilisation des abonnements Pub/Sub :
- Événements enrichis, tels que la fourniture d'informations de profil client complètes, ainsi que les données liées à une commande client spécifique.
- Notifications d'agrégation en quasi-temps réel, telles que les statistiques de commande totales pour les 15 dernières minutes.
- Alertes au niveau de l'entreprise, par exemple générer une alerte si le volume des commandes a diminué de 20 % par rapport à une période similaire le jour précédent.
- Notifications de modification des données (semblable au concept de capture de données modifiées), telles que l'état d'une commande spécifique.
Le format de données utilisé par les producteurs de données pour les messages Pub/Sub a une incidence sur les coûts et le mode de traitement de ces messages. Pour les flux à volume élevé dans une architecture de maillage de données, les formats Avro ou Protobuf sont de bonnes options. Si les producteurs de données utilisent ces formats, ils peuvent attribuer des schémas aux sujets Pub/Sub. Les schémas permettent de s'assurer que les utilisateurs reçoivent des messages correctement formés.
Étant donné qu'une structure de données en flux continu peut changer en permanence, la gestion des versions de cette interface nécessite une coordination entre les producteurs de données et les utilisateurs de données. Les producteurs de données peuvent adopter plusieurs approches courantes, comme ce qui suit :
- Un sujet est créé chaque fois que la structure des messages est modifiée. Ce sujet comporte souvent un schéma Pub/Sub explicite. Les utilisateurs de données qui ont besoin de la nouvelle interface peuvent commencer à exploiter les nouvelles données. La version du message est implicite par le nom du sujet, par exemple
click_events_v1. Les formats des messages sont fortement typés. Il n'existe aucune variation au niveau du format des messages entre les messages d'un même sujet. L'inconvénient de cette approche est que certains utilisateurs de données ne peuvent pas passer au nouvel abonnement. Dans ce cas, le producteur de données doit continuer à publier des événements sur tous les sujets actifs pendant un certain temps, et les utilisateurs de données qui s'abonnent au sujet doivent soit gérer un fossé dans le flux de messages, soit supprimer les doublons. - Les données sont toujours publiées dans le même sujet. Cependant, la structure du message peut changer. Un attribut de message Pub/Sub (distinct de la charge utile) définit la version du message. Exemple :
v=1.0. Cette approche vous évite d'avoir à gérer les écarts ou les doublons. Cependant, tous les utilisateurs de données doivent être prêts à recevoir des messages d'un nouveau type. Les producteurs de données ne peuvent pas non plus utiliser de schémas de sujets Pub/Sub pour cette approche. - Une approche hybride. Le schéma du message peut comporter une section de données arbitraire pouvant être utilisée pour de nouveaux champs. Cette approche peut fournir un équilibre raisonnable entre des données fortement typées et des modifications fréquentes et complexes des versions.
API d'accès aux données
Les producteurs de données peuvent créer une API personnalisée pour accéder directement aux tables de base d'un entrepôt de données. En règle générale, ces producteurs exposent cette API personnalisée en tant qu'API REST ou gRPC, et la déploient sur Cloud Run ou un cluster Kubernetes. Une passerelle API telle qu'Apigee peut fournir d'autres fonctionnalités, telles que la limitation du trafic ou une couche de mise en cache. Ces fonctionnalités sont utiles lorsque vous exposez l'API d'accès aux données à des clients extérieurs à une organisation Google Cloud . Les candidats potentiels à une API d'accès aux données sont des requêtes simultanées sensibles à la latence élevée qui renvoient toutes deux un résultat relativement faible dans une seule API et peuvent être mises en cache.
Exemples d'API personnalisées pour l'accès aux données :
- Vue combinée sur les métriques de contrat de niveau de service de la table ou du produit.
- Les 10 premiers enregistrements (éventuellement mis en cache) d'une table particulière.
- Un ensemble de données de statistiques de table (nombre total de lignes ou distribution des données dans les colonnes de clé).
Toutes les consignes et la gouvernance propres à l'organisation concernant la création d'API d'application sont également applicables aux API personnalisées créées par les producteurs de données. Les consignes et la gouvernance de l'organisation doivent couvrir des problèmes tels que l'hébergement, la surveillance, le contrôle des accès et la gestion des versions.
L'inconvénient d'une API personnalisée est le fait que les producteurs de données sont responsables de toute infrastructure supplémentaire requise pour héberger cette interface, ainsi que du codage et de la maintenance de l'API personnalisée. Nous recommandons aux producteurs de données d'étudier d'autres options avant de décider de créer des API d'accès aux données personnalisées. Par exemple, les producteurs de données peuvent utiliser BigQuery BI Engine pour réduire la latence de réponse et augmenter la simultanéité.
Blocs Looker
Pour les produits tels que Looker, qui sont fortement utilisés dans les outils d'informatique décisionnelle, il peut être utile de gérer un ensemble de widgets spécifiques à l'informatique décisionnelle. Étant donné que l'équipe des producteurs de données connaît le modèle de données sous-jacent utilisé dans le domaine, elle est mieux placée pour créer et gérer un ensemble prédéfini de visualisations.
Dans le cas de Looker, cette visualisation peut être un ensemble de blocs Looker (modèles de données LookML prédéfinis). Les blocs Looker peuvent facilement être intégrés dans des tableaux de bord hébergés par les clients.
Modèles de ML
Les équipes qui travaillent dans des domaines de données ont une compréhension et une connaissance approfondies de leurs données. Elles sont donc souvent les mieux placées pour créer et gérer des modèles de ML entraînés sur les données de domaines. Ces modèles de ML peuvent être exposés via plusieurs interfaces différentes, y compris les suivantes :
- Les modèles BigQuery ML peuvent être déployés dans un ensemble de données dédié et partagés avec les utilisateurs de données pour les prédictions par lot BigQuery.
- Les modèles BigQuery ML peuvent être exportés dans Vertex AI et utilisés pour les prédictions en ligne.
Remarques concernant l'emplacement des données pour les interfaces de consommation
L'emplacement des données est un aspect important à prendre en compte lorsque les producteurs de données définissent des interfaces de consommation pour les produits de données. En général, pour réduire les coûts, les données doivent être traitées dans la même région que celle dans laquelle elles sont stockées. Cette approche permet d'éviter les frais de sortie de données interrégionaux. Cette approche présente également la plus faible latence de consommation des données. Pour toutes ces raisons, les données stockées dans des emplacements BigQuery multirégionaux sont généralement les meilleurs candidats pour l'exposition en tant que produit de données.
Toutefois, pour des raisons de performances, les données stockées dans Cloud Storage et exposées via des tables BigLake ou des API de lecture directe doivent être stockées dans des buckets régionaux.
Si les données exposées dans un produit résident dans une région et doivent être associées à des données d'un autre domaine dans une autre région, les utilisateurs de données doivent prendre en compte les limites suivantes :
- Les requêtes interrégionales qui utilisent BigQuery SQL ne sont pas acceptées. Si la méthode de consommation principale des données est BigQuery SQL, toutes les tables de la requête doivent se trouver au même emplacement.
- Les engagements forfaitaires de BigQuery sont régionaux. Si un projet utilise uniquement un engagement forfaitaire dans une région, mais interroge un produit de données d'une autre région, la tarification à la demande s'applique.
- Les utilisateurs de données peuvent utiliser les API de lecture directe pour lire des données depuis une autre région. Toutefois, des frais de sortie de réseau interrégionaux s'appliquent, et les utilisateurs de données rencontreront probablement une latence dans le cas de transferts de données volumineux.
Les données fréquemment consultées dans les régions peuvent être répliquées dans ces régions afin de réduire le coût et la latence des requêtes encourues par les clients du produit. Par exemple, les ensembles de données BigQuery peuvent être copiés dans d'autres régions. Cependant, les données ne doivent être copiées que lorsque cela est nécessaire. Nous recommandons aux producteurs de données de ne mettre à disposition qu'un sous-ensemble des données produit disponibles dans plusieurs régions lorsque vous les copiez. Cette approche permet de minimiser la latence et les coûts de réplication. Cette approche peut conduire à fournir plusieurs versions de l'interface de consommation avec la région d'emplacement des données explicitement appelée. Par exemple, les vues autorisées BigQuery peuvent être exposées via des noms, tels que sales_eu_v1 et sales_us_v1.
Les interfaces de flux de données utilisant des sujets Pub/Sub ne nécessitent aucune logique de réplication supplémentaire pour consommer les messages des régions différentes de celle dans laquelle le message est stocké. Toutefois, des frais de sortie interrégionaux supplémentaires s'appliquent dans ce cas.
Exposer les interfaces de consommation aux utilisateurs de données
Cette section explique comment rendre les interfaces de consommation visibles par les clients potentiels. Data Catalog est un service entièrement géré que les entreprises peuvent utiliser pour fournir les services de découverte de données et de gestion des métadonnées. Les producteurs de données doivent rendre les interfaces de consommation de leurs produits de données consultables et les annoter avec les métadonnées appropriées afin que les utilisateurs puissent y accéder en libre-service. Mer
Les sections suivantes expliquent comment chaque type d'interface est défini en tant qu'entrée Data Catalog.
Interfaces SQL basées sur BigQuery
Les métadonnées techniques, telles qu'un nom de table complet ou un schéma de table, sont automatiquement enregistrées pour les vues autorisées, les vues BigLake et les tables BigQuery disponibles via l'API Storage Read. Nous recommandons aux producteurs de données de fournir également des informations supplémentaires dans la documentation du produit de données pour aider les utilisateurs de données. Par exemple, pour aider les utilisateurs à trouver la documentation d'une entrée, les producteurs de données peuvent ajouter une URL à l'un des tags appliqués à l'entrée. Les producteurs peuvent également fournir les éléments suivants :
- Ensembles de colonnes en cluster, à utiliser dans les filtres de requête.
- Valeurs d'énumération des champs ayant un type d'énumération logique, si le type n'est pas fourni dans la description du champ.
- Jointures compatibles avec d'autres tables.
Flux de données
Les sujets Pub/Sub sont automatiquement enregistrés dans Data Catalog. Toutefois, les producteurs de données doivent décrire le schéma dans la documentation du produit de données.
API Cloud Storage
Data Catalog accepte la définition des entrées de fichier Cloud Storage et leur schéma. Si un ensemble de fichiers de lac de données est géré par Dataplex Universal Catalog, il est automatiquement enregistré dans Data Catalog. Les ensembles de fichiers qui ne sont pas associés à Dataplex Universal Catalog sont ajoutés à l'aide d'une approche différente.
Autres interfaces
Vous pouvez ajouter d'autres interfaces qui ne sont pas compatibles avec Data Catalog en créant des entrées personnalisées.
Étapes suivantes
- Consultez une mise en œuvre de référence de l'architecture de maillage de données.
- Obtenez davantage d'informations sur BigQuery.
- Découvrez Dataplex.
- Pour découvrir d'autres architectures de référence, schémas et bonnes pratiques, consultez le Centre d'architecture cloud.