Nesta página, apresentamos a recuperação de desastres no Cloud SQL.
Visão geral
No Google Cloud, a recuperação de desastres (DR) do banco de dados se trata de fornecer continuidade do processamento, especificamente quando uma região falha ou fica indisponível. O Cloud SQL é um serviço regional, quando configurado para alta disponibilidade (HA). Portanto, se a região Google Cloud que hospeda um banco de dados do Cloud SQL ficar indisponível, o banco de dados do Cloud SQL também ficará.
Para continuar o processamento, é preciso disponibilizar o banco de dados em uma região secundária o mais rápido possível. O plano de DR requer que você configure uma réplica de leitura entre regiões no Cloud SQL. Um failover baseado em exportação/importação ou backup/restauração também é possível, mas essa abordagem demora mais, especialmente para bancos de dados grandes.
Os cenários de negócios a seguir são exemplos que garantem uma configuração de failover entre regiões:
- O contrato de nível de serviço do aplicativo comercial é maior que o contrato de nível de serviço do Cloud SQL regional (99,99% de disponibilidade, dependendo da edição do Cloud SQL). Ao fazer o failover para outra região, você pode reduzir uma falha.
- Todos os níveis do aplicativo comercial já são multirregionais e podem continuar o processamento quando ocorre uma falha na região. A configuração de failover entre regiões ajuda a manter a disponibilidade contínua de um banco de dados.
- O objetivo de tempo de recuperação obrigatório (RTO, na sigla em inglês) e o objetivo do ponto de recuperação (RPO, na sigla em inglês) estão em minutos, e não em horas. Fazer o failover para outra região é mais rápido do que recriar um banco de dados.
Em geral, há duas variantes para o processo de DR:
- Um banco de dados faz o failover para uma região secundária. Depois que o banco de dados estiver pronto e for usado por um aplicativo, ele se tornará o novo banco de dados principal e permanecerá como principal.
- Um banco de dados faz o failover para uma região secundária, mas volta para a região principal depois que esta é recuperada da falha.
Nesta visão geral de recuperação de desastres do banco de dados SQL, descrevemos a segunda variante: quando um banco de dados com falha é recuperado e retorna à região principal. Google Cloud A variante desse processo de DR é especialmente relevante para bancos de dados que precisam ser executados na região principal devido à latência da rede ou porque alguns recursos estão disponíveis apenas na região principal. Com essa variante, o banco de dados é executado na região secundária apenas durante a duração da falha na região principal.
Arquitetura de recuperação de desastres
O diagrama a seguir mostra a arquitetura mínima que aceita DR de banco de dados para uma instância de alta disponibilidade do Cloud SQL:
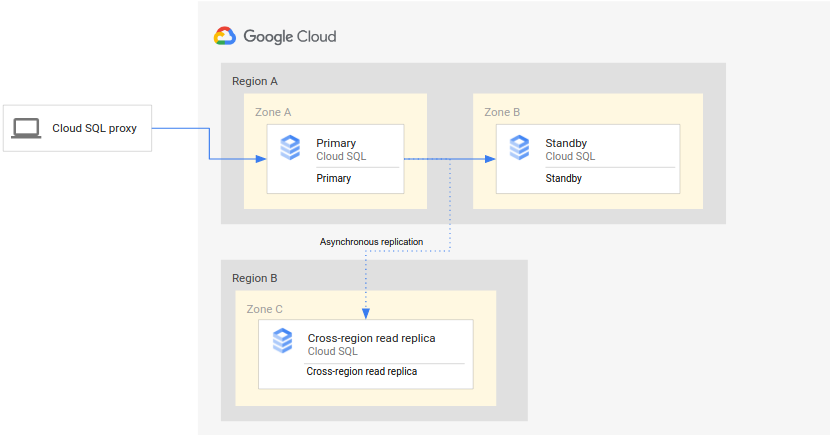
A arquitetura funciona da seguinte maneira:
- Duas instâncias do Cloud SQL, uma instância principal e uma instância em espera, estão localizadas em duas zonas separadas dentro de uma única região (a região principal). As instâncias são sincronizadas com discos permanentes regionais.
- Uma instância do Cloud SQL (a réplica de leitura entre regiões) está localizada em uma segunda região (a região secundária). No caso de DR, a réplica de leitura entre regiões está configurada para sincronizar (usando a replicação assíncrona) com a instância principal usando uma configuração de réplica de leitura.
As instâncias principal e em espera compartilham o mesmo disco regional. Por isso, seus estados são idênticos.
Como essa configuração usa a replicação assíncrona, é possível que a réplica de leitura entre regiões demore para a instância principal. Como resultado, quando ocorre um failover, o RPO da réplica de leitura entre regiões provavelmente é diferente de zero.
Processo de recuperação de desastres (DR)
O processo de recuperação de desastres (DR) começa quando a região principal fica indisponível. Para retomar o processamento em uma região secundária, você aciona um failover da instância principal, promovendo uma réplica de leitura entre regiões. O processo de DR descreve as etapas operacionais que precisam ser executadas manual ou automaticamente para reduzir a falha regional e estabelecer uma instância principal em execução em uma região secundária.
O diagrama a seguir mostra o processo de DR:
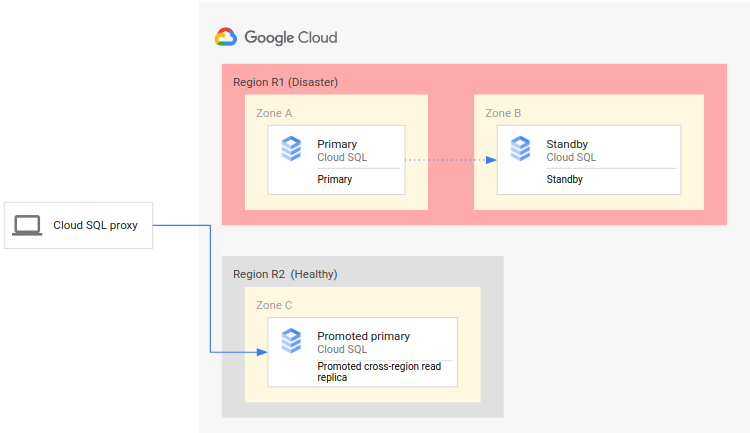
O processo de DR consiste nas etapas a seguir:
- A região principal (R1), que está executando a instância principal, fica indisponível.
- A equipe de operações reconhece e confirma formalmente o desastre e decide se um failover é necessário.
- Se for necessário um failover, promova a réplica de leitura entre regiões na região secundária (R2) para que ela seja a nova instância principal.
- As conexões do cliente são reconfiguradas para retomar o processamento na nova instância principal e acessar a instância principal no R2.
Esse processo inicial estabelece novamente um banco de dados principal em funcionamento. Porém, ela não estabelece uma arquitetura de DR completa, em que a nova instância principal tem uma instância em espera e uma réplica de leitura entre regiões.
Um processo de DR completo garante que a única instância, a nova principal, esteja ativada para alta disponibilidade e tenha uma réplica de leitura entre regiões. Um processo completo de DR também fornece um fallback para a implantação original na região principal original.
Como fazer failover para uma região secundária
O processo completo de DR é uma extensão do processo básico porque adiciona etapas para estabelecer uma arquitetura completa de DR após um failover. No diagrama a seguir, mostramos uma arquitetura completa de DR de banco de dados após o failover:
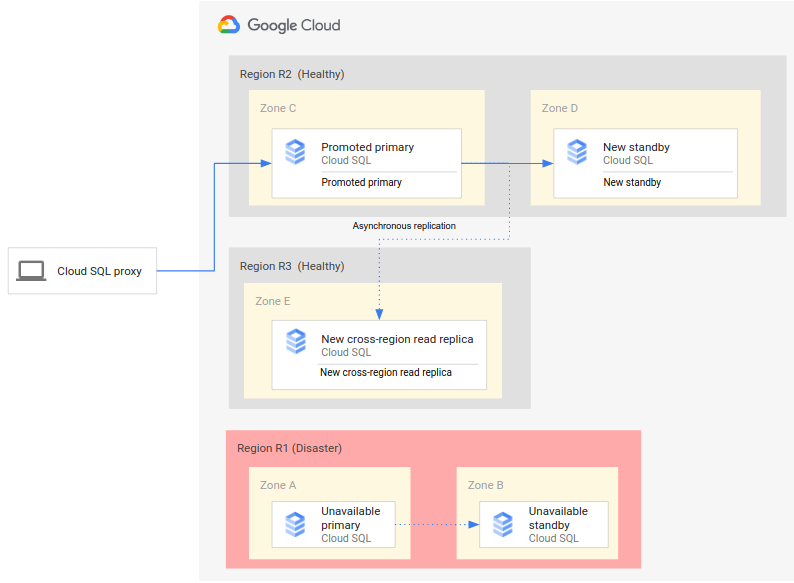
O processo completo de DR de banco de dados consiste nas seguintes etapas:
- A região principal (R1), que está executando o banco de dados principal, torna-se indisponível.
- A equipe de operações reconhece e confirma formalmente o desastre e decide se um failover é necessário.
- Se for necessário um failover, promova a réplica de leitura entre regiões na região secundária (R2) para que ela seja a nova instância principal.
- As conexões do cliente são reconfiguradas para acessar e processar na nova instância principal (R2).
- Uma nova instância em espera é criada, iniciada em R2 e adicionada à instância principal. A instância em espera está em uma zona diferente da instância principal. A instância principal agora está altamente disponível porque uma instância em espera foi criada para ela.
- Em uma terceira região (R3), uma nova réplica de leitura entre regiões é criada e anexada à instância principal. Neste ponto, uma arquitetura de recuperação de desastres completa é recriada e está em operação.
Se a região principal original (R1) ficar disponível antes da implementação da etapa 6, a réplica de leitura entre regiões poderá ser colocada na região R1, em vez de na região R3, imediatamente. Nesse caso, o fallback para a região principal original (R1) é menos complexo e requer menos etapas.
Como evitar um estado de "dupla personalidade"
Uma falha na região principal (R1) não significa que a instância principal original e a instância em espera são automaticamente encerradas, removidas ou tornadas inacessíveis quando R1 fica disponível novamente. Se R1 estiver disponível, os clientes poderão ler e gravar dados (mesmo por acidente) na instância principal original. Nesse caso, uma situação de "dupla personalidade" pode ser desenvolvida, em que alguns clientes acessam dados desatualizados no antigo banco de dados principal e outros clientes acessam dados novos no novo banco de dados principal, gerando problemas na sua empresa.
Para evitar uma situação assim, certifique-se de que os clientes não possam mais acessar a instância principal original depois que R1 estiver disponível. O ideal é tornar a instância principal original inacessível antes que os clientes comecem a usar a nova instância principal e, em seguida, excluir a instância principal original assim que ela ficar inacessível.
Como estabelecer um backup inicial após o failover
Quando você promove a réplica de leitura entre regiões como a nova principal em um failover, as transações na nova principal podem não ser totalmente sincronizadas com as transações da principal original. Portanto, essas transações não estão disponíveis na nova instância.
Como prática recomendada, faça backup imediato da nova instância principal no início do failover e antes que os clientes acessem o banco de dados. Esse backup representa um estado consistente e conhecido no ponto do failover. Esses backups podem ser importantes para fins regulatórios ou para recuperar um estado conhecido se os clientes encontrarem problemas ao acessar o novo principal.
Voltando à região primária original
Conforme descrito anteriormente, neste documento são fornecidas as etapas para voltar à região original (R1). Há duas versões diferentes do processo de fallback.
- Se você criou a nova réplica de leitura entre regiões em uma região terciária (R3), será preciso criar outra (segunda) réplica de leitura entre regiões na região principal (R1).
- Se você criou a nova réplica de leitura entre regiões na região principal (R1), não será necessário criar outra réplica de leitura entre regiões na R1.
Depois que a réplica de leitura entre regiões existir em R1, a instância do Cloud SQL poderá voltar para R1. Como esse fallback é acionado manualmente e não é baseado em uma falha, é possível escolher um dia e horário adequados para essa atividade de manutenção.
Assim, para ter uma DR completa que tenha uma réplica de leitura principal, em espera e entre regiões, você precisa de dois failovers. O primeiro failover é acionado pela falha (um failover verdadeiro) e o segundo failover restabelece a implantação inicial (fallback).
A substituição para a região principal original (R1) consiste nas seguintes etapas:
- Promover a réplica entre regiões recém-criada na região primária original (R1).
- Se a instância promovida não tiver sido criada originalmente como uma réplica de alta disponibilidade, ative a alta disponibilidade na instância para proteção contra falhas zonais.
- Reconfigure os aplicativos para que eles se conectem à nova instância principal.
- Crie uma réplica entre regiões para a nova instância principal na região de DR (R2).
- Opcional: para evitar a execução de várias instâncias principais independentes, limpe a instância principal na região de DR (R2).
Recuperação de desastres (DR) avançada
Se você estiver usando o Cloud SQL Enterprise Plus, poderá aproveitar a DR avançada. A DR avançada simplifica a recuperação e o fallback após um failover entre regiões. Conforme descrito em Processo de recuperação de desastres, ao fazer a DR, você remove a conexão entre a região com falha da instância principal antiga e a região operacional da nova instância principal. Com a DR, para restaurar as conexões para a região de implantação original e recuperar a instância principal antiga, é necessário executar uma série de etapas de substituição manuais.
Com a DR avançada, quando ocorre uma falha regional, é possível invocar um failover de réplica. Com o failover de réplica, você promove uma réplica de leitura entre regiões semelhante à execução de DR normal, exceto pela promoção da réplica de recuperação de desastres (DR) designada. A promoção da réplica de DR é imediata.
Em vez de remover a instância principal antiga, ela permanece parte da topologia de replicação assíncrona do Cloud SQL. A instância principal antiga (instância A) eventualmente se torna uma réplica da réplica de DR (instância B) depois que a réplica de DR é promovida para a nova instância principal.
Depois que a instância principal antiga (A) tiver sido transformada em uma réplica, será possível executar a etapa final da DR avançada. É possível retornar a implantação do Cloud SQL ao estado original e restaurar a instância principal antiga (A) ao papel anterior como a instância principal sem perda de dados. Para executar essa restauração sem perda de dados da antiga instância principal (A), use a operação de alternância. Quando você realiza uma alternância, não há perda de dados porque a instância principal (B) permanece no modo somente leitura até que a réplica de DR designada (A) chegue à instância principal (B). Depois que a réplica de DR (A) recebe todas as atualizações de replicação, a réplica de DR (A) assume o papel da instância principal, enquanto a instância principal anterior (B) é reconfigurada automaticamente como a réplica de DR da instância principal atual (A). As instâncias são retornadas aos papéis originais, retornando a topologia ao estado original antes da DR e do failover da réplica.
Na DR avançada, todas as instâncias envolvidas nas operações de failover e alternância de réplica mantêm os respectivos endereços IP.
Também é possível usar a operação de alternância da DR avançada para executar detalhes de rotina de DR a fim de testar e preparar sua topologia do Cloud SQL para failover entre regiões antes que ocorra um desastre. Se ocorrer um desastre real, execute o failover da réplica entre regiões que já foi testado.
Réplica de recuperação de desastres (DR)
Como um componente obrigatório da DR avançada, a réplica da DR tem as características a seguir:
- Uma réplica de DR é uma réplica de leitura entre regiões diretamente conectada.
- É possível alterar a designação da réplica de DR várias vezes.
- É possível alterar a designação da réplica de DR a qualquer momento, exceto durante uma operação de alternância ou failover de réplica.
Além disso, para reduzir o RTO depois de usar a DR avançada, recomendamos que você faça o seguinte:
- Configure a réplica de DR com o mesmo tamanho da instância principal.
- Se a instância principal tiver a alta disponibilidade ativada, recomendamos que você ative a alta disponibilidade na réplica de DR também. Para fazer isso, primeiro verifique se o primário tem HA ativado. Em seguida, faça a alternância para a réplica de DR. Depois que a operação de alternância for concluída, ative a HA na nova instância principal. Em seguida, volte para a instância principal antiga. A réplica de DR mantém a configuração de HA, mesmo depois de se tornar uma réplica novamente.
Failover da réplica
Resumindo, um failover de réplica consiste nos seguintes eventos:
- Você cria e atribui uma réplica de DR.
- A região principal fica indisponível.
- Você executa o failover de réplica para a réplica de DR.
- O endpoint de gravação é atualizado e começa a apontar para a nova instância principal.
- Quando a instância principal original volta a ficar on-line, ela se torna uma réplica de leitura da nova instância principal.
- Você pode usar a operação de alternância para restaurar a implantação à topologia original.
Para ver os detalhes e diagramas de uma operação de failover da réplica, clique nas seguintes guias.
Atribuir réplica de DR
Antes de executar um failover de réplica, você atribuiu uma réplica de DR à instância principal e, possivelmente, testou o processo realizando uma alternância.

Ocorre uma interrupção
A região principal, que está executando o banco de dados principal, fica indisponível.

Failover da réplica
Depois de determinar que a recuperação de desastres é necessária, execute um failover de réplica para a réplica de DR designada entre regiões.
A réplica de DR designada entre regiões se torna a instância principal imediatamente e começa a aceitar leituras e gravações recebidas. O endpoint de gravação é atualizado e começa a apontar para a nova instância principal.

A instância principal original se torna uma réplica.
Depois que a réplica é promovida, o Cloud SQL verifica periodicamente se a instância principal original voltou a ficar on-line. Se a instância principal original estiver on-line, o Cloud SQL vai recriar a principal antiga como uma réplica da instância promovida. A instância principal antiga mantém o endereço IP.

Retornar para o original
Depois de realizar um failover de réplica, restaure a instância principal na região original executando a operação de alternância, invertendo a mesma réplica de DR e o par de instâncias principal.

Trocar
Resumindo, uma operação de alternância consiste nos seguintes eventos:
- Você cria e atribui uma réplica de DR.
- Você inicia uma alternância.
- Quando o atraso da replicação diminui para zero, as novas instâncias principais começam a aceitar conexões de entrada.
- A instância principal antiga se torna uma réplica de leitura.
- Se um endpoint de gravação DNS estiver sendo usado, ele será atualizado para apontar para a nova instância principal.
Para conferir os detalhes e diagramas de uma operação de alternância, clique nas seguintes guias.
Atribuir réplica de DR
Antes de iniciar a operação de *alternância*, atribua uma réplica de DR à instância principal.
Verifique se a instância principal está íntegra. Só é possível realizar uma alternância quando a instância principal e a réplica de DR estão on-line.
Iniciar failover
Você inicia a alternância. Quando você inicia uma alternância, a instância principal deixa de aceitar gravações e se torna somente leitura. O Cloud SQL aguarda a cópia dos registros de transação para o Cloud Storage. A réplica de DR designada alcança a instância principal.
Quando o atraso da replicação diminui para zero, a réplica de DR é promovida como a nova instância principal. A nova instância principal começa a aceitar as conexões de entrada, incluindo leituras e gravações de aplicativos.
Endpoint atualizado
Depois que a réplica de DR é promovida para a nova instância principal, o endpoint de gravação DNS é atualizado e começa a apontar para a nova instância principal. Se você não estiver usando um endpoint de gravação de DNS, configure seus aplicativos para apontar para o endereço IP da nova instância principal.
A instância principal antiga é reconfigurada como uma réplica de leitura.
A PITR é ativada automaticamente para a nova instância principal. A PITR só é possível após o primeiro backup automatizado.
Endpoint de gravação
Um endpoint de gravação é um nome de serviço de nome de domínio (DNS) global que se refere automaticamente ao endereço IP da instância principal atual. Esse endpoint redireciona as conexões de entrada para a nova instância principal automaticamente no caso de uma operação de failover ou alternância da réplica. É possível usar o endpoint de gravação em uma string de conexão SQL em vez de um endereço IP. Ao usar um endpoint de gravação, você evita ter que fazer mudanças na conexão do aplicativo quando ocorre uma interrupção regional.
Um endpoint de gravação exige que a API Cloud DNS esteja ativada no projeto em que você cria ou tem sua instância principal do Cloud SQL Enterprise Plus. Quando você cria uma instância do Cloud SQL edição Enterprise Plus com um endereço IP particular e redes autorizadas, o Cloud SQL gera um endpoint de gravação para a instância automaticamente. Se você já tiver uma instância principal do Cloud SQL Enterprise Plus, o Cloud SQL vai gerar o endpoint de gravação quando você criar a réplica de DR (uma réplica entre regiões designada para a instância principal). Se a instância principal mudar devido a uma operação de alternância ou failover de réplica, o Cloud SQL vai atribuir o endpoint de gravação à réplica de DR quando ela se tornar a nova instância principal.
Para mais informações sobre como usar um endpoint de gravação para se conectar a uma instância, consulte Conectar-se a uma instância usando um endpoint de gravação.
A seguir
- Usar a recuperação avançada de desastres (DR).
- Confira arquiteturas de referência, diagramas, tutoriais e práticas recomendadas sobre Google Cloud. Confira o Centro de arquitetura do Cloud.