本部署文件說明如何部署 Dataflow 管道,以使用 Cloud Vision API 大規模處理圖片檔。這個管道會將處理後的檔案結果儲存在 BigQuery 中。您可以將這些檔案用於分析,或訓練 BigQuery ML 模型。
您在這個部署作業中建立的 Dataflow 管道,每天可處理數百萬張圖片。唯一限制是Vision API 配額。您可以根據規模需求提高 Vision API 配額。
以下操作說明專供資料工程師和資料科學家參考。本文假設您已具備使用 Apache Beam 的 Java SDK、BigQuery 適用的 GoogleSQL 和基本殼層指令碼,建構 Dataflow 管道的基礎知識。此外,您也必須熟悉 Vision API。
架構
下圖說明建構 ML 視覺分析解決方案的系統流程。

在上圖中,資訊會透過架構流動,如下所示:
- 用戶端將圖片檔上傳至 Cloud Storage bucket。
- Cloud Storage 會將資料上傳訊息傳送至 Pub/Sub。
- Pub/Sub 會通知 Dataflow 上傳作業。
- Dataflow 管道會將圖片傳送至 Vision API。
- Vision API 會處理圖片,然後傳回註解。
- 管道會將註解檔案傳送至 BigQuery,供您分析。
目標
- 建立 Apache Beam 管道,用於分析 Cloud Storage 中載入的圖片。
- 使用 Dataflow Runner v2 以串流模式執行 Apache Beam 管道,在圖片上傳後立即進行分析。
- 使用 Vision API 分析圖片,取得一組功能類型。
- 使用 BigQuery 分析註解。
費用
在本文件中,您會使用下列 Google Cloud的計費元件:
如要根據預測用量估算費用,請使用 Pricing Calculator。
建構範例應用程式後,您可以刪除已建立的資源,避免系統繼續計費。詳情請參閱清除所用資源一節。
事前準備
- Sign in to your Google Cloud account. If you're new to Google Cloud, create an account to evaluate how our products perform in real-world scenarios. New customers also get $300 in free credits to run, test, and deploy workloads.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
-
In the Google Cloud console, activate Cloud Shell.
At the bottom of the Google Cloud console, a Cloud Shell session starts and displays a command-line prompt. Cloud Shell is a shell environment with the Google Cloud CLI already installed and with values already set for your current project. It can take a few seconds for the session to initialize.
- 複製包含 Dataflow 管道原始碼的 GitHub 存放區:
git clone https://github.com/GoogleCloudPlatform/dataflow-vision-analytics.git - 前往存放區的根資料夾:
cd dataflow-vision-analytics - 請按照 GitHub 中 dataflow-vision-analytics 存放區的「Getting started」(開始使用) 部分操作說明,完成下列工作:
- 啟用多個 API。
- 建立 Cloud Storage bucket。
- 建立 Pub/Sub 主題和訂閱項目。
- 建立 BigQuery 資料集。
- 為這次部署作業設定多個環境變數。
在 Cloud Shell 中執行下列指令,處理 Dataflow 管道支援的所有特徵類型圖片:
./gradlew run --args=" \ --jobName=test-vision-analytics \ --streaming \ --runner=DataflowRunner \ --enableStreamingEngine \ --diskSizeGb=30 \ --project=${PROJECT} \ --datasetName=${BIGQUERY_DATASET} \ --subscriberId=projects/${PROJECT}/subscriptions/${GCS_NOTIFICATION_SUBSCRIPTION} \ --visionApiProjectId=${PROJECT} \ --features=IMAGE_PROPERTIES,LABEL_DETECTION,LANDMARK_DETECTION,LOGO_DETECTION,CROP_HINTS,FACE_DETECTION"專屬服務帳戶必須具備包含圖片的值區讀取權限。換句話說,該帳戶必須在該 bucket 上獲授
roles/storage.objectViewer角色。如要進一步瞭解如何使用專屬服務帳戶,請參閱「Dataflow 安全性和權限」。
在新瀏覽器分頁中開啟顯示的網址,或前往 Dataflow Jobs 頁面,然後選取 test-vision-analytics 管道。
幾秒後,系統會顯示 Dataflow 工作圖表:
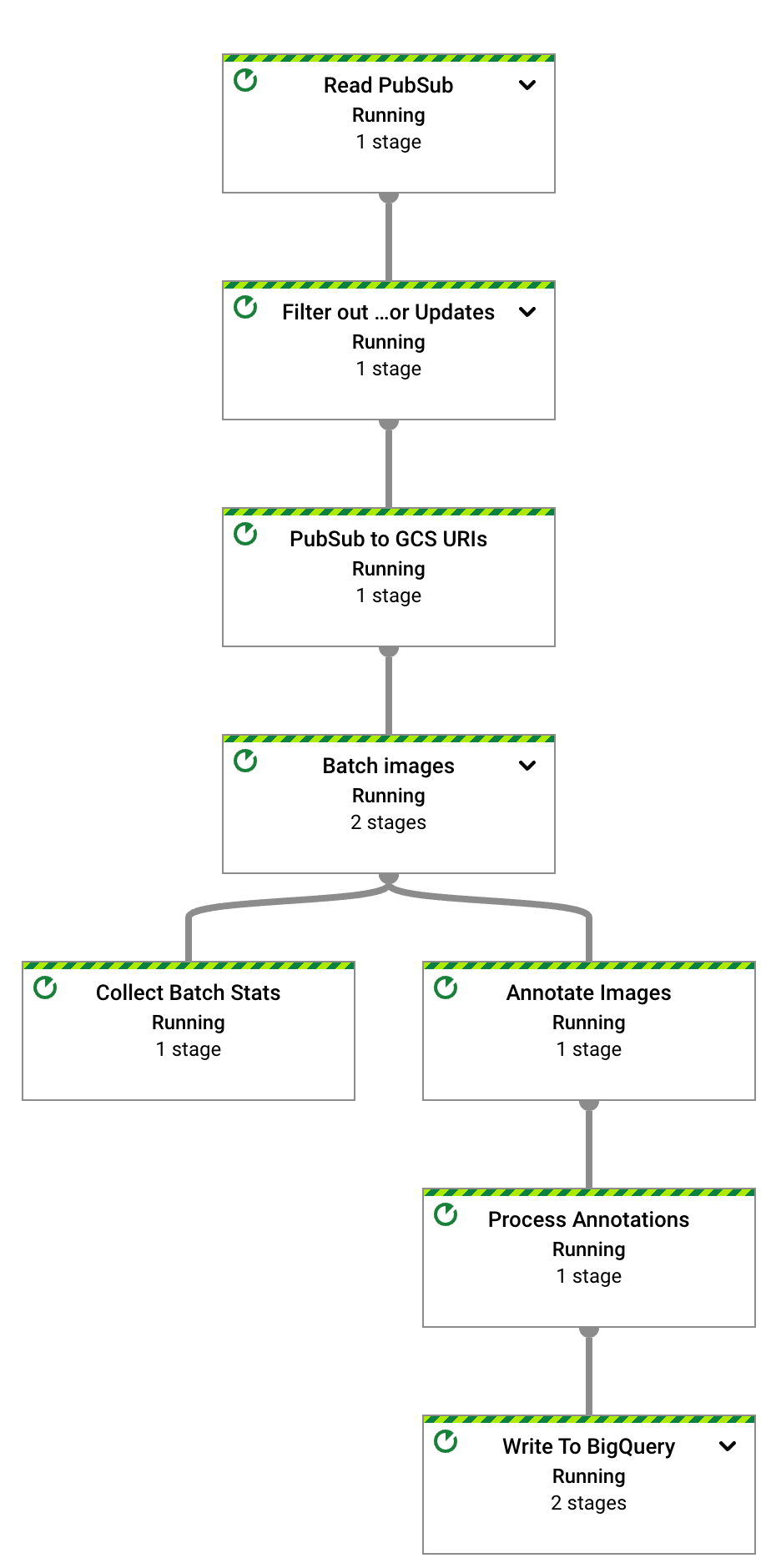
Dataflow 管道現在正在執行,並等待接收來自 Pub/Sub 訂閱項目的輸入通知。
將六個範例檔案上傳至輸入值區,觸發 Dataflow 圖片處理作業:
gcloud storage cp data-sample/* gs://${IMAGE_BUCKET}在 Google Cloud 控制台中,找到「Custom Counters」(自訂計數器) 面板,並使用該面板查看 Dataflow 中的自訂計數器,確認 Dataflow 已處理所有六張圖片。您可以使用面板的篩選功能,前往正確的指標。如要只顯示以
numberOf前置字串開頭的計數器,請在篩選器中輸入numberOf。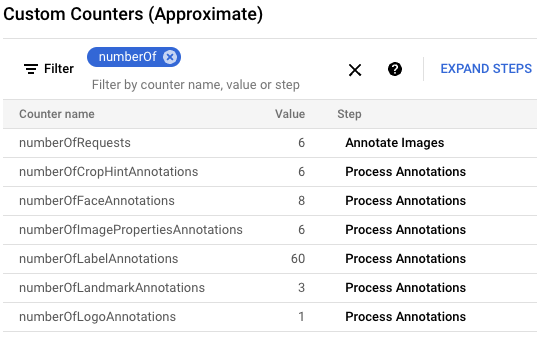
在 Cloud Shell 中,驗證系統是否已自動建立資料表:
bq query --nouse_legacy_sql "SELECT table_name FROM ${BIGQUERY_DATASET}.INFORMATION_SCHEMA.TABLES ORDER BY table_name"輸出看起來像這樣:
+----------------------+ | table_name | +----------------------+ | crop_hint_annotation | | face_annotation | | image_properties | | label_annotation | | landmark_annotation | | logo_annotation | +----------------------+
查看
landmark_annotation資料表的結構定義。LANDMARK_DETECTION功能會擷取從 API 呼叫傳回的屬性。bq show --schema --format=prettyjson ${BIGQUERY_DATASET}.landmark_annotation輸出看起來像這樣:
[ { "name":"gcs_uri", "type":"STRING" }, { "name":"feature_type", "type":"STRING" }, { "name":"transaction_timestamp", "type":"STRING" }, { "name":"mid", "type":"STRING" }, { "name":"description", "type":"STRING" }, { "name":"score", "type":"FLOAT" }, { "fields":[ { "fields":[ { "name":"x", "type":"INTEGER" }, { "name":"y", "type":"INTEGER" } ], "mode":"REPEATED", "name":"vertices", "type":"RECORD" } ], "name":"boundingPoly", "type":"RECORD" }, { "fields":[ { "fields":[ { "name":"latitude", "type":"FLOAT" }, { "name":"longitude", "type":"FLOAT" } ], "name":"latLon", "type":"RECORD" } ], "mode":"REPEATED", "name":"locations", "type":"RECORD" } ]執行下列
bq query指令,即可查看 API 產生的註解資料,並依最可能的得分排序,查看這六張圖片中找到的所有地標:bq query --nouse_legacy_sql "SELECT SPLIT(gcs_uri, '/')[OFFSET(3)] file_name, description, score, locations FROM ${BIGQUERY_DATASET}.landmark_annotation ORDER BY score DESC"輸出結果會與下列內容相似:
+------------------+-------------------+------------+---------------------------------+ | file_name | description | score | locations | +------------------+-------------------+------------+---------------------------------+ | eiffel_tower.jpg | Eiffel Tower | 0.7251996 | ["POINT(2.2944813 48.8583701)"] | | eiffel_tower.jpg | Trocadéro Gardens | 0.69601923 | ["POINT(2.2892823 48.8615963)"] | | eiffel_tower.jpg | Champ De Mars | 0.6800974 | ["POINT(2.2986304 48.8556475)"] | +------------------+-------------------+------------+---------------------------------+
如要詳細瞭解備註專用的所有資料欄,請參閱
AnnotateImageResponse。如要停止串流管道,請執行下列指令。即使沒有要處理的 Pub/Sub 通知,管道仍會繼續執行。
gcloud dataflow jobs cancel --region ${REGION} $(gcloud dataflow jobs list --region ${REGION} --filter="NAME:test-vision-analytics AND STATE:Running" --format="get(JOB_ID)")下一節包含更多範例查詢,可分析圖片的不同影像特徵。
在 Cloud Shell 中,變更 Dataflow 管道參數,以便針對大型資料集進行最佳化。如要提高輸送量,請一併增加
batchSize和keyRange值。Dataflow 會視需要調度工作站數量:./gradlew run --args=" \ --runner=DataflowRunner \ --jobName=vision-analytics-flickr \ --streaming \ --enableStreamingEngine \ --diskSizeGb=30 \ --autoscalingAlgorithm=THROUGHPUT_BASED \ --maxNumWorkers=5 \ --project=${PROJECT} \ --region=${REGION} \ --subscriberId=projects/${PROJECT}/subscriptions/${GCS_NOTIFICATION_SUBSCRIPTION} \ --visionApiProjectId=${PROJECT} \ --features=LABEL_DETECTION,LANDMARK_DETECTION \ --datasetName=${BIGQUERY_DATASET} \ --batchSize=16 \ --keyRange=5"由於資料集很大,您無法使用 Cloud Shell 從 Kaggle 擷取圖片,並傳送至 Cloud Storage 值區。您必須使用磁碟大小較大的 VM 才能執行這項操作。
如要擷取 Kaggle 圖片並傳送至 Cloud Storage 值區,請按照 GitHub 存放區中「模擬圖片上傳至儲存空間值區」一節的說明操作。
如要透過 Dataflow UI 中提供的自訂指標觀察複製作業的進度,請前往「Dataflow Jobs」(Dataflow 工作) 頁面,然後選取
vision-analytics-flickr管道。在 Dataflow 管道處理所有檔案之前,客戶計數器應會定期變更。輸出結果類似於「自訂計數器」面板的下列螢幕截圖。資料集中的其中一個檔案類型有誤,
rejectedFiles計數器會反映這項問題。這些計數器值為約略值。您可能會看到較高的數字。此外,由於 Vision API 的處理準確度提升,註解數量很可能也會有所變動。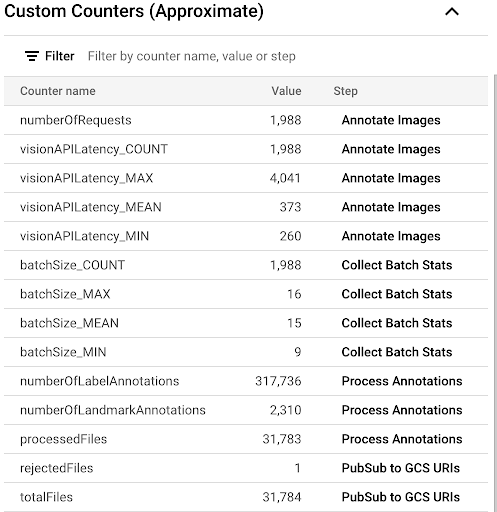
如要判斷您是否即將用盡或已用盡可用資源,請參閱 Vision API 配額頁面。
在本範例中,Dataflow 管道只使用了約 50% 的配額。根據配額用量百分比,您可以決定增加
keyRange參數的值,藉此提高管道的平行處理能力。關閉管道:
gcloud dataflow jobs list --region $REGION --filter="NAME:vision-analytics-flickr AND STATE:Running" --format="get(JOB_ID)"前往 Google Cloud 控制台的 BigQuery 查詢編輯器頁面,然後執行下列指令,查看資料集中前 20 個標籤:
SELECT description, count(*)ascount \ FROM vision_analytics.label_annotation GROUP BY description ORDER BY count DESC LIMIT 20輸出結果會與下列內容相似:
+------------------+-------+ | description | count | +------------------+-------+ | Leisure | 7663 | | Plant | 6858 | | Event | 6044 | | Sky | 6016 | | Tree | 5610 | | Fun | 5008 | | Grass | 4279 | | Recreation | 4176 | | Shorts | 3765 | | Happy | 3494 | | Wheel | 3372 | | Tire | 3371 | | Water | 3344 | | Vehicle | 3068 | | People in nature | 2962 | | Gesture | 2909 | | Sports equipment | 2861 | | Building | 2824 | | T-shirt | 2728 | | Wood | 2606 | +------------------+-------+
根據特定標籤,判斷圖片上還有哪些其他標籤,並依出現頻率排序:
DECLARE label STRING DEFAULT 'Plucked string instruments'; WITH other_labels AS ( SELECT description, COUNT(*) count FROM vision_analytics.label_annotation WHERE gcs_uri IN ( SELECT gcs_uri FROM vision_analytics.label_annotation WHERE description = label ) AND description != label GROUP BY description) SELECT description, count, RANK() OVER (ORDER BY count DESC) rank FROM other_labels ORDER BY rank LIMIT 20;輸出內容如下所示。針對上述指令中使用的「Plucked string instruments」(撥弦樂器) 標籤,您應該會看到:
+------------------------------+-------+------+ | description | count | rank | +------------------------------+-------+------+ | String instrument | 397 | 1 | | Musical instrument | 236 | 2 | | Musician | 207 | 3 | | Guitar | 168 | 4 | | Guitar accessory | 135 | 5 | | String instrument accessory | 99 | 6 | | Music | 88 | 7 | | Musical instrument accessory | 72 | 8 | | Guitarist | 72 | 8 | | Microphone | 52 | 10 | | Folk instrument | 44 | 11 | | Violin family | 28 | 12 | | Hat | 23 | 13 | | Entertainment | 22 | 14 | | Band plays | 21 | 15 | | Jeans | 17 | 16 | | Plant | 16 | 17 | | Public address system | 16 | 17 | | Artist | 16 | 17 | | Leisure | 14 | 20 | +------------------------------+-------+------+
查看偵測到的前 10 個地標:
SELECT description, COUNT(description) AS count FROM vision_analytics.landmark_annotation GROUP BY description ORDER BY count DESC LIMIT 10輸出看起來像這樣:
+--------------------+-------+ | description | count | +--------------------+-------+ | Times Square | 55 | | Rockefeller Center | 21 | | St. Mark's Square | 16 | | Bryant Park | 13 | | Millennium Park | 13 | | Ponte Vecchio | 13 | | Tuileries Garden | 13 | | Central Park | 12 | | Starbucks | 12 | | National Mall | 11 | +--------------------+-------+
判斷最有可能含有瀑布的圖片:
SELECT SPLIT(gcs_uri, '/')[OFFSET(3)] file_name, description, score FROM vision_analytics.landmark_annotation WHERE LOWER(description) LIKE '%fall%' ORDER BY score DESC LIMIT 10輸出看起來像這樣:
+----------------+----------------------------+-----------+ | file_name | description | score | +----------------+----------------------------+-----------+ | 895502702.jpg | Waterfall Carispaccha | 0.6181358 | | 3639105305.jpg | Sahalie Falls Viewpoint | 0.44379658 | | 3672309620.jpg | Gullfoss Falls | 0.41680416 | | 2452686995.jpg | Wahclella Falls | 0.39005348 | | 2452686995.jpg | Wahclella Falls | 0.3792498 | | 3484649669.jpg | Kodiveri Waterfalls | 0.35024035 | | 539801139.jpg | Mallela Thirtham Waterfall | 0.29260656 | | 3639105305.jpg | Sahalie Falls | 0.2807213 | | 3050114829.jpg | Kawasan Falls | 0.27511594 | | 4707103760.jpg | Niagara Falls | 0.18691841 | +----------------+----------------------------+-----------+
在羅馬競技場 3 公里內尋找地標圖片 (
ST_GEOPOINT函式會使用羅馬競技場的經緯度):WITH landmarksWithDistances AS ( SELECT gcs_uri, description, location, ST_DISTANCE(location, ST_GEOGPOINT(12.492231, 41.890222)) distance_in_meters, FROM `vision_analytics.landmark_annotation` landmarks CROSS JOIN UNNEST(landmarks.locations) AS location ) SELECT SPLIT(gcs_uri,"/")[OFFSET(3)] file, description, ROUND(distance_in_meters) distance_in_meters, location, CONCAT("https://storage.cloud.google.com/", SUBSTR(gcs_uri, 6)) AS image_url FROM landmarksWithDistances WHERE distance_in_meters < 3000 ORDER BY distance_in_meters LIMIT 100執行查詢後,您會發現除了羅馬競技場的圖片外,還有君士坦丁凱旋門、帕拉丁山,以及其他許多經常拍攝的地點。
您可以在 BigQuery Geo Viz 中貼上先前的查詢,以視覺化方式呈現資料。選取地圖上的點,即可查看詳細資料。
Image_url屬性包含圖片檔案的連結。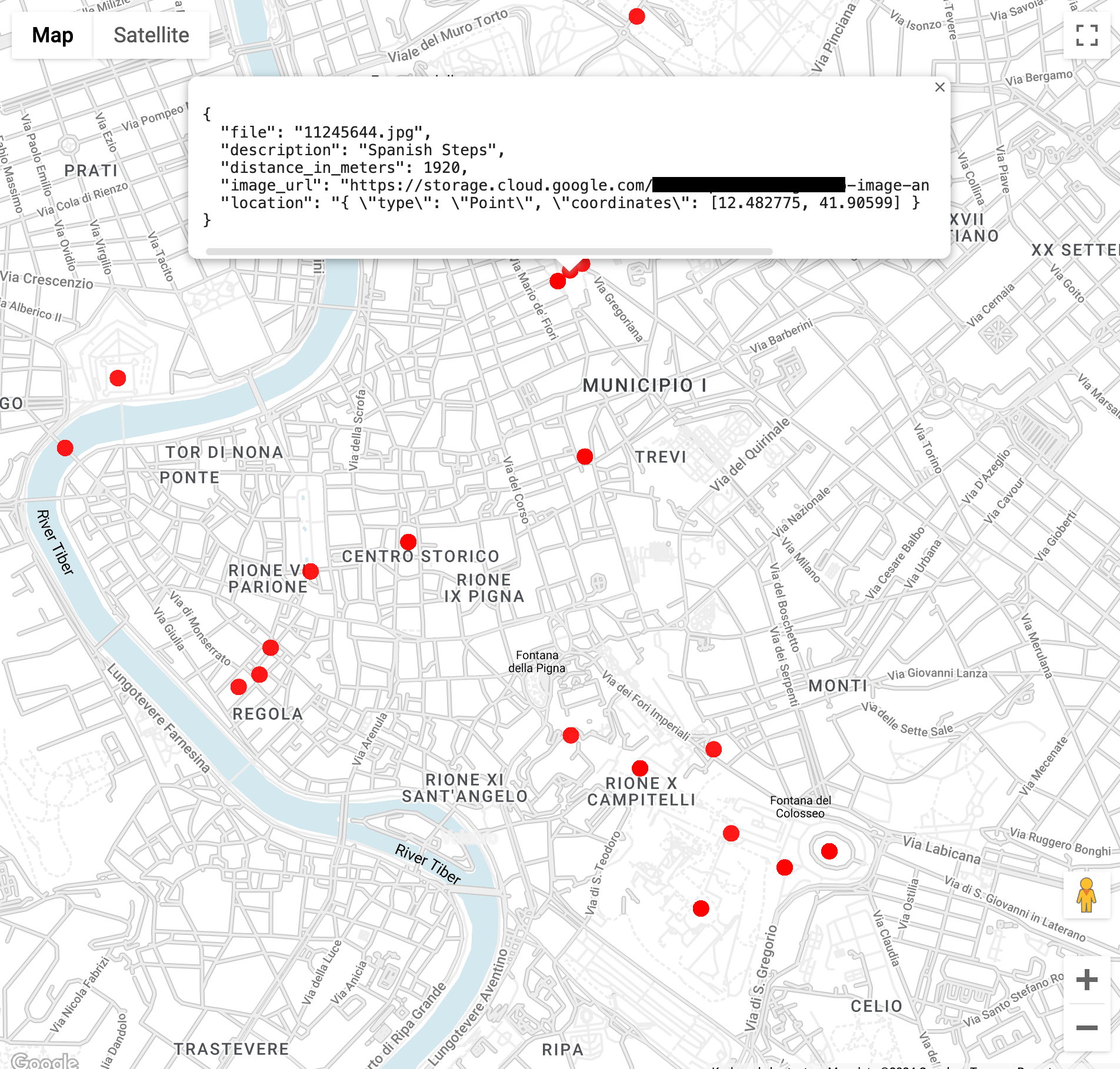
- In the Google Cloud console, go to the Manage resources page.
- In the project list, select the project that you want to delete, and then click Delete.
- In the dialog, type the project ID, and then click Shut down to delete the project.
- 如要查看更多參考架構、圖表和最佳做法,請瀏覽 Cloud 架構中心。
- Masud Hasan | 網站可靠性工程經理
- Sergei Lilichenko | 解決方案架構師
- Lakshmanan Sethu | 客戶技術顧問
- Jiyeon Kang | 客戶工程師
- Sunil Kumar Jang Bahadur | 客戶工程師
針對所有已導入的 Vision API 功能執行 Dataflow 管道
Dataflow 管道會要求並處理註解檔案中的特定 Vision API 功能和屬性集。
下表列出的參數是這個部署作業中 Dataflow 管道專用的參數。如需標準 Dataflow 執行參數的完整清單,請參閱「設定 Dataflow 管道選項」。
| 參數名稱 | 說明 |
|---|---|
|
要求中要納入 Vision API 的圖片數量。預設值為 1。您可以將這個值調高至最多 16。 |
|
輸出 BigQuery 資料集的名稱。 |
|
圖片處理功能清單。這個管道支援標籤、地標、標誌、臉孔、裁剪提示和圖片屬性功能。 |
|
這個參數會定義 Vision API 的平行呼叫次數上限。預設值是 1。 |
|
含有各種註解資料表名稱的字串參數。每個表格都會提供預設值,例如 label_annotation。 |
|
如果圖片批次處理作業未完成,系統會等待一段時間再處理圖片。預設值為 30 秒。 |
|
接收輸入 Cloud Storage 通知的 Pub/Sub 訂閱 ID。 |
|
要用於 Vision API 的專案 ID。 |
分析 Flickr30K 資料集
在本節中,您將偵測 Kaggle 託管的公開 Flickr30k 圖片資料集中的標籤和地標。
在 BigQuery 中分析註解
在這個部署作業中,您已處理超過 30,000 張圖片,用於標籤和地標註解。在本節中,您將收集這些檔案的統計資料。 您可以在 BigQuery 的 GoogleSQL 工作區中執行這些查詢,也可以使用 bq 指令列工具。
請注意,您看到的數字可能與這個部署作業中的範例查詢結果不同。Vision API 會不斷提升分析準確度;在您初步測試解決方案後,分析同一張圖片可產生更豐富的結果。
查詢結果注意事項。地標通常會提供位置資訊。同一張圖片可能包含同一地標的多個位置。
這項功能會在 AnnotateImageResponse 型別中說明。
因為一個位置可以指出圖片中場景的位置,所以可以有多個 LocationInfo 元素。另一個位置則可指出圖片的拍攝地點。
清除所用資源
如要避免系統向您的 Google Cloud 帳戶收取本指南所用資源的費用,請刪除含有相關資源的專案,或者保留專案但刪除個別資源。
刪除 Google Cloud 專案
如要避免付費,最簡單的方法就是刪除您針對教學課程建立的 Google Cloud 專案。
如要個別刪除資源,請按照 GitHub 存放區「清除」一節的步驟操作。
後續步驟
貢獻者
作者:
其他貢獻者: