Para garantir que os exemplos de utilização dos consumidores de dados são cumpridos, é essencial que os produtos de dados numa malha de dados sejam concebidos e criados com cuidado. A conceção de um produto de dados começa com a definição de como os consumidores de dados usariam esse produto e como esse produto é, então, exposto aos consumidores. Os produtos de dados numa malha de dados são criados com base num repositório de dados (por exemplo, um armazém de dados ou um lago de dados de domínio). Quando cria produtos de dados numa malha de dados, existem alguns fatores importantes que recomendamos que tenha em conta ao longo deste processo. Estas considerações estão descritas neste documento.
Este documento faz parte de uma série que descreve como implementar uma malha de dados no Google Cloud. Parte do princípio de que leu e está familiarizado com os conceitos descritos em Arquitetura e funções numa malha de dados e Crie uma malha de dados moderna e distribuída com o Google Cloud.
A série tem as seguintes partes:
- Arquitetura e funções numa malha de dados
- Conceba uma plataforma de dados self-service para uma malha de dados
- Crie produtos de dados numa malha de dados (este documento)
- Descubra e consuma produtos de dados numa malha de dados
Quando criar produtos de dados a partir de um armazém de dados de domínio, recomendamos que os produtores de dados criem cuidadosamente interfaces analíticas (de consumo) para esses produtos. Estas interfaces de consumo são um conjunto de garantias sobre a qualidade dos dados e os parâmetros operacionais, juntamente com um modelo de apoio técnico do produto e documentação do produto. O custo da alteração das interfaces de consumo é normalmente elevado devido à necessidade de o produtor de dados e, potencialmente, vários consumidores de dados alterarem os respetivos processos e aplicações de consumo. Dado que os consumidores de dados têm maior probabilidade de estar em unidades organizacionais separadas das dos produtores de dados, a coordenação das alterações pode ser difícil.
As secções seguintes fornecem informações gerais sobre o que tem de considerar ao criar um armazém de dados de domínio, definir interfaces de consumo e expor essas interfaces aos consumidores de dados.
Crie um armazém de dados de domínio
Não existe uma diferença fundamental entre criar um armazém de dados autónomo e criar um armazém de dados de domínio a partir do qual a equipa de produção de dados cria produtos de dados. A única diferença real entre os dois é que o último expõe um subconjunto dos respetivos dados através das interfaces de consumo.
Em muitos armazéns de dados, os dados não processados carregados a partir de origens de dados operacionais passam pelo processo de enriquecimento e verificação da qualidade dos dados (organização). Nos data lakes geridos pelo catálogo universal do Dataplex, os dados organizados são normalmente armazenados em zonas organizadas designadas. Quando a organização estiver concluída, um subconjunto dos dados deve estar pronto para consumo externo ao domínio através de vários tipos de interfaces. Para definir essas interfaces de consumo, uma organização deve fornecer um conjunto de ferramentas às equipas de domínio que estão a adotar uma abordagem de malha de dados. Estas ferramentas permitem que os produtores de dados criem novos produtos de dados de forma autónoma. Para ver as práticas recomendadas, consulte o artigo Crie uma plataforma de dados self-service.
Além disso, os produtos de dados têm de cumprir os requisitos de governação de dados definidos centralmente. Estes requisitos afetam a qualidade dos dados, a disponibilidade dos dados e a gestão do ciclo de vida. Uma vez que estes requisitos criam a confiança dos consumidores de dados nos produtos de dados e incentivam a utilização dos produtos de dados, as vantagens da implementação destes requisitos compensam o esforço de os apoiar.
Defina interfaces de consumo
Recomendamos que os produtores de dados usem vários tipos de interfaces, em vez de definir apenas um ou dois. Cada tipo de interface na estatística de dados tem vantagens e desvantagens, e não existe um único tipo de interface que se destaque em tudo. Quando os produtores de dados avaliam a adequação de cada tipo de interface, têm de considerar o seguinte:
- Capacidade de realizar o tratamento de dados necessário.
- Escalabilidade para suportar exemplos de utilização de consumidores de dados atuais e futuros.
- Desempenho exigido pelos consumidores de dados.
- Custo de desenvolvimento e manutenção.
- Custo de execução da interface.
- Suporte pelos idiomas e ferramentas que a sua organização usa.
- Suporte para a separação do armazenamento e da computação.
Por exemplo, se o requisito empresarial for poder executar consultas analíticas num conjunto de dados de 1 petabyte, a única interface prática é uma vista do BigQuery. No entanto, se os requisitos forem fornecer dados de streaming quase em tempo real, uma interface baseada no Pub/Sub é mais adequada.
Muitas destas interfaces não requerem que copie nem replique dados existentes. A maioria também permite separar o armazenamento e a computação, uma funcionalidade essencial dasGoogle Cloud ferramentas de análise. Os consumidores de dados expostos através destas interfaces processam os dados usando os recursos de computação disponíveis para eles. Os produtores de dados não têm de fazer aprovisionamento de infraestrutura adicional.
Existe uma grande variedade de interfaces de consumo. As seguintes interfaces são as mais comuns usadas numa malha de dados e são abordadas nas secções seguintes:
- Vistas e funções autorizadas
- APIs de leitura direta
- Dados como streams
- API Data Access
- Blocos do Looker
- Modelos de aprendizagem automática (AA)
A lista de interfaces neste documento não é exaustiva. Também existem outras opções que pode considerar para as suas interfaces de consumo (por exemplo, a partilha do BigQuery [anteriormente Analytics Hub]). No entanto, estas outras interfaces estão fora do âmbito deste documento.
Vistas e funções autorizadas
Sempre que possível, os produtos de dados devem ser expostos através de vistas autorizadas e funções autorizadas,incluindo funções de valor de tabela. Os conjuntos de dados autorizados oferecem uma forma conveniente de autorizar várias vistas automaticamente. A utilização de vistas autorizadas impede o acesso direto às tabelas de base e permite-lhe otimizar as tabelas subjacentes e as consultas em relação às mesmas, sem afetar a utilização destas vistas por parte dos consumidores. Os consumidores desta interface usam SQL para consultar os dados. O diagrama seguinte ilustra a utilização de conjuntos de dados autorizados como a interface de consumo.
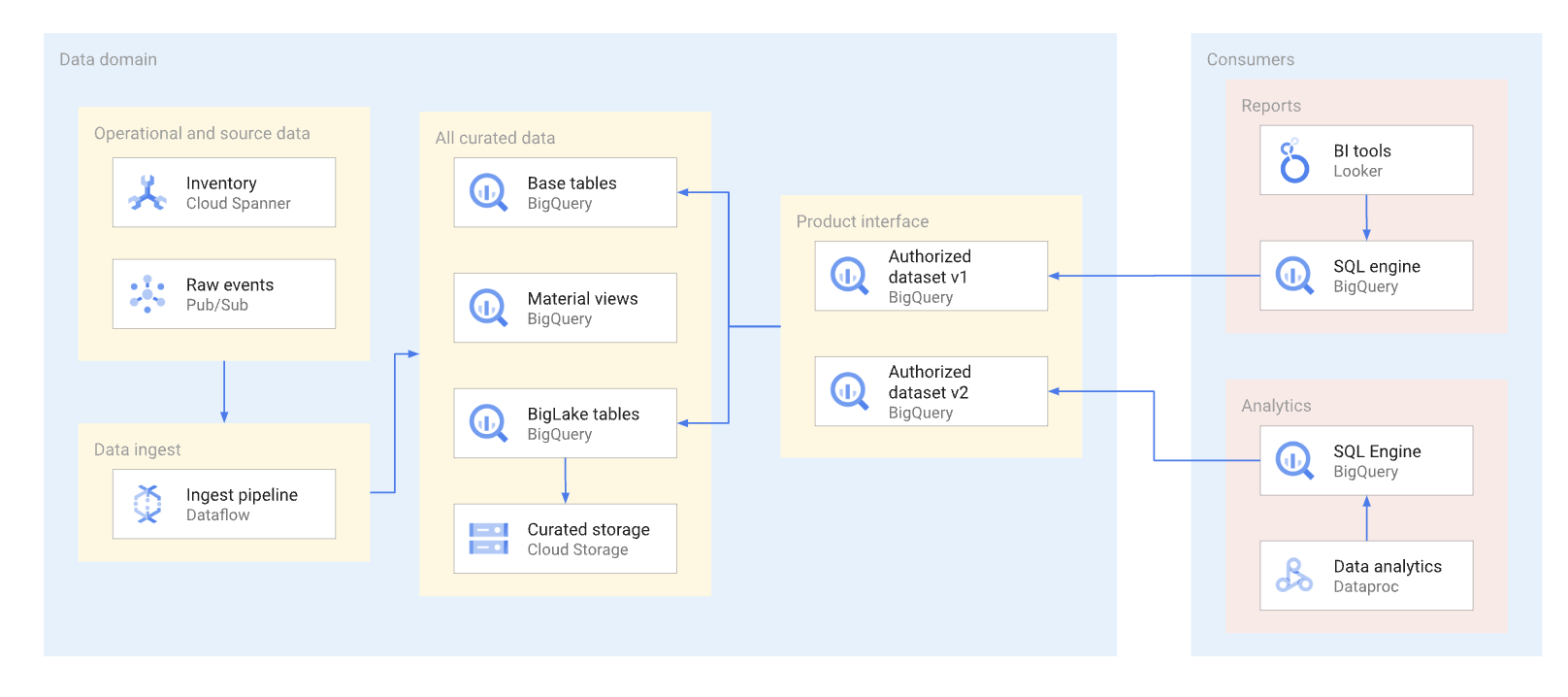
Os conjuntos de dados e as vistas autorizados ajudam a ativar facilmente o controlo de versões das interfaces. Conforme mostrado no diagrama seguinte, existem duas abordagens de controlo de versões principais que os produtores de dados podem adotar:
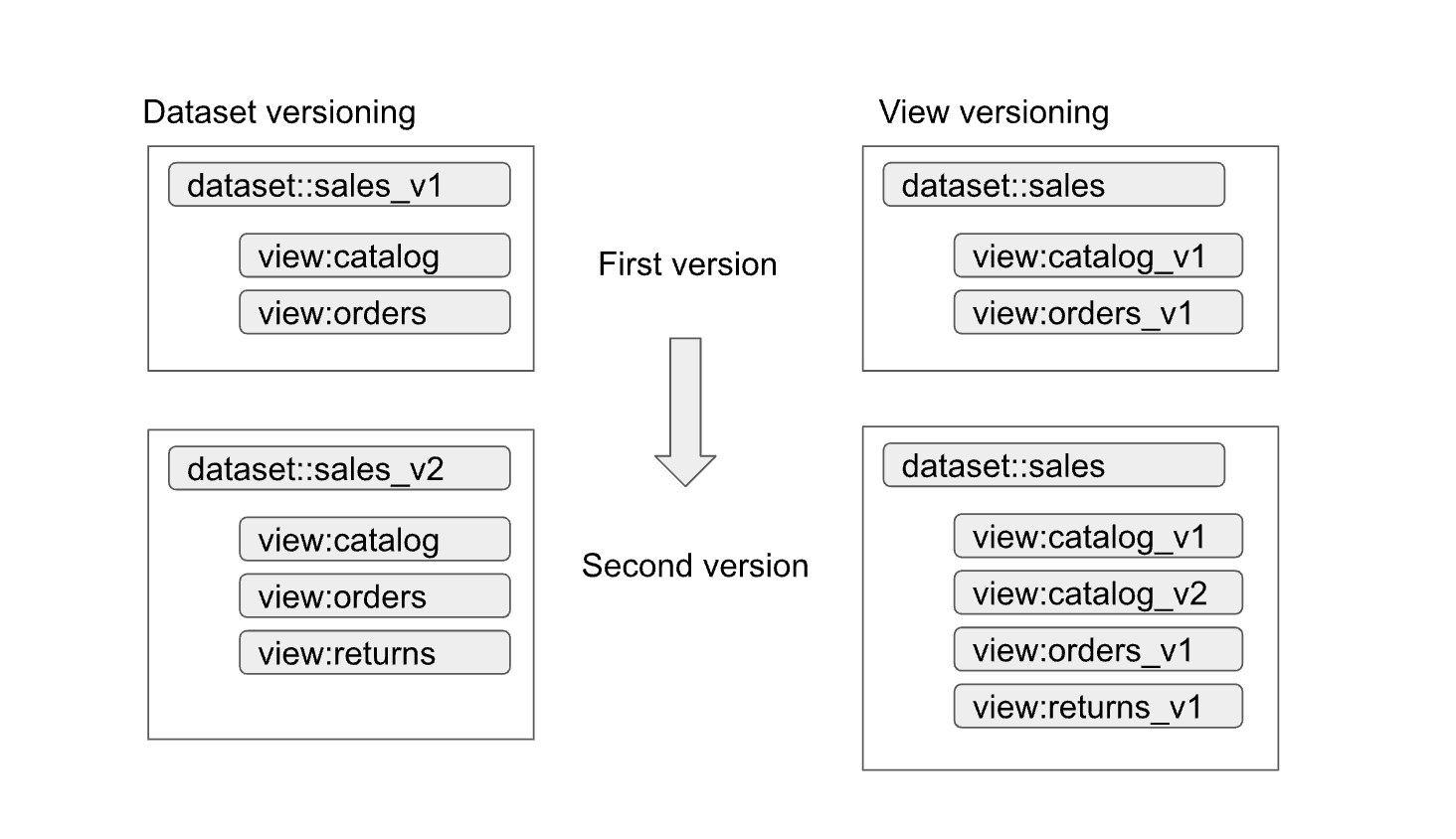
As abordagens podem ser resumidas da seguinte forma:
- Controlo de versões do conjunto de dados: nesta abordagem, controla as versões do nome do conjunto de dados.
Não controla as versões das visualizações de propriedades e das funções no conjunto de dados. Mantém os mesmos nomes para as vistas e funções, independentemente da versão. Por exemplo, a primeira versão de um conjunto de dados de vendas é definida num conjunto de dados denominado
sales_v1com duas visualizações,catalogeorders. Para a segunda versão, o conjunto de dados de vendas foi mudado parasales_v2, e todas as visualizações anteriores no conjunto de dados mantêm os nomes anteriores, mas têm novos esquemas. A segunda versão do conjunto de dados também pode ter novas visualizações adicionadas ou remover qualquer uma das visualizações anteriores. - Controlo de versões das visualizações de propriedades: nesta abordagem, as visualizações de propriedades no conjunto de dados têm versões em vez do próprio conjunto de dados. Por exemplo, o conjunto de dados de vendas
mantém o nome de
salesindependentemente da versão. No entanto, os nomes das visualizações no conjunto de dados mudam para refletir cada nova versão da visualização (comocatalog_v1,catalog_v2,orders_v1,orders_v2eorders_v3).
A melhor abordagem de controlo de versões para a sua organização depende das políticas da organização e do número de vistas que ficam obsoletas com a atualização dos dados subjacentes. O controlo de versões do conjunto de dados é mais adequado quando é necessária uma atualização importante do produto e a maioria das visualizações tem de ser alterada. O controlo de versões das vistas resulta em menos vistas com o mesmo nome em diferentes conjuntos de dados, mas pode gerar ambiguidades, por exemplo, como saber se uma junção entre conjuntos de dados funciona corretamente. Uma abordagem híbrida pode ser um bom compromisso. Numa abordagem híbrida, as alterações de esquema compatíveis são permitidas num único conjunto de dados, e as alterações incompatíveis requerem um novo conjunto de dados.
Considerações sobre a tabela do BigLake
As vistas autorizadas podem ser criadas não só em tabelas do BigQuery, mas também em tabelas do BigLake. As tabelas BigLake permitem que os consumidores consultem os dados armazenados no Cloud Storage através da interface SQL do BigQuery. As tabelas do BigLake suportam o controlo de acesso detalhado sem que os consumidores de dados tenham autorizações de leitura para o contentor do Cloud Storage subjacente.
Os produtores de dados têm de considerar o seguinte para as tabelas do BigLake:
- O design dos formatos de ficheiros e a disposição dos dados influenciam o desempenho das consultas. Os formatos baseados em colunas, por exemplo, o Parquet ou o ORC, geralmente, têm um desempenho muito melhor para consultas analíticas do que os formatos JSON ou CSV.
- Um esquema particionado do Hive permite remover partições e acelera as consultas que usam colunas de partição.
- O número de ficheiros e o desempenho de consulta preferencial para o tamanho do ficheiro também têm de ser tidos em conta na fase de conceção.
Se as consultas que usam tabelas BigLake não cumprirem os requisitos do contrato de nível de serviço (SLA) para a interface e não puderem ser otimizadas, recomendamos as seguintes ações:
- Para os dados que têm de ser expostos ao consumidor de dados, converta-os para o armazenamento do BigQuery.
- Redefina as vistas autorizadas para usar as tabelas do BigQuery.
Geralmente, esta abordagem não causa interrupções aos consumidores de dados nem requer alterações às respetivas consultas. As consultas no armazenamento do BigQuery podem ser otimizadas através de técnicas que não são possíveis com tabelas do BigLake. Por exemplo, com o armazenamento do BigQuery, os consumidores podem consultar vistas materializadas com partições e agrupamentos diferentes das tabelas base, e podem usar o BI Engine do BigQuery.
APIs de leitura direta
Embora, geralmente, não recomendemos que os produtores de dados concedam aos consumidores de dados acesso direto de leitura às tabelas base, ocasionalmente, pode ser prático permitir esse acesso por motivos como o desempenho e o custo. Nestes casos, deve ter especial cuidado para garantir que o esquema da tabela é estável.
Existem duas formas de aceder diretamente aos dados num armazém típico. Os produtores de dados podem usar a API BigQuery Storage Read ou as APIs JSON ou XML do Cloud Storage. O diagrama seguinte ilustra dois exemplos de consumidores que usam estas APIs. Um é um exemplo de utilização da aprendizagem automática (ML) e o outro é uma tarefa de processamento de dados.
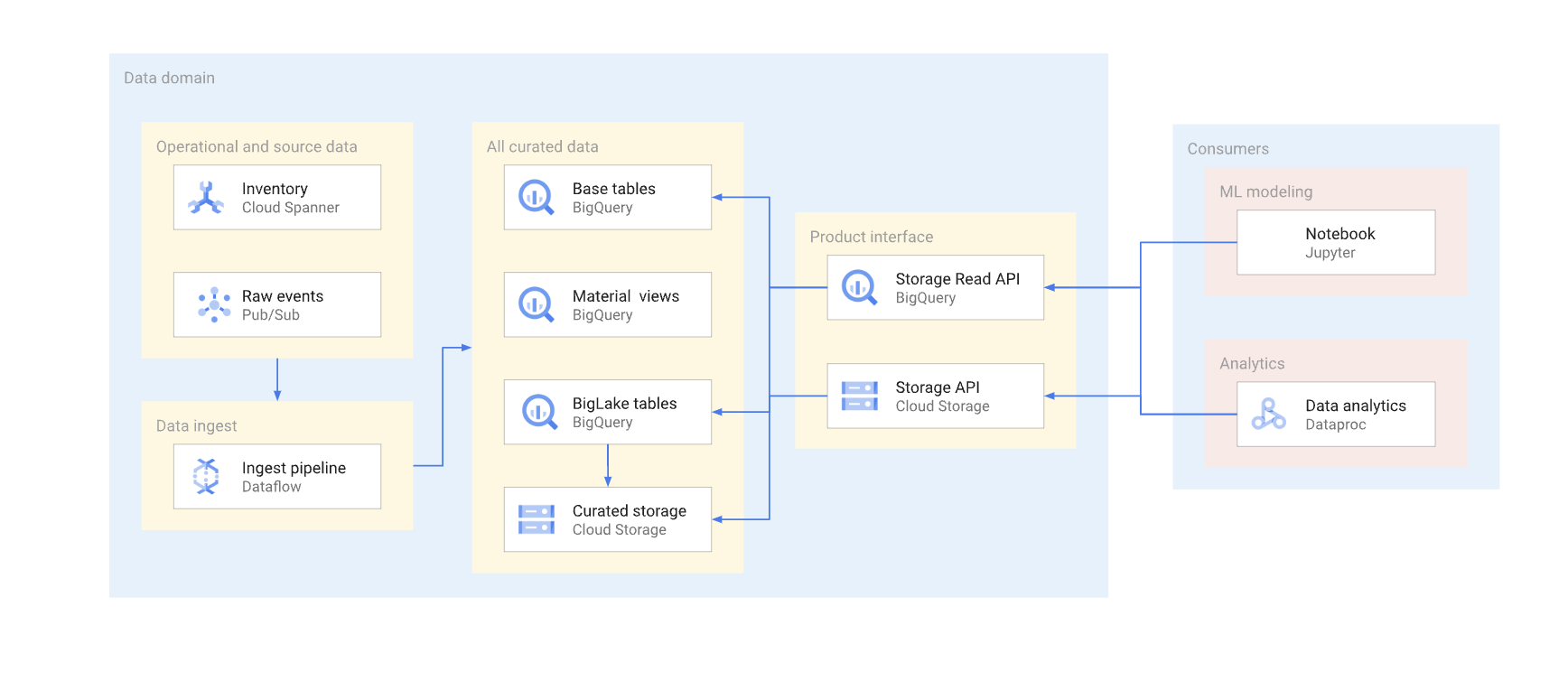
A gestão de versões de uma interface de leitura direta é complexa. Normalmente, os produtores de dados têm de criar outra tabela com um esquema diferente. Também têm de manter duas versões da tabela até que todos os consumidores de dados da versão descontinuada migrem para a nova. Se os consumidores puderem tolerar a interrupção da reconstrução da tabela e a mudança para o novo esquema, é possível evitar a duplicação de dados. Nos casos em que as alterações ao esquema podem ser retrocompatíveis, é possível evitar a migração da tabela base. Por exemplo, não tem de migrar a tabela base se forem adicionadas apenas novas colunas e os dados nessas colunas forem preenchidos para todas as linhas.
Segue-se um resumo das diferenças entre a Storage Read API e a API Cloud Storage. Em geral, sempre que possível, recomendamos que os produtores de dados usem a API BigQuery para aplicações analíticas.
API Storage Read: a API Storage Read pode ser usada para ler dados em tabelas do BigQuery e para ler tabelas do BigLake. Esta API suporta a filtragem e o controlo de acesso detalhado, e pode ser uma boa opção para a análise de dados estáveis ou consumidores de ML.
API Cloud Storage: os produtores de dados podem ter de partilhar um determinado contentor do Cloud Storage diretamente com os consumidores de dados. Por exemplo, os produtores de dados podem partilhar o contentor se os consumidores de dados não puderem usar a interface SQL por algum motivo ou se o contentor tiver formatos de dados que não são suportados pela API Storage Read.
Em geral, não recomendamos que os produtores de dados permitam o acesso direto através das APIs de armazenamento, uma vez que o acesso direto não permite a filtragem nem o controlo de acesso detalhado. No entanto, a abordagem de acesso direto pode ser uma escolha viável para conjuntos de dados estáveis e de tamanho pequeno (gigabytes).
Permitir o acesso do Pub/Sub ao contentor dá aos consumidores de dados uma forma fácil de copiar os dados para os respetivos projetos e processá-los aí. Em geral, não recomendamos a cópia de dados se puder ser evitada. As várias cópias de dados aumentam o custo de armazenamento e adicionam sobrecarga à manutenção e ao acompanhamento da linhagem.
Dados como streams
Um domínio pode expor dados de streaming publicando esses dados num tópico do Pub/Sub. Os subscritores que querem consumir os dados criam subscrições para consumir as mensagens publicadas nesse tópico. Cada subscritor recebe e consome dados de forma independente. O diagrama seguinte mostra um exemplo de tais streams de dados.
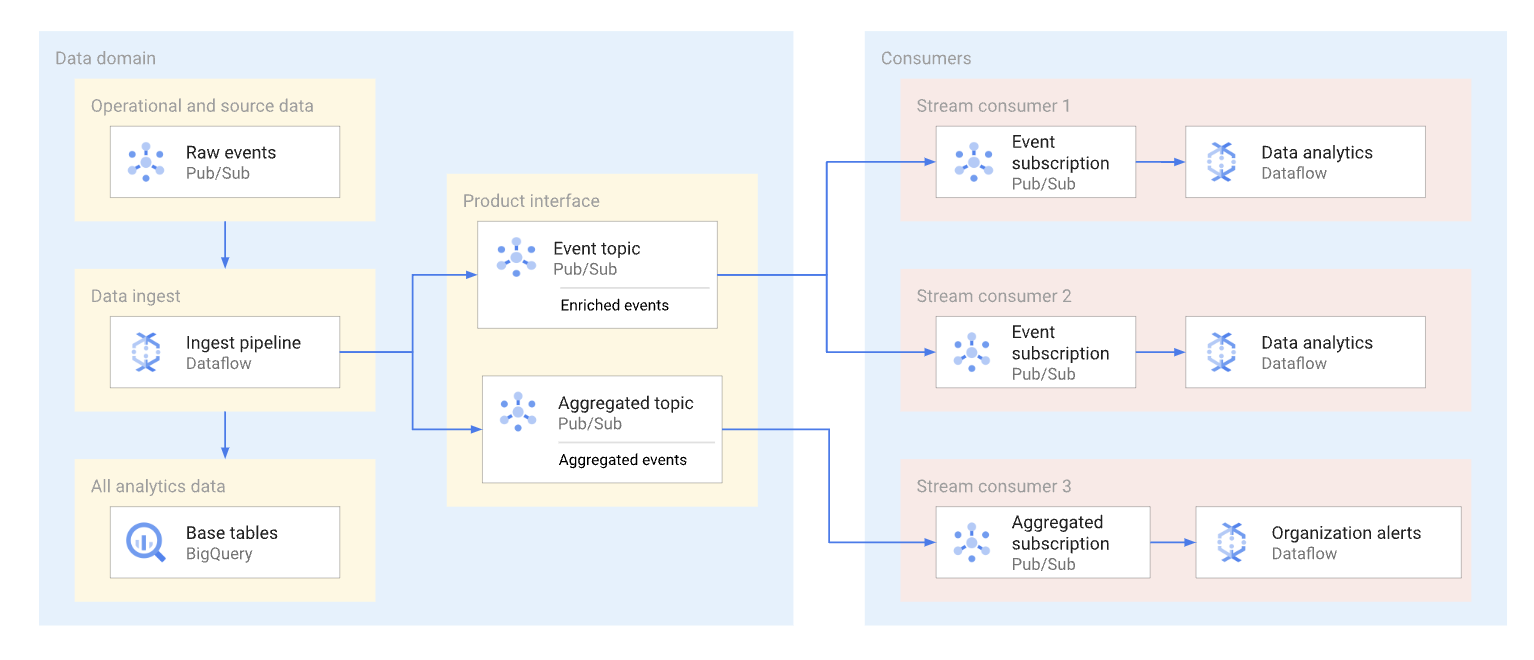
No diagrama, o pipeline de carregamento lê eventos não processados, enriquece-os (organiza-os) e guarda estes dados organizados no repositório de dados analíticos (tabela base do BigQuery). Ao mesmo tempo, o pipeline publica os eventos enriquecidos num tópico dedicado. Este tópico é consumido por vários subscritores, cada um dos quais pode estar a filtrar potencialmente estes eventos para obter apenas os relevantes para si. O pipeline também agrega e publica estatísticas de eventos no seu próprio tópico para serem processadas por outro consumidor de dados.
Seguem-se exemplos de utilização de subscrições do Pub/Sub:
- Eventos enriquecidos, como o fornecimento de informações completas do perfil do cliente, juntamente com dados sobre uma encomenda específica do cliente.
- Notificações de agregação quase em tempo real, como estatísticas totais de encomendas dos últimos 15 minutos.
- Alertas ao nível da empresa, como gerar um alerta se o volume de encomendas diminuir 20% em comparação com um período semelhante no dia anterior.
- Notificações de alteração de dados (semelhantes em conceito às notificações de captura de dados de alterações), como quando o estado de uma determinada encomenda é alterado.
O formato de dados que os produtores de dados usam para mensagens do Pub/Sub afeta os custos e a forma como estas mensagens são processadas. Para streams de grande volume numa arquitetura de malha de dados, os formatos Avro ou Protobuf são boas opções. Se os produtores de dados usarem estes formatos, podem atribuir esquemas a tópicos do Pub/Sub. Os esquemas ajudam a garantir que os consumidores recebem mensagens bem formadas.
Uma vez que uma estrutura de dados de streaming pode estar em constante mudança, o controlo de versões desta interface requer coordenação entre os produtores de dados e os consumidores de dados. Existem várias abordagens comuns que os produtores de dados podem adotar, que são as seguintes:
- É criado um novo tópico sempre que a estrutura da mensagem muda. Este tópico tem frequentemente um esquema Pub/Sub explícito. Os consumidores de dados que precisam da nova interface podem começar a consumir os novos dados. A versão da mensagem é implícita no nome do tópico, por exemplo,
click_events_v1. Os formatos de mensagens são fortemente tipados. Não existe variação no formato das mensagens entre mensagens no mesmo tópico. A desvantagem desta abordagem é que pode haver consumidores de dados que não conseguem mudar para a nova subscrição. Neste caso, o produtor de dados tem de continuar a publicar eventos em todos os tópicos ativos durante algum tempo, e os consumidores de dados que subscrevem o tópico têm de lidar com uma lacuna no fluxo de mensagens ou remover as mensagens duplicadas. - Os dados são sempre publicados no mesmo tópico. No entanto, a estrutura da mensagem pode mudar. Um atributo de mensagem do Pub/Sub (separado da carga útil) define a versão da mensagem. Por
exemplo,
v=1.0. Esta abordagem elimina a necessidade de lidar com lacunas ou duplicados. No entanto, todos os consumidores de dados têm de estar prontos para receber mensagens de um novo tipo. Os produtores de dados também não podem usar esquemas de tópicos do Pub/Sub para esta abordagem. - Uma abordagem híbrida. O esquema de mensagens pode ter uma secção de dados arbitrária que pode ser usada para novos campos. Esta abordagem pode oferecer um equilíbrio razoável entre ter dados fortemente tipados e alterações de versão frequentes e complexas.
API de acesso aos dados
Os produtores de dados podem criar uma API personalizada para aceder diretamente às tabelas base num data warehouse. Normalmente, estes produtores expõem esta API personalizada como uma API REST ou gRPC e implementam-na no Cloud Run ou num cluster do Kubernetes. Um gateway de API, como o Apigee, pode oferecer outras funcionalidades adicionais, como a limitação do tráfego ou uma camada de colocação em cache. Estas funcionalidades são úteis quando expõem a API de acesso aos dados a consumidores fora de uma Google Cloud organização. Os potenciais candidatos para uma API de acesso a dados são consultas sensíveis à latência e de alta concorrência, que devolvem um resultado relativamente pequeno numa única API e podem ser armazenadas em cache de forma eficaz.
Seguem-se exemplos de uma API personalizada para acesso aos dados:
- Uma vista combinada das métricas de ANS da tabela ou do produto.
- Os 10 principais registos (potencialmente em cache) de uma tabela específica.
- Um conjunto de dados de estatísticas de tabelas (número total de linhas ou distribuição de dados nas colunas de chaves).
Todas as diretrizes e a governação que a organização tem em torno da criação de APIs de aplicações também são aplicáveis às APIs personalizadas criadas pelos produtores de dados. As diretrizes e a administração da organização devem abranger questões como o alojamento, a monitorização, o controlo de acesso e o controlo de versões.
A desvantagem de uma API personalizada é o facto de os produtores de dados serem responsáveis por qualquer infraestrutura adicional necessária para alojar esta interface, bem como pela programação e manutenção da API personalizada. Recomendamos que os produtores de dados investiguem outras opções antes de decidirem criar APIs de acesso a dados personalizadas. Por exemplo, os produtores de dados podem usar o BigQuery BI Engine para diminuir a latência de resposta e aumentar a simultaneidade.
Blocos do Looker
Para produtos como o Looker, que são usados com frequência em ferramentas de Business Intelligence (BI), pode ser útil manter um conjunto de widgets específicos da ferramenta de BI. Uma vez que a equipa de produção de dados conhece o modelo de dados subjacente usado no domínio, esta equipa está na melhor posição para criar e manter um conjunto predefinido de visualizações.
No caso do Looker, esta visualização pode ser um conjunto de blocos do Looker (modelos de dados do LookML pré-criados). Os Looker Blocks podem ser facilmente incorporados em painéis de controlo alojados pelos consumidores.
Modelos de ML
Uma vez que as equipas que trabalham em domínios de dados têm uma compreensão e um conhecimento profundos dos seus dados, são frequentemente as melhores equipas para criar e manter modelos de ML que são preparados com os dados do domínio. Estes modelos de ML podem ser expostos através de várias interfaces diferentes, incluindo as seguintes:
- Os modelos do BigQuery ML podem ser implementados num conjunto de dados dedicado e partilhados com os consumidores de dados para previsões em lote do BigQuery.
- Os modelos do BigQuery ML podem ser exportados para o Vertex AI para serem usados em previsões online.
Considerações sobre a localização dos dados para interfaces de consumo
Uma consideração importante quando os produtores de dados definem interfaces de consumo para produtos de dados é a localização dos dados. Em geral, para minimizar os custos, os dados devem ser processados na mesma região em que são armazenados. Esta abordagem ajuda a evitar cobranças de saída de dados entre regiões. Esta abordagem também tem a latência de consumo de dados mais baixa. Por estes motivos, os dados armazenados em localizações multirregionais do BigQuery são normalmente a melhor opção para exposição como um produto de dados.
No entanto, por motivos de desempenho, os dados armazenados no Cloud Storage e expostos através de tabelas do BigLake ou APIs de leitura direta devem ser armazenados em contentores regionais.
Se os dados expostos num produto residirem numa região e tiverem de ser unidos com dados noutro domínio noutra região, os consumidores de dados têm de considerar as seguintes limitações:
- As consultas entre regiões que usam o SQL do BigQuery não são suportadas. Se o método de consumo principal dos dados for o SQL do BigQuery, todas as tabelas na consulta têm de estar na mesma localização.
- Os compromissos de taxa fixa do BigQuery são regionais. Se um projeto usar apenas um compromisso de taxa fixa numa região, mas consultar um produto de dados noutra região, aplica-se o preço a pedido.
- Os consumidores de dados podem usar APIs de leitura direta para ler dados de outra região. No entanto, aplicam-se custos de saída da rede entre regiões, e os consumidores de dados vão, muito provavelmente, sentir latência nas transferências de dados de grande dimensão.
Os dados acedidos frequentemente em várias regiões podem ser replicados nessas
regiões para reduzir o custo e a latência das consultas incorridas pelos
consumidores de produtos. Por exemplo, os conjuntos de dados do BigQuery
podem ser copiados
para outras regiões. No entanto, os dados só devem ser copiados quando for necessário. Recomendamos que os produtores de dados disponibilizem apenas um subconjunto dos dados dos produtos disponíveis a várias regiões quando copiam dados. Esta abordagem ajuda a minimizar a latência e o custo da replicação. Esta abordagem pode resultar na necessidade de fornecer várias versões da interface de consumo com a região de localização dos dados explicitamente indicada. Por exemplo, as visualizações autorizadas do BigQuery podem ser expostas através de nomes como sales_eu_v1 e sales_us_v1.
As interfaces de fluxo de dados que usam tópicos do Pub/Sub não precisam de lógica de replicação adicional para consumir mensagens em regiões que não sejam a mesma região em que a mensagem está armazenada. No entanto, aplicam-se custos de saída adicionais entre regiões neste caso.
Exponha interfaces de consumo aos consumidores de dados
Esta secção aborda como tornar as interfaces de consumo detetáveis por potenciais consumidores. O Data Catalog é um serviço totalmente gerido que as organizações podem usar para fornecer os serviços de descoberta de dados e gestão de metadados. Os produtores de dados têm de tornar as interfaces de consumo dos respetivos produtos de dados pesquisáveis e anotá-las com os metadados adequados para permitir que os consumidores de produtos acedam aos mesmos de forma autónoma. A nossa equipa
As secções seguintes abordam a forma como cada tipo de interface é definido como uma entrada do Data Catalog.
Interfaces SQL baseadas no BigQuery
Os metadados técnicos, como um nome de tabela totalmente qualificado ou um esquema de tabela, são registados automaticamente para vistas autorizadas, vistas do BigLake e tabelas do BigQuery que estão disponíveis através da API Storage Read. Recomendamos que os produtores de dados também forneçam informações adicionais na documentação do produto de dados para ajudar os consumidores de dados. Por exemplo, para ajudar os utilizadores a encontrar a documentação do produto de uma entrada, os produtores de dados podem adicionar um URL a uma das etiquetas que foi aplicada à entrada. Os produtores também podem fornecer o seguinte:
- Conjuntos de colunas agrupadas que devem ser usadas em filtros de consultas.
- Valores de enumeração para campos que têm um tipo de enumeração lógica, se o tipo não for fornecido como parte da descrição do campo.
- Junções suportadas com outras tabelas.
Streams de dados
Os tópicos do Pub/Sub são registados automaticamente no catálogo de dados. No entanto, os produtores de dados têm de descrever o esquema na documentação do produto de dados.
API Cloud Storage
O Data Catalog suporta a definição de entradas de ficheiros do Cloud Storage e respetivo esquema. Se um conjunto de ficheiros do data lake for gerido pelo Catálogo universal do Dataplex, o conjunto de ficheiros é registado automaticamente no Data Catalog. Os conjuntos de ficheiros que não estão associados ao Dataplex Universal Catalog são adicionados através de uma abordagem diferente.
Outras interfaces
Pode adicionar outras interfaces que não tenham suporte integrado do Data Catalog criando entradas personalizadas.
O que se segue?
- Veja uma implementação de referência da arquitetura de malha de dados.
- Saiba mais acerca do BigQuery.
- Leia sobre o Dataplex.
- Para ver mais arquiteturas de referência, diagramas e práticas recomendadas, explore o Centro de arquitetura na nuvem.