Para que se cumplan los casos prácticos de los consumidores de datos, es fundamental que los productos de datos de una malla de datos se diseñen y se creen con cuidado. El diseño de un producto de datos empieza con la definición de cómo usarían los consumidores de datos ese producto y cómo se expondría ese producto a los consumidores. Los productos de datos de una malla de datos se crean sobre un almacén de datos (por ejemplo, un almacén o un lago de datos de dominio). Cuando creas productos de datos en una malla de datos, hay algunos factores clave que te recomendamos que tengas en cuenta durante este proceso. Estas consideraciones se describen en este documento.
Este documento forma parte de una serie en la que se describe cómo implementar una malla de datos en Google Cloud. Se da por hecho que has leído y conoces los conceptos descritos en Arquitectura y funciones de una malla de datos y Crea una malla de datos moderna y distribuida con Google Cloud.
La serie consta de las siguientes partes:
- Arquitectura y funciones de una malla de datos
- Diseñar una plataforma de datos de autoservicio para una malla de datos
- Crear productos de datos en una malla de datos (este documento)
- Descubrir y consumir productos de datos en una malla de datos
Cuando se crean productos de datos a partir de un almacén de datos de dominio, recomendamos que los productores de datos diseñen cuidadosamente las interfaces analíticas (de consumo) de esos productos. Estas interfaces de consumo son un conjunto de garantías sobre la calidad de los datos y los parámetros operativos, junto con un modelo de asistencia y documentación del producto. El coste de cambiar las interfaces de consumo suele ser alto porque tanto el productor de datos como, posiblemente, varios consumidores de datos deben cambiar sus procesos y aplicaciones de consumo. Dado que es muy probable que los consumidores de datos se encuentren en unidades organizativas distintas a las de los productores de datos, coordinar los cambios puede ser difícil.
En las siguientes secciones se proporciona información general sobre lo que debe tener en cuenta al crear un almacén de dominio, definir interfaces de consumo y exponer esas interfaces a los consumidores de datos.
Crear un almacén de datos de dominio
No hay ninguna diferencia fundamental entre crear un almacén de datos independiente y crear un almacén de datos de dominio a partir del cual el equipo de productores de datos crea productos de datos. La única diferencia real entre ambos es que el segundo expone un subconjunto de sus datos a través de las interfaces de consumo.
En muchos almacenes de datos, los datos sin procesar que se ingieren de fuentes de datos operativas se someten a un proceso de enriquecimiento y verificación de la calidad de los datos (curación). En los lagos de datos gestionados por Dataplex Universal Catalog, los datos seleccionados suelen almacenarse en zonas seleccionadas designadas. Cuando se haya completado la selección, un subconjunto de los datos debería estar listo para el consumo externo al dominio a través de varios tipos de interfaces. Para definir esas interfaces de consumo, una organización debe proporcionar un conjunto de herramientas a los equipos de dominio que no estén familiarizados con la adopción de un enfoque de malla de datos. Estas herramientas permiten a los productores de datos crear nuevos productos de datos de forma autónoma. Para consultar las prácticas recomendadas, consulta Diseñar una plataforma de datos de autoservicio.
Además, los productos de datos deben cumplir los requisitos de gobernanza de datos definidos de forma centralizada. Estos requisitos afectan a la calidad, la disponibilidad y la gestión del ciclo de vida de los datos. Como estos requisitos fomentan la confianza de los consumidores de datos en los productos de datos y animan a usar estos productos, merece la pena esforzarse en cumplirlos.
Definir interfaces de consumo
Recomendamos que los productores de datos usen varios tipos de interfaces en lugar de definir solo uno o dos. Cada tipo de interfaz de analíticas de datos tiene sus ventajas y desventajas, y no hay ningún tipo de interfaz que destaque en todos los aspectos. Cuando los productores de datos evalúan la idoneidad de cada tipo de interfaz, deben tener en cuenta lo siguiente:
- Capacidad para llevar a cabo el tratamiento de datos necesario.
- Escalabilidad para admitir los casos prácticos de los consumidores de datos actuales y futuros.
- Rendimiento requerido por los consumidores de datos.
- Coste de desarrollo y mantenimiento.
- Coste de ejecutar la interfaz.
- Asistencia en los idiomas y las herramientas que usa tu organización.
- Compatibilidad con la separación de almacenamiento y recursos de computación.
Por ejemplo, si el requisito empresarial es poder ejecutar consultas analíticas en un conjunto de datos de un petabyte, la única interfaz práctica es una vista de BigQuery. Sin embargo, si los requisitos son proporcionar datos de streaming casi en tiempo real, una interfaz basada en Pub/Sub es más adecuada.
En muchas de estas interfaces no es necesario copiar ni replicar los datos. La mayoría de ellas también te permiten separar el almacenamiento y la computación, una función fundamental de lasGoogle Cloud herramientas analíticas. Los consumidores de los datos expuestos a través de estas interfaces procesan los datos con los recursos de computación que tienen disponibles. Los productores de datos no tienen que aprovisionar ninguna infraestructura adicional.
Hay una gran variedad de interfaces de consumo. Las siguientes interfaces son las más habituales en una malla de datos y se describen en las secciones siguientes:
- Vistas y funciones autorizadas
- APIs de lectura directa
- Datos como flujos
- API de acceso a datos
- Bloques de Looker
- Modelos de aprendizaje automático
La lista de interfaces de este documento no es exhaustiva. También hay otras opciones que puede tener en cuenta para sus interfaces de consumo (por ejemplo, Compartir de BigQuery, antes Analytics Hub). Sin embargo, estas otras interfaces no se incluyen en este documento.
Vistas y funciones autorizadas
En la medida de lo posible, los productos de datos deben exponerse a través de vistas autorizadas y funciones autorizadas,incluidas las funciones con valores de tabla. Los conjuntos de datos autorizados ofrecen una forma cómoda de autorizar varias vistas automáticamente. Las vistas autorizadas impiden el acceso directo a las tablas base y te permiten optimizar las tablas subyacentes y las consultas que se hagan en ellas sin que afecte al uso que hagan los consumidores de estas vistas. Los consumidores de esta interfaz usan SQL para consultar los datos. En el siguiente diagrama se ilustra el uso de conjuntos de datos autorizados como interfaz de consumo.
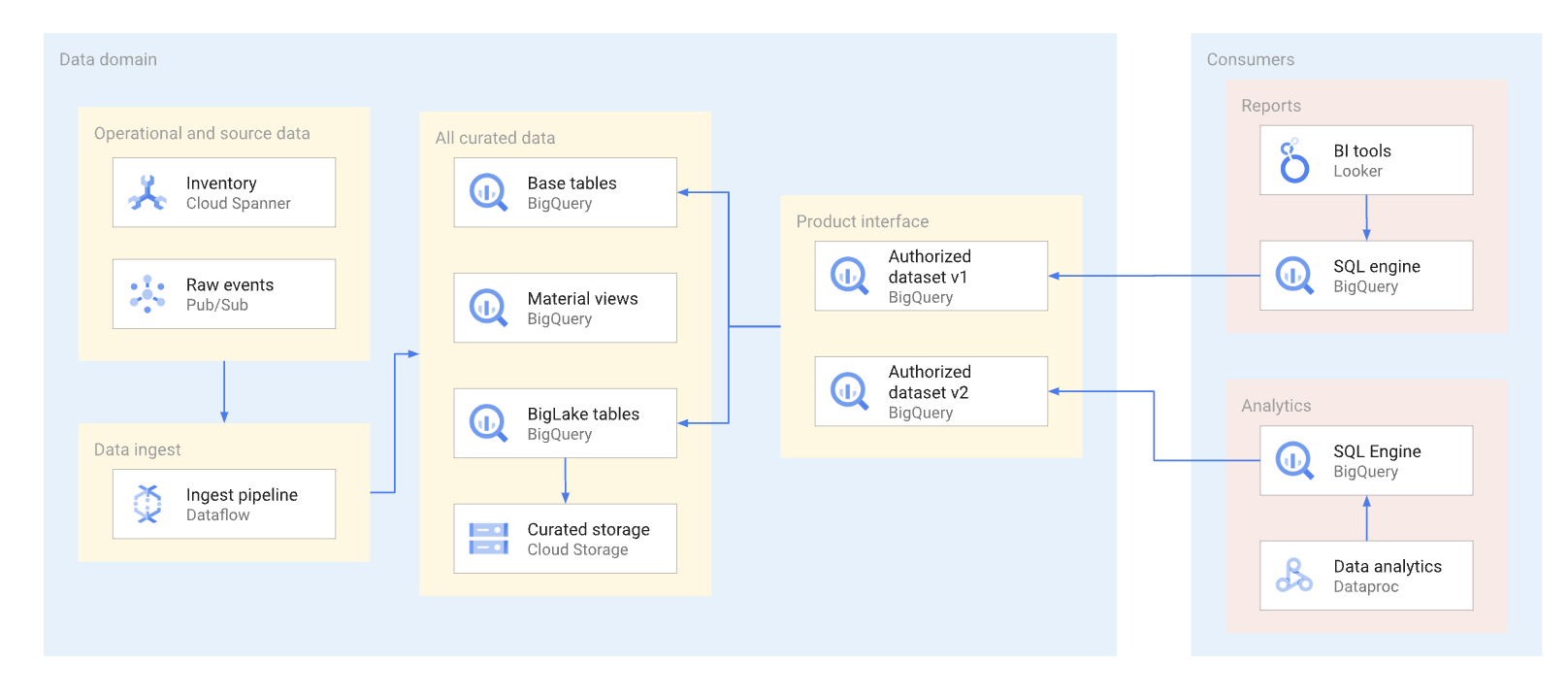
Los conjuntos de datos y las vistas autorizados permiten crear versiones de interfaces fácilmente. Como se muestra en el siguiente diagrama, los productores de datos pueden adoptar dos enfoques principales para el control de versiones:
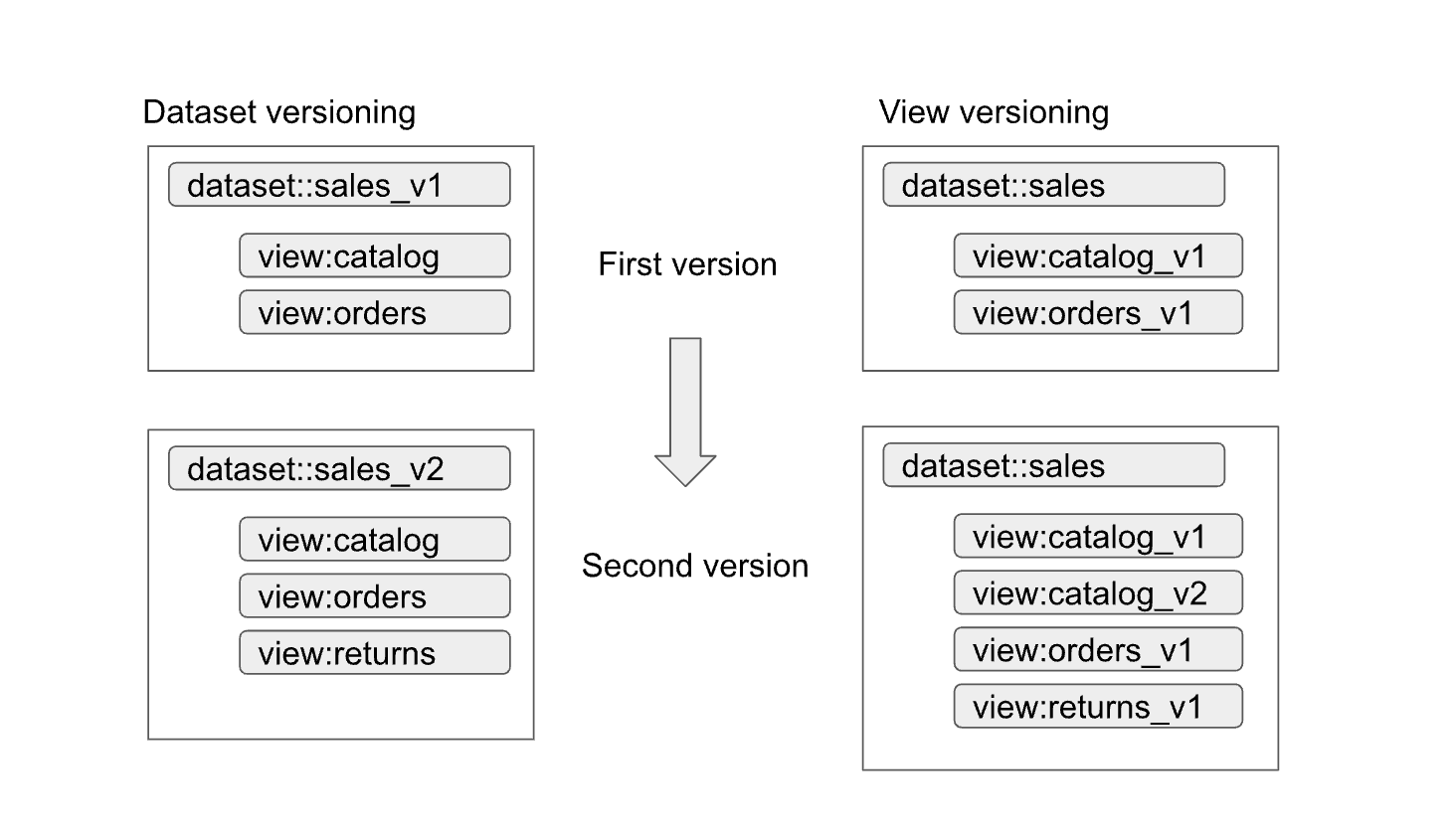
Los enfoques se pueden resumir de la siguiente manera:
- Control de versiones del conjunto de datos: en este enfoque, se controla la versión del nombre del conjunto de datos.
No se crea una versión de las vistas y las funciones del conjunto de datos. Los nombres de las vistas y las funciones son los mismos independientemente de la versión. Por ejemplo, la primera versión de un conjunto de datos de ventas se define en un conjunto de datos llamado
sales_v1con dos vistas,catalogyorders. En la segunda versión, el conjunto de datos de ventas se ha renombrado comosales_v2y las vistas anteriores del conjunto de datos conservan sus nombres, pero tienen nuevos esquemas. La segunda versión del conjunto de datos también puede tener vistas nuevas o eliminar cualquiera de las vistas anteriores. - Control de versiones de las vistas: en este enfoque, las vistas del conjunto de datos tienen versiones en lugar del propio conjunto de datos. Por ejemplo, el conjunto de datos de ventas
conserva el nombre
salesindependientemente de la versión. Sin embargo, los nombres de las vistas del conjunto de datos cambian para reflejar cada nueva versión de la vista (comocatalog_v1,catalog_v2,orders_v1,orders_v2yorders_v3).
La mejor estrategia de control de versiones para tu organización depende de las políticas de la organización y del número de vistas que queden obsoletas al actualizar los datos subyacentes. El control de versiones de conjuntos de datos es la mejor opción cuando se necesita una actualización importante del producto y la mayoría de las vistas deben cambiar. El control de versiones de las vistas reduce el número de vistas con el mismo nombre en diferentes conjuntos de datos, pero puede generar ambigüedades. Por ejemplo, ¿cómo se puede saber si una combinación entre conjuntos de datos funciona correctamente? Un enfoque híbrido puede ser una buena opción. En un enfoque híbrido, se permiten cambios de esquema compatibles en un mismo conjunto de datos, mientras que los cambios incompatibles requieren un nuevo conjunto de datos.
Consideraciones sobre las tablas de BigLake
Las vistas autorizadas se pueden crear no solo en tablas de BigQuery, sino también en tablas de BigLake. Las tablas de BigLake permiten a los consumidores consultar los datos almacenados en Cloud Storage mediante la interfaz SQL de BigQuery. Las tablas de BigLake admiten un control de acceso pormenorizado sin que los consumidores de datos tengan permisos de lectura para el segmento de Cloud Storage subyacente.
Los productores de datos deben tener en cuenta lo siguiente en las tablas de BigLake:
- El diseño de los formatos de archivo y la disposición de los datos influyen en el rendimiento de las consultas. Los formatos basados en columnas, como Parquet u ORC, suelen ofrecer un rendimiento mucho mejor en las consultas analíticas que los formatos JSON o CSV.
- Un diseño con particiones de Hive te permite eliminar particiones y acelera las consultas que usan columnas de partición.
- También se deben tener en cuenta el número de archivos y el rendimiento de las consultas preferido para el tamaño del archivo en la fase de diseño.
Si las consultas que usan tablas de BigLake no cumplen los requisitos del acuerdo de nivel de servicio (SLA) de la interfaz y no se pueden optimizar, le recomendamos que haga lo siguiente:
- En el caso de los datos que deban exponerse al consumidor de datos, conviértalos al almacenamiento de BigQuery.
- Vuelve a definir las vistas autorizadas para que usen las tablas de BigQuery.
Por lo general, este enfoque no provoca ninguna interrupción en los consumidores de datos ni requiere que se hagan cambios en sus consultas. Las consultas de almacenamiento de BigQuery se pueden optimizar con técnicas que no son posibles con las tablas de BigLake. Por ejemplo, con el almacenamiento de BigQuery, los consumidores pueden consultar vistas materializadas que tengan una partición y un agrupamiento diferentes a los de las tablas base, y pueden usar BigQuery BI Engine.
APIs de lectura directa
Aunque, por lo general, no recomendamos que los productores de datos den a los consumidores acceso de lectura directo a las tablas base, en ocasiones puede ser práctico permitir dicho acceso por motivos como el rendimiento y el coste. En estos casos, se debe tener especial cuidado para asegurarse de que el esquema de la tabla sea estable.
Hay dos formas de acceder directamente a los datos de un almacén típico. Los productores de datos pueden usar la API Storage Read de BigQuery o las APIs JSON o XML de Cloud Storage. En el siguiente diagrama se muestran dos ejemplos de consumidores que usan estas APIs. Uno es un caso práctico de aprendizaje automático y el otro es un trabajo de procesamiento de datos.
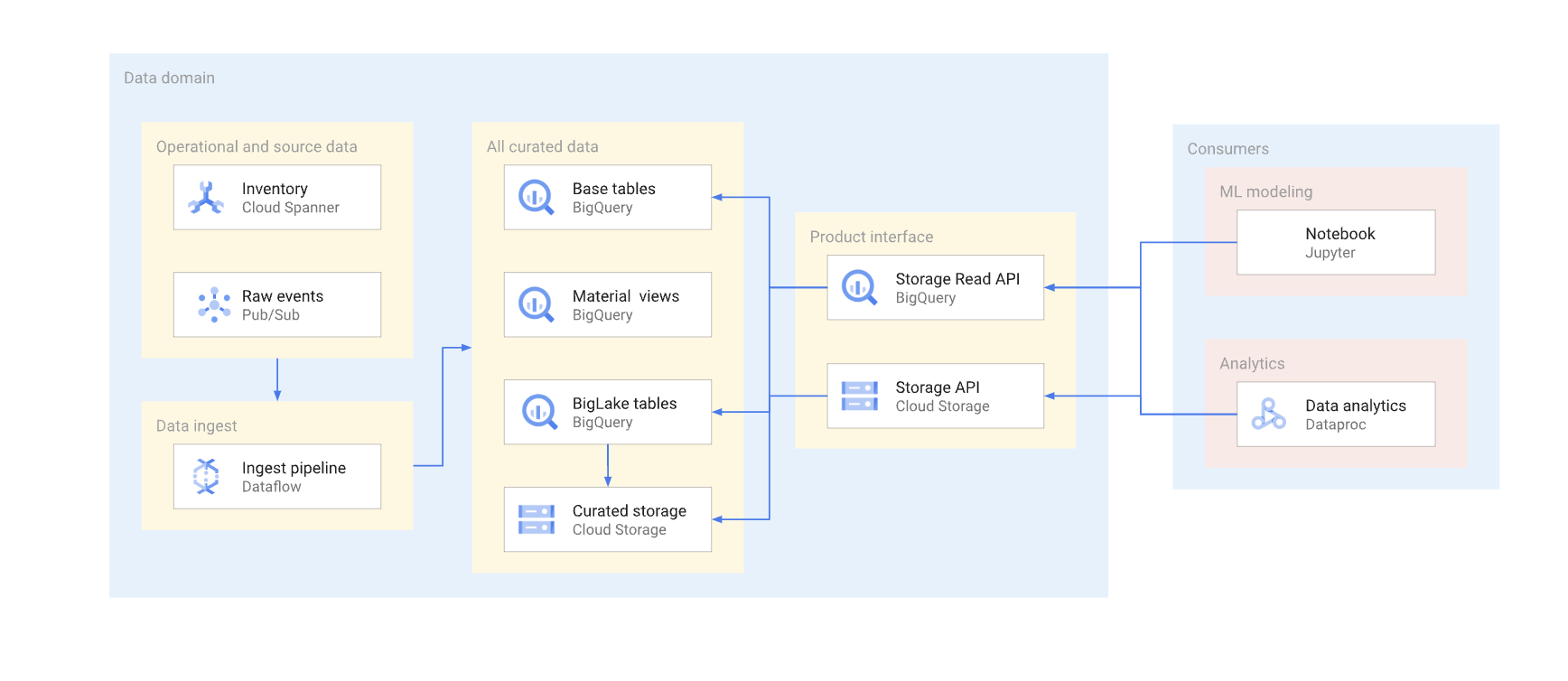
Crear versiones de una interfaz de lectura directa es complejo. Por lo general, los productores de datos deben crear otra tabla con un esquema diferente. También deben mantener dos versiones de la tabla hasta que todos los consumidores de datos de la versión obsoleta migren a la nueva. Si los consumidores pueden tolerar la interrupción de la recompilación de la tabla y el cambio al nuevo esquema, es posible evitar la duplicación de datos. En los casos en los que los cambios de esquema pueden ser retrocompatibles, se puede evitar la migración de la tabla base. Por ejemplo, no tienes que migrar la tabla base si solo se añaden columnas nuevas y los datos de estas columnas se rellenan para todas las filas.
A continuación, se muestra un resumen de las diferencias entre la API Storage Read y la API Cloud Storage. En general, siempre que sea posible, recomendamos que los productores de datos usen la API de BigQuery para aplicaciones analíticas.
API Storage Read: La API Storage Read se puede usar para leer datos de tablas de BigQuery y de BigLake. Esta API admite el filtrado y el control de acceso detallado, y puede ser una buena opción para los consumidores de analíticas de datos o de aprendizaje automático estables.
API Cloud Storage: es posible que los productores de datos tengan que compartir un segmento de Cloud Storage concreto directamente con los consumidores de datos. Por ejemplo, los productores de datos pueden compartir el segmento si los consumidores de datos no pueden usar la interfaz SQL por algún motivo o si el segmento tiene formatos de datos que no son compatibles con la API Storage Read.
Por lo general, no recomendamos que los productores de datos permitan el acceso directo a través de las APIs de almacenamiento, ya que este tipo de acceso no permite filtrar ni controlar el acceso de forma granular. Sin embargo, el acceso directo puede ser una opción viable para conjuntos de datos estables y de tamaño reducido (gigabytes).
Si permites que Pub/Sub acceda al segmento, los consumidores de datos podrán copiar los datos en sus proyectos y procesarlos allí fácilmente. Por lo general, no recomendamos copiar datos si se puede evitar. Las copias múltiples de datos aumentan el coste de almacenamiento y se suman a la sobrecarga de mantenimiento y seguimiento del linaje.
Datos como flujos
Un dominio puede exponer datos de streaming publicándolos en un tema de Pub/Sub. Los suscriptores que quieran consumir los datos crean suscripciones para consumir los mensajes publicados en ese tema. Cada suscriptor recibe y consume datos de forma independiente. En el siguiente diagrama se muestra un ejemplo de este tipo de flujos de datos.
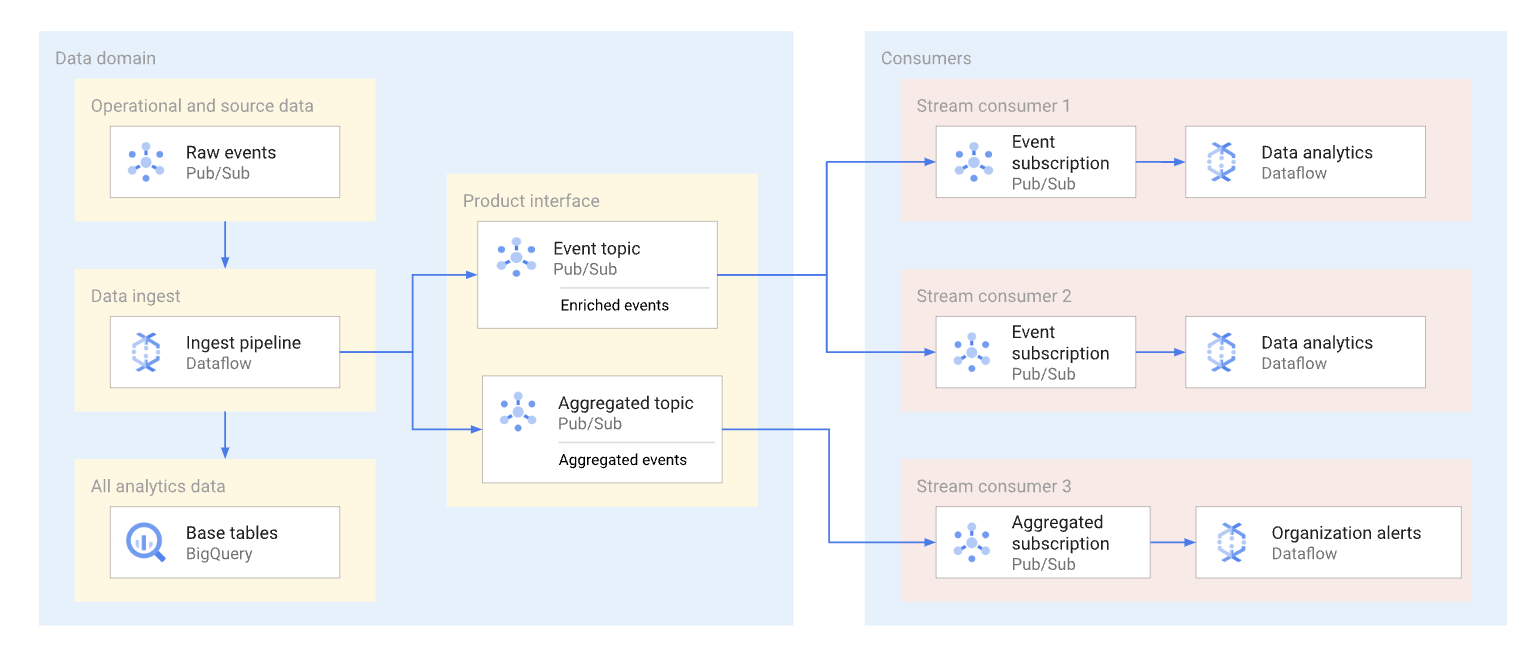
En el diagrama, la canalización de ingestión lee eventos sin procesar, los enriquece (los selecciona) y guarda los datos seleccionados en el almacén de datos analíticos (tabla base de BigQuery). Al mismo tiempo, la canalización publica los eventos enriquecidos en un tema específico. Varios suscriptores consumen este tema, y cada uno de ellos puede filtrar estos eventos para obtener solo los que le interesan. La canalización también agrega y publica estadísticas de eventos en su propio tema para que otro consumidor de datos las procese.
A continuación, se muestran algunos ejemplos de casos prácticos de suscripciones de Pub/Sub:
- Eventos enriquecidos, como proporcionar información completa del perfil de cliente junto con datos sobre un pedido de cliente concreto.
- Notificaciones de agregación casi en tiempo real, como las estadísticas totales de pedidos de los últimos 15 minutos.
- Alertas a nivel de empresa, como generar una alerta si el volumen de pedidos se ha reducido en un 20% en comparación con un periodo similar del día anterior.
- Notificaciones de cambios en los datos (similares a las notificaciones de captura de datos de cambios), como cuando cambia el estado de un pedido concreto.
El formato de datos que usan los productores de datos para los mensajes de Pub/Sub afecta a los costes y a la forma en que se procesan estos mensajes. Para las secuencias de gran volumen en una arquitectura de malla de datos, los formatos Avro o Protobuf son buenas opciones. Si los productores de datos usan estos formatos, pueden asignar esquemas a temas de Pub/Sub. Los esquemas ayudan a asegurar que los consumidores reciban mensajes bien formados.
Como una estructura de datos de streaming puede cambiar constantemente, el control de versiones de esta interfaz requiere la coordinación entre los productores y los consumidores de datos. Los productores de datos pueden adoptar varios enfoques habituales, que son los siguientes:
- Se crea un tema nuevo cada vez que cambia la estructura del mensaje. Este tema suele tener un esquema de Pub/Sub explícito. Los consumidores de datos que necesiten la nueva interfaz pueden empezar a consumir los nuevos datos. La versión del mensaje se deduce del nombre del tema; por ejemplo,
click_events_v1. Los formatos de los mensajes tienen un tipado fuerte. No hay variaciones en el formato de los mensajes de un mismo tema. La desventaja de este enfoque es que puede haber consumidores de datos que no puedan cambiar a la nueva suscripción. En este caso, el productor de datos debe seguir publicando eventos en todos los temas activos durante un tiempo, y los consumidores de datos que se suscriban al tema deben gestionar el vacío en el flujo de mensajes o eliminar los mensajes duplicados. - Los datos siempre se publican en el mismo tema. Sin embargo, la estructura del mensaje puede cambiar. Un atributo de mensaje de Pub/Sub (independiente de la carga útil) define la versión del mensaje. Por ejemplo,
v=1.0. Con este enfoque, no es necesario gestionar las lagunas ni los duplicados. Sin embargo, todos los consumidores de datos deben estar preparados para recibir mensajes de un nuevo tipo. Los productores de datos tampoco pueden usar esquemas de temas de Pub/Sub con este método. - Un enfoque híbrido. El esquema de mensaje puede tener una sección de datos arbitraria que se puede usar para nuevos campos. Este enfoque puede ofrecer un equilibrio razonable entre tener datos con tipos definidos y cambios de versión frecuentes y complejos.
API de acceso a datos
Los productores de datos pueden crear una API personalizada para acceder directamente a las tablas base de un almacén de datos. Normalmente, estos productores exponen esta API personalizada como una API REST o gRPC, y la implementan en Cloud Run o en un clúster de Kubernetes. Una pasarela de APIs como Apigee puede proporcionar otras funciones adicionales, como la limitación del tráfico o una capa de caché. Estas funciones son útiles cuando se expone la API de acceso a datos a consumidores ajenos a una organización. Google Cloud Los candidatos potenciales para una API de acceso a datos son las consultas con alta simultaneidad y sensibles a la latencia, que devuelven un resultado relativamente pequeño en una sola API y se pueden almacenar en caché de forma eficaz.
Estos son algunos ejemplos de APIs personalizadas para acceder a los datos:
- Una vista combinada de las métricas de SLA de la tabla o el producto.
- Los 10 primeros registros (posiblemente almacenados en caché) de una tabla concreta.
- Conjunto de datos de estadísticas de tabla (número total de filas o distribución de datos en columnas clave).
Las directrices y las políticas que tenga la organización sobre la creación de APIs de aplicaciones también se aplican a las APIs personalizadas creadas por los productores de datos. Las directrices y la gestión de la organización deben abordar cuestiones como el alojamiento, la monitorización, el control de acceso y el control de versiones.
La desventaja de una API personalizada es que los productores de datos son responsables de cualquier infraestructura adicional que se requiera para alojar esta interfaz, así como de la codificación y el mantenimiento de la API personalizada. Recomendamos que los productores de datos investiguen otras opciones antes de decidirse a crear APIs de acceso a datos personalizadas. Por ejemplo, los productores de datos pueden usar BigQuery BI Engine para reducir la latencia de respuesta y aumentar la simultaneidad.
Bloques de Looker
En el caso de productos como Looker, que se usan mucho en herramientas de inteligencia empresarial (BI), puede ser útil mantener un conjunto de widgets específicos de herramientas de BI. Como el equipo de productores de datos conoce el modelo de datos subyacente que se usa en el dominio, es el más adecuado para crear y mantener un conjunto de visualizaciones prediseñadas.
En el caso de Looker, esta visualización podría ser un conjunto de Looker Blocks (modelos de datos de LookML predefinidos). Los Looker Blocks se pueden incorporar fácilmente a los paneles de control alojados por los consumidores.
Modelos de aprendizaje automático
Como los equipos que trabajan en dominios de datos conocen a fondo sus datos, suelen ser los más adecuados para crear y mantener modelos de aprendizaje automático entrenados con los datos del dominio. Estos modelos de aprendizaje automático se pueden exponer a través de varias interfaces, entre las que se incluyen las siguientes:
- Los modelos de BigQuery ML se pueden implementar en un conjunto de datos específico y compartir con los consumidores de datos para las predicciones por lotes de BigQuery.
- Los modelos de BigQuery ML se pueden exportar a Vertex AI para usarlos en predicciones online.
Consideraciones sobre la ubicación de los datos para las interfaces de consumo
Un aspecto importante que deben tener en cuenta los productores de datos al definir interfaces de consumo para productos de datos es la ubicación de los datos. Por lo general, para minimizar los costes, los datos deben procesarse en la misma región en la que se almacenan. Este enfoque ayuda a evitar los cargos por tráfico de salida de datos entre regiones. Este método también tiene la latencia de consumo de datos más baja. Por estos motivos, los datos almacenados en ubicaciones multirregionales de BigQuery suelen ser los más adecuados para exponerlos como producto de datos.
Sin embargo, por motivos de rendimiento, los datos almacenados en Cloud Storage y expuestos a través de tablas de BigLake o APIs de lectura directa deben almacenarse en segmentos regionales.
Si los datos expuestos en un producto residen en una región y deben combinarse con datos de otro dominio en otra región, los consumidores de datos deben tener en cuenta las siguientes limitaciones:
- No se admiten consultas entre regiones que usen BigQuery SQL. Si el método de consumo principal de los datos es BigQuery SQL, todas las tablas de la consulta deben estar en la misma ubicación.
- Los compromisos de tarifa plana de BigQuery son regionales. Si un proyecto solo usa un compromiso de tarifa fija en una región, pero consulta un producto de datos en otra región, se aplican los precios bajo demanda.
- Los consumidores de datos pueden usar APIs de lectura directa para leer datos de otra región. Sin embargo, se aplican cargos de salida de red entre regiones y es muy probable que los consumidores de datos experimenten latencia en las transferencias de grandes cantidades de datos.
Los datos a los que se accede con frecuencia en varias regiones se pueden replicar en esas regiones para reducir el coste y la latencia de las consultas que realicen los consumidores del producto. Por ejemplo, los conjuntos de datos de BigQuery se pueden copiar a otras regiones. Sin embargo, los datos solo deben copiarse cuando sea necesario. Le recomendamos que los productores de datos solo pongan a disposición de varias regiones un subconjunto de los datos de producto disponibles cuando copie datos. Este enfoque ayuda a minimizar la latencia y el coste de la replicación. Este enfoque puede requerir que se proporcionen varias versiones de la interfaz de consumo con la región de ubicación de los datos indicada explícitamente. Por ejemplo, las vistas autorizadas de BigQuery se pueden exponer mediante nombres como sales_eu_v1 y sales_us_v1.
Las interfaces de flujo de datos que usan temas de Pub/Sub no necesitan ninguna lógica de replicación adicional para consumir mensajes en regiones que no sean la misma región en la que se almacenan los mensajes. Sin embargo, en este caso se aplican cargos de salida entre regiones adicionales.
Exponer interfaces de consumo a los consumidores de datos
En esta sección se explica cómo hacer que las interfaces de consumo sean detectables por los consumidores potenciales. Data Catalog es un servicio totalmente gestionado que las organizaciones pueden usar para proporcionar servicios de descubrimiento de datos y gestión de metadatos. Los productores de datos deben hacer que las interfaces de consumo de sus productos de datos se puedan buscar y deben anotarlas con los metadatos adecuados para que los consumidores de productos puedan acceder a ellas de forma autónoma. X
En las siguientes secciones se explica cómo se define cada tipo de interfaz como una entrada de Data Catalog.
Interfaces SQL basadas en BigQuery
Los metadatos técnicos, como el nombre completo de una tabla o el esquema de una tabla, se registran automáticamente en las vistas autorizadas, las vistas de BigLake y las tablas de BigQuery que están disponibles a través de la API Storage Read. Recomendamos que los productores de datos también proporcionen información adicional en la documentación del producto de datos para ayudar a los consumidores de datos. Por ejemplo, para ayudar a los usuarios a encontrar la documentación de un producto, los productores de datos pueden añadir una URL a una de las etiquetas que se hayan aplicado a la entrada. Los productores también pueden proporcionar lo siguiente:
- Conjuntos de columnas agrupadas que se deben usar en los filtros de consulta.
- Valores de enumeración de los campos que tienen un tipo de enumeración lógica, si el tipo no se proporciona como parte de la descripción del campo.
- Uniones admitidas con otras tablas.
Flujos de datos
Los temas de Pub/Sub se registran automáticamente en Data Catalog. Sin embargo, los productores de datos deben describir el esquema en la documentación del producto de datos.
API de Cloud Storage
Data Catalog admite la definición de entradas de archivos de Cloud Storage y sus esquemas. Si un conjunto de archivos de un lago de datos está gestionado por Dataplex Universal Catalog, se registra automáticamente en Data Catalog. Los conjuntos de archivos que no están asociados a Dataplex Universal Catalog se añaden con otro método.
Otras interfaces
Puedes añadir otras interfaces que no tengan asistencia integrada de Data Catalog creando entradas personalizadas.
Siguientes pasos
- Consulta una implementación de referencia de la arquitectura de malla de datos.
- BigQuery
- Consulta información sobre Dataplex.
- Para ver más arquitecturas de referencia, diagramas y prácticas recomendadas, consulta el centro de arquitectura de Cloud.