このドキュメントでは、 Google Cloud上の PostgreSQL デプロイメントにおいて高可用性(HA)を実現するアーキテクチャについて説明します。HA は、基盤となるインフラストラクチャの障害に対するシステムの復元性を表します。このドキュメントでは、HA のアーキテクチャに応じて、HA という用語を単一のクラウド リージョン内または複数リージョン間での PostgreSQL クラスタの可用性という意味で使用しています。
このドキュメントは、システム全体の稼働時間を改善し、PostgreSQL データ層の信頼性を向上させる方法を必要としているデータベース管理者、クラウド アーキテクト、DevOps エンジニアを対象としています。このドキュメントでは、Compute Engine での PostgreSQL の実行に関連するコンセプトについて説明しますが、Cloud SQL for PostgreSQL や AlloyDB for PostgreSQL などのマネージド データベースの使用方法については説明しません。
システムやアプリケーションがリクエストまたはトランザクションの処理で永続状態を必要とする場合は、データクエリまたはミューテーションのリクエストを正常に処理するために、データ パーシステンス レイヤ(データ層)を使用する必要があります。データ層でダウンタイムが発生すると、システムやアプリケーションで必要なタスクを処理できなくなります。
システムのサービスレベル目標(SLO)によっては、より高いレベルの可用性を提供するアーキテクチャが必要になることがあります。HA の実現方法はいくつかありますが、アプリケーションにすばやくアクセスできるように冗長なインフラストラクチャをプロビジョニングする方法が一般的です。
このドキュメントでは、次のトピックについて説明します。
- HA データベースのコンセプトに関連する用語の定義。
- HA PostgreSQL トポロジのオプション。
- 各アーキテクチャ オプションに関するコンテキスト情報。
用語
次の用語とコンセプトは業界標準のもので、このドキュメントで扱っていない内容を理解する際にも役立ちます。
- レプリケーション
-
書き込みトランザクション(
INSERT、UPDATE、またはDELETE)とスキーマ変更(データ定義言語、DDL)のキャプチャ、ロギング、アーキテクチャ内のすべてのダウンストリーム データベースのレプリカノードへの順次適用を確実に行うプロセス。 - プライマリ ノード
- 最新状態の永続データの読み取りを行うノード。データベースへの書き込みはすべてプライマリ ノードに転送する必要があります。
- レプリカ(セカンダリ)ノード
- プライマリ データベース ノードのオンライン コピー。変更は、プライマリ ノードからレプリカノードに同期的または非同期的に複製されます。レプリカノードからの読み取りでは、レプリケーション ラグのため、データが若干遅れる可能性があるので注意してください。
- レプリケーション ラグ
- ログシーケンス番号(LSN)、トランザクション ID、または時間から構成される測定値。レプリケーション ラグは、変更オペレーションがレプリカに適用されるタイミングとプライマリ ノードに適用されるタイミングの差を表しています。
- 継続的なアーカイブ
- 増分バックアップ。データベースが継続的に順次トランザクションをファイルに保存します。
- write-ahead log(WAL)
- write-ahead log(WAL)は、データファイルに実際に変更が加えられる前に記録されるログファイルです。WAL は、サーバーがクラッシュした場合でも書き込みデータの整合性と耐久性を確保するために使用する標準的な方法です。
- WAL レコード
- データベースに適用されたトランザクションのレコード。WAL レコードは、データファイルのページレベルの変更を記述する一連のレコードとしてフォーマットされ、保存されます。
- ログシーケンス番号(LSN)
- トランザクションにより、WAL ファイルに追加される WAL レコードが作成されます。挿入が行われる位置は、ログシーケンス番号(LSN)と呼ばれます。これは 64 ビットの整数値で、スラッシュで区切られた 2 つの 16 進数(XXXXXXXX/YYZZZZZZZ)で表現します。「Z」は、WAL ファイル内のオフセット位置を表します。
- セグメント ファイル
- 構成されたファイルのサイズに応じて、可能な限り多くの WAL レコードを保存するファイル。セグメント ファイルのファイル名は単調に増加します。デフォルトのファイルサイズは 16 MB です。
- 同期レプリケーション
-
レプリカのトランザクション ログにデータが書き込まれたことをプライマリ サーバーが確認してからクライアントに commit するレプリケーションの方法。ストリーミング レプリケーションを実行する場合は、PostgreSQL の
synchronous_commitオプションを使用できます。このオプションは、プライマリ サーバーとレプリカ間の整合性の確保に役立ちます。 - 非同期レプリケーション
- レプリカでトランザクションが正常に処理されたことをプライマリ サーバーが確認する前にクライアントに commit するレプリケーションの方法。非同期レプリケーションでは、同期レプリケーションよりもレイテンシが低くなります。ただし、プライマリがクラッシュし、commit されたトランザクションがレプリカに転送されない場合は、データが失われる可能性があります。非同期レプリケーションは PostgreSQL でのデフォルトのレプリケーション モードで、ファイルベースのログ配布またはストリーミング レプリケーションが使用されます。
- ファイルベースのログ配布
- プライマリ データベース サーバーからレプリカに WAL セグメント ファイルを転送する PostgreSQL のレプリケーション方法。プライマリはアーカイブ モードを継続し、各スタンバイ サービスはリカバリモードを継続して WAL ファイルを読み取ります。このタイプのレプリケーションは非同期です。
- ストリーミング レプリケーション
- レプリカがプライマリに接続し、連続する一連の変更を継続的に受信するレプリケーション方法。この方法では、ストリーミングで更新を受信するため、ログ配布形式のレプリケーションと比べると、レプリカが常にプライマリのデータを受信し、最新の状態が維持されます。デフォルトでは、レプリケーションは非同期ですが、同期レプリケーションを構成することもできます。
- 物理ストリーミング レプリケーション
- レプリカに変更を転送するレプリケーション方法。この方法では、ディスク ブロック アドレス形式の物理データの変更とバイト単位の変更を含む WAL レコードを使用します。
- 論理ストリーミング レプリケーション
- レプリケーション ID(主キー)に基づいて変更をキャプチャするレプリケーション方法。物理レプリケーションと比べると、データの複製方法をより詳細に制御できます。PostgreSQL では論理レプリケーションの制限があるため、論理ストリーミング レプリケーションを行うには、HA の設定で特別な構成が必要になります。このガイドでは、標準的な物理レプリケーションについて説明します。論理レプリケーションについては説明しません。
- 稼働時間
- リソースが動作し、リクエストへのレスポンスの提供ができている時間の割合。
- 障害検出
- インフラストラクチャ障害が発生したことを特定するプロセス。
- フェイルオーバー
- バックアップ インフラストラクチャまたはスタンバイ インフラストラクチャ(この場合は、レプリカノード)をプライマリ インフラストラクチャに昇格するプロセス。フェイルオーバーが発生すると、レプリカノードがプライマリ ノードになります。
- スイッチオーバー
- 本番環境システムで手動フェイルオーバーを行うプロセス。スイッチオーバーは、システムが正常に機能しているかどうかをテストする際に使用します。また、メンテナンスのために、現在のプライマリ ノードをクラスタから除外する場合にも使用します。
- 目標復旧時間(RTO)
- データ層のフェイルオーバー プロセスが完了するまでの経過時間。RTO は、ビジネス上の観点から許容できる時間に応じて異なります。
- 目標復旧時点(RPO)
- フェイルオーバーの結果、データ層を維持するために許容できるデータ損失量(実際の経過時間)。RPO は、ビジネス上の観点から許容されるデータ損失量によって異なります。
- フォールバック
- フェイルオーバーの原因となった条件が修正された後に以前のプライマリ ノードを復元するプロセス。
- 自己回復
- オペレーターによる人的な外部アクションなしで問題を解決するシステムの能力。
- ネットワーク パーティション
- アーキテクチャ内の 2 つのノード(たとえば、プライマリ ノードとレプリカノード)がネットワーク経由で相互に通信できない条件。
- スプリット ブレイン
- 2 つのノードが同時に自身をプライマリ ノードであると認識している場合に発生する状態。
- ノードグループ
- サービスを提供するコンピューティング リソースのセット。このドキュメントでは、データ パーシステンス層にあるサービスを意味します。
- 監視ノードまたはクォーラム ノード
- スプリット ブレイン状態が発生した場合にノードグループの処理を決定する際に役立つ個別のコンピューティング リソース。
- プライマリまたはリーダーの選択
- 監視ノードを含むピアアウェア ノードのグループが、どのノードをプライマリ ノードとすべきかを決定するプロセス。
HA アーキテクチャを検討すべき場合
HA アーキテクチャでは、単一ノードのデータベース設定よりも、データレベルのダウンタイムに対する保護が強化されます。ビジネス ユースケースに最適なオプションを選択するには、ダウンタイムの許容可能性と、さまざまなアーキテクチャのトレードオフを理解する必要があります。
HA のアーキテクチャは、ワークロードとサービスの信頼性要件を満たすため、データ層の稼働率を高める場合に使用します。環境である程度のダウンタイムを許容できる場合に HA アーキテクチャを使用すると、不要なコストや複雑さが生じる可能性があります。たとえば、開発環境やテスト環境の場合、データベース層に高可用性が必要になることはまずありません。
HA の要件を検討する
以下の質問を検討して、最適な PostgreSQL HA オプションを判断してください。
- どのようなレベルの可用性を実現したいのか。単一ゾーンに障害が発生したときにサービスを継続できるようにするのか、リージョン全体で障害が発生した場合でもサービスを継続するのか。マルチリージョンで使用可能な HA オプションもありますが、リージョンに限定されるものもあります。
- どのサービスまたはユーザーがデータ層に依存しているのか。データ パーシステンス層でダウンタイムが発生した場合にかかる費用はどのくらいか。サービスを利用するのがシステムの使用頻度が低い内部ユーザーに限定されている場合、エンドユーザー向けサービスよりも可用性の要件は低くなります。
- 運用予算はどのくらいか。コストは重要な検討要素です。HA を実現するために、インフラストラクチャとストレージのコストが増加する可能性があります。
- プロセスをどのように自動化するのか。どのくらいの間隔でフェイルオーバーが必要になるか(RTO はどのくらいか)。HA オプションは、システムがフェイルオーバーして復旧するまでにかかる時間によって異なります。
- フェイルオーバーの結果として発生するデータの消失は許容できるか(RPO はどのくらいか)。HA トポロジは分散型のため、commit のレイテンシと障害によるデータ損失のリスクがトレードオフになります。
HA の仕組み
このセクションでは、PostgreSQL HA アーキテクチャの基礎となるストリーミング レプリケーションと同期レプリケーションについて説明します。
ストリーミング レプリケーション
ストリーミング レプリケーションでは、レプリカがプライマリに接続して WAL レコードのストリームを継続的に受信します。ログ配布形式のレプリケーションと異なり、ストリーミング レプリケーションを使用すると、レプリカはプライマリとより近い状態で維持されます。PostgreSQL では、バージョン 9 から組み込みのストリーミング レプリケーションを使用できます。多くの PostgreSQL HA ソリューションでは、組み込みのストリーミング レプリケーションを使用して、複数の PostgreSQL レプリカノードがプライマリと同期されるメカニズムを提供しています。これらのオプションについては、このドキュメントの後半の PostgreSQL HA アーキテクチャのセクションで説明します。
各レプリカノードには、専用のコンピューティング リソースとストレージ リソースが必要になります。レプリカノードのインフラストラクチャはプライマリから独立しています。レプリカノードをホット スタンバイとして使用して、読み取り専用のクライアント クエリを実行できます。このアプローチでは、プライマリと 1 つ以上のレプリカの間で読み取り専用クエリの負荷分散が可能です。
デフォルトでは、ストリーミング レプリケーションは非同期です。プライマリはレプリカからの確認応答を待ってから、クライアントにトランザクションの commit を確認します。非同期レプリケーションでは、トランザクションの確認後、レプリカがトランザクションを受け入れる前にプライマリで障害が発生すると、データが失われる可能性があります。レプリカが新しいプライマリに昇格すると、このようなトランザクションはなくなります。
同期ストリーミング レプリケーション
同期スタンバイにする 1 つ以上のレプリカを選択すると、ストリーミング レプリケーションを同期として構成できます。同期レプリケーションのアーキテクチャを構成すると、レプリカがトランザクションの永続性を確認するまで、プライマリはトランザクションの commit を確認しません。同期ストリーミング レプリケーションでは、トランザクションのレイテンシが大きくなるので、耐久性が高まります。
synchronous_commit 構成オプションを使用すると、トランザクションに対して次のプログレッシブ レプリカの耐久性を構成できます。
local: 同期スタンバイ レプリカは commit 確認に関与しません。プライマリは、WAL レコードがローカル ディスクに書き込まれてフラッシュされた後に、トランザクション commit を承認します。プライマリでのトランザクション commit には、スタンバイ レプリカは関与しません。プライマリで障害が発生すると、トランザクションが失われる可能性があります。on(デフォルト): 同期スタンバイ レプリカが commit されたトランザクションを WAL に書き込んでから、プライマリに確認を送信します。on構成を使用すると、プライマリ レプリカとすべての同期スタンバイ レプリカで同時にストレージ障害が発生した場合にのみ、トランザクションが失われる可能性があります。レプリカが確認応答を送信するのは WAL レコードの書き込み後であるため、レプリカにクエリを送信するクライアントは、WAL レコードがレプリカ データベースに適用されるまで変更を確認できません。remote_write: 同期スタンバイ レプリカは、OS レベルで WAL レコードの受信を認識しますが、WAL レコードがディスクに書き込まれたかどうかは保証しません。remote_writeでは WAL の書き込みを保証できないため、レコードを書き込む前にプライマリとセカンダリの両方で障害が発生すると、トランザクションが失われる可能性があります。remote_writeの耐久性はonオプションよりも低くなります。remote_apply: 同期スタンバイ レプリカは、クライアントにトランザクションの commit を確認する前に、トランザクションの受信とデータベースへの正常な適応を確認します。remote_apply構成を使用すると、トランザクションがレプリカに確実に保持され、クライアント クエリの結果にトランザクションの結果がすぐに反映されます。onやremote_writeと比べると、remote_applyは耐久性と整合性が高くなります。
synchronous_commit 構成オプションは、同期レプリケーション プロセスに参加するスタンバイ サーバーのリストを指定する synchronous_standby_names 構成オプションと連携して動作します。同期スタンバイ名が指定されていない場合、トランザクションの commit はレプリケーションを待機しません。
PostgreSQL HA アーキテクチャ
最も基本的なレベルでは、データ層の HA は次の要素から構成されます。
- プライマリ ノードの障害発生を認識するメカニズム。
- レプリカノードをプライマリ ノードに昇格するフェイルオーバーを実行するプロセス。
- アプリケーションのリクエストが新しいプライマリ ノードに到達するようにクエリ ルーティングを変更するプロセス。
- フェイルオーバー前のプライマリ ノードとレプリカノードを元の容量で使用して、元のアーキテクチャにフォールバックする方法(必要な場合)。
以降のセクションでは、次の HA アーキテクチャの概要について説明します。
- Patroni テンプレート
- pg_auto_failover 拡張機能とサービス
- ステートフル MIG とリージョン永続ディスク
HA ソリューションは、インフラストラクチャまたはゾーンの停止が発生した場合にダウンタイムを最小限に抑えます。オプションを選択する際は、ビジネスニーズに応じて commit レイテンシと耐久性を考慮し、バランスの良いオプションを選択します。
HA アーキテクチャでは、今後のフェイルオーバーまたはフォールバックに備えるために新しいスタンバイ環境の準備に必要になる時間と手間が重要な要素となります。このような準備を行わないと、システムが 1 回の障害にしか耐えられず、サービスが SLA に違反することになります。本番環境のインフラストラクチャでは、手動フェイルオーバーまたはスイッチオーバーが可能な HA アーキテクチャを選択することをおすすめします。
Patroni テンプレートを使用した HA
Patroni は、PostgreSQL HA アーキテクチャを構成、デプロイ、運用するためのツールを提供するオープンソース(MIT ライセンス)のソフトウェア テンプレートです。これは完成度の高いテンプレートで、メンテナンスが積極的に行われています。Patroni には共有クラスタ状態のものと、分散構成ストア(DCS)に保持されているアーキテクチャ構成があります。DCS を実装するためのオプションとしては、etcd、Consul、Apache ZooKeeper、Kubernetes があります。次の図は、Patroni クラスタの主なコンポーネントを示しています。
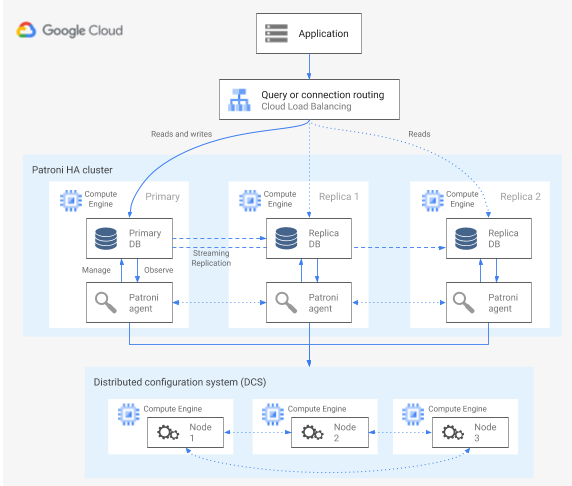
図 1: Patroni クラスタの主なコンポーネントの図。
図 1 では、PostgreSQL ノードの前にロードバランサが配置され、DCS と Patroni エージェントが PostgreSQL ノードで稼働しています。
Patroni は、各 PostgreSQL ノードでエージェント プロセスを実行します。エージェント プロセスは、PostgreSQL プロセスとデータノードの構成を管理します。Patroni エージェントは、DCS を介して他のノードとの調整を行います。Patroni エージェント プロセスは、各ノードの PostgreSQL サービスの正常性と構成を判断するための REST API も公開しています。
クラスタ メンバーの役割を明確にするため、プライマリ ノードは DCS のリーダーキーを定期的に更新します。リーダーキーには有効期間(TTL)が設定されています。更新されずに TTL が経過すると、リーダーキーは DCS から強制排除され、リーダーの選択が開始し、候補者プールから新しいプライマリが選択されます。
次の図は、ノード A がリーダーロックを正常に更新する正常なクラスタを示しています。
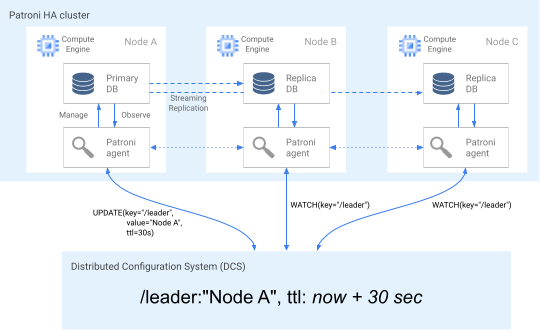
図 2: 正常なクラスタの図。
図 2 は正常なノードを示しています。ノード B とノード C がウォッチしている間に、ノード A がリーダーキーを正常に更新しています。
障害検出
Patroni エージェントは、DCS のキーを更新することで、正常な状態を継続的に伝達します。同時に、エージェントは PostgreSQL の健全性を検証します。エージェントが問題を検出すると、ノードをシャットダウンして自動的にノードを隔離するか、ノードのレプリカを降格します。次の図に示すように、障害が発生したノードがプライマリの場合、DCS のリーダーキーが期限切れになり、新しいリーダーの選択が行われます。
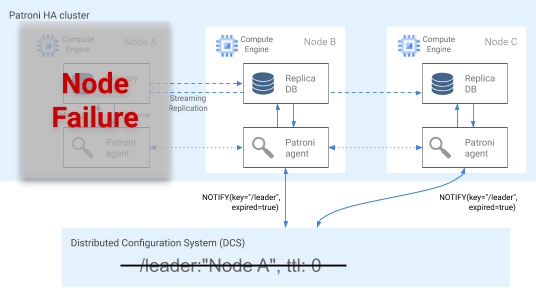
図 3: 障害が発生したクラスタの図。
図 3 は、障害が発生したクラスタを示しています。プライマリ ノードが DCS のリーダーキーを最近更新しておらず、リーダー以外のレプリカにリーダーキーの期限切れが通知されています。
Linux ホストの場合、Patroni もプライマリ ノードで OS レベルのウォッチドッグを実行します。このウォッチドッグは、Patroni エージェント プロセスからの keep-alive メッセージをリッスンします。プロセスが応答しなくなり、keep-alive が送信されない場合、ウォッチドッグがホストを再起動します。ウォッチドックは、PostgreSQL ノードがプライマリとして機能し続けるスプリット ブレイン状態の回避に役立ちますが、エージェント障害で DCS のリーダーキーが期限切れになるため、別のプライマリ(リーダー)が選択されています。
フェイルオーバー プロセス
リーダーロックが DCS で期限切れになると、レプリカノードがリーダーの選択を開始します。レプリカでリーダーロックがないことが検出されると、他のレプリカと比較してレプリカの位置が確認されます。次の図に示すように、各レプリカは REST API を使用して他のレプリカノードの WAL ログの位置を取得します。
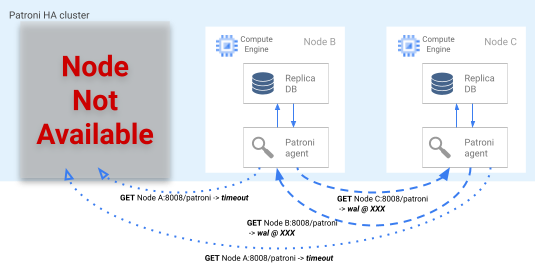
図 4: Patroni フェイルオーバー プロセスの図。
図 4 は、WAL ログ位置のクエリとアクティブなレプリカノードからの結果を示しています。ノード A が使用不能になり、正常なノード B と C が互いに同じ WAL 位置を返しています。
最新のノード(同じ位置にある場合は複数のノード)が同時に DCS のリーダーロックを取得しようとします。ただし、DCS にリーダーキーを作成できるのは 1 つのノードのみです。次の図に示すように、リーダーキーが正常に作成された最初のノードがリーダーレースの勝者になります。また、構成ファイルで failover_priority タグを設定して、フェイルオーバーの優先候補を指定することもできます。
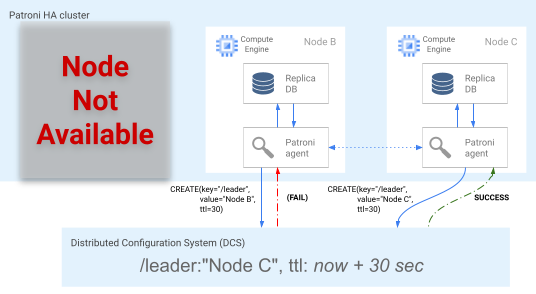
図 5: リーダーレースの図。
図 5 はリーダースコアを表しています。2 つのリーダー候補がリーダーロックを獲得しようとしていますが、2 つのノードのうちノード C のみがリーダーキーの設定に成功し、レースの勝者となっています。
リーダーに選択されると、レプリカは自身を新しいプライマリに昇格させます。レプリカが自身の昇格を開始すると、新しいプライマリが DCS のリーダーキーを更新してリーダーロックを保持し、他のノードはレプリカとして機能します。
Patroni では、スイッチオーバーを実行してノードのフェイルオーバーをテストできる patronictl コントロール ツールも提供しています。このツールは、本番環境における HA 設定をテストするのに役立ちます。
クエリ ルーティング
各ノードで実行される Patroni エージェント プロセスは、現在のノードの役割(プライマリかレプリカ)を示す REST API エンドポイントを公開します。
| REST エンドポイント | プライマリの場合の HTTP リターンコード | レプリカの場合の HTTP リターンコード |
|---|---|---|
/primary |
200 |
503 |
/replica |
503 |
200 |
特定のノードの役割が変更されると関連するヘルスチェックのレスポンスが変わるため、ロードバランサのヘルスチェックは、これらのエンドポイントを使用してプライマリ ノードとレプリカノードのトラフィック ルーティングを通知します。Patroni プロジェクトは、HAProxy などのロードバランサのテンプレート構成を提供しています。内部パススルー ネットワーク ロードバランサは、これらの同じヘルスチェックを使用して同様の機能を提供できます。
フォールバック プロセス
ノードに障害が発生すると、クラスタは異常な状態のままになります。Patroni のフォールバック プロセスは、フェイルオーバー後に HA クラスタを正常な状態に戻すのに役立ちます。フォールバック プロセスは、影響を受けたノードをクラスタ レプリカとして自動的に初期化することで、クラスタの元の状態を復元します。
たとえば、オペレーティング システムや基盤となるインフラストラクチャに問題があると、ノードが再起動することがあります。ノードがプライマリで、再起動にリーダーキーの TTL よりも時間がかかる場合、リーダーの選択がトリガーされ、新しいノードが選択されてプライマリに昇格されます。最新でないプライマリの Patroni プロセスが開始すると、リーダーロックがないことが検出され、自動的にレプリカに降格され、クラスタに参加します。
ゾーンの障害など、回復不能なノード障害が発生した場合は、新しいノードを起動する必要があります。データベース オペレーターは、新しいノードを手動で開始することも、最小ノード数が設定されたステートフル マネージド インスタンス グループ(MIG)を使用してプロセスを自動化することもできます。新しいノードが作成されると、Patroni はそのノードを既存のクラスタの一部として検出し、自動的にレプリカとして初期化します。
pg_auto_failover 拡張機能とサービスを使用する HA
pg_auto_failover は、積極的に開発されているオープンソース(PostgreSQL ライセンス)の PostgreSQL 拡張機能です。pg_auto_failover は、既存の PostgreSQL 機能を拡張して HA アーキテクチャを構成します。pg_auto_failover には PostgreSQL 以外の依存関係はありません。
HA アーキテクチャで pg_auto_failover 拡張機能を使用するには、少なくとも 3 つのノードが必要です。各ノードでは、拡張機能を有効にして PostgreSQL を実行する必要があります。どのノードで障害が発生しても、データベース グループの稼働時間に影響を与えることはありません。pg_auto_failover によって管理されるノードのコレクションはフォーメーションと呼ばれます。次の図に、pg_auto_failover のアーキテクチャを示します。
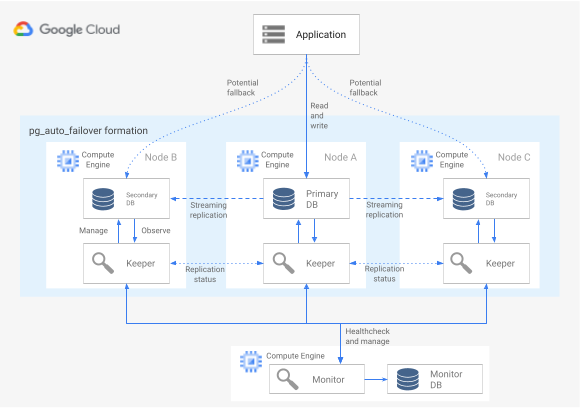
図 6: pg_auto_failover アーキテクチャの図。
図 6 は、2 つの主要コンポーネント(Monitor サービスと Keeper エージェント)で構成される pg_auto_failover アーキテクチャを示しています。Keeper と Monitor はどちらも pg_auto_failover 拡張機能に含まれています。
サービスのモニタリング
pg_auto_failover Monitor サービスは PostgreSQL 拡張機能として実装されます。このサービスは、Monitor ノードを作成すると、pg_auto_failover 拡張機能を有効にして PostgreSQL インスタンスを開始します。Monitor は、フォーメーションのグローバル状態を維持して、メンバー PostgreSQL データノードからヘルスチェック ステータスを取得し、有限状態機械(FSM)で設定されたルールを使用してグループをオーケストレートします。Monitor は、状態遷移に対する FSM ルールに従い、昇格、降格、構成の変更などのアクションをグループノードに指示します。
Keeper エージェント
この拡張機能は、各 pg_auto_failover データノードで Keeper エージェント プロセスを開始します。この Keeper プロセスは、PostgreSQL サービスを監視して管理します。Keeper は、ステータスの更新を Monitor ノードに送信し、そのレスポンスで Monitor から受信したアクションを実行します。
デフォルトでは、pg_auto_failover は、すべてのグループのセカンダリ データノードを同期レプリカとして設定します。commit に必要な同期レプリカの数は、Monitor に設定した number_sync_standby 構成に応じて変わります。
障害検出
プライマリ データノードとセカンダリ データノードの Keeper エージェントは、定期的に Monitor ノードに接続して現在の状態を報告し、実行が必要なアクションがあるかどうかを確認します。また、Monitor ノードはデータノードに接続し、ヘルスチェックを実行します。PostgreSQL プロトコル(libpq)API 呼び出しを実行し、pg_isready() PostgreSQL クライアント アプリケーションのように動作します。一定の時間(デフォルトでは 30 秒)が経過しても、これらの操作が正常に完了しなかった場合、Monitor ノードはデータノードに障害が発生したと判断します。PostgreSQL の構成設定を変更して、モニタリングのタイミングと再試行の回数をカスタマイズできます。詳しくは、フェイルオーバーとフォールト トレラントをご覧ください。
単一ノード障害が発生した場合、次のいずれかの状態になります。
- 異常なデータノードがプライマリの場合、Monitor はフェイルオーバーを開始します。
- 異常なデータノードがセカンダリの場合、Monitor は異常なノードの同期レプリケーションを無効にします。
- 障害が発生したノードが Monitor ノードの場合、自動フェイルオーバーは実行されません。この単一障害点を回避するには、適切なモニタリングと障害復旧を実施する必要があります。
次の図に、上記以外の障害シナリオとその場合のフォーメーションの状態を示します。
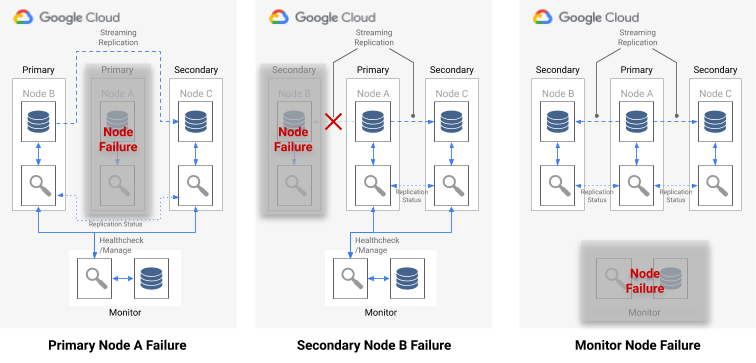
図 7: pg_auto_failover の障害シナリオの図。
フェイルオーバー プロセス
グループ内の各データベース ノードには、フェイルオーバー プロセスを決定する次の構成オプションがあります。
replication_quorum: ブール値のオプション。replication_quorumがtrueに設定されている場合、そのノードはフェイルオーバー候補としてみなされます。candidate_priority: 0~100 の整数値。candidate_priorityのデフォルト値は 50 です。この値を変更すると、フェイルオーバーの優先度に影響します。ノードは、candidate_priority値に基づいてフェイルオーバー候補の優先度が設定されます。candidate_priorityの値が高いほど、ノードの優先度が高くなります。フェイルオーバー プロセスを行うには、pg_auto_failover フォーメーションで少なくとも 2 つのノードにゼロ以外の候補優先度が設定されている必要があります。
プライマリ ノードで障害が発生したときに、セカンダリ同期ノードがプライマリへの昇格対象とみなされるのは、同期レプリケーションがアクティブで、replication_quorum のメンバーである場合です。
セカンダリ ノードは、次の進行状況の基準に従って昇格対象とみなされます。
- 候補優先度が最も高いノード
- 最新の WAL ログ位置を Monitor に公開しているスタンバイ
- 最終的に同じ結果になった場合はランダムに選択
WAL で最新の LSN 位置が公開されていないフェイルオーバー候補は、遅れた候補になります。このシナリオでは、pg_auto_failover は、フェイルオーバー メカニズムの中間ステップをオーケストレートします。遅れた候補は、最新の LSN 位置を持つスタンバイ ノードから欠落している WAL バイトを取得します。その後、スタンバイ ノードが昇格されます。Postgres のレプリケーションでは、任意のスタンバイが他のスタンバイのアップストリーム ノードとして機能できるため、こうした処理が可能になります。
クエリ ルーティング
pg_auto_failure は、サーバー側のクエリ ルーティング機能を提供しません。pg_auto_failure は、正式な PostgreSQL クライアント ドライバ(libpq)を使用するクライアント側のクエリ ルーティングに依存します。接続 URI を定義すると、このドライバは host キーワードの複数のホストを受け入れることができます。
アプリケーションで使用するクライアント ライブラリは、libpq をラップするか、完全な自動フェイルオーバーをサポートするアーキテクチャに複数のホストを提供する機能を実装する必要があります。
フォールバック プロセスとスイッチオーバー プロセス
Keeper プロセスが障害ノードを再起動するか、新しい置換先のノードを起動すると、プロセスは Monitor ノードをチェックして、次に実行するアクションを決定します。プライマリ ノードに障害が発生し、フェイルオーバー プロセスに従って Monitor がすでに新しいプライマリを選択していた場合、Keeper はこの古いプライマリ レプリカをセカンダリ レプリカとして再初期化します。
pg_auto_failure には、ノードのフェイルオーバー プロセスをテストするスイッチオーバーを実行できる pg_autoctl ツールが用意されています。このツールを使用すると、オペレーターは本番環境の HA 設定をテストするだけでなく、フェイルオーバー後に HA クラスタを正常な状態に戻すことができます。
ステートフル MIG とリージョン永続ディスクを使用した HA
このセクションでは、次の Google Cloudコンポーネントを使用する HA アプローチについて説明します。
- リージョン永続ディスク。リージョン永続ディスクを使用する場合、データはリージョン内の 2 つのゾーン間で同期的に複製されるため、ストリーミング レプリケーションを使用する必要はありません。ただし、HA は 1 つのリージョン内の 2 つのゾーンに制限されます。
- ステートフル マネージド インスタンス グループ。1 つのプライマリ PostgreSQL ノードを実行し続けるために、コントロール プレーンの一部としてステートフル MIG のペアが使用されます。ステートフル MIG が新しいインスタンスを起動すると、既存のリージョン永続ディスクをアタッチできます。ある時点で、実行中のインスタンスは 2 つの MIG の 1 つのみになります。
- Cloud Storage。Cloud Storage バケット内のオブジェクトには、2 つの MIG のうちどちらがプライマリ データベース ノードを実行しているかと、どちらの MIG でフェイルオーバー インスタンスを作成する必要があるかを示す構成が含まれています。
- MIG のヘルスチェックと自動修復。ヘルスチェックは、インスタンスの正常性をモニタリングします。実行中のノードが正常でなくなると、ヘルスチェックによる自動修復が開始されます。
- Logging。自動修復によりプライマリ ノードが停止すると、Logging にエントリが記録されます。関連するログエントリが、フィルタを使用して Pub/Sub シンクトピックにエクスポートされます。
- Cloud Run functions のイベント ドリブン関数。Pub/Sub メッセージが Cloud Run functions の関数をトリガーします。Cloud Run functions は、Cloud Storage の構成を使用して、ステートフル MIG ごとに実行するアクションを決定します。
- 内部パススルー ネットワーク ロードバランサ。ロードバランサが、グループ内で実行中のインスタンスにルーティングを行います。これにより、インスタンスの再作成によるインスタンス IP アドレスの変更がクライアントから抽象化されます。
次の図は、ステートフル MIG とリージョン永続ディスクを使用した HA の例を示しています。

図 8: ステートフル MIG とリージョン永続ディスクを使用する HA の図。
図 8 は、クライアント トラフィックを処理する正常なプライマリ ノードを示しています。クライアントは内部パススルー ネットワーク ロードバランサの静的 IP アドレスに接続します。ロードバランサは、MIG の一部として実行中の VM にクライアント リクエストをルーティングします。データ ボリュームは、マウントされたリージョン永続ディスクに保存されます。
この方法を実装するには、初期化時に起動し、MIG のインスタンス テンプレートとして使用される VM イメージを PostgreSQL 付きで作成します。また、ノードで HTTP ベースのヘルスチェック(HAProxy や pgDoctor など)を構成する必要があります。HTTP ベースのヘルスチェックは、ロードバランサとインスタンス グループの両方が PostgreSQL ノードの正常性を判断する際に役立ちます。
リージョン永続ディスク
リージョン内の 2 つのゾーン間で同期データ レプリケーションを提供するブロック ストレージ デバイスをプロビジョニングするには、Compute Engine のリージョン永続ディスク ストレージ オプションを使用します。リージョン永続ディスクは、PostgreSQL の組み込みストリーミング レプリケーションに依存しない PostgreSQL HA オプションを実装するための基礎的な構成要素を提供します。
インフラストラクチャの障害やゾーンの停止が原因でプライマリ ノードの VM インスタンスが使用できなくなった場合、リージョン永続ディスクを同じリージョン内のバックアップ ゾーン内の VM インスタンスに強制的にアタッチできます。
リージョン永続ディスクをバックアップ ゾーンの VM インスタンスにアタッチするには、次のいずれかを行います。
- バックアップ ゾーン内でコールド スタンバイ VM インスタンスを維持します。コールド スタンバイ VM インスタンスにリージョン Persistent Disk はマウントされませんが、このインスタンスはプライマリ ノードの VM インスタンスとまったく同じです。障害が発生すると、コールド スタンバイ VM が起動し、リージョン永続ディスクがマウントされます。コールド スタンバイ インスタンスとプライマリ ノード インスタンスは同じデータを所有します。
- 同じインスタンス テンプレートを使用して、ステートフル MIG のペアを作成します。MIG はヘルスチェックを行い、コントロール プレーンの一部として機能します。プライマリ ノードに障害が発生すると、ターゲット MIG にフェイルオーバー インスタンスが宣言的に作成されます。ターゲット MIG は Cloud Storage オブジェクトで定義されます。インスタンスごとの構成は、リージョン永続ディスクの接続に使用されます。
データサービスの停止が迅速に特定された場合、通常は 1 分以内に強制アタッチが完了するので、分単位の RTO が達成されます。
サービスの停止を検出して連絡し、フェイルオーバーを手動で行うための追加のダウンタイムを許容できる場合は、強制アタッチ プロセスを自動化する必要はありません。RTO の許容範囲が低い場合は、検出とフェイルオーバーのプロセスを自動化します。Cloud SQL for PostgreSQL では、この HA アプローチのフルマネージド実装も提供されます。
障害検出とフェイルオーバー プロセス
HA アプローチでは、インスタンス グループの自動修復機能とヘルスチェックを使用して、ノードの状態をモニタリングします。ヘルスチェックに失敗すると、既存のインスタンスが異常とみなされます。このインスタンスは停止されます。この停止により、Logging、Pub/Sub、トリガーされた Cloud Run functions の関数を使用してフェイルオーバー プロセスが開始されます。
この VM に常にリージョン ディスクをマウントするという要件を満たすため、Cloud Run functions の関数によって 2 つの MIG の 1 つが構成され、リージョン永続ディスクを利用できる 2 つのゾーンのうちの 1 つにインスタンスを作成できます。ノードに障害が発生すると、Cloud Storage で保持されている状態に基づいて、置換インスタンスが代替ゾーンで起動されます。

図 9: MIG のゾーン障害の図。
図 9 では、ゾーン A の以前のプライマリ ノードに障害が発生し、Cloud Run functions の関数によって MIG B がゾーン B で新しいプライマリ インスタンスを起動するように構成されています。障害検出メカニズムは、新しいプライマリ ノードの正常性をモニタリングするように自動的に構成されています。
クエリ ルーティング
内部パススルー ネットワーク ロードバランサは、PostgreSQL サービスを実行しているインスタンスにクライアントを転送します。ロードバランサは、インスタンス グループと同じヘルスチェックを使用して、インスタンスでクエリが処理可能かどうかを判断します。ノードの再作成で使用できない場合、接続は失敗します。インスタンスがバックアップされた後、ヘルスチェックが受け渡しを開始し、使用可能なノードに新しい接続がルーティングされます。この設定では、実行中のノードが 1 つしかないため、読み取り専用ノードはありません。
フォールバック プロセス
基盤となるハードウェアの問題によってデータベース ノードでヘルスチェックが失敗した場合、そのノードは別の基盤となるインスタンスで再作成されます。この時点で、アーキテクチャが元の状態に戻ります。追加のステップを行う必要はありません。ただし、ゾーンに障害が発生しても、最初のゾーンが復旧するまで設定は劣化状態で実行されます。非常にまれですが、リージョン Persistent Disk のレプリケーションとステートフル MIG に構成されている両方のゾーンで同時障害が発生した場合、PostgreSQL インスタンスは復元できません。停止している間、データベースはリクエストを処理できません。
HA オプションの比較
次の表に、Patroni、pg_auto_failover、ステートフル MIG とリージョン永続ディスクを使用する HA オプションの比較を示します。
設定とアーキテクチャ
| Patroni | pg_auto_failover | ステートフル MIG とリージョン永続ディスク |
|---|---|---|
|
HA アーキテクチャ、DCS 設定、モニタリングとアラートが必要です。データノードでのエージェントの設定は比較的簡単です。 |
PostgreSQL 以外の外部依存関係は必要ありません。モニター専用のノードが必要です。モニターノードが単一障害点(SPOF)でないことを確認するため、HA と DR が必要です。 | Google Cloudサービスのみで構成されるアーキテクチャ。一度に実行するアクティブなデータベース ノードは 1 つだけです。 |
HA 構成の可能性
| Patroni | pg_auto_failover | ステートフル MIG とリージョン永続ディスク |
|---|---|---|
| 非常に柔軟な構成が可能: 同期レプリケーションと非同期レプリケーションの両方をサポートします。同期および非同期にするノードを指定できます。同期ノードの自動管理が含まれます。マルチゾーンとマルチリージョンの HA 設定が可能です。DCS へのアクセスが必要です。 | Patroni と同様: 構成可能。ただし、モニターは単一インスタンスとしてのみ使用可能なため、設定のタイプに関係なく、このノードへのアクセスを検討する必要があります。 | 同期レプリケーションは、1 つのリージョン内の 2 つのゾーンに制限されます。 |
ネットワーク パーティションの処理能力
| Patroni | pg_auto_failover | ステートフル MIG とリージョン永続ディスク |
|---|---|---|
| 自己隔離と OS レベルのモニターを使用することで、スプリット ブレインを防ぐことができます。DCS に接続できない場合は、プライマリがレプリカに降格し、フェイルオーバーがトリガーされます。可用性よりも耐久性が優先されます。 | プライマリからモニター、レプリカまでのヘルスチェックを組み合わせて使用し、ネットワーク パーティションを検出して必要に応じて自身の降格を行います。 | なし: 一度にアクティブにできる PostgreSQL ノードは 1 つのみです。このため、ネットワーク パーティションはありません。 |
費用
| Patroni | pg_auto_failover | ステートフル MIG とリージョン永続ディスク |
|---|---|---|
| 選択した DCS と PostgreSQL レプリカの数によって費用が高くなります。Patroni アーキテクチャでは、費用が大幅に増加することはありません。ただし、基盤となるインフラストラクチャで PostgreSQL と DCS に複数のコンピューティング インスタンスを使用するため、全体的な費用が影響を受けます。複数のレプリカと個別の DCS クラスタを使用するため、このオプションは最も費用がかかる可能性があります。 | モニタリング ノードと少なくとも 3 つの PostgreSQL ノード(1 つのプライマリと 2 つのレプリカ)の実行が必要になるため、費用は中程度です。 | 一度にアクティブに実行される PostgreSQL ノードは 1 つのみであるため、費用が抑えられます。料金は 1 つのコンピューティング インスタンスに対してのみ発生します。 |
クライアントの構成
| Patroni | pg_auto_failover | ステートフル MIG とリージョン永続ディスク |
|---|---|---|
| クライアントはロードバランサに接続するため、クライアントに対して透過的です。 | ロードバランサを前面に配置することが難しいため、設定で複数のホスト定義をサポートするクライアント ライブラリが必要です。 | クライアントはロードバランサに接続するため、クライアントに対して透過的です。 |
スケーラビリティ
| Patroni | pg_auto_failover | ステートフル MIG とリージョン永続ディスク |
|---|---|---|
| スケーラビリティと可用性のトレードオフを構成する際の高い柔軟性。レプリカを追加することで、読み取りのスケーリングが可能です。 | Patroni と同様に、レプリカを追加することで読み取りスケーリングが可能です。 | 一度にアクティブにできる PostgreSQL ノードが 1 つしかないため、スケーラビリティが制限されます。 |
PostgreSQL ノードの初期化、構成管理の自動化
| Patroni | pg_auto_failover | ステートフル MIG とリージョン永続ディスク |
|---|---|---|
PostgreSQL 構成(patronictl
edit-config)の管理ツールを提供します。クラスタ内の新しいノードまたは再起動されたノードを自動的に初期化します。ノードの初期化には pg_basebackup を使用するか、Barman などのツールを使用できます。 |
ノードを自動的に初期化します。ただし、新しいレプリカノードを初期化する場合は、pg_basebackup を使用します。構成管理は、pg_auto_failover 関連の構成に制限されています。 |
共有ディスクを持つステートフル インスタンス グループにより、PostgreSQL ノードの初期化が不要になります。実行中のノードは 1 つのみであるため、構成管理は単一ノードで行います。 |
カスタマイズの可能性と機能の充実
| Patroni | pg_auto_failover | ステートフル MIG とリージョン永続ディスク |
|---|---|---|
|
降格や昇格などの重要なステップでユーザー定義可能なアクションを呼び出せるように、フック インターフェースを提供します。 構成機能が充実しています。さまざまな種類の DCS をサポートし、さまざまな方法でレプリカの初期化や PostgreSQL の構成を提供できます。 カスケード レプリカ クラスタがクラスタ間で簡単に移行できるように、スタンバイ クラスタを設定できます。 |
これは比較的新しいプロジェクトであるため、機能が制限されています。 | なし |
成熟度
| Patroni | pg_auto_failover | ステートフル MIG とリージョン永続ディスク |
|---|---|---|
| プロジェクトは 2015 年から提供され、Zalando や GitLab などの大企業の本番環境で使用されています。 | 新しいプロジェクトが 2019 年初頭に発表されました。 | 一般提供されている Google Cloud プロダクトだけで構成されます。 |
メンテナンスとモニタリングのベスト プラクティス
PostgreSQL HA クラスタのメンテナンスとモニタリングは、高可用性、データの完全性、最適なパフォーマンスを確保するために不可欠です。以降のセクションでは、PostgreSQL HA クラスタのモニタリングとメンテナンスに関するベスト プラクティスについて説明します。
定期的にバックアップと復元のテストを実施する
PostgreSQL データベースを定期的にバックアップし、復元プロセスをテストします。これにより、データの完全性が確保され、停止時のダウンタイムを最小限に抑えることができます。復元プロセスをテストして、バックアップを検証し、停止が発生する前に潜在的な問題を特定します。
PostgreSQL サーバーとレプリケーションの遅延をモニタリングする
PostgreSQL サーバーをモニタリングして、実行されていることを確認します。プライマリ ノードとレプリカノード間のレプリケーション ラグをモニタリングします。ラグが大きすぎると、データが不整合になり、フェイルオーバー時にデータ損失が増加する可能性があります。大幅な遅延の増加に関するアラートを設定し、根本原因を速やかに調査します。pg_stat_replication や pg_replication_slots などのビューを使用すると、レプリケーション ラグをモニタリングできます。
接続プーリングを実装する
接続プーリングは、データベース接続の効率的な管理に役立ちます。接続プーリングは、新しい接続を確立する際のオーバーヘッドを削減し、アプリケーションのパフォーマンスとデータベース サーバーの安定性を向上させます。PGBouncer や Pgpool-II などのツールは、PostgreSQL の接続プーリングを提供できます。
包括的なモニタリングを実装する
PostgreSQL HA クラスタに関する分析情報を取得するには、次のように堅牢なモニタリング システムを確立します。
- CPU 使用率、メモリ使用量、ディスク I/O、ネットワーク アクティビティ、アクティブな接続など、PostgreSQL とシステムの主要な指標をモニタリングします。
- 詳細な分析とトラブルシューティングのために、サーバーログ、WAL ログ、自動バキュームログなどの PostgreSQL ログを収集します。
- モニタリング ツールとダッシュボードを使用して指標とログを可視化し、問題を迅速に特定します。
- 指標とログをアラート システムと統合して、潜在的な問題について事前に通知します。
Compute Engine インスタンスのモニタリングの詳細については、Cloud Monitoring の概要をご覧ください。
次のステップ
- Cloud SQL 高可用性構成の詳細を確認する。
- リージョン永続ディスクを使用した高可用性オプションについて学習する。
- Patroni の詳細を確認する。
- pg_auto_failover の詳細を確認する。
- Cloud アーキテクチャ センターで、リファレンス アーキテクチャ、図、ベスト プラクティスを確認する。
協力者
著者: ソリューション アーキテクト、Alex Cârciu