Cette page décrit les journaux disponibles pour les applications App Engine, et explique comment écrire et afficher des entrées de journal et comment les mettre en corrélation.
App Engine collecte deux types de journaux :
Journal de requêtes: journaux des requêtes envoyées à votre application. Par défaut, App Engine émet automatiquement une entrée de journal pour chaque requête HTTP reçue par une application.
Journal d'application: entrées de journal émises par une application App Engine en fonction des entrées de journal que vous écrivez dans un framework ou un fichier compatible.
App Engine envoie automatiquement les journaux de requête et les journaux d'application à l'agent Cloud Logging.
Écrire des journaux d'application
App Engine émet automatiquement des journaux pour les requêtes envoyées à votre application. Il n'est donc pas nécessaire d'écrire des journaux de requêtes. Cette section explique comment écrire des journaux d'application.
Lorsque vous écrivez des journaux d'application à partir de votre application App Engine, ils sont automatiquement récupérés par Cloud Logging, à condition qu'ils soient écrits à l'aide des méthodes suivantes:
Intégration à Cloud Logging
Vous pouvez intégrer votre application App Engine à Cloud Logging. Cette approche vous permet d'utiliser toutes les fonctionnalités proposées par Cloud Logging et ne nécessite que quelques lignes de code spécifique à Google.
Écrire des journaux structurés dans stdout et stderr
Par défaut, App Engine utilise la bibliothèque cliente Cloud Logging pour envoyer des journaux.
Toutefois, cette méthode n'est pas compatible avec la journalisation structurée. Vous ne pouvez écrire des journaux structurés qu'à l'aide des flux de redirection stdout/stderr. Vous pouvez également envoyer des chaînes de texte à stdout et stderr. Par défaut, la charge utile du journal est une chaîne de texte stockée dans le champ textPayload de l'entrée de journal. Les chaînes apparaissent sous forme de messages dans l'explorateur de journaux, la ligne de commande et l'API Cloud Logging. Elles sont associées au service App Engine et à la version qui les a émises.
Pour mieux exploiter les journaux, vous pouvez filtrer ces chaînes par niveau de gravité dans l'explorateur de journaux. Pour filtrer ces chaînes, vous devez les mettre en forme en tant que données structurées.
Pour ce faire, vous écrivez des journaux sous la forme d'une seule ligne de données JSON sérialisées. App Engine récupère et analyse cette ligne JSON sérialisée et la place dans le champ jsonPayload de l'entrée de journal au lieu de textPayload.
Dans l'environnement standard App Engine, l'écriture de journaux structurés dans stdout et stderr n'est pas comptabilisée dans le quota de requêtes d'ingestion de journaux par minute dans l'API Cloud Logging.
Champs JSON spéciaux dans les messages
Lorsque vous fournissez un journal structuré sous forme de dictionnaire JSON, certains champs spéciaux sont supprimés de jsonPayload et écrits dans le champ correspondant de la LogEntry générée, comme décrit dans la documentation sur les champs spéciaux.
Par exemple, si vos données JSON incluent une entrée severity, celle-ci est supprimée de jsonPayload et apparaît en tant que propriété severity de l'entrée de journal.
La propriété message est utilisée comme texte d'affichage principal de l'entrée de journal, le cas échéant.
Corréler les journaux de requête avec les journaux d'application
Une fois que vous avez formaté les entrées en tant qu'objets JSON et fourni des métadonnées spécifiques, vous pouvez activer le filtrage et la corrélation avec les journaux de requêtes. Pour mettre en corrélation les entrées de journal de requêtes avec les entrées de journal d'application, vous avez besoin de l'identifiant de trace de la requête. Suivez les instructions pour mettre en corrélation les messages de journal :
- Extrayez l'identifiant de trace de l'en-tête de requête
X-Cloud-Trace-Context. - Dans votre entrée de journal structurée, écrivez l'ID dans un champ nommé
logging.googleapis.com/trace. Pour en savoir plus sur l'en-têteX-Cloud-Trace-Context, consultez la section Forcer le traçage d'une requête.
Pour afficher les journaux corrélés, consultez la page Afficher les entrées de journal corrélées dans l'explorateur de journaux.
Afficher les journaux
Vous pouvez afficher les journaux d'application et les journaux de requêtes de plusieurs manières :
- Utilisez l'explorateur de journaux de Cloud Logging dans la console Google Cloud .
- Afficher les journaux à l'aide de gcloud via la Google Cloud CLI
- Lire les journaux de manière automatisée à l'aide de différentes méthodes.
Utiliser l'Explorateur de journaux
Vous pouvez afficher les journaux d'application et de requêtes à l'aide de l'Explorateur de journaux :
Accédez à l'explorateur de journaux dans la console Google Cloud :
Sélectionnez un projet Google Cloud existant en haut de la page.
Dans Type de ressource, sélectionnez Application GAE.
Vous pouvez filtrer l'Explorateur de journaux en fonction du service, de la version et d'autres critères d'App Engine. Vous pouvez également rechercher des entrées spécifiques dans les journaux. Consultez la page Utiliser l'explorateur de journaux pour plus d'informations.
Si vous envoyez des entrées de texte simples à la sortie standard, vous ne pouvez pas utiliser la visionneuse de journaux pour filtrer les entrées d'application par gravité ni identifier les journaux d'application correspondant à des requêtes spécifiques. Vous pouvez toujours utiliser d'autres types de filtres dans l'explorateur de journaux, tels que le texte et l'horodatage.
Afficher les entrées de journal corrélées dans l'Explorateur de journaux
Dans l'Explorateur de journaux, pour afficher les entrées de journal enfants corrélées à une entrée de journal parente, développez l'entrée de journal.
Par exemple, pour afficher les entrées de journal de requêtes App Engine et d'application, procédez comme suit :
Dans le panneau de navigation de la console Google Cloud , sélectionnez Logging, puis Explorateur de journaux :
Dans Type de ressource, sélectionnez Application GAE.
Pour afficher et mettre en corrélation les journaux de requêtes, sélectionnez request_log dans le champ Nom du journal. Sinon, pour mettre en corrélation par journaux de requêtes, cliquez sur Corréler par et sélectionnez request_log.
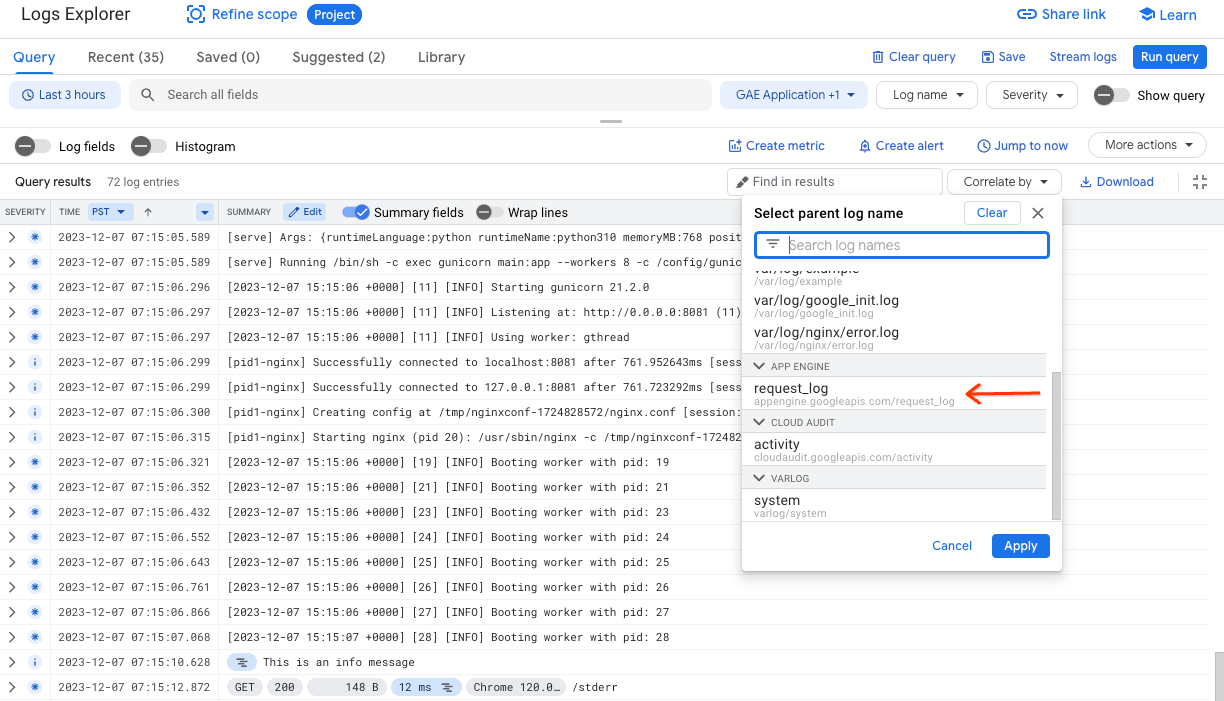
Dans le volet Résultats de la requête, cliquez sur Développer pour développer une entrée de journal. Lors du développement, chaque journal de requêtes affiche les journaux d'application associés.
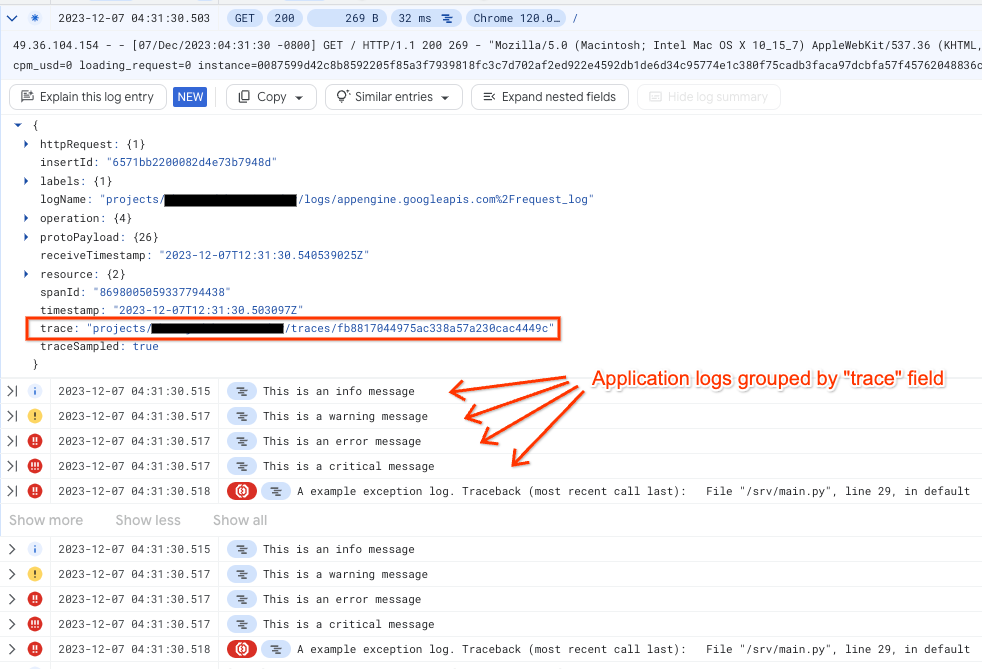
Après avoir créé un filtre pour les journaux, chaque journal de requêtes affiche les journaux d'application correspondants en tant que journaux enfants. Pour ce faire, l'Explorateur de journaux met en corrélation le champ trace dans les journaux d'application et un journal de requêtes donné, en supposant que l'application utilise la bibliothèque google-cloud-logging.
L'image suivante montre les journaux d'application regroupés par champ trace :
Utiliser la Google Cloud CLI
Pour afficher vos journaux App Engine à partir de la ligne de commande, exécutez la commande suivante :
gcloud app logs tail
Pour plus d'informations, consultez la page gcloud app logs tail.
Lire les journaux de manière automatisée
Si vous souhaitez lire les journaux de manière automatisée, vous pouvez utiliser l'une des méthodes suivantes :
- Utilisez un récepteur pour envoyer les journaux à Pub/Sub et un script pour les extraire de Pub/Sub.
- Appelez l'API Cloud Logging via la bibliothèque cliente correspondant à votre langage de programmation.
- Appelez directement les points de terminaison REST de l'API Cloud Logging.
Tarifs, quotas et règles de conservation des journaux
Pour plus d'informations sur les tarifs applicables aux journaux d'application et de requêtes, consultez la section Tarifs de Cloud Logging.
Pour en savoir plus sur les règles de conservation des journaux et la taille maximale des entrées de journal, consultez la page Quotas et limites. Si vous souhaitez stocker vos journaux pendant une période plus longue, vous pouvez les exporter vers Cloud Storage. Vous avez également la possibilité d'exporter vos journaux vers BigQuery et Pub/Sub en vue d'un traitement ultérieur.
Gérer l'utilisation des ressources de journal
Vous pouvez contrôler la quantité d'activité de journalisation de vos journaux d'application en écrivant plus ou moins d'entrées à partir du code de votre application. Les journaux de requêtes sont créés automatiquement. Par conséquent, pour gérer le nombre d'entrées de journal de requêtes associées à votre application, utilisez la fonctionnalité d'exclusion de journaux de Cloud Logging.
Problèmes connus
Voici quelques-uns des problèmes de journalisation dans les environnements d'exécution de deuxième génération :
Il peut arriver que les entrées de journal d'application ne soient pas mises en corrélation avec les entrées de journal de requêtes. Cela se produit la première fois que votre application reçoit une requête et chaque fois qu'App Engine écrit des messages d'état dans le journal de votre application. Pour en savoir plus, consultez la page https://issuetracker.google.com/issues/138365527.
Lorsque vous acheminez des journaux du récepteur de journaux vers Cloud Storage, la destination Cloud Storage ne contient que des journaux de requêtes. App Engine écrit les journaux d'application dans différents dossiers.
BigQuery ne parvient pas à ingérer les journaux à cause du champ
@typedans les journaux de requêtes. Cela perturbe la détection automatique du schéma, car BigQuery n'autorise pas@typedans les noms de champs. Pour résoudre ce problème, vous devez définir manuellement le schéma et supprimer le champ@typedes journaux de requêtes.Si vous utilisez les API REST de journalisation, un thread d'arrière-plan écrit des journaux dans Cloud Logging. Si le thread principal n'est pas actif, l'instance n'obtient pas de temps CPU, ce qui entraîne l'arrêt du thread d'arrière-plan. Le temps de traitement des journaux s'en trouve augmenté. À un moment donné, l'instance est supprimée et tous les journaux non envoyés sont perdus. Voici les possibilités qui s'offrent à vous pour éviter de perdre des journaux :
- Configurer le SDK Cloud Logging pour qu'il utilise gRPC. Avec gRPC, les journaux sont immédiatement envoyés à Cloud Logging. Cela peut cependant faire augmenter les limites de processeur requises.
- Envoyer les messages de journal à Cloud Logging à l'aide des flux de redirection
stdout/stderr. Ce pipeline se trouve en dehors de l'instance App Engine et n'est pas soumis au risque de limitation.
Étapes suivantes
- Consultez la section Surveiller et signaler la latence pour découvrir comment afficher les journaux des erreurs de débogage à l'aide de Cloud Logging, et comment utiliser Cloud Trace pour comprendre la latence des applications.