リージョン ID
REGION_ID は、アプリの作成時に選択したリージョンに基づいて Google が割り当てる省略形のコードです。一部のリージョン ID は、一般的に使用されている国や州のコードと類似しているように見える場合がありますが、このコードは国または州に対応するものではありません。2020 年 2 月以降に作成されたアプリの場合、REGION_ID.r は App Engine の URL に含まれています。この日付より前に作成されたアプリの場合、URL のリージョン ID は省略可能です。
詳しくは、リージョン ID をご覧ください。
ソフトウェア開発においては常にトレードオフの問題が伴いますが、マイクロサービスも例外ではありません。コードのデプロイやオペレーションの分離を進めれば、その分だけパフォーマンスのオーバーヘッドが発生することになります。ここでは、その影響を最小限に抑えるためのおすすめの手順をいくつか紹介します。
CRUD オペレーションをマイクロサービスにする
マイクロサービスは、作成、読み取り、更新、削除(CRUD)のパターンでアクセスするエンティティに特に適しています。この種のエンティティを操作するときは、一度に 1 つのエンティティ(ユーザーなど)のみを使用し、CRUD のアクションを一度に 1 つずつ実行するのが一般的です。したがって、このオペレーションに対するマイクロサービスの呼び出しは 1 回で済みます。CRUD オペレーションと一連のビジネス メソッドを含み、アプリケーションの多くの部分で使用されているエンティティを探し、それらのエンティティにマイクロサービスを使用すると効果的です。
バッチ API を使用する
CRUD スタイルの API に加え、バッチ API を使用すると、エンティティのグループに対するマイクロサービスのパフォーマンスを高めることができます。たとえば、単一のユーザーを取得する GET API メソッドを公開する代わりに、一連のユーザー ID を取得して対応するユーザーのディクショナリを返す API を使用できます。
リクエスト:
/user-service/v1/?userId=ABC123&userId=DEF456&userId=GHI789レスポンス:
{
"ABC123": {
"userId": "ABC123",
"firstName": "Jake",
… },
"DEF456": {
"userId": "DEF456",
"firstName": "Sue",
… },
"GHI789": {
"userId": "GHI789",
"firstName": "Ted",
… }
}
App Engine SDK では、Cloud Datastore から単一の RPC で複数のエンティティをフェッチする機能など、さまざまなバッチ API をサポートしており、それらのバッチ API を使用すると非常に効率的な場合があります。
非同期リクエストを使用する
レスポンスを作成する際に複数のマイクロサービスが必要になることがよくあります。たとえば、ログインしているユーザーの設定に加え、そのユーザーの会社の詳細もフェッチしなければならない場合があります。多くの場合、それらの情報は相互に依存しておらず、それぞれを並行してフェッチできます。App Engine SDK の Urlfetch ライブラリでは非同期リクエストがサポートされており、マイクロサービスを並行して呼び出すことができます。
from google.appengine.api import urlfetch
preferences_rpc = urlfetch.create_rpc()
urlfetch.make_fetch_call(preferences_rpc,
'https://preferences-service-dot-my-app.uc.r.appspot.com/preferences-service/v1/?userId=ABC123')
company_rpc = urlfetch.create_rpc()
urlfetch.make_fetch_call(company_rpc,
'https://company-service-dot-my-app.uc.r.appspot.com/company-service/v3/?companyId=ACME')
### microservice requests are now occurring in parallel
try:
preferences_response = preferences_rpc.get_result() # blocks until response
if preferences_response.status_code == 200:
# deserialize JSON, or whatever is appropriate
else:
# handle error
except urlfetch.DownloadError:
# timeout, or other transient error
try:
company_response = company_rpc.get_result() # blocks until response
if company_response.status_code == 200:
# deserialize JSON, or whatever is appropriate
else:
# handle error
except urlfetch.DownloadError:
# timeout, or other transient error
実際のシナリオでは、1 つのクラスに設定メソッドをカプセル化し、別のクラスに会社のメソッドをカプセル化することが多いため、並列処理を行うと、コードの構造が難しくなる可能性があります。このカプセル化を維持したまま非同期の Urlfetch 呼び出しを利用するのは簡単ではありません。App Engine Python SDK の NDB パッケージであるタスクレットを使用すると、この問題を解決できます。タスクレットを使用すると、コード内のカプセル化を維持したまま、マイクロサービスを並列で呼び出すことができます。タスクレットは、RPC ではなく Future を使用しますが、考え方は似ています。
最短のルートを使用する
Urlfetch を呼び出す方法によって、異なるインフラストラクチャやルートが使用される場合があります。最適なルートを使用できるように推奨される方法を次に示します。
- カスタム ドメインではなく
REGION_ID.r.appspot.comを使用する - カスタム ドメインを使用すると、Google のインフラストラクチャでのルーティング時に異なるルートが使用されます。マイクロサービスの呼び出しは内部的なものであるため、
https://PROJECT_ID.REGION_ID.r.appspot.comを使用した方が処理が簡単で、パフォーマンスも高くなります。 follow_redirectsをFalseに設定するUrlfetchを呼び出すときは明示的にfollow_redirects=Falseを設定します。この設定により、リダイレクトをフォローするよう設計された高負荷のサービスを回避できます。通常、API エンドポイントは独自のマイクロサービスであり、HTTP 200 シリーズ、400 シリーズ、500 シリーズのレスポンスのみを返すため、クライアントにリダイレクトする必要はありません。- サービスを複数のプロジェクトではなく 1 つのプロジェクトにまとめる
- マイクロサービスベースのアプリケーションを構築する際、複数のプロジェクトを使用すると便利な場合もありますが、パフォーマンスを優先するのであれば単一のプロジェクト内でサービスを使用した方が効果的です。1 つのプロジェクトのサービスは同じデータセンターでホストされます。Google のデータセンター間ネットワークのスループットは優秀であるとはいえ、処理速度ではローカル呼び出しには敵いません。
セキュリティを強化する際の注意
API 呼び出しの認証に何度もやり取りが必要になるようなセキュリティ メカニズムは、パフォーマンスに悪影響を及ぼします。たとえば、アプリケーションから受け取ったチケットを検証するためにマイクロサービスからアプリケーションにコールバックしなければならない場合、データを取得するために複数回のラウンドトリップが発生することになります。
OAuth2 の実装では、リフレッシュ トークンを使用し、アクセス トークンをキャッシュに保存することで、この負荷を Urlfetch の呼び出し間で平均化できます。ただし、アクセス トークンのキャッシュが Memcache に格納されている場合は、そのキャッシュをフェッチするために Memcache のオーバーヘッドが発生します。このオーバーヘッドを回避するためにアクセス トークンのキャッシュをインスタンス メモリに保存する方法もありますが、新しいインスタンスが作成されるたびにアクセス トークンのネゴシエーションが行われるため、OAuth2 のアクティビティが頻繁に発生することに変わりはありません。App Engine のインスタンスのスピンアップおよびスピンダウンが頻繁に行われることに注意が必要です。Memcache とインスタンス キャッシュを融合した方法は、この問題の軽減に役立ちますが、ソリューションが複雑になる原因にもなります。
パフォーマンスを高めるためのもう 1 つのアプローチとして、マイクロサービス間でシークレット トークンを共有する(カスタム HTTP ヘッダーとして送信するなど)方法があります。このアプローチでは、各マイクロサービスでそれぞれの呼び出し元に固有のトークンを使用できます。共有シークレットがセキュリティ実装に適した選択であるかについては疑問の余地がありますが、同じアプリケーションのマイクロサービスどうしであれば問題は少なく、パフォーマンスの向上が得られます。共有シークレットを使用すれば、マイクロサービスで受信したシークレットの文字列をメモリなどに保存されたディクショナリと比較するだけで済み、セキュリティ実装が非常に軽量になります。
すべてのマイクロサービスを App Engine で展開している場合は、受信した X-Appengine-Inbound-Appid ヘッダーを検査することも可能です。このヘッダーは、別の App Engine プロジェクトに対するリクエストを実行する際に Urlfetch インフラストラクチャで追加されるもので、外部から設定することはできません。セキュリティ要件によっては、この受信ヘッダーを検査してセキュリティ ポリシーを適用できます。
マイクロサービスのリクエストをトレースする
マイクロサービスベースのアプリケーションを構築すると、連続する Urlfetch の呼び出しによってオーバーヘッドが蓄積されていきます。そのような場合は、Cloud Trace を使用して実行中の呼び出しやオーバーヘッドの発生箇所を確認できます。ここで重要なのは、Cloud Trace を使用すれば、独立したマイクロサービスが連続して呼び出される場合にもそれらを特定できることです。これにより、コードをリファクタリングして、それらのフェッチを並行して実行できます。
Cloud Trace の機能は、単一のプロジェクトで複数のサービスを使用する場合に効果的です。Cloud Trace では、プロジェクトのマイクロサービス間で行われたすべての呼び出しが 1 つのコールグラフにまとめて表示されるため、エンドツーエンドのリクエスト全体を 1 つのトレースで確認できます。
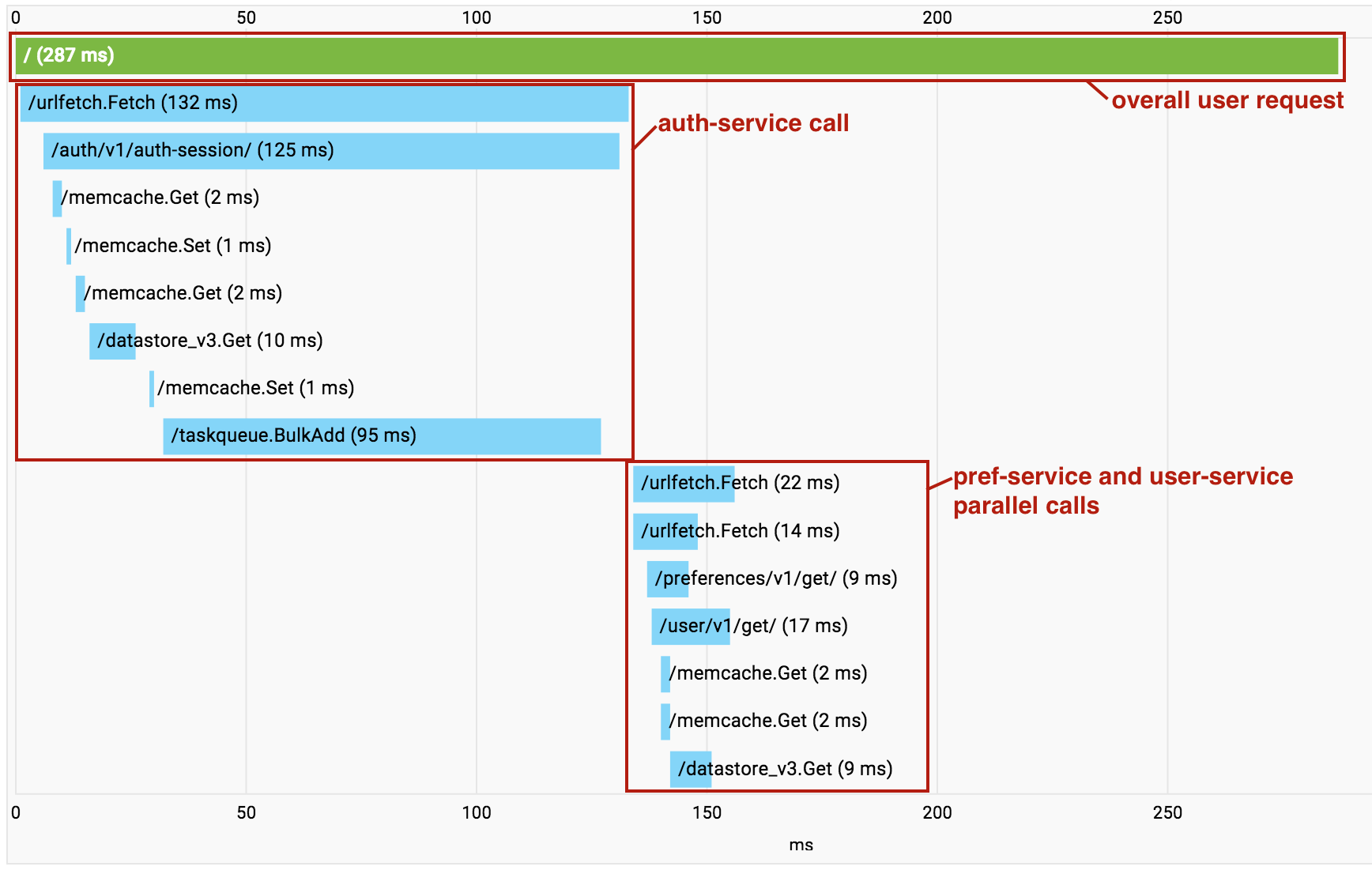
この例では、pref-service と user-service の呼び出しが非同期の Urlfetch を使用して並行して実行されているため、両方の RPC が一緒に表示されています。それでも、レイテンシの診断には十分に役立ちます。
次のステップ
- App Engine のマイクロサービス アーキテクチャの概要を確認します。
- App Engine でマイクロサービスを使用する開発環境、テスト環境、QA 環境、ステージング環境、本番環境を作成して名前を付ける方法を確認します。
- マイクロサービス間で通信する API を設計する際におすすめの方法を確認します。
- 既存のモノリシック アプリケーションを、マイクロサービスを使用するアプリケーションに移行する方法を確認します。