マイクロサービスは、アプリケーション開発におけるアーキテクチャ スタイルの一つです。マイクロサービスによって、大きなアプリケーションを、それぞれが独自の責任範囲を持つ独立した構成要素に分解できます。単一のユーザー リクエストまたは API リクエストを受け取ると、マイクロサービスベースのアプリケーションは多くの内部マイクロサービスを呼び出して、レスポンスを作成します。
正しく実装されたマイクロサービスベースのアプリケーションは、以下の目的を達成します。
- さまざまなマイクロサービスの間に厳密なコントラクトを定義する。
- 独立したデプロイ サイクル(ロールバックを含む)を可能にする。
- サブシステム上での A/B リリーステストの同時実行を促進する。
- テスト自動化と品質保証のオーバーヘッドを最小化する。
- ロギングとモニタリングの明瞭性を改善する。
- より詳細な費用計算を提供する。
- アプリケーションのスケーラビリティと信頼性を高める。
Google App Engine にはマイクロサービスベースのアプリケーションに最適なたくさんの機能があります。ここでは、Google App Engine で実行するマイクロサービスベースのアプリケーションとして自分のアプリケーションをデプロイする際に利用できるおすすめの方法の概略を説明します。
マイクロサービスとしての App Engine サービス
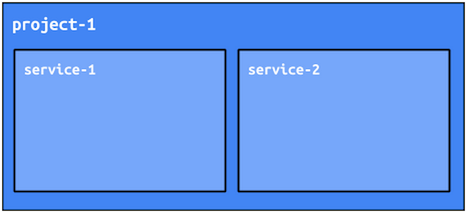
1 つの App Engine プロジェクトでは、複数のマイクロサービスを別個のサービスとしてデプロイできます(App Engine でサービスは以前「モジュール」と呼ばれていました)。マイクロサービスではコードが完全に分離されます。したがって、これらのサービスでコードを実行する方法は、HTTP 呼び出し(ユーザー リクエストや RESTful API 呼び出しなど)のみです。あるサービスのコードが別のサービスのコードを直接呼び出すことはできません。コードを複数のサービスに別々にデプロイすることが可能で、異なるサービスを異なる言語(Python、Java、Go、PHP など)で作成することもできます。自動スケーリング、ロード バランシング、マシン インスタンスのタイプはすべてサービスごとに独立して管理されます。
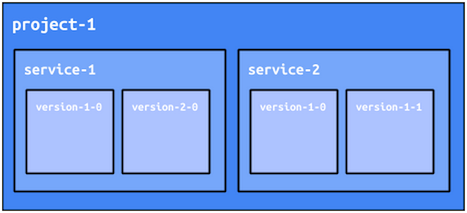
サービス内部での複数のバージョン
さらに、それぞれのサービスについて同時に複数のバージョンをデプロイできます。それらのバージョンのうちのいずれか 1 つがそのサービスのデフォルトのバージョンとして機能しますが、サービスの各バージョンはそれぞれ独自のアドレスを持っているので、デプロイされた任意のバージョンに直接アクセスすることが可能です。このような構造のおかげで、新規バージョンのスモークテスト、異なるバージョン間の A/B テスト、ロール フォワードとロールバックの簡易操作など、行えることは限りなく広がります。App Engine フレームワークには、これらの多くを支援するメカニズムが用意されています。それらのメカニズムについては、後のセクションで詳しく説明します。
サービスの分離
サービスはその大部分が分離されていますが、App Engine リソースの一部を共有しています。たとえば、Cloud Datastore、Memcache、タスクキューはすべて同じ App Engine プロジェクトに属するサービスの共有リソースです。これらのリソースを共有することにはいくつかの利点もありますが、マイクロサービスベースのアプリケーションでは、マイクロサービス間でコードとデータの分離が維持されている点が重要です。不必要にリソースを共有することで受ける影響を軽減するのに役立つアーキテクチャ パターンがいくつか用意されています。それらのパターンについては、この記事の後半で説明します。
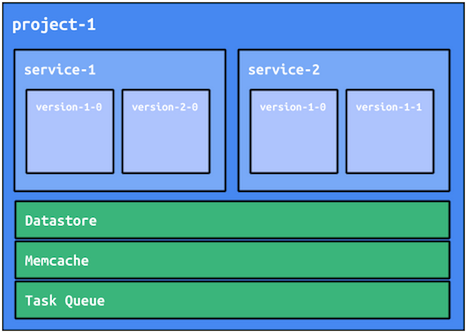
プロジェクトの分離
アーキテクチャ パターンに依存した分離ではなく、より秩序だった手法で分離を行うには、複数の App Engine プロジェクトを使用します。ここでサービスではなくプロジェクトを利用することには長所と短所があるので、実際の状況を念頭に置いてバランスを考慮する必要があります。複数のプロジェクトを使用することの利点が特に必要とされる状況でない限り、まずは 1 つのプロジェクト内で複数のサービスを使用することから始めるのが最善です。そのほうがパフォーマンスに優れ、管理オーバーヘッドも最低限で済むからです。もちろん、サービスの使用とプロジェクトの使用を融合させた方法も選択できます。
サービスの分離とプロジェクトの分離の比較
次の表に、マイクロサービス アーキテクチャにおいて複数のサービスを使用した場合と複数のプロジェクトを使用した場合の比較を示します。
| 複数のサービス | 複数のプロジェクト | |
|---|---|---|
| コードの分離 | デプロイされるコードは、サービスごと、バージョンごとに完全に独立している。 | デプロイされるコードは、プロジェクトごとに完全に独立しており、各プロジェクトのサービスごと、バージョンごとにも完全に独立している。 |
| データの分離 |
Cloud Datastore と Memcache はすべてのサービスとバージョンで共有されるが、名前空間をデベロッパー パターンとして使用することによりデータを分離できる。
タスクキューを分離するには、キュー名のデベロッパー命名規則を利用して、user-service-queue-1 のようにすることができる。 |
Cloud Datastore、Memcache、タスクキューはプロジェクトごとに完全に独立している。 |
| ログの分離 | 各サービス(と各バージョン)のログはそれぞれ独立しているが、それらのログを同時に表示することも可能。 | 各プロジェクト(および各プロジェクトのサービスとバージョン)のログはそれぞれ独立しているが、同一プロジェクトのすべてのログを同時に表示することも可能。 ただし、複数のプロジェクトのログを同時に表示することはできない。 |
| パフォーマンスのオーバーヘッド | 同一プロジェクトのサービスは同じデータセンターにデプロイされるため、あるサービスが HTTP で別のサービスを呼び出す場合のレイテンシは非常に低い。 | プロジェクトがデプロイされるデータセンターはそれぞれ異なる場合があるため、HTTP レイテンシが上がるかもしれないが、Google のネットワークは世界トップレベルなので、上がるとしてもかなり低い。 |
| 費用計算 | インスタンス時間の費用(コードの実行に要する CPU とメモリ)はサービスごとに分離されない。プロジェクト全体のインスタンス時間すべてが一括で扱われる。 | プロジェクトごとの費用は分離されるので、マイクロサービスごとの費用の確認が非常に簡単。 |
| オペレーターの権限 | オペレーターは、プロジェクト内のすべてのサービスについて、コードのデプロイ、バージョンのロール フォワードとロールバック、ログの表示を行うことができる。 特定のサービスに対するアクセスを制限することはできない。 | 個々のプロジェクトごとにオペレーターのアクセス権を制御できる。 |
| リクエストのトレース | Google Cloud Trace を使用して、同一プロジェクト内のサービスについて、リクエストとその結果生じるマイクロサービスのリクエストを 1 つの合成トレースとして表示できる。この機能のおかげで、パフォーマンス調整が行いやすい。 | Cloud Trace の呼び出しは、同じ組織に含まれている GCP プロジェクト間で可視化できる。 |
次のステップ
- App Engine でマイクロサービスを使用する開発環境、テスト環境、QA 環境、ステージング環境、本番環境を作成して名前を付ける方法を確認します。
- マイクロサービス間で通信する API を設計するためのおすすめの方法を確認します。
- マイクロサービスのパフォーマンスを高めるためのおすすめの方法を確認します。
- 既存のモノリシック アプリケーションをマイクロサービスを採用したアプリケーションに移行する方法を確認します。
- ユーザーの状況でマイクロサービスを使用することがふさわしいかどうかを確認します。Google のソリューション アーキテクトであるプレストン ホルムズが、彼の個人的なブログで、彼がマイクロサービスの弱点だと考えるいくつかの点に関する投稿を公開しています。