Les microservices désignent un style d'architecture utilisé dans le développement d'applications. Ils permettent de décomposer une application volumineuse en composants indépendants, chaque élément ayant ses propres responsabilités. Pour diffuser la requête d'un utilisateur unique ou d'une API, une application basée sur des microservices peut appeler plusieurs microservices internes pour composer sa réponse.
Une application basée sur des microservices correctement implémentée peut permettre d'atteindre les objectifs suivants :
- Définir des contrats forts entre les différents microservices
- Autoriser les cycles de déploiement indépendants, y compris le rollback
- Faciliter les tests A/B simultanés de versions sur les sous-systèmes
- Minimiser les frais d'automatisation des tests et d'assurance qualité
- Clarifier les rapports de journalisation et de surveillance
- Fournir une comptabilité précise
- Augmenter l'évolutivité et la fiabilité globales des applications
Google App Engine comporte un certain nombre de fonctionnalités adaptées aux applications basées sur des microservices. Cette page décrit les bonnes pratiques à suivre lors du déploiement de votre application basée sur des microservices sur Google App Engine.
Services App Engine en tant que microservices
Dans un projet App Engine, vous pouvez déployer plusieurs microservices en tant que services distincts, auparavant appelés modules dans App Engine. Ces services isolent complètement le code. Le seul moyen de l'exécuter consiste alors à utiliser des appels HTTP, tels que les requêtes utilisateur ou les appels d'API RESTful. Le code d'un service ne peut pas appeler directement celui d'un autre service. Le code peut être déployé sur des services de manière indépendante, et différents services peuvent être écrits dans des langages différents, tels que Python, Java, Go et PHP. L'autoscaling, l'équilibrage de charge et les types d'instances de machine sont tous gérés de manière indépendante pour les services.
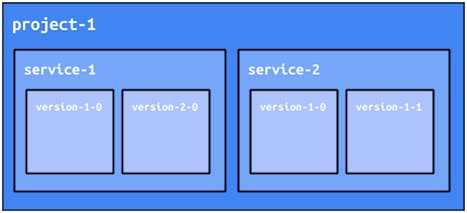
Versions au sein des services
De plus, chaque service peut posséder plusieurs versions déployées simultanément. Pour chaque service, l'une d'elles est la version de diffusion par défaut, bien qu'il soit possible d'accéder directement à n'importe quelle version déployée d'un service, puisque pour chaque service, toute version dispose de sa propre adresse. Cette structure offre de nombreuses possibilités, par exemple celle d'effectuer des tests de confiance d'une nouvelle version, des tests A/B entre différentes versions, et des opérations simplifiées de déploiement et de rollback. Le framework App Engine fournit des mécanismes afin de vous aider avec la plupart de ces éléments. Nous détaillons ces mécanismes dans les prochaines sections.
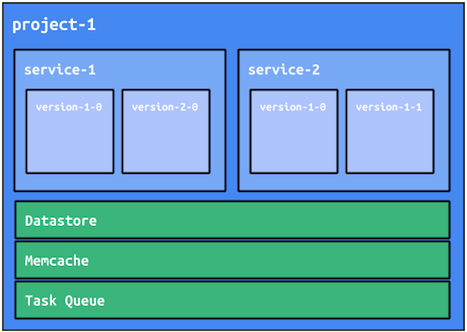
Isoler les services
Bien que les services soient majoritairement isolés, ils partagent certaines ressources App Engine. Par exemple, Cloud Datastore, Memcache et les files d'attente de tâches sont des ressources partagées entre des services d'un projet App Engine. Bien que ces partages présentent certains avantages, il est important pour une application basée sur des microservices de garantir l'isolation du code et des données entre les microservices. Il existe des modèles d'architecture permettant de limiter les partages indésirables. Nous les décrivons dans la suite de cet article.
Isoler le projet
Si vous ne voulez pas vous fier à ces modèles pour procéder à l'isolation et si vous souhaitez mettre en place une séparation plus formelle, vous pouvez utiliser plusieurs projets App Engine. Il y a des avantages et des inconvénients à utiliser des projets plutôt que des services, et vous devez équilibrer les compromis en fonction de votre situation. À moins que vous n'ayez besoin spécifiquement de l'un des avantages que permet l'utilisation de plusieurs projets, il est préférable de commencer par utiliser plusieurs services au sein d'un seul projet, car les performances seront meilleures et les frais administratifs moins importants. Bien entendu, vous pouvez également choisir une combinaison de ces deux approches.
Comparaison de l'isolation des services et de l'isolation des projets
Le tableau suivant compare l'utilisation de services et de projets multiples dans une architecture de microservices :
| Services multiples | Projets multiples | |
|---|---|---|
| Isolation du code | Le code déployé fonctionne de manière complètement indépendante entre les services et les versions. | Le code déployé fonctionne de manière complètement indépendante entre les projets, ainsi qu'entre les services et les versions de chaque projet. |
| Isolation des données |
Cloud Datastore et Memcache sont partagés entre les services et les versions. Toutefois, les espaces de noms peuvent être utilisés comme modèles de développement afin d'isoler des données.
Pour procéder à l'isolation de la file d'attente de tâches, vous pouvez utiliser une convention de développement concernant les noms de files d'attente, telle que user-service-queue-1.
|
Cloud Datastore, Memcache et les files d'attente de tâches fonctionnent de manière complètement indépendante entre les projets. |
| Isolation des journaux | Chaque service et chaque version possèdent des journaux indépendants, bien qu'ils puissent être visualisés conjointement. | Chaque projet, ainsi que les services et versions qu'ils contiennent, possèdent des journaux indépendants, bien que tous les journaux d'un projet donné puissent être visualisés conjointement. Les journaux de plusieurs projets ne peuvent pas être visualisés conjointement. |
| Impact sur les performances | Les services d'un projet étant déployés dans le même centre de données, la latence d'appel d'un service à partir d'un autre à l'aide du protocole HTTP est très faible. | Les projets peuvent être déployés dans différents centres de données. Par conséquent, la latence HTTP peut être plus élevée, tout en restant relativement faible dans la mesure où Google utilise un réseau de pointe. |
| Comptabilité analytique | Les coûts correspondant aux heures d'utilisation d'une instance, à savoir le processeur et la mémoire nécessaires à l'exécution de votre code, ne sont pas séparés par service, mais regroupés pour l'intégralité du projet. | Les coûts des différents projets sont séparés, ce qui permet de visualiser facilement le coût des différents microservices. |
| Autorisations de l'opérateur | Un opérateur peut déployer du code, effectuer le déploiement et le rollback de versions, et afficher les journaux de tous les services d'un projet. Il n'existe aucun moyen de limiter l'accès à des services spécifiques. | L'accès des opérateurs peut être contrôlé séparément sur des projets distincts. |
| Traçage des requêtes | L'utilisation de Google Cloud Trace vous permet d'afficher une requête ainsi que les requêtes de microservices qui en découlent pour les services d'un même projet. Celles-ci se présentent alors sous la forme d'une trace composée unique. Cette fonctionnalité peut faciliter le réglage des performances. | Les appels Cloud Trace peuvent être visualisés dans les projets GCP s'ils appartiennent à la même organisation. |
Étapes suivantes
- Découvrez comment créer et nommer des environnements de développement, de test, de contrôle qualité, de préproduction et de production avec des microservices dans App Engine.
- Découvrez les bonnes pratiques relatives à la conception d'API permettant la communication entre les microservices.
- Découvrez les bonnes pratiques en matière de performances de microservices.
- Découvrez comment migrer une application monolithique existante vers une application dotée de microservices.
- Déterminez si les microservices constituent la solution idéale dans votre situation. Sur son blog personnel, Preston Holmes, architecte de solutions Google, a publié un article détaillant certains des inconvénients que présentent selon lui les microservices.