BigQuery
BigQuery コネクタを使用すると、Google BigQuery データに対して挿入、削除、更新、読み取りオペレーションを実行できます。BigQuery データに対してカスタム SQL クエリを実行することもできます。BigQuery コネクタを使用すると、複数の Google Cloud サービスや、Cloud Storage や Amazon S3 などの他のサードパーティ サービスからデータを統合できます。
始める前に
Google Cloud プロジェクトで次のタスクを行います。
- ネットワーク接続が設定されていることを確認します。ネットワーク パターンの詳細については、Network Connectivity をご覧ください。
- コネクタを構成するユーザーに roles/connectors.admin IAM ロールを付与します。
- コネクタに使用するサービス アカウントに
roles/bigquery.dataEditorIAM ロールを付与します。サービス アカウントがない場合は、サービス アカウントを作成する必要があります。コネクタとサービス アカウントは同じプロジェクトに属している必要があります。 - 次のサービスを有効にします。
secretmanager.googleapis.com(Secret Manager API)connectors.googleapis.com(Connectors API)
サービスを有効にする方法については、サービスを有効にするをご覧ください。以前にプロジェクトでこうしたサービスを有効にしていない場合は、コネクタを構成するときに有効にするよう求められます。
BigQuery Connection を作成する
接続はデータソースに特有です。つまり、多数のデータソースがある場合は、データソースごとに別々の接続を作成する必要があります。接続を作成する手順は次のとおりです。
- Cloud コンソールで、[Integration Connectors] > [接続] ページに移動し、Google Cloud プロジェクトを選択または作成します。
- [+ 新規作成] をクリックして [接続の作成] ページを開きます。
- [ロケーション] セクションで、[リージョン] リストからロケーションを選択し、[次へ] をクリックします。
サポートされているすべてのリージョンのリストについては、ロケーションをご覧ください。
- [接続の詳細] セクションで、次の操作を行います。
- [コネクタ] リストから [BigQuery] を選択します。
- [Connector version] リストからコネクタのバージョンを選択します。
- [接続名] フィールドに、接続インスタンスの名前を入力します。接続名には、小文字、数字、ハイフンを使用できます。名前の先頭は英字、末尾は英字または数字にします。名前は 49 文字を超えないようにします。
- 必要に応じて、Cloud Logging を有効にして、ログレベルを選択します。デフォルトのログレベルは
Errorに設定されています。 - サービス アカウント: 必要なロールを持つサービス アカウントを選択します。
- (省略可)接続ノードの設定を構成します。
- ノードの最小数: 接続ノードの最小数を入力します。
- ノードの最大数: 接続ノードの最大数を入力します。
- プロジェクト ID: データが存在する Google Cloud プロジェクトの ID。
- データセット ID: BigQuery データセットの ID を入力します。
- BigQuery Array データ型をサポートするには、[ネイティブ データ型をサポート] を選択します。次の配列型がサポートされています。Varchar、Int64、Float64、Long、Double、Bool、Timestamp。ネストされた配列はサポートされていません。
- (省略可)接続用のプロキシ サーバーを構成するには、[プロキシの使用] を選択して、プロキシの詳細を入力します。
-
Proxy Auth Scheme: プロキシ サーバーで認証する認証タイプを選択します。次の認証タイプがサポートされています。
- 基本: 基本的な HTTP 認証。
- ダイジェスト: ダイジェスト HTTP 認証。
- Proxy User: プロキシ サーバーでの認証に使用されるユーザー名。
- プロキシ パスワード: ユーザーのパスワードの Secret Manager シークレット。
-
Proxy SSL Type: プロキシ サーバーへの接続時に使用する SSL タイプ。次の認証タイプがサポートされています。
- 自動: デフォルトの設定。URL が HTTPS URL の場合は、[トンネル] オプションが使用されます。URL が HTTP URL の場合、[なし] オプションが使用されます。
- 常に: 接続は常に SSL 対応です。
- なし: 接続は SSL に対応していません。
- トンネル: 接続はトンネリング プロキシ経由で行われます。プロキシ サーバーがリモートホストへの接続を開き、トラフィックはプロキシを経由するようになります。
- [Proxy Server] セクションで、プロキシ サーバーの詳細を入力します。
- [+ 宛先を追加] をクリックします。
- [宛先の種類] を選択します。
- ホストアドレス: 宛先のホスト名または IP アドレスを指定します。
バックエンドへのプライベート接続を確立する場合は、次のようにします。
- PSC サービス アタッチメントを作成します。
- エンドポイント アタッチメントを作成し、続いて [Host address] フィールドにあるエンドポイント アタッチメントの詳細を入力します。
- ホストアドレス: 宛先のホスト名または IP アドレスを指定します。
- [NEXT] をクリックします。
ノードは、トランザクションを処理する接続の単位(またはレプリカ)です。1 つの接続でより多くのトランザクションを処理するには、より多くのノードが必要になります。逆に、より少ないトランザクションを処理するには、より少ないノードが必要になります。ノードがコネクタの料金に与える影響については、 接続ノードの料金をご覧ください。値を入力しない場合は、デフォルトで最小ノード数は 2 に設定され(可用性を高めるため)、最大ノード数は 50 に設定されます。
-
[認証] セクションで、認証の詳細を入力します。
- OAuth 2.0 による認証 - 認証コードで認証するか、認証なしで続行するかを選択します。
認証の構成方法については、認証を構成するをご覧ください。
- [NEXT] をクリックします。
- OAuth 2.0 による認証 - 認証コードで認証するか、認証なしで続行するかを選択します。
- 接続と認証の詳細を確認し、[作成] をクリックします。
認証を構成する
使用する認証に基づいて詳細を入力します。
- 認証なし: 認証が不要な場合は、このオプションを選択します。
- OAuth 2.0 - 認証コード: ウェブベースのユーザー ログインフローを使用して認証する場合は、このオプションを選択します。次の詳細を指定します。
- クライアント ID: バックエンド Google サービスに接続するために必要なクライアント ID。
- スコープ: 必要なスコープのカンマ区切りのリスト。必要な Google サービスでサポートされている OAuth 2.0 スコープを確認するには、Google API の OAuth 2.0 スコープ ページの関連セクションをご覧ください。
- クライアント シークレット: Secret Manager のシークレットを選択します。 この認証を構成する前に、Secret Manager のシークレットを作成しておく必要があります。
- シークレットのバージョン: クライアント シークレットの Secret Manager シークレットのバージョン。
Authorization code 認証タイプの場合は、接続を作成した後、接続を承認する必要があります。
接続を承認する
OAuth 2.0 - 認証コードを使用して接続を認証する場合は、接続の作成後に次のタスクを完了します。
- 接続ページで、新しく作成された接続を見つけます。
新しいコネクタの [ステータス] は [承認が必要] になります。
- [承認が必要] をクリックします。
これにより、[承認の編集] ペインが表示されます。
- [リダイレクト URI] の値を外部アプリケーションにコピーします。
- 認可の詳細を確認します。
- [Authorize(承認)] をクリックします。
認可が成功すると、[接続] ページの接続ステータスが「有効」に設定されます。
認証コードの再認可
Authorization code 認証タイプを使用しているユーザーが、BigQuery の構成を変更した場合は、BigQuery 接続を再認証する必要があります。接続を再認可するには、次の手順を行います。
統合で BigQuery 接続を使用する
接続を作成すると、Apigee Integration と Application Integration の両方で使用できるようになります。この接続は、コネクタタスクを介して統合で使用できます。
- Apigee Integration で Connectors タスクを作成して使用する方法については、Connectors タスクをご覧ください。
- Application Integration で Connectors タスクを作成して使用する方法については、Connectors タスクをご覧ください。
操作
このセクションでは、BigQuery コネクタで使用可能なアクションについて説明します。
すべてのエンティティ オペレーションとアクションの結果は、統合を実行した後に JSON レスポンスとして Connectors タスクの connectorOutputPayload レスポンス パラメータとして利用できます。
CancelJob アクション
このアクションを使用すると、実行中の BigQuery ジョブをキャンセルできます。
次の表では、CancelJob アクションの入力パラメータを示します。
| パラメータ名 | データ型 | 説明 |
|---|---|---|
| JobId | 文字列 | キャンセルするジョブの ID。このフィールドは必須です。 |
| リージョン | 文字列 | ジョブが現在実行されているリージョン。ジョブが米国または EU リージョンの場合、必須ではありません。 |
GetJob アクション
このアクションを使用すると、既存のジョブの構成情報と実行状態を取得できます。
次の表では、GetJob アクションの入力パラメータを示します。
| パラメータ名 | データ型 | 説明 |
|---|---|---|
| JobId | 文字列 | 構成を取得するジョブの ID。このフィールドは必須です。 |
| リージョン | 文字列 | ジョブが現在実行されているリージョン。ジョブが米国または EU リージョンの場合、必須ではありません。 |
InsertJob アクション
このアクションを使用すると、BigQuery ジョブを挿入できます。その後、ジョブを選択してクエリ結果を取得できます。
次の表では、InsertJob アクションの入力パラメータを示します。
| パラメータ名 | データ型 | 説明 |
|---|---|---|
| クエリ | 文字列 | BigQuery に送信するクエリ。このフィールドは必須です。 |
| IsDML | 文字列 | クエリが DML ステートメントの場合は true に設定し、それ以外の場合は false に設定します。デフォルト値は false です。 |
| DestinationTable | 文字列 | クエリの宛先テーブル(DestProjectId:DestDatasetId.DestTable 形式)。 |
| WriteDisposition | 文字列 | 宛先テーブルにデータを書き込む方法を指定します。既存の結果を切り捨てる、既存の結果を追加する、テーブルが空の場合にのみ書き込みを行うなどです。サポートされている値は次のとおりです。
|
| DryRun | 文字列 | ジョブの実行がドライランかどうかを指定します。 |
| MaximumBytesBilled | 文字列 | ジョブで処理できる最大バイト数を指定します。ジョブが指定された値を超えるバイト数を処理しようとすると、BigQuery はジョブをキャンセルします。 |
| 地域 | 文字列 | ジョブを実行するリージョンを指定します。 |
InsertLoadJob アクション
このアクションを使用すると、Google Cloud Storage から既存のテーブルにデータを追加する BigQuery 読み込みジョブを挿入できます。
次の表では、InsertLoadJob アクションの入力パラメータを示します。
| パラメータ名 | データ型 | 説明 |
|---|---|---|
| SourceURIs | 文字列 | Google Cloud Storage URI のスペース区切りのリスト。 |
| SourceFormat | 文字列 | ファイルのソース形式。サポートされている値は次のとおりです。
|
| DestinationTable | 文字列 | クエリの宛先テーブル(DestProjectId.DestDatasetId.DestTable 形式)。 |
| DestinationTableProperties | 文字列 | テーブルのわかりやすい名前、説明、ラベルのリストを指定する JSON オブジェクト。 |
| DestinationTableSchema | 文字列 | テーブルの作成に使用されるフィールドを指定する JSON リスト。 |
| DestinationEncryptionConfiguration | 文字列 | テーブルの KMS 暗号化設定を指定する JSON オブジェクト。 |
| SchemaUpdateOptions | 文字列 | 宛先テーブルのスキーマを更新するときに適用するオプションを指定する JSON リスト。 |
| TimePartitioning | 文字列 | 時間パーティショニングのタイプとフィールドを指定する JSON オブジェクト。 |
| RangePartitioning | 文字列 | 範囲パーティショニングのフィールドとバケットを指定する JSON オブジェクト。 |
| クラスタリング | 文字列 | クラスタリングに使用するフィールドを指定する JSON オブジェクト。 |
| 自動検出 | 文字列 | JSON ファイルと CSV ファイルのオプションとスキーマを自動的に決定するかどうかを指定します。 |
| CreateDisposition | 文字列 | 宛先テーブルが存在しない場合に宛先テーブルを作成する必要があるかどうかを指定します。サポートされている値は次のとおりです。
|
| WriteDisposition | 文字列 | 宛先テーブルにデータを書き込む方法を指定します。既存の結果を切り捨てる、既存の結果を追加する、テーブルが空の場合にのみ書き込みを行うなどです。サポートされている値は次のとおりです。
|
| 地域 | 文字列 | ジョブを実行するリージョンを指定します。Google Cloud Storage リソースと BigQuery データセットは同じリージョンに存在する必要があります。 |
| DryRun | 文字列 | ジョブの実行がドライランかどうかを指定します。デフォルト値は false です。 |
| MaximumBadRecords | 文字列 | ジョブ全体がキャンセルされる前に無効であることが許容されるレコードの数を指定します。デフォルトでは、すべてのレコードが有効である必要があります。デフォルト値は 0 です。 |
| IgnoreUnknownValues | 文字列 | 入力ファイルで不明なフィールドを無視するか、エラーとして扱うかを指定します。デフォルトではエラーとして扱われます。デフォルト値は false です。 |
| AvroUseLogicalTypes | 文字列 | AVRO のデータ型を BigQuery 型に変換するために AVRO 論理型を使用する必要があるかどうかを指定します。デフォルト値は true です。 |
| CSVSkipLeadingRows | 文字列 | CSV ファイルの先頭でスキップする行数を指定します。通常、ヘッダー行をスキップするために使用されます。 |
| CSVEncoding | 文字列 | CSV ファイルのエンコード タイプ。サポートされている値は次のとおりです。
|
| CSVNullMarker | 文字列 | 指定された場合、この文字列は CSV ファイル内の NULL 値に使用されます。デフォルトでは、CSV ファイルで NULL を使用できません。 |
| CSVFieldDelimiter | 文字列 | CSV ファイル内の列を区切るために使用される文字。デフォルト値はカンマ(,)です。 |
| CSVQuote | 文字列 | CSV ファイルの引用符で囲まれたフィールドに使用する文字。引用を無効にするために空に設定できます。デフォルト値は二重引用符(")です。 |
| CSVAllowQuotedNewlines | 文字列 | CSV ファイルに引用符で囲まれたフィールド内で改行を含めることができるかどうかを指定します。デフォルト値は false です。 |
| CSVAllowJaggedRows | 文字列 | CSV ファイルに欠落しているフィールドを含めることができるかどうかを指定します。デフォルト値は false です。 |
| DSBackupProjectionFields | 文字列 | Cloud Datastore バックアップから読み込むフィールドの JSON リスト。 |
| ParquetOptions | 文字列 | Parquet 固有のインポート オプションを指定する JSON オブジェクト。 |
| DecimalTargetTypes | 文字列 | 数値型に適用される優先順位を示す JSON リスト。 |
| HivePartitioningOptions | 文字列 | ソース側のパーティショニング オプションを指定する JSON オブジェクト。 |
カスタム SQL クエリを実行する
カスタムクエリを作成する手順は次のとおりです。
- 詳細な手順に沿って、コネクタタスクを追加します。
- コネクタタスクを構成するときに、実行するアクションの種類で [Actions] を選択します。
- [Actions] リストで [Execute custom query] を選択し、[Done] をクリックします。
- [Task input] セクションを開き、次の操作を行います。
- [タイムアウト後] フィールドに、クエリが実行されるまで待機する秒数を入力します。
デフォルト値:
180秒 - [Maximum number of rows] フィールドに、データベースから返される最大行数を入力します。
デフォルト値:
25。 - カスタムクエリを更新するには、[Edit Custom Script] をクリックします。[Script editor] ダイアログが開きます。
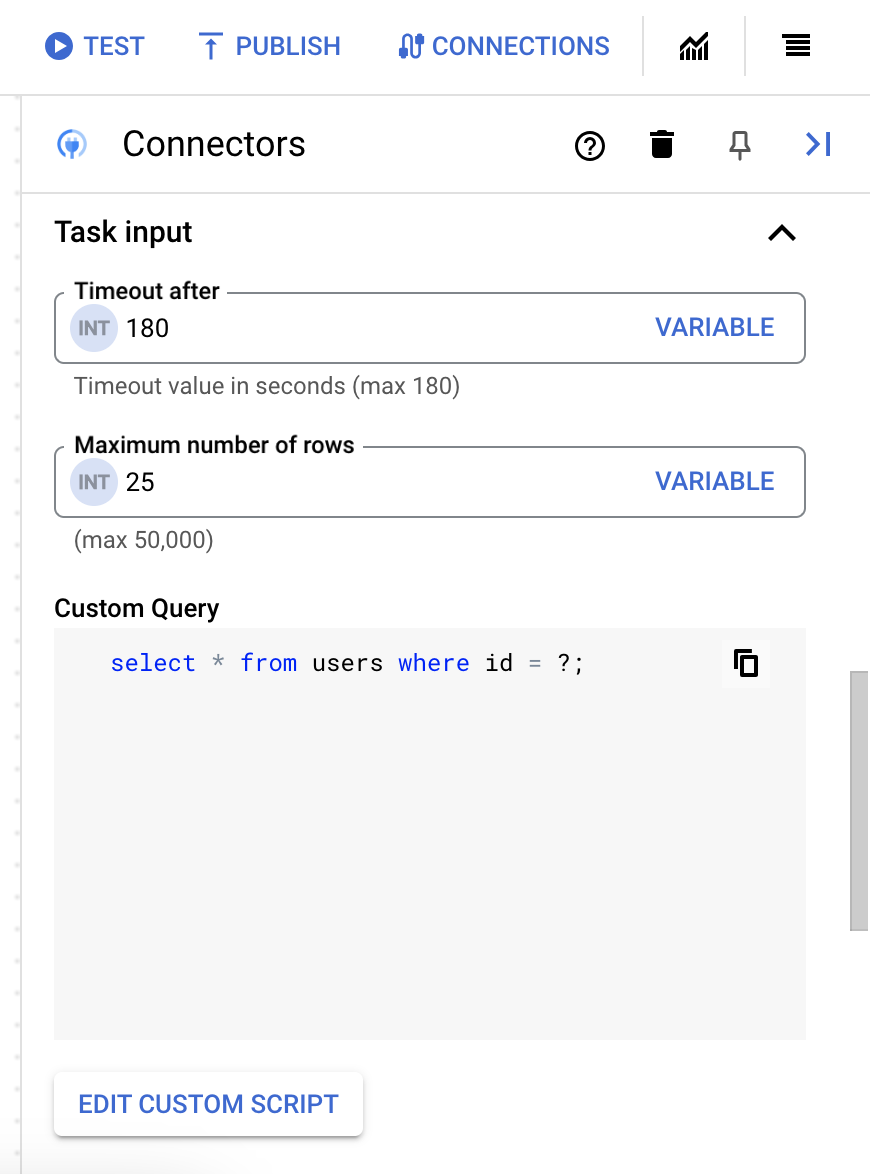
- [Script editor] ダイアログで、SQL クエリを入力して [Save] をクリックします。
SQL ステートメントで疑問符(?)を使用して、クエリ パラメータ リストで指定する必要がある 1 つのパラメータを表すことができます。たとえば、次の SQL クエリは、
LastName列に指定された値と一致するEmployeesテーブルからすべての行を選択します。SELECT * FROM Employees where LastName=?
- SQL クエリで疑問符を使用した場合は、各疑問符の [+ パラメータ名を追加] をクリックして、パラメータを追加する必要があります。統合の実行中に、これらのパラメータにより SQL クエリ内の疑問符(?)が順番に置き換わります。たとえば、3 つの疑問符(?)を追加した場合、3 つのパラメータを順番に追加する必要があります。
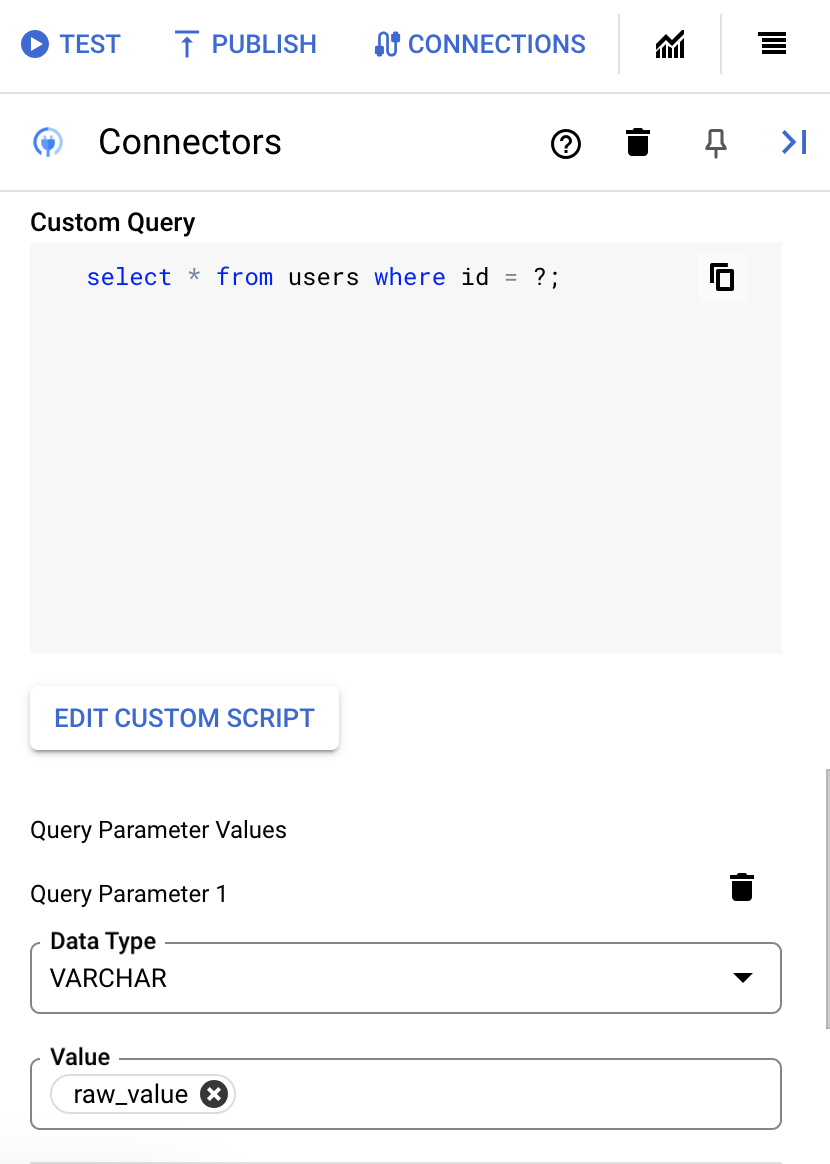
クエリ パラメータを追加する手順は次のとおりです。
- [Type] リストから、パラメータのデータ型を選択します。
- [Value] フィールドに、パラメータの値を入力します。
- 複数のパラメータを追加するには、[+ クエリ パラメータを追加] をクリックします。
カスタムクエリの実行アクションは、配列変数をサポートしていません。
- [タイムアウト後] フィールドに、クエリが実行されるまで待機する秒数を入力します。
Terraform を使用して接続を作成する
Terraform リソースを使用して、新しい接続を作成できます。
Terraform 構成を適用または削除する方法については、基本的な Terraform コマンドをご覧ください。
接続作成用の Terraform テンプレートのサンプルを表示するには、サンプル テンプレートをご覧ください。
Terraform を使用してこの接続を作成する場合は、Terraform 構成ファイルで次の変数を設定する必要があります。
| パラメータ名 | データ型 | 必須 | 説明 |
|---|---|---|---|
| project_id | STRING | True | BigQuery データセットを含むプロジェクトの ID(例: myproject)。 |
| dataset_id | STRING | False | プロジェクト名のない BigQuery データセットのデータセット ID(例: mydataset)。 |
| proxy_enabled | BOOLEAN | False | 接続用のプロキシ サーバーを構成するには、このチェックボックスをオンにします。 |
| proxy_auth_scheme | ENUM | False | ProxyServer プロキシへの認証に使用する認証タイプです。サポートされている値は、BASIC、DIGEST、NONE です。 |
| proxy_user | STRING | False | ProxyServer プロキシへの認証に使用されるユーザー名です。 |
| proxy_password | SECRET | False | ProxyServer プロキシの認証に使用されるパスワード。 |
| proxy_ssltype | ENUM | False | ProxyServer プロキシへの接続時に使用する SSL のタイプです。サポートされている値は AUTO、ALWAYS、NEVER、TUNNEL です。 |
システムの上限
BigQuery コネクタは、ノードごとに 1 秒あたり最大 8 件のトランザクションを処理することができ、この上限を超えるトランザクションはすべてスロットルされます。 デフォルトでは、Integration Connectors は、接続に 2 つのノードを割り当てます(可用性を高めるため)。
Integration Connectors に適用される上限の詳細については、上限をご覧ください。
サポートされているデータ型
このコネクタでサポートされているデータ型は次のとおりです。
- ARRAY
- BIGINT
- BINARY
- BIT
- BOOLEAN
- CHAR
- DATE
- DECIMAL
- DOUBLE
- FLOAT
- INTEGER
- LONGN VARCHAR
- LONG VARCHAR
- NCHAR
- NUMERIC
- NVARCHAR
- REAL
- SMALL INT
- TIME
- TIMESTAMP
- TINY INT
- VARBINARY
- VARCHAR
既知の制限事項
-
BigQuery コネクタは、BigQuery テーブルの主キーをサポートしていません。つまり、
entityIdを使用してエンティティ オペレーションを取得、更新、削除することはできません。または、フィルタ句を使用して、ID に基づいてレコードをフィルタリングすることもできます。 -
初めてデータを取得するときに、約 6 秒の初期レイテンシが発生する場合があります。キャッシュ保存により、後続のリクエストではレイテンシが発生しません。このレイテンシは、キャッシュの有効期限が切れると再発する可能性があります。
Google Cloud コミュニティの助けを借りる
Google Cloud コミュニティの Cloud フォーラムで質問を投稿したり、このコネクタについてディスカッションしたりできます。
次のステップ
- 接続を一時停止して再開する方法を確認する。
- コネクタの使用状況をモニタリングする方法を確認する。
- コネクタログを表示する方法を確認する。