Nesta página, descrevemos suas opções de alta disponibilidade (HA, na sigla em inglês) em clusters do Anthos no VMware (GKE On-Prem), como configurar determinados clusters do Anthos em componentes no VMware para alta disponibilidade e como se recuperar de desastres.
Principal recurso
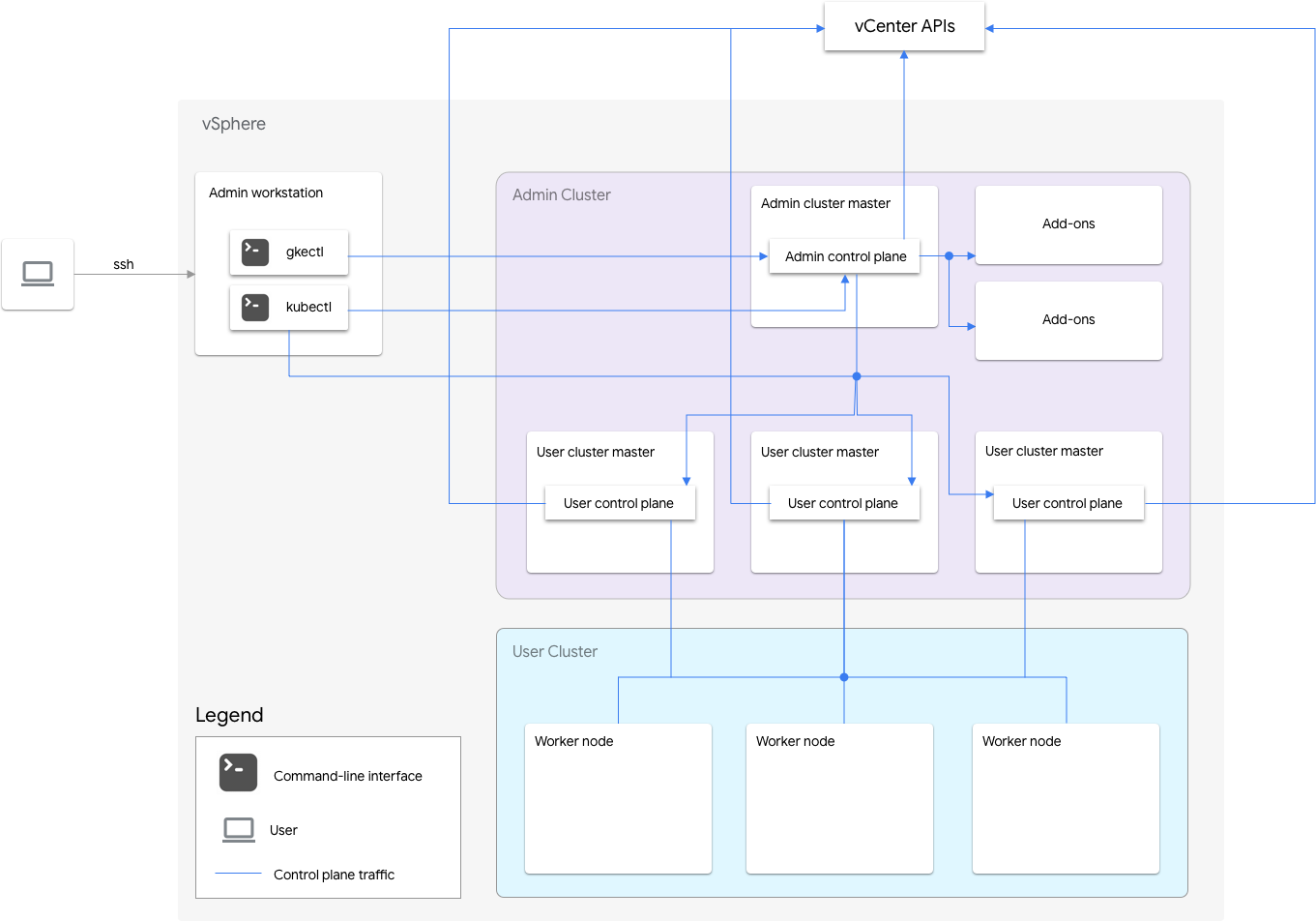
Os clusters do Anthos no VMware incluem um cluster de administrador e um ou mais clusters de usuário.
O cluster de administrador gerencia o ciclo de vida dos clusters de usuários, incluindo a criação, atualizações, upgrades e exclusão de clusters. No cluster de administração, o mestre do administrador gerencia os nós de worker de administrador, que incluem mestres do usuário (nós que executam o plano de controle dos clusters de usuários gerenciados) e nós de complemento (nós que executam os componentes do complemento compatíveis com o funcionalidade do cluster de administração).
Para cada cluster de usuário, o cluster de administrador tem um nó não HA ou três nós de alta disponibilidade que executam o plano de controle. O plano de controle inclui o servidor da API Kubernetes, o programador do Kubernetes, o gerenciador do controlador do Kubernetes e vários controles críticos para o cluster do usuário.
A disponibilidade do plano de controle do cluster de usuários é essencial para operações de carga de trabalho, como criação, escalonamento, redução e encerramento. Em outras palavras, uma interrupção do plano de controle não interfere nas cargas de trabalho em execução. No entanto, as cargas de trabalho atuais perdem os recursos de gerenciamento do servidor da API Kubernetes se o plano de controle estiver ausente.
As cargas de trabalho e os serviços em contêineres são implantados nos nós de trabalho do cluster de usuários. Nenhum nó de trabalho único é essencial para a disponibilidade do aplicativo, desde que seja implantado com pods redundantes programados em vários nós de trabalho.
O GKE On-Prem foi projetado para garantir que as falhas sejam isoladas em uma área funcional o máximo possível e a fim de priorizar a funcionalidade essencial para a continuidade do negócio.
As principais funcionalidades dos clusters do Anthos no VMware têm as seguintes categorias:
Ciclo de vida do aplicativo
As cargas de trabalho atuais podem ser executadas continuamente. Essa é a funcionalidade mais importante para garantir a continuidade dos negócios.
Crie, atualize e exclua cargas de trabalho. Essa é a segunda funcionalidade mais importante porque os clusters do Anthos no VMware precisam escalonar as cargas de trabalho quando o tráfego aumenta.
Ciclo de vida do cluster do usuário
É possível adicionar, atualizar, fazer upgrade e excluir clusters de usuários. Isso é menos importante porque a incapacidade de modificar clusters de usuário não afeta as cargas de trabalho do usuário.
Ciclo de vida do cluster do administrador
Atualize e faça upgrade do cluster de administração. Isso é menos importante porque o cluster de administrador não hospeda nenhuma carga de trabalho do usuário.
Modos de falha
Os seguintes tipos de falhas podem afetar o desempenho dos clusters do Anthos nos clusters do VMware.
Falha no host ESXi
Um host do ESXi que executa instâncias de máquina virtual (VM) que hospedam nós do Kubernetes pode parar de funcionar ou ser particionado pela rede.
| Cargas de trabalho atuais | Como criar, atualizar e excluir cargas de trabalho | Ciclo de vida do cluster do usuário | Ciclo de vida do cluster do administrador |
|---|---|---|---|
| Possível interrupção + recuperação automática |
Possível interrupção + recuperação automática |
Interrupção + recuperação automática |
Interrupção + recuperação automática |
Os pods em execução nas VMs hospedadas pelo host com falha são interrompidos e reprogramados automaticamente em outras VMs em bom estado. Se os aplicativos do usuário tiverem capacidade de carga de trabalho disponível e estiverem distribuídos entre vários nós, a interrupção não será observável por clientes que implementam novas tentativa. |
Se a falha do host afetar a VM do plano de controle em um cluster de usuário sem alta disponibilidade ou mais de uma VM de plano de controle em um cluster de usuário de alta disponibilidade, haverá interrupções. | Se a falha do host afetar a VM do plano de controle ou as VMs do worker no cluster de administrador, haverá interrupções. | Se a falha do host afetar a VM do plano de controle no cluster de administrador, haverá interrupções. |
| O vSphere HA reinicia automaticamente as VMs em hosts em bom estado. | O vSphere HA reinicia automaticamente as VMs em hosts em bom estado. | O vSphere HA reinicia automaticamente as VMs em hosts em bom estado. | O vSphere HA reinicia automaticamente as VMs em hosts em bom estado. |
| Implante as cargas de trabalho com HA para minimizar a possibilidade de interrupção. | Use clusters de usuários de alta disponibilidade para minimizar a possibilidade de interrupção. |
Falha na VM
Uma VM pode ser excluída inesperadamente ou um disco de inicialização pode ser corrompido. Além disso, uma VM pode ser comprometida devido a problemas no sistema operacional.
| Cargas de trabalho atuais | Como criar, atualizar e excluir cargas de trabalho | Ciclo de vida do cluster do usuário | Ciclo de vida do cluster do administrador |
|---|---|---|---|
| Possível interrupção + recuperação automática |
Possível interrupção + recuperação automática |
Interrupção + recuperação automática manual |
Interrupção + recuperação manual |
Os pods em execução nas VMs de worker com falha são interrompidos e são reprogramados automaticamente em outras VMs íntegras pelo Kubernetes. Se os aplicativos do usuário tiverem capacidade de carga de trabalho disponível e estiverem distribuídos entre vários nós, a interrupção não será observável por clientes que implementam novas tentativas. |
Se a VM do plano de controle em um cluster de usuário sem alta disponibilidade ou mais de uma VM de plano de controle em um cluster de usuário de alta disponibilidade falhar, haverá interrupção. | Se a VM do plano de controle ou as VMs do worker no cluster de administrador falharem, haverá interrupções. | Se a VM do plano de controle no cluster de administrador falhar, haverá interrupções. |
| A VM com falha é recuperada automaticamente se o reparo automático de nó estiver ativado no cluster de usuário. | A VM com falha é recuperada automaticamente se o reparo automático de nós estiver ativado no cluster de administrador. | A VM de worker com falha no cluster de administrador será recuperada automaticamente se o reparo automático de nós estiver ativado no cluster de administrador. Para recuperar a VM do plano de controle do cluster do administrador, consulte Como reparar a VM do plano de controle do cluster de administrador. |
Para recuperar a VM do plano de controle do cluster do administrador, consulte Como reparar a VM do plano de controle do cluster de administrador. |
| Implante as cargas de trabalho com HA para minimizar a possibilidade de interrupção. | Use clusters de usuários de alta disponibilidade para minimizar a possibilidade de interrupção. |
Falha no armazenamento
O conteúdo em um arquivo VMDK pode ser corrompido devido à diminuição da potência de uma VM ou a uma falha no armazenamento de dados fazer com que dados etcd e PersistentVolumes (PVs) sejam perdidos.
Falha no etcd
| Cargas de trabalho atuais | Como criar, atualizar e excluir cargas de trabalho | Ciclo de vida do cluster do usuário | Ciclo de vida do cluster do administrador |
|---|---|---|---|
| Sem interrupção | Possível interrupção + recuperação manual |
Interrupção + recuperação manual |
Interrupção + recuperação manual |
| Se o armazenamento do etcd em um cluster de usuário que não seja de alta disponibilidade ou mais de uma réplica do etcd em um cluster de usuário de alta disponibilidade falharem, haverá interrupção. | Se o armazenamento do etcd em um cluster de usuário que não seja de alta disponibilidade ou mais de uma réplica do etcd em um cluster de usuário de alta disponibilidade falharem, haverá interrupção. Se a réplica do etcd em um cluster de administrador falhar, haverá interrupções. |
Se a réplica do etcd em um cluster de administrador falhar, haverá interrupções. | |
| Os clusters do Anthos no VMware fornecem um processo manual para se recuperar da falha. | Os clusters do Anthos no VMware fornecem um processo manual para recuperação da falha. | Os clusters do Anthos no VMware fornecem um processo manual para recuperação da falha. |
Falha no PV do aplicativo do usuário
| Cargas de trabalho atuais | Como criar, atualizar e excluir cargas de trabalho | Ciclo de vida do cluster do usuário | Ciclo de vida do cluster do administrador |
|---|---|---|---|
| Possível interrupção | Sem interrupção | Sem interrupção | Sem interrupção |
As cargas de trabalho que usam o PV com falha são afetadas. Implante as cargas de trabalho com HA para minimizar a possibilidade de interrupção. |
Falha do balanceador de carga
Uma falha no balanceador de carga pode afetar as cargas de trabalho do usuário que expõem serviços do
tipo LoadBalancer.
| Cargas de trabalho atuais | Como criar, atualizar e excluir cargas de trabalho | Ciclo de vida do cluster do usuário | Ciclo de vida do cluster do administrador |
|---|---|---|---|
| Interrupção + recuperação manual |
|||
|
Há alguns segundos de interrupção até que o balanceador de carga em espera recupere a conexão VIP do plano de controle do administrador. A interrupção do serviço pode ser de até dois segundos ao usar o Seesaw e até 300 segundos ao usar F5. A alta disponibilidade detecta a falha automaticamente e faz o failover para a utilização da instância de backup. Os clusters do Anthos no VMware fornecem um processo manual para recuperação de uma falha de Seesaw. |
|||
Como ativar a alta disponibilidade
Os clusters do vSphere e do Anthos no VMware fornecem uma série de recursos que contribuem para alta disponibilidade (HA, na sigla em inglês).
vSphere HA e vMotion
Recomendamos a ativação dos dois recursos a seguir no cluster do vCenter que hospeda os clusters do Anthos nos clusters da VMware:
Esses recursos melhoram a disponibilidade e a recuperação caso um host ESXi falhe.
O vCenter com alta disponibilidade usa vários hosts ESXi configurados como um cluster para fornecer recuperação
rápida de interrupções e alta disponibilidade econômica para aplicativos
executados em máquinas virtuais. Recomendamos que você provisione seu cluster
do vCenter com hosts extras e ative o
Monitoramento de host de alta disponibilidade do vSphere
com Host Failure Response definido como Restart VMs. Assim, as VMs poderão ser
reiniciadas automaticamente em outros hosts disponíveis em caso de falha do host do ESXi.
O vMotion permite migração em tempo real e sem inatividade de VMs de um host ESXi para outro. Para a manutenção planejada do host, use a vMotion disponibilização em tempo real para evitar a inatividade do aplicativo e garantir a continuidade dos negócios.
Cluster de administrador
Os clusters do Anthos no VMware não são compatíveis com a execução de vários planos de controle para o cluster de administrador. No entanto, a indisponibilidade do plano de controle do administrador não afeta a funcionalidade do cluster de usuário atual nem as cargas de trabalho em execução nos clusters de usuários.
Há dois nós complementares em um cluster de administrador. Se um deles estiver inativo, o outro
ainda poderá fornecer as operações de cluster de administrador. Para redundância, os clusters do Anthos no VMware espalham os serviços de complementos críticos, como kube-dns, nos dois nós do complemento.
Se você definir antiAffinityGroups.enabled como true no arquivo de configuração
do cluster de administração, o GKE On-Prem criará
automaticamente as regras de antiafinidade vSphere DRS
para o nó do suplemento, que fazem com que eles sejam distribuídos por
dois hosts físicos para alta disponibilidade.
Cluster de usuário
É possível ativar a alta disponibilidade para um cluster de usuário ao definir masterNode.replicas como 3 no
arquivo de configuração do cluster de usuário. Isso resulta em três nós no cluster do
administrador, cada um executando um plano de controle para o cluster do usuário. Cada
um desses nós também executa uma réplica do etcd. O cluster do usuário continua funcionando,
desde que haja um plano de controle em execução e um quórum do etcd. Um quórum
do etcd exige que duas das três réplicas do etcd estejam funcionando.
Se você definir antiAffinityGroups.enabled como true no arquivo
de configuração do cluster de administração, o GKE On-Prem criará automaticamente as regras de antiafinidade do vSphere DRS
para os três nós que executam o plano de controle do cluster do usuário.
Isso faz com que essas VMs sejam distribuídas em três hosts físicos.
O GKE On-Prem também cria regras antiafinidade do vSphere DRS para os nós de trabalho no seu cluster de usuário, o que faz com que esses nós sejam distribuídos por pelo menos três hosts físicos. Várias regras antiafinidade do DRS são usadas por pool de nós de cluster de usuário com base no número de nós. Isso garante que os nós de trabalho encontrem hosts para serem executados, mesmo quando o número de hosts for menor que o número de VMs no pool de nós do cluster de usuário. Recomendamos que você inclua hosts físicos extras no cluster do vCenter. Além disso, configure o DRS para ser totalmente automatizado. Assim, se um host ficar indisponível, o DRS poderá reiniciar automaticamente as VMs em outros hosts disponíveis sem violar as regras de antiafinidade da VM.
Os clusters do Anthos no VMware mantêm um rótulo de nó especial, onprem.gke.io/failure-domain-name, que tem um valor definido como o nome do host subjacente do ESXi. Os aplicativos do usuário que querem alta disponibilidade podem configurar
regras podAntiAffinity com este rótulo como o topologyKey para garantir que
seus pods de aplicativo estejam distribuídos em diferentes VMs e hosts físicos.
Também é possível configurar vários pools de nós para um cluster de usuário com armazenamentos
de dados diferentes e rótulos de nós especiais. Da mesma forma, é possível configurar regras podAntiAffinity
com esse rótulo de nó especial como topologyKey para ter uma disponibilidade maior
após falhas do armazenamento de dados.
Para ter alta disponibilidade para cargas de trabalho do usuário, verifique se o cluster de usuário tem um número
suficiente de réplicas em nodePools.replicas. Isso garantirá o número pretendido de nós de trabalho do cluster de usuário
na condição de execução.
É possível usar armazenamentos de dados separados para clusters de administrador e clusters de usuários para isolar as falhas deles.
Balanceador de carga
Há dois tipos de balanceadores de carga que podem ser usados para alta disponibilidade.
Balanceador de carga da Seesaw em pacote
Para o
balanceador de carga da Seesaw em pacote,
é possível ativar a alta disponibilidade ao definir
loadBalancer.seesaw.enableHA como true no arquivo de configuração do cluster.
Também é preciso ativar uma combinação de aprendizado MAC, transmissões forjadas
e modo variado no grupo de portas do balanceador de carga.
Com a alta disponibilidade, dois balanceadores de carga são configurados em modo ativo-passivo. Se o balanceador de carga ativo tiver um problema, o tráfego fará o failover para o balanceador de carga passivo.
Durante o upgrade de um balanceador de carga, há um tempo de inatividade. Se a alta disponibilidade estiver ativada no balanceador de carga, o tempo máximo de inatividade será de dois segundos.
Balanceador de carga com F5 BIG-IP integrado
A plataforma F5 BIG-IP oferece diversos Serviços para você melhorar a segurança, a disponibilidade e o desempenho dos seus aplicativos. Para clusters do Anthos no VMware, o BIG-IP fornece acesso externo e serviços de balanceamento de carga L3/4.
Para mais informações, consulte Alta disponibilidade do BIG-IP.
Como recuperar um cluster corrompido
Veja nas seções a seguir como recuperar um cluster corrompido.
Recuperação de falhas de host ESXi
O GKE On-Prem utiliza o vSphere com alta disponibilidade para recuperar uma falha de host ESXi. O vSphere com alta disponibilidade pode monitorar continuamente os hosts ESXi e reiniciar as VMs automaticamente em outros hosts quando necessário. Isso é transparente para os clusters do Anthos em usuários do VMware.
Recuperação de falhas de VM
As falhas de VM podem incluir o seguinte:
Exclusão inesperada de uma VM.
Corrupção do disco de inicialização da VM. Por exemplo, um disco de inicialização se tornou somente leitura devido a registros de diário de spam.
Falha na inicialização da VM devido a problemas de configuração do disco ou de desempenho. Por exemplo, uma VM não pode ser inicializada porque não foi possível alocar um endereço IP para ela por algum motivo.
Corrupção do sistema do arquivo de sobreposição do Docker.
Perda de VM de plano de controle de administrador devido a uma falha de upgrade.
Problemas no sistema operacional.
As falhas de VM discutidas nesta seção não incluem corrupção de dados/perda no disco de dados PV ou etcd anexados à VM. Para isso, consulte Recuperação de falhas de armazenamento.
Os clusters do Anthos no VMware fornecem um mecanismo de recuperação automática para os nós de complementos, planos de controle de usuário e nós de usuários. Esse recurso de reparo automático de nós pode ser ativado por cluster de administrador e pelo cluster do usuário.
A VM do plano de controle do administrador é especial porque não é gerenciada por um cluster do Kubernetes. Além disso, sua disponibilidade não afeta a continuidade dos negócios. Para a recuperação de falhas de VM do plano de controle do administrador, entre em contato com o Suporte do Google.
Recuperação de falhas de armazenamento
Algumas das falhas de armazenamento podem ser atenuadas pelo vSphere HA e vv sem afetar os clusters do Anthos no VMware. No entanto, algumas falhas de armazenamento podem ocorrer no nível do vSphere causando corrupção ou perda de dados em vários clusters do Anthos em componentes do VMware.
As informações com estado de um cluster e cargas de trabalho do usuário são armazenadas nos seguintes locais:
etcd
Cada cluster (cluster de administrador e cluster de usuário) tem um banco de dados etcd que armazena o estado (objetos do Kubernetes) do cluster.
Volumes permanentes
É usado por componentes do sistema e cargas de trabalho do usuário.
Recuperação de corrupção/perda de dados do etcd
O etcd é o banco de dados usado pelo Kubernetes para armazenar todo o estado do cluster, inclusive o manifesto do aplicativo do usuário. As operações de ciclo de vida do aplicativo seriam interrompidas se o banco de dados do etcd do cluster do usuário fossem corrompido ou perdido. As operações do ciclo de vida do cluster do usuário pararam de funcionar se o banco de dados etcd do cluster de administrador estava corrompido ou perdido.
O etcd não fornece um mecanismo integrado confiável para detectar corrupção de dados. Será preciso analisar os registros dos pods do etcd se você suspeitar que os dados do etcd estão corrompidos ou perdidos.
Um pod do etcd pendente/error/crash-looping nem sempre significa que os dados do etcd estão corrompidos ou perdidos. Isso pode ocorrer devido a erros nas VMs que hospedam os pods do etcd. Execute a recuperação do etcd a seguir somente para corrupção ou perda de dados.
Para conseguir se recuperar (em um estado de cluster recente) da corrupção ou perda de dados do etcd, é preciso fazer o backup dos dados do etcd após qualquer operação de ciclo de vida no cluster (por exemplo, criar, atualizar ou fazer upgrade). Para fazer backup dos dados do etcd, consulte Como fazer backup de um cluster de administrador e Como fazer backup de um cluster de usuário.
Como restaurar dados do etcd transforma o cluster em um estado anterior. Em outras palavras, se um backup for feito antes de um aplicativo ser implantado e esse backup for usado para restaurar o cluster, o aplicativo não será executado no cluster restaurado. Por exemplo, se você usar o snapshot do etcd de um cluster de administrador que é criado antes da criação de um cluster de usuário, o plano de administração restaurado terá o plano de controle do cluster do usuário. Portanto, recomendamos fazer backup do cluster após cada operação de cluster essencial.
A falha de corrupção/perda de dados do etcd pode ocorrer nos seguintes cenários:
Um único nó de um cluster do etcd (cluster de HA) é permanentemente interrompido devido à corrupção ou perda de dados. Nesse caso, apenas um nó é interrompido e o quórum do etcd ainda existe. Isso pode acontecer em um cluster de alta disponibilidade, em que os dados de uma das réplicas do etcd são corrompidos ou perdidos. O problema pode ser corrigido sem a perda de dados por meio da substituição da réplica do etcd com falha por uma nova em estado limpo. Para mais informações, consulte Como substituir uma réplica do etcd com falha.
Dois nós de um cluster de três nós do etcd (cluster de usuário de alta disponibilidade) são permanentemente corrompidos devido à corrupção ou perda de dados. O quórum é perdido, portanto, a substituição das réplicas do etcd com falhas por novas não ajuda. O estado do cluster precisa ser restaurado dos dados de backup. Para mais informações, consulte Como restaurar um cluster de usuário de um backup (HA).
Um cluster do etcd de nó único (cluster de administrador ou cluster de usuário sem alta disponibilidade) é permanentemente corrompido devido à corrupção ou perda de dados. O quórum é perdido, então é preciso criar um novo cluster com base no backup. Para mais informações, consulte Como restaurar um cluster de usuário de um backup (sem alta disponibilidade).
Recuperação da perda ou perda do PV de aplicativo do usuário
Os clusters do Anthos em clientes VMware podem usar determinadas soluções de armazenamento de parceiros para fazer backup e restaurar PersistentVolumes de aplicativos do usuário.
Para ver a lista de parceiros de armazenamento qualificados para clusters do Anthos no VMware, consulte os parceiros de armazenamento Ready do Anthos (em inglês).
Recuperação de falhas do balanceador de carga
Para o balanceamento de carga agrupado (Seesaw), é possível se recuperar de falhas ao recriar o balanceador de carga. Para recriar o balanceador de carga, faça o upgrade da Seekaw para a mesma versão, conforme mostrado em Como fazer upgrade do balanceador de carga para seu cluster de administrador.
No caso de falhas do balanceador de carga do cluster do administrador, é possível que o plano de controle esteja fora de alcance. Como resultado, você precisa executar o upgrade na VM do plano de controle do administrador onde há acesso ao plano de controle.
Para balanceadores de carga integrados (F5), consulte o suporte da F5.
Como usar vários clusters para recuperação de desastres
A implantação de aplicativos em vários clusters em várias plataformas vCenters ou Anthos pode fornecer maior disponibilidade global e limitar o raio de alcance durante as interrupções.
Essa configuração usa o cluster do Anthos atual no data center secundário para recuperação de desastres, em vez de configurar um novo cluster. Veja a seguir um resumo completo para conseguir isso:
Crie outro cluster de administrador e um cluster de usuário no data center secundário. Nesta arquitetura de vários clusters, é necessário que os usuários tenham dois clusters de administrador em cada data center, e cada cluster de administrador executa um cluster de usuário.
O cluster de usuário secundário tem um número mínimo de nós de trabalho (três) e está em espera ativa (sempre em execução).
As implantações de aplicativos podem ser replicadas nos dois vCenters usando o Anthos Config Management, ou a abordagem preferida é usar um conjunto de ferramentas de DevOps de aplicativos (CI/CD, Spinnaker) atual.
No caso de um desastre, o cluster de usuário pode ser redimensionado para o número de nós.
Além disso, é necessário fazer uma alternância de DNS para rotear o tráfego entre os clusters para o data center secundário.