En este documento, se muestra cómo probar y supervisar el rendimiento de la entrega en línea de los modelos de aprendizaje automático (AA) que se implementan en AI Platform Prediction. En el documento, se usa Locust, una herramienta de código abierto para pruebas de carga.
El documento está dirigido a científicos de datos y a ingenieros de MLOps que deseen supervisar la carga de trabajo del servicio, la latencia y el uso de recursos de los modelos de AA en producción.
En el documento, se supone que tienes experiencia con Google Cloud, TensorFlow, AI Platform Prediction, Cloud Monitoring y los notebooks de Jupyter.
El documento está acompañado de un repositorio de GitHub que incluye el código y una guía de implementación para implementar el sistema que se describe en este documento. Las tareas se incorporan a los notebooks de Jupyter.
Costos
Los notebooks con los que trabajas en este documento usan los siguientes componentes facturables de Google Cloud:
- Notebooks administrados por el usuario de Vertex AI Workbench
- AI Platform Prediction
- Cloud Storage
- Cloud Monitoring
- Google Kubernetes Engine (GKE)
Para generar una estimación de costos en función del uso previsto, usa la calculadora de precios.
Antes de comenzar
- Sign in to your Google Cloud account. If you're new to Google Cloud, create an account to evaluate how our products perform in real-world scenarios. New customers also get $300 in free credits to run, test, and deploy workloads.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
-
Make sure that billing is enabled for your Google Cloud project.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
-
Make sure that billing is enabled for your Google Cloud project.
Descripción general de la arquitectura
En el siguiente diagrama, se muestra la arquitectura del sistema a fin de implementar el modelo de AA para la predicción en línea, ejecutar la prueba de carga, y recopilar y analizar las métricas del rendimiento de entrega del modelo de AA.
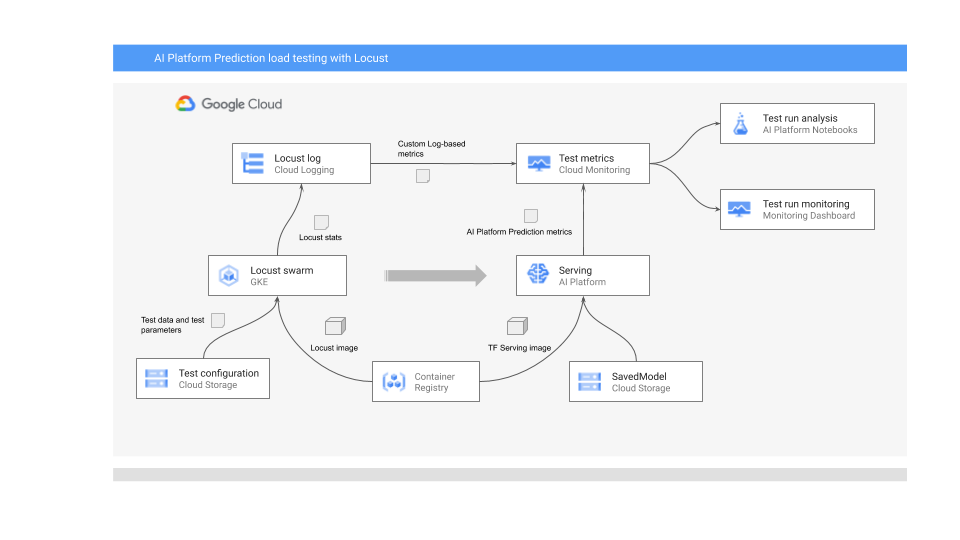
En el diagrama, se muestra el siguiente flujo:
- El modelo entrenado podría estar en Cloud Storage, por ejemplo, un modelo guardado de TensorFlow o scikit-learn joblib. Como alternativa, puede incorporarse en un contenedor de entrega personalizado en Container Registry, por ejemplo, TorchServe para entregar modelos de PyTorch.
- El modelo se implementa en AI Platform Prediction como una API de REST. AI Platform Prediction es un servicio completamente administrado para la entrega de modelos que admite diferentes tipos de máquinas, ajuste de escala automático según el uso de recursos y varios aceleradores de GPU.
- Locust se usa para implementar una tarea de prueba (es decir, el comportamiento del usuario). Para ello, llama al modelo de AA que se implementa en AI Platform Prediction y lo ejecuta a gran escala en Google Kubernetes Engine (GKE). Esto simula muchas llamadas de usuario simultáneas para probar la carga del servicio de predicción del modelo. Puedes supervisar el progreso de las pruebas con la interfaz web de Locust.
- Locust registra las estadísticas de prueba en Cloud Logging. Las entradas de registro que crea la prueba de Locust se usan para definir un conjunto de métricas basadas en registros en Cloud Monitoring. Estas métricas complementan las métricas estándar de AI Platform Prediction.
- Las métricas de AI Platform y las métricas personalizadas de Locust están disponibles para su visualización en un panel de Cloud Monitoring en tiempo real. Una vez que finaliza la prueba, las métricas también se recopilan de manera programática para que puedas analizar y visualizar las métricas en notebooks administrados por el usuario de Vertex AI Workbench.
Los notebooks de Jupyter para esta situación
Todas las tareas para preparar e implementar el modelo, ejecutar la prueba de Locust, y recopilar y analizar los resultados de la prueba se codifican en los siguientes notebooks de Jupyter. Para realizar las tareas, ejecuta la secuencia de celdas en cada notebook.
01-prepare-and-deploy.ipynb. Debes ejecutar este notebook a fin de preparar un modelo guardado de TensorFlow para entregarlo y, luego, implementarlo en AI Platform Prediction.02-perf-testing.ipynb. Ejecuta este notebook a fin de crear métricas basadas en registros en Cloud Monitoring para la prueba de Locust y, luego, implementar la prueba de Locust en GKE y ejecutarla.03-analyze-results.ipynb. Ejecuta este notebook para recopilar y analizar los resultados de la prueba de carga de Locust a partir de las métricas estándar de AI Platform que crea Cloud Monitoring y desde métricas personalizadas de Locust.
Inicializa tu entorno
Como se describe en el archivo README.md del repositorio de GitHub asociado, debes realizar los siguientes pasos para preparar el entorno para ejecutar los notebooks:
- En tu proyecto de Google Cloud, crea un bucket de Cloud Storage, que es necesario para almacenar el modelo entrenado y la configuración de prueba de Locust. Toma nota del nombre que usas para el bucket, ya que lo necesitarás más adelante.
- Crea un lugar de trabajo de Cloud Monitoring en tu proyecto.
- Crea un clúster de Google Kubernetes Engine que tenga las CPUs necesarias. El grupo de nodos debe tener acceso a las API de Cloud.
- Crea una instancia de notebooks administrados por el usuario de Vertex AI Workbench que use TensorFlow 2. Para este instructivo, no necesitas GPU porque no entrenas el modelo. (Las GPU pueden ser útiles en otras situaciones, en particular para acelerar el entrenamiento de los modelos).
Abre JupyterLab
Para revisar las tareas de la situación, debes abrir el entorno de JupyterLab y obtener los notebooks.
En la consola de Google Cloud, ve a la página Notebooks.
En la pestaña Notebooks administrados por el usuario, haz clic en Abrir Jupyterlab junto al entorno del notebook que creaste.
Esto abrirá el entorno de JupyterLab en el navegador.
Para iniciar una pestaña de la terminal, haz clic en el ícono de Terminal en la pestaña Selector.
En la terminal, clona el repositorio de GitHub
mlops-on-gcp:git clone https://github.com/GoogleCloudPlatform/mlops-on-gcp.gitCuando el comando finalice, verás la carpeta
mlops-on-gcpen el navegador de archivos. En esa carpeta, verás los notebooks con los que trabajas en este documento.
Establece la configuración del notebook
En esta sección, configurarás variables en los notebooks con valores específicos de tu contexto y prepararás el entorno para ejecutar el código de la situación.
- Navega al directorio
model_serving/caip-load-testing. - Para cada uno de los tres notebooks, haz lo siguiente:
- Abre el notebook.
- Ejecuta las celdas en Establece la configuración del entorno de Google Cloud.
En las secciones siguientes, se destacan partes clave del proceso, y se explican aspectos del diseño y el código.
Entrega el modelo de predicción en línea
El modelo de AA que se usa en este documento usa el modelo de clasificación de imágenes ResNet V2 101 previamente entrenado de TensorFlow Hub. Sin embargo, puedes adaptar los patrones y las técnicas de diseño del sistema de este documento a otros dominios y a otros tipos de modelos.
El código para preparar y entregar el modelo ResNet 101 se encuentra en el notebook 01-prepare-and-deploy.ipynb. Ejecuta las celdas del notebook para realizar las siguientes tareas:
- Descargar y ejecutar el modelo ResNet desde TensorFlow Hub.
- Crear firmas de entrega para el modelo.
- Exportar el modelo como modelo guardado
- Implementar el modelo guardado en AI Platform Prediction.
- Validar el modelo implementado.
En las siguientes secciones de este documento, se proporcionan detalles sobre cómo preparar el modelo ResNet y cómo implementarlo.
Prepara el modelo ResNet para la implementación
El modelo ResNet de TensorFlow Hub no tiene firmas de entrega porque está optimizado para la recomposición y el ajuste. Por lo tanto, debes crear firmas de entrega para el modelo a fin de que este pueda entregarlo en el caso de las predicciones en línea.
Además, para entregar el modelo, recomendamos que incorpores la lógica de ingeniería de atributos en la interfaz de entrega. Esto garantiza la afinidad entre el procesamiento previo y la entrega del modelo, en lugar de depender de la aplicación cliente para el procesamiento previo de los datos en el formato requerido. También debes incluir el procesamiento posterior en la interfaz de entrega, como convertir un ID de clase en una etiqueta de clase.
Para que el modelo ResNet se pueda entregar, debes implementar firmas de entrega que describan los métodos de inferencia del modelo. Por lo tanto, el código del notebook agrega dos firmas:
- La firma predeterminada. Esta firma expone el método
predictpredeterminado del modelo ResNet V2 101. El método predeterminado no tiene lógica de procesamiento previo ni posterior. - Firma de procesamiento previo y posterior. Las entradas esperadas para esta interfaz requieren un procesamiento previo relativamente complejo, lo que incluye la codificación, el escalamiento y la normalización de la imagen. Por lo tanto, el modelo también expone una firma alternativa que incorpora la lógica de procesamiento previo y posterior. En esta firma, se aceptan imágenes sin procesar y se muestra la lista de etiquetas de clase clasificadas y las probabilidades de las etiquetas asociadas.
Las firmas se crean en una clase de módulo personalizado. La clase se deriva de la clase base tf.Module que encapsula el modelo ResNet. La clase personalizada extiende la clase base con un método que implementa la lógica de procesamiento previo de imágenes y de procesamiento posterior. El método predeterminado del módulo personalizado se asigna al método predeterminado del modelo ResNet base para mantener la interfaz análoga. El módulo personalizado se exporta como un modelo guardado que incluye el modelo original, la lógica de procesamiento previo y dos firmas de entrega.
La implementación de la clase del módulo personalizado se muestra en el siguiente fragmento de código:
LABELS_KEY = 'labels'
PROBABILITIES_KEY = 'probabilities'
NUM_LABELS = 5
class ServingModule(tf.Module):
"""
A custom tf.Module that adds image preprocessing and output post processing to
a base TF 2 image classification model from TensorFlow Hub.
"""
def __init__(self, base_model, input_size, output_labels):
super(ServingModule, self).__init__()
self._model = base_model
self._input_size = input_size
self._output_labels = tf.constant(output_labels, dtype=tf.string)
def _decode_and_scale(self, raw_image):
"""
Decodes, crops, and resizes a single raw image.
"""
image = tf.image.decode_image(raw_image, dtype=tf.dtypes.uint8, expand_animations=False)
image_shape = tf.shape(image)
image_height = image_shape[0]
image_width = image_shape[1]
crop_size = tf.minimum(image_height, image_width)
offset_height = ((image_height - crop_size) + 1) // 2
offset_width = ((image_width - crop_size) + 1) // 2
image = tf.image.crop_to_bounding_box(image, offset_height, offset_width, crop_size, crop_size)
image = tf.image.resize(image, [self._input_size, self._input_size])
image = tf.cast(image, tf.uint8)
return image
def _preprocess(self, raw_inputs):
"""
Preprocesses raw inputs as sent by the client.
"""
# A mitigation for https://github.com/tensorflow/tensorflow/issues/28007
with tf.device('/cpu:0'):
images = tf.map_fn(self._decode_and_scale, raw_inputs, dtype=tf.uint8)
images = tf.image.convert_image_dtype(images, tf.float32)
return images
def _postprocess(self, model_outputs):
"""
Postprocess outputs returned by the base model.
"""
probabilities = tf.nn.softmax(model_outputs)
indices = tf.argsort(probabilities, axis=1, direction='DESCENDING')
return {
LABELS_KEY: tf.gather(self._output_labels, indices, axis=-1)[:,:NUM_LABELS],
PROBABILITIES_KEY: tf.sort(probabilities, direction='DESCENDING')[:,:NUM_LABELS]
}
@tf.function(input_signature=[tf.TensorSpec([None, 224, 224, 3], tf.float32)])
def __call__(self, x):
"""
A pass-through to the base model.
"""
return self._model(x)
@tf.function(input_signature=[tf.TensorSpec([None], tf.string)])
def predict_labels(self, raw_images):
"""
Preprocesses inputs, calls the base model
and postprocess outputs from the base model.
"""
# Call the preprocessing handler
images = self._preprocess(raw_images)
# Call the base model
logits = self._model(images)
# Call the postprocessing handler
outputs = self._postprocess(logits)
return outputs
serving_module = ServingModule(model, 224, imagenet_labels)
En el siguiente fragmento de código, se muestra cómo se exporta el modelo como un modelo guardado con las firmas activas que se definieron antes:
...
default_signature = serving_module.__call__.get_concrete_function()
preprocess_signature = serving_module.predict_labels.get_concrete_function()
signatures = {
'serving_default': default_signature,
'serving_preprocess': preprocess_signature
}
tf.saved_model.save(serving_module, model_path, signatures=signatures)
Implementa el modelo en AI Platform Prediction
Cuando el modelo se exporta como un modelo guardado, se realizan las siguientes tareas:
- El modelo se sube a Cloud Storage.
- Se crea un objeto de modelo en AI Platform Prediction.
- Se crea una versión del modelo para el modelo guardado.
En el siguiente fragmento de código del notebook, se muestran los comandos que realizan estas tareas.
gcloud storage cp {model_path} {GCS_MODEL_LOCATION} --recursive
gcloud ai-platform models create {MODEL_NAME} \
--project {PROJECT_ID} \
--regions {REGION}
MACHINE_TYPE='n1-standard-8'
ACCELERATOR='count=1,type=nvidia-tesla-p4'
gcloud beta ai-platform versions create {MODEL_VERSION} \
--model={MODEL_NAME} \
--origin={GCS_MODEL_LOCATION} \
--runtime-version=2.1 \
--framework=TENSORFLOW \
--python-version=3.7 \
--machine-type={MACHINE_TYPE} \
--accelerator={ACCELERATOR} \
--project={PROJECT_ID}
El comando crea un tipo de máquina n1-standard-8 para el servicio de predicción del modelo junto con un acelerador de GPU nvidia-tesla-p4.
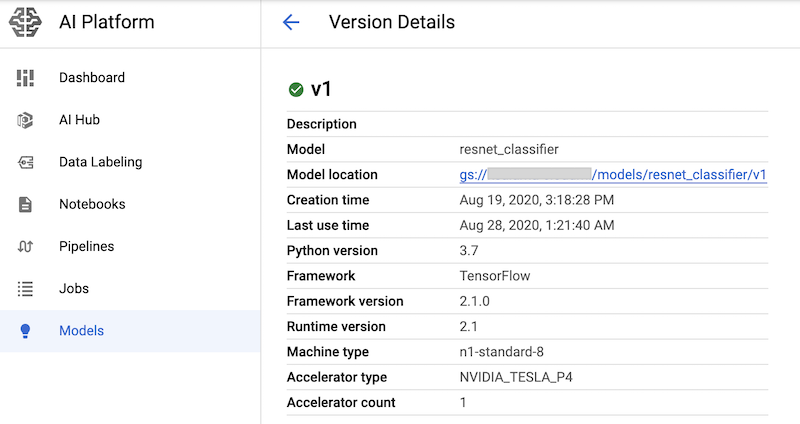
Después de ejecutar las celdas de notebook que tienen estos comandos, puedes verificar que la versión del modelo se haya implementado si la visualizas en la página Modelos de AI Platform de la consola de Google Cloud. El resultado es similar a este:
Crea métricas de Cloud Monitoring
Una vez que el modelo esté configurado para la entrega, puedes configurar métricas que te permitan supervisar su rendimiento. El código para configurar las métricas se encuentra en el notebook 02-perf-testing.ipynb.
La primera parte del notebook 02-perf-testing.ipynb crea métricas personalizadas basadas en registros en Cloud Monitoring mediante el SDK de Cloud Logging para Python.
Las métricas se basan en las entradas de registro que generó la tarea de Locust.
El método log_stats escribe las entradas de registro en un registro de Cloud Logging llamado locust.
Cada entrada de registro incluye un conjunto de pares clave-valor en formato JSON, como se muestra en la siguiente tabla. Las métricas se basan en el subconjunto de claves de la entrada de registro.
| Clave | Descripción del valor | Uso |
|---|---|---|
test_id
|
El ID de una prueba | Filtrar atributos |
model |
El nombre del modelo de AI Platform Prediction | |
model_version |
La versión del modelo de AI Platform Prediction | |
latency
|
El tiempo de respuesta del percentil 95, que se calcula en una ventana deslizante de 10 segundos | Valores de la métrica |
num_requests |
La cantidad total de solicitudes desde que comenzó la prueba | |
num_failures |
La cantidad total de errores desde que comenzó la prueba | |
user_count |
La cantidad de usuarios simulados | |
rps |
Las solicitudes por segundo |
En el siguiente fragmento de código, se muestra la función create_locust_metric en el notebook que crea una métrica personalizada basada en registros.
def create_locust_metric(
metric_name:str,
log_path:str,
value_field:str,
bucket_bounds:List[int]):
metric_path = logging_client.metric_path(PROJECT_ID, metric_name)
log_entry_filter = 'resource.type=global AND logName={}'.format(log_path)
metric_descriptor = {
'metric_kind': 'DELTA',
'value_type': 'DISTRIBUTION',
'labels': [{'key': 'test_id', 'value_type': 'STRING'},
{'key': 'signature', 'value_type': 'STRING'}]}
bucket_options = {
'explicit_buckets': {'bounds': bucket_bounds}}
value_extractor = 'EXTRACT(jsonPayload.{})'.format(value_field)
label_extractors = {
'test_id': 'EXTRACT(jsonPayload.test_id)',
'signature': 'EXTRACT(jsonPayload.signature)'}
metric = logging_v2.types.LogMetric(
name=metric_name,
filter=log_entry_filter,
value_extractor=value_extractor,
bucket_options=bucket_options,
label_extractors=label_extractors,
metric_descriptor=metric_descriptor,
)
try:
logging_client.get_log_metric(metric_path)
print('Metric: {} already exists'.format(metric_path))
except:
logging_client.create_log_metric(parent, metric)
print('Created metric {}'.format(metric_path))
En el siguiente fragmento de código, se muestra cómo se invoca el método create_locust_metric en el notebook para crear las cuatro métricas personalizadas de Locust que se muestran en la tabla anterior.
# user count metric
metric_name = 'locust_users'
value_field = 'user_count'
bucket_bounds = [1, 16, 32, 64, 128]
create_locust_metric(metric_name, log_path, value_field, bucket_bounds)
# latency metric
metric_name = 'locust_latency'
value_field = 'latency'
bucket_bounds = [1, 50, 100, 200, 500]
create_locust_metric(metric_name, log_path, value_field, bucket_bounds)
# failure count metric
metric_name = 'num_failures'
value_field = 'num_failures'
bucket_bounds = [1, 1000]
create_locust_metric(metric_name, log_path, value_field, bucket_bounds)
# request count metric
metric_name = 'num_requests'
value_field = 'num_requests'
bucket_bounds = [1, 1000]
create_locust_metric(metric_name, log_path, value_field, bucket_bounds)
El notebook crea un panel personalizado de Cloud Monitoring llamado AI Platform Prediction y Locust. En el panel, se combinan las métricas estándar de AI Platform Prediction y las métricas personalizadas que se crean en función de los registros de Locust.
Para obtener más información, consulta la documentación de la API de Cloud Logging.
Este panel y sus gráficos se pueden crear de forma manual.
Sin embargo, el notebook proporciona una forma programática de crearla con la plantilla JSON monitoring-template.json. El código usa la clase DashboardsServiceClient para cargar la plantilla JSON y crear el panel en Cloud Monitoring, como se muestra en el siguiente fragmento de código:
parent = 'projects/{}'.format(PROJECT_ID)
dashboard_template_file = 'monitoring-template.json'
with open(dashboard_template_file) as f:
dashboard_template = json.load(f)
dashboard_proto = Dashboard()
dashboard_proto = ParseDict(dashboard_template, dashboard_proto)
dashboard = dashboard_service_client.create_dashboard(parent, dashboard_proto)
Después de crear el panel, podrás verlo en la lista de paneles de Cloud Monitoring en la consola de Google Cloud:
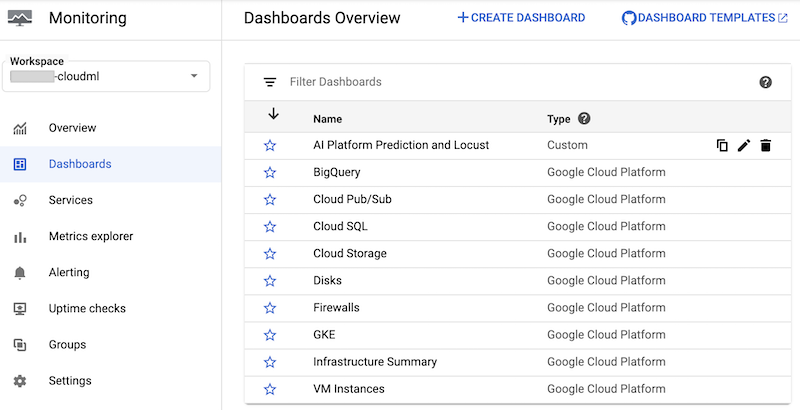
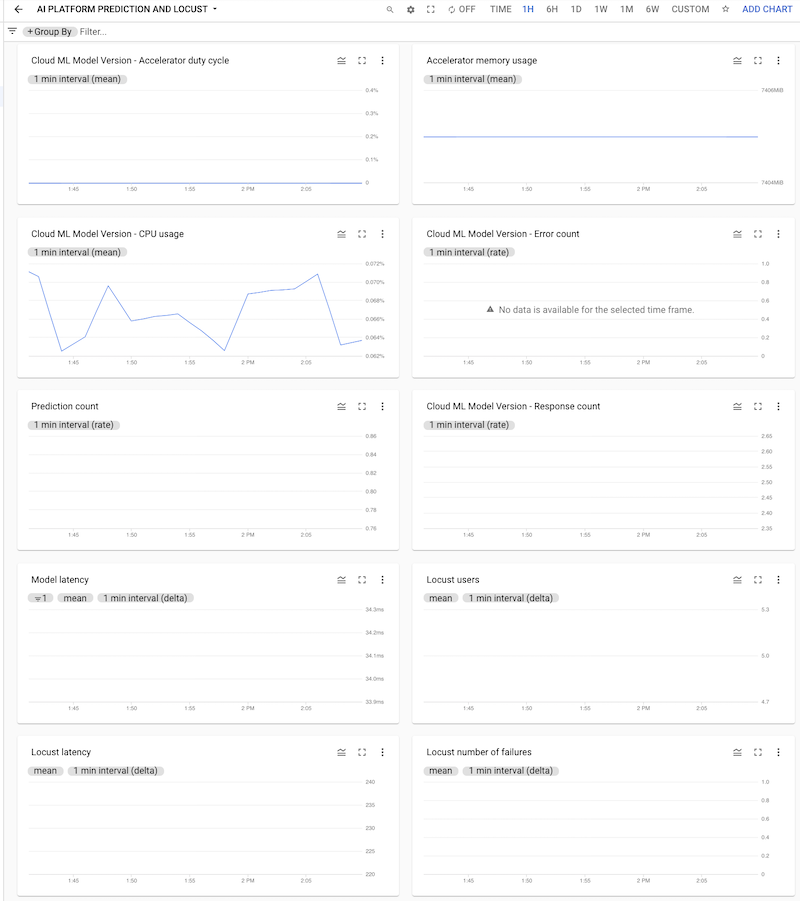
Puedes hacer clic en el panel para abrirlo y ver los gráficos. En cada gráfico, se muestra una métrica de AI Platform Prediction o de los registros de Locust, como se muestra en las siguientes capturas de pantalla.
Implementa la prueba de Locust en el clúster de GKE
Antes de implementar el sistema de Locust en GKE, debes compilar la imagen de contenedor de Docker que contiene la lógica de prueba integrada en el archivo task.py. La imagen deriva de la imagen baseline locust.io y se usa para los Pods trabajadores y principales de Locust.
La lógica para compilar y, luego, implementar se encuentra en el notebook, en 3. Implementa Locust en un clúster de GKE. La imagen se compila con el siguiente código:
image_uri = 'gcr.io/{}/locust'.format(PROJECT_ID)
!gcloud builds submit --tag {image_uri} locust/locust-image
El proceso de implementación que se describe en el notebook se definió con Kustomize. Los manifiestos de la implementación de Locust Kustomize definen los siguientes archivos que definen los componentes:
locust-master. Este archivo define una implementación que aloja una interfaz web en la que inicias la prueba y ves las estadísticas activas.locust-worker. Este archivo define una implementación que ejecuta una tarea para probar la carga de tu servicio de predicción del modelo de AA. Por lo general, se crean varios trabajadores para simular el efecto de varios usuarios simultáneos que realizan llamadas a la API del servicio de predicción.locust-worker-service. Este archivo define un servicio que accede a la interfaz web enlocust-mastera través de un balanceador de cargas de HTTP.
Debes actualizar el manifiesto predeterminado antes de implementar el clúster. El manifiesto predeterminado consta de los archivos kustomization.yaml y patch.yaml. Debes realizar cambios en ambos archivos.
En el archivo kustomization.yaml, haz lo siguiente:
- Establece el nombre de la imagen de Locust personalizada. Configura el campo
newNameen la secciónimagescon el nombre de la imagen personalizada que compilaste antes. - De manera opcional, establece la cantidad de Pods de trabajadores. La configuración predeterminada implementa 32 Pods de trabajadores. Para cambiar el número, modifica el campo
counten la secciónreplicas. Asegúrate de que tu clúster de GKE tenga una cantidad suficiente de CPU para los trabajadores de Locust. - Establece el bucket de Cloud Storage para la configuración de prueba y los archivos de carga útil. En la sección
configMapGenerator, asegúrate de que estén establecidos los siguientes valores:LOCUST_TEST_BUCKET: Configura esto con el nombre del bucket de Cloud Storage que creaste antes.LOCUST_TEST_CONFIG. Establece esto en el nombre del archivo de configuración de prueba. En el archivo YAML, esto se configura entest-config.json, pero puedes cambiarlo si deseas usar un nombre diferente.LOCUST_TEST_PAYLOAD. Establece esto en el nombre del archivo de carga útil de prueba. En el archivo YAML, esto se configura entest-payload.json, pero puedes cambiarlo si deseas usar un nombre diferente.
En el archivo patch.yaml, haz lo siguiente:
- De manera opcional, modifica el grupo de nodos que aloja el principal y los trabajadores de Locust. Si implementas la carga de trabajo de Locust en un grupo de nodos que no sea
default-pool, busca la secciónmatchExpressionsy, luego, envalues, actualiza el nombre del grupo de nodos en la que se implementará la carga de trabajo de Locust.
Después de realizar estos cambios, puedes compilar tus personalizaciones en los manifiestos de Kustomize y aplicar la implementación de Locust (locust-master, locust-worker y locust-master-service) al clúster de GKE. El siguiente comando en el notebook realiza estas tareas:
!kustomize build locust/manifests | kubectl apply -f -
Puedes verificar las cargas de trabajo implementadas en la consola de Google Cloud. El resultado es similar a este:
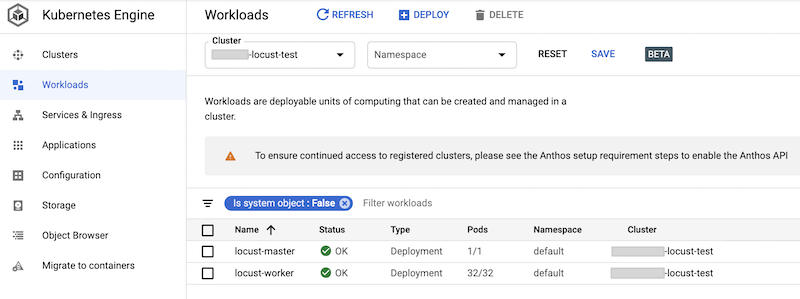
Implementa la prueba de carga de Locust
La tarea de prueba de Locust es llamar al modelo que se implementa en AI Platform Prediction.
Esta tarea se implementa en la clase AIPPClient en el módulo task.py que se encuentra en la carpeta /locust/locust-image/. En el siguiente fragmento de código, se muestra la implementación de la clase.
class AIPPClient(object):
"""
A convenience wrapper around AI Platform Prediction REST API.
"""
def __init__(self, service_endpoint):
logging.info(
"Setting the AI Platform Prediction service endpoint: {}".format(service_endpoint))
credentials, _ = google.auth.default()
self._authed_session = AuthorizedSession(credentials)
self._service_endpoint = service_endpoint
def predict(self, project_id, model, version, signature, instances):
"""
Invokes the predict method on the specified signature.
"""
url = '{}/v1/projects/{}/models/{}/versions/{}:predict'.format(
self._service_endpoint, project_id, model, version)
request_body = {
'signature_name': signature,
'instances': instances
}
response = self._authed_session.post(url, data=json.dumps(request_body))
return response
La clase AIPPUser del archivo task.py hereda de la clase locust.User para simular el comportamiento del usuario de llamar al modelo de AI Platform Prediction. Este comportamiento se implementa en el método predict_task. El método on_start de la clase AIPPUser descarga los siguientes archivos de un bucket de Cloud Storage que se especifica en la variable LOCUST_TEST_BUCKET del archivo task.py:
test-config.json. En este archivo JSON, se incluyen las siguientes configuraciones para la prueba:test_id,project_id,modelyversion.test-payload.json: Este archivo JSON incluye las instancias de datos en el formato que espera AI Platform Prediction, junto con la firma de destino.
El código para preparar los datos de prueba y la configuración de prueba se incluye en el notebook 02-perf-testing.ipynb, en 4. Configura una prueba de Locust.
Las configuraciones de prueba y las instancias de datos se usan como parámetros para el método predict en la clase AIPPClient a fin de probar el modelo de destino con los datos de prueba requeridos. El AIPPUser
simula un tiempo de espera de 1 a 2 segundos entre las llamadas de un solo usuario.
Ejecuta la prueba de Locust
Después de ejecutar las celdas del notebook para implementar la carga de trabajo de Locust en el clúster de GKE, y después de crear y, luego, subir los archivos test-config.json y test-payload.json a Cloud Storage, haz lo siguiente: puede iniciar, detener y configurar una prueba de carga de Locust nueva mediante su interfaz web.
El código del notebook recupera la URL del balanceador de cargas externo que expone la interfaz web mediante el siguiente comando:
%%bash
IP_ADDRESS=$(kubectl get service locust-master | awk -v col=4 'FNR==2{print $col}')
echo http://$IP_ADDRESS:8089
Para realizar la prueba, haz lo siguiente:
- En un navegador, ingresa la URL que recuperaste.
Para simular la carga de trabajo de prueba mediante diferentes opciones de configuración, ingresa valores en la interfaz de Locust, que es similar a lo siguiente:
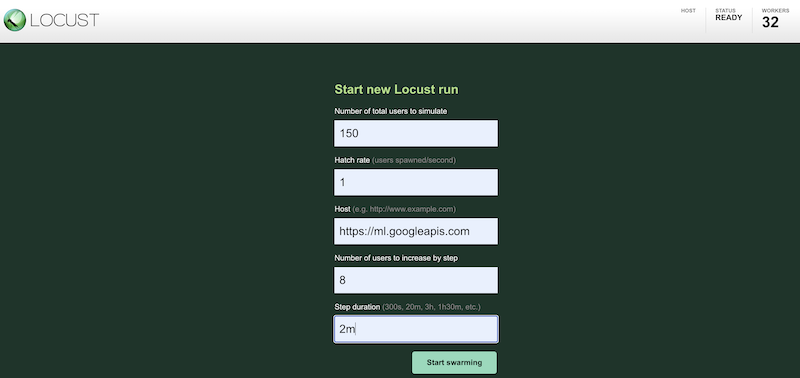
En la captura de pantalla anterior, se muestran los siguientes valores de configuración:
- Cantidad de usuarios totales que se deben simular:
150 - Tasa de generación:
1 - Host:
http://ml.googleapis.com - Cantidad de usuarios que aumentará por paso:
10 - Duración del paso:
2m
- Cantidad de usuarios totales que se deben simular:
A medida que la prueba se ejecuta, puedes examinar los gráficos de Locust para supervisar la prueba. En las siguientes capturas de pantalla, se muestra cómo se visualizan los valores.
En un gráfico, se muestra la cantidad total de solicitudes por segundo:
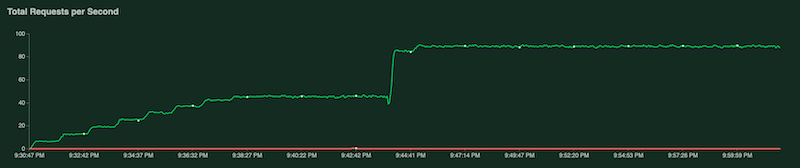
En otro gráfico, se muestra el tiempo de respuesta en milisegundos:
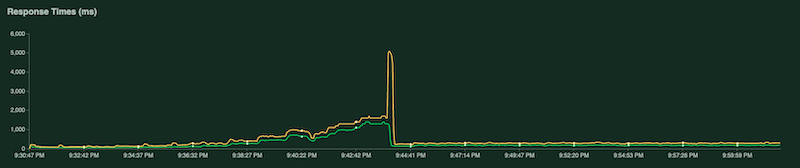
Como se mencionó antes, estas estadísticas también se registran en Cloud Logging para que puedas crear métricas personalizadas basadas en registros de Cloud Monitoring.
Recopila y analiza los resultados de la prueba
La siguiente tarea es recopilar y analizar las métricas de Cloud Monitoring que se calculan a partir de los registros de resultados como un objeto DataFrame de Pandas para que puedas visualizar y analizar los resultados en el notebook. El código para realizar esta tarea está en el notebook 03-analyze-results.ipynb.
El código usa el SDK de Python de consulta de Cloud Monitoring para filtrar y recuperar los valores de métrica, según los valores que se pasan en los parámetros project_id, test_id, start_time, end_time, model, model_version y log_name.
En el siguiente fragmento de código, se muestran los métodos que recuperan las métricas de AI Platform Prediction y las métricas personalizadas basadas en registros de Locust.
import pandas as pd
from google.cloud.monitoring_v3.query import Query
def _get_aipp_metric(metric_type: str, labels: List[str]=[], metric_name=None)-> pd.DataFrame:
"""
Retrieves a specified AIPP metric.
"""
query = Query(client, project_id, metric_type=metric_type)
query = query.select_interval(end_time, start_time)
query = query.select_resources(model_id=model)
query = query.select_resources(version_id=model_version)
if metric_name:
labels = ['metric'] + labels
df = query.as_dataframe(labels=labels)
if not df.empty:
if metric_name:
df.columns.set_levels([metric_name], level=0, inplace=True)
df = df.set_index(df.index.round('T'))
return df
def _get_locust_metric(metric_type: str, labels: List[str]=[],
metric_name=None)-> pd.DataFrame:
"""
Retrieves a specified custom logs-based metric.
"""
query = Query(client, project_id, metric_type=metric_type)
query = query.select_interval(end_time, start_time)
query = query.select_metrics(log=log_name)
query = query.select_metrics(test_id=test_id)
if metric_name:
labels = ['metric'] + labels
df = query.as_dataframe(labels=labels)
if not df.empty:
if metric_name:
df.columns.set_levels([metric_name], level=0, inplace=True)
df = df.apply(lambda row: [metric.mean for metric in row])
df = df.set_index(df.index.round('T'))
return df
Los datos de las métricas se recuperan como un objeto DataFrame de Pandas para cada métrica. Los marcos de datos individuales se combinan en un solo objeto DataFrame. El objeto final DataFrame con los resultados combinados se ve de la siguiente manera en tu notebook:
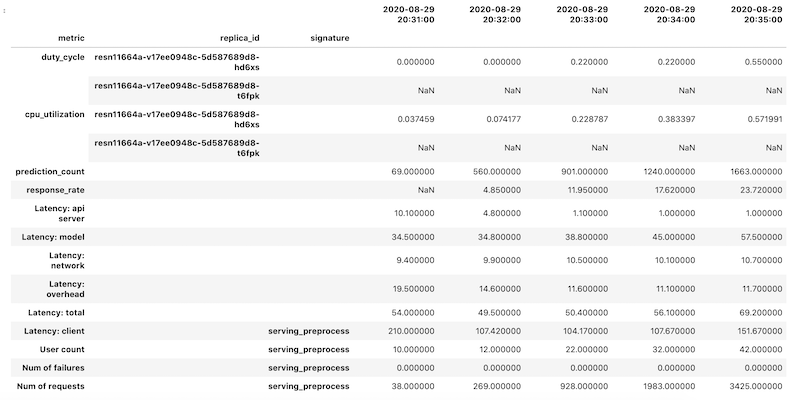
El objeto DataFrame recuperado usa la indexación jerárquica para los nombres de las columnas. Esto se debe a que algunas métricas contienen varias series temporales.
Por ejemplo, la métrica duty_cycle de GPU incluye una serie temporal de medidas para cada GPU que se usa en la implementación, indicada como replica_id. En el nivel superior del índice de la columna, se muestra el nombre de una métrica individual. El segundo nivel es un ID de réplica. En el tercer nivel, se muestra la firma de un modelo. Todas las métricas están alineadas en el mismo cronograma.
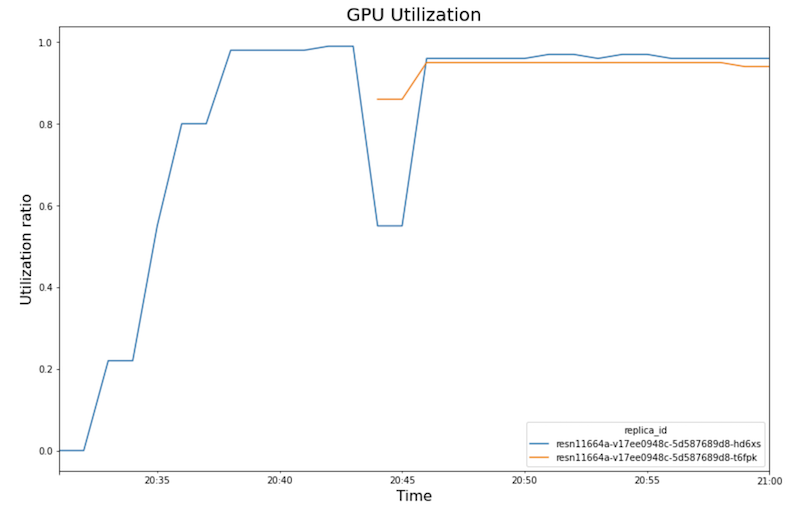
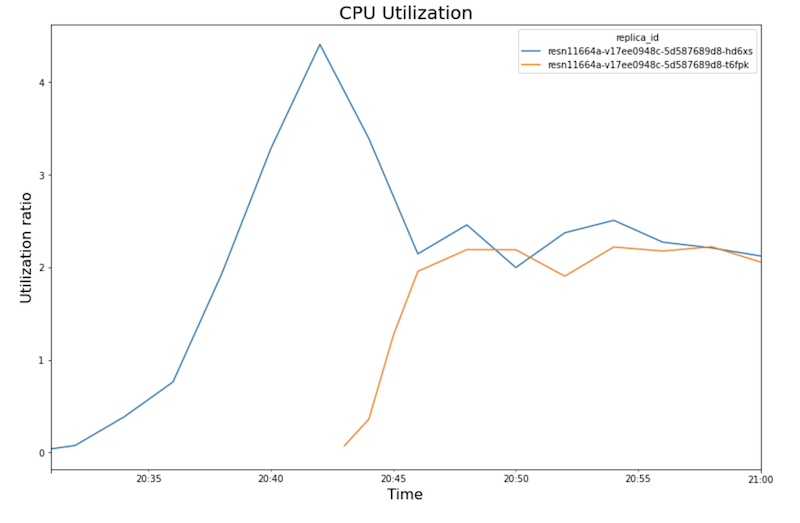
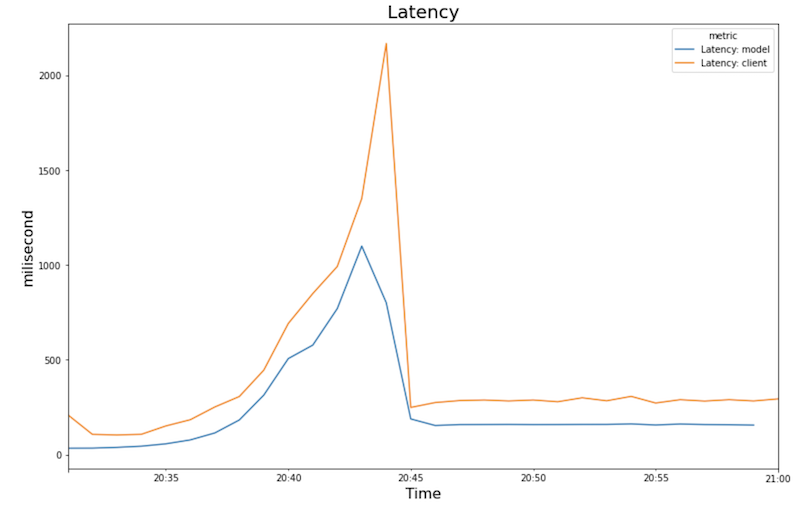
En los siguientes gráficos, se muestran el uso de GPU, el uso de CPU y la latencia a medida que los ves en el notebook.
Uso de GPU:
Uso de CPU:
Latencia:
Los gráficos muestran el siguiente comportamiento y secuencia:
- A medida que aumenta la carga de trabajo (cantidad de usuarios), aumenta el uso de CPU y GPU. Como resultado, la latencia aumenta y la diferencia entre la latencia del modelo y la latencia total aumenta hasta alcanzar su punto máximo alrededor de la hora 20:40.
- A las 20:40, el uso de GPU alcanza el 100%, mientras que el gráfico de CPU muestra que el uso alcanza 4 CPU. En esta muestra, se usa una máquina
n1-standard-8en esta prueba, que tiene 8 CPU. Por lo tanto, el uso de CPU alcanza el 50%. - En este punto, el ajuste de escala automático agrega capacidad: se agrega un nodo de entrega nuevo con una réplica de GPU adicional. El primer uso de la réplica de GPU disminuye y el uso de la segunda réplica de GPU aumenta.
- La latencia disminuye a medida que la réplica nueva comienza a entregar predicciones, y converge a alrededor de 200 milisegundos.
- El uso de CPU converge alrededor de un 250% para cada réplica, es decir, con 2.5 CPU de 8 CPU. Este valor indica que puedes usar una máquina
n1-standard-4en lugar den1-standard-8.
Realice una limpieza
Para evitar que se apliquen cargos a tu Google Cloud por los recursos usados en este documento, borra el proyecto que contiene los recursos o conserva el proyecto y borra los recursos individuales.
- In the Google Cloud console, go to the Manage resources page.
- In the project list, select the project that you want to delete, and then click Delete.
- In the dialog, type the project ID, and then click Shut down to delete the project.
Si deseas conservar el proyecto de Google Cloud, pero borrar los recursos que creaste, borra el clúster de Google Kubernetes Engine y el modelo implementado de AI Platform.
¿Qué sigue?
- Obtén información sobre MLOps y las canalizaciones de automatización y entrega continua en el aprendizaje automático.
- Obtén información sobre la arquitectura de MLOps con TFX, Kubeflow Pipelines y Cloud Build.
- Para obtener más información sobre las arquitecturas de referencia, los diagramas y las prácticas recomendadas, explora Cloud Architecture Center.