Nachdem Sie ein AutoML Vision Edge-Modell erstellt und in einen Google Cloud Storage-Bucket exportiert haben, können Sie RESTful-Dienste mit Ihren AutoML Vision Edge-Modellen und TF Serving-Docker-Images verwenden.
Umfang
Mit Docker-Containern lassen sich Edge-Modelle problemlos auf verschiedenen Geräten bereitstellen. Zum Ausführen von Edge-Modellen können Sie mit einer beliebigen Sprache REST APIs aus Containern aufrufen. Dies bietet den zusätzlichen Vorteil, dass Sie weder Abhängigkeiten installieren noch geeignete TensorFlow-Versionen suchen müssen.
In dieser Anleitung lernen Sie Schritt für Schritt, wie Sie Edge-Modelle auf Geräten mit Docker-Containern ausführen.
Insbesondere führt Sie diese Anleitung durch drei Schritte:
- Vorkonfigurierte Container abrufen
- Container mit Edge-Modellen ausführen, um REST APIs zu starten
- Vorhersagen treffen
Viele Geräte haben nur CPUs, einige haben jedoch GPUs, um Vorhersagen schneller zu erhalten. Daher stellen wir Anleitungen mit vorkonfigurierten CPU- und GPU-Containern bereit.
Ziele
In dieser einführenden, umfassenden Schritt-für-Schritt-Anleitung werden Codebeispiele für folgende Zwecke verwendet:
- Docker-Container abrufen
- REST APIs über Docker-Container mit Edge-Modellen starten
- Vorhersagen treffen, um analysierte Ergebnisse zu erhalten
Vorbereitung
Für diese Anleitung müssen Sie folgende Schritte ausführen:
- Ein exportierbares Edge-Modell trainieren. Folgen Sie der Kurzanleitung für Edge-Gerätemodelle, um ein Edge-Modell zu trainieren.
- Ein AutoML Vision Edge-Modell exportieren. Dieses Modell wird mit Containern als REST APIs bereitgestellt.
- Docker installieren. Diese Software wird zum Ausführen von Docker-Containern benötigt.
- (Optional) NVIDIA-Docker und -Treiber installieren. Dies ist ein optionaler Schritt, wenn Sie Geräte mit GPUs verwenden und Vorhersagen schneller erhalten möchten.
- Testbilder vorbereiten. Diese Bilder werden in Anfragen gesendet, um analysierte Ergebnisse zu erhalten.
Einzelheiten zum Exportieren von Modellen und zur Installation der erforderlichen Software finden Sie im folgenden Abschnitt.
AutoML Vision Edge-Modell exportieren
Nachdem Sie ein Edge-Modell trainiert haben, können Sie es auf verschiedene Geräte exportieren.
Die Container unterstützen TensorFlow-Modelle, die beim Export den Namen saved_model.pb haben.
Wählen Sie zum Exportieren eines AutoML Vision Edge-Modells für Container über die Benutzeroberfläche den Tab Container aus und exportieren Sie das Modell dann nach ${YOUR_MODEL_PATH} in Google Cloud Storage. Dieses exportierte Modell wird später mit Containern als REST APIs bereitgestellt.
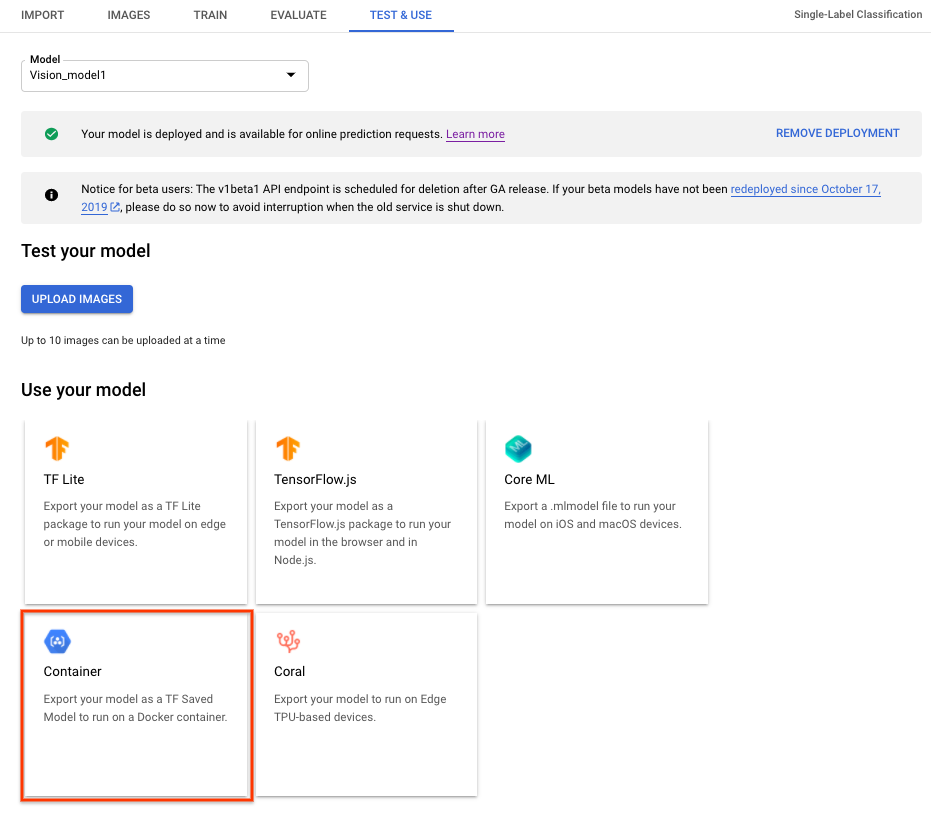
Führen Sie den folgenden Befehl aus, um das exportierte Modell lokal herunterzuladen.
Dabei gilt:
- ${YOUR_MODEL_PATH}: Modellstandort in Google Cloud Storage (z. B.
gs://my-bucket-vcm/models/edge/ICN4245971651915048908/2020-01-20_01-27-14-064_tf-saved-model/) - ${YOUR_LOCAL_MODEL_PATH}: der lokale Pfad, unter dem Sie das Modell speichern möchten (z. B.
/tmp)
gcloud storage cp ${YOUR_MODEL_PATH} ${YOUR_LOCAL_MODEL_PATH}/saved_model.pb
Docker installieren
Docker ist Software, die zum Bereitstellen und Ausführen von Anwendungen in Containern verwendet wird.
Installieren Sie Docker Community Edition (CE) auf Ihrem System. Damit werden Edge-Modelle als REST APIs bereitgestellt.
NVIDIA-Treiber und NVIDIA DOCKER installieren (optional – nur für GPU)
Einige Geräte haben GPUs, um schnellere Vorhersagen zu ermöglichen. Der GPU-Docker-Container unterstützt NVIDIA-GPUs.
Zum Ausführen von GPU-Containern müssen Sie den NVIDIA-Treiber und NVIDIA Docker auf Ihrem System installieren.
Modellinferenz mithilfe einer CPU ausführen
In diesem Abschnitt wird Schritt für Schritt erklärt, wie Sie mithilfe von CPU-Containern Modellinferenzen ausführen. Mit dem installierten Docker rufen Sie den CPU-Container ab und führen ihn aus, um die exportierten Edge-Modelle als REST APIs bereitzustellen. Dann senden Sie Anfragen mit einem Testbild an die REST APIs, um analysierte Ergebnisse zu erhalten.
Docker-Image abrufen
Zuerst verwenden Sie Docker, um einen vorkonfigurierten CPU-Container abzurufen. Der vorkonfigurierte CPU-Container hat bereits die gesamte Umgebung, um exportierte Edge-Modelle bereitzustellen, enthält jedoch noch keine Edge-Modelle.
Der vorkonfigurierte CPU-Container wird in Google Container Registry gespeichert. Legen Sie vor dem Anfordern des Containers in Google Container Registry eine Umgebungsvariable für den Speicherort des Containers fest:
export CPU_DOCKER_GCR_PATH=gcr.io/cloud-devrel-public-resources/gcloud-container-1.14.0:latest
Nachdem Sie die Umgebungsvariable für den Container Registry-Pfad festgelegt haben, führen Sie die folgende Befehlszeile aus, um den CPU-Container abzurufen:
sudo docker pull ${CPU_DOCKER_GCR_PATH}
Docker-Container ausführen
Nachdem Sie den vorhandenen Container abgerufen haben, führen Sie ihn aus, um Edge-Modellinferenzen mit REST APIs bereitzustellen.
Bevor Sie den CPU-Container starten, müssen Sie Systemvariablen festlegen:
- ${CONTAINER_NAME}: ein String, der den Namen des Containers bei der Ausführung angibt, z. B.
CONTAINER_NAME=automl_high_accuracy_model_cpu - ${PORT}: eine Zahl, die den Port auf Ihrem Gerät angibt, um später REST API-Aufrufe anzunehmen, z. B.
PORT=8501
Nachdem Sie die Variablen festgelegt haben, führen Sie Docker in der Befehlszeile aus, um mit REST APIs Edge-Modellinferenzen bereitzustellen:
sudo docker run --rm --name ${CONTAINER_NAME} -p ${PORT}:8501 -v ${YOUR_MODEL_PATH}:/tmp/mounted_model/0001 -t ${CPU_DOCKER_GCR_PATH}
Wenn der Container erfolgreich ausgeführt wird, können die REST APIs unter http://localhost:${PORT}/v1/models/default:predict Ergebnisse liefern. Im folgenden Abschnitt wird beschrieben, wie Anfragen für Vorhersagen an diesen Speicherort gesendet werden.
Vorhersageanfrage senden
Nachdem der Container nun erfolgreich ausgeführt wird, können Sie Vorhersageanfragen für ein Testbild an die REST APIs senden.
Befehlszeile
Der Anfragetext in der Befehlszeile enthält base64-codierte image_bytes und den String key, um das angegebene Bild zu identifizieren. Weitere Informationen zur Bildcodierung finden Sie unter Base64-Codierung. Das Format der JSON-Anfragedatei sieht so aus:
/tmp/request.json
{
"instances":
[
{
"image_bytes":
{
"b64": "/9j/7QBEUGhvdG9zaG9...base64-encoded-image-content...fXNWzvDEeYxxxzj/Coa6Bax//Z"
},
"key": "your-chosen-image-key"
}
]
}
Nachdem Sie eine lokale JSON-Anfragedatei erstellt haben, können Sie eine Vorhersageanfrage senden.
Verwenden Sie dafür den folgenden Befehl:
curl -X POST -d @/tmp/request.json http://localhost:${PORT}/v1/models/default:predict
Antwort
Die Ausgabe sollte in etwa so aussehen:
{
"predictions": [
{
"labels": ["Good", "Bad"],
"scores": [0.665018, 0.334982]
}
]
}
Python
Weitere Informationen finden Sie in der AutoML Vision Python API-Referenzdokumentation.
Richten Sie zur Authentifizierung bei AutoML Vision die Standardanmeldedaten für Anwendungen ein. Weitere Informationen finden Sie unter Authentifizierung für eine lokale Entwicklungsumgebung einrichten.
Modellinferenz mithilfe von GPU-Containern ausführen (optional)
In diesem Abschnitt wird gezeigt, wie Modellinferenzen mithilfe von GPU-Containern ausgeführt werden. Dieser Prozess ist dem Ausführen von Modellinferenzen mithilfe einer CPU sehr ähnlich. Die Hauptunterschiede sind der GPU-Containerpfad und die Methode zum Starten von GPU-Containern.
Docker-Image abrufen
Zuerst verwenden Sie Docker, um einen vorkonfigurierten GPU-Container abzurufen. Der vorkonfigurierte GPU-Container hat bereits die Umgebung, um exportierte Edge-Modelle mit GPUs bereitzustellen, enthält jedoch noch keine Edge-Modelle oder Treiber.
Der vorkonfigurierte CPU-Container wird in Google Container Registry gespeichert. Legen Sie vor dem Anfordern des Containers in Google Container Registry eine Umgebungsvariable für den Speicherort des Containers fest:
export GPU_DOCKER_GCR_PATH=gcr.io/cloud-devrel-public-resources/gcloud-container-1.14.0-gpu:latest
Führen Sie die folgende Befehlszeile aus, um den GPU-Container abzurufen:
sudo docker pull ${GPU_DOCKER_GCR_PATH}
Docker-Container ausführen
Mit diesem Schritt wird der GPU-Container ausgeführt, um mit REST APIs Edge-Modellinferenzen bereitzustellen. Sie müssen NVIDIA-Treiber und Docker wie oben beschrieben installieren. Außerdem müssen die folgenden Systemvariablen festgelegt werden:
- ${CONTAINER_NAME}: ein String, der den Namen des Containers bei der Ausführung angibt, z. B.
CONTAINER_NAME=automl_high_accuracy_model_gpu - ${PORT}: eine Zahl, die den Port auf Ihrem Gerät angibt, um später REST API-Aufrufe anzunehmen, z. B.
PORT=8502
Nachdem Sie die Variablen festgelegt haben, führen Sie Docker in der Befehlszeile aus, um mit REST APIs Edge-Modellinferenzen bereitzustellen:
sudo docker run --runtime=nvidia --rm --name "${CONTAINER_NAME}" -v \
${YOUR_MODEL_PATH}:/tmp/mounted_model/0001 -p \
${PORT}:8501 -t ${GPU_DOCKER_GCR_PATH}
Wenn der Container erfolgreich ausgeführt wird, können die REST APIs unter http://localhost:${PORT}/v1/models/default:predict Ergebnisse liefern. Im folgenden Abschnitt wird beschrieben, wie Anfragen für Vorhersagen an diesen Speicherort gesendet werden.
Vorhersageanfrage senden
Nachdem der Container nun erfolgreich ausgeführt wird, können Sie Vorhersageanfragen für ein Testbild an die REST APIs senden.
Befehlszeile
Der Anfragetext in der Befehlszeile enthält base64-codierte image_bytes und den String key, um das angegebene Bild zu identifizieren. Weitere Informationen zur Bildcodierung finden Sie unter Base64-Codierung. Das Format der JSON-Anfragedatei sieht so aus:
/tmp/request.json
{
"instances":
[
{
"image_bytes":
{
"b64": "/9j/7QBEUGhvdG9zaG9...base64-encoded-image-content...fXNWzvDEeYxxxzj/Coa6Bax//Z"
},
"key": "your-chosen-image-key"
}
]
}
Nachdem Sie eine lokale JSON-Anfragedatei erstellt haben, können Sie eine Vorhersageanfrage senden.
Verwenden Sie dafür den folgenden Befehl:
curl -X POST -d @/tmp/request.json http://localhost:${PORT}/v1/models/default:predict
Antwort
Die Ausgabe sollte in etwa so aussehen:
{
"predictions": [
{
"labels": ["Good", "Bad"],
"scores": [0.665018, 0.334982]
}
]
}
Python
Weitere Informationen finden Sie in der AutoML Vision Python API-Referenzdokumentation.
Richten Sie zur Authentifizierung bei AutoML Vision die Standardanmeldedaten für Anwendungen ein. Weitere Informationen finden Sie unter Authentifizierung für eine lokale Entwicklungsumgebung einrichten.
Zusammenfassung
In dieser Anleitung haben Sie Edge-Modelle mithilfe von CPU- oder GPU-Docker-Containern ausgeführt. Sie können diese containerbasierte Lösung jetzt auf weiteren Geräten bereitstellen.
Nächste Schritte
- Einführungsdokumentation zu TensorFlow lesen, um weitere Einzelheiten über TensorFlow zu erfahren
- Mehr über TensorFlow Serving erfahren
- TensorFlow Serving mit Kubernetes verwenden