Résumé
Ce tutoriel vous explique comment déployer et mettre en service des modèles Llama 3.1 et 3.2 à l'aide de vLLM dans Vertex AI. Il est conçu pour être utilisé avec deux notebooks distincts : Serve Llama 3.1 avec vLLM pour déployer des modèles Llama 3.1 uniquement textuels, et Serve Multimodal Llama 3.2 avec vLLM pour déployer des modèles Llama 3.2 multimodaux qui gèrent à la fois les entrées de texte et d'image. Les étapes décrites sur cette page vous montrent comment gérer efficacement l'inférence de modèle sur des GPU et personnaliser des modèles pour diverses applications. Vous disposez ainsi des outils nécessaires pour intégrer des modèles de langage avancés à vos projets.
À la fin de ce guide, vous saurez :
- Téléchargez des modèles Llama prédéfinis depuis Hugging Face avec un conteneur vLLM.
- Utiliser vLLM pour déployer ces modèles sur des instances GPU dans Google Cloud Vertex AI Model Garden.
- Mettre en service des modèles de manière efficace pour traiter les requêtes d'inférence à grande échelle
- Exécuter l'inférence sur les requêtes uniquement basées sur du texte et les requêtes basées sur du texte et des images
- Supprimer les fichiers de l"atelier
- Déboguer le déploiement
Principales fonctionnalités de vLLM
| Fonctionnalité | Description |
|---|---|
| PagedAttention | Mécanisme d'attention optimisé qui gère efficacement la mémoire pendant l'inférence. Prend en charge la génération de texte à haut débit en allouant dynamiquement des ressources de mémoire, ce qui permet l'évolutivité pour plusieurs requêtes simultanées. |
| Traitement par lots continu | Regroupe plusieurs requêtes d'entrée dans un seul lot pour le traitement en parallèle, ce qui maximise l'utilisation et le débit du GPU. |
| Streaming de jetons | Permet une sortie jeton par jeton en temps réel lors de la génération de texte. Idéal pour les applications qui nécessitent une faible latence, comme les chatbots ou les systèmes d'IA interactifs. |
| Compatibilité des modèles | Compatible avec une large gamme de modèles pré-entraînés dans des frameworks populaires tels que Hugging Face Transformers. Il facilite l'intégration et l'expérimentation de différents LLM. |
| Multi-GPU et multi-hôte | Permet un service de modèle efficace en répartissant la charge de travail sur plusieurs GPU au sein d'une même machine et sur plusieurs machines d'un cluster, ce qui augmente considérablement le débit et l'évolutivité. |
| Déploiement efficace | Elle offre une intégration parfaite aux API, telles que les finalisations de chat OpenAI, ce qui facilite le déploiement pour les cas d'utilisation en production. |
| Intégration parfaite aux modèles Hugging Face | vLLM est compatible avec le format des artefacts de modèle Hugging Face et permet de charger des modèles depuis HF. Il est donc facile de déployer des modèles Llama aux côtés d'autres modèles populaires comme Gemma, Phi et Qwen dans un paramètre optimisé. |
| Projet Open Source axé sur la communauté | vLLM est Open Source et encourage les contributions de la communauté, ce qui favorise l'amélioration continue de l'efficacité de la diffusion des LLM. |
Personnalisations vLLM Google Vertex AI : améliorez les performances et l'intégration
L'implémentation de vLLM dans Google Vertex AI Model Garden n'est pas une intégration directe de la bibliothèque Open Source. Vertex AI gère une version personnalisée et optimisée de vLLM, spécialement conçue pour améliorer les performances, la fiabilité et l'intégration fluide dans Google Cloud.
- Optimisation des performances :
- Téléchargement parallèle depuis Cloud Storage : accélère considérablement les temps de chargement et de déploiement des modèles en permettant la récupération parallèle des données depuis Cloud Storage, ce qui réduit la latence et améliore la vitesse de démarrage.
- Améliorations des fonctionnalités :
- LoRA dynamique avec mise en cache améliorée et compatibilité avec Cloud Storage : étend les fonctionnalités LoRA dynamiques avec des mécanismes de mise en cache sur disque local et gestion des exceptions robuste, tout en permettant de charger les pondérations LoRA directement à partir de chemins Cloud Storage et d'URL signées. Cela simplifie la gestion et le déploiement de modèles personnalisés.
- Analyse des appels de fonction Llama 3.1/3.2 : implémente une analyse spécialisée pour les appels de fonction Llama 3.1/3.2, ce qui améliore la robustesse de l'analyse.
- Mise en cache du préfixe de mémoire de l'hôte : le vLLM externe n'est compatible qu'avec la mise en cache du préfixe de mémoire GPU.
- Décodage spéculatif : il s'agit d'une fonctionnalité vLLM existante, mais Vertex AI a effectué des tests pour trouver des configurations de modèles très performantes.
Ces personnalisations spécifiques à Vertex AI, bien que souvent transparentes pour l'utilisateur final, vous permettent de maximiser les performances et l'efficacité de vos déploiements Llama 3.1 sur Vertex AI Model Garden.
- Intégration de l'écosystème Vertex AI :
- Compatibilité avec les formats d'entrée/de sortie de prédiction Vertex AI : assure une compatibilité fluide avec les formats d'entrée et de sortie de prédiction Vertex AI, ce qui simplifie la gestion des données et l'intégration à d'autres services Vertex AI.
- Connaissance des variables d'environnement Vertex : respecte et exploite les variables d'environnement Vertex AI (
AIP_*) pour la configuration et la gestion des ressources, ce qui simplifie le déploiement et assure un comportement cohérent dans l'environnement Vertex AI. - Gestion des gestion des exceptions et robustesse améliorées : implémente des mécanismes complets de gestion des exceptions, de validation des entrées/sorties et d'arrêt du serveur pour assurer la stabilité, la fiabilité et le bon fonctionnement dans l'environnement Vertex AI géré.
- Serveur Nginx pour la capacité : intègre un serveur Nginx au-dessus du serveur vLLM, ce qui facilite le déploiement de plusieurs répliques et améliore l'évolutivité et la haute disponibilité de l'infrastructure de diffusion.
Avantages supplémentaires de vLLM
- Performances de référence : vLLM offre des performances compétitives par rapport à d'autres systèmes de diffusion tels que Hugging Face text-generation-inference et FasterTransformer de NVIDIA en termes de débit et de latence.
- Facilité d'utilisation : la bibliothèque fournit une API simple pour l'intégration aux workflows existants, ce qui vous permet de déployer les modèles Llama 3.1 et 3.2 avec une configuration minimale.
- Fonctionnalités avancées : vLLM est compatible avec les flux de sortie (génération de réponses jeton par jeton) et gère efficacement les requêtes de longueur variable, ce qui améliore l'interactivité et la réactivité des applications.
Pour obtenir une présentation du système vLLM, consultez l'article.
Modèles compatibles
vLLM est compatible avec une large sélection de modèles de pointe, ce qui vous permet de choisir celui qui correspond le mieux à vos besoins. Le tableau suivant présente une sélection de ces modèles. Toutefois, pour accéder à une liste complète des modèles compatibles, y compris ceux pour l'inférence textuelle et multimodale, vous pouvez consulter le site Web officiel de vLLM.
| Catégorie | Modèles |
|---|---|
| Meta AI | Llama 3.3, Llama 3.2, Llama 3.1, Llama 3, Llama 2, Code Llama |
| Mistral AI | Mistral 7B, Mixtral 8x7B, Mixtral 8x22B et leurs variantes (Instruct, Chat), Mistral-tiny, Mistral-small, Mistral-medium |
| DeepSeek AI | DeepSeek-V3, DeepSeek-R1, DeepSeek-R1-Distill-Qwen-1.5B, DeepSeek-R1-Distill-Qwen-7B, DeepSeek-R1-Distill-Llama-8B, DeepSeek-R1-Distill-Qwen-14B, DeepSeek-R1-Distill-Qwen-32B, DeepSeek-R1-Distill-Llama-70B, Deepseek-vl2-tiny, Deepseek-vl2-small, Deepseek-vl2 |
| MosaicML | MPT (7B, 30B) et variantes (Instruct, Chat), MPT-7B-StoryWriter-65k |
| OpenAI | GPT-2, GPT-3, GPT-4, GPT-NeoX |
| Together AI | RedPajama, Pythia |
| Stability AI | StableLM (3B, 7B), StableLM-Alpha-3B, StableLM-Base-Alpha-7B, StableLM-Instruct-Alpha-7B |
| TII (Technology Innovation Institute) | Falcon 7B, Falcon 40B et leurs variantes (Instruct, Chat), Falcon-RW-1B, Falcon-RW-7B |
| BigScience | BLOOM, BLOOMZ |
| FLAN-T5, UL2, Gemma (2B, 7B), PaLM 2, | |
| Salesforce | CodeT5, CodeT5+ |
| LightOn | Persimmon-8B-base, Persimmon-8B-chat |
| EleutherAI | GPT-Neo, Pythia |
| AI21 Labs | Jamba |
| Cerebras | Cerebras-GPT |
| Intel | Intel-NeuralChat-7B |
| Autres modèles importants | StarCoder, OPT, Baichuan, Aquila, Qwen, InternLM, XGen, OpenLLaMA, Phi-2, Yi, OpenCodeInterpreter, Nous-Hermes, Gemma-it, Mistral-Instruct-v0.2-7B-Zeus, |
Premiers pas dans Model Garden
Le conteneur de diffusion vLLM Cloud GPU est intégré à Model Garden, au Playground, au déploiement en un clic et aux exemples de notebooks Colab Enterprise. Ce tutoriel se concentre sur la famille de modèles Llama de Meta AI comme exemple.
Utiliser le notebook Colab Enterprise
Les playgrounds et les déploiements en un clic sont également disponibles, mais ne sont pas décrits dans ce tutoriel.
- Accédez à la page Fiche de modèle, puis cliquez sur Ouvrir le notebook.
- Sélectionnez le notebook Vertex Serving. Le notebook s'ouvre dans Colab Enterprise.
- Parcourez le notebook pour déployer un modèle à l'aide de vLLM et envoyez des requêtes de prédiction au point de terminaison.
Préparation
Cette section décrit les étapes nécessaires pour configurer votre projet Google Cloudet vous assurer de disposer des ressources requises pour déployer et diffuser des modèles vLLM.
1. Facturation
- Activez la facturation : assurez-vous que la facturation est activée pour votre projet. Pour en savoir plus, consultez Activer, désactiver ou modifier la facturation pour un projet.
2. Disponibilité et quotas des GPU
- Pour exécuter des prédictions à l'aide de GPU hautes performances (NVIDIA A100 80 Go ou H100 80 Go), assurez-vous de vérifier vos quotas pour ces GPU dans la région sélectionnée :
| Type de machine | Type d'accélérateur | Régions recommandées |
|---|---|---|
| a2-ultragpu-1g | 1 NVIDIA_A100_80GB | us-central1, us-east4, europe-west4, asia-southeast1 |
| a3-highgpu-8g | 8 NVIDIA_H100_80GB | us-central1, us-west1, europe-west4, asia-southeast1 |
3. Configurer un projet Google Cloud
Exécutez l'exemple de code suivant pour vous assurer que votre environnement Google Cloud est correctement configuré. Cette étape installe les bibliothèques Python nécessaires et configure l'accès aux ressources Google Cloud . Ceci inclut les actions suivantes :
- Installation : mettez à niveau la bibliothèque
google-cloud-aiplatformet clonez le dépôt contenant les fonctions utilitaires. - Configuration de l'environnement : définition des variables pour l'ID du projet Google Cloud , la région et un bucket Cloud Storage unique pour stocker les artefacts du modèle.
- Activation des API : activez les API Vertex AI et Compute Engine, qui sont essentielles pour déployer et gérer les modèles d'IA.
- Configuration du bucket : créez un bucket Cloud Storage ou vérifiez qu'un bucket existant se trouve dans la région appropriée.
- Initialisation de Vertex AI : initialisez la bibliothèque cliente Vertex AI avec les paramètres du projet, de l'emplacement et du bucket de préproduction.
- Configuration du compte de service : identifiez le compte de service par défaut pour exécuter les jobs Vertex AI et accordez-lui les autorisations nécessaires.
BUCKET_URI = "gs://"
REGION = ""
! pip3 install --upgrade --quiet 'google-cloud-aiplatform>=1.64.0'
! git clone https://github.com/GoogleCloudPlatform/vertex-ai-samples.git
import datetime
import importlib
import os
import uuid
from typing import Tuple
import requests
from google.cloud import aiplatform
common_util = importlib.import_module(
"vertex-ai-samples.community-content.vertex_model_garden.model_oss.notebook_util.common_util"
)
models, endpoints = {}, {}
PROJECT_ID = os.environ["GOOGLE_CLOUD_PROJECT"]
if not REGION:
REGION = os.environ["GOOGLE_CLOUD_REGION"]
print("Enabling Vertex AI API and Compute Engine API.")
! gcloud services enable aiplatform.googleapis.com compute.googleapis.com
now = datetime.datetime.now().strftime("%Y%m%d%H%M%S")
BUCKET_NAME = "/".join(BUCKET_URI.split("/")[:3])
if BUCKET_URI is None or BUCKET_URI.strip() == "" or BUCKET_URI == "gs://":
BUCKET_URI = f"gs://{PROJECT_ID}-tmp-{now}-{str(uuid.uuid4())[:4]}"
BUCKET_NAME = "/".join(BUCKET_URI.split("/")[:3])
! gsutil mb -l {REGION} {BUCKET_URI}
else:
assert BUCKET_URI.startswith("gs://"), "BUCKET_URI must start with `gs://`."
shell_output = ! gsutil ls -Lb {BUCKET_NAME} | grep "Location constraint:" | sed "s/Location constraint://"
bucket_region = shell_output[0].strip().lower()
if bucket_region != REGION:
raise ValueError(
"Bucket region %s is different from notebook region %s"
% (bucket_region, REGION)
)
print(f"Using this Bucket: {BUCKET_URI}")
STAGING_BUCKET = os.path.join(BUCKET_URI, "temporal")
MODEL_BUCKET = os.path.join(BUCKET_URI, "llama3_1")
print("Initializing Vertex AI API.")
aiplatform.init(project=PROJECT_ID, location=REGION, staging_bucket=STAGING_BUCKET)
shell_output = ! gcloud projects describe $PROJECT_ID
project_number = shell_output[-1].split(":")[1].strip().replace("'", "")
SERVICE_ACCOUNT = "your service account email"
print("Using this default Service Account:", SERVICE_ACCOUNT)
! gsutil iam ch serviceAccount:{SERVICE_ACCOUNT}:roles/storage.admin $BUCKET_NAME
! gcloud config set project $PROJECT_ID
! gcloud projects add-iam-policy-binding --no-user-output-enabled {PROJECT_ID} --member=serviceAccount:{SERVICE_ACCOUNT} --role="roles/storage.admin"
! gcloud projects add-iam-policy-binding --no-user-output-enabled {PROJECT_ID} --member=serviceAccount:{SERVICE_ACCOUNT} --role="roles/aiplatform.user"
Utiliser Hugging Face avec Meta Llama 3.1, 3.2 et vLLM
Les collections Llama 3.1 et 3.2 de Meta proposent un éventail de grands modèles de langage (LLM) multilingues conçus pour générer du texte de haute qualité dans divers cas d'utilisation. Ces modèles sont pré-entraînés et adaptés aux instructions. Ils excellent dans des tâches telles que le dialogue multilingue, la synthèse et la récupération agentique. Avant d'utiliser les modèles Llama 3.1 et 3.2, vous devez accepter leurs conditions d'utilisation, comme indiqué dans la capture d'écran. La bibliothèque vLLM offre un environnement de diffusion Open Source simplifié avec des optimisations pour la latence, l'efficacité de la mémoire et l'évolutivité.
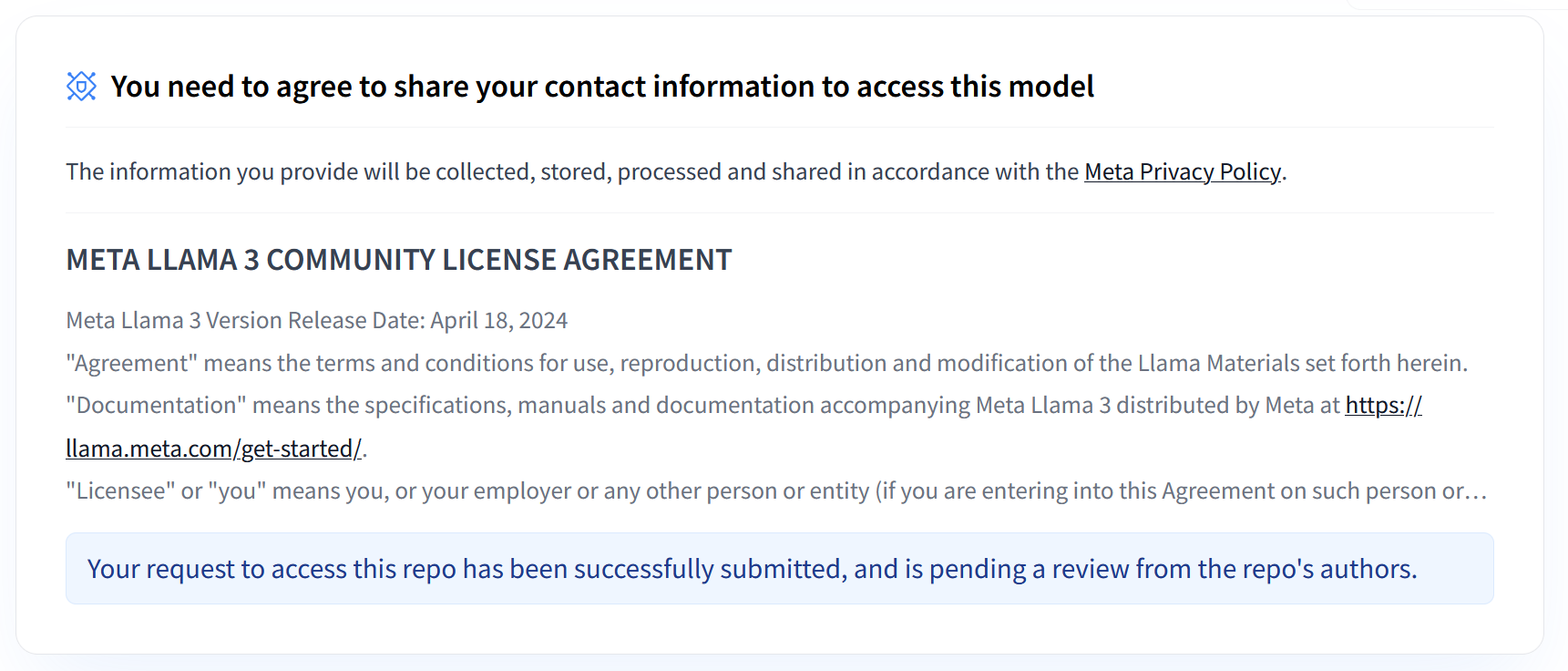 Figure 1 : Contrat de licence Communauté Meta Llama 3
Figure 1 : Contrat de licence Communauté Meta Llama 3
Présentation des collections Meta Llama 3.1 et 3.2
Les collections Llama 3.1 et 3.2 s'adressent chacune à des échelles de déploiement et des tailles de modèles différentes, ce qui vous offre des options flexibles pour les tâches de dialogue multilingues et plus encore. Pour en savoir plus, consultez la page Présentation de Llama.
- Texte uniquement : la collection Llama 3.2 de grands modèles de langage (LLM) multilingues est une collection de modèles génératifs pré-entraînés et adaptés aux instructions, offrant 1 ou 3 milliards de paramètres (texte entrant, texte sortant).
- Vision et Vision Instruct : la collection Llama 3.2-Vision de grands modèles de langage (LLM) multimodaux est une collection de modèles génératifs de raisonnement par image pré-entraînés et adaptés aux instructions, offrant 11 ou 90 milliards de paramètres (texte et images en entrée, texte en sortie). Optimisation : comme Llama 3.1, les modèles 3.2 sont adaptés aux dialogues multilingues et sont performants dans les tâches de récupération et de synthèse, obtenant les meilleurs résultats sur les benchmarks standards.
- Architecture du modèle : Llama 3.2 dispose également d'un framework Transformer autorégressif, avec SFT et RLHF appliqués pour aligner les modèles sur l'utilité et la sécurité.
Jetons d'accès utilisateur Hugging Face
Ce tutoriel nécessite un jeton d'accès en lecture depuis le Hugging Face Hub pour accéder aux ressources nécessaires. Pour configurer votre authentification, procédez comme suit :
 Figure 2 : Paramètres du jeton d'accès Hugging Face
Figure 2 : Paramètres du jeton d'accès Hugging Face
Générez un jeton d'accès en lecture :
- Accédez aux paramètres de votre compte Hugging Face.
- Créez un jeton, attribuez-lui le rôle "Lecture" et enregistrez-le de manière sécurisée.
Utilisez le jeton :
- Utilisez le jeton généré pour vous authentifier et accéder aux dépôts publics ou privés selon les besoins du tutoriel.
 Figure 3 : Gérer le jeton d'accès Hugging Face
Figure 3 : Gérer le jeton d'accès Hugging Face
Cette configuration vous permet de disposer du niveau d'accès approprié sans autorisations inutiles. Ces pratiques renforcent la sécurité et empêchent l'exposition accidentelle de jetons. Pour en savoir plus sur la configuration des jetons d'accès, consultez la page sur les jetons d'accès Hugging Face.
Évitez de partager ou d'exposer votre jeton publiquement ou en ligne. Lorsque vous définissez votre jeton comme variable d'environnement lors du déploiement, il reste privé pour votre projet. Vertex AI assure sa sécurité en empêchant d'autres utilisateurs d'accéder à vos modèles et points de terminaison.
Pour en savoir plus sur la protection de votre jeton d'accès, consultez Jetons d'accès Hugging Face : bonnes pratiques.
Déployer des modèles Llama 3.1 uniquement textuels avec vLLM
Pour le déploiement en production de grands modèles de langage, vLLM fournit une solution de diffusion efficace qui optimise l'utilisation de la mémoire, réduit la latence et augmente le débit. Il est donc particulièrement adapté à la gestion des modèles Llama 3.1 plus volumineux, ainsi que des modèles Llama 3.2 multimodaux.
Étape 1 : Choisir un modèle à déployer
Choisissez la variante du modèle Llama 3.1 à déployer. Les options disponibles incluent différentes tailles et versions ajustées aux instructions :
base_model_name = "Meta-Llama-3.1-8B" # @param ["Meta-Llama-3.1-8B", "Meta-Llama-3.1-8B-Instruct", "Meta-Llama-3.1-70B", "Meta-Llama-3.1-70B-Instruct", "Meta-Llama-3.1-405B-FP8", "Meta-Llama-3.1-405B-Instruct-FP8"]
hf_model_id = "meta-Llama/" + base_model_name
Étape 2 : Vérifiez le matériel et le quota de déploiement
La fonction de déploiement définit le GPU et le type de machine appropriés en fonction de la taille du modèle, et vérifie le quota dans cette région pour un projet spécifique :
if "8b" in base_model_name.lower():
accelerator_type = "NVIDIA_L4"
machine_type = "g2-standard-12"
accelerator_count = 1
elif "70b" in base_model_name.lower():
accelerator_type = "NVIDIA_L4"
machine_type = "g2-standard-96"
accelerator_count = 8
elif "405b" in base_model_name.lower():
accelerator_type = "NVIDIA_H100_80GB"
machine_type = "a3-highgpu-8g"
accelerator_count = 8
else:
raise ValueError(f"Recommended GPU setting not found for: {accelerator_type} and {base_model_name}.")
Vérifiez la disponibilité du quota de GPU dans la région spécifiée :
common_util.check_quota(
project_id=PROJECT_ID,
region=REGION,
accelerator_type=accelerator_type,
accelerator_count=accelerator_count,
is_for_training=False,
)
Étape 3 : Inspecter le modèle à l'aide de vLLM
La fonction suivante importe le modèle dans Vertex AI, configure les paramètres de déploiement et le déploie sur un point de terminaison à l'aide de vLLM.
- Image Docker : le déploiement utilise une image Docker vLLM prédéfinie pour un service efficace.
- Configuration : configurez l'utilisation de la mémoire, la longueur du modèle et d'autres paramètres vLLM. Pour en savoir plus sur les arguments acceptés par le serveur, consultez la page de documentation officielle de vLLM.
- Variables d'environnement : définissez des variables d'environnement pour l'authentification et la source de déploiement.
def deploy_model_vllm(
model_name: str,
model_id: str,
service_account: str,
base_model_id: str = None,
machine_type: str = "g2-standard-8",
accelerator_type: str = "NVIDIA_L4",
accelerator_count: int = 1,
gpu_memory_utilization: float = 0.9,
max_model_len: int = 4096,
dtype: str = "auto",
enable_trust_remote_code: bool = False,
enforce_eager: bool = False,
enable_lora: bool = False,
max_loras: int = 1,
max_cpu_loras: int = 8,
use_dedicated_endpoint: bool = False,
max_num_seqs: int = 256,
) -> Tuple[aiplatform.Model, aiplatform.Endpoint]:
"""Deploys trained models with vLLM into Vertex AI."""
endpoint = aiplatform.Endpoint.create(
display_name=f"{model_name}-endpoint",
dedicated_endpoint_enabled=use_dedicated_endpoint,
)
if "8b" in base_model_name.lower():
accelerator_type = "NVIDIA_L4"
machine_type = "g2-standard-12"
accelerator_count = 1
elif "70b" in base_model_name.lower():
accelerator_type = "NVIDIA_L4"
machine_type = "g2-standard-96"
accelerator_count = 8
elif "405b" in base_model_name.lower():
accelerator_type = "NVIDIA_H100_80GB"
machine_type = "a3-highgpu-8g"
accelerator_count = 8
else:
raise ValueError(f"Recommended GPU setting not found for: {accelerator_type} and {base_model_name}.")
common_util.check_quota(
project_id=PROJECT_ID,
region=REGION,
accelerator_type=accelerator_type,
accelerator_count=accelerator_count,
is_for_training=False,
)
vllm_args = [
"python", "-m", "vllm.entrypoints.api_server",
"--host=0.0.0.0",
"--port=8080",
f"--model={model_id}",
f"--tensor-parallel-size={accelerator_count}",
"--swap-space=16",
f"--gpu-memory-utilization={gpu_memory_utilization}",
f"--max-model-len={max_model_len}", f"--dtype={dtype}",
f"--max-loras={max_loras}", f"--max-cpu-loras={max_cpu_loras}",
f"--max-num-seqs={max_num_seqs}", "--disable-log-stats"
]
if enable_trust_remote_code:
vllm_args.append("--trust-remote-code")
if enforce_eager:
vllm_args.append("--enforce-eager")
if enable_lora:
vllm_args.append("--enable-lora")
if model_type:
vllm_args.append(f"--model-type={model_type}")
env_vars = {
"MODEL_ID": model_id,
"DEPLOY_SOURCE": "notebook",
"HF_TOKEN": HF_TOKEN
}
model = aiplatform.Model.upload(
display_name=model_name,
serving_container_image_uri=VLLM_DOCKER_URI,
serving_container_args=vllm_args,
serving_container_ports=[8080],
serving_container_predict_route="/generate",
serving_container_health_route="/ping",
serving_container_environment_variables=env_vars,
serving_container_shared_memory_size_mb=(16 * 1024),
serving_container_deployment_timeout=7200,
)
print(f"Deploying {model_name} on {machine_type} with {accelerator_count} {accelerator_type} GPU(s).")
model.deploy(
endpoint=endpoint,
machine_type=machine_type,
accelerator_type=accelerator_type,
accelerator_count=accelerator_count,
deploy_request_timeout=1800,
service_account=service_account,
)
print("endpoint_name:", endpoint.name)
return model, endpoint
Étape 4 : Exécuter le déploiement
Exécutez la fonction de déploiement avec le modèle et la configuration sélectionnés. Cette étape déploie le modèle et renvoie les instances de modèle et de point de terminaison :
HF_TOKEN = ""
VLLM_DOCKER_URI = "us-docker.pkg.dev/vertex-ai/vertex-vision-model-garden-dockers/pytorch-vllm-serve:20241001_0916_RC00"
model_name = common_util.get_job_name_with_datetime(prefix=f"{base_model_name}-serve-vllm")
gpu_memory_utilization = 0.9
max_model_len = 4096
max_loras = 1
models["vllm_gpu"], endpoints["vllm_gpu"] = deploy_model_vllm(
model_name=common_util.get_job_name_with_datetime(prefix=f"{base_model_name}-serve"),
model_id=hf_model_id,
service_account=SERVICE_ACCOUNT,
machine_type=machine_type,
accelerator_type=accelerator_type,
accelerator_count=accelerator_count,
gpu_memory_utilization=gpu_memory_utilization,
max_model_len=max_model_len,
max_loras=max_loras,
enforce_eager=True,
enable_lora=True,
use_dedicated_endpoint=use_dedicated_endpoint,
)
Après avoir exécuté cet exemple de code, votre modèle Llama 3.1 sera déployé sur Vertex AI et accessible via le point de terminaison spécifié. Vous pouvez interagir avec lui pour des tâches d'inférence telles que la génération de texte, la synthèse et le dialogue. Selon la taille du modèle, le déploiement d'un nouveau modèle peut prendre jusqu'à une heure. Vous pouvez suivre la progression de la prédiction en ligne.
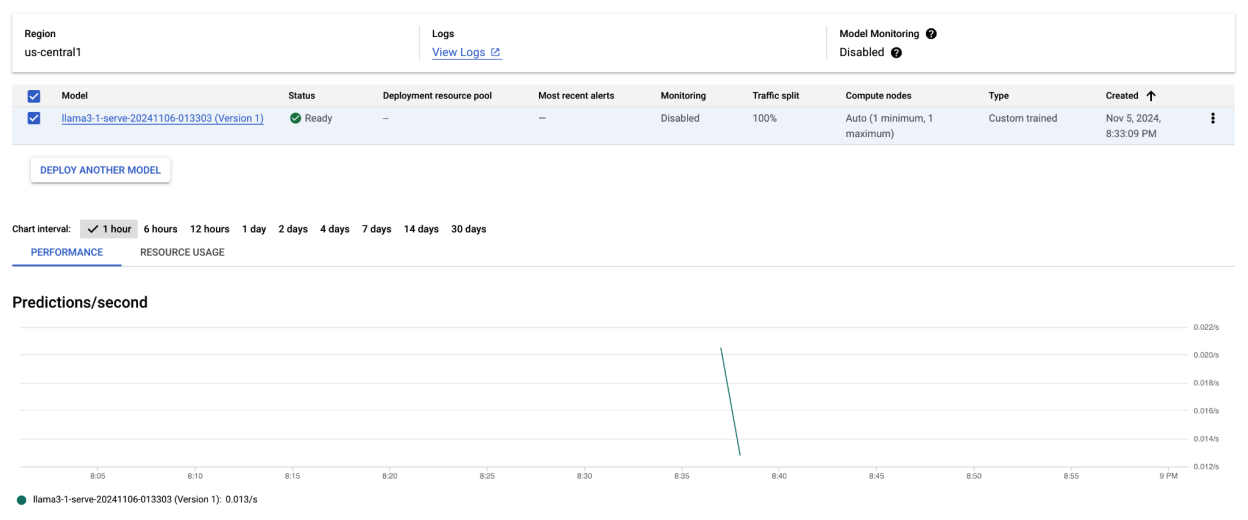 Figure 4 : Point de terminaison de déploiement Llama 3.1 dans le tableau de bord Vertex
Figure 4 : Point de terminaison de déploiement Llama 3.1 dans le tableau de bord Vertex
Effectuer des prédictions avec Llama 3.1 sur Vertex AI
Une fois le modèle Llama 3.1 déployé sur Vertex AI, vous pouvez commencer à effectuer des prédictions en envoyant des requêtes textuelles au point de terminaison. Cette section fournit un exemple de génération de réponses avec différents paramètres personnalisables pour contrôler la sortie.
Étape 1 : Définissez votre requête et vos paramètres
Commencez par configurer votre requête textuelle et vos paramètres d'échantillonnage pour guider la réponse du modèle. Voici les principaux paramètres :
prompt: texte d'entrée pour lequel vous souhaitez que le modèle génère une réponse. Par exemple, la requête "Qu'est-ce qu'une voiture ?".max_tokens: nombre maximal de jetons dans le résultat généré. Réduire cette valeur peut aider à éviter les problèmes de délai avant expiration.temperature: contrôle le caractère aléatoire des prédictions. Des valeurs plus élevées (par exemple, 1,0) augmentent la diversité, tandis que des valeurs plus faibles (par exemple, 0,5) rendent le résultat plus ciblé.top_p: limite le pool d'échantillonnage à la probabilité cumulative la plus élevée. Par exemple, si vous définissez top_p sur 0,9, seuls les jetons dont la masse de probabilité se situe dans les 90 % les plus élevés seront pris en compte.top_k: limite l'échantillonnage aux k jetons les plus probables. Par exemple, si vous définissez top_k sur 50, l'échantillonnage ne sera effectué que sur les 50 premiers jetons.raw_response: si la valeur est "True", renvoie la sortie brute du modèle. Si la valeur est "False", appliquez une mise en forme supplémentaire avec la structure "Prompt:\n{prompt}\nOutput:\n{output}".lora_id(facultatif) : chemin d'accès aux fichiers de pondération LoRA pour appliquer les pondérations d'adaptation de rang faible (LoRA). Il peut s'agir d'un bucket Cloud Storage ou d'une URL de dépôt Hugging Face. Notez que cela ne fonctionne que si--enable-loraest défini dans les arguments de déploiement. LoRA dynamique n'est pas compatible avec les modèles multimodaux.
prompt = "What is a car?"
max_tokens = 50
temperature = 1.0
top_p = 1.0
top_k = 1
raw_response = False
lora_id = ""
Étape 2 : Envoyer la requête de prédiction
Maintenant que l'instance est configurée, vous pouvez envoyer la requête de prédiction au point de terminaison Vertex AI déployé. Cet exemple montre comment effectuer une prédiction et imprimer le résultat :
response = endpoints["vllm_gpu"].predict(
instances=instances, use_dedicated_endpoint=use_dedicated_endpoint
)
for prediction in response.predictions:
print(prediction)
Exemple de résultat :
Voici un exemple de réponse du modèle à la requête "Qu'est-ce qu'une voiture ?" :
Human: What is a car?
Assistant: A car, or a motor car, is a road-connected human-transportation system
used to move people or goods from one place to another.
Remarques supplémentaires
- Modération : pour garantir la sécurité du contenu, vous pouvez modérer le texte généré à l'aide des fonctionnalités de modération de texte de Vertex AI.
- Gérer les délais d'attente : si vous rencontrez des problèmes tels que
ServiceUnavailable: 503, essayez de réduire le paramètremax_tokens.
Cette approche offre un moyen flexible d'interagir avec le modèle Llama 3.1 à l'aide de différentes techniques d'échantillonnage et d'adaptateurs LoRA. Elle convient donc à une variété de cas d'utilisation, allant de la génération de texte à usage général aux réponses spécifiques à des tâches.
Déployer des modèles multimodaux Llama 3.2 avec vLLM
Cette section vous explique comment importer des modèles Llama 3.2 prédéfinis dans Model Registry et les déployer sur un point de terminaison Vertex AI. Le déploiement peut prendre jusqu'à une heure, selon la taille du modèle. Les modèles Llama 3.2 sont disponibles dans des versions multimodales qui acceptent les entrées de texte et d'image. vLLM est compatible avec les éléments suivants :
- Format texte uniquement
- Format image unique + texte
Ces formats rendent Llama 3.2 adapté aux applications nécessitant un traitement visuel et textuel.
Étape 1 : Choisir un modèle à déployer
Spécifiez la variante du modèle Llama 3.2 que vous souhaitez déployer. L'exemple suivant utilise Llama-3.2-11B-Vision comme modèle sélectionné, mais vous pouvez choisir parmi d'autres options disponibles en fonction de vos besoins.
base_model_name = "Llama-3.2-11B-Vision" # @param ["Llama-3.2-1B", "Llama-3.2-1B-Instruct", "Llama-3.2-3B", "Llama-3.2-3B-Instruct", "Llama-3.2-11B-Vision", "Llama-3.2-11B-Vision-Instruct", "Llama-3.2-90B-Vision", "Llama-3.2-90B-Vision-Instruct"]
hf_model_id = "meta-Llama/" + base_model_name
Étape 2 : Configurez le matériel et les ressources
Sélectionnez le matériel approprié pour la taille du modèle. vLLM peut utiliser différents GPU en fonction des besoins de calcul du modèle :
- Modèles 1B et 3B : utilisez des GPU NVIDIA L4.
- Modèles 11B : utilisez des GPU NVIDIA A100.
- Modèles 90B : utilisez des GPU NVIDIA H100.
Cet exemple configure le déploiement en fonction de la sélection du modèle :
if "3.2-1B" in base_model_name or "3.2-3B" in base_model_name:
accelerator_type = "NVIDIA_L4"
machine_type = "g2-standard-8"
accelerator_count = 1
elif "3.2-11B" in base_model_name:
accelerator_type = "NVIDIA_TESLA_A100"
machine_type = "a2-highgpu-1g"
accelerator_count = 1
elif "3.2-90B" in base_model_name:
accelerator_type = "NVIDIA_H100_80GB"
machine_type = "a3-highgpu-8g"
accelerator_count = 8
else:
raise ValueError(f"Recommended GPU setting not found for: {base_model_name}.")
Assurez-vous de disposer du quota de GPU requis :
common_util.check_quota(
project_id=PROJECT_ID,
region=REGION,
accelerator_type=accelerator_type,
accelerator_count=accelerator_count,
is_for_training=False,
)
Étape 3 : Déployer le modèle à l'aide de vLLM
La fonction suivante gère le déploiement du modèle Llama 3.2 sur Vertex AI. Il configure l'environnement du modèle, l'utilisation de la mémoire et les paramètres vLLM pour une diffusion efficace.
def deploy_model_vllm(
model_name: str,
model_id: str,
service_account: str,
base_model_id: str = None,
machine_type: str = "g2-standard-8",
accelerator_type: str = "NVIDIA_L4",
accelerator_count: int = 1,
gpu_memory_utilization: float = 0.9,
max_model_len: int = 4096,
dtype: str = "auto",
enable_trust_remote_code: bool = False,
enforce_eager: bool = False,
enable_lora: bool = False,
max_loras: int = 1,
max_cpu_loras: int = 8,
use_dedicated_endpoint: bool = False,
max_num_seqs: int = 12,
model_type: str = None,
) -> Tuple[aiplatform.Model, aiplatform.Endpoint]:
"""Deploys trained models with vLLM into Vertex AI."""
endpoint = aiplatform.Endpoint.create(
display_name=f"{model_name}-endpoint",
dedicated_endpoint_enabled=use_dedicated_endpoint,
)
if not base_model_id:
base_model_id = model_id
vllm_args = [
"python",
"-m",
"vllm.entrypoints.api_server",
"--host=0.0.0.0",
"--port=8080",
f"--model={model_id}",
f"--tensor-parallel-size={accelerator_count}",
"--swap-space=16",
f"--gpu-memory-utilization={gpu_memory_utilization}",
f"--max-model-len={max_model_len}",
f"--dtype={dtype}",
f"--max-loras={max_loras}",
f"--max-cpu-loras={max_cpu_loras}",
f"--max-num-seqs={max_num_seqs}",
"--disable-log-stats",
]
if enable_trust_remote_code:
vllm_args.append("--trust-remote-code")
if enforce_eager:
vllm_args.append("--enforce-eager")
if enable_lora:
vllm_args.append("--enable-lora")
if model_type:
vllm_args.append(f"--model-type={model_type}")
env_vars = {
"MODEL_ID": base_model_id,
"DEPLOY_SOURCE": "notebook",
}
# HF_TOKEN is not a compulsory field and may not be defined.
try:
if HF_TOKEN:
env_vars["HF_TOKEN"] = HF_TOKEN
except NameError:
pass
model = aiplatform.Model.upload(
display_name=model_name,
serving_container_image_uri=VLLM_DOCKER_URI,
serving_container_args=vllm_args,
serving_container_ports=[8080],
serving_container_predict_route="/generate",
serving_container_health_route="/ping",
serving_container_environment_variables=env_vars,
serving_container_shared_memory_size_mb=(16 * 1024),
serving_container_deployment_timeout=7200,
)
print(f"Deploying {model_name} on {machine_type} with {accelerator_count} {accelerator_type} GPU(s).")
model.deploy(
endpoint=endpoint,
machine_type=machine_type,
accelerator_type=accelerator_type,
accelerator_count=accelerator_count,
deploy_request_timeout=1800,
service_account=service_account,
)
print("endpoint_name:", endpoint.name)
return model, endpoint
Étape 4 : Exécuter le déploiement
Exécutez la fonction de déploiement avec le modèle et les paramètres configurés. La fonction renverra les instances de modèle et de point de terminaison, que vous pourrez utiliser pour l'inférence.
model_name = common_util.get_job_name_with_datetime(prefix=f"{base_model_name}-serve-vllm")
models["vllm_gpu"], endpoints["vllm_gpu"] = deploy_model_vllm(
model_name=model_name
model_id=hf_model_id,
base_model_id=hf_model_id,
service_account=SERVICE_ACCOUNT,
machine_type=machine_type,
accelerator_type=accelerator_type,
accelerator_count=accelerator_count,
gpu_memory_utilization=gpu_memory_utilization,
max_model_len=max_model_len,
enforce_eager=True,
use_dedicated_endpoint=use_dedicated_endpoint,
max_num_seqs=max_num_seqs,
)
 Figure 5 : Point de terminaison de déploiement Llama 3.2 dans le tableau de bord Vertex
Figure 5 : Point de terminaison de déploiement Llama 3.2 dans le tableau de bord Vertex
Selon la taille du modèle, le déploiement d'un nouveau modèle peut prendre jusqu'à une heure. Vous pouvez suivre sa progression au niveau de la prédiction en ligne.
Inférence avec vLLM sur Vertex AI à l'aide de la route de prédiction par défaut
Cette section vous explique comment configurer l'inférence pour le modèle Llama 3.2 Vision sur Vertex AI à l'aide de la route de prédiction par défaut. Vous utiliserez la bibliothèque vLLM pour une diffusion efficace et interagirez avec le modèle en envoyant une requête visuelle combinée à du texte.
Pour commencer, assurez-vous que le point de terminaison de votre modèle est déployé et prêt à effectuer des prédictions.
Étape 1 : Définissez votre requête et vos paramètres
Cet exemple fournit une URL d'image et une requête textuelle, que le modèle traitera pour générer une réponse.
 Figure 6 : Exemple d'image d'entrée pour inviter Llama 3.2
Figure 6 : Exemple d'image d'entrée pour inviter Llama 3.2
image_url = "https://images.pexels.com/photos/1254140/pexels-photo-1254140.jpeg"
raw_prompt = "This is a picture of"
# Reference prompt formatting guidelines here: https://www.Llama.com/docs/model-cards-and-prompt-formats/Llama3_2/#-base-model-prompt
prompt = f"<|begin_of_text|><|image|>{raw_prompt}"
Étape 2 : Configurez les paramètres de prédiction
Ajustez les paramètres suivants pour contrôler la réponse du modèle :
max_tokens = 64
temperature = 0.5
top_p = 0.95
Étape 3 : Préparez la requête de prédiction
Configurez la requête de prédiction avec l'URL de l'image, l'invite et d'autres paramètres.
instances = [
{
"prompt": prompt,
"multi_modal_data": {"image": image_url},
"max_tokens": max_tokens,
"temperature": temperature,
"top_p": top_p,
},
]
Étape 4 : Effectuer la prédiction
Envoyez la requête à votre point de terminaison Vertex AI et traitez la réponse :
response = endpoints["vllm_gpu"].predict(instances=instances)
for raw_prediction in response.predictions:
prediction = raw_prediction.split("Output:")
print(prediction[1])
Si vous rencontrez un problème de délai d'attente (par exemple, ServiceUnavailable: 503 Took too
long to respond when processing), essayez de réduire la valeur max_tokens à un nombre inférieur, tel que 20, pour réduire le temps de réponse.
Inférence avec vLLM sur Vertex AI à l'aide d'OpenAI Chat Completion
Cette section explique comment effectuer une inférence sur les modèles Llama 3.2 Vision à l'aide de l'API OpenAI Chat Completions sur Vertex AI. Cette approche vous permet d'utiliser des fonctionnalités multimodales en envoyant à la fois des images et des requêtes textuelles au modèle pour obtenir des réponses plus interactives.
Étape 1 : Exécutez le déploiement du modèle Llama 3.2 Vision Instruct
Exécutez la fonction de déploiement avec le modèle et les paramètres configurés. La fonction renverra les instances de modèle et de point de terminaison, que vous pourrez utiliser pour l'inférence.
base_model_name = "Llama-3.2-11B-Vision-Instruct"
hf_model_id = f"meta-llama/{base_model_name}"
model_name = common_util.get_job_name_with_datetime(prefix=f"{base_model_name}-serve-vllm")
model, endpoint = deploy_model_vllm(
model_name=model_name
model_id=hf_model_id,
base_model_id=hf_model_id,
service_account=SERVICE_ACCOUNT,
machine_type="a2-highgpu-1g",
accelerator_type="NVIDIA_TESLA_A100",
accelerator_count=1,
gpu_memory_utilization=0.9,
max_model_len=4096,
enforce_eager=True,
max_num_seqs=12,
)
Étape 2 : Configurez la ressource de point de terminaison
Commencez par configurer le nom de ressource du point de terminaison pour votre déploiement Vertex AI.
ENDPOINT_RESOURCE_NAME = "projects/{}/locations/{}/endpoints/{}".format(
PROJECT_ID, REGION, endpoint.name
)
Étape 3 : Installez le SDK OpenAI et les bibliothèques d'authentification
Pour envoyer des requêtes à l'aide du SDK d'OpenAI, assurez-vous que les bibliothèques nécessaires sont installées :
!pip install -qU openai google-auth requests
Étape 4 : Définir les paramètres d'entrée pour la finalisation du chat
Configurez l'URL de votre image et la requête textuelle qui seront envoyées au modèle. Ajustez max_tokens et temperature pour contrôler respectivement la longueur et le caractère aléatoire de la réponse.
user_image = "https://images.freeimages.com/images/large-previews/ab3/puppy-2-1404644.jpg"
user_message = "Describe this image?"
max_tokens = 50
temperature = 1.0
Étape 5 : Configurez l'authentification et l'URL de base
Récupérez vos identifiants et définissez l'URL de base pour les requêtes API.
import google.auth
import openai
creds, project = google.auth.default()
auth_req = google.auth.transport.requests.Request()
creds.refresh(auth_req)
BASE_URL = (
f"https://{REGION}-aiplatform.googleapis.com/v1beta1/{ENDPOINT_RESOURCE_NAME}"
)
try:
if use_dedicated_endpoint:
BASE_URL = f"https://{DEDICATED_ENDPOINT_DNS}/v1beta1/{ENDPOINT_RESOURCE_NAME}"
except NameError:
pass
Étape 6 : Envoyez une requête Chat Completion
À l'aide de l'API Chat Completions d'OpenAI, envoyez l'image et la requête textuelle à votre point de terminaison Vertex AI :
client = openai.OpenAI(base_url=BASE_URL, api_key=creds.token)
model_response = client.chat.completions.create(
model="",
messages=[
{
"role": "user",
"content": [
{"type": "image_url", "image_url": {"url": user_image}},
{"type": "text", "text": user_message},
],
}
],
temperature=temperature,
max_tokens=max_tokens,
)
print(model_response)
(Facultatif) Étape 7 : Se reconnecter à un point de terminaison existant
Pour vous reconnecter à un point de terminaison créé précédemment, utilisez son ID. Cette étape est utile si vous souhaitez réutiliser un point de terminaison au lieu d'en créer un.
endpoint_name = ""
aip_endpoint_name = (
f"projects/{PROJECT_ID}/locations/{REGION}/endpoints/{endpoint_name}"
)
endpoint = aiplatform.Endpoint(aip_endpoint_name)
Cette configuration vous permet de basculer entre les points de terminaison nouvellement créés et ceux existants selon vos besoins, ce qui simplifie les tests et le déploiement.
Nettoyage
Pour éviter les frais récurrents et libérer des ressources, veillez à supprimer les modèles et les points de terminaison déployés, ainsi que le bucket de stockage utilisé pour ce test (facultatif).
Étape 1 : Supprimez les points de terminaison et les modèles
Le code suivant annule le déploiement de chaque modèle et supprime les points de terminaison associés :
# Undeploy model and delete endpoint
for endpoint in endpoints.values():
endpoint.delete(force=True)
# Delete models
for model in models.values():
model.delete()
Étape 2 : (Facultatif) Supprimer le bucket Cloud Storage
Si vous avez créé un bucket Cloud Storage spécifiquement pour cette expérience, vous pouvez le supprimer en définissant delete_bucket sur "True". Cette étape est facultative, mais recommandée si vous n'avez plus besoin du bucket.
delete_bucket = False
if delete_bucket:
! gsutil -m rm -r $BUCKET_NAME
En suivant ces étapes, vous vous assurez que toutes les ressources utilisées dans ce tutoriel sont nettoyées, ce qui réduit les coûts inutiles associés à l'expérience.
Déboguer les problèmes courants
Cette section explique comment identifier et résoudre les problèmes courants rencontrés lors du déploiement et de l'inférence de modèles vLLM sur Vertex AI.
Vérifier les journaux
Consultez les journaux pour identifier la cause première des échecs de déploiement ou des comportements inattendus :
- Accédez à la console Vertex AI Prediction : accédez à la console Vertex AI Prediction dans la console Google Cloud .
- Sélectionnez le point de terminaison : cliquez sur le point de terminaison qui pose problème. L'état doit indiquer si le déploiement a échoué.
- Afficher les journaux : cliquez sur le point de terminaison, puis accédez à l'onglet Journaux ou cliquez sur Afficher les journaux. Vous êtes redirigé vers Cloud Logging, filtré pour afficher les journaux spécifiques à ce point de terminaison et au déploiement du modèle. Vous pouvez également accéder directement aux journaux via le service Cloud Logging.
- Analysez les journaux : examinez les entrées du journal pour identifier les messages d'erreur, les avertissements et d'autres informations pertinentes. Affichez les codes temporels pour corréler les entrées de journal avec des actions spécifiques. Recherchez les problèmes liés aux contraintes de ressources (mémoire et processeur), aux problèmes d'authentification ou aux erreurs de configuration.
Problème courant 1 : CUDA Out of Memory (OOM) lors du déploiement
Les erreurs CUDA de mémoire insuffisante (OOM, Out Of Memory) se produisent lorsque l'utilisation de la mémoire par le modèle dépasse la capacité de GPU disponible.
Dans le cas du modèle de texte uniquement, nous avons utilisé les arguments de moteur suivants :
base_model_name = "Meta-Llama-3.1-8B"
hf_model_id = f"meta-llama/{base_model_name}"
accelerator_type = "NVIDIA_L4"
accelerator_count = 1
machine_type = "g2-standard-12"
accelerator_count: int = 1
gpu_memory_utilization = 0.9
max_model_len = 4096
dtype = "auto"
max_num_seqs = 256
Dans le cas du modèle multimodal, nous avons utilisé les arguments de moteur suivants :
base_model_name = "Llama-3.2-11B-Vision-Instruct"
hf_model_id = f"meta-llama/{base_model_name}"
accelerator_type = "NVIDIA_L4"
accelerator_count = 1
machine_type = "g2-standard-12"
accelerator_count: int = 1
gpu_memory_utilization = 0.9
max_model_len = 4096
dtype = "auto"
max_num_seqs = 12
Le déploiement du modèle multimodal avec max_num_seqs = 256, comme nous l'avons fait pour le modèle de texte uniquement, peut entraîner l'erreur suivante :
[rank0]: torch.OutOfMemoryError: CUDA out of memory. Tried to allocate 3.91 GiB. GPU 0 has a total capacity of 39.38 GiB of which 3.76 GiB is free. Including non-PyTorch memory, this process has 0 bytes memory in use. Of the allocated memory 34.94 GiB is allocated by PyTorch, and 175.15 MiB is reserved by PyTorch but unallocated. If reserved but unallocated memory is large try setting PYTORCH_CUDA_ALLOC_CONF=expandable_segments:True to avoid fragmentation. See documentation for Memory Management (https://pytorch.org/docs/stable/notes/cuda.html#environment-variables)
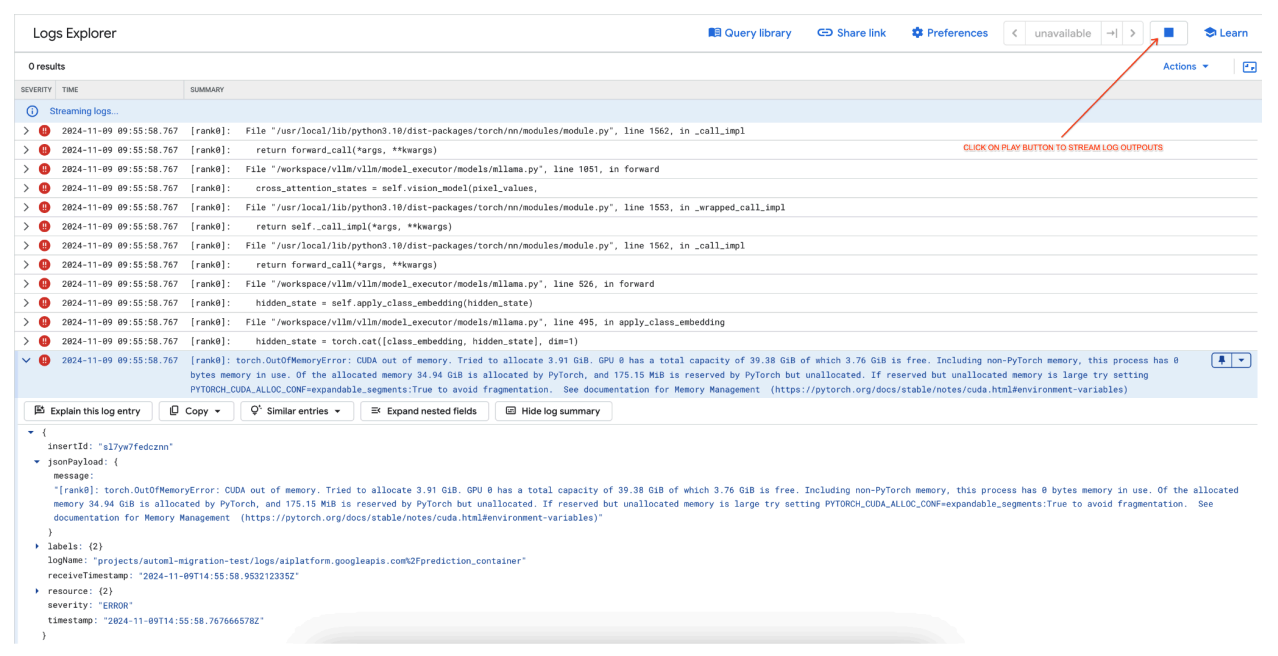 Figure 7 : Journal des erreurs GPU "Out of Memory" (OOM)
Figure 7 : Journal des erreurs GPU "Out of Memory" (OOM)
Comprendre max_num_seqs et la mémoire GPU :
- Le paramètre
max_num_seqsdéfinit le nombre maximal de requêtes simultanées que le modèle peut gérer. - Chaque séquence traitée par le modèle consomme de la mémoire GPU. L'utilisation totale de la mémoire est proportionnelle à
max_num_seqsfois la mémoire par séquence. - Les modèles de texte uniquement (comme Meta-Llama-3.1-8B) consomment généralement moins de mémoire par séquence que les modèles multimodaux (comme Llama-3.2-11B-Vision-Instruct), qui traitent à la fois du texte et des images.
Consultez le journal d'erreurs (figure 8) :
- Le journal affiche un
torch.OutOfMemoryErrorlors de la tentative d'allocation de mémoire sur le GPU. - Cette erreur se produit parce que l'utilisation de la mémoire par le modèle dépasse la capacité GPU disponible. Le GPU NVIDIA L4 dispose de 24 Go. Si vous définissez le paramètre
max_num_seqssur une valeur trop élevée pour le modèle multimodal, cela provoque un dépassement de capacité. - Le journal suggère de définir
PYTORCH_CUDA_ALLOC_CONF=expandable_segments:Truepour améliorer la gestion de la mémoire, bien que le problème principal ici soit une utilisation élevée de la mémoire.
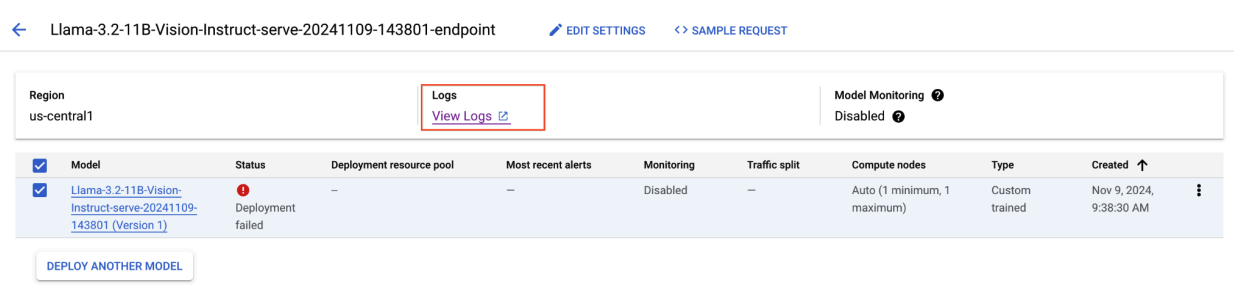 Figure 8 : Échec du déploiement de Llama 3.2
Figure 8 : Échec du déploiement de Llama 3.2
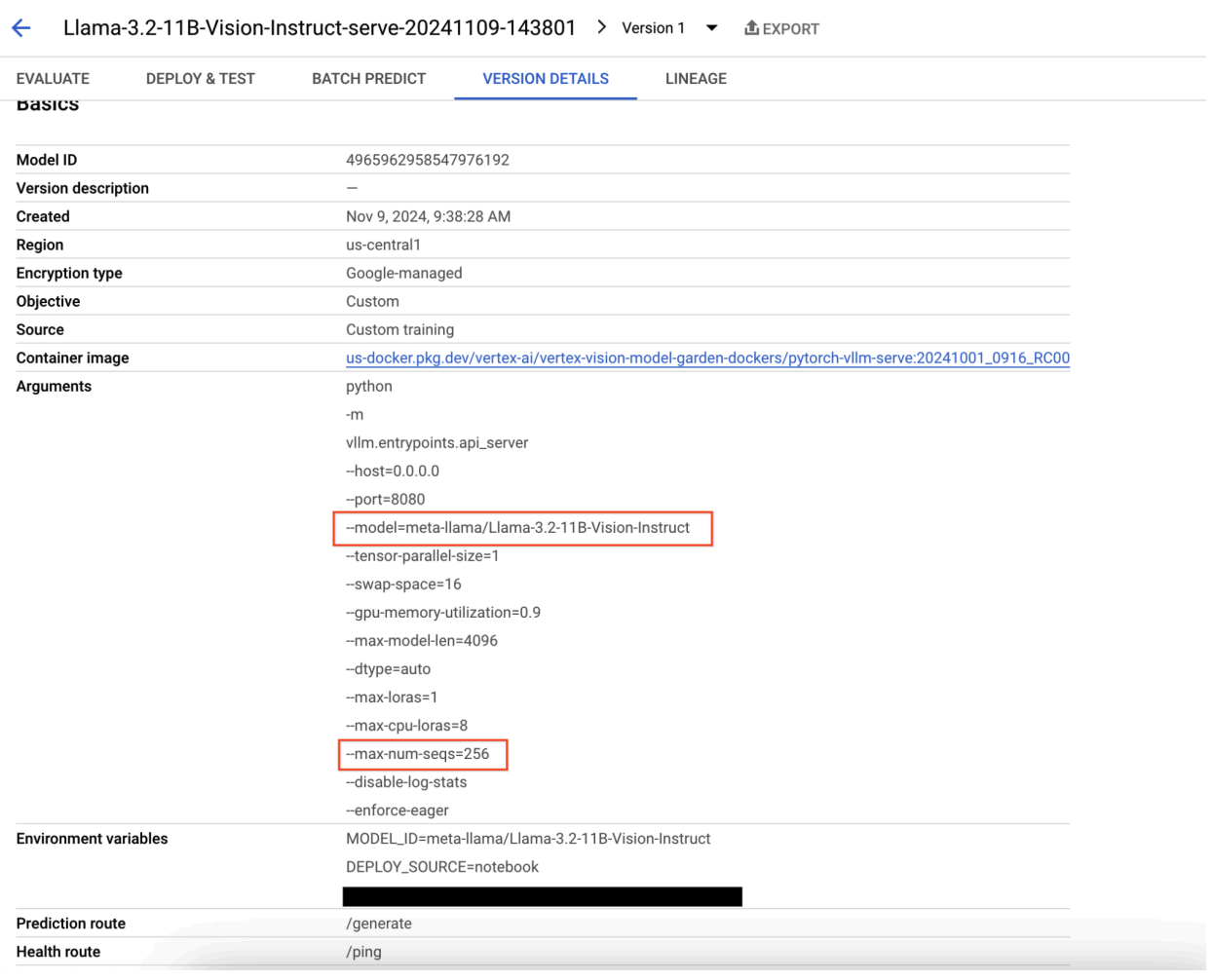 Figure 9 : Panneau "Détails de la version du modèle"
Figure 9 : Panneau "Détails de la version du modèle"
Pour résoudre ce problème, accédez à la console Vertex AI Prediction, puis cliquez sur le point de terminaison. L'état doit indiquer que le déploiement a échoué. Cliquez pour afficher les journaux. Vérifiez que max-num-seqs = 256. Cette valeur est trop élevée pour Llama-3.2-11B-Vision-Instruct. Une valeur plus appropriée serait de 12.
Problème courant 2 : Jeton Hugging Face requis
Les erreurs de jeton Hugging Face se produisent lorsque le modèle est soumis à un accès restreint et nécessite des identifiants d'authentification appropriés pour y accéder.
La capture d'écran suivante affiche une entrée de journal dans l'explorateur de journaux de Google Cloud, qui montre un message d'erreur lié à l'accès au modèle Meta LLaMA-3.2-11B-Vision hébergé sur Hugging Face. Cette erreur indique que l'accès au modèle est restreint et qu'une authentification est requise pour continuer. Le message indique spécifiquement "Impossible d'accéder au dépôt fermé pour l'URL", ce qui souligne que le modèle est fermé et nécessite des identifiants d'authentification appropriés pour y accéder. Cette entrée de journal peut vous aider à résoudre les problèmes d'authentification lorsque vous travaillez avec des ressources restreintes dans des dépôts externes.
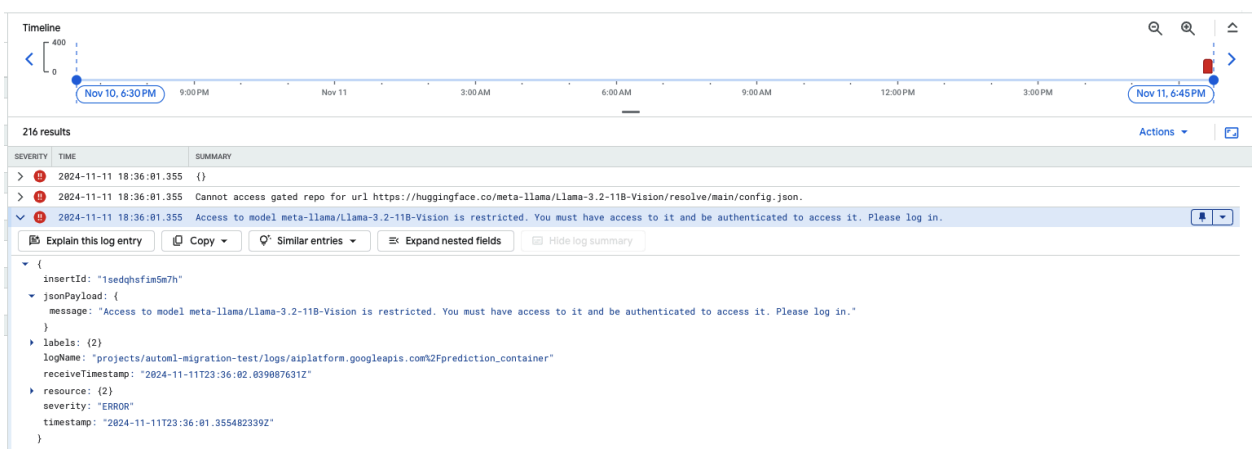 Figure 10 : Erreur de jeton Hugging Face
Figure 10 : Erreur de jeton Hugging Face
Pour résoudre ce problème, vérifiez les autorisations de votre jeton d'accès Hugging Face. Copiez le dernier jeton et déployez un nouveau point de terminaison.
Problème courant 3 : Modèle de chat requis
Les erreurs de modèle de chat se produisent lorsque le modèle de chat par défaut n'est plus autorisé et qu'un modèle de chat personnalisé doit être fourni si le tokenizer n'en définit pas.
Cette capture d'écran montre une entrée de journal dans l'explorateur de journaux de Google Cloud, où une erreur ValueError se produit en raison d'un modèle de chat manquant dans la version 4.44 de la bibliothèque Transformers. Le message d'erreur indique que le modèle de chat par défaut n'est plus autorisé et qu'un modèle de chat personnalisé doit être fourni si le tokenizer n'en définit pas. Cette erreur met en évidence une modification récente de la bibliothèque qui nécessite une définition explicite d'un modèle de chat. Elle est utile pour déboguer les problèmes lors du déploiement d'applications basées sur le chat.
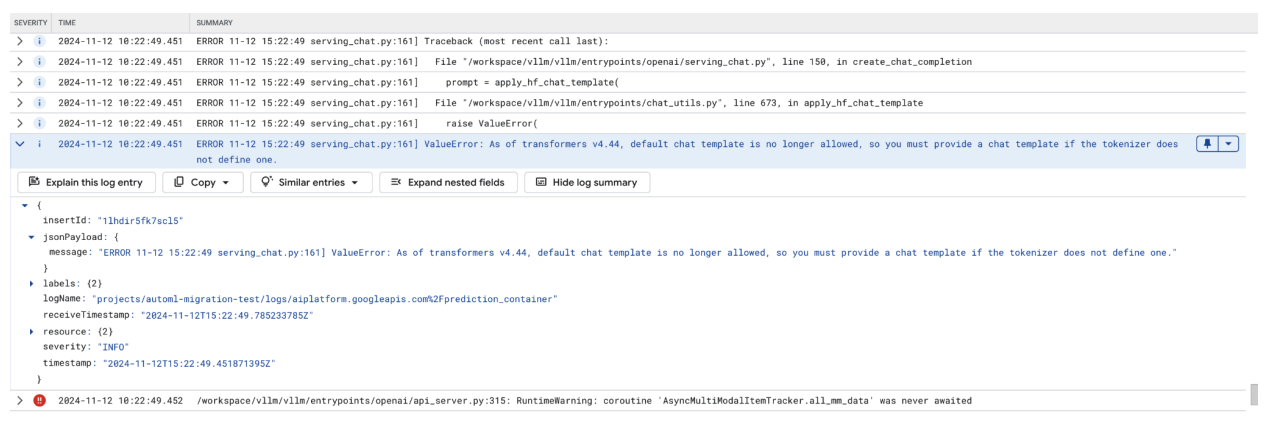 Figure 11 : Modèle de chat requis
Figure 11 : Modèle de chat requis
Pour éviter cela, assurez-vous de fournir un modèle de chat lors du déploiement à l'aide de l'argument d'entrée --chat-template. Vous trouverez des exemples de modèles dans le dépôt d'exemples vLLM.
Problème courant 4 : Longueur de séquence maximale du modèle
Les erreurs de longueur de séquence maximale du modèle se produisent lorsque la longueur de séquence maximale du modèle (4 096) est supérieure au nombre maximal de jetons pouvant être stockés dans le cache KV (2 256).
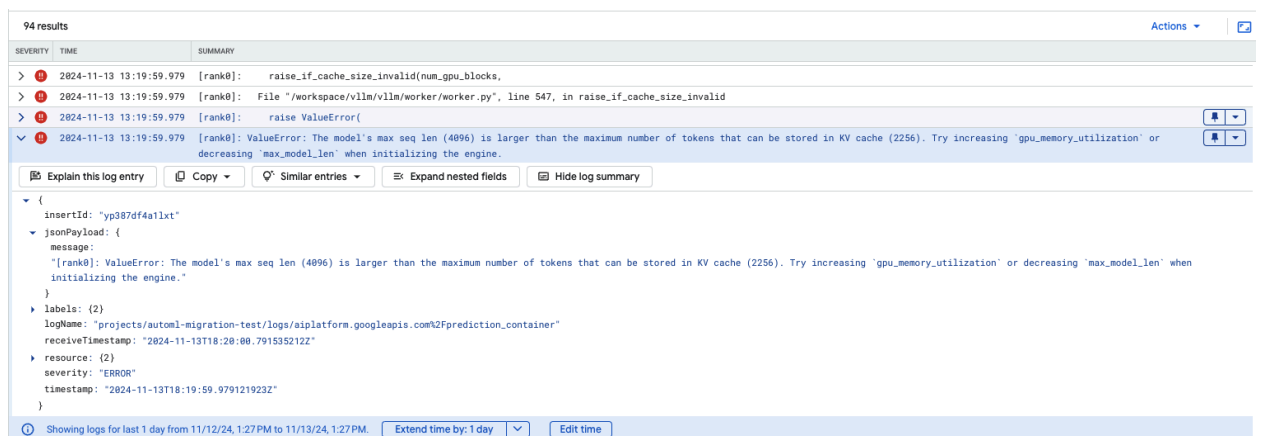 Figure 12 : Longueur de séquence maximale trop élevée
Figure 12 : Longueur de séquence maximale trop élevée
ValueError: The model's max seq len (4096) is larger than the maximum number of
tokens that can be stored in KV cache (2256). Essayez d'augmenter gpu_memory_utilization ou de diminuer max_model_len lors de l'initialisation du moteur.
Pour résoudre ce problème, définissez max_model_len sur 2048, ce qui est inférieur à 2256. Pour résoudre ce problème, vous pouvez également utiliser des GPU plus nombreux ou plus grands. Si vous choisissez d'utiliser plus de GPU, vous devrez définir la taille du parallélisme tensoriel de manière appropriée.
Notes de version du conteneur vLLM Model Garden
Versions principales
vLLM standard
Date de sortie |
Architecture |
Version de vLLM |
URI du conteneur |
|---|---|---|---|
| 17 juillet 2025 | ARM |
v0.9.2 |
us-docker.pkg.dev/vertex-ai/vertex-vision-model-garden-dockers/pytorch-vllm-serve:20250717_0916_arm_RC01 |
| 10 juillet 2025 | x86 |
v0.9.2 |
us-docker.pkg.dev/vertex-ai/vertex-vision-model-garden-dockers/pytorch-vllm-serve:20250710_0916_RC01 |
| 20 juin 2025 | x86 |
Après la version 0.9.1, commit |
us-docker.pkg.dev/vertex-ai/vertex-vision-model-garden-dockers/pytorch-vllm-serve:20250620_0916_RC01 |
| 11 juin 2025 | x86 |
v0.9.1 |
us-docker.pkg.dev/vertex-ai/vertex-vision-model-garden-dockers/pytorch-vllm-serve:20250611_0916_RC01 |
| 2 juin 2025 | x86 |
v0.9.0 |
us-docker.pkg.dev/vertex-ai/vertex-vision-model-garden-dockers/pytorch-vllm-serve:20250601_0916_RC01 |
| 6 mai 2025 | x86 |
v0.8.5.post1 |
us-docker.pkg.dev/vertex-ai/vertex-vision-model-garden-dockers/pytorch-vllm-serve:20250506_0916_RC01 |
| 29 avril 2025 | x86 |
v0.8.4 |
us-docker.pkg.dev/vertex-ai/vertex-vision-model-garden-dockers/pytorch-vllm-serve:20250429_0916_RC01, 20250430_0916_RC00_maas |
| 17 avril 2025 | x86 |
v0.8.4 |
us-docker.pkg.dev/vertex-ai/vertex-vision-model-garden-dockers/pytorch-vllm-serve:20250417_0916_RC01 |
| 10 avril 2025 | x86 |
Après la version 0.8.3, commit |
us-docker.pkg.dev/vertex-ai/vertex-vision-model-garden-dockers/pytorch-vllm-serve:20250410_0917_RC01 |
| Apr 7, 2025 | x86 |
v0.8.3 |
us-docker.pkg.dev/vertex-ai/vertex-vision-model-garden-dockers/pytorch-vllm-serve:20250407_0917_RC01, 20250407_0917_RC0120250429_0916_RC00_maas |
| Apr 7, 2025 | x86 |
v0.8.1 |
us-docker.pkg.dev/vertex-ai/vertex-vision-model-garden-dockers/pytorch-vllm-serve:20250404_0916_RC01 |
| 5 avril 2025 | x86 |
Past v0.8.2, commit |
us-docker.pkg.dev/vertex-ai/vertex-vision-model-garden-dockers/pytorch-vllm-serve:20250405_1205_RC01 |
| 31 mars 2025 | x86 |
v0.8.1 |
us-docker.pkg.dev/vertex-ai/vertex-vision-model-garden-dockers/pytorch-vllm-serve:20250401_0916_RC01 |
| 26 mars 2025 | x86 |
v0.8.1 |
us-docker.pkg.dev/vertex-ai/vertex-vision-model-garden-dockers/pytorch-vllm-serve:20250327_0916_RC01 |
| 23 mars 2025 | x86 |
v0.8.1 |
us-docker.pkg.dev/vertex-ai/vertex-vision-model-garden-dockers/pytorch-vllm-serve:20250324_0916_RC01 |
| 21 mars 2025 | x86 |
v0.8.1 |
us-docker.pkg.dev/vertex-ai/vertex-vision-model-garden-dockers/pytorch-vllm-serve:20250321_0916_RC01 |
| 11 mars 2025 | x86 |
Après la version 0.7.3, commit |
us-docker.pkg.dev/vertex-ai/vertex-vision-model-garden-dockers/pytorch-vllm-serve:20250312_0916_RC01 |
| 3 mars 2025 | x86 |
v0.7.2 |
us-docker.pkg.dev/vertex-ai/vertex-vision-model-garden-dockers/pytorch-vllm-serve:20250304_0916_RC01 |
| 14 janv. 2025 | x86 |
v0.6.4.post1 |
us-docker.pkg.dev/vertex-ai/vertex-vision-model-garden-dockers/pytorch-vllm-serve:20250114_0916_RC00_maas |
| 2 déc. 2024 | x86 |
v0.6.4.post1 |
us-docker.pkg.dev/vertex-ai/vertex-vision-model-garden-dockers/pytorch-vllm-serve:20241202_0916_RC00_maas |
| 12 novembre 2024 | x86 |
v0.6.2 |
us-docker.pkg.dev/vertex-ai/vertex-vision-model-garden-dockers/pytorch-vllm-serve:20241112_0916_RC00_maas |
| 16 octobre 2024 | x86 |
v0.6.2 |
us-docker.pkg.dev/vertex-ai/vertex-vision-model-garden-dockers/pytorch-vllm-serve:20241016_0916_RC00_maas |
vLLM optimisé
Date de sortie |
Architecture |
URI du conteneur |
|---|---|---|
| 21 janvier 2025 | x86 |
us-docker.pkg.dev/vertex-ai-restricted/vertex-vision-model-garden-dockers/pytorch-vllm-optimized-serve:20250121_0835_RC00 |
| 29 octobre 2024 | x86 |
us-docker.pkg.dev/vertex-ai-restricted/vertex-vision-model-garden-dockers/pytorch-vllm-optimized-serve:20241029_0835_RC00 |
Autres versions
La liste complète des versions de conteneurs vLLM standards VMG est disponible sur la page Artifact Registry.
Les versions de vLLM-TPU en état expérimental sont taguées avec <yyyymmdd_hhmm_tpu_experimental_RC00>.