Este tutorial explica como implementar o modelo Meta-Llama-3.1-8B na Vertex AI. Vai aprender a implementar pontos finais e a otimizar para as suas necessidades específicas. Se tiver cargas de trabalho com tolerância a falhas, pode otimizar os custos usando VMs do Spot. Se quiser garantir a disponibilidade, use as reservas do Compute Engine. Vai aprender a implementar pontos finais que usam:
- VMs do Spot: use instâncias aprovisionadas no modo Spot para obter poupanças de custos significativas.
- Reservas: garanta a disponibilidade de recursos para um desempenho previsível, especialmente para cargas de trabalho de produção. Este tutorial demonstra a utilização de reservas automáticas (
ANY_RESERVATION) e específicas (SPECIFIC_RESERVATION).
Para mais informações, consulte os artigos VMs Spot ou Reservas de recursos do Compute Engine.
Pré-requisitos
Antes de começar, conclua os seguintes pré-requisitos:
- Um Google Cloud projeto com a faturação ativada.
- As APIs Vertex AI e Compute Engine ativadas.
- Quota suficiente para o tipo de máquina e o acelerador que pretende usar, como GPUs NVIDIA L4. Para verificar as suas quotas, consulte o artigo Quotas e limites do sistema na Google Cloud consola.
- Uma conta do Hugging Face e um símbolo de acesso do utilizador com acesso de leitura.
- Se estiver a usar reservas partilhadas, conceda autorizações de IAM entre projetos. Todas essas autorizações estão abrangidas no bloco de notas.
Implemente em VMs do Spot
As secções seguintes explicam o processo de configuração do Google Cloud projeto, configuração da autenticação do Hugging Face, implementação do modelo Llama-3.1 através de VMs de spot ou reservas, e teste da implementação.
1. Configure o seu Google Cloud projeto e reserva partilhada
Abra o bloco de notas do Colab Enterprise.
Na primeira secção, defina as variáveis PROJECT_ID, SHARED_PROJECT_ID (se aplicável), BUCKET_URI e REGION no bloco de notas do Colab.
O bloco de notas concede a função compute.viewer à conta de serviço de ambos os projetos.
Se pretender usar uma reserva criada num projeto diferente na mesma organização, certifique-se de que atribui a função compute.viewer à conta de serviço principal (P4SA) de ambos os projetos. O código do bloco de notas automatiza este processo, mas certifique-se de que SHARED_PROJECT_ID está definido corretamente. Esta autorização entre projetos permite que o ponto final da Vertex AI no seu projeto principal veja e use a capacidade de reserva no projeto partilhado.
2. Configure a autenticação do Hugging Face
Para transferir o modelo Llama-3.1, tem de fornecer a sua chave de acesso de utilizador do Hugging Face na variável HF_TOKEN no bloco de notas do Colab. Se não indicar um, recebe o seguinte erro: Cannot access gated repository for URL.
 Figura 1: definições do token de acesso do Hugging Face
Figura 1: definições do token de acesso do Hugging Face
3. Implemente com a VM do Spot
Para implementar o modelo Llama numa VM Spot, navegue para a secção "Implementação do ponto final da VM Spot do Vertex AI" no bloco de notas do Colab e defina is_spot=True.
base_model_name = "Meta-Llama-3.1-8B"
hf_model_id = "meta-llama/" + base_model_name
if "8b" in base_model_name.lower():
accelerator_type = "NVIDIA_L4"
machine_type = "g2-standard-12"
accelerator_count = 1
max_loras = 5
else:
raise ValueError(
f"Recommended GPU setting not found for: {accelerator_type} and {base_model_name}."
)
common_util.check_quota(
project_id=PROJECT_ID,
region=REGION,
accelerator_type=accelerator_type,
accelerator_count=accelerator_count,
is_for_training=False,
)
gpu_memory_utilization = 0.95
max_model_len = 8192
models["vllm_gpu_spotvm"], endpoints["vllm_gpu_spotvm"] = deploy_model_vllm(
model_name=common_util.get_job_name_with_datetime(prefix="llama3_1-serve-spotvm"),
model_id=hf_model_id,
base_model_id=hf_model_id,
service_account=SERVICE_ACCOUNT,
machine_type=machine_type,
accelerator_type=accelerator_type,
accelerator_count=accelerator_count,
gpu_memory_utilization=gpu_memory_utilization,
max_model_len=max_model_len,
max_loras=max_loras,
enforce_eager=True,
enable_lora=True,
use_dedicated_endpoint=False,
model_type="llama3.1",
is_spot=True,
)
Implemente em instâncias de reserva partilhadas
As secções seguintes explicam o processo de criação de uma reserva partilhada, configuração das definições de reserva, implementação do modelo Llama-3.1 através de ANY_RESERVATION ou SPECIFIC_RESERVATION e teste da implementação.
1. Crie uma reserva partilhada
Para configurar as suas reservas, aceda à secção "Configure as reservas para as previsões do Vertex AI" do bloco de notas. Defina as variáveis necessárias para a reserva, como RES_ZONE, RESERVATION_NAME, RES_MACHINE_TYPE, RES_ACCELERATOR_TYPE e RES_ACCELERATOR_COUNT.
Tem de definir RES_ZONE como {REGION}-{availability_zone}
RES_ZONE = "a"
RES_ZONE = f"{REGION}-{RES_ZONE}"
RESERVATION_NAME = "shared-reservation-1"
RESERVATION_NAME = f"{PROJECT_ID}-{RESERVATION_NAME}"
RES_MACHINE_TYPE = "g2-standard-12"
RES_ACCELERATOR_TYPE = "nvidia-l4"
RES_ACCELERATOR_COUNT = 1
rev_names.append(RESERVATION_NAME)
create_reservation(
res_project_id=PROJECT_ID,
res_zone=RES_ZONE,
res_name=RESERVATION_NAME,
res_machine_type=RES_MACHINE_TYPE,
res_accelerator_type=RES_ACCELERATOR_TYPE,
res_accelerator_count=RES_ACCELERATOR_COUNT,
shared_project_id=SHARED_PROJECT_ID,
)
2. Partilhe as suas reservas
Existem dois tipos de reservas: reservas de projeto único (a predefinição) e reservas partilhadas. As reservas de projeto único só podem ser usadas por VMs no mesmo projeto que a própria reserva. Por outro lado, as reservas partilhadas podem ser usadas por VMs no projeto onde a reserva está localizada, bem como por VMs em qualquer outro projeto com o qual a reserva tenha sido partilhada. A utilização de reservas partilhadas pode melhorar a utilização dos seus recursos reservados e reduzir o número geral de reservas que tem de criar e gerir. Este tutorial foca-se nas reservas partilhadas. Para mais informações, consulte o artigo Como funcionam as reservas partilhadas.
Antes de continuar, certifique-se de que "Partilha com outros serviços Google" a partir da Google Cloud consola, conforme mostrado na figura:
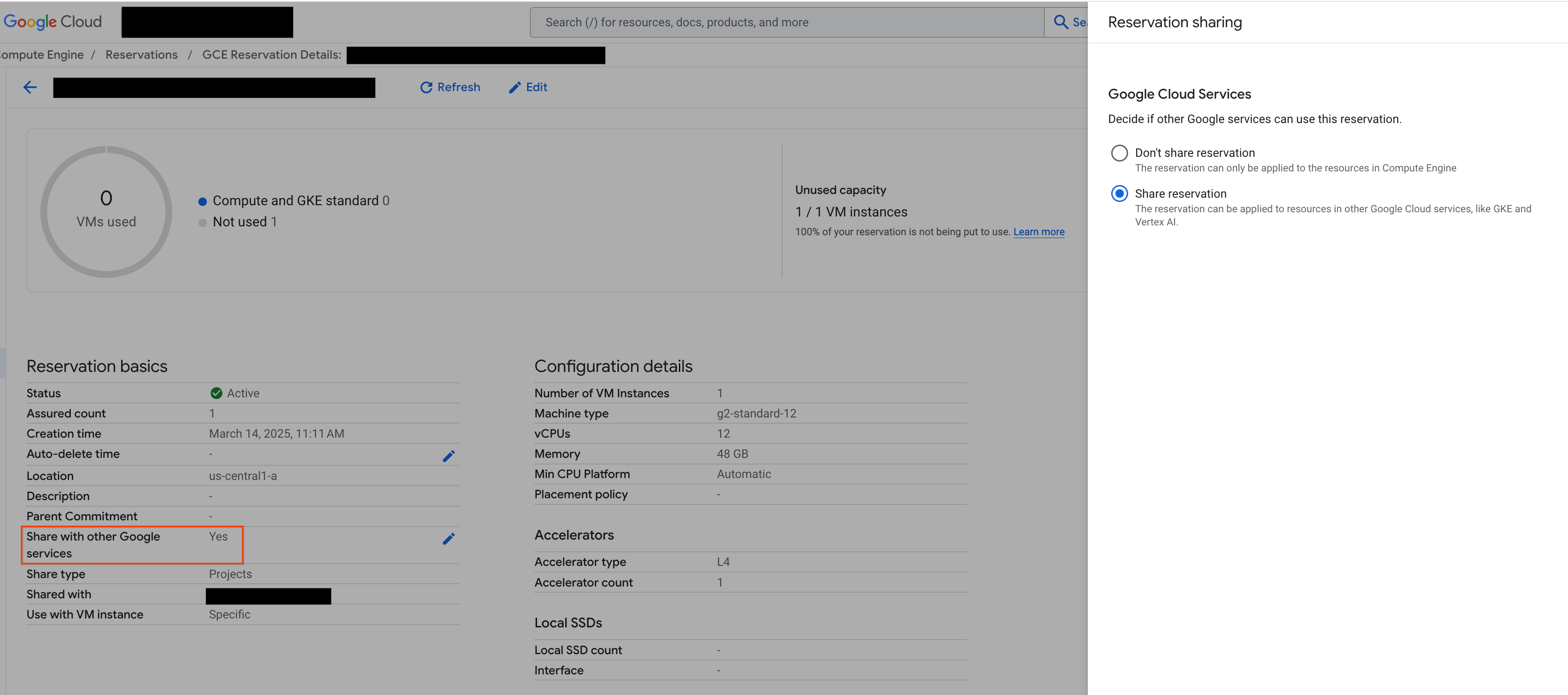 Figura 2: partilhe a reserva com outros serviços Google
Figura 2: partilhe a reserva com outros serviços Google
3. Implemente com ANY_RESERVATION
Para implementar o ponto final através do ANY_RESERVATION, aceda à secção "Implemente o ponto final do Llama-3.1 com o ANY_RESERVATION" do bloco de notas. Especifique as definições de implementação e, em seguida, defina reservation_affinity_type="ANY_RESERVATION". Em seguida, execute a célula para implementar o ponto final.
hf_model_id = "meta-llama/Meta-Llama-3.1-8B"
models["vllm_gpu_any_reserve"], endpoints["vllm_gpu_any_reserve"] = deploy_model_vllm(
model_name=common_util.get_job_name_with_datetime(
prefix=f"llama3_1-serve-any-{RESERVATION_NAME}"
),
model_id=hf_model_id,
base_model_id=hf_model_id,
service_account=SERVICE_ACCOUNT,
machine_type=MACHINE_TYPE,
accelerator_type=ACCELERATOR_TYPE,
accelerator_count=ACCELERATOR_COUNT,
model_type="llama3.1",
reservation_affinity_type="ANY_RESERVATION",
)
4. Teste o ponto final ANY_RESERVATION
Com o seu ponto final implementado, certifique-se de que testa alguns comandos para garantir que está implementado corretamente.
5. Implemente com SPECIFIC_RESERVATION
Para implementar o ponto final através do SPECIFIC_RESERVATION, aceda à secção "Implemente o ponto final do Llama-3.1 com o SPECIFIC_RESERVATION" do bloco de notas. Especifique os seguintes parâmetros: reservation_name, reservation_affinity_type="SPECIFIC_RESERVATION", reservation_project e reservation_zone. Em seguida, execute a célula para implementar o ponto final.
hf_model_id = "meta-llama/Meta-Llama-3.1-8B"
MACHINE_TYPE = "g2-standard-12"
ACCELERATOR_TYPE = "NVIDIA_L4"
ACCELERATOR_COUNT = 1
(
models["vllm_gpu_specific_reserve"],
endpoints["vllm_gpu_specific_reserve"],
) = deploy_model_vllm(
model_name=common_util.get_job_name_with_datetime(
prefix=f"llama3_1-serve-specific-{RESERVATION_NAME}"
),
model_id=hf_model_id,
base_model_id=hf_model_id,
service_account=SERVICE_ACCOUNT,
machine_type=MACHINE_TYPE,
accelerator_type=ACCELERATOR_TYPE,
accelerator_count=ACCELERATOR_COUNT,
model_type="llama3.1",
reservation_name=RESERVATION_NAME,
reservation_affinity_type="SPECIFIC_RESERVATION",
reservation_project=PROJECT_ID,
reservation_zone=RES_ZONE,
)
6. Teste o ponto final SPECIFIC_RESERVATION
Com o seu ponto final implementado, verifique se a reserva é usada pela previsão online da Vertex AI e certifique-se de que testa alguns comandos para garantir que é implementada corretamente.
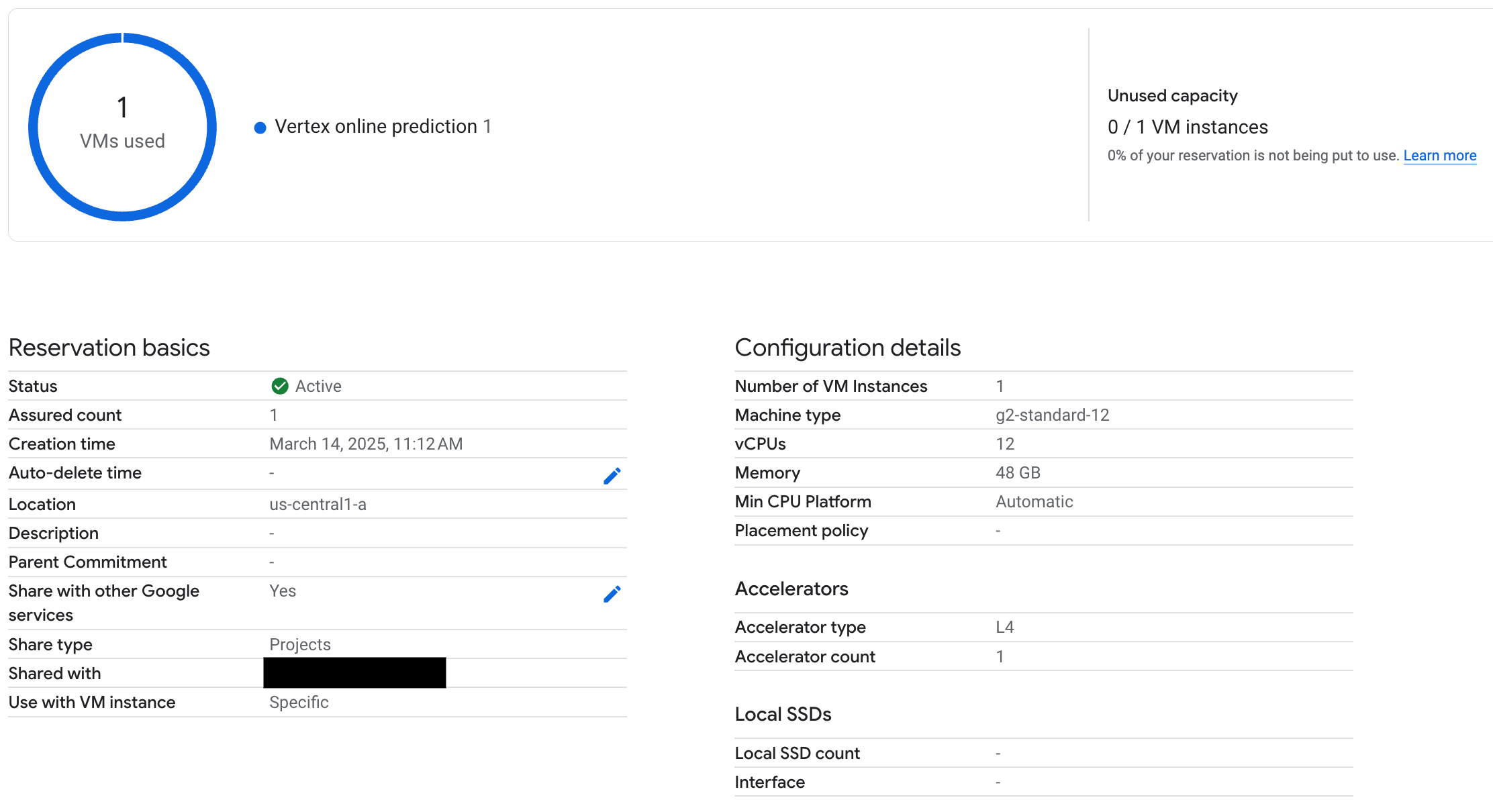 Figura 3: verifique se a reserva é usada pela previsão online do Vertex
Figura 3: verifique se a reserva é usada pela previsão online do Vertex
7. Limpar
Para evitar cobranças contínuas, elimine os modelos, os pontos finais e as reservas criados durante este tutorial. O bloco de notas do Colab fornece código na secção "Limpar" para automatizar este processo de limpeza.
Resolução de problemas
- Erros de token do Hugging Face: verifique se o seu token do Hugging Face tem autorizações
reade está corretamente definido no bloco de notas. - Erros de quota: verifique se tem quota de GPU suficiente na região para a qual está a fazer a implementação. Peça um aumento da quota, se necessário.
- Conflitos de reserva: certifique-se de que o tipo de máquina e a configuração do acelerador da implementação do seu ponto final correspondem às definições da sua reserva. Certifique-se de que as reservas estão ativadas para serem partilhadas com os serviços Google
Passos seguintes
- Explore diferentes variantes do modelo Llama 3.
- Saiba mais sobre as reservas com esta vista geral das reservas do Compute Engine.
- Saiba mais sobre as VMs do Spot com esta vista geral das VMs do Spot.