Ce tutoriel vous explique comment déployer le modèle Meta-Llama-3.1-8B sur Vertex AI. Vous apprendrez à déployer des points de terminaison et à les optimiser en fonction de vos besoins spécifiques. Si vos charges de travail sont tolérantes aux pannes, vous pouvez optimiser les coûts en utilisant des VM Spot. Pour vous assurer de la disponibilité, utilisez les réservations Compute Engine. Vous apprendrez à déployer des points de terminaison qui utilisent:
- VM Spot:utilisez des instances provisionnées de manière ponctuelle pour réaliser des économies importantes.
- Réservations:garantissent la disponibilité des ressources pour des performances prévisibles, en particulier pour les charges de travail de production. Ce tutoriel explique comment utiliser des réservations automatiques (
ANY_RESERVATION) et spécifiques (SPECIFIC_RESERVATION).
Pour en savoir plus, consultez VM Spot ou Réservations de ressources Compute Engine.
Prérequis
Avant de commencer, vérifiez que vous remplissez les conditions préalables suivantes:
- Un projet Google Cloud avec facturation activée
- Les API Vertex AI et Compute Engine sont activées.
- Quota suffisant pour le type de machine et l'accélérateur que vous prévoyez d'utiliser, tels que les GPU NVIDIA L4. Pour vérifier vos quotas, consultez Quotas et limites du système dans la console Google Cloud .
- Un compte Hugging Face et un jeton d'accès utilisateur avec accès en lecture.
- Si vous utilisez des réservations partagées, accordez des autorisations IAM entre les projets. Ces autorisations sont toutes abordées dans le notebook.
Déployer sur des VM Spot
Les sections suivantes vous guident dans le processus de configuration de votre Google Cloud projet, de configuration de l'authentification Hugging Face, de déploiement du modèle Llama-3.1 à l'aide de VM Spot ou de réservations, et de test du déploiement.
1. Configurer votre Google Cloud projet et votre réservation partagée
Ouvrez le notebook Colab Enterprise.
Dans la première section, définissez les variables PROJECT_ID, SHARED_PROJECT_ID (le cas échéant), BUCKET_URI et REGION dans le notebook Colab.
Le notebook attribue le rôle compute.viewer au compte de service des deux projets.
Si vous souhaitez utiliser une réservation créée dans un autre projet de la même organisation, veillez à attribuer le rôle compute.viewer au compte de service principal (P4SA) des deux projets. Le code du notebook automatisera cette opération, mais assurez-vous que SHARED_PROJECT_ID est correctement défini. Cette autorisation interprojet permet au point de terminaison Vertex AI de votre projet principal de voir et d'utiliser la capacité de réservation du projet partagé.
2. Configurer l'authentification Hugging Face
Pour télécharger le modèle Llama-3.1, vous devez fournir votre jeton d'accès utilisateur Hugging Face dans la variable HF_TOKEN du notebook Colab. Si vous ne fournissez pas de valeur, l'erreur suivante s'affiche: Cannot access gated repository for URL.
 Figure 1: Paramètres du jeton d'accès Hugging Face
Figure 1: Paramètres du jeton d'accès Hugging Face
3. Déployer avec une VM Spot
Pour déployer le modèle Llama sur une VM Spot, accédez à la section "Déploiement du point de terminaison Vertex AI sur une VM Spot" dans le notebook Colab et définissez is_spot=True.
base_model_name = "Meta-Llama-3.1-8B"
hf_model_id = "meta-llama/" + base_model_name
if "8b" in base_model_name.lower():
accelerator_type = "NVIDIA_L4"
machine_type = "g2-standard-12"
accelerator_count = 1
max_loras = 5
else:
raise ValueError(
f"Recommended GPU setting not found for: {accelerator_type} and {base_model_name}."
)
common_util.check_quota(
project_id=PROJECT_ID,
region=REGION,
accelerator_type=accelerator_type,
accelerator_count=accelerator_count,
is_for_training=False,
)
gpu_memory_utilization = 0.95
max_model_len = 8192
models["vllm_gpu_spotvm"], endpoints["vllm_gpu_spotvm"] = deploy_model_vllm(
model_name=common_util.get_job_name_with_datetime(prefix="llama3_1-serve-spotvm"),
model_id=hf_model_id,
base_model_id=hf_model_id,
service_account=SERVICE_ACCOUNT,
machine_type=machine_type,
accelerator_type=accelerator_type,
accelerator_count=accelerator_count,
gpu_memory_utilization=gpu_memory_utilization,
max_model_len=max_model_len,
max_loras=max_loras,
enforce_eager=True,
enable_lora=True,
use_dedicated_endpoint=False,
model_type="llama3.1",
is_spot=True,
)
Déployer sur des instances de réservation partagées
Les sections suivantes vous guident tout au long du processus de création d'une réservation partagée, de configuration des paramètres de réservation, de déploiement du modèle Llama-3.1 à l'aide de ANY_RESERVATION ou SPECIFIC_RESERVATION, et de test du déploiement.
1. Créer une réservation partagée
Pour configurer vos réservations, accédez à la section "Configurer les réservations pour les prédictions Vertex AI" du notebook. Définissez les variables requises pour la réservation, telles que RES_ZONE, RESERVATION_NAME, RES_MACHINE_TYPE, RES_ACCELERATOR_TYPE et RES_ACCELERATOR_COUNT.
Vous devez définir RES_ZONE sur {REGION}-{availability_zone}.
RES_ZONE = "a"
RES_ZONE = f"{REGION}-{RES_ZONE}"
RESERVATION_NAME = "shared-reservation-1"
RESERVATION_NAME = f"{PROJECT_ID}-{RESERVATION_NAME}"
RES_MACHINE_TYPE = "g2-standard-12"
RES_ACCELERATOR_TYPE = "nvidia-l4"
RES_ACCELERATOR_COUNT = 1
rev_names.append(RESERVATION_NAME)
create_reservation(
res_project_id=PROJECT_ID,
res_zone=RES_ZONE,
res_name=RESERVATION_NAME,
res_machine_type=RES_MACHINE_TYPE,
res_accelerator_type=RES_ACCELERATOR_TYPE,
res_accelerator_count=RES_ACCELERATOR_COUNT,
shared_project_id=SHARED_PROJECT_ID,
)
2. Partager vos réservations
Il existe deux types de réservations: les réservations à projet unique (par défaut) et les réservations partagées. Les réservations à projet unique ne peuvent être utilisées que par les VM du même projet que la réservation. En revanche, les réservations partagées peuvent être utilisées par les VM du projet où se trouve la réservation, ainsi que par les VM de tout autre projet avec lequel la réservation a été partagée. Les réservations partagées peuvent vous aider à améliorer l'utilisation de vos ressources réservées et à réduire le nombre global de réservations que vous devez créer et gérer. Ce tutoriel porte sur les réservations partagées. Pour en savoir plus, consultez la section Fonctionnement des réservations partagées.
Avant de continuer, assurez-vous d'activer l'option Partager avec d'autres services Google dans la console Google Cloud , comme illustré ci-dessous:
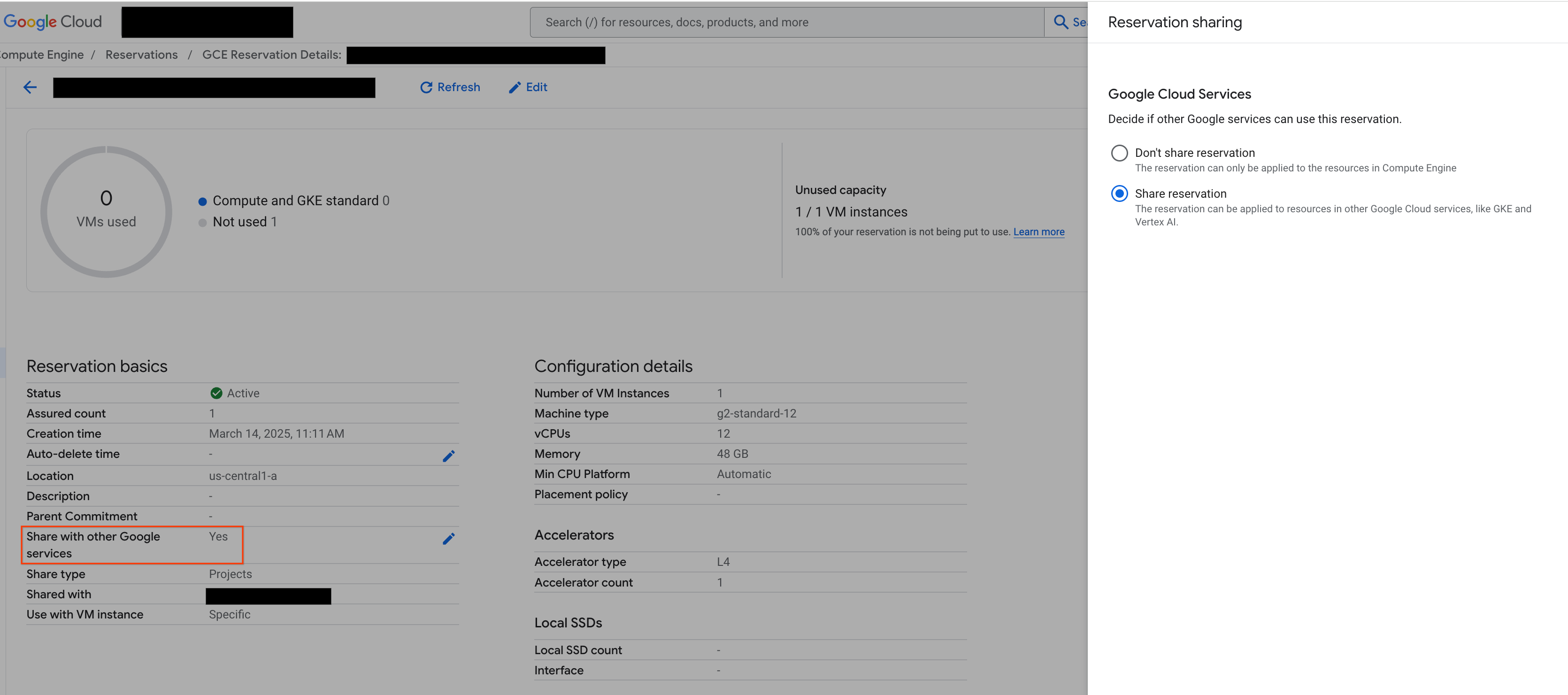 Figure 2: Partager la réservation avec d'autres services Google
Figure 2: Partager la réservation avec d'autres services Google
3. Déployer avec ANY_RESERVATION
Pour déployer le point de terminaison à l'aide de ANY_RESERVATION, accédez à la section "Déployer le point de terminaison Llama-3.1 avec ANY_RESERVATION" du notebook. Spécifiez vos paramètres de déploiement, puis définissez reservation_affinity_type="ANY_RESERVATION". Exécutez ensuite la cellule pour déployer le point de terminaison.
hf_model_id = "meta-llama/Meta-Llama-3.1-8B"
models["vllm_gpu_any_reserve"], endpoints["vllm_gpu_any_reserve"] = deploy_model_vllm(
model_name=common_util.get_job_name_with_datetime(
prefix=f"llama3_1-serve-any-{RESERVATION_NAME}"
),
model_id=hf_model_id,
base_model_id=hf_model_id,
service_account=SERVICE_ACCOUNT,
machine_type=MACHINE_TYPE,
accelerator_type=ACCELERATOR_TYPE,
accelerator_count=ACCELERATOR_COUNT,
model_type="llama3.1",
reservation_affinity_type="ANY_RESERVATION",
)
4. Tester le point de terminaison ANY_RESERVATION
Une fois votre point de terminaison déployé, assurez-vous de tester quelques invites pour vous assurer qu'il est correctement déployé.
5. Déployer avec SPECIFIC_RESERVATION
Pour déployer le point de terminaison à l'aide de SPECIFIC_RESERVATION, accédez à la section "Déployer le point de terminaison Llama-3.1 avec SPECIFIC_RESERVATION" du notebook. Spécifiez les paramètres suivants: reservation_name, reservation_affinity_type="SPECIFIC_RESERVATION", reservation_project et reservation_zone. Exécutez ensuite la cellule pour déployer le point de terminaison.
hf_model_id = "meta-llama/Meta-Llama-3.1-8B"
MACHINE_TYPE = "g2-standard-12"
ACCELERATOR_TYPE = "NVIDIA_L4"
ACCELERATOR_COUNT = 1
(
models["vllm_gpu_specific_reserve"],
endpoints["vllm_gpu_specific_reserve"],
) = deploy_model_vllm(
model_name=common_util.get_job_name_with_datetime(
prefix=f"llama3_1-serve-specific-{RESERVATION_NAME}"
),
model_id=hf_model_id,
base_model_id=hf_model_id,
service_account=SERVICE_ACCOUNT,
machine_type=MACHINE_TYPE,
accelerator_type=ACCELERATOR_TYPE,
accelerator_count=ACCELERATOR_COUNT,
model_type="llama3.1",
reservation_name=RESERVATION_NAME,
reservation_affinity_type="SPECIFIC_RESERVATION",
reservation_project=PROJECT_ID,
reservation_zone=RES_ZONE,
)
6. Tester le point de terminaison SPECIFIC_RESERVATION
Une fois votre point de terminaison déployé, vérifiez que la réservation est utilisée par la prédiction en ligne Vertex AI, et assurez-vous de tester quelques requêtes pour vous assurer qu'elle est correctement déployée.
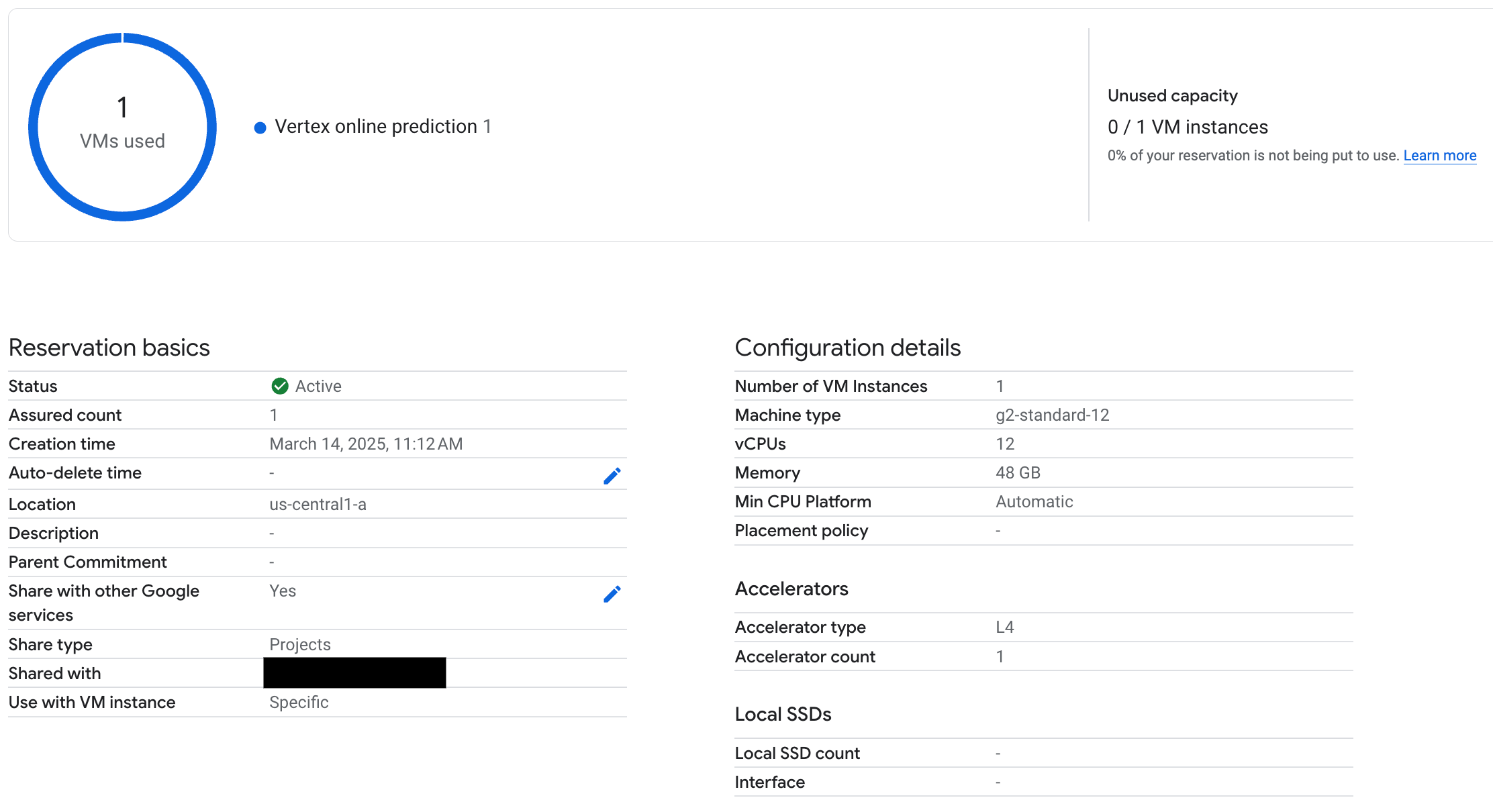 Figure 3: La réservation de vérification est utilisée par la prédiction en ligne Vertex
Figure 3: La réservation de vérification est utilisée par la prédiction en ligne Vertex
7. Effectuer un nettoyage
Pour éviter de payer des frais en continu, supprimez les modèles, les points de terminaison et les réservations créés au cours de ce tutoriel. Le notebook Colab fournit du code dans la section "Nettoyage" pour automatiser ce processus de nettoyage.
Dépannage
- Erreurs liées au jeton Hugging Face:vérifiez que votre jeton Hugging Face dispose d'autorisations
readet qu'il est correctement défini dans le notebook. - Erreurs de quota:vérifiez que vous disposez d'un quota de GPU suffisant dans la région où vous effectuez le déploiement. Demandez une augmentation de quota si nécessaire.
- Conflits de réservation:assurez-vous que le type de machine et la configuration de l'accélérateur de votre déploiement de point de terminaison correspondent aux paramètres de votre réservation. Assurez-vous que les réservations peuvent être partagées avec les services Google.
Étapes suivantes
- Découvrez les différentes variantes du modèle Llama 3.
- Pour en savoir plus sur les réservations, consultez la présentation des réservations Compute Engine.
- Pour en savoir plus sur les VM Spot, consultez Présentation des VM Spot.