La chiamata di funzione, nota anche come utilizzo di strumenti, fornisce all'LLM le definizioni di strumenti esterni (ad esempio una funzione get_current_weather). Quando elabora un prompt, il modello determina in modo intelligente se è necessario uno strumento e, in caso affermativo, restituisce dati strutturati che specificano lo strumento da chiamare e i relativi parametri (ad esempio get_current_weather(location='Boston')). La tua applicazione esegue quindi questo strumento, restituisce il risultato al modello, consentendogli di completare la risposta con informazioni dinamiche e reali o con il risultato di un'azione. In questo modo, il modello linguistico di grandi dimensioni viene collegato ai tuoi sistemi e le sue funzionalità vengono estese.
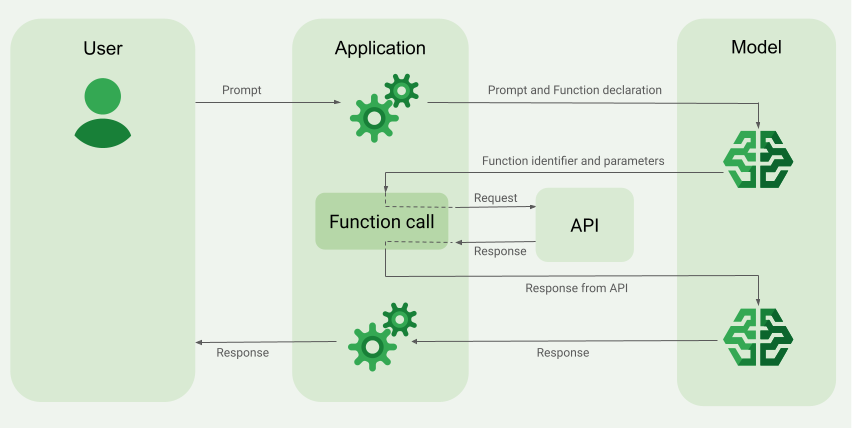
La chiamata di funzione consente due casi d'uso principali:
Recupero dei dati: recupera informazioni aggiornate per le risposte del modello, come il meteo attuale, la conversione di valuta o dati specifici da knowledge base e API (RAG).
Azione: esegui operazioni esterne come l'invio di moduli, l'aggiornamento dello stato dell'applicazione o l'orchestrazione di flussi di lavoro agentici (ad es. trasferimenti di conversazioni).
Per altri casi d'uso ed esempi basati sulla chiamata di funzione, vedi Casi d'uso.
Funzionalità e limitazioni
I seguenti modelli supportano la chiamata di funzioni:
Modelli Gemini:
- Gemini 2.5 Flash (anteprima)
- Gemini 2.5 Flash-Lite (anteprima)
- Gemini 2.5 Flash-Lite
- Gemini 2.5 Flash con audio nativo dell'API Live (anteprima)
- Gemini 2.0 Flash con API Live (anteprima)
- Gemini 2.5 Pro
- Gemini 2.5 Flash
- Gemini 2.0 Flash
- Gemini 2.0 Flash-Lite
Modelli aperti:
Puoi specificare fino a 512
FunctionDeclarationsDefinisci le funzioni nel formato dello schema OpenAPI.
Per le best practice relative alle dichiarazioni di funzione, inclusi suggerimenti per nomi e descrizioni, vedi Best practice.
Per i modelli aperti, segui questa guida per l'utente.
Come creare un'applicazione di chiamata di funzione
Per utilizzare le chiamate di funzione, svolgi le seguenti attività:
Passaggio 1: invia al modello le dichiarazioni del prompt e della funzione
Dichiara un Tool in un formato di schema compatibile con lo schema OpenAPI. Per saperne di più, consulta Esempi di schema.
Gli esempi che seguono inviano un prompt e una dichiarazione di funzione ai modelli Gemini.
REST
PROJECT_ID=myproject
LOCATION=us-central1
MODEL_ID=gemini-2.0-flash-001
curl -X POST \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "Content-Type: application/json" \
https://${LOCATION}-aiplatform.googleapis.com/v1/projects/${PROJECT_ID}/locations/${LOCATION}/publishers/google/models/${MODEL_ID}:generateContent \
-d '{
"contents": [{
"role": "user",
"parts": [{
"text": "What is the weather in Boston?"
}]
}],
"tools": [{
"functionDeclarations": [
{
"name": "get_current_weather",
"description": "Get the current weather in a given location",
"parameters": {
"type": "object",
"properties": {
"location": {
"type": "string",
"description": "The city name of the location for which to get the weather.",
"default": {
"string_value": "Boston, MA"
}
}
},
"required": [
"location"
]
}
}
]
}]
}'
Python
Puoi specificare lo schema manualmente utilizzando un dizionario Python o automaticamente con la funzione helper from_func. Il seguente esempio mostra come dichiarare una funzione manualmente.
import vertexai
from vertexai.generative_models import (
Content,
FunctionDeclaration,
GenerationConfig,
GenerativeModel,
Part,
Tool,
ToolConfig
)
# Initialize Vertex AI
# TODO(developer): Update the project
vertexai.init(project="PROJECT_ID", location="us-central1")
# Initialize Gemini model
model = GenerativeModel(model_name="gemini-2.0-flash")
# Manual function declaration
get_current_weather_func = FunctionDeclaration(
name="get_current_weather",
description="Get the current weather in a given location",
# Function parameters are specified in JSON schema format
parameters={
"type": "object",
"properties": {
"location": {
"type": "string",
"description": "The city name of the location for which to get the weather.",
"default": {
"string_value": "Boston, MA"
}
}
},
},
)
response = model.generate_content(
contents = [
Content(
role="user",
parts=[
Part.from_text("What is the weather like in Boston?"),
],
)
],
generation_config = GenerationConfig(temperature=0),
tools = [
Tool(
function_declarations=[get_current_weather_func],
)
]
)
In alternativa, puoi dichiarare la funzione automaticamente con la funzione helper from_func come mostrato nell'esempio seguente:
def get_current_weather(location: str = "Boston, MA"):
"""
Get the current weather in a given location
Args:
location: The city name of the location for which to get the weather.
"""
# This example uses a mock implementation.
# You can define a local function or import the requests library to call an API
return {
"location": "Boston, MA",
"temperature": 38,
"description": "Partly Cloudy",
"icon": "partly-cloudy",
"humidity": 65,
"wind": {
"speed": 10,
"direction": "NW"
}
}
get_current_weather_func = FunctionDeclaration.from_func(get_current_weather)
Node.js
Questo esempio mostra uno scenario di testo con una funzione e un prompt.
Node.js
Prima di provare questo esempio, segui le istruzioni di configurazione di Node.js nella guida rapida di Vertex AI per l'utilizzo delle librerie client. Per saperne di più, consulta la documentazione di riferimento dell'API Vertex AI Node.js.
Per eseguire l'autenticazione in Vertex AI, configura le Credenziali predefinite dell'applicazione. Per ulteriori informazioni, consulta Configura l'autenticazione per un ambiente di sviluppo locale.
Vai
Questo esempio mostra uno scenario di testo con una funzione e un prompt.
Scopri come installare o aggiornare Go.
Per saperne di più, consulta la documentazione di riferimento dell'SDK.
Imposta le variabili di ambiente per utilizzare l'SDK Gen AI con Vertex AI:
# Replace the `GOOGLE_CLOUD_PROJECT` and `GOOGLE_CLOUD_LOCATION` values # with appropriate values for your project. export GOOGLE_CLOUD_PROJECT=GOOGLE_CLOUD_PROJECT export GOOGLE_CLOUD_LOCATION=global export GOOGLE_GENAI_USE_VERTEXAI=True
C#
Questo esempio mostra uno scenario di testo con una funzione e un prompt.
C#
Prima di provare questo esempio, segui le istruzioni di configurazione di C# nella guida rapida di Vertex AI per l'utilizzo delle librerie client. Per saperne di più, consulta la documentazione di riferimento dell'API Vertex AI C#.
Per eseguire l'autenticazione in Vertex AI, configura le Credenziali predefinite dell'applicazione. Per ulteriori informazioni, consulta Configura l'autenticazione per un ambiente di sviluppo locale.
Java
Java
Prima di provare questo esempio, segui le istruzioni di configurazione di Java nella guida rapida di Vertex AI per l'utilizzo delle librerie client. Per saperne di più, consulta la documentazione di riferimento dell'API Vertex AI Java.
Per eseguire l'autenticazione in Vertex AI, configura le Credenziali predefinite dell'applicazione. Per ulteriori informazioni, consulta Configura l'autenticazione per un ambiente di sviluppo locale.
Se il modello determina di aver bisogno dell'output di una determinata funzione, la risposta che l'applicazione riceve dal modello contiene il nome della funzione e i valori dei parametri con cui deve essere chiamata la funzione.
Di seguito è riportato un esempio di risposta del modello al prompt dell'utente "Che tempo fa a Boston?". Il modello propone di chiamare
la funzione get_current_weather con il parametro Boston, MA.
candidates {
content {
role: "model"
parts {
function_call {
name: "get_current_weather"
args {
fields {
key: "location"
value {
string_value: "Boston, MA"
}
}
}
}
}
}
...
}
Passaggio 2: fornisci l'output dell'API al modello
Richiama l'API esterna e passa l'output dell'API al modello.
L'esempio seguente utilizza dati sintetici per simulare un payload di risposta da un'API esterna e invia l'output al modello.
REST
PROJECT_ID=myproject
MODEL_ID=gemini-2.0-flash
LOCATION="us-central1"
curl -X POST \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "Content-Type: application/json" \
https://${LOCATION}-aiplatform.googleapis.com/v1/projects/${PROJECT_ID}/locations/${LOCATION}/publishers/google/models/${MODEL_ID}:generateContent \
-d '{
"contents": [
{
"role": "user",
"parts": {
"text": "What is the weather in Boston?"
}
},
{
"role": "model",
"parts": [
{
"functionCall": {
"name": "get_current_weather",
"args": {
"location": "Boston, MA"
}
}
}
]
},
{
"role": "user",
"parts": [
{
"functionResponse": {
"name": "get_current_weather",
"response": {
"temperature": 20,
"unit": "C"
}
}
}
]
}
],
"tools": [
{
"function_declarations": [
{
"name": "get_current_weather",
"description": "Get the current weather in a specific location",
"parameters": {
"type": "object",
"properties": {
"location": {
"type": "string",
"description": "The city name of the location for which to get the weather."
}
},
"required": [
"location"
]
}
}
]
}
]
}'
Python
function_response_contents = []
function_response_parts = []
# Iterates through the function calls in the response in case there are parallel function call requests
for function_call in response.candidates[0].function_calls:
print(f"Function call: {function_call.name}")
# In this example, we'll use synthetic data to simulate a response payload from an external API
if (function_call.args['location'] == "Boston, MA"):
api_response = { "location": "Boston, MA", "temperature": 38, "description": "Partly Cloudy" }
if (function_call.args['location'] == "San Francisco, CA"):
api_response = { "location": "San Francisco, CA", "temperature": 58, "description": "Sunny" }
function_response_parts.append(
Part.from_function_response(
name=function_call.name,
response={"contents": api_response}
)
)
# Add the function call response to the contents
function_response_contents = Content(role="user", parts=function_response_parts)
# Submit the User's prompt, model's response, and API output back to the model
response = model.generate_content(
[
Content( # User prompt
role="user",
parts=[
Part.from_text("What is the weather like in Boston?"),
],
),
response.candidates[0].content, # Function call response
function_response_contents # API output
],
tools=[
Tool(
function_declarations=[get_current_weather_func],
)
],
)
# Get the model summary response
print(response.text)
Per le best practice relative all'invocazione dell'API, consulta Best practice - API invocation.
Se il modello ha proposto diverse chiamate di funzione parallele, l'applicazione deve fornire tutte le risposte al modello. Per saperne di più, consulta l'esempio di chiamata di funzione parallela.
Il modello potrebbe determinare che l'output di un'altra funzione è necessario per rispondere al prompt. In questo caso, la risposta che l'applicazione riceve dal modello contiene un altro nome di funzione e un altro insieme di valori dei parametri.
Se il modello determina che la risposta dell'API è sufficiente per rispondere al prompt dell'utente, crea una risposta in linguaggio naturale e la restituisce all'applicazione. In questo caso, l'applicazione deve restituire la risposta all'utente. Di seguito è riportato un esempio di risposta in linguaggio naturale:
It is currently 38 degrees Fahrenheit in Boston, MA with partly cloudy skies.
Chiamata di funzione con pensieri
Quando chiami funzioni con l'opzione thinking attivata, devi recuperare thought_signature dall'oggetto di risposta del modello e restituirlo quando invii il risultato dell'esecuzione della funzione al modello. Ad esempio:
Python
# Call the model with function declarations
# ...Generation config, Configure the client, and Define user prompt (No changes)
# Send request with declarations (using a thinking model)
response = client.models.generate_content(
model="gemini-2.5-flash", config=config, contents=contents)
# See thought signatures
for part in response.candidates[0].content.parts:
if not part.text:
continue
if part.thought and part.thought_signature:
print("Thought signature:")
print(part.thought_signature)
La visualizzazione delle firme dei pensieri non è obbligatoria, ma dovrai modificare il passaggio 2 per restituirle insieme al risultato dell'esecuzione della funzione in modo che possa incorporare i pensieri nella risposta finale:
Python
# Create user friendly response with function result and call the model again
# ...Create a function response part (No change)
# Append thought signatures, function call and result of the function execution to contents
function_call_content = response.candidates[0].content
# Append the model's function call message, which includes thought signatures
contents.append(function_call_content)
contents.append(types.Content(role="user", parts=[function_response_part])) # Append the function response
final_response = client.models.generate_content(
model="gemini-2.5-flash",
config=config,
contents=contents,
)
print(final_response.text)
Quando restituisci le firme dei pensieri, segui queste linee guida:
- Il modello restituisce le firme all'interno di altre parti della risposta, ad esempio le parti di chiamata di funzione o di riepilogo di testo, testo o pensiero. Restituisci l'intera risposta con tutte le parti al modello nei turni successivi.
- Non unire una parte con una firma a un'altra parte che contiene anche una firma. Le firme non possono essere concatenate.
- Non unire una parte con una firma a un'altra parte senza firma. Ciò interrompe il corretto posizionamento del pensiero rappresentato dalla firma.
Scopri di più sulle limitazioni e sull'utilizzo delle firme del pensiero e sui modelli di pensiero in generale nella pagina Pensiero.
Chiamata di funzione parallela
Per prompt come "Dammi i dettagli meteo a Boston e San Francisco", il modello potrebbe proporre diverse chiamate di funzioni parallele. Per un elenco dei modelli che supportano la chiamata di funzioni parallela, consulta Modelli supportati.
REST
Questo esempio mostra uno scenario con una funzione get_current_weather.
Il prompt dell'utente è "Voglio i dettagli meteo di Boston e San Francisco". Il modello propone due chiamate di funzione get_current_weather parallele: una con il parametro Boston e l'altra con il parametro San Francisco.
Per scoprire di più sui parametri della richiesta, consulta l'API Gemini.
{
"candidates": [
{
"content": {
"role": "model",
"parts": [
{
"functionCall": {
"name": "get_current_weather",
"args": {
"location": "Boston"
}
}
},
{
"functionCall": {
"name": "get_current_weather",
"args": {
"location": "San Francisco"
}
}
}
]
},
...
}
],
...
}
Il seguente comando mostra come fornire l'output della funzione al modello. Sostituisci my-project con il nome del tuo progetto Google Cloud .
Richiesta di modello
PROJECT_ID=my-project
MODEL_ID=gemini-2.0-flash
LOCATION="us-central1"
curl -X POST \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "Content-Type: application/json" \
https://${LOCATION}-aiplatform.googleapis.com/v1/projects/${PROJECT_ID}/locations/${LOCATION}/publishers/google/models/${MODEL_ID}:generateContent \
-d '{
"contents": [
{
"role": "user",
"parts": {
"text": "What is difference in temperature in Boston and San Francisco?"
}
},
{
"role": "model",
"parts": [
{
"functionCall": {
"name": "get_current_weather",
"args": {
"location": "Boston"
}
}
},
{
"functionCall": {
"name": "get_current_weather",
"args": {
"location": "San Francisco"
}
}
}
]
},
{
"role": "user",
"parts": [
{
"functionResponse": {
"name": "get_current_weather",
"response": {
"temperature": 30.5,
"unit": "C"
}
}
},
{
"functionResponse": {
"name": "get_current_weather",
"response": {
"temperature": 20,
"unit": "C"
}
}
}
]
}
],
"tools": [
{
"function_declarations": [
{
"name": "get_current_weather",
"description": "Get the current weather in a specific location",
"parameters": {
"type": "object",
"properties": {
"location": {
"type": "string",
"description": "The city name of the location for which to get the weather."
}
},
"required": [
"location"
]
}
}
]
}
]
}'
La risposta in linguaggio naturale creata dal modello è simile alla seguente:
Risposta del modello
[
{
"candidates": [
{
"content": {
"parts": [
{
"text": "The temperature in Boston is 30.5C and the temperature in San Francisco is 20C. The difference is 10.5C. \n"
}
]
},
"finishReason": "STOP",
...
}
]
...
}
]
Python
Questo esempio mostra uno scenario con una funzione get_current_weather.
Il prompt dell'utente è "Che tempo fa a Boston e San Francisco?".
Sostituisci my-project con il nome del tuo progetto Google Cloud .
import vertexai
from vertexai.generative_models import (
Content,
FunctionDeclaration,
GenerationConfig,
GenerativeModel,
Part,
Tool,
ToolConfig
)
# Initialize Vertex AI
# TODO(developer): Update the project
vertexai.init(project="my-project", location="us-central1")
# Initialize Gemini model
model = GenerativeModel(model_name="gemini-2.0-flash")
# Manual function declaration
get_current_weather_func = FunctionDeclaration(
name="get_current_weather",
description="Get the current weather in a given location",
# Function parameters are specified in JSON schema format
parameters={
"type": "object",
"properties": {
"location": {
"type": "string",
"description": "The city name of the location for which to get the weather.",
"default": {
"string_value": "Boston, MA"
}
}
},
},
)
response = model.generate_content(
contents = [
Content(
role="user",
parts=[
Part.from_text("What is the weather like in Boston and San Francisco?"),
],
)
],
generation_config = GenerationConfig(temperature=0),
tools = [
Tool(
function_declarations=[get_current_weather_func],
)
]
)
Il seguente comando mostra come fornire l'output della funzione al modello.
function_response_contents = []
function_response_parts = []
# You can have parallel function call requests for the same function type.
# For example, 'location_to_lat_long("London")' and 'location_to_lat_long("Paris")'
# In that case, collect API responses in parts and send them back to the model
for function_call in response.candidates[0].function_calls:
print(f"Function call: {function_call.name}")
# In this example, we'll use synthetic data to simulate a response payload from an external API
if (function_call.args['location'] == "Boston, MA"):
api_response = { "location": "Boston, MA", "temperature": 38, "description": "Partly Cloudy" }
if (function_call.args['location'] == "San Francisco, CA"):
api_response = { "location": "San Francisco, CA", "temperature": 58, "description": "Sunny" }
function_response_parts.append(
Part.from_function_response(
name=function_call.name,
response={"contents": api_response}
)
)
# Add the function call response to the contents
function_response_contents = Content(role="user", parts=function_response_parts)
function_response_contents
response = model.generate_content(
contents = [
Content(
role="user",
parts=[
Part.from_text("What is the weather like in Boston and San Francisco?"),
],
), # User prompt
response.candidates[0].content, # Function call response
function_response_contents, # Function response
],
tools = [
Tool(
function_declarations=[get_current_weather_func],
)
]
)
# Get the model summary response
print(response.text)
Vai
Modalità di chiamata di funzione
Puoi controllare il modo in cui il modello utilizza gli strumenti forniti (dichiarazioni di funzioni) impostando la modalità all'interno di function_calling_config.
| Modalità | Descrizione |
|---|---|
AUTO |
Il comportamento predefinito del modello. Il modello decide se prevedere le chiamate di funzione o rispondere in linguaggio naturale in base al contesto. Questa è la modalità più flessibile e consigliata per la maggior parte degli scenari. |
VALIDATED (anteprima) |
Il modello è vincolato a prevedere chiamate di funzioni o linguaggio naturale e garantisce il rispetto dello schema delle funzioni. Se allowed_function_names non viene fornito, il modello sceglie tra tutte le dichiarazioni di funzioni disponibili. Se viene fornito allowed_function_names, il modello sceglie tra l'insieme di funzioni consentite. |
ANY |
Il modello è vincolato a prevedere sempre una o più chiamate di funzione e garantisce il rispetto dello schema della funzione. Se allowed_function_names non viene fornito, il modello sceglie tra tutte le dichiarazioni di funzioni disponibili. Se viene fornito allowed_function_names, il modello sceglie tra l'insieme di funzioni consentite. Utilizza questa modalità quando è necessaria una risposta alla chiamata di funzione per ogni prompt (se applicabile). |
NONE |
Al modello è vietato effettuare chiamate di funzione. Equivale a inviare una richiesta senza dichiarazioni di funzioni. Utilizza questa modalità per disattivare temporaneamente le chiamate di funzione senza rimuovere le definizioni degli strumenti. |
Chiamata di funzione forzata
Anziché consentire al modello di scegliere tra una risposta in linguaggio naturale e una chiamata di funzione, puoi forzarlo a prevedere solo chiamate di funzione. Questa operazione è nota come chiamata forzata di funzioni. Puoi anche scegliere di fornire al modello un insieme completo di dichiarazioni di funzioni, ma limitare le sue risposte a un sottoinsieme di queste funzioni.
Il seguente esempio è forzato a prevedere solo chiamate di funzioni get_weather.
Python
response = model.generate_content(
contents = [
Content(
role="user",
parts=[
Part.from_text("What is the weather like in Boston?"),
],
)
],
generation_config = GenerationConfig(temperature=0),
tools = [
Tool(
function_declarations=[get_weather_func, some_other_function],
)
],
tool_config=ToolConfig(
function_calling_config=ToolConfig.FunctionCallingConfig(
# ANY mode forces the model to predict only function calls
mode=ToolConfig.FunctionCallingConfig.Mode.ANY,
# Allowed function calls to predict when the mode is ANY. If empty, any of
# the provided function calls will be predicted.
allowed_function_names=["get_weather"],
)
)
)
Esempi di schema di funzione
Le dichiarazioni di funzione sono compatibili con lo schema OpenAPI. Supportiamo i seguenti attributi: type, nullable, required, format, description, properties, items, enum, anyOf, $ref e $defs. Gli attributi rimanenti non sono supportati.
Funzione con parametri oggetto e array
L'esempio seguente utilizza un dizionario Python per dichiarare una funzione che accetta parametri di oggetti e array:
extract_sale_records_func = FunctionDeclaration( name="extract_sale_records", description="Extract sale records from a document.", parameters={ "type": "object", "properties": { "records": { "type": "array", "description": "A list of sale records", "items": { "description": "Data for a sale record", "type": "object", "properties": { "id": {"type": "integer", "description": "The unique id of the sale."}, "date": {"type": "string", "description": "Date of the sale, in the format of MMDDYY, e.g., 031023"}, "total_amount": {"type": "number", "description": "The total amount of the sale."}, "customer_name": {"type": "string", "description": "The name of the customer, including first name and last name."}, "customer_contact": {"type": "string", "description": "The phone number of the customer, e.g., 650-123-4567."}, }, "required": ["id", "date", "total_amount"], }, }, }, "required": ["records"], }, )
Funzione con parametro enum
L'esempio seguente utilizza un dizionario Python per dichiarare una funzione che accetta un parametro intero enum:
set_status_func = FunctionDeclaration( name="set_status", description="set a ticket's status field", # Function parameters are specified in JSON schema format parameters={ "type": "object", "properties": { "status": { "type": "integer", "enum": [ "10", "20", "30" ], # Provide integer (or any other type) values as strings. } }, }, )
Funzione con ref e def
La seguente dichiarazione di funzione JSON utilizza gli attributi ref e defs:
{ "contents": ..., "tools": [ { "function_declarations": [ { "name": "get_customer", "description": "Search for a customer by name", "parameters": { "type": "object", "properties": { "first_name": { "ref": "#/defs/name" }, "last_name": { "ref": "#/defs/name" } }, "defs": { "name": { "type": "string" } } } } ] } ] }
Note sull'utilizzo:
- A differenza dello schema OpenAPI, specifica
refedefssenza il simbolo$. refdeve fare riferimento all'elemento secondario diretto didefs; non sono consentiti riferimenti esterni.- La profondità massima dello schema nidificato è 32.
- La profondità della ricorsione in
defs(auto-riferimento) è limitata a due.
from_func con parametro array
Il seguente esempio di codice dichiara una funzione che moltiplica un array di numeri e utilizza from_func per generare lo schema FunctionDeclaration.
from typing import List # Define a function. Could be a local function or you can import the requests library to call an API def multiply_numbers(numbers: List[int] = [1, 1]) -> int: """ Calculates the product of all numbers in an array. Args: numbers: An array of numbers to be multiplied. Returns: The product of all the numbers. If the array is empty, returns 1. """ if not numbers: # Handle empty array return 1 product = 1 for num in numbers: product *= num return product multiply_number_func = FunctionDeclaration.from_func(multiply_numbers) """ multiply_number_func contains the following schema: {'name': 'multiply_numbers', 'description': 'Calculates the product of all numbers in an array.', 'parameters': {'properties': {'numbers': {'items': {'type': 'INTEGER'}, 'description': 'list of numbers', 'default': [1.0, 1.0], 'title': 'Numbers', 'type': 'ARRAY'}}, 'description': 'Calculates the product of all numbers in an array.', 'title': 'multiply_numbers', 'property_ordering': ['numbers'], 'type': 'OBJECT'}} """
Best practice per la chiamata di funzioni
Scrivi nomi di funzioni, descrizioni dei parametri e istruzioni chiare e dettagliate
I nomi delle funzioni devono iniziare con una lettera o un trattino basso e contenere solo caratteri a-z, A-Z, 0-9, trattini bassi, punti o trattini con una lunghezza massima di 64 caratteri.
Sii estremamente chiaro e specifico nelle descrizioni di funzioni e parametri. Il modello si basa su questi per scegliere la funzione corretta e fornire gli argomenti appropriati. Ad esempio, una funzione
book_flight_ticketpotrebbe avere la descrizionebook flight tickets after confirming users' specific requirements, such as time, departure, destination, party size and preferred airline
Utilizzare parametri fortemente tipizzati
Se i valori dei parametri provengono da un insieme finito, aggiungi un campo enum anziché inserire l'insieme di valori nella descrizione. Se il valore parametro è sempre un numero intero, imposta il tipo su integer anziché number.
Selezione dello strumento
Sebbene il modello possa utilizzare un numero arbitrario di strumenti, fornirne troppi può aumentare il rischio di selezionare uno strumento errato o non ottimale. Per ottenere risultati ottimali, cerca di fornire solo gli strumenti pertinenti per il contesto o l'attività, idealmente mantenendo il set attivo a un massimo di 10-20. Se hai un numero totale elevato di strumenti, valuta la possibilità di selezionare gli strumenti in modo dinamico in base al contesto della conversazione.
Se fornisci strumenti generici di basso livello (come bash), il modello potrebbe utilizzare lo strumento
più spesso, ma con minore precisione. Se fornisci uno strumento specifico di alto livello
(come get_weather), il modello sarà in grado di utilizzarlo in modo più accurato, ma
potrebbe non essere utilizzato con la stessa frequenza.
Utilizzare le istruzioni di sistema
Quando utilizzi funzioni con parametri di data, ora o posizione, includi la data, l'ora o le informazioni sulla posizione pertinenti (ad esempio città e paese) attuali nell'istruzione di sistema. In questo modo, il modello dispone del contesto necessario per elaborare la richiesta in modo accurato, anche se il prompt dell'utente non contiene dettagli.
Prompt engineering
Per risultati ottimali, anteponi al prompt utente i seguenti dettagli:
- Contesto aggiuntivo per il modello, ad esempio
You are a flight API assistant to help with searching flights based on user preferences. - Dettagli o istruzioni su come e quando utilizzare le funzioni, ad esempio
Don't make assumptions on the departure or destination airports. Always use a future date for the departure or destination time. - Istruzioni per porre domande chiarificatrici se le query degli utenti sono ambigue, ad esempio
Ask clarifying questions if not enough information is available.
Utilizzare la configurazione della generazione
Per il parametro della temperatura, utilizza 0 o un altro valore basso. In questo modo
il modello genera risultati più affidabili e riduce le allucinazioni.
Utilizzare l'output strutturato
La chiamata di funzione può essere utilizzata insieme all'output strutturato per consentire al modello di prevedere sempre chiamate di funzione o output che rispettano uno schema specifico, in modo da ricevere risposte formattate in modo coerente quando il modello non genera chiamate di funzione.
Convalida la chiamata API
Se il modello propone l'invocazione di una funzione che invierebbe un ordine, aggiornerebbe un database o avrebbe altrimenti conseguenze significative, convalida la chiamata di funzione con l'utente prima di eseguirla.
Utilizzare le firme di pensiero
Per ottenere risultati ottimali, le firme del pensiero devono essere sempre utilizzate con la chiamata di funzione.
Prezzi
Il prezzo per la chiamata di funzioni si basa sul numero di caratteri all'interno degli input e degli output di testo. Per scoprire di più, consulta la pagina Prezzi di Vertex AI.
In questo caso, l'input di testo (prompt) si riferisce al prompt dell'utente per il turno di conversazione corrente, alle dichiarazioni di funzione per il turno di conversazione corrente e alla cronologia della conversazione. La cronologia della conversazione include le query, le chiamate di funzione e le risposte di funzione dei turni di conversazione precedenti. Vertex AI tronca la cronologia della conversazione a 32.000 caratteri.
L'output di testo (risposta) si riferisce alle chiamate di funzioni e alle risposte di testo per il turno di conversazione corrente.
Casi d'uso della chiamata di funzioni
Puoi utilizzare la chiamata di funzioni per le seguenti attività:
| Caso d'uso | Esempio di descrizione | Link di esempio |
|---|---|---|
| Integrare API esterne | Ottenere informazioni meteo utilizzando un'API meteorologica | Tutorial sul notebook |
| Converti indirizzi in coordinate di latitudine/longitudine | Tutorial sul notebook | |
| Convertire le valute utilizzando un'API di cambio valuta | Codelab | |
| Creare chatbot avanzati | Rispondere alle domande dei clienti su prodotti e servizi | Tutorial sul notebook |
| Creare un assistente per rispondere a domande finanziarie e di notizie sulle aziende | Tutorial sul notebook | |
| Strutturare e controllare le chiamate di funzione | Estrai entità strutturate dai dati di log non elaborati | Tutorial sul notebook |
| Estrai uno o più parametri dall'input utente dell'utente | Tutorial sul notebook | |
| Gestire elenchi e strutture di dati nidificate nelle chiamate di funzione | Tutorial sul notebook | |
| Gestire il comportamento della chiamata di funzione | Gestire chiamate di funzioni e risposte parallele | Tutorial sul notebook |
| Gestire quando e quali funzioni può chiamare il modello | Tutorial sul notebook | |
| Eseguire query sui database con il linguaggio naturale | Converti le domande in linguaggio naturale in query SQL per BigQuery | App di esempio |
| Chiamata di funzione multimodale | Utilizzare immagini, video, audio e PDF come input per attivare le chiamate di funzioni | Tutorial sul notebook |
Ecco altri casi d'uso:
Interpretare i comandi vocali: crea funzioni che corrispondono alle attività nel veicolo. Ad esempio, puoi creare funzioni che accendono la radio o attivano il climatizzatore. Invia i file audio dei comandi vocali dell'utente al modello e chiedi al modello di convertire l'audio in testo e identificare la funzione che l'utente vuole chiamare.
Automatizza i workflow in base a trigger ambientali: crea funzioni per rappresentare i processi che possono essere automatizzati. Fornisci al modello i dati dei sensori ambientali e chiedigli di analizzarli ed elaborarli per determinare se uno o più flussi di lavoro devono essere attivati. Ad esempio, un modello potrebbe elaborare i dati di temperatura in un magazzino e scegliere di attivare una funzione di irrigatore.
Automatizza l'assegnazione dei ticket di assistenza: fornisci al modello ticket di assistenza, log e regole sensibili al contesto. Chiedi al modello di elaborare tutte queste informazioni per determinare a chi deve essere assegnato il ticket. Chiama una funzione per assegnare il ticket alla persona suggerita dal modello.
Recuperare informazioni da una knowledge base: crea funzioni che recuperano e riassumono articoli accademici su un determinato argomento. Consenti al modello di rispondere a domande su materie accademiche e fornire citazioni per le sue risposte.
Passaggi successivi
Consulta il riferimento API per la chiamata di funzioni.
Scopri di più su Vertex AI Agent Engine.