Layanan evaluasi GenAI menyediakan alat tingkat perusahaan untuk penilaian objektif dan berbasis data pada model AI generatif. Alat ini mendukung dan menginformasikan sejumlah tugas pengembangan seperti migrasi model, pengeditan perintah, dan penyesuaian.
Fitur layanan evaluasi AI generatif
Fitur utama layanan evaluasi AI Generatif adalah kemampuan untuk menggunakan rubrik adaptif, serangkaian uji lulus atau gagal yang disesuaikan untuk setiap perintah. Rubrik evaluasi mirip dengan pengujian unit dalam pengembangan software dan bertujuan untuk meningkatkan performa model di berbagai tugas.
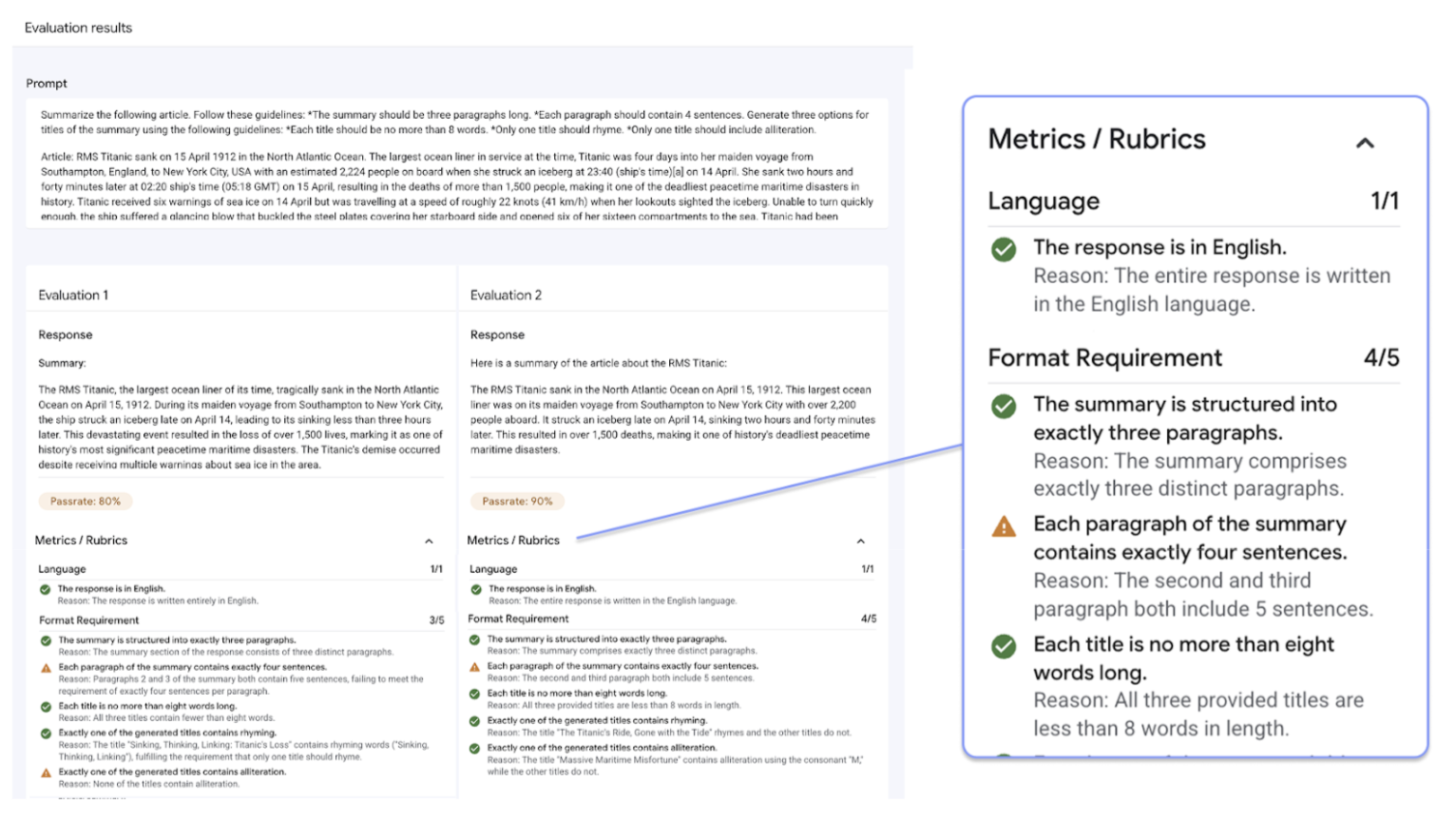
Layanan evaluasi AI generatif mendukung metode evaluasi umum berikut:
Rubrik adaptif (Direkomendasikan): Membuat serangkaian rubrik lulus atau tidak lulus yang unik untuk setiap perintah individual dalam set data Anda.
Rubrik statis: Menerapkan sekumpulan kriteria penilaian tetap di semua perintah.
Metrik berbasis komputasi: Gunakan algoritma deterministik seperti
ROUGEatauBLEUjika kebenaran nyata tersedia.Fungsi kustom: Tentukan logika evaluasi Anda sendiri di Python untuk persyaratan khusus.
Pembuatan set data evaluasi
Anda dapat membuat set data evaluasi melalui metode berikut:
Upload file yang berisi instance perintah lengkap, atau berikan template perintah bersama file nilai variabel yang sesuai untuk mengisi perintah yang telah selesai.
Ambil sampel langsung dari log produksi untuk mengevaluasi penggunaan model Anda di dunia nyata.
Gunakan pembuatan data sintetis untuk membuat sejumlah besar contoh yang konsisten untuk template perintah apa pun.
Antarmuka yang didukung
Anda dapat menentukan dan menjalankan evaluasi menggunakan antarmuka berikut:
Google Cloud Konsol: Antarmuka pengguna web yang menyediakan alur kerja terpandu secara menyeluruh. Kelola set data, jalankan evaluasi, dan pelajari laporan dan visualisasi interaktif secara mendalam. Lihat Melakukan evaluasi menggunakan konsol.
Python SDK: Jalankan evaluasi secara terprogram dan tampilkan perbandingan model berdampingan langsung di lingkungan Colab atau Jupyter Anda. Lihat Menjalankan evaluasi menggunakan Klien GenAI di Vertex AI SDK
Kasus penggunaan
Layanan evaluasi AI generatif memungkinkan Anda melihat performa model pada tugas spesifik dan berdasarkan kriteria unik Anda, sehingga memberikan insight berharga yang tidak dapat diperoleh dari papan peringkat publik dan tolok ukur umum. Hal ini mendukung tugas pengembangan penting, termasuk:
Migrasi model: Bandingkan versi model untuk memahami perbedaan perilaku dan sesuaikan perintah serta setelan Anda.
Menemukan model terbaik: Jalankan perbandingan langsung model Google dan pihak ketiga pada data Anda untuk menetapkan dasar pengukuran performa dan mengidentifikasi model yang paling sesuai untuk kasus penggunaan Anda.
Peningkatan kualitas perintah: Gunakan hasil evaluasi untuk memandu upaya penyesuaian Anda. Menjalankan kembali evaluasi akan membuat feedback loop yang ketat, sehingga memberikan masukan langsung yang dapat diukur atas perubahan Anda.
Penyesuaian model: Evaluasi kualitas model yang disesuaikan dengan menerapkan kriteria evaluasi yang konsisten pada setiap proses.
Evaluasi dengan rubrik adaptif
Rubrik adaptif adalah metode yang direkomendasikan untuk sebagian besar kasus penggunaan evaluasi dan biasanya merupakan cara tercepat untuk memulai evaluasi.
Daripada menggunakan serangkaian rubrik rating umum seperti kebanyakan sistem LLM sebagai hakim, framework evaluasi berbasis pengujian secara adaptif menghasilkan serangkaian rubrik lulus atau gagal yang unik untuk setiap perintah individual dalam set data Anda. Pendekatan ini memastikan bahwa setiap evaluasi relevan dengan tugas tertentu yang sedang dievaluasi.
Proses evaluasi untuk setiap perintah menggunakan sistem dua langkah:
Pembuatan rubrik: Layanan ini pertama-tama menganalisis perintah Anda dan membuat daftar pengujian spesifik yang dapat diverifikasi—rubrik—yang harus dipenuhi oleh respons yang baik.
Validasi rubrik: Setelah model Anda membuat respons, layanan akan menilai respons tersebut berdasarkan setiap rubrik, memberikan putusan
PassatauFailyang jelas dan alasan.

Hasil akhirnya adalah tingkat kelulusan gabungan dan perincian mendetail tentang rubrik yang dilalui model, sehingga memberi Anda insight yang dapat ditindaklanjuti untuk mendiagnosis masalah dan mengukur peningkatan.
Dengan beralih dari skor subjektif tingkat tinggi ke hasil pengujian objektif yang terperinci, Anda dapat menerapkan siklus pengembangan berbasis evaluasi dan menerapkan praktik terbaik software engineering ke dalam proses pembuatan aplikasi AI generatif.
Contoh evaluasi rubrik
Untuk memahami cara layanan evaluasi AI generatif membuat dan menggunakan rubrik, pertimbangkan contoh berikut:
Perintah pengguna: Write a four-sentence summary of the provided article about renewable energy, maintaining an optimistic tone.
Untuk perintah ini, langkah pembuatan rubrik dapat menghasilkan rubrik berikut:
Rubrik 1: Respons adalah ringkasan dari artikel yang diberikan.
Rubrik 2: Respons berisi tepat empat kalimat.
Rubrik 3: Respons mempertahankan nada yang optimistis.
Model Anda dapat menghasilkan respons berikut: The article highlights significant growth in solar and wind power. These advancements are making clean energy more affordable. The future looks bright for renewables. However, the report also notes challenges with grid infrastructure.
Selama validasi rubrik, layanan evaluasi AI generatif menilai respons berdasarkan setiap rubrik:
Rubrik 1: Respons adalah ringkasan dari artikel yang diberikan.
Putusan:
PassAlasan: Respons secara akurat meringkas poin-poin utama.
Rubrik 2: Respons berisi tepat empat kalimat.
Putusan:
PassAlasan: Respons terdiri dari empat kalimat yang berbeda
Rubrik 3: Respons mempertahankan nada yang optimistis.
Putusan:
FailAlasan: Kalimat terakhir memperkenalkan poin negatif, yang mengurangi nuansa optimis.
Tingkat kelulusan akhir untuk respons ini adalah 66,7%. Untuk membandingkan dua model, Anda dapat mengevaluasi responsnya terhadap kumpulan pengujian yang sama ini dan membandingkan tingkat kelulusan keseluruhannya.
Alur kerja evaluasi
Untuk menyelesaikan evaluasi, biasanya Anda harus melakukan langkah-langkah berikut:
Buat set data evaluasi: Kumpulkan set data instance perintah yang mencerminkan kasus penggunaan spesifik Anda. Anda dapat menyertakan jawaban referensi (kebenaran dasar) jika berencana menggunakan metrik berbasis komputasi.
Tentukan metrik evaluasi: Pilih metrik yang ingin Anda gunakan untuk mengukur performa model. SDK mendukung semua jenis metrik, sedangkan konsol mendukung rubrik adaptif.
Buat respons model: Pilih satu atau beberapa model untuk membuat respons untuk set data Anda. SDK mendukung semua model yang dapat dipanggil melalui
LiteLLM, sedangkan konsol mendukung model Google Gemini.Jalankan evaluasi: Jalankan tugas evaluasi, yang menilai respons setiap model berdasarkan metrik yang Anda pilih.
Menafsirkan hasil: Tinjau skor gabungan dan respons individual untuk menganalisis performa model.
Mulai menggunakan evaluasi
Anda dapat mulai menggunakan evaluasi menggunakan konsol.
Atau, kode berikut menunjukkan cara menyelesaikan evaluasi dengan Klien GenAI di Vertex AI SDK:
from vertexai import Client
from vertexai import types
import pandas as pd
client = Client(project=PROJECT_ID, location=LOCATION)
# Create an evaluation dataset
prompts_df = pd.DataFrame({
"prompt": [
"Write a simple story about a dinosaur",
"Generate a poem about Vertex AI",
],
})
# Get responses from one or multiple models
eval_dataset = client.evals.run_inference(model="gemini-2.5-flash", src=prompts_df)
# Define the evaluation metrics and run the evaluation job
eval_result = client.evals.evaluate(
dataset=eval_dataset,
metrics=[types.RubricMetric.GENERAL_QUALITY]
)
# View the evaluation results
eval_result.show()
Layanan evaluasi AI generatif menawarkan dua antarmuka SDK:
Klien GenAI di Vertex AI SDK (Direkomendasikan) (Pratinjau)
from vertexai import clientKlien GenAI adalah antarmuka yang lebih baru dan direkomendasikan untuk evaluasi, yang diakses melalui class Klien terpadu. Alat ini mendukung semua metode evaluasi dan dirancang untuk alur kerja yang mencakup perbandingan model, visualisasi dalam notebook, dan insight untuk penyesuaian model.
Modul evaluasi di Vertex AI SDK (GA)
from vertexai.evaluation import EvalTaskModul evaluasi adalah antarmuka yang lebih lama, yang dipertahankan untuk kompatibilitas mundur dengan alur kerja yang ada, tetapi tidak lagi dalam pengembangan aktif. Objek ini diakses melalui class
EvalTask. Metode ini mendukung metrik berbasis komputasi dan LLM-as-a-judge standar, tetapi tidak mendukung metode evaluasi yang lebih baru seperti rubrik adaptif.
Region yang didukung
Wilayah berikut didukung untuk layanan evaluasi AI Generatif:
Iowa (
us-central1)Northern Virginia (
us-east4)Oregon (
us-west1)Las Vegas, Nevada (
us-west4)Belgia (
europe-west1)Belanda (
europe-west4)Paris, Prancis (
europe-west9)