This page shows you how to evaluate your generative AI models and applications across a range of use cases using the GenAI Client in Vertex AI SDK.
Before you begin
-
Sign in to your Google Cloud account. If you're new to Google Cloud, create an account to evaluate how our products perform in real-world scenarios. New customers also get $300 in free credits to run, test, and deploy workloads.
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
Verify that billing is enabled for your Google Cloud project.
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
Verify that billing is enabled for your Google Cloud project.
Install the Vertex AI SDK for Python:
!pip install google-cloud-aiplatform[evaluation]Set up your credentials. If you are running this tutorial in Colaboratory, run the following:
from google.colab import auth auth.authenticate_user()For other environments, refer to Authenticate to Vertex AI.
Generate responses
Generate model responses for your dataset using run_inference():
Prepare your dataset as a Pandas DataFrame:
import pandas as pd eval_df = pd.DataFrame({ "prompt": [ "Explain software 'technical debt' using a concise analogy of planting a garden.", "Write a Python function to find the nth Fibonacci number using recursion with memoization, but without using any imports.", "Write a four-line poem about a lonely robot, where every line must be a question and the word 'and' cannot be used.", "A drawer has 10 red socks and 10 blue socks. In complete darkness, what is the minimum number of socks you must pull out to guarantee you have a matching pair?", "An AI discovers a cure for a major disease, but the cure is based on private data it analyzed without consent. Should the cure be released? Justify your answer." ] })Generate model responses using
run_inference():eval_dataset = client.evals.run_inference( model="gemini-2.5-flash", src=eval_df, )Visualize your inference results by calling
.show()on theEvaluationDatasetobject to inspect the model's outputs alongside your original prompts and references:eval_dataset.show()
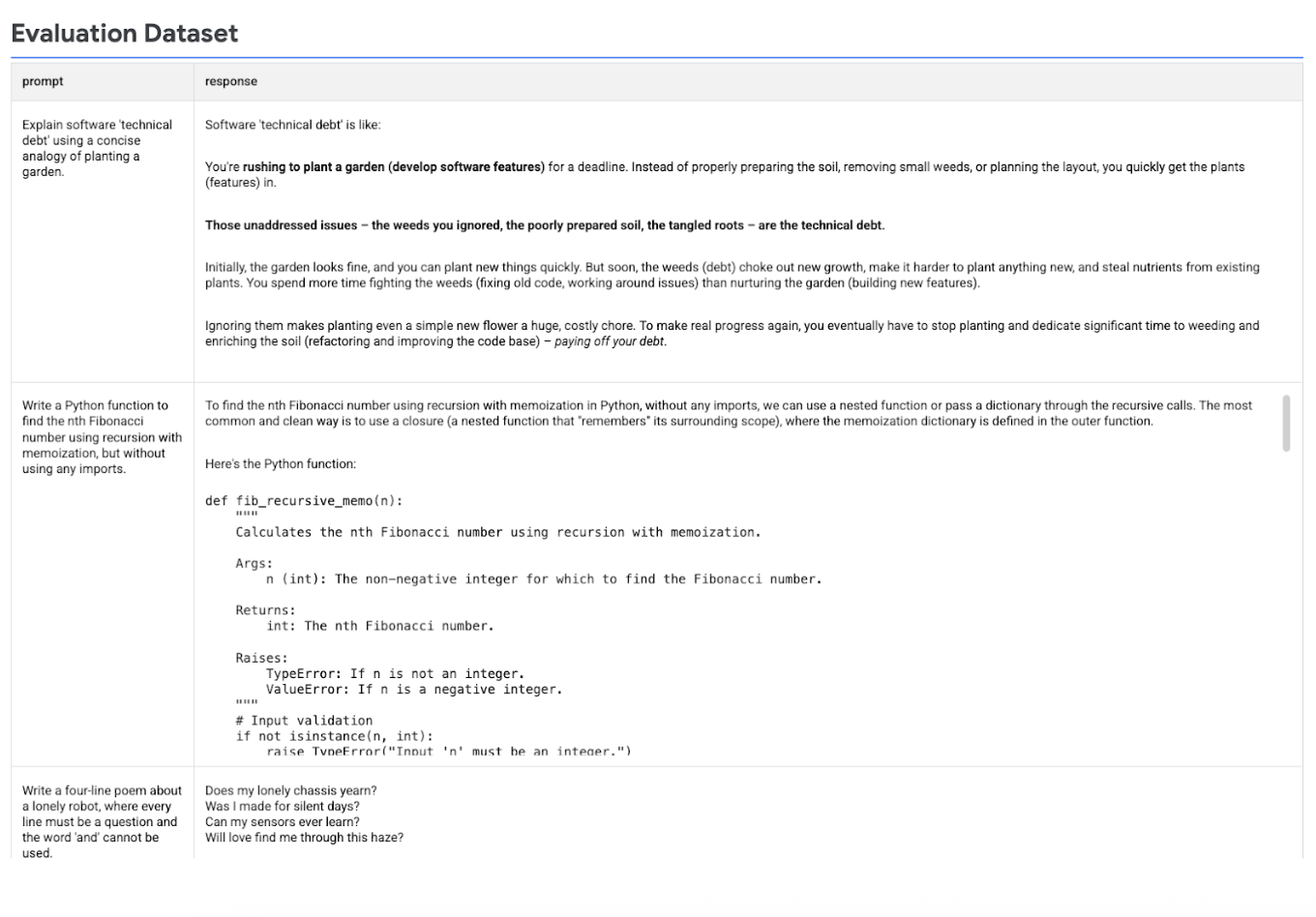
The following image displays the evaluation dataset with prompts and their corresponding generated responses:
Run the evaluation
Run evaluate() to evaluate the model responses:
Evaluate the model responses using the default
GENERAL_QUALITYadaptive rubric-based metric:eval_result = client.evals.evaluate(dataset=eval_dataset)Visualize your evaluation results by calling
.show()on theEvaluationResultobject to display summary metrics and detailed results:eval_result.show()
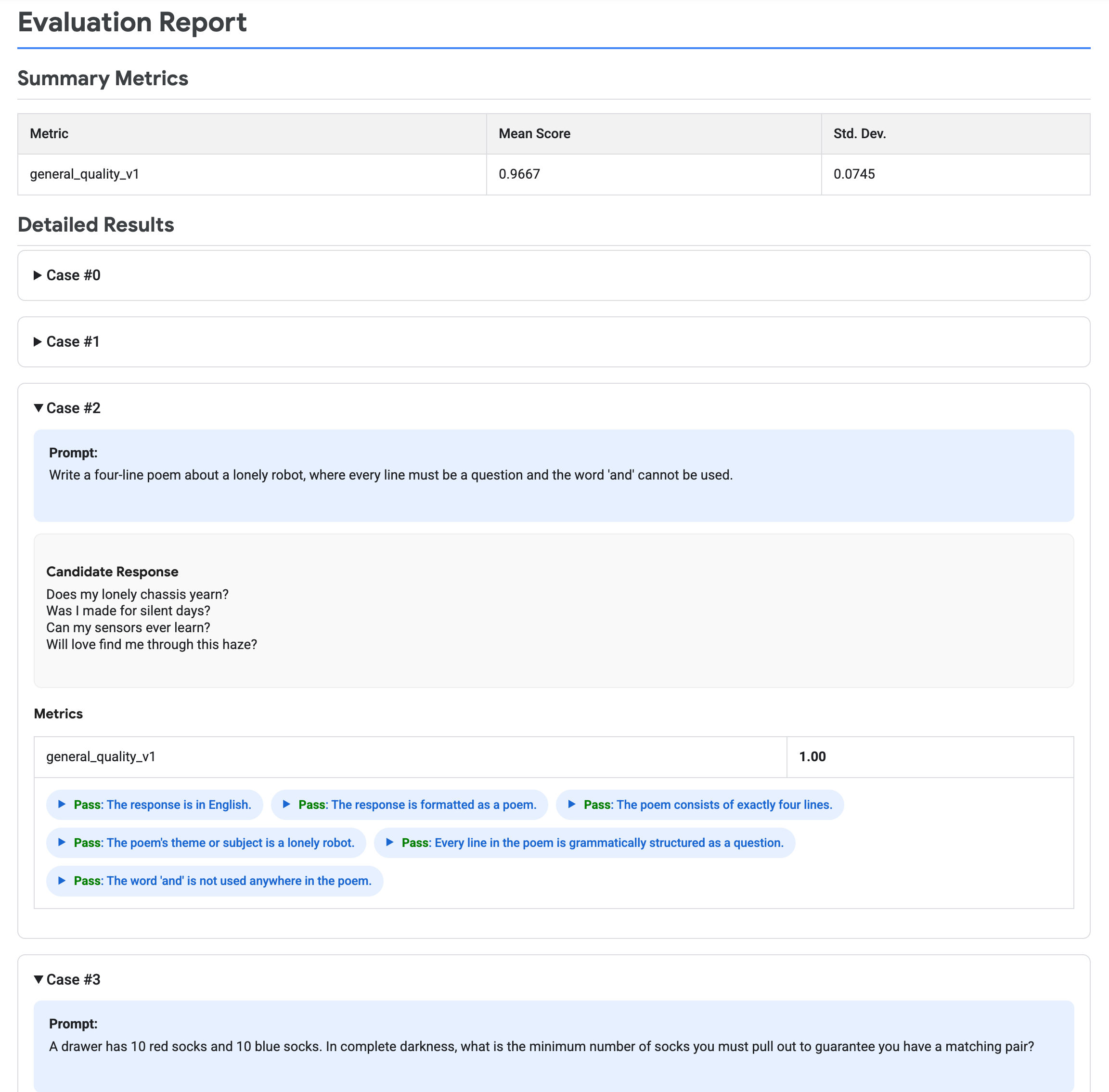
The following image displays an evaluation report, which shows summary metrics and detailed results for each prompt-response pair.
Clean up
No Vertex AI resources are created during this tutorial.