Auf dieser Seite wird beschrieben, was die Vertex AI RAG Engine ist und wie sie funktioniert.
| Beschreibung | Console |
|---|---|
| Informationen zur Verwendung des Vertex AI SDK zum Ausführen von Vertex AI RAG Engine-Aufgaben finden Sie im RAG-Schnellstart für Python. |
Übersicht
Die Vertex AI RAG Engine, eine Komponente der Vertex AI-Plattform, erleichtert die Retrieval-Augmented Generation (RAG). Vertex AI RAG Engine ist auch ein Datenframework für die Entwicklung von Anwendungen, die kontexterweiterte Large Language Models (LLMs) nutzen. Die Kontexterweiterung erfolgt, wenn Sie ein LLM auf Ihre Daten anwenden. Hier wird Retrieval Augmented Generation (RAG) implementiert.
Ein häufiges Problem bei LLMs ist, dass sie kein privates Wissen, also die Daten Ihrer Organisation, verstehen. Mit der Vertex AI RAG Engine können Sie den LLM-Kontext mit zusätzlichen privaten Informationen anreichern, da das Modell Halluzinationen reduzieren und Fragen genauer beantworten kann.
Durch die Kombination zusätzlicher Wissensquellen mit dem vorhandenen Wissen von LLMs wird ein besserer Kontext bereitgestellt. Der verbesserte Kontext zusammen mit der Abfrage verbessert die Qualität der LLM-Antwort.
Das folgende Bild veranschaulicht die wichtigsten Konzepte, die zum Verständnis der Vertex AI RAG Engine erforderlich sind.
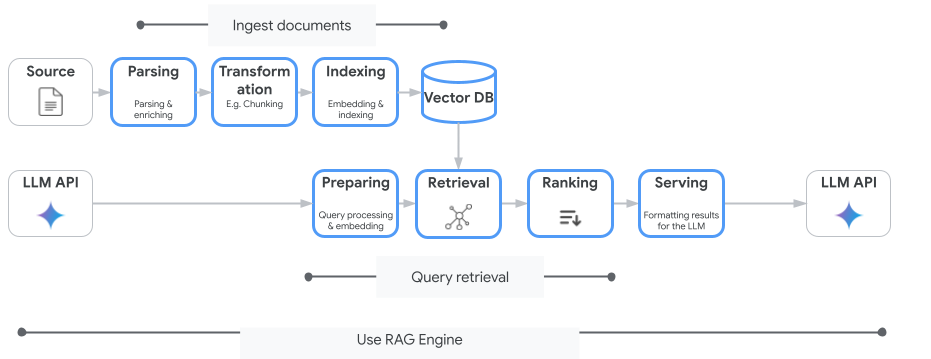
Diese Konzepte sind in der Reihenfolge des RAG-Prozesses (Retrieval-Augmented Generation) aufgeführt.
Datenaufnahme: Nehmen Sie Daten aus verschiedenen Datenquellen auf. Zum Beispiel lokale Dateien, Cloud Storage und Google Drive.
Datentransformation: Konvertierung der Daten in der Vorbereitung auf die Indexierung. Beispielsweise werden Daten in Blöcke unterteilt.
Einbettung: Numerische Darstellungen von Wörtern oder Textabschnitten. Diese Zahlen erfassen die semantische Bedeutung und den Kontext des Texts. Ähnliche oder verwandte Wörter oder Text haben in der Regel ähnliche Einbettungen. Das bedeutet, dass sie im hochdimensionalen Vektorbereich näher beieinander liegen.
Datenindexierung: Mit der Vertex AI RAG Engine wird ein Index erstellt, der als Korpus bezeichnet wird. Der Index strukturiert die Wissensdatenbank so, dass sie für die Suche optimiert ist. Der Index ist beispielsweise mit einem detaillierten Inhaltsverzeichnis für ein großes Referenzbuch vergleichbar.
Abrufen: Wenn ein Nutzer eine Frage stellt oder einen Prompt bereitstellt, durchsucht die Abrufkomponente in der Vertex AI RAG Engine in ihrer Wissensdatenbank nach relevanten Informationen.
Generierung: Die abgerufenen Informationen werden zum Kontext, der der ursprünglichen Nutzeranfrage als Leitfaden für das generative KI-Modell hinzugefügt wurde, um faktisch fundierte und relevante Antworten zu generieren.
Unterstützte Regionen
Die Vertex AI RAG Engine wird in den folgenden Regionen unterstützt:
| Region | Standort | Beschreibung | Startphase |
|---|---|---|---|
us-central1 |
Iowa | Die Versionen v1 und v1beta1 werden unterstützt. |
Zulassungsliste |
us-east4 |
Virginia | Die Versionen v1 und v1beta1 werden unterstützt. |
GA |
europe-west3 |
Frankfurt, Deutschland | Die Versionen v1 und v1beta1 werden unterstützt. |
GA |
europe-west4 |
Eemshaven, Niederlande | Die Versionen v1 und v1beta1 werden unterstützt. |
GA |
- „
us-central1“ wird zu „Allowlist“ geändert. Wenn Sie die Vertex AI RAG Engine testen möchten, versuchen Sie es mit anderen Regionen. Wenn Sie planen, Ihren Produktionsverkehr aufus-central1umzustellen, wenden Sie sich anvertex-ai-rag-engine-support@google.com.
Vertex AI-RAG-Engine löschen
In den folgenden Codebeispielen wird veranschaulicht, wie Sie eine Vertex AI RAG Engine für die Google Cloud -Konsole, Python und REST löschen:
Parameter und Codebeispiele für die Version 1 (v1) der API.
Parameter und Codebeispiele für die v1beta1 API
Feedback geben
Wenn Sie mit dem Google-Support chatten möchten, rufen Sie die Supportgruppe für die Vertex AI RAG Engine auf.
Verwenden Sie zum Senden einer E-Mail die E-Mail-Adresse vertex-ai-rag-engine-support@google.com.
Nächste Schritte
- Informationen zur Verwendung des Vertex AI SDK zum Ausführen von Vertex AI RAG Engine-Aufgaben finden Sie unter RAG-Kurzanleitung für Python.
- Weitere Informationen zur Fundierung finden Sie unter Fundierungsübersicht.
- Weitere Informationen zu den Antworten von RAG finden Sie unter Ausgabe von Abruf und Generierung der Vertex AI RAG Engine.
- Informationen zur RAG-Architektur: