Este documento explica como monitorar o comportamento, a integridade e a performance dos seus modelos totalmente gerenciados na Vertex AI. Ele descreve como usar o painel de observabilidade do modelo pré-criado para ter insights sobre o uso do modelo, identificar problemas de latência e resolver erros.
Você vai aprender a fazer o seguinte:
- Acessar e interpretar o painel de capacidade de observação do modelo.
- Confira as métricas de monitoramento disponíveis.
- Monitore o tráfego do endpoint do modelo usando o Metrics Explorer.
Acessar e interpretar o painel de observabilidade do modelo
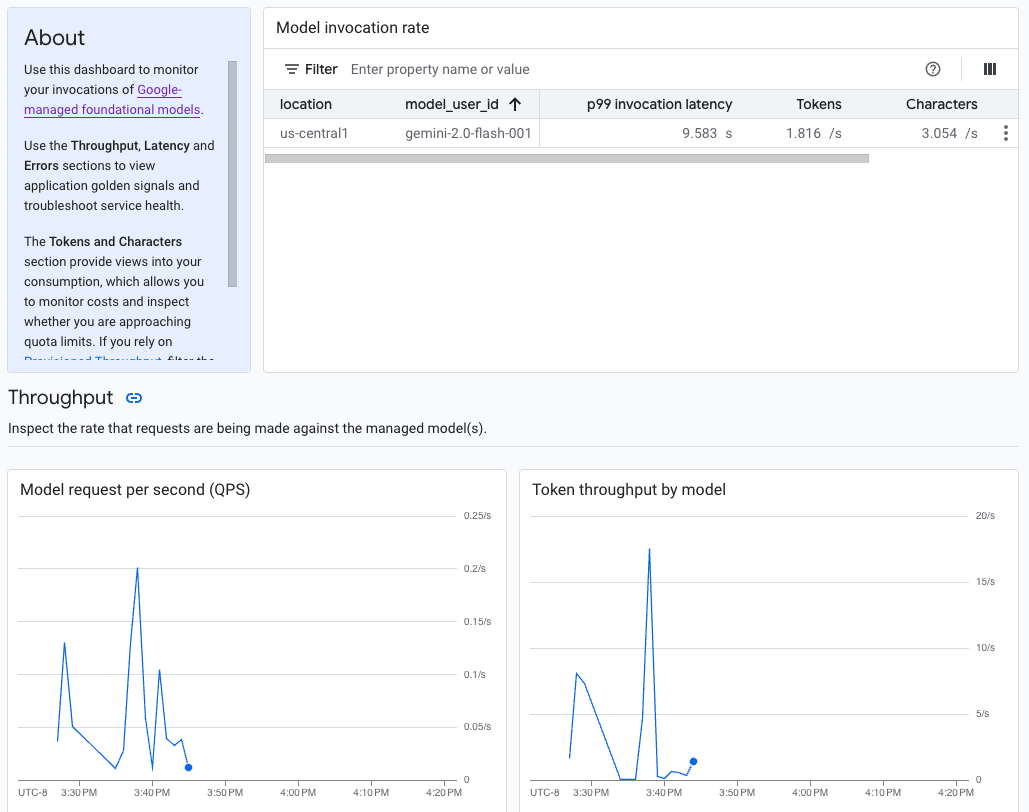
A IA generativa na Vertex AI oferece um painel de observabilidade de modelo pré-criado para analisar o comportamento, a integridade e o desempenho de modelos totalmente gerenciados. Os modelos totalmente gerenciados, também conhecidos como modelo como serviço (MaaS), são fornecidos pelo Google e incluem os modelos Gemini do Google e modelos de parceiros com endpoints gerenciados. As métricas de modelos auto-hospedados não estão incluídas no painel.
A IA generativa na Vertex AI coleta e informa automaticamente a atividade dos modelos de MaaS para ajudar você a resolver rapidamente problemas de latência e monitorar a capacidade.
Caso de uso
Como desenvolvedor de aplicativos, você pode ver como os usuários estão interagindo com os modelos que você expôs. Por exemplo, é possível ver como o uso do modelo (solicitações de modelo por segundo) e a intensidade de computação dos comandos do usuário (latências de invocação do modelo) estão mudando ao longo do tempo. Como essas métricas estão relacionadas ao uso do modelo, também é possível estimar os custos de execução de cada um deles.
Quando um problema surge, você pode solucionar rapidamente no painel. Para verificar se os modelos estão respondendo de maneira confiável e oportuna, confira as taxas de erros da API, as latências do primeiro token e a capacidade de processamento de tokens.
Métricas de monitoramento disponíveis
O painel de observabilidade do modelo mostra um subconjunto de métricas coletadas pelo Cloud Monitoring, como solicitações de modelo por segundo (QPS), taxa de transferência de tokens e latências do primeiro token. Acesse o painel para conferir todas as métricas disponíveis.
Limitações
A Vertex AI captura métricas do painel apenas para chamadas de API ao endpoint de um modelo.O uso do console Google Cloud , como métricas do Vertex AI Studio, não é adicionado ao painel.
Ver o painel
- Na seção "Vertex AI" do console Google Cloud , acesse a página Painel.
Acesse a Vertex AI. 1. No painel, em "Observabilidade do modelo", clique em Mostrar todas as métricas para conferir o painel de observabilidade do modelo no console do Google Cloud Observability.
Para conferir métricas de um modelo específico ou em um local específico, defina um ou mais filtros na parte de cima da página do painel.
Para ver uma descrição de cada métrica, consulte a seção "
aiplatform" na página Google Cloud métricas.
Monitorar o tráfego do endpoint do modelo
Siga as instruções abaixo para monitorar o tráfego do seu endpoint no Metrics Explorer.
No console Google Cloud , acesse a página Metrics Explorer.
Selecione o projeto para o qual você quer ver as métricas.
No menu suspenso Métrica, clique em Selecionar uma métrica.
Na barra de pesquisa Filtrar por nome do recurso ou da métrica, digite
Vertex AI Endpoint.Selecione a categoria de métrica Endpoint da Vertex AI > Previsão. Em Métricas ativas, selecione uma das seguintes métricas:
prediction/online/error_countprediction/online/prediction_countprediction/online/prediction_latenciesprediction/online/response_count
Clique em Aplicar. Para adicionar mais de uma métrica, clique em Adicionar consulta.
É possível filtrar ou agregar suas métricas usando os seguintes menus suspensos:
Para selecionar e visualizar um subconjunto de dados com base em critérios especificados, use o menu suspenso Filtro. Por exemplo, para filtrar o modelo
gemini-2.0-flash-001, useendpoint_id = gemini-2p0-flash-001. Observe que o.na versão do modelo é substituído por ump.Para combinar vários pontos de dados em um único valor e ver uma visão resumida das suas métricas, use o menu suspenso Agregação. Por exemplo, é possível agregar a soma de
response_code.
Você também pode configurar alertas para seu endpoint. Para mais informações, consulte Gerenciar políticas de alertas.
Para conferir as métricas adicionadas ao projeto usando um painel, consulte Visão geral dos painéis.
A seguir
- Para saber como criar alertas para seu painel, consulte Visão geral de alertas.
- Para saber mais sobre a retenção de dados de métricas, consulte Cotas e limites do Monitoring.
- Para saber mais sobre dados em repouso, consulte Como proteger dados em repouso.
- Para conferir uma lista de todas as métricas coletadas pelo Cloud Monitoring, consulte a seção
"
aiplatform" na página Google Cloud métricas.