Sie können die Ausführung einer vorkompilierten Pipeline mithilfe von Cloud Scheduler über die ereignisgesteuerte Cloud Functions-Funktion mit einem HTTP-Trigger planen.
Einfache Pipeline erstellen und kompilieren
Mit dem Kubeflow Pipelines SDK eine geplante Pipeline erstellen und in eine YAML-Datei kompilieren.
Beispiel hello-world-scheduled-pipeline:
from kfp import compiler
from kfp import dsl
# A simple component that prints and returns a greeting string
@dsl.component
def hello_world(message: str) -> str:
greeting_str = f'Hello, {message}'
print(greeting_str)
return greeting_str
# A simple pipeline that contains a single hello_world task
@dsl.pipeline(
name='hello-world-scheduled-pipeline')
def hello_world_scheduled_pipeline(greet_name: str):
hello_world_task = hello_world(greet_name)
# Compile the pipeline and generate a YAML file
compiler.Compiler().compile(pipeline_func=hello_world_scheduled_pipeline,
package_path='hello_world_scheduled_pipeline.yaml')
Kompilierte YAML-Pipeline in den Cloud Storage-Bucket hochladen
Öffnen Sie den Cloud Storage-Browser in der Google Cloud Console.
Klicken Sie auf den Cloud Storage-Bucket, den Sie bei der Konfiguration Ihres Projekts erstellt haben.
Laden Sie mithilfe eines vorhandenen Ordners oder eines neuen Ordners Ihre kompilierte YAML-Pipeline (in diesem Beispiel
hello_world_scheduled_pipeline.yaml) in den ausgewählten Ordner hoch.Klicken Sie auf die hochgeladene YAML-Datei, um die Details aufzurufen. Kopieren Sie den gsutil-URI zur späteren Verwendung.
Cloud Functions-Funktion mit HTTP-Trigger erstellen
Gehen Sie in der Konsole zur Seite Cloud Functions:
Klicken Sie auf Funktion erstellen.
Geben Sie der Funktion im Abschnitt Grundlagen einen Namen (z. B.
hello-world-scheduled-pipeline-function).Wählen Sie im Abschnitt Trigger HTTP als Triggertyp aus.
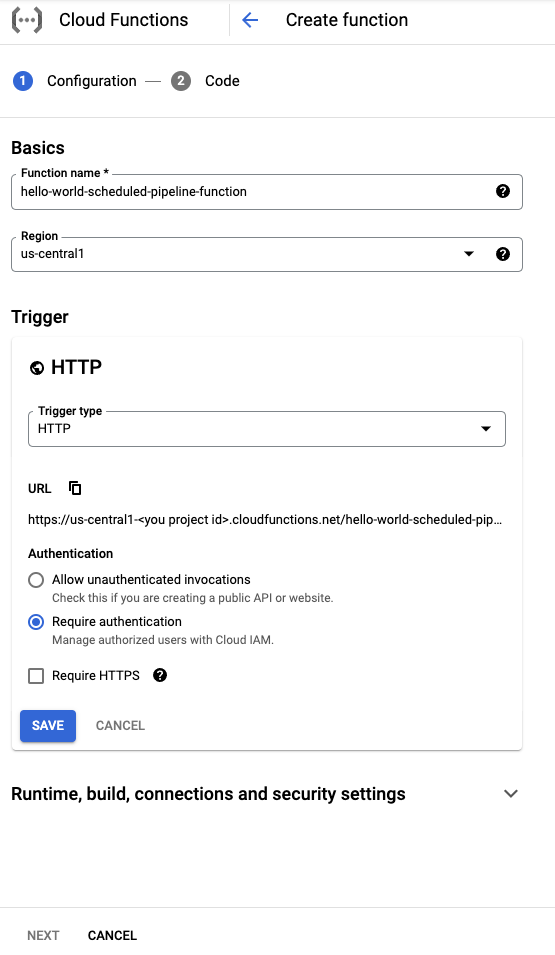
Notieren Sie sich die für diesen Trigger generierte URL und speichern Sie sie zur Verwendung im nächsten Abschnitt.
Übernehmen Sie für alle anderen Felder die Standardeinstellungen und klicken Sie auf Speichern, um die Konfiguration des Triggerabschnitts zu speichern.
Übernehmen Sie für alle anderen Felder die Standardwerte und klicken Sie auf Weiter, um zum Abschnitt „Code“ zu gelangen.
Wählen Sie unter Laufzeit die Option Python 3.7 aus.
Geben Sie unter Einstiegspunkt den Wert process_request ein, den Funktionsnamen des Beispielcodes für den Einstiegspunkt.
Wählen Sie unter Quellcode Inline-Editor aus, falls er noch nicht ausgewählt ist.
Fügen Sie in der Datei
main.pyden folgenden Code hinzu:import json from google.cloud import aiplatform PROJECT_ID = 'your-project-id' # <---CHANGE THIS REGION = 'your-region' # <---CHANGE THIS PIPELINE_ROOT = 'your-cloud-storage-pipeline-root' # <---CHANGE THIS def process_request(request): """Processes the incoming HTTP request. Args: request (flask.Request): HTTP request object. Returns: The response text or any set of values that can be turned into a Response object using `make_response <http://flask.pocoo.org/docs/1.0/api/#flask.Flask.make_response>`. """ # decode http request payload and translate into JSON object request_str = request.data.decode('utf-8') request_json = json.loads(request_str) pipeline_spec_uri = request_json['pipeline_spec_uri'] parameter_values = request_json['parameter_values'] aiplatform.init( project=PROJECT_ID, location=REGION, ) job = aiplatform.PipelineJob( display_name=f'hello-world-cloud-function-pipeline', template_path=pipeline_spec_uri, pipeline_root=PIPELINE_ROOT, enable_caching=False, parameter_values=parameter_values ) job.submit() return "Job submitted"Dabei gilt:
- PROJECT_ID: Das Google Cloud-Projekt, in dem diese Pipeline ausgeführt wird.
- REGION: Die Region, in der diese Pipeline ausgeführt wird.
- PIPELINE_ROOT: Geben Sie einen Cloud Storage-URI an, auf den das Pipelines-Dienstkonto zugreifen kann. Die Artefakte Ihrer Pipelineausführungen werden im Pipeline-Stammverzeichnis gespeichert.
Ersetzen Sie in der Datei
requirements.txtden Inhalt durch die folgenden Paketanforderungen:google-api-python-client>=1.7.8,<2 google-cloud-aiplatformKlicken Sie auf Bereitstellen, um die Funktion bereitzustellen.
Cloud Scheduler-Job erstellen
Gehen Sie in der Konsole zur Seite Cloud Scheduler:
Klicken Sie auf Create Job (Job erstellen).
Geben Sie Ihrem Job einen Namen (z. B.
my-hello-world-schedule) und fügen Sie optional eine Beschreibung hinzu.Geben Sie die Häufigkeit für den Job im Format unix-cron an. Beispiel:
0 9 * * 1Dieser beispielhafte Cron-Zeitplan wird jeden Montag um 9:00 Uhr ausgeführt. Weitere Informationen finden Sie unter Zeitpläne für Cronjobs konfigurieren.
Wählen Sie Ihre Zeitzone unter "Timezone" aus.
Klicken Sie auf Weiter, um die Ausführung zu konfigurieren.
Wählen Sie im Menü „Zieltyp“ die Option HTTP aus.
Geben Sie im Feld URL die Trigger-URL ein, die Sie im vorherigen Abschnitt gespeichert haben.
Wählen Sie POST als HTTP-Methode aus, falls sie nicht bereits ausgewählt ist.
Geben Sie im Feld Text einen JSON-String in dem im Code definierten Format ein. Verwenden Sie das Beispiel aus dem vorherigen Abschnitt:
{ "pipeline_spec_uri": "<path-to-your-compiled-pipeline>", "parameter_values": { "greet_name": "<any-greet-string>" } }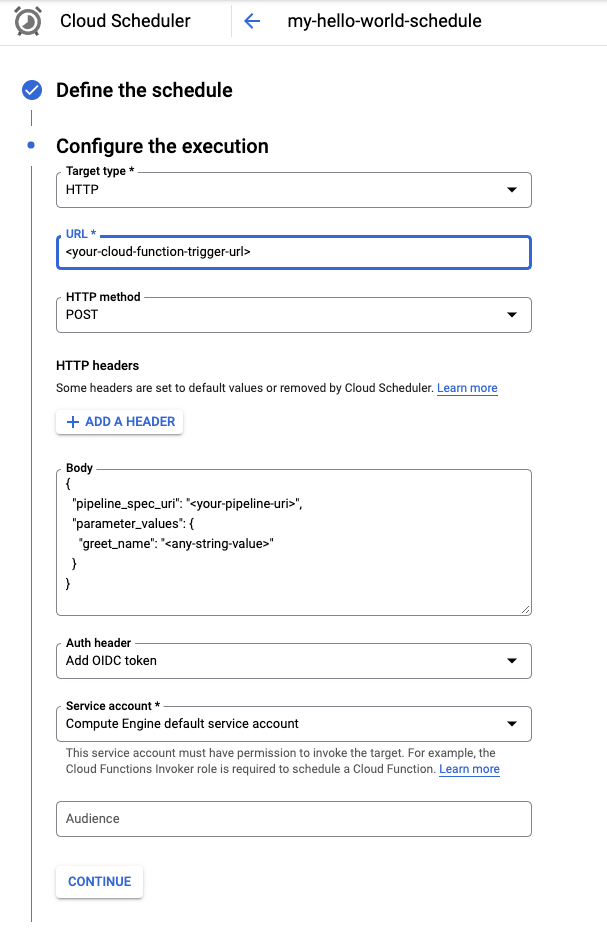
Wählen Sie im Drop-down-Menü Auth den Eintrag OIDC-Token hinzufügen aus.
Wählen Sie im Drop-down-Menü des Dienstkontos ein Dienstkonto aus, das die Berechtigung zum Aufrufen der Cloud Functions-Funktion hat. Sie können das Compute Engine-Standarddienstkonto für diese Anleitung verwenden.
Übernehmen Sie für alle anderen Felder die Standardeinstellungen und klicken Sie auf Erstellen.
Job manuell ausführen (optional)
Sie können den gerade erstellten Job optional ausführen, um seine Funktionalität zu prüfen.
Besuchen Sie in der Konsole die Seite Cloud Scheduler.
Klicken Sie neben dem Namen des Jobs auf die Schaltfläche Jetzt ausführen.
Die Ausführung des ersten in einem Projekt erstellten Jobs kann aufgrund der erforderlichen Konfiguration beim ersten Aufruf einige Minuten dauern.
Den Status des Jobs sehen Sie in der Spalte Ergebnis.