Questa pagina fornisce una panoramica concettuale dell'esportazione dei dati di traccia utilizzando Cloud Trace. Potresti voler esportare i dati di traccia per i seguenti motivi:
- Per archiviare i dati di tracciamento per un periodo più lungo del periodo di conservazione predefinito di 30 giorni.
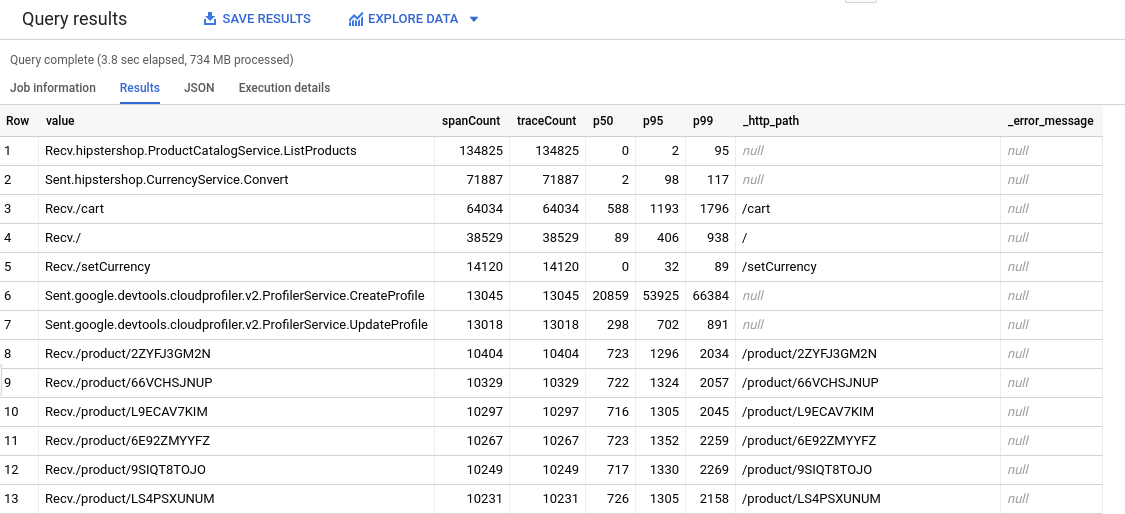
Per consentirti di utilizzare gli strumenti BigQuery per analizzare i dati delle tracce. Ad esempio, utilizzando BigQuery, puoi identificare i conteggi e i quantili degli intervalli. Per informazioni sulla query utilizzata per generare la seguente tabella, vedi Query HipsterShop.
Come funzionano le esportazioni
L'esportazione prevede la creazione di un sink per un progetto Google Cloud . Un sink definisce un set di dati BigQuery come destinazione.
Puoi creare un sink utilizzando l'Cloud Trace API o Google Cloud CLI.
Proprietà e terminologia del sink
I sink sono definiti per un progetto e hanno le seguenti proprietà: Google Cloud
Nome: un nome per il sink. Ad esempio, un nome potrebbe essere:
"projects/PROJECT_NUMBER/traceSinks/my-sink"
dove
PROJECT_NUMBERè il numero di progetto Google Cloud del sink emy-sinkè l'identificatore del sink.Risorsa padre: la risorsa in cui crei il sink. Il progetto padre deve essere un progetto Google Cloud :
"projects/PROJECT_ID"
PROJECT_IDpuò essere un identificatore o un numero di progetto. Google CloudDestinazione: un unico luogo in cui inviare gli intervalli di traccia. Trace supporta l'esportazione delle tracce in BigQuery. La destinazione può essere il progetto Google Cloud del sink o qualsiasi altro progetto Google Cloud che si trova nella stessa organizzazione.
Ad esempio, una destinazione valida è:
bigquery.googleapis.com/projects/DESTINATION_PROJECT_NUMBER/datasets/DATASET_ID
dove
DESTINATION_PROJECT_NUMBERè il Google Cloud numero di progetto della destinazione eDATASET_IDè l'identificatore del set di dati BigQuery.Identità writer: un nome di account di servizio. Il proprietario della destinazione di esportazione deve concedere a questoaccount di serviziot le autorizzazioni per scrivere nella destinazione di esportazione. Quando esporta le tracce, Trace adotta questa identità per l'autorizzazione. Per maggiore sicurezza, i nuovi sink ricevono un account di servizio unico:
export-PROJECT_NUMBER-GENERATED_VALUE@gcp-sa-cloud-trace.iam.gserviceaccount.com
dove
PROJECT_NUMBERè il numero del tuo progetto Google Cloud , in esadecimale, eGENERATED_VALUEè un valore generato in modo casuale.Non crei, possiedi o gestisci il account di servizio identificato dall'identità writer di un sink. Quando crei un sink, Trace crea ilaccount di serviziot richiesto dal sink. Questo account di servizio non è incluso nell'elenco dei service account per il tuo progetto finché non ha almeno un binding Identity and Access Management. Aggiungi questo binding quando configuri una destinazione sink.
Per informazioni sull'utilizzo dell'identità writer, consulta Autorizzazioni della destinazione.
Come funzionano i sink
Ogni volta che un intervallo di traccia arriva in un progetto, Trace esporta una copia dell'intervallo.
Le tracce ricevute da Trace prima della creazione del sink non possono essere esportate.
Controllo degli accessi
Per creare o modificare un sink, devi disporre di uno dei seguenti ruoli Identity and Access Management:
- Trace Admin
- Utente Trace
- Proprietario progetto
- Editor progetto
Per ulteriori informazioni, consulta Controllo dell'accesso.
Per esportare le tracce in una destinazione, l'account di servizio writer del sink deve avere l'autorizzazione di scrittura nella destinazione. Per ulteriori informazioni sulle identità degli autori, consulta Proprietà sink in questa pagina.
Quote e limiti
Cloud Trace utilizza l'API BigQuery Streaming per inviare gli span di traccia alla destinazione. L'API Cloud Trace raggruppa le chiamate API. Cloud Trace non implementa un meccanismo di throttling o di nuovi tentativi. Gli intervalli di Trace potrebbero non essere esportati correttamente se la quantità di dati supera le quote di destinazione.
Per informazioni dettagliate su quote e limiti di BigQuery, consulta la sezione Quote e limiti.
Prezzi
L'esportazione delle tracce non comporta addebiti di Cloud Trace. Tuttavia, potresti sostenere costi di utilizzo di BigQuery. Per saperne di più, consulta la pagina Prezzi di BigQuery.
Stima dei costi
BigQuery addebita un costo per l'importazione e l'archiviazione dei dati. Per stimare i costi mensili di BigQuery:
Stima il numero totale di intervalli di traccia importati in un mese.
Per informazioni su come visualizzare l'utilizzo, vedi Visualizzare l'utilizzo per account di fatturazione.
Stima i requisiti di streaming in base al numero di intervalli di traccia importati.
Ogni intervallo viene scritto in una riga della tabella. Ogni riga in BigQuery richiede almeno 1024 byte. Pertanto, un limite inferiore per i requisiti di streaming di BigQuery è di assegnare 1024 byte a ogni intervallo. Ad esempio, se il tuo Google Cloud progetto ha importato 200 span, questi richiedono almeno 20.400 byte per l'inserimento di flussi di dati.
Utilizza il Calcolatore prezzi per stimare i costi di BigQuery dovuti ad archiviazione, inserimenti di flussi di dati e query.
Visualizzare e gestire l'utilizzo di BigQuery
Puoi utilizzare Metrics Explorer per visualizzare l'utilizzo di BigQuery. Puoi anche creare un criterio di avviso che ti avvisa se l'utilizzo di BigQuery supera i limiti predefiniti. La tabella seguente contiene le impostazioni per creare un criterio di avviso. Puoi utilizzare le impostazioni nella tabella del riquadro dei target quando crei un grafico o quando utilizzi Esplora metriche.
Per creare un criterio di avviso che si attivi quando le metriche BigQuery importate superano un livello definito dall'utente, utilizza le impostazioni seguenti.
| Nuova condizione Campo |
Valore |
|---|---|
| Risorsa e metrica | Nel menu Risorse, seleziona Set di dati BigQuery. Nel menu Categorie di metriche, seleziona Archiviazione. Seleziona una metrica dal menu Metriche. Le metriche specifiche per l'utilizzo includono Stored bytes, Uploaded bytes
e Uploaded bytes billed. Per un elenco completo delle metriche disponibili, vedi
Metriche BigQuery.
|
| Filtro | project_id: il tuo ID progetto Google Cloud . dataset_id: il tuo ID set di dati. |
| Tra le serie temporali Raggruppa serie temporali per |
dataset_id: l'ID del tuo set di dati. |
| Tra le serie temporali Aggregazione serie temporali |
sum |
| Finestra temporale continua | 1 m |
| Funzione finestra temporale continua | mean |
| Configura trigger di avviso Campo |
Valore |
|---|---|
| Tipo di condizione | Threshold |
| Trigger avviso | Any time series violates |
| Posizione soglia | Above threshold |
| Valore soglia | Sei tu a determinare il valore accettabile. |
| Finestra di ripetizione test | 1 minute |
Passaggi successivi
Per configurare un sink, consulta Esportazione delle tracce.