Monitorize VMs da Cloud TPU
Este guia explica como usar o Google Cloud Monitoring para monitorizar as suas VMs de TPU do Google Cloud. Google Cloud O Monitoring recolhe automaticamente métricas e registos da sua TPU do Google Cloud e do respetivo Compute Engine anfitrião. Estes dados podem ser usados para monitorizar o estado do seu Cloud TPU e Compute Engine.
As métricas permitem-lhe acompanhar uma quantidade numérica ao longo do tempo, por exemplo, a utilização da CPU, a utilização da rede ou a duração inativa do TensorCore. Os registos captam eventos num momento específico. As entradas do registo são escritas pelo seu próprio código, Google Cloud serviços, aplicações de terceiros e a Google Cloud infraestrutura. Também pode gerar métricas a partir dos dados presentes numa entrada de registo criando uma métrica baseada em registos. Também pode definir políticas de alerta com base nos valores das métricas ou nas entradas do registo.
Este guia aborda a Google Cloud monitorização e mostra-lhe como:
- Veja as métricas da Cloud TPU
- Configure políticas de alerta de métricas do Cloud TPU
- Consultar registos do Cloud TPU
- Crie métricas baseadas em registos para configurar alertas e visualizar painéis de controlo
Para monitorizar as UTPs, também pode usar o Capacity Planner (Pré-visualização). Com o planeador de capacidade, pode ver a utilização de UTPs e os dados de previsão para o seu projeto, pasta ou organização. Estes dados são atualizados a cada 24 horas e pode usá-los para analisar as tendências de utilização e planear as necessidades de capacidade futuras. Para mais informações, consulte a Vista geral do planeador de capacidade.
Este documento pressupõe alguns conhecimentos básicos sobre a Google Cloud monitorização. Tem de ter uma VM do Compute Engine e recursos do Cloud TPU criados antes de poder começar a gerar e trabalhar com o Google Cloud Monitoring. Consulte o início rápido do Cloud TPU para mais detalhes.
Métrica
Google Cloud As métricas são geradas automaticamente pelas VMs do Compute Engine e pelo tempo de execução da TPU na nuvem. As seguintes métricas são geradas pelas VMs da Cloud TPU:
memory/usagenetwork/received_bytes_countnetwork/sent_bytes_countcpu/utilizationtpu/tensorcore/idle_durationaccelerator/tensorcore_utilizationaccelerator/memory_bandwidth_utilizationaccelerator/duty_cycleaccelerator/memory_totalaccelerator/memory_used
Pode demorar até 180 segundos entre o momento em que um valor de métrica é gerado e o momento em que é apresentado no explorador de métricas.
Para uma lista completa de métricas geradas pelo Cloud TPU, consulte o artigo Google Cloud Métricas do Cloud TPU.
Utilização de memória
A métrica memory/usage é gerada para o recurso TPU Worker e monitoriza a memória usada pela VM de TPU em bytes. Esta métrica é amostrada a cada 60 segundos.
Contagem de bytes recebidos pela rede
A métrica network/received_bytes_count é gerada para o recurso TPU Worker
e acompanha o número de bytes cumulativos de dados que a VM da TPU recebeu
através da rede num determinado momento.
Contagem de bytes enviados pela rede
A métrica network/sent_bytes_count é gerada para o recurso TPU Worker e acompanha o número de bytes cumulativos que a VM da TPU enviou através da rede num determinado momento.
Utilização da CPU
A métrica cpu/utilization é gerada para o recurso TPU Worker e
monitoriza a utilização atual da CPU no worker da TPU, representada como uma percentagem,
com amostragem uma vez por minuto. Normalmente, os valores situam-se entre 0,0 e 100,0, mas podem exceder 100,0.
Duração da inatividade do TensorCore
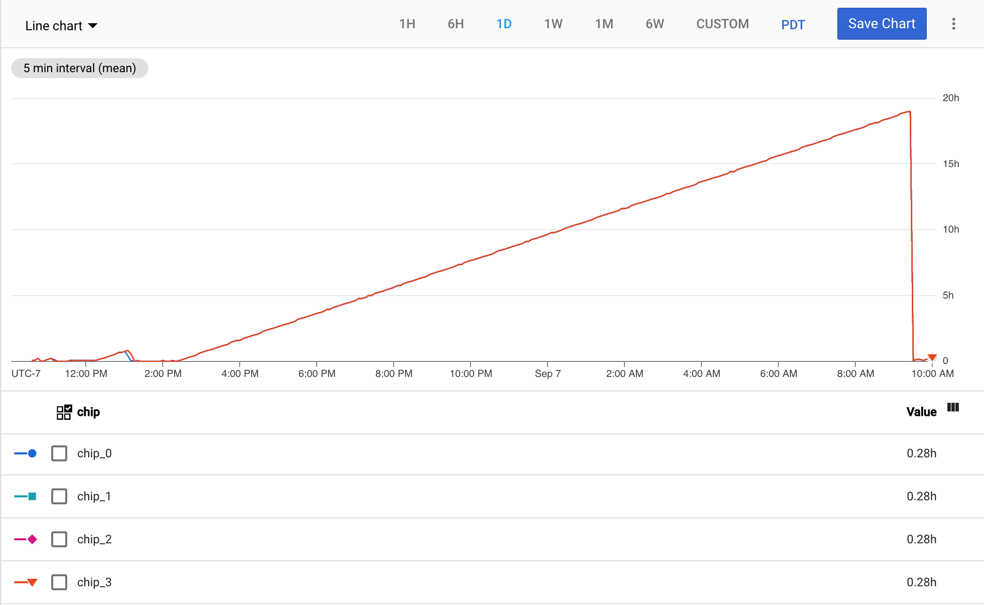
A métrica tpu/tensorcore/idle_duration é gerada para o recurso TPU Worker e acompanha o número de segundos em que o TensorCore de cada chip de TPU esteve inativo. Esta métrica está disponível para cada chip em todas as TPUs em utilização. Se estiver a ser usado um TensorCore, o valor da duração de inatividade é reposto para zero. Quando o TensorCore deixa de estar em utilização, o valor da duração de inatividade começa a aumentar.
O gráfico seguinte mostra a métrica tpu/tensorcore/idle_duration para uma VM de TPU v2-8, que tem um trabalhador. Cada trabalhador tem quatro fichas. Neste exemplo, todos os quatro chips têm os mesmos valores para tpu/tensorcore/idle_duration, pelo que os gráficos estão sobrepostos.
Utilização do TensorCore
A métrica accelerator/tensorcore_utilization é gerada para o recurso GCE TPU
Worker e acompanha a percentagem atual do TensorCore que está a ser usado. Esta métrica é calculada dividindo o número de operações TensorCore realizadas durante um período de amostragem pelo número máximo de operações que podem ser realizadas durante o mesmo período de amostragem. Um valor maior significa uma melhor utilização. A métrica de utilização do TensorCore é suportada pelas gerações de TPUs v4 e mais recentes.
Utilização da largura de banda da memória
A métrica accelerator/memory_bandwidth_utilization é gerada para o recurso GCE TPU Worker e acompanha a percentagem atual da largura de banda da memória do acelerador que está a ser usada. Esta métrica é calculada dividindo a largura de banda da memória usada durante um período de amostragem pela largura de banda máxima suportada durante o mesmo período de amostragem. Um valor maior significa uma melhor utilização. A métrica Memory Bandwidth Utilization é suportada pela v4 e pelas gerações de TPUs mais recentes.
Ciclo de atividade do acelerador
A métrica accelerator/duty_cycle é gerada para o recurso GCE TPU Worker e acompanha a percentagem de tempo durante o período de amostragem em que o TensorCore do acelerador estava a processar ativamente. Os valores estão no intervalo de 0 a 100. Um valor mais elevado significa uma melhor utilização dos TensorCores. Esta métrica é
comunicada quando uma carga de trabalho de aprendizagem automática está a ser executada na VM da TPU. A métrica
Accelerator Duty Cycle é suportada para JAX
0.4.14 e posterior,
PyTorch
2.1 e posterior, e
TensorFlow
2.14.0 e
posterior.
Memória total do acelerador
A métrica accelerator/memory_total é gerada para o recurso GCE TPU Worker
e acompanha o total de memória do acelerador atribuída em bytes.
Esta métrica é comunicada quando uma carga de trabalho de aprendizagem automática está a ser executada na VM de TPU. A métrica Total de memória do acelerador é suportada para JAX
0.4.14 e posteriores,
PyTorch
2.1 e posteriores, e
TensorFlow
2.14.0 e
posteriores.
Memória do acelerador usada
A métrica accelerator/memory_used é gerada para o recurso GCE TPU Worker
e acompanha a memória total do acelerador usada em bytes. Esta métrica é
comunicada quando uma carga de trabalho de aprendizagem automática está a ser executada na VM da TPU. A métrica Accelerator Memory Used é suportada para JAX
0.4.14 e versões posteriores, PyTorch
2.1 e versões posteriores, e
TensorFlow
2.14.0 e versões posteriores.
Visualizar métricas
Pode ver métricas através do Explorador de métricas na Google Cloud consola.
No explorador de métricas, clique em Selecionar uma métrica e pesquise TPU Worker
ou GCE TPU Worker, consoante a métrica que lhe interessa.
Selecione um recurso para apresentar todas as métricas disponíveis para esse recurso.
Se a opção Ativo estiver ativada, apenas são apresentadas as métricas com dados de séries cronológicas nas últimas 25 horas. Desative a opção Ativo para listar todas as métricas.
Criar alertas
Pode criar políticas de alerta que indicam ao Cloud Monitoring para enviar um alerta quando uma condição é cumprida.
Os passos nesta secção mostram um exemplo de como adicionar uma política de alerta para a métrica TensorCore Idle Duration. Sempre que esta métrica exceder as 24 horas, o Cloud Monitoring envia um email para o endereço de email registado.
- Aceda à consola de monitorização.
- No painel de navegação, clique em Alertas.
- Clique em Editar canais de notificação.
- Em Email, clique em Adicionar novo. Escreva um endereço de email, um nome a apresentar e clique em Guardar.
- Na página de alertas, clique em Criar política.
- Clique em Selecionar uma métrica e, de seguida, selecione Duração de inatividade do Tensorcore e clique em Aplicar.
- Clique em Seguinte e, de seguida, em Limite.
- Para Acionador de alerta, selecione Qualquer série cronológica viola.
- Para Posição do limite, selecione Acima do limite.
- Em Valor limite, escreva
86400000. - Clicar em Seguinte.
- Em Canais de notificação, selecione o seu canal de notificação por email e clique em OK.
- Escreva um nome para a política de alertas.
- Clique em Seguinte e, de seguida, em Criar política.
Quando a duração de inatividade do TensorCore excede as 24 horas, é enviado um email para o endereço de email que especificou.
Registo
As entradas de registo são escritas por Google Cloud serviços, serviços de terceiros, frameworks de ML ou o seu código. Pode ver os registos através do Explorador de registos ou da API Logs. Para mais informações sobre o Google Cloud registo, consulte Google Cloud Registo.
Os registos do trabalhador da TPU contêm informações sobre um trabalhador da Cloud TPU específico numa zona específica, por exemplo, a quantidade de memória disponível no trabalhador da Cloud TPU (system_available_memory_GiB).
Os registos de recursos auditados contêm informações sobre quando uma API Cloud TPU específica foi chamada e quem fez a chamada. Por exemplo, pode encontrar informações
sobre chamadas para as APIs CreateNode, UpdateNode e DeleteNode.
As frameworks de ML podem gerar registos para a saída padrão e o erro padrão. Estes registos são controlados por variáveis de ambiente e são lidos pelo seu script de preparação.
O seu código pode escrever registos no Google Cloud Registo. Para mais informações, consulte os artigos Escreva registos padrão e Escreva registos estruturados.
Registo da porta de série
O Cloud TPU baseia-se no registo de portas de série para a resolução de problemas, a monitorização e a depuração. A predefinição é ativar o registo de portas de série. Se o registo da porta série não estiver ativado, o processo de criação da VM de TPU falha e gera a seguinte mensagem de erro.
"Cloud TPU received a bad request. Constraint
`constraints/compute.disableSerialPortLogging` violated. Create TPUs with
serial port logging enabled or remove the Organization Policy Constraint."
Esta mensagem indica que a restrição,
constraints/compute.disableSerialPortLogging foi violada.
Para evitar este erro, tem de garantir que o registo de portas série é permitido para os seus projetos de TPU. A prática recomendada é substituir a política da organização ao nível do projeto.
Para mais informações sobre como ativar o registo da porta série, consulte o artigo Ativar e desativar o registo de saída da porta série.
Registos Google Cloud de consultas
Quando vê os registos na Google Cloud consola, a página executa uma consulta predefinida.
Pode ver a consulta selecionando o Show query interruptor. Pode
modificar a consulta predefinida ou criar uma nova. Para mais informações, consulte o artigo
Crie consultas no Explorador de registos.
Registos de recursos auditados
Para ver os registos de recursos auditados:
- Aceda ao Google Cloud Explorador de registos.
- Clique no menu pendente Todos os recursos.
- Clique em Recurso auditado e, de seguida, em Cloud TPU.
- Escolha a API Cloud TPU que lhe interessa.
- Clique em Aplicar. Os registos são apresentados nos resultados da consulta.
Clique em qualquer entrada do registo para a expandir. Cada entrada de registo tem vários campos, incluindo:
- logName: o nome do registo
- protoPayload -> @type: o tipo do registo
- protoPayload -> resourceName: o nome do seu Cloud TPU
- protoPayload -> methodName: o nome do método chamado (apenas registos de auditoria)
- protoPayload -> request -> @type: o tipo de pedido
- protoPayload -> request -> node: detalhes sobre o nó da Cloud TPU
- protoPayload -> request -> node_id: o nome do TPU
- gravidade: a gravidade do registo
Registos do trabalhador da TPU
Para ver os registos do trabalhador da TPU:
- Aceda ao Google Cloud Explorador de registos.
- Clique no menu pendente Todos os recursos.
- Clique em TPU Worker.
- Selecione uma zona.
- Selecione o Cloud TPU no qual tem interesse.
- Clique em Aplicar. Os registos são apresentados nos resultados da consulta.
Clique em qualquer entrada do registo para a expandir. Cada entrada de registo tem um campo denominado jsonPayload. Expanda jsonPayload para ver vários campos, incluindo:
- accelerator_type: o tipo de acelerador
- consumer_project: o projeto onde reside a Cloud TPU
- evententry_timestamp: a hora em que o registo foi gerado
- system_available_memory_GiB: a memória disponível no worker do Cloud TPU (0 ~ 350 GiB)
Criar métricas baseadas em registos
Esta secção descreve como criar métricas baseadas em registos usadas para configurar painéis de controlo de monitorização e alertas. Para ver informações sobre como criar métricas baseadas em registos de forma programática, consulte o artigo Crie métricas baseadas em registos de forma programática com a API REST do Cloud Logging.
O exemplo seguinte usa o subcampo system_available_memory_GiB para demonstrar como criar uma métrica baseada em registos para monitorizar a memória disponível do worker do Cloud TPU.
- Aceda ao Google Cloud Explorador de registos.
Na caixa de consulta, introduza a seguinte consulta para extrair todas as entradas de registo que tenham system_available_memory_GiB definido para o worker do Cloud TPU principal:
resource.type=tpu_worker resource.labels.project_id=your-project resource.labels.zone=your-tpu-zone resource.labels.node_id=your-tpu-name resource.labels.worker_id=0 logName=projects/your-project/logs/tpu.googleapis.com%2Fruntime_monitor jsonPayload.system_available_memory_GiB:*
Clique em Criar métrica para apresentar o Editor de métricas.
Em Tipo de métrica, escolha Distribuição.
Escreva um nome, uma descrição opcional e uma unidade de medida para a métrica. Para este exemplo, escreva "matrix_unit_utilization_percent" e "MXU utilization" nos campos Nome e Descrição, respetivamente. O filtro é pré-preenchido com o script que introduziu no Explorador de registos.
Clique em Criar métrica.
Clique em Ver no explorador de métricas para ver a nova métrica. As métricas podem demorar alguns minutos a serem apresentadas.
Criar métricas baseadas em registos com a API REST do Cloud Logging
Também pode criar métricas baseadas em registos através da API Cloud Logging. Para mais informações, consulte o artigo Criar uma métrica de distribuição.
Criar painéis de controlo e alertas com métricas baseadas em registos
Os painéis de controlo são úteis para visualizar métricas (espere um atraso de cerca de 2 minutos). Os alertas são úteis para enviar notificações quando ocorrem erros. Para mais informações, consulte:
- Painéis de controlo de monitorização e registo
- Faça a gestão dos painéis de controlo personalizados
- Crie políticas de alerta baseadas em métricas
Criar painéis de controlo
Para criar um painel de controlo no Cloud Monitoring para a métrica Duração inativa do Tensorcore:
- Aceda à consola de monitorização.
- No painel de navegação, clique em Painéis de controlo.
- Clique em Criar painel de controlo e, de seguida, em Adicionar widget.
- Escolha o tipo de gráfico que quer adicionar. Para este exemplo, escolha Linha.
- Escreva um título para o widget.
- Clique no menu pendente Selecionar uma métrica e escreva "Duração de inatividade do Tensorcore" no campo de filtro.
- Na lista de métricas, selecione TPU Worker -> Tpu -> Tensorcore idle duration.
- Para filtrar o conteúdo do painel de controlo, clique no menu pendente Filtrar.
- Em Etiquetas de recursos, selecione project_id.
- Escolha um comparador e introduza um valor no campo Valor.
- Clique em Aplicar.