GKE の TPU の概要
Google Kubernetes Engine(GKE)のお客様は、TPU v4 と v5e の Pod を含む Kubernetes ノードプールを作成できるようになりました。TPU Pod - 高速相互接続で接続された TPU デバイスのグループ。これは、Kubernetes で作成して管理できる、デプロイ可能な最小のコンピューティング単位である Kubernetes Pod とは異なります。完全な TPU Pod を必要としないワークロードの場合は、TPU スライスと呼ばれる完全な TPU Pod のサブセットを使用できます。完全な TPU Pod と同様に、スライス内の各 TPU デバイスには独自の TPU VM があります。 TPU VM とその接続されたデバイスを、ホストまたは TPU ノードと呼びます。TPU 構成の詳細については、システム アーキテクチャをご覧ください。
通常、GKE のコンテキストで使用される Pod という用語は、Kubernetes Pod を意味します。混乱を避けるため、1 つ以上の TPU デバイスのコレクションを、常にスライスと呼ぶことにします。
GKE を使用する場合は、まず GKE クラスタを作成する必要があります。
次に、クラスタにノードプールを追加します。GKE ノードプールは、同じ属性を共有する VM のコレクションです。TPU ワークロードの場合、ノードプールは TPU VM で構成されます。
ノードプールの種類
GKE は、2 種類の TPU ノードプールをサポートしています。
マルチホスト TPU スライス ノードプール
マルチホスト TPU スライス ノードプールは、2 つ以上の相互接続された TPU VM を含むノードプールです。各 VM に TPU デバイスが接続されています。マルチホスト スライスの TPU は、高速相互接続(ICI)で接続されています。マルチホスト TPU スライスのノードプールは不変です。マルチホスト スライスのノードプールを作成した後に、ノードを追加することはできません。たとえば、v4-32 ノードプールを作成し、後でノードプールに Kubernetes ノード(TPU VM)を追加することはできません。GKE クラスタに TPU スライスを追加するには、新しいノードプールを作成する必要があります。
マルチホスト TPU スライス ノードプール内のホストは、単一のアトミック単位として扱われます。 GKE がスライスに 1 つのノードをデプロイできない場合、スライス内のすべてのノードのデプロイに失敗します。
マルチホスト TPU スライス内のノードを修復する必要がある場合、GKE はスライス内のすべての TPU VM(ノード)をシャットダウンし、ワークロード内のすべての Kubernetes Pod を強制的に排除します。スライス内のすべての TPU VM が稼働すると、新しいスライスの TPU VM で Kubernetes Pod をスケジュールできます。
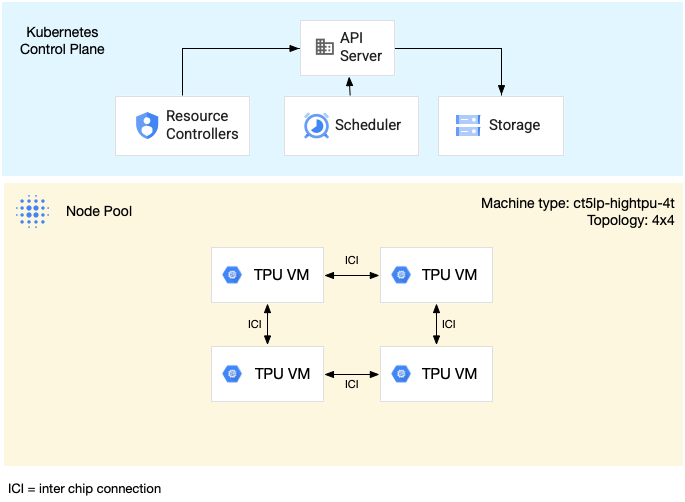
次の図は、v5litepod-16(v5e)マルチホスト TPU スライスの例を示しています。このスライスには 4 つの TPU VM があります。各 TPU VM には 4 つの TPU v5e チップがあり、高速相互接続(ICI)で接続されています。各 TPU v5e チップには 1 つの TensorCore があります。
次の図は、1 つの TPU v5litepod-16(v5e)スライス(トポロジ: 4x4)と 1 つの TPU v5litepod-8(v5e)スライス(トポロジ: 2x4)を含む GKE クラスタを示しています。
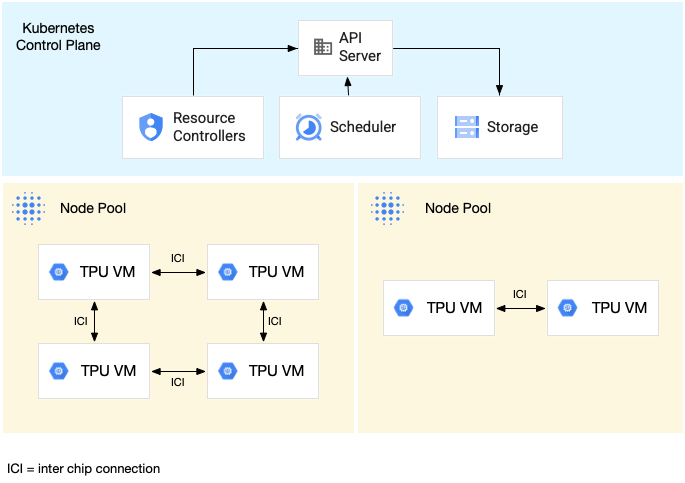
マルチホスト TPU スライスでワークロードを実行する例については、マルチホスト TPU スライスでワークロードを実行するをご覧ください。
単一ホスト TPU スライス ノードプール
単一ホスト スライスのノードプールは、1 つ以上の独立した TPU VM を含むノードプールです。各 VM には TPU デバイスが接続されています。単一ホスト スライスのノードプール内の VM はデータセンター ネットワーク(DCN)を介して通信できますが、VM に接続された TPU は相互接続されません。
次の図は、7 台の v4-8 マシンを持つ単一ホストの TPU スライスの例を示しています。
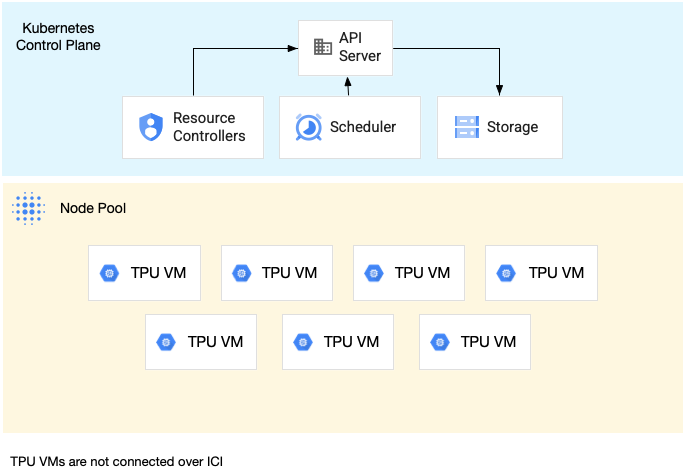
単一ホストの TPU スライスでワークロードを実行する例については、TPU ノードでワークロードを実行するをご覧ください。
GKE ノードプールの TPU マシンタイプ
ノードプールを作成する前に、ワークロードに必要な TPU バージョンと TPU スライスのサイズを選択する必要があります。TPU v4 は GKE Standard バージョン 1.26.1-gke.1500 以降で、v5e は GKE Standard バージョン 1.27.2-gke.2100 以降で、v5p は GKE Standard バージョン 1.28.3-gke.1024000 以降でサポートされています。
TPU v4、v5e、v5p は、GKE Autopilot バージョン 1.29.2-gke.1521000 以降でサポートされています。
TPU バージョン別のハードウェア仕様については、システム アーキテクチャをご覧ください。TPU ノードプールを作成するときに、モデルのサイズと必要なメモリ量に基づいて TPU スライスサイズ(TPU トポロジ)を選択します。ノードプールの作成時に指定するマシンタイプは、スライスのバージョンとサイズによって異なります。
v5e
トレーニングと推論のユースケースでサポートされている TPU v5e のマシンタイプとトポロジは次のとおりです。
| マシンタイプ | トポロジ | TPU チップの数 | VM 数 | おすすめの使用例 |
|---|---|---|---|---|
ct5lp-hightpu-1t |
1×1 | 1 | 1 | トレーニング、単一ホストの推論 |
ct5lp-hightpu-4t |
2x2 | 4 | 1 | トレーニング、単一ホストの推論 |
ct5lp-hightpu-8t |
2x4 | 8 | 1 | トレーニング、単一ホストの推論 |
ct5lp-hightpu-4t |
2x4 | 8 | 2 | トレーニング、マルチホストの推論 |
ct5lp-hightpu-4t |
4x4 | 16 | 4 | 大規模なトレーニング、マルチホストの推論 |
ct5lp-hightpu-4t |
4x8 | 32 | 8 | 大規模なトレーニング、マルチホストの推論 |
ct5lp-hightpu-4t |
8x8 | 64 | 16 | 大規模なトレーニング、マルチホストの推論 |
ct5lp-hightpu-4t |
8x16 | 128 | 32 | 大規模なトレーニング、マルチホストの推論 |
ct5lp-hightpu-4t |
16x16 | 256 | 64 | 大規模なトレーニング、マルチホストの推論 |
Cloud TPU v5e は、トレーニングと推論を組み合わせたプロダクトです。トレーニング ジョブはスループットと可用性に最適化されており、推論ジョブはレイテンシに最適化されています。詳細については、v5e トレーニング アクセラレータ タイプと v5e 推論アクセラレータ タイプをご覧ください。
TPU v5e マシンは、us-west4-a、us-east5-b、us-east1-c で利用できます。
GKE Standard クラスタでは、コントロール プレーン バージョン 1.27.2-gke.2100 以降を実行する必要があります。GKE Autopilot は、コントロール プレーン バージョン 1.29.2-gke.1521000 以降を実行する必要があります。v5e の詳細については、Cloud TPU v5e トレーニングをご覧ください。
マシンタイプの比較
| マシンタイプ | ct5lp-hightpu-1t | ct5lp-hightpu-4t | ct5lp-hightpu-8t |
|---|---|---|---|
| v5e チップの数 | 1 | 4 | 8 |
| vCPU 数 | 24 | 112 | 224 |
| RAM(GB) | 48 | 192 | 384 |
| NUMA ノードの数 | 1 | 1 | 2 |
| プリエンプションの可能性 | 高 | 中 | 低 |
チップ数の多い VM 用にスペースを確保するため、GKE スケジューラは、チップ数が少ない VM をプリエンプトして再スケジュールすることがあります。したがって、8 チップの VM は 1 チップ VM と 4 チップ VM をプリエンプトする可能性が高くなります。
v4 と v5p
TPU v4 および v5p のマシンタイプは次のとおりです。
| マシンタイプ | vCPU 数 | メモリ(GB) | NUMA ノードの数 |
|---|---|---|---|
ct4p-hightpu-4t |
240 | 407 | 2 |
ct5p-hightpu-4t |
208 | 448 | 2 |
TPU v4 スライスを作成する場合は、1 つのホストと 4 つのチップを含む ct4p-hightpu-4t マシンタイプを使用します。詳細については、v4 トポロジと TPU システム アーキテクチャをご覧ください。TPU v4 Pod マシンタイプは、us-central2-b で利用できます。GKE Standard クラスタは、コントロール プレーン バージョン 1.26.1-gke.1500 以降を実行する必要があります。GKE Autopilot クラスタは、コントロール プレーン バージョン 1.29.2-gke.1521000 以降を実行する必要があります。
TPU v5p スライスを作成する場合は、1 つのホストと 4 つのチップを含む ct5p-hightpu-4t マシンタイプを使用します。TPU v5p Pod マシンタイプは、us-west4-a と us-east5-a で利用できます。GKE Standard クラスタは、コントロール プレーン バージョン 1.28.3-gke.1024000 以降を実行する必要があります。GKE Autopilot は、1.29.2-gke.1521000 以降を実行する必要があります。v5p の詳細については、v5p トレーニングの概要をご覧ください。
既知の問題と制限事項
- Kubernetes Pod の最大数: 単一の TPU VM で最大 256 個の Kubernetes Pod を実行できます。
- 特殊な予約のみ: GKE で TPU を使用する場合、
gcloud container node-pools createコマンドの--reservation-affinityフラグでサポートされている値はSPECIFICのみです。 - プリエンプティブル TPU の Spot VM バリアントのみをサポート: Spot VM はプリエンプティブル VM に似ており、同じ可用性制限が適用されますが、最大時間 24 時間の制限はありません。
- 費用割り当てサポートなし: GKE の費用割り当てと使用状況測定には、TPU の使用量と費用に関するデータは含まれません。
- オートスケーラーが容量を計算する: クラスタ オートスケーラーは、新しい TPU ノードが利用可能になる前に、新しい TPU ノードの容量を正しく計算しないことがあります。これにより、クラスタ オートスケーラーが追加のスケールアップを実行して、結果として必要以上にノードを作成する場合があります。クラスタ オートスケーラーは、通常のスケールダウン オペレーションの後、不要なノードをスケールダウンします。
- オートスケーラーがスケールアップをキャンセルする: クラスタ オートスケーラーは、10 時間以上待機状態になっている TPU ノードプールのスケールアップをキャンセルしますクラスタ オートスケーラーは、このようなスケールアップ オペレーションを後で再試行します。この動作により、予約を使用しない TPU の取得可能性が低下する可能性があります。
- taint でスケールダウンが妨げられる: TPU taint の容認機能がある TPU 以外のワークロードは、TPU ノードプールのドレイン中に再作成されると、ノードプールのスケールダウンを妨げることがあります。
十分な TPU 割り当てと GKE 割り当てを確保する
リソースが作成されるリージョンでは、GKE 関連の特定の割り当てを引き上げる必要があります。
次の割り当てには、増やす必要性が高いデフォルト値があります。
- Persistent Disk SSD(GB)割り当て: 各 Kubernetes ノードのブートディスクにはデフォルトで 100 GB 必要です。そのため、この割り当ては、少なくとも、(作成する予定の GKE ノードの最大数)x 100GB に設定する必要があります。
- 使用中の IP アドレスの割り当て: 各 Kubernetes ノードは 1 つの IP アドレスを消費します。そのため、この割り当ては、少なくとも、作成する予定の GKE ノードの最大数と同じ値に設定する必要があります。
割り当ての増加をリクエストするには、割り当ての増加をリクエストするをご覧ください。 TPU 割り当ての種類について詳しくは、TPU 割り当てをご覧ください。
割り当て増加のリクエストが承認されるまで数日かかることがあります。数日以内に割り当ての増加リクエストが承認されない場合は、Google アカウント チームにお問い合わせください。
TPU 予約を移行する
GKE の TPU で既存の TPU 予約を使用する予定がない場合は、このセクションをスキップして Google Kubernetes Engine クラスタの作成に移動してください。
GKE で予約済み TPU を使用するには、まず TPU 予約を新しい Compute Engine ベースの予約システムに移行する必要があります。
この移行について、注意すべき重要な点がいくつかあります。
- 新しい Compute Engine ベースの予約システムに移行された TPU 容量は、Cloud TPU Queued Resource API では使用できません。 TPU キューに格納されたリソースを予約で使用する場合は、TPU 予約の一部のみを新しい Compute Engine ベースの予約システムに移行する必要があります。
- 新しい Compute Engine ベースの予約システムに移行すされている場合、TPU でアクティブに実行できるワークロードはありません。
- 移行を実行する時間を選択し、Google Cloud アカウント チームと協力して移行をスケジュールします。移行の時間枠は、営業時間中(月曜日~金曜日の太平洋時間午前 9 時~午後 5 時)にする必要があります。
Google Kubernetes Engine クラスタを作成する
Google Kubernetes Engine のドキュメントのクラスタを作成するをご覧ください。
TPU ノードプールを作成する
Google Kubernetes Engine のドキュメントのノードプールを作成するをご覧ください。
特権モードなしでの実行
コンテナの権限の範囲を縮小するには、TPU 権限モードをご覧ください。
TPU ノードでワークロードを実行する
Google Kubernetes Engine のドキュメントの TPU ノードでワークロードを実行するをご覧ください。
ノードセレクタ
Kubernetes が TPU ノードでワークロードをスケジュールするには、Google Kubernetes Engine マニフェストの TPU ノードごとに 2 つのセレクタを指定する必要があります。
cloud.google.com/gke-accelerator-typeをtpu-v5-lite-podsliceまたはtpu-v4-podsliceに設定します。cloud.google.com/gke-tpu-topologyを TPU ノードの TPU トポロジに設定します。
トレーニング ワークロードと推論ワークロードのセクションには、これらのノードセレクタの使用方法を示すマニフェストの例が含まれています。
ワークロードのスケジューリングに関する考慮事項
TPU には、Kubernetes での特別なワークロードのスケジューリングと管理を必要とする固有の特性があります。詳細については、GKE ドキュメントのワークロードのスケジューリングに関する考慮事項をご覧ください。
TPU ノードの修復
マルチホスト TPU スライス ノードプール内の TPU ノードが正常でない場合は、ノードプール全体が再作成されます。詳細については、GKE ドキュメントのノードの自動修復をご覧ください。
マルチスライス - 単一スライス以外
小さなスライスをマルチスライスに集約することで、より大きなトレーニング ワークロードを処理できます。詳細については、Cloud TPU マルチスライスをご覧ください。
トレーニング ワークロードのチュートリアル
このチュートリアルでは、マルチホスト TPU スライス(たとえば 4 つの v5e マシン)でワークロードをトレーニングする方法について説明します。次のモデルを対象としています。
- Hugging Face FLAX Models: Pokémon 上で Diffusion をトレーニングする
- PyTorch/XLA: WikiText 上の GPT2
チュートリアルのリソースをダウンロードする
次のコマンドを使用して、各トレーニング済みモデルのチュートリアル Python スクリプトと YAML 仕様をダウンロードします。
git clone https://github.com/GoogleCloudPlatform/ai-on-gke.git
クラスタを作成して接続する
リージョン GKE クラスタを作成することにより、Kubernetes コントロール プレーンが 3 つのゾーンに複製され、高可用性を実現します。使用する TPU のバージョンに応じて、us-west4、us-east1 または us-central2 でクラスタを作成します。TPU とゾーンの詳細については、Cloud TPU のリージョンとゾーンをご覧ください。
次のコマンドは、最初にゾーンごとに 1 つのノードを含むノードプールを持つ、ラピッド リリース チャンネルに登録される新しい GKE リージョン クラスタを作成します。このガイドの推論ワークロードの例では、Cloud Storage バケットを使用して事前トレーニング済みモデルを保存しているため、このコマンドは、Workload Identity と Cloud Storage FUSE CSI ドライバの機能もクラスタで有効にします。
gcloud container clusters create cluster-name \ --region your-region \ --release-channel rapid \ --num-nodes=1 \ --workload-pool=project-id.svc.id.goog \ --addons GcsFuseCsiDriver
既存のクラスタに対して Workload Identity と Cloud Storage FUSE CSI ドライバの機能を有効にするには、次のコマンドを実行します。
gcloud container clusters update cluster-name \ --region your-region \ --update-addons GcsFuseCsiDriver=ENABLED \ --workload-pool=project-id.svc.id.goog
このサンプル ワークロードは、次のことを前提として構成されています。
- ノードプールは 4 つのノードを持つ
tpu-topology=4x4を使用している - ノードプールは
machine-typect5lp-hightpu-4tを使用している
次のコマンドを実行して、新しく作成したクラスタに接続します。
gcloud container clusters get-credentials cluster-name \ --location=cluster-region
Hugging Face FLAX Models: Pokémon 上で Diffusion をトレーニングする
この例では、Pokémon データセットを使用して HuggingFace からの Stable Diffusion モデルをトレーニングします。
Stable Diffusion モデルは、テキスト入力からフォトリアリスティックな画像を生成する、潜在的 text-to-image モデルです。Stable Diffusion の詳細については、以下をご覧ください。
Docker イメージを作成する
Dockerfile はフォルダ ai-on-gke/tutorials-and-examples/tpu-examples/training/diffusion/ の下にあります。次のコマンドを実行して、Docker イメージのビルドと push を行います。
cd ai-on-gke/tutorials-and-examples/tpu-examples/training/diffusion/ docker build -t gcr.io/project-id/diffusion:latest . docker push gcr.io/project-id/diffusion:latest
ワークロードをデプロイする
次のコンテンツを含むファイルを作成し、tpu_job_diffusion.yaml という名前を付けます。
イメージ フィールドに、作成したイメージを入力します。
apiVersion: v1
kind: Service
metadata:
name: headless-svc
spec:
clusterIP: None
selector:
job-name: tpu-job-diffusion
---
apiVersion: batch/v1
kind: Job
metadata:
name: tpu-job-diffusion
spec:
backoffLimit: 0
# Completions and parallelism should be the number of chips divided by 4.
# (e.g. 4 for a v5litepod-16)
completions: 4
parallelism: 4
completionMode: Indexed
template:
spec:
subdomain: headless-svc
restartPolicy: Never
nodeSelector:
cloud.google.com/gke-tpu-accelerator: tpu-v5-lite-podslice
cloud.google.com/gke-tpu-topology: 4x4
containers:
- name: tpu-job-diffusion
image: gcr.io/${project-id}/diffusion:latest
ports:
- containerPort: 8471 # Default port using which TPU VMs communicate
- containerPort: 8431 # Port to export TPU usage metrics, if supported
command:
- bash
- -c
- |
cd examples/text_to_image
python3 train_text_to_image_flax.py --pretrained_model_name_or_path=duongna/stable-diffusion-v1-4-flax --dataset_name=lambdalabs/pokemon-blip-captions --resolution=128 --center_crop --random_flip --train_batch_size=4 --mixed_precision=fp16 --max_train_steps=1500 --learning_rate=1e-05 --max_grad_norm=1 --output_dir=sd-pokemon-model
resources:
requests:
google.com/tpu: 4
limits:
google.com/tpu: 4
次に、以下のコマンドを使用してデプロイします。
kubectl apply -f tpu_job_diffusion.yaml
クリーンアップ
ジョブの実行が終了したら、次のコマンドを使用してジョブを削除できます。
kubectl delete -f tpu_job_diffusion.yaml
PyTorch/XLA: WikiText 上の GPT2
このチュートリアルでは、wikitext データセットを使用して PyTorch/XLA で HuggingFace を使用して、v5e TPU で GPT2 を実行する方法を説明します。
Docker イメージを作成する
Dockerfile はフォルダ ai-on-gke/tutorials-and-examples/tpu-examples/training/gpt/ の下にあります。次のコマンドを実行して、Docker イメージのビルドと push を行います。
cd ai-on-gke/tutorials-and-examples/tpu-examples/training/gpt/ docker build -t gcr.io/project-id/gpt:latest . docker push gcr.io/project-id/gpt:latest
ワークロードをデプロイする
次の YAML をコピーして tpu_job_gpt.yaml というファイルに保存します。作成したイメージをイメージ フィールドに入力します。
apiVersion: v1
kind: Service
metadata:
name: headless-svc
spec:
clusterIP: None
selector:
job-name: tpu-job-gpt
---
apiVersion: batch/v1
kind: Job
metadata:
name: tpu-job-gpt
spec:
backoffLimit: 0
# Completions and parallelism should be the number of chips divided by 4.
# (for example, 4 for a v5litepod-16)
completions: 4
parallelism: 4
completionMode: Indexed
template:
spec:
subdomain: headless-svc
restartPolicy: Never
volumes:
# Increase size of tmpfs /dev/shm to avoid OOM.
- name: shm
emptyDir:
medium: Memory
# consider adding `sizeLimit: XGi` depending on needs
nodeSelector:
cloud.google.com/gke-tpu-accelerator: tpu-v5-lite-podslice
cloud.google.com/gke-tpu-topology: 4x4
containers:
- name: tpu-job-gpt
image: gcr.io/$(project-id)/gpt:latest
ports:
- containerPort: 8479
- containerPort: 8478
- containerPort: 8477
- containerPort: 8476
- containerPort: 8431 # Port to export TPU usage metrics, if supported.
env:
- name: PJRT_DEVICE
value: 'TPU'
- name: XLA_USE_BF16
value: '1'
command:
- bash
- -c
- |
numactl --cpunodebind=0 python3 -u examples/pytorch/xla_spawn.py --num_cores 4 examples/pytorch/language-modeling/run_clm.py --num_train_epochs 3 --dataset_name wikitext --dataset_config_name wikitext-2-raw-v1 --per_device_train_batch_size 16 --per_device_eval_batch_size 16 --do_train --do_eval --output_dir /tmp/test-clm --overwrite_output_dir --config_name my_config_2.json --cache_dir /tmp --tokenizer_name gpt2 --block_size 1024 --optim adafactor --adafactor true --save_strategy no --logging_strategy no --fsdp "full_shard" --fsdp_config fsdp_config.json
volumeMounts:
- mountPath: /dev/shm
name: shm
resources:
requests:
google.com/tpu: 4
limits:
google.com/tpu: 4
以下のコマンドを使用してデプロイします。
kubectl apply -f tpu_job_gpt.yaml
クリーンアップ
ジョブの実行が終了したら、次のコマンドを使用してジョブを削除できます。
kubectl delete -f tpu_job_gpt.yaml
チュートリアル: 単一ホストの推論ワークロード
このチュートリアルでは、JAX、TensorFlow、PyTorch を使用して、GKE v5e TPU 上で事前にトレーニングされたモデルの単一ホストの推論ワークロードを実行する方法について説明します。GKE クラスタでは、大きく分けて、実行する次の 4 つのステップがあります。
Cloud Storage バケットを作成し、バケットへのアクセスを設定します。事前トレーニング済みモデルの保存には、Cloud Storage バケットが使用されます。
事前トレーニング済みモデルをダウンロードして TPU 互換モデルに変換します。事前トレーニング済みモデルをダウンロードし、Cloud TPU Converter を使用し、変換されたモデルを Cloud Storage FUSE CSI ドライバを使用して Cloud Storage バケットに保存する Kubernetes Pod を適用します。Cloud TPU Converter には特別なハードウェアは必要ありません。このチュートリアルでは、モデルをダウンロードして CPU ノードプールで Cloud TPU Converter を実行する方法について説明します。
変換されたモデルのサーバーを起動します。ReadOnlyMany(ROX)Persistent ボリュームに保存されているボリュームを基盤とするサーバー フレームワークを使用して、モデルを提供する Deployment を適用します。Deployment レプリカは、ノードごとに 1 つの Kubernetes Pod を持つ v5e Pod TPU ノードで実行する必要があります。
ロードバランサをデプロイして、モデルサーバーをテストします。サーバーは LoadBalancer Service を使用して外部リクエストに公開されます。モデル サーバーのテスト用に、サンプル リクエスト付きの Python スクリプトが用意されています。
次の図は、ロードバランサによってリクエストがルーティングされる方法を示しています。
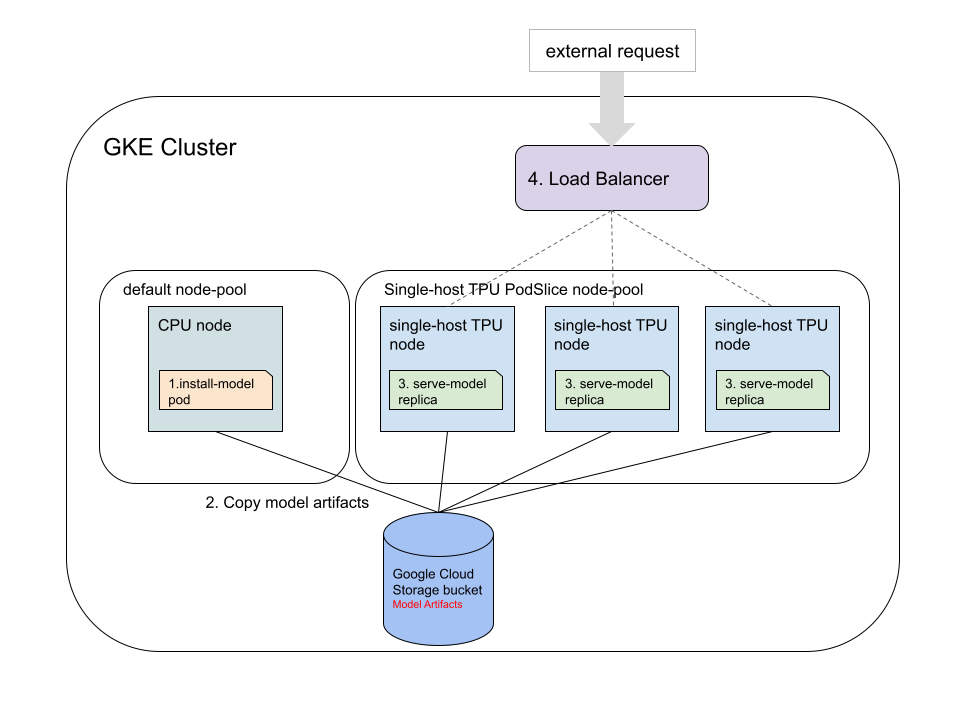
サーバーの Deployment の例
このサンプル ワークロードは、次のことを前提として構成されています。
- クラスタは 3 つのノードを持つ TPU v5 ノードプールで実行されている
- ノードプールはマシンタイプ
ct5lp-hightpu-1tを使用している。ここで- トポロジは 1x1
- TPU チップの数は 1
次の GKE マニフェストは、単一のホストサーバーの Deployment を定義します。
apiVersion: apps/v1
kind: Deployment
metadata:
name: bert-deployment
spec:
selector:
matchLabels:
app: tf-bert-server
replicas: 3 # number of nodes in node pool
template:
metadata:
annotations:
gke-gcsfuse/volumes: "true"
labels:
app: tf-bert-server
spec:
nodeSelector:
cloud.google.com/gke-tpu-topology: 1x1 # target topology
cloud.google.com/gke-tpu-accelerator: tpu-v5-lite-podslice # target version
containers:
- name: serve-bert
image: us-docker.pkg.dev/cloud-tpu-images/inference/tf-serving-tpu:2.13.0
env:
- name: MODEL_NAME
value: "bert"
volumeMounts:
- mountPath: "/models/"
name: bert-external-storage
ports:
- containerPort: 8500
- containerPort: 8501
- containerPort: 8431 # Port to export TPU usage metrics, if supported.
resources:
requests:
google.com/tpu: 1 # TPU chip request
limits:
google.com/tpu: 1 # TPU chip request
volumes:
- name: bert-external-storage
persistentVolumeClaim:
claimName: external-storage-pvc
TPU ノードプールで異なる数のノードを使用している場合は、replicas フィールドをノードの数に変更します。
Standard クラスタで GKE バージョン 1.27 以前が実行されている場合は、次のフィールドをマニフェストに追加します。
spec:
securityContext:
privileged: true
GKE バージョン 1.28 以降では、Kubernetes Pod を特権モードで実行する必要はありません。詳細については、特権モードなしでコンテナを実行するをご覧ください。
別のマシンタイプを使用している場合は、以下のようにします。
cloud.google.com/gke-tpu-topologyを、使用しているマシンタイプのトポロジに設定します。resourcesの下にある両方のgoogle.com/tpuフィールドを、対応するマシンタイプのチップ数に合わせて設定します。
設定
次のコマンドを使用して、チュートリアルの Python スクリプトと YAML マニフェストをダウンロードします。
git clone https://github.com/GoogleCloudPlatform/ai-on-gke.git
single-host-inference ディレクトリに移動します。
cd ai-on-gke/gke-tpu-examples/single-host-inference/
Python 環境を設定する
このチュートリアルで使用する Python スクリプトには、Python バージョン 3.9 以降が必要です。
Python テスト スクリプトを実行する前に、チュートリアルごとに requirements.txt をインストールしてください。
ローカル環境に適切な Python 設定がない場合は、Cloud Shell を使用して、このチュートリアルの Python スクリプトをダウンロードして実行できます。
クラスタを設定する
e2-standard-4マシンタイプを使用してクラスタを作成します。gcloud container clusters create cluster-name \ --region your-region \ --release-channel rapid \ --num-nodes=1 \ --machine-type=e2-standard-4 \ --workload-pool=project-id.svc.id.goog \ --addons GcsFuseCsiDriver
サンプル ワークロードは次のことを前提としています。
- クラスタは 3 ノードの TPU v5e ノードプールで実行されている。
- TPU ノードプールはマシンタイプ
ct5lp-hightpu-1tを使用している。
前述のものとは異なるクラスタ構成を使用している場合は、サーバー Deployment マニフェストを編集する必要があります。
JAX Stable Diffusion のデモでは、16 GB 以上の使用可能なメモリを備えたマシンタイプ(たとえば、e2-standard-4)の CPU ノードプールが必要です。これは、gcloud container clusters create コマンド、または次のコマンドを使用して、既存のクラスタにノードプールを追加することによって構成されます。
gcloud beta container node-pools create your-pool-name \ --zone=your-cluster-zone \ --cluster=your-cluster-name \ --machine-type=e2-standard-4 \ --num-nodes=1
以下を置き換えます。
your-pool-name: 作成するノードプールの名前。your-cluster-zone: クラスタが作成されたゾーン。your-cluster-name: ノードプールを追加するクラスタの名前。your-machine-type: ノードプール内に作成するノードのマシンタイプ。
モデル ストレージを設定する
提供するモデルの保存方法はいくつかあります。このチュートリアルでは、次のアプローチを使用します。
- TPU で動作するように事前トレーニング済みモデルを変換するために、
ReadWriteMany(RWX)アクセス権を持つ Persistent Disk を基盤とする Virtual Private Cloud を使用します。 - 複数の単一ホスト TPU でモデルを提供するには、Cloud Storage バケットを基盤とする同じ VPC を使用します。
次のコマンドを実行して Cloud Storage バケットを作成します。
gcloud storage buckets create gs://your-bucket-name \ --project=your-bucket-project-id \ --location=your-bucket-location
以下を置き換えます。
your-bucket-name: Cloud Storage バケットの名前。your-bucket-project-id: Cloud Storage バケットを作成したプロジェクト ID。your-bucket-location: Cloud Storage バケットのロケーション。パフォーマンスを向上させるには、GKE クラスタが実行されているロケーションを指定します。
GKE クラスタにバケットへのアクセスを許可するには、次の操作を行います。設定を簡素化するために、次の例ではデフォルトの名前空間とデフォルトの Kubernetes サービス アカウントを使用しています。詳細については、GKE Workload Identity を使用して Cloud Storage バケットへのアクセスを構成するをご覧ください。
アプリケーションに IAM サービス アカウントを作成するか、既存の IAM サービス アカウントを使用します。Cloud Storage バケットのプロジェクトでは、任意の IAM サービス アカウントを使用できます。
gcloud iam service-accounts create your-iam-service-acct \ --project=your-bucket-project-id
以下を置き換えます。
your-iam-service-acct: 新しい IAM サービス アカウントの名前。your-bucket-project-id: IAM サービス アカウントを作成したプロジェクトの ID。IAM サービス アカウントは、Cloud Storage バケットと同じプロジェクト内に存在する必要があります。
必要なストレージ ロールが IAM サービス アカウントにあることを確認します。
gcloud storage buckets add-iam-policy-binding gs://your-bucket-name \ --member "serviceAccount:your-iam-service-acct@your-bucket-project-id.iam.gserviceaccount.com" \ --role "roles/storage.objectAdmin"
以下を置き換えます。
your-bucket-name: Cloud Storage バケットの名前。your-iam-service-acct: 新しい IAM サービス アカウントの名前。your-bucket-project-id: IAM サービス アカウントを作成したプロジェクトの ID。
2 つのサービス アカウントの間に IAM ポリシー バインディングを追加して、Kubernetes サービス アカウントが IAM サービス アカウントの権限を借用できるようにします。このバインドでは、Kubernetes サービス アカウントが IAM サービス アカウントとして機能します。
gcloud iam service-accounts add-iam-policy-binding your-iam-service-acct@your-bucket-project-id.iam.gserviceaccount.com \ --role roles/iam.workloadIdentityUser \ --member "serviceAccount:your-project-id.svc.id.goog[default/default]"
以下を置き換えます。
your-iam-service-acct: 新しい IAM サービス アカウントの名前。your-bucket-project-id: IAM サービス アカウントを作成したプロジェクトの ID。your-project-id: GKE クラスタを作成したプロジェクトの ID。Cloud Storage バケットと GKE クラスタは、同じプロジェクトまたは別のプロジェクトに存在する可能性があります。
Kubernetes サービス アカウントに IAM サービス アカウントのメールアドレスでアノテーションを付けます。
kubectl annotate serviceaccount default \ --namespace default \ iam.gke.io/gcp-service-account=your-iam-service-acct@your-bucket-project-id.iam.gserviceaccount.com
以下を置き換えます。
your-iam-service-acct: 新しい IAM サービス アカウントの名前。your-bucket-project-id: IAM サービス アカウントを作成したプロジェクトの ID。
次のコマンドを実行して、このデモの YAML ファイルにバケット名を入力します。
find . -type f -name "*.yaml" | xargs sed -i "s/BUCKET_NAME/your-bucket-name/g"
your-bucket-nameは、Cloud Storage バケットの名前に置き換えます。次のコマンドを使用して、Persisten Volume と Persistent Volume Claim を作成します。
kubectl apply -f pvc-pv.yaml
JAX モデルの推論とサービス提供
JAX モデルサービスにリクエストを送信するチュートリアル Python スクリプトを実行するための Python 依存関係をインストールします。
pip install -r jax/requirements.txt
JAX BERT E2E サービス提供デモを実行します。
このデモでは、Hugging Face からの事前トレーニング済みの BERT モデルを使用します。
Kubernetes Pod は、次の手順を実行します。
- サンプル リソースから Python スクリプト
export_bert_model.pyをダウンロードして使用し、事前トレーニング済みの bert モデルを一時ディレクトリにダウンロードします。 - Cloud TPU Converter イメージを使用して、事前トレーニング済みモデルを CPU から TPU に変換し、セットアップ時に作成した Cloud Storage バケットにモデルを保存します。
この Kubernetes Pod は、デフォルトのノードプール CPU で実行するように構成されています。次のコマンドで Pod を実行します。
kubectl apply -f jax/bert/install-bert.yaml
以下のコマンドを使用して、モデルが正しくインストールされたことを確認します。
kubectl get pods install-bert
STATUS が Completed を読み取るまでに数分かかる場合があります。
モデルの TF モデルサーバーを起動する
このチュートリアルのサンプル ワークロードは、次のことを前提としています。
- クラスタは 3 つのノードを持つ TPU v5 ノードプールで実行されている
- ノードプールは 1 つの TPU チップを含む
ct5lp-hightpu-1tマシンタイプを使用している
前述のものとは異なるクラスタ構成を使用している場合は、サーバー Deployment マニフェストを編集する必要があります。
Deployment を適用する
kubectl apply -f jax/bert/serve-bert.yaml
次のコマンドを使用して、サーバーが稼働していることを確認します。
kubectl get deployment bert-deployment
AVAILABLE が 3 を読み取るまでに 1 分ほどかかることがあります。
ロードバランサ サービスを適用する
kubectl apply -f jax/bert/loadbalancer.yaml
以下のコマンドを使用して、ロードバランサが外部トラフィックに対して準備ができていることを確認します。
kubectl get svc tf-bert-service
EXTERNAL_IP に IP が表示されるまでには数分かかる場合があります。
モデルサーバーにリクエストを送信する
ロードバランサ サービスから外部 IP を取得します。
EXTERNAL_IP=$(kubectl get services tf-bert-service --output jsonpath='{.status.loadBalancer.ingress[0].ip}')
サーバーにリクエストを送信するスクリプトを実行します。
python3 jax/bert/bert_request.py $EXTERNAL_IP
予想される出力:
For input "The capital of France is [MASK].", the result is ". the capital of france is paris.."
For input "Hello my name [MASK] Jhon, how can I [MASK] you?", the result is ". hello my name is jhon, how can i help you?."
クリーンアップ
リソースをクリーンアップするには、kubectl delete を逆順で実行します。
kubectl delete -f jax/bert/loadbalancer.yaml kubectl delete -f jax/bert/serve-bert.yaml kubectl delete -f jax/bert/install-bert.yaml
JAX Stable Diffusion E2E サービス提供デモを実行する
このデモでは、Hugging Face からの事前トレーニング済みのStable Diffusion モデルを使用します。
TPU 互換の TF2 保存済みモデルを Flax Stable Diffusion モデルからエクスポートする
Stable Diffusion モデルをエクスポートするには、クラスタの設定で説明されているように、クラスタに 16 GB 以上の利用可能なメモリを備えたマシンタイプの CPU ノードプールが必要です。
Kubernetes Pod は、次の手順を実行します。
- サンプル リソースから Python スクリプト
export_stable_diffusion_model.pyをダウンロードして使用し、トレーニング済みの Stable Diffusion モデルを一時ディレクトリにダウンロードします。 - Cloud TPU Converter イメージを使用して、事前トレーニング済みモデルを CPU から TPU に変換し、ストレージの設定中に作成した Cloud Storage バケットにモデルを保存します。
この Kubernetes Pod は、デフォルトの CPU ノードプールで実行するように構成されています。次のコマンドで Pod を実行します。
kubectl apply -f jax/stable-diffusion/install-stable-diffusion.yaml
以下のコマンドを使用して、モデルが正しくインストールされたことを確認します。
kubectl get pods install-stable-diffusion
STATUS が Completed を読み取るまでに数分かかる場合があります。
モデルの TF モデルサーバー コンテナを起動する
サンプル ワークロードは、以下を前提として構成されています。
- クラスタは 3 つのノードを持つ TPU v5 ノードプールで実行されている
- ノードプールは
ct5lp-hightpu-1tマシンタイプを使用している。ここで- トポロジは 1x1
- TPU チップの数は 1
前述のものとは異なるクラスタ構成を使用している場合は、サーバー Deployment マニフェストを編集する必要があります。
Deployment を適用します。
kubectl apply -f jax/stable-diffusion/serve-stable-diffusion.yaml
サーバーが期待どおりに動作していることを確認します。
kubectl get deployment stable-diffusion-deployment
AVAILABLE が 3 を読み取るまでに 1 分ほどかかることがあります。
ロードバランサ サービスを適用します。
kubectl apply -f jax/stable-diffusion/loadbalancer.yaml
以下のコマンドを使用して、ロードバランサが外部トラフィックに対して準備ができていることを確認します。
kubectl get svc tf-stable-diffusion-service
EXTERNAL_IP に IP が表示されるまでには数分かかる場合があります。
モデルサーバーにリクエストを送信する
ロードバランサから外部 IP を取得します。
EXTERNAL_IP=$(kubectl get services tf-stable-diffusion-service --output jsonpath='{.status.loadBalancer.ingress[0].ip}')
サーバーにリクエストを送信するためのスクリプトを実行する
python3 jax/stable-diffusion/stable_diffusion_request.py $EXTERNAL_IP
予想される出力:
プロンプトが Painting of a squirrel skating in New York で、出力イメージが現在のディレクトリに stable_diffusion_images.jpg として保存されます。
クリーンアップ
リソースをクリーンアップするには、kubectl delete を逆順で実行します。
kubectl delete -f jax/stable-diffusion/loadbalancer.yaml kubectl delete -f jax/stable-diffusion/serve-stable-diffusion.yaml kubectl delete -f jax/stable-diffusion/install-stable-diffusion.yaml
TensorFlow ResNet 50 E2E サービス提供デモを実行します。
TF モデルサービスにリクエストを送信するチュートリアル Python スクリプトを実行するための Python 依存関係をインストールします。
pip install -r tf/resnet50/requirements.txt
ステップ 1: モデルを変換する
モデル変換を適用します。
kubectl apply -f tf/resnet50/model-conversion.yml
以下のコマンドを使用して、モデルが正しくインストールされたことを確認します。
kubectl get pods resnet-model-conversion
STATUS が Completed を読み取るまでに数分かかる場合があります。
ステップ 2: TensorFlow サービス提供でモデルを提供する
モデルサービス提供の Deployment を適用します。
kubectl apply -f tf/resnet50/deployment.yml
次のコマンドを使用して、サーバーが想定どおりに動作していることを確認します。
kubectl get deployment resnet-deployment
AVAILABLE が 3 を読み取るまでに 1 分ほどかかることがあります。
ロードバランサ サービスを適用します。
kubectl apply -f tf/resnet50/loadbalancer.yml
以下のコマンドを使用して、ロードバランサが外部トラフィックに対して準備ができていることを確認します。
kubectl get svc resnet-service
EXTERNAL_IP に IP が表示されるまでには数分かかる場合があります。
ステップ 3: テストリクエストをモデルサーバーに送信する
ロードバランサから外部 IP を取得します。
EXTERNAL_IP=$(kubectl get services resnet-service --output jsonpath='{.status.loadBalancer.ingress[0].ip}')
テスト リクエスト(HTTP)スクリプトを実行して、リクエストをモデルサーバーに送信します。
python3 tf/resnet50/request.py --host $EXTERNAL_IP
レスポンスは次のようになります。
Predict result: ['ImageNet ID: n07753592, Label: banana, Confidence: 0.94921875', 'ImageNet ID: n03532672, Label: hook, Confidence: 0.0223388672', 'ImageNet ID: n07749582, Label: lemon, Confidence: 0.00512695312
ステップ 4: クリーンアップする
リソースをクリーンアップするには、次の kubectl delete コマンドを実行します。
kubectl delete -f tf/resnet50/loadbalancer.yml kubectl delete -f tf/resnet50/deployment.yml kubectl delete -f tf/resnet50/model-conversion.yml
それらが完了したら、GKE ノードプールとクラスタを削除します。
PyTorch モデルの推論とサービス提供
PyTorch モデルサービスにリクエストを送信する Python スクリプトを実行するために、Python 依存関係をインストールします。
pip install -r pt/densenet161/requirements.txt
TorchServe Densenet161 E2E サービス提供デモを実行します。
モデル アーカイブを生成します。
- モデル アーカイブを適用します。
kubectl apply -f pt/densenet161/model-archive.yml
- 以下のコマンドを使用して、モデルが正しくインストールされたことを確認します。
kubectl get pods densenet161-model-archive
STATUSがCompletedを読み取るまでに数分かかる場合があります。TorchServe でモデルを提供します。
モデルサービス提供の Deployment を適用します。
kubectl apply -f pt/densenet161/deployment.yml
次のコマンドを使用して、サーバーが想定どおりに動作していることを確認します。
kubectl get deployment densenet161-deployment
AVAILABLEが3を読み取るまでに 1 分ほどかかることがあります。ロードバランサ サービスを適用します。
kubectl apply -f pt/densenet161/loadbalancer.yml
以下のコマンドを使用して、ロードバランサが外部トラフィックに対して準備ができていることを確認します。
kubectl get svc densenet161-service
EXTERNAL_IPに IP が表示されるまでには数分かかる場合があります。
テスト リクエストをモデルサーバーに送信します。
ロードバランサから外部 IP を取得します。
EXTERNAL_IP=$(kubectl get services densenet161-service --output jsonpath='{.status.loadBalancer.ingress[0].ip}')
テスト リクエスト スクリプトを実行して、リクエスト(HTTP)をモデルサーバーに送信します。
python3 pt/densenet161/request.py --host $EXTERNAL_IP
次のようなレスポンスが表示されます。
Request successful. Response: {'tabby': 0.47878125309944153, 'lynx': 0.20393909513950348, 'tiger_cat': 0.16572578251361847, 'tiger': 0.061157409101724625, 'Egyptian_cat': 0.04997897148132324
次の
kubectl deleteコマンドを実行してリソースをクリーンアップします。kubectl delete -f pt/densenet161/loadbalancer.yml kubectl delete -f pt/densenet161/deployment.yml kubectl delete -f pt/densenet161/model-archive.yml
一般的な問題のトラブルシューティング
GKE のトラブルシューティング情報については、GKE での TPU のトラブルシューティングをご覧ください。
TPU の初期化に失敗した
次のエラーが発生した場合は、TPU コンテナを特権モードで実行しているか、コンテナ内で ulimit を増やしていることを確認してください。詳細については、特権モードなしでの実行をご覧ください。
TPU platform initialization failed: FAILED_PRECONDITION: Couldn't mmap: Resource
temporarily unavailable.; Unable to create Node RegisterInterface for node 0,
config: device_path: "/dev/accel0" mode: KERNEL debug_data_directory: ""
dump_anomalies_only: true crash_in_debug_dump: false allow_core_dump: true;
could not create driver instance
スケジューリングのデッドロック
2 つのジョブ(ジョブ A とジョブ B)があり、両方が特定の TPU トポロジ(たとえば、v4-32)を持つ TPU スライスでスケジューリングされるとします。また、GKE クラスタ内に 2 つの v4-32 TPU スライスがあり、これをスライス X とスライス Y と呼ぶことにします。クラスタには両方のジョブをスケジュールするのに十分な容量があるため、理論的には、両方のジョブをすばやくスケジュールする必要があります。2 つの TPU v4-32 スライスのそれぞれに 1 つのジョブが必要です。
ただし、慎重に計画しなければ、スケジューリングのデッドロックが発生する可能性があります。Kubernetes スケジューラがジョブ A から 1 つの Kubernetes Pod をスライス X でスケジュールし、その後、ジョブ B から 1 つの Kubernetes Pod をスライス X でスケジュールするとします。この場合、ジョブ A の Kubernetes Pod アフィニティ ルールに基づいて、スケジューラはジョブ A の残りのすべての Kubernetes Pod をスライス X でスケジュールしようとします。ジョブ B も同じです。したがって、ジョブ A とジョブ B のどちらも、単一のスライスで完全にスケジュールすることはできません。その結果、スケジューリングのデッドロックが発生します。
スケジューリングのデッドロックのリスクを回避するために、次の例のように、cloud.google.com/gke-nodepool の Kubernetes Pod 反アフィニティを topologyKey として使用できます。
apiVersion: batch/v1
kind: Job
metadata:
name: pi
spec:
parallelism: 2
template:
metadata:
labels:
job: pi
spec:
affinity:
podAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchExpressions:
- key: job
operator: In
values:
- pi
topologyKey: cloud.google.com/gke-nodepool
podAntiAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchExpressions:
- key: job
operator: NotIn
values:
- pi
topologyKey: cloud.google.com/gke-nodepool
namespaceSelector:
matchExpressions:
- key: kubernetes.io/metadata.name
operator: NotIn
values:
- kube-system
containers:
- name: pi
image: perl:5.34.0
command: ["sleep", "60"]
restartPolicy: Never
backoffLimit: 4
Terraform を使用した TPU ノードプール リソースの作成
Terraform を使用して、クラスタとノードプールのリソースを管理することもできます。
既存の GKE クラスタにマルチホスト TPU スライス ノードプールを作成する
マルチホスト TPU ノードプールを作成する既存のクラスタがある場合は、次の Terraform スニペットを使用できます。
resource "google_container_cluster" "cluster_multi_host" {
…
release_channel {
channel = "RAPID"
}
workload_identity_config {
workload_pool = "my-gke-project.svc.id.goog"
}
addons_config {
gcs_fuse_csi_driver_config {
enabled = true
}
}
}
resource "google_container_node_pool" "multi_host_tpu" {
provider = google-beta
project = "${project-id}"
name = "${node-pool-name}"
location = "${location}"
node_locations = ["${node-locations}"]
cluster = google_container_cluster.cluster_multi_host.name
initial_node_count = 2
node_config {
machine_type = "ct4p-hightpu-4t"
reservation_affinity {
consume_reservation_type = "SPECIFIC_RESERVATION"
key = "compute.googleapis.com/reservation-name"
values = ["${reservation-name}"]
}
workload_metadata_config {
mode = "GKE_METADATA"
}
}
placement_policy {
type = "COMPACT"
tpu_topology = "2x2x2"
}
}
次の値を置き換えます。
your-project: ワークロードを実行している Google Cloud プロジェクト。your-node-pool: 作成するノードプールの名前。us-central2: ワークロードを実行しているリージョン。us-central2-b: ワークロードを実行しているゾーン。your-reservation-name: 予約の名前。
既存の GKE クラスタに単一ホストの TPU スライス ノードプールを作成する
次の Terraform スニペットを使用します。
resource "google_container_cluster" "cluster_single_host" {
…
cluster_autoscaling {
autoscaling_profile = "OPTIMIZE_UTILIZATION"
}
release_channel {
channel = "RAPID"
}
workload_identity_config {
workload_pool = "${project-id}.svc.id.goog"
}
addons_config {
gcs_fuse_csi_driver_config {
enabled = true
}
}
}
resource "google_container_node_pool" "single_host_tpu" {
provider = google-beta
project = "${project-id}"
name = "${node-pool-name}"
location = "${location}"
node_locations = ["${node-locations}"]
cluster = google_container_cluster.cluster_single_host.name
initial_node_count = 0
autoscaling {
total_min_node_count = 2
total_max_node_count = 22
location_policy = "ANY"
}
node_config {
machine_type = "ct4p-hightpu-4t"
workload_metadata_config {
mode = "GKE_METADATA"
}
}
}
次の値を置き換えます。
your-project: ワークロードを実行している Google Cloud プロジェクト。your-node-pool: 作成するノードプールの名前。us-central2: ワークロードを実行しているリージョン。us-central2-b: ワークロードを実行しているゾーン。