使用自动检查点保留训练进度
过去,当 TPU 虚拟机需要维护时,系统会立即启动相应流程,而不会留出时间让用户执行保留进度的操作,例如保存检查点。如图 1(a) 所示。
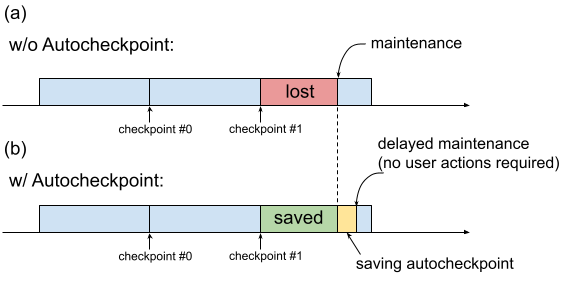
图 1. 自动检查点功能图示:(a) 如果不使用自动检查点,则在即将发生维护事件时,上一个检查点的训练进度会丢失。(b) 如果使用自动检查点,则在即将发生维护事件时,可以保留自上次检查点以来的训练进度。
您可以使用自动检查点(图 1(b))来保留训练进度,方法是将代码配置为在发生维护事件时保存非预定检查点。发生维护事件时,系统会自动保存自上一个检查点以来的进度。此功能同时适用于单切片和多切片。
自动检查点功能可与能够捕获 SIGTERM 信号并随后保存检查点的框架搭配使用。支持的框架包括:
使用自动检查点
自动检查点功能默认处于停用状态。创建 TPU 或请求已排队的资源时,您可以通过在预配 TPU 时添加 --autocheckpoint-enabled 标志来启用自动检查点。启用此功能后,Cloud TPU 在收到维护事件通知后会执行以下步骤:
- 使用 TPU 设备捕获发送到进程的 SIGTERM 信号
- 等待进程退出或 5 分钟后(以先到者为准)
- 对受影响的切片执行维护
自动检查点使用的基础设施与机器学习框架无关。如果机器学习框架可以捕获 SIGTERM 信号并启动检查点过程,则可以支持自动检查点。
在应用代码中,您需要启用机器学习框架提供的自动检查点功能。例如,在 Pax 中,这意味着在启动训练时启用命令行标志。如需了解详情,请参阅将自动检查点与 Pax 结合使用快速入门。在后台,框架会在收到 SIGTERM 信号时保存非预定检查点,并且受影响的 TPU 虚拟机会在 TPU 不再使用时进行维护。
快速入门:将自动检查点与 MaxText 结合使用
MaxText 是一种高性能、可任意扩缩、开源且经过充分测试的 LLM,采用纯 Python/JAX 针对 Cloud TPU 编写。MaxText 包含使用自动检查点功能所需的所有设置。
MaxText README 文件介绍了两种大规模运行 MaxText 的方式:
- 使用
multihost_runner.py,建议用于实验 - 使用
multihost_job.py,建议用于生产
使用 multihost_runner.py 时,通过在预配已排队的资源时设置 autocheckpoint-enabled 标志来启用自动检查点。
使用 multihost_job.py 时,通过在启动作业时指定 ENABLE_AUTOCHECKPOINT=true 命令行标志来启用自动检查点。
快速入门:在单个切片上将自动检查点与 Pax 结合使用
本部分提供了一个示例,说明如何在单个切片上设置并使用 Autocheckpoint 与 Pax。通过适当的设置:
- 当发生维护事件时,系统会保存一个检查点。
- 在保存检查点后,Cloud TPU 会对受影响的 TPU 虚拟机执行维护。
- Cloud TPU 完成维护后,您可以照常使用 TPU 虚拟机。
在创建 TPU 虚拟机或请求已排队的资源时,请使用
autocheckpoint-enabled标志。例如:
设置环境变量:
export PROJECT_ID=your-project-id export TPU_NAME=your-tpu-name export ZONE=zone-you-want-to-use export ACCELERATOR_TYPE=your-accelerator-type export RUNTIME_VERSION=tpu-ubuntu2204-base
环境变量说明
变量 说明 PROJECT_ID您的 Google Cloud 项目 ID。使用现有项目或创建新项目。 TPU_NAMETPU 的名称。 ZONE要在其中创建 TPU 虚拟机的可用区。如需详细了解支持的可用区,请参阅 TPU 区域和可用区。 ACCELERATOR_TYPE加速器类型用于指定您要创建的 Cloud TPU 的版本和大小。如需详细了解每个 TPU 版本支持的加速器类型,请参阅 TPU 版本。 RUNTIME_VERSIONCloud TPU 软件版本。 在有效配置中设置项目 ID 和可用区:
gcloud config set project $PROJECT_ID gcloud config set compute/zone $ZONE
创建 TPU:
gcloud alpha compute tpus tpu-vm create $TPU_NAME \ --accelerator-type $ACCELERATOR_TYPE \ --version $RUNTIME_VERSION \ --autocheckpoint-enabled
使用 SSH 连接到 TPU:
gcloud compute tpus tpu-vm ssh $TPU_NAME在单个切片上安装 Pax
自动检查点功能适用于 Pax 1.1.0 版及更高版本。在 TPU 虚拟机上,安装
jax[tpu]和最新的paxml:pip install paxml && pip install jax[tpu] -f https://storage.googleapis.com/jax-releases/libtpu_releases.html
配置
LmCloudSpmd2B模型。在运行训练脚本之前,请将ICI_MESH_SHAPE更改为[1, 8, 1]:@experiment_registry.register class LmCloudSpmd2B(LmCloudSpmd): """SPMD model with 2B params. Global batch size = 2 * 2 * 1 * 32 = 128 """ PERCORE_BATCH_SIZE = 8 NUM_LAYERS = 18 MODEL_DIMS = 3072 HIDDEN_DIMS = MODEL_DIMS * 4 CHECKPOINT_POLICY = layers.AutodiffCheckpointType.SAVE_NOTHING ICI_MESH_SHAPE = [1, 8, 1]
使用适当的配置启动训练。
以下示例展示了如何配置
LmCloudSpmd2B模型,以将自动检查点触发的检查点保存到 Cloud Storage 存储桶。将 your-storage-bucket 替换为现有存储桶的名称,或创建新的存储桶。export JOB_LOG_DIR=gs://your-storage-bucket { python3 .local/lib/python3.10/site-packages/paxml/main.py \ --jax_fully_async_checkpoint=1 \ --exit_after_ondemand_checkpoint=1 \ --exp=tasks.lm.params.lm_cloud.LmCloudSpmd2B \ --job_log_dir=$JOB_LOG_DIR; } 2>&1 | tee pax_logs.txt
请注意传递给该命令的两个标志:
jax_fully_async_checkpoint:启用此标志后,系统会使用orbax.checkpoint.AsyncCheckpointer。当训练脚本收到 SIGTERM 信号时,AsyncCheckpointer类会自动保存检查点。exit_after_ondemand_checkpoint:启用此标志后,TPU 进程会在自动检查点成功保存后退出,从而触发立即执行维护。如果您不使用此标志,则在检查点保存后,训练将继续进行,并且 Cloud TPU 将等待超时(5 分钟)发生后再执行所需的维护。
将自动检查点与 Orbax 结合使用
自动检查点功能不限于 MaxText 或 Pax。任何可以捕获 SIGTERM 信号并启动检查点过程的框架都可以与自动检查点提供的基础设施搭配使用。Orbax 是一个为 JAX 用户提供通用实用程序库的命名空间,可提供这些功能。
如 Orbax 文档中所述,系统默认会为 orbax.checkpoint.CheckpointManager 的用户启用这些功能。在每个步骤之后调用的 save 方法会自动检查是否即将发生维护事件,如果是,则系统会保存检查点,即使步数不是 save_interval_steps 的倍数也是如此。GitHub 文档还说明了如何在保存自动检查点后通过修改用户代码使训练退出。