Esta página descreve como usar o painel de controlo Estatísticas de consultas para detetar e analisar problemas de desempenho com as suas consultas.
Introdução
As estatísticas de consultas ajudam a detetar, diagnosticar e evitar problemas de desempenho de consultas para bases de dados do Cloud SQL. Suporta a monitorização intuitiva e fornece informações de diagnóstico que ajudam a ir além da deteção para identificar a causa principal dos problemas de desempenho.
Com as estatísticas de consultas, pode monitorizar o desempenho ao nível da aplicação e rastrear a origem de uma consulta problemática na pilha de aplicações por modelo, vista, controlador, rota, utilizador e anfitrião. A ferramenta de estatísticas de consultas pode ser integrada com as suas ferramentas e serviços de monitorização de aplicações (APM) existentes através de padrões abertos e APIs. Google CloudDesta forma, pode monitorizar e resolver problemas de consultas através da sua ferramenta favorita.
As estatísticas de consultas ajudam a melhorar o desempenho das consultas do Cloud SQL através das seguintes etapas:
- Veja a carga da base de dados para as principais consultas
- Identifique uma consulta ou uma etiqueta potencialmente problemática
- Examine a consulta ou a etiqueta para identificar problemas
- Examine um rastreio gerado por uma consulta de amostra
Estatísticas de consultas para a edição Cloud SQL Enterprise Plus
Se estiver a usar a edição Cloud SQL Enterprise Plus, pode aceder a capacidades adicionais nas estatísticas de consultas para realizar diagnósticos avançados do desempenho das consultas. Além das capacidades padrão do painel de controlo Estatísticas de consultas, as estatísticas de consultas para a edição Cloud SQL Enterprise Plus permitem-lhe fazer o seguinte:
- Capte e analise eventos de espera para todas as consultas executadas.
- Filtre a carga da base de dados agregada por dimensões adicionais, como consultas, etiquetas, tipos de eventos de espera e muito mais.
- Capture planos de consultas para todas as consultas executadas.
- Amostre até 200 planos de consulta por minuto.
- Capturar texto de consulta mais longo até 1 MB.
- Obtenha atualizações quase em tempo real para métricas (na ordem dos segundos).
- Manter uma retenção de métricas de 30 dias mais longa.
- Obtenha recomendações de índices do consultor de índices.
- Terminar uma sessão ou uma transação de longa duração em consultas ativas.
- Aceda à resolução de problemas assistida por IA (pré-visualização).
A tabela seguinte compara os requisitos funcionais e as capacidades do Query Insights para a edição Cloud SQL Enterprise com o Query Insights para a edição Cloud SQL Enterprise Plus.
| Área de comparação | Estatísticas de consultas para a edição Enterprise do Cloud SQL | Estatísticas de consultas para a edição Cloud SQL Enterprise Plus |
|---|---|---|
| Versões de base de dados suportadas | MySQL 5.7 ou posterior | MySQL 8.0 ou posterior |
| Tipos de máquinas suportados | Suportado em todos os tipos de máquinas | Não suportado em instâncias que usam um tipo de máquina de núcleo partilhado |
| Regiões suportadas | Localizações regionais do Cloud SQL | Localizações regionais da edição Cloud SQL Enterprise Plus |
| Período de retenção de métricas | 7 dias | 30 dias |
| Máximo do limite de comprimento da consulta | 4500 bytes | 1 MB |
| Máximo de exemplos de planos de consulta | 20 | 200 |
| Análise do evento de espera | Não disponível | Disponível |
| Recomendações do Consultor de índices | Não disponível | Disponível |
| Termine sessões ou transações de longa duração em consultas ativas | Não disponível | Disponível |
| Resolução de problemas assistida por IA (Pré-visualização) | Não disponível | Disponível |
Ative as estatísticas de consultas para a edição Cloud SQL Enterprise Plus
Para ativar as estatísticas de consultas para a edição Cloud SQL Enterprise Plus, selecione Ativar funcionalidades do Enterprise Plus quando ativar as estatísticas de consultas na instância da edição Cloud SQL Enterprise Plus.
Preços
Não existem custos adicionais para as estatísticas de consultas em instâncias da edição Cloud SQL Enterprise ou da edição Cloud SQL Enterprise Plus.
Requisitos de armazenamento
O Query Insights para a edição Enterprise do Cloud SQL não ocupa espaço de armazenamento no espaço de armazenamento da instância do Cloud SQL. As métricas são armazenadas no Cloud Monitoring. Para pedidos de API, consulte os preços do Cloud Monitoring. O Cloud Monitoring tem um nível que pode usar sem custos adicionais.
O Query Insights para a edição Cloud SQL Enterprise Plus armazena dados de métricas no mesmo disco associado à sua instância do Cloud SQL e requer que mantenha a definição de aumentos automáticos do armazenamento ativada.
O requisito de armazenamento para sete dias de dados é de aproximadamente 45 GB. Para 30 dias, precisa de aproximadamente 180 GB. As estatísticas de consultas para a edição Cloud SQL Enterprise Plus usam até 130 MB de RAM. As métricas devem estar disponíveis nas estatísticas de consultas no prazo de um minuto após a conclusão da consulta. Aplicam-se taxas de armazenamento aplicáveis.Limitações
As seguintes limitações aplicam-se às estatísticas de consultas para instâncias da edição Cloud SQL Enterprise Plus:
- Se a sua instância estiver a sofrer uma carga pesada do sistema, quando consultar os dados de métricas no painel de controlo Estatísticas de consultas, as suas consultas podem demorar a carregar ou expirar.
- Se recriar uma réplica de leitura, esta não mantém o histórico de métricas anterior.
- Se restaurar uma instância com uma cópia de segurança antiga, pode perder as métricas entre a hora da cópia de segurança e a hora em que restaura a instância para estatísticas de consultas para a edição Cloud SQL Enterprise Plus. Por exemplo, se restaurar a instância a 30 de abril com uma cópia de segurança feita a 25 de abril, pode perder todas as métricas entre 25 e 30 de abril.
Antes de começar
Antes de usar as estatísticas de consultas, faça o seguinte.
- Adicione as funções e as autorizações necessárias.
- Ative a Cloud Trace API.
- Se estiver a usar as Estatísticas de consultas para a edição Cloud SQL Enterprise Plus, certifique-se de que a opção Ativar aumentos automáticos do armazenamento está ativada para a instância.
Funções e autorizações necessárias
Para receber as autorizações de que precisa para aceder aos dados de execução de consultas do histórico no painel de controlo Estatísticas de consultas, peça ao seu administrador que lhe conceda as seguintes funções da IAM no projeto que aloja a instância do Cloud SQL:
-
Visualizador de monitorização de estatísticas da base de dados (
roles/databaseinsights.monitoringViewer) -
Leitor do Cloud SQL (
roles/cloudsql.viewer)
Para mais informações sobre a atribuição de funções, consulte o artigo Faça a gestão do acesso a projetos, pastas e organizações.
Também pode conseguir as autorizações necessárias através de funções personalizadas ou outras funções predefinidas.
Ative a Cloud Trace API
Para ver planos de consulta e as respetivas vistas ponto a ponto, o seu Google Cloud projeto tem de ter a API Cloud Trace ativada. Esta definição permite que o seu Google Cloud projeto receba dados de rastreio de origens autenticadas sem custos adicionais. Estes dados podem ajudar a detetar e diagnosticar problemas de desempenho na sua instância.
Para confirmar que a API Cloud Trace está ativada, siga estes passos:
- Na Google Cloud consola, aceda a APIs e serviços:
- Clique em Ativar APIs e serviços.
- Na barra de pesquisa, introduza
Cloud Trace API. - Se for apresentado API ativada, significa que esta API está ativada e não tem de fazer nada. Caso contrário, clique em Ativar.
Ative os aumentos automáticos de armazenamento
Se estiver a usar as estatísticas de consultas para a edição Cloud SQL Enterprise Plus, certifique-se de que a definição da instância para ativar os aumentos automáticos de armazenamento permanece ativada. Por predefinição, esta opção está ativada para instâncias do Cloud SQL.
Se desativou anteriormente esta definição da instância e quiser ativar as estatísticas de consultas para a edição Cloud SQL Enterprise Plus, reative primeiro os aumentos automáticos do armazenamento. Não é possível desativar os aumentos automáticos de armazenamento e ativar as estatísticas de consultas para a edição Cloud SQL Enterprise Plus.
Ative as estatísticas de consultas
Quando ativa as estatísticas de consultas, todas as outras operações são temporariamente suspensas. Estas operações incluem verificações de funcionamento, registo, monitorização e outras operações de instâncias.
Consola
Ative as estatísticas de consultas para uma instância
-
Na Google Cloud consola, aceda à página Instâncias do Cloud SQL.
- Para abrir a página Vista geral de uma instância, clique no nome da instância.
- No mosaico Configuração, clique em Editar configuração.
- Na secção Personalize a sua instância, expanda Estatísticas de consultas.
- Selecione a caixa de verificação Ativar estatísticas de consultas.
- Opcional: selecione funcionalidades adicionais para a sua instância. Algumas funcionalidades só estão disponíveis para a edição Cloud SQL Enterprise Plus.
- Clique em Guardar.
| Funcionalidade | Descrição | Edição Enterprise do Cloud SQL | Edição Cloud SQL Enterprise Plus |
|---|---|---|---|
| Ative as funcionalidades do Enterprise Plus | Selecione esta caixa de verificação para ativar as estatísticas de consultas para a edição Cloud SQL Enterprise Plus. As estatísticas de consultas para a edição Cloud SQL Enterprise Plus permitem terminar sessões e transações de longa duração em consultas ativas, ativam as recomendações do consultor de índices para ajudar a acelerar o processamento de consultas e aumentam a retenção de dados de métricas para 30 dias. As recomendações do Consultor de índices são ativadas automaticamente quando ativa as Estatísticas de consultas para a edição Cloud SQL Enterprise Plus. Para desativar as recomendações do consultor de índices, desmarque esta caixa de verificação. Tem de selecionar esta caixa de verificação para ativar as recomendações do consultor de índices e a resolução de problemas assistida por IA (pré-visualização). | Não disponível | Disponível
Predefinição: desativado |
| Resolução de problemas assistida por IA | Selecione esta caixa de verificação para ativar a deteção de anomalias de desempenho, a análise da causa essencial e da situação, e para receber recomendações para corrigir problemas com as suas consultas e base de dados. Esta funcionalidade está em pré-visualização e só pode ativá-la e aceder à mesma através da Google Cloud consola. Para mais informações, consulte Observe e resolva problemas com a ajuda da IA. | Não disponível | Disponível
Predefinição: desativado |
| Armazene endereços IP de clientes | Selecione esta caixa de verificação para ativar o armazenamento de endereços IP de clientes. O Cloud SQL pode armazenar os endereços IP de onde as consultas são provenientes e permitir-lhe agrupar esses dados para executar métricas em função dos mesmos. As consultas provêm de mais do que um anfitrião. A revisão dos gráficos de consultas de endereços IP de clientes pode ajudar a identificar a origem de um problema. | Disponível
Predefinição: desativado |
Disponível
Predefinição: desativado |
| Etiquetas de aplicações da loja | Selecione esta caixa de verificação para ativar o armazenamento de etiquetas de aplicações. O armazenamento de etiquetas de aplicações ajuda a determinar as APIs e as rotas de modelo-vista-controlador (MVC) que estão a fazer pedidos e a agrupar os dados para executar métricas em função dos mesmos. Esta opção requer que comente as consultas com um conjunto específico de etiquetas através da biblioteca de instrumentação automática de mapeamento relacional de objetos (ORM) de código aberto sqlcommenter. Estas informações ajudam as estatísticas de consultas a identificar a origem de um problema e o MVC de onde o problema está a surgir. Os caminhos de aplicação ajudam na monitorização de aplicações. | Disponível
Predefinição: desativado |
Disponível
Predefinição: desativado |
| Personalize os comprimentos das consultas |
Selecione esta caixa de verificação para personalizar o limite do comprimento de uma string de consulta.
Os comprimentos de consultas mais elevados são mais úteis para
consultas analíticas, mas também requerem mais memória.
Qualquer string de consulta que exceda o limite especificado é truncada na apresentação. A alteração do limite de comprimento da consulta requer o reinício da instância. Pode continuar a adicionar etiquetas a consultas que excedam o limite de comprimento. |
Pode definir o limite em bytes de 256 bytes a 4500 bytes.
Predefinição: 1024.
|
Pode
especificar um limite em bytes de
1 a 1048576.
Predefinição: 1024 bytes (1 KB).
|
| Defina a taxa de amostragem máxima |
Selecione esta caixa de verificação para definir a taxa de amostragem máxima. A taxa de amostragem é o número de amostras do plano de consulta executadas que são captadas por minuto em todas as bases de dados na instância. É provável que o aumento da taxa de amostragem lhe dê mais pontos de dados, mas pode aumentar a sobrecarga de desempenho.
Para desativar a amostragem, defina o valor como 0.
|
Altere este valor para um número de 0 a 20.
Predefinição: 5.
|
Pode aumentar o máximo para 200 para fornecer mais pontos de dados.
Predefinição: 5.
|
Ative as estatísticas de consultas para várias instâncias
-
Na Google Cloud consola, aceda à página Instâncias do Cloud SQL.
- Clique no menu Mais ações em qualquer linha.
- Selecione Ativar estatísticas de consultas.
- Na caixa de diálogo, selecione a caixa de verificação Ativar estatísticas de consultas para várias instâncias.
- Clique em Ativar.
- Na caixa de diálogo seguinte, selecione as instâncias para as quais quer ativar as estatísticas de consultas.
- Clique em Ativar estatísticas de consultas.
gcloud
Para ativar as estatísticas de consultas para uma instância do Cloud SQL através de
gcloud, execute gcloud sql instances patch
com a flag --insights-config-query-insights-enabled da seguinte forma após substituir INSTANCE_ID pelo ID da instância.
Se ativar as estatísticas de consultas para uma instância da edição Cloud SQL Enterprise Plus, as recomendações do Consultor de índices são ativadas automaticamente.
gcloud sql instances patch INSTANCE_ID \ --insights-config-query-insights-enabled
Além disso, use uma ou mais das seguintes flags opcionais:
--insights-config-record-client-addressArmazena os endereços IP dos clientes de onde as consultas são provenientes e ajuda a agrupar esses dados para executar métricas em função dos mesmos. As consultas provêm de mais do que um anfitrião. A revisão dos gráficos de consultas de endereços IP de clientes pode ajudar a identificar a origem de um problema.
--insights-config-record-application-tagsArmazena etiquetas de aplicações que ajudam a determinar as APIs e as rotas de controlador de visualização de modelos (MVC) que estão a fazer pedidos e agrupa os dados para executar métricas em função dos mesmos. Esta opção requer que comente as consultas com um conjunto específico de etiquetas. Pode fazê-lo através da biblioteca de instrumentação automática de mapeamento relacional de objetos (ORM) de código aberto sqlcommenter. Estas informações ajudam as estatísticas de consultas a identificar a origem de um problema e o MVC de onde o problema está a surgir. Os caminhos de aplicação ajudam na monitorização de aplicações.
--insights-config-query-string-lengthDefine o limite de comprimento da consulta predefinido. Os comprimentos de consultas mais elevados são mais úteis para consultas analíticas, mas também requerem mais memória. A alteração da duração da consulta requer o reinício da instância. Pode continuar a adicionar etiquetas a consultas que excedam o limite de comprimento. Para a edição Cloud SQL Enterprise, pode especificar um valor em bytes de
256a4500. O comprimento da consulta predefinido é de1024bytes. Para a edição Cloud SQL Enterprise Plus, pode especificar um limite em bytes de1a1048576. O valor predefinido é1024bytes (1 KB).--insights-config-query-plans-per-minutePor predefinição, é captado um máximo de 5 exemplos de planos de consultas executados por minuto em todas as bases de dados na instância. Aumentar a taxa de amostragem provavelmente dá-lhe mais pontos de dados, mas pode adicionar uma sobrecarga de desempenho. Para desativar a amostragem, defina este valor como
0. Para a edição Enterprise do Cloud SQL, pode alterar o valor de 0 para 20. Para a edição Cloud SQL Enterprise Plus, pode aumentar o máximo até 200 para fornecer mais pontos de dados.
Substitua o seguinte:
- INSIGHTS_CONFIG_QUERY_STRING_LENGTH: o comprimento da string de consulta a armazenar, em bytes.
- API_TIER_STRING: A configuração da instância personalizada a usar para a instância.
- REGION: A região da instância.
gcloud sql instances patch INSTANCE_ID \ --insights-config-query-insights-enabled \ --insights-config-query-string-length=INSIGHTS_CONFIG_QUERY_STRING_LENGTH \ --insights-config-query-plans-per-minute=QUERY_PLANS_PER_MINUTE \ --insights-config-record-application-tags \ --insights-config-record-client-address \ --tier=API_TIER_STRING \ --region=REGION
REST v1
Para ativar as estatísticas de consultas para uma instância do Cloud SQL através da API REST, chame o método instances.patch com as definições insightsConfig.
Se ativar as estatísticas de consultas para uma instância da edição Cloud SQL Enterprise Plus, as recomendações do Consultor de índices são ativadas automaticamente.
Antes de usar qualquer um dos dados do pedido, faça as seguintes substituições:
- PROJECT_ID: o ID do projeto
- INSTANCE_ID: o ID da instância
Método HTTP e URL:
PATCH https://sqladmin.googleapis.com/v1/projects/PROJECT_ID/instances/INSTANCE_ID
Corpo JSON do pedido:
{
"settings" : {
"insightsConfig" : {
"queryInsightsEnabled" : true,
"recordClientAddress" : true,
"recordApplicationTags" : true,
"queryStringLength" : 1024,
"queryPlansPerMinute" : 20,
}
}
}
Para enviar o seu pedido, expanda uma destas opções:
Deve receber uma resposta JSON semelhante à seguinte:
{
"kind": "sql#operation",
"targetLink": "https://sqladmin.googleapis.com/v1/projects/PROJECT_ID/instances/INSTANCE_ID",
"status": "PENDING",
"user": "user@example.com",
"insertTime": "2025-03-28T22:43:40.009Z",
"operationType": "UPDATE",
"name": "OPERATION_ID",
"targetId": "INSTANCE_ID",
"selfLink": "https://sqladmin.googleapis.com/v1/projects/PROJECT_ID/operations/OPERATION_ID",
"targetProject": "PROJECT_ID"
}
Terraform
Para usar o Terraform para ativar as estatísticas de consultas para uma instância do Cloud SQL,
defina a flag query_insights_enabled como true.
Se ativar as estatísticas de consultas para uma instância da edição Cloud SQL Enterprise Plus, ativa automaticamente as recomendações do Consultor de índices.
Além disso, pode usar uma ou mais das seguintes flags opcionais:
query_string_length: for Cloud SQL Enterprise edition, you can specify a value in bytes from256to4500. O comprimento da consulta predefinido é de1024bytes. Para a edição Cloud SQL Enterprise Plus, pode especificar um limite em bytes de1a1048576. O valor predefinido é1024bytes (1 KB).record_application_tags: defina o valor comotruese quiser registar etiquetas de aplicações a partir da consulta.record_client_address: defina o valor comotruese quiser registar o endereço IP do cliente. A predefinição éfalse.-
query_plans_per_minute: para a edição Enterprise do Cloud SQL, pode definir o valor de0para20. A predefinição é5. Para a edição Cloud SQL Enterprise Plus, pode aumentar o máximo até200para fornecer mais pontos de dados.
Segue-se um exemplo:
resource "google_sql_database_instance" "INSTANCE_NAME" { name = "INSTANCE_NAME" database_version = "MYSQL_VERSION" region = "REGION" root_password = "PASSWORD" deletion_protection = false # set to true to prevent destruction of the resource settings { tier = "DB_TIER" insights_config { query_insights_enabled = true query_string_length = 2048 # Optional record_application_tags = true # Optional record_client_address = true # Optional query_plans_per_minute = 10 # Optional } } }
Para aplicar a configuração do Terraform num Google Cloud projeto, conclua os passos nas secções seguintes.
Prepare o Cloud Shell
- Inicie o Cloud Shell.
-
Defina o Google Cloud projeto predefinido onde quer aplicar as suas configurações do Terraform.
Só tem de executar este comando uma vez por projeto e pode executá-lo em qualquer diretório.
export GOOGLE_CLOUD_PROJECT=PROJECT_ID
As variáveis de ambiente são substituídas se definir valores explícitos no ficheiro de configuração do Terraform.
Prepare o diretório
Cada ficheiro de configuração do Terraform tem de ter o seu próprio diretório (também denominado módulo raiz).
-
No Cloud Shell, crie um diretório e um novo ficheiro nesse diretório. O nome do ficheiro tem de ter a extensão
.tf, por exemplo,main.tf. Neste tutorial, o ficheiro é denominadomain.tf.mkdir DIRECTORY && cd DIRECTORY && touch main.tf
-
Se estiver a seguir um tutorial, pode copiar o código de exemplo em cada secção ou passo.
Copie o exemplo de código para o ficheiro
main.tfcriado recentemente.Opcionalmente, copie o código do GitHub. Isto é recomendado quando o fragmento do Terraform faz parte de uma solução completa.
- Reveja e modifique os parâmetros de exemplo para aplicar ao seu ambiente.
- Guarde as alterações.
-
Inicialize o Terraform. Só tem de fazer isto uma vez por diretório.
terraform init
Opcionalmente, para usar a versão mais recente do fornecedor Google, inclua a opção
-upgrade:terraform init -upgrade
Aplique as alterações
-
Reveja a configuração e verifique se os recursos que o Terraform vai criar ou
atualizar correspondem às suas expetativas:
terraform plan
Faça correções à configuração conforme necessário.
-
Aplique a configuração do Terraform executando o seguinte comando e introduzindo
yesno comando:terraform apply
Aguarde até que o Terraform apresente a mensagem "Apply complete!" (Aplicação concluída!).
- Abra o seu Google Cloud projeto para ver os resultados. Na Google Cloud consola, navegue para os seus recursos na IU para se certificar de que o Terraform os criou ou atualizou.
As métricas devem estar disponíveis nas estatísticas de consultas no prazo de alguns minutos após a conclusão da consulta. Reveja a política de retenção de dados do Cloud Monitoring.
Os rastreios de estatísticas de consultas são armazenados no Cloud Trace. Reveja a política de retenção de dados do Cloud Trace.
Veja o painel de controlo Estatísticas de consultas
O painel de controlo Estatísticas de consultas mostra a carga de consultas com base nos fatores que selecionar. A carga de consultas é uma medição do trabalho total para todas as consultas na instância no intervalo de tempo selecionado. O painel de controlo oferece uma série de filtros que ajudam a ver a carga de consultas.
Para abrir o painel de controlo Estatísticas de consultas, siga estes passos:
- Para abrir a página Vista geral de uma instância, clique no nome da instância.
- No menu de navegação do Cloud SQL, clique em Estatísticas de consultas ou clique em Aceder às estatísticas de consultas para ver informações mais detalhadas sobre consultas e desempenho na página Vista geral da instância.
É apresentado o painel de controlo Estatísticas de consultas. Consoante esteja a usar o Query Insights para a edição Enterprise do Cloud SQL ou o Query Insights para a edição Enterprise Plus do Cloud SQL, o painel de controlo do Query Insights mostra as seguintes informações acerca da sua instância:
Edição Cloud SQL Enterprise Plus

- Todas as consultas: mostra a carga da base de dados para todas as consultas no intervalo de tempo selecionado. Cada consulta é codificada por cores individualmente. Para ver um ponto específico no tempo para uma consulta específica, mantenha o ponteiro sobre o gráfico da consulta.
- Base de dados: filtra a carga de consultas numa base de dados específica ou em todas as bases de dados.
- Utilizador: filtra a carga de consultas de uma conta de utilizador específica.
- Endereço do cliente: filtra a carga de consultas de um endereço IP específico.
- Intervalo de tempo: filtra o carregamento de consultas por intervalos de tempo, como 1 hora, 6 horas, 1 dia, 7 dias, 30 dias ou um intervalo personalizado.
- Tipos de eventos de espera: filtra o carregamento de consultas por tipos de eventos de espera de CPU e bloqueio.
- Consultas, Tipos de eventos de espera, Bases de dados, Utilizadores, Etiquetas e Moradas de clientes: ordene pelas principais dimensões que mais contribuem para o carregamento da base de dados no gráfico. Consulte a secção Filtre o carregamento da base de dados.
Edição Enterprise do Cloud SQL
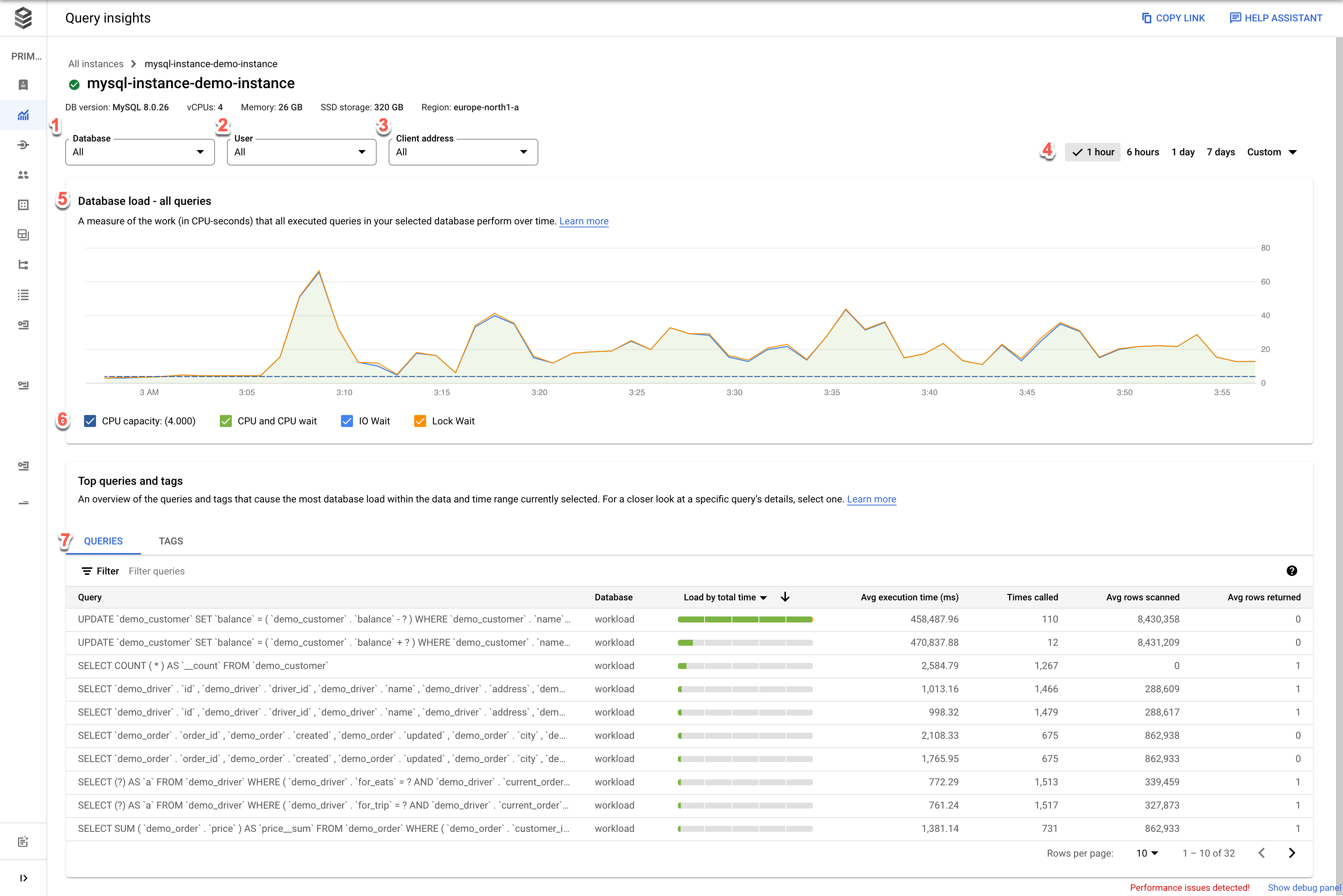
- Base de dados: filtra a carga de consultas numa base de dados específica ou em todas as bases de dados.
- Utilizador: filtra a carga de consultas de uma conta de utilizador específica.
- Endereço do cliente: filtra a carga de consultas de um endereço IP específico.
- Intervalo de tempo: filtra o carregamento de consultas por intervalos de tempo, como 1 hora, 6 horas, 1 dia, 7 dias, 30 dias ou um intervalo personalizado.
- Gráfico de carga da base de dados: apresenta o gráfico de carga de consultas com base nos dados filtrados.
- Capacidade da CPU, CPU e espera da CPU, espera de E/S e espera de bloqueio: Filtra os carregamentos com base nas opções que selecionar. Consulte o artigo Veja a carga da base de dados para as principais consultas para ver detalhes sobre cada um destes filtros.
- Consultas e Etiquetas: filtra o carregamento de consultas por uma consulta selecionada ou uma etiqueta de consulta SQL selecionada. Consulte a secção Filtre o carregamento da base de dados.
Veja o carregamento da base de dados para todas as consultas
A carga de consultas da base de dados é uma medida do trabalho (em segundos de CPU) que as consultas executadas na base de dados selecionada realizam ao longo do tempo. Cada consulta em execução está a usar ou a aguardar recursos de CPU, recursos de E/S ou recursos de bloqueio. A carga de consultas da base de dados é a proporção do tempo gasto por todas as consultas que são concluídas num determinado período em relação ao tempo real.
O painel de controlo de estatísticas de consultas de nível superior mostra o gráfico Carga da base de dados: todas as principais consultas. Os menus pendentes no painel de controlo permitem-lhe filtrar o gráfico para uma base de dados, um utilizador ou um endereço de cliente específico.
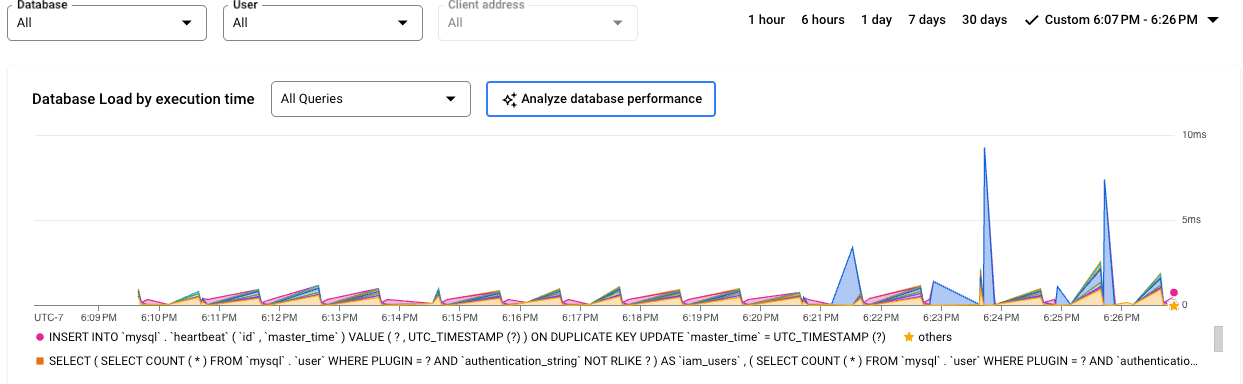
Edição Cloud SQL Enterprise Plus
Edição Enterprise do Cloud SQL
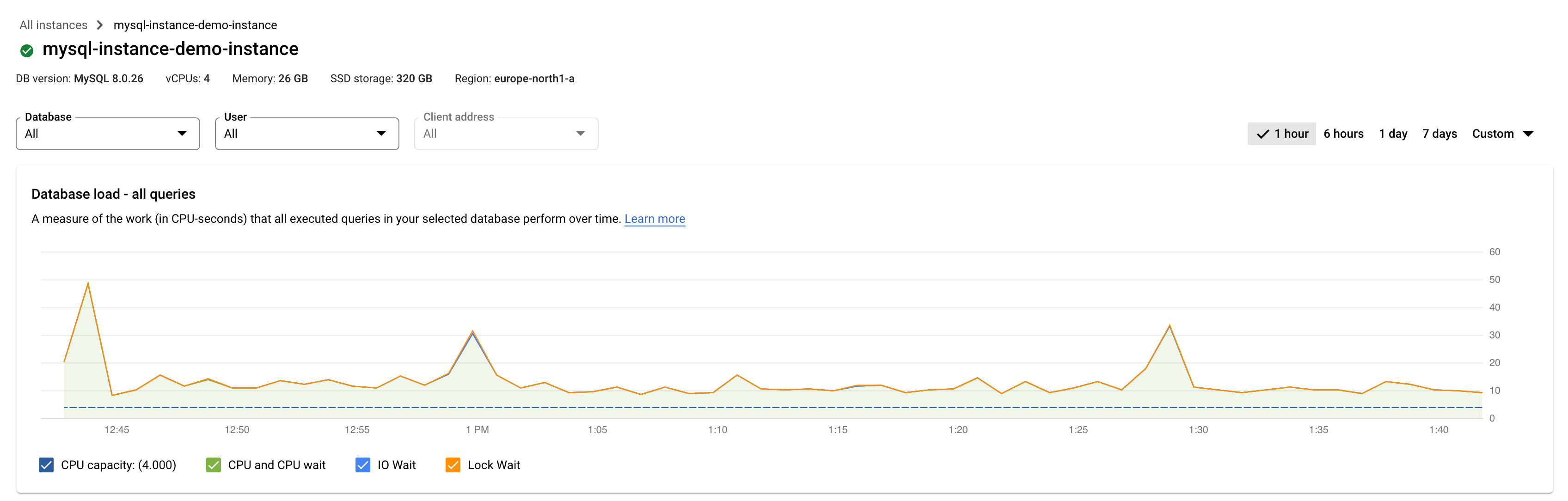
As linhas coloridas no gráfico mostram a carga de consultas, dividida em categorias:
- Capacidade da CPU: o número de CPUs disponíveis na instância.
- CPU e CPU Wait: a proporção do tempo gasto pelas consultas num estado ativo em relação ao tempo real. As esperas de E/S e bloqueio não bloqueiam as consultas que se encontram num estado ativo. Esta métrica pode significar que a consulta está a usar a CPU ou a aguardar que o agendador do Linux agende o processo do servidor que executa a consulta enquanto outros processos estão a usar a CPU.
- IO Wait: a proporção do tempo gasto por consultas que estão à espera de IO em relação ao tempo real. O tempo de espera de E/S inclui o tempo de espera de E/S de leitura e o tempo de espera de E/S de escrita. Se quiser uma discriminação das informações para as esperas de E/S, pode vê-las no Cloud Monitoring. Consulte as métricas do Cloud SQL para mais informações.
- Tempo de espera de bloqueio: a proporção do tempo gasto por consultas que estão à espera de bloqueios em relação ao tempo real. Inclui Lock Waits, LwLock Waits e Buffer pin Lock waits. Para ver uma discriminação das informações sobre as esperas de bloqueio, use o Cloud Monitoring. Consulte as métricas do Cloud SQL para mais informações.
As linhas coloridas no gráfico mostram o carregamento por base de dados por tempo de execução. Reveja o gráfico e use as opções de filtragem para explorar estas perguntas:
- A carga de consultas é elevada? O gráfico está a aumentar ou a ficar elevado ao longo do tempo? Se não vir uma carga elevada, o problema não está na sua consulta.
- Há quanto tempo é que a carga está elevada? O valor está elevado apenas agora ou está elevado há muito tempo? Use o seletor de intervalo para selecionar vários períodos para saber quanto tempo o problema durou. Aumente o zoom para ver um período de tempo em que se observam picos de carga de consultas. Diminua o zoom para ver até uma semana da cronologia.
- O que está a causar a carga elevada? Pode selecionar opções para examinar a capacidade da CPU, a CPU e a espera da CPU, a espera do bloqueio ou a espera de E/S. O gráfico de cada uma destas opções tem uma cor diferente para que possa identificar a opção com a carga mais elevada. A linha azul escura no gráfico mostra a capacidade máxima da CPU do sistema. Permite-lhe comparar a carga de consultas com a capacidade máxima do sistema de CPU. Esta comparação ajuda a determinar se uma instância está a ficar sem recursos da CPU.
- Que base de dados está a sofrer a carga? Selecione bases de dados diferentes no menu pendente Bases de dados para encontrar as bases de dados com os carregamentos mais elevados.
- Os utilizadores ou os endereços IP específicos causam cargas mais elevadas? Selecione diferentes utilizadores e endereços nos menus pendentes para identificar os que estão a causar cargas mais elevadas.
Filtre o carregamento da base de dados
Pode filtrar o carregamento da base de dados por consultas ou etiquetas. Se estiver a usar as estatísticas de consultas para a edição Cloud SQL Enterprise Plus, pode personalizar o gráfico de carga da base de dados para analisar os dados apresentados usando qualquer uma das seguintes dimensões:Todas as consultas
Tipos de eventos de espera
Bases de dados
Utilizadores
Etiquetas
Moradas dos clientes
Para personalizar o gráfico de carregamento da base de dados, selecione uma dimensão no menu pendente Carregamento da base de dados por tempo de execução.
Veja os principais colaboradores para o carregamento da base de dados
Para ver os principais contribuintes para o carregamento da base de dados, pode usar a tabela Principais dimensões por carregamento da base de dados. A tabela Principais dimensões por carregamento da base de dados apresenta os principais contribuintes para o período e a dimensão que selecionar no menu pendente do gráfico Carregamento da base de dados por tempo de execução. Pode modificar o período ou a dimensão para ver os principais contribuintes de uma dimensão ou um período diferentes.
Na tabela Principais dimensões por carregamento de dados, pode selecionar os seguintes separadores.
| Tab | Descrição |
|---|---|
| Consultas | A tabela apresenta as principais consultas normalizadas por tempo de execução total.
Para cada consulta, os dados apresentados nas colunas são apresentados da seguinte forma:
|
| Tipos de eventos de espera | A tabela apresenta a lista dos principais tipos de eventos de espera que ocorreram durante o período selecionado. Esta tabela só está disponível para estatísticas de consultas da edição Cloud SQL Enterprise Plus.
|
| Bases de dados | A tabela mostra a lista das principais bases de dados que contribuíram para a
carga durante o período escolhido em todas as consultas executadas.
|
| Utilizadores | A tabela mostra a lista dos principais utilizadores para o período selecionado
em todas as consultas executadas.
|
| Etiquetas | Para informações sobre etiquetas, Filtre por etiquetas de consulta. |
| Endereços de clientes | A tabela mostra a lista dos principais utilizadores para o período selecionado
em todas as consultas executadas.
|
Filtre por consultas
A tabela Principais dimensões por carga da base de dados oferece uma vista geral das consultas que causam a maior carga de consultas. A tabela mostra todas as consultas normalizadas para o intervalo de tempo e as opções selecionadas no painel de controlo Estatísticas de consultas. Ordena as consultas pelo tempo de execução total durante o intervalo de tempo que selecionou.
Edição Cloud SQL Enterprise Plus
Para ordenar a tabela, selecione um cabeçalho de coluna.
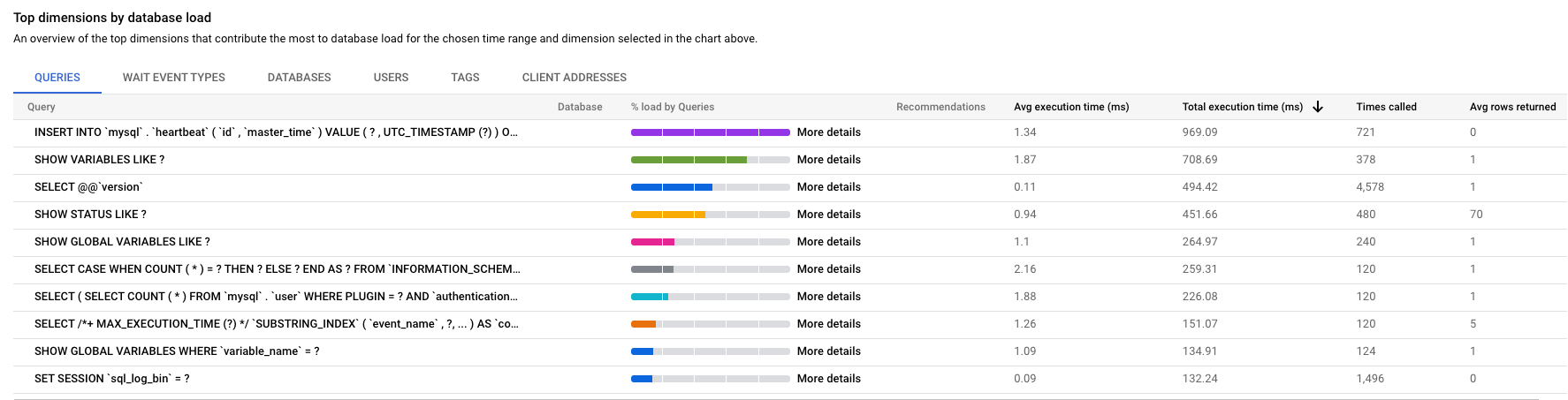
Edição Enterprise do Cloud SQL
Para ordenar a tabela, selecione um cabeçalho de coluna ou uma propriedade em Filtrar consultas.
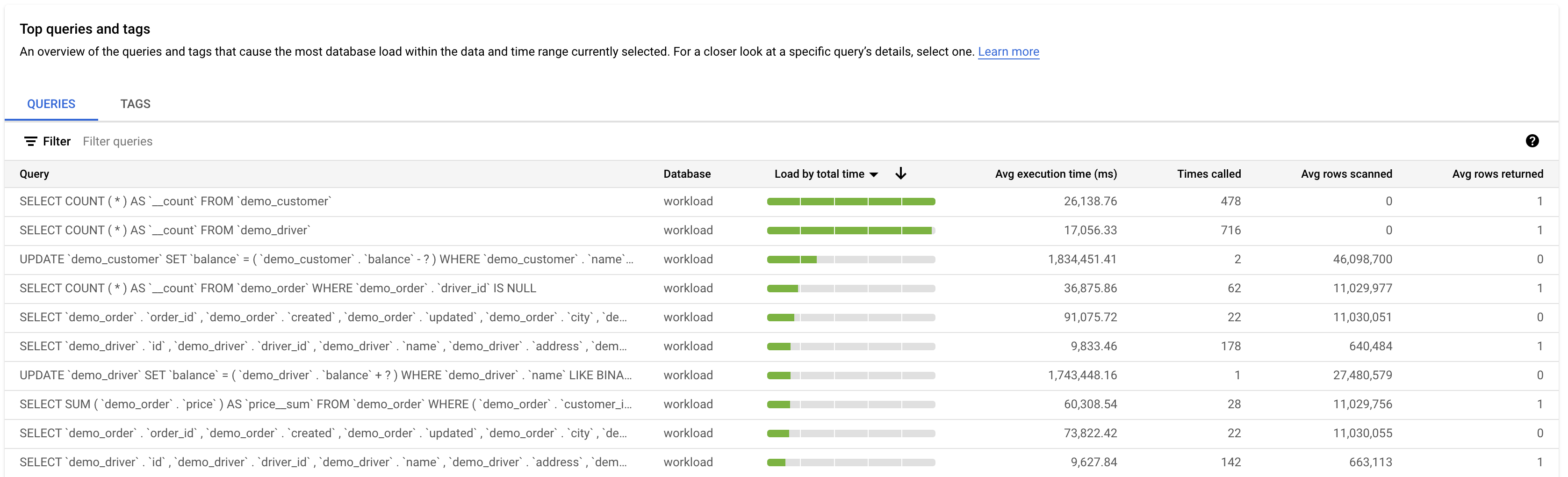
A tabela mostra as seguintes propriedades:
- Consulta: a string de consulta normalizada. Por predefinição, as estatísticas de consultas mostram apenas 1024 carateres na string de consulta.
As consultas etiquetadas como
UTILITY COMMANDincluem normalmente comandosBEGIN,COMMITeEXPLAINou comandos de wrapper. - Base de dados: a base de dados em relação à qual a consulta foi executada.
- Recomendações: as recomendações sugeridas, como Criar índices, para melhorar o desempenho das consultas.
- Carregar por tempo total/Carregar por CPU/Carregar por espera de E/S/Carregar por espera de bloqueio: As opções pelas quais pode filtrar consultas específicas para encontrar a carga mais elevada.
- % de carregamento por consultas: A percentagem de carregamento por consulta individual.
- Analise a latência: se ativou a resolução de problemas assistida por IA (pré-visualização) para esta instância, pode clicar neste link para resolver problemas de consultas lentas.
- Tempo de execução médio (ms): o tempo médio de execução da consulta.
- Número de chamadas: o número de vezes que a aplicação chamou a consulta.
- Linhas devolvidas médias: o número médio de linhas devolvidas para a consulta.
- Média de linhas analisadas: o número médio de linhas analisadas para a consulta.
As estatísticas de consultas armazenam e apresentam apenas consultas normalizadas.
Por predefinição, as estatísticas de consultas não recolhem endereços IP nem informações de etiquetas. Pode ativar as estatísticas de consultas para recolher estas informações e, quando necessário, desativar a recolha.
Os rastreios do plano de consulta não recolhem nem armazenam valores constantes e removem todas as informações de IPI que a constante possa apresentar.
As estatísticas de consultas apresentam consultas normalizadas, ou seja, ? substitui
o valor constante literal. No exemplo seguinte, a constante de nome é removida e ? substitui-a.
UPDATE "demo_customer" SET "customer_id" = ?::uuid, "name" = ?, "address" = ?, "rating" = ?, "balance" = ?, "current_city" = ?, "current_location" = ? WHERE "demo_customer"."id" = ?
Filtre por etiquetas de consulta
Para resolver problemas de uma aplicação, tem de adicionar etiquetas às suas consultas SQL. As etiquetas de carregamento de consultas fornecem uma discriminação do carregamento de consultas da etiqueta selecionada ao longo do tempo.
As estatísticas de consultas oferecem monitorização centrada na aplicação para diagnosticar problemas de desempenho de aplicações criadas com ORMs. Se for responsável por toda a pilha de aplicações, as estatísticas de consultas fornecem a monitorização de consultas a partir de uma vista de aplicação. A etiquetagem de consultas ajuda a encontrar problemas em construções de nível superior, como na lógica empresarial ou num microsserviço.
Pode etiquetar as consultas pela lógica empresarial, por exemplo, as etiquetas de pagamento, inventário, estatísticas empresariais ou envio. Em seguida, pode encontrar a carga de consultas criada pela várias lógicas empresariais. Por exemplo, pode observar eventos inesperados, como picos de uma etiqueta de estatísticas empresariais às 13:00 ou um crescimento inesperado de um serviço de pagamento que é tendência na semana anterior.
Para calcular o Carregamento da base de dados para a etiqueta, as estatísticas de consultas usam a quantidade de tempo gasto por cada consulta que usa a etiqueta que selecionar. A ferramenta calcula o tempo de conclusão no limite do minuto através do tempo de relógio.
No painel de controlo Estatísticas de consultas, para ver a tabela de etiquetas, selecione Etiquetas. A tabela ordena as etiquetas pelo respetivo carregamento total por tempo total.

Pode ordenar a tabela selecionando uma propriedade em Filtrar etiquetas ou clicando num cabeçalho de coluna. A tabela mostra as seguintes propriedades:
- Ação, controlador, framework, rota, aplicação, controlador de BD: cada propriedade que adicionou às suas consultas aparece como uma coluna. Tem de adicionar, pelo menos, uma destas propriedades se quiser filtrar por etiquetas.
- Carregar por tempo total/Carregar por CPU/Carregar por espera de E/S/Carregar por espera de bloqueio: opções para filtrar consultas específicas para encontrar o maior carregamento para cada opção.
- Tempo de execução médio (ms): o tempo médio de execução da consulta.
- Linhas devolvidas médias: o número médio de linhas devolvidas para a consulta.
- Média de linhas analisadas: o número médio de linhas analisadas para a consulta.
- Número de vezes que foi chamado: o número de vezes que a aplicação chamou a consulta.
- Base de dados: a base de dados em que a consulta foi executada.
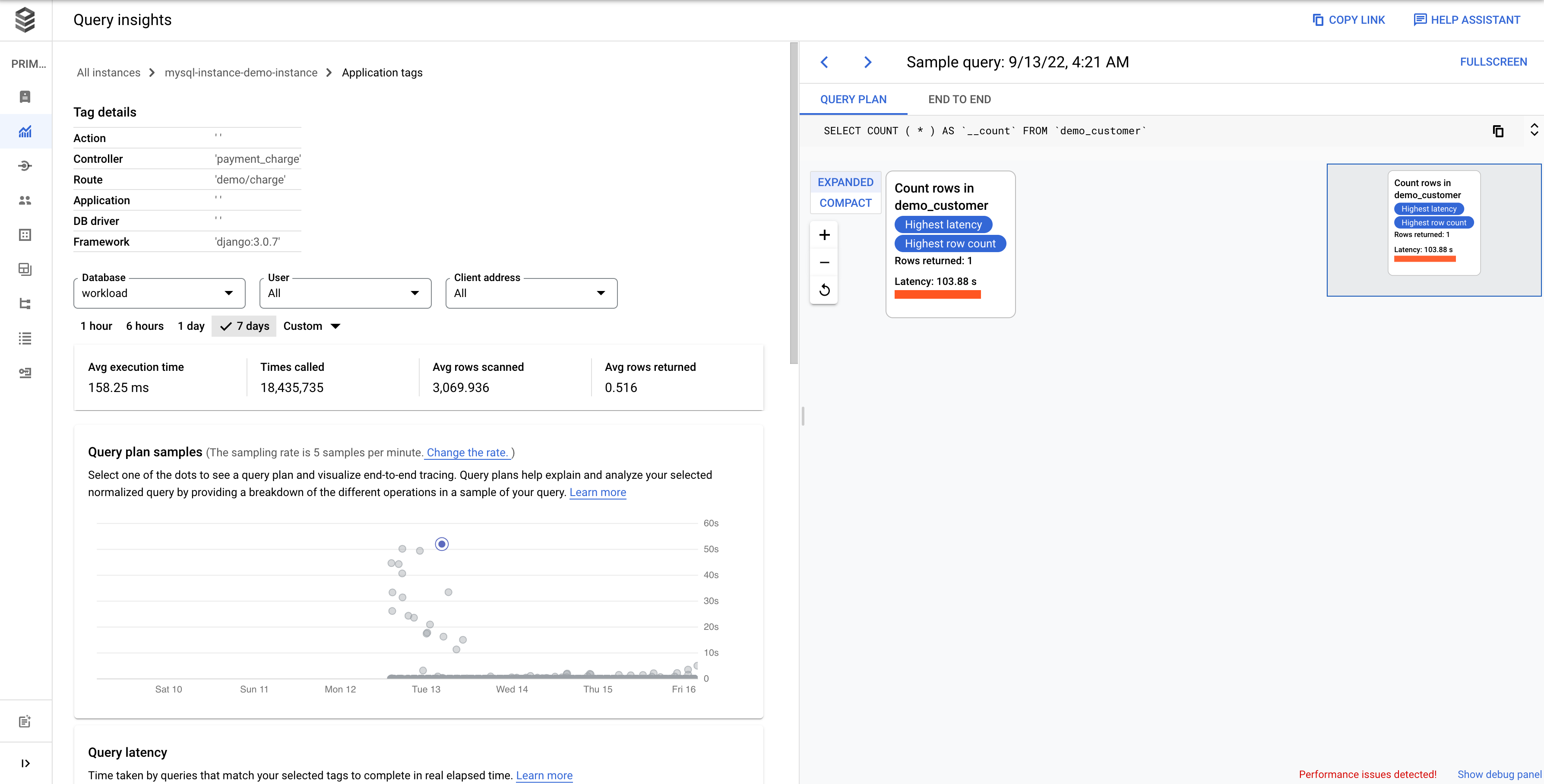
Veja os detalhes da consulta de uma consulta ou uma etiqueta específica
Para determinar se uma consulta ou uma etiqueta específica é a causa principal do problema, faça o seguinte no separador Consultas ou no separador Etiquetas, respetivamente:
- Para ordenar a lista por ordem descendente, clique no cabeçalho Carregamento por tempo total.
- Clique na consulta ou na etiqueta na parte superior da lista. Tem o carregamento mais elevado e está a demorar mais tempo do que os outros.
A página Detalhes da consulta é aberta e mostra os detalhes da consulta ou da etiqueta selecionada.
Examine o carregamento de uma consulta específica
A página Detalhes da consulta de uma consulta selecionada é apresentada da seguinte forma:

O gráfico Carga da base de dados: consulta específica mostra uma medida do trabalho (em segundos de CPU) que a sua consulta normalizada realizou na consulta selecionada ao longo do tempo. Para calcular o carregamento, usa a quantidade de tempo que as consultas normalizadas demoram a concluir no limite do minuto até à hora real. Na parte superior da tabela, são apresentados os primeiros 1024 carateres da consulta normalizada, com os literais removidos por motivos de agregação e PII.
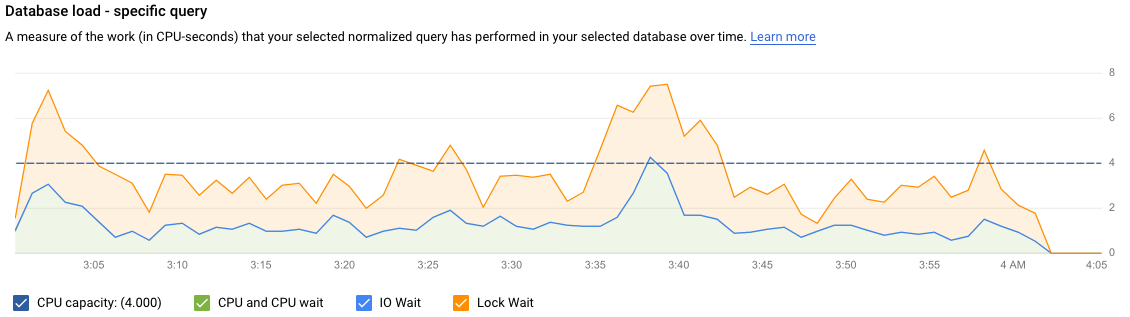
Tal como no gráfico de consultas totais, pode filtrar a carga de uma consulta específica por Base de dados, Utilizador e Endereço do cliente. A carga de consultas é dividida em capacidade da CPU, CPU e espera da CPU, espera de E/S e espera de bloqueio.
Examine o carregamento de uma consulta etiquetada específica
O painel de controlo de uma etiqueta selecionada é apresentado da seguinte forma. Por exemplo, se todas as consultas de um pagamento de microsserviços estiverem etiquetadas como payment, pode ver a quantidade de carga de consultas que está a ser tendência visualizando a etiqueta payment.
O gráfico Carga da base de dados: etiquetas específicas mostra uma medida do trabalho (em segundos de CPU) que as consultas correspondentes às etiquetas selecionadas realizaram na base de dados selecionada ao longo do tempo. Tal como no gráfico de consultas totais, pode filtrar o carregamento de uma etiqueta específica por Base de dados, Utilizador e Endereço do cliente.
Examine as operações num plano de consulta com amostragem
Um plano de consulta usa uma amostra da sua consulta e divide-a em operações individuais. Explica e analisa cada operação na consulta.
O MySQL 5.7 fornece um plano de consulta estimado com a vista EXPLAIN, enquanto o MySQL 8.0 e versões posteriores fornecem um plano de consulta executado com a vista EXPLAIN ANALYZE. Um plano de consulta estimado indica o tempo de execução estimado de uma consulta, enquanto um plano de consulta executado fornece informações em tempo real de cada passo de execução de uma determinada consulta.
Os planos de consultas no MySQL 5.7 são suportados para as seguintes consultas que são suportadas pela declaração EXPLAIN:
- Para tabelas únicas: INSERT, SELECT, UPDATE e DELETE.
- Para várias tabelas: SELECT, UPDATE e DELETE.
Pode gerar planos de consultas no MySQL 8.0 e posterior para todas as consultas suportadas por EXPLAIN ANALYZE. Esta ferramenta mostra onde o MySQL gasta tempo nas suas consultas SELECT para tabelas únicas e várias tabelas. O Cloud SQL não suporta a geração de planos de consulta da linguagem de manipulação de dados (DML) de várias tabelas porque estas consultas não são suportadas por EXPLAIN ANALYZE.
O plano de consulta de exemplo fornece uma vista EXPLAIN ANALYZE para os exemplos de planos de consulta relacionados com a consulta normalizada. Estes são planos de consultas executados que fornecem uma discriminação do tempo ativo gasto por cada operação no plano de consulta.
O gráfico Exemplos de planos de consultas mostra todos os planos de consultas em execução em momentos específicos e o tempo que cada plano demorou a ser executado. Pode alterar a taxa à qual as amostras do plano de consulta são capturadas por minuto. Consulte o artigo Ative as estatísticas de consultas.

Por predefinição, o painel do lado direito mostra os detalhes do plano de consulta de exemplo que demora mais tempo, conforme visível no gráfico Exemplos de planos de consulta. Para ver os detalhes de outro plano de consulta de exemplo, clique no círculo relevante no gráfico. Os detalhes expandidos mostram um modelo de todas as operações no plano de consulta.
Cada operação mostra a latência, as linhas devolvidas e o custo da operação. Quando seleciona uma operação, pode ver mais detalhes, como blocos de resultados partilhados, o tipo de esquema, ciclos e linhas de planos.

Tente restringir o problema analisando as seguintes questões:
- Qual é o consumo de recursos?
- Como se relaciona com outras consultas?
- O consumo muda ao longo do tempo?
Examine um rastreio gerado por uma consulta de amostra
Além de ver o plano de consulta de exemplo, pode usar as estatísticas de consultas para ver um rastreio de aplicação completo e contextualizado para uma consulta de exemplo. Este rastreio pode ajudar a identificar a origem de uma consulta problemática ao apresentar a atividade da base de dados para um pedido específico. Além disso, as entradas de registo que a aplicação envia para o Cloud Logging durante o pedido estão associadas ao rastreio, o que ajuda na sua investigação.
Para ver o rastreio no contexto, faça o seguinte:
- No ecrã Consulta de exemplo, clique no separador Rastreio ponto a ponto. Este separador apresenta um gráfico de Gantt que detalha os intervalos, que são registos de operações individuais, para o rastreio gerado pela consulta.
- Para ver mais detalhes sobre cada intervalo, como atributos e metadados, selecione o intervalo.
Também pode ver o rastreio na página Explorador de rastreios. Para o fazer, clique em Ver no Cloud Trace. Para ver detalhes sobre como usar a página Explorador de rastreios para explorar os dados de rastreio, consulte o artigo Encontre e explore rastreios.
Examine a latência
A latência é o tempo necessário para a consulta normalizada ser concluída, em tempo real. Use o gráfico Latência para examinar a latência na consulta ou na etiqueta. O painel de controlo de latência mostra as latências do 50.º, 95.º e 99.º percentil para encontrar comportamentos atípicos.
A imagem seguinte mostra o gráfico de carregamento da base de dados no percentil 50 para uma consulta específica com filtros selecionados para capacidade da CPU, CPU e tempo de espera da CPU, tempo de espera de E/S e tempo de espera de bloqueio.
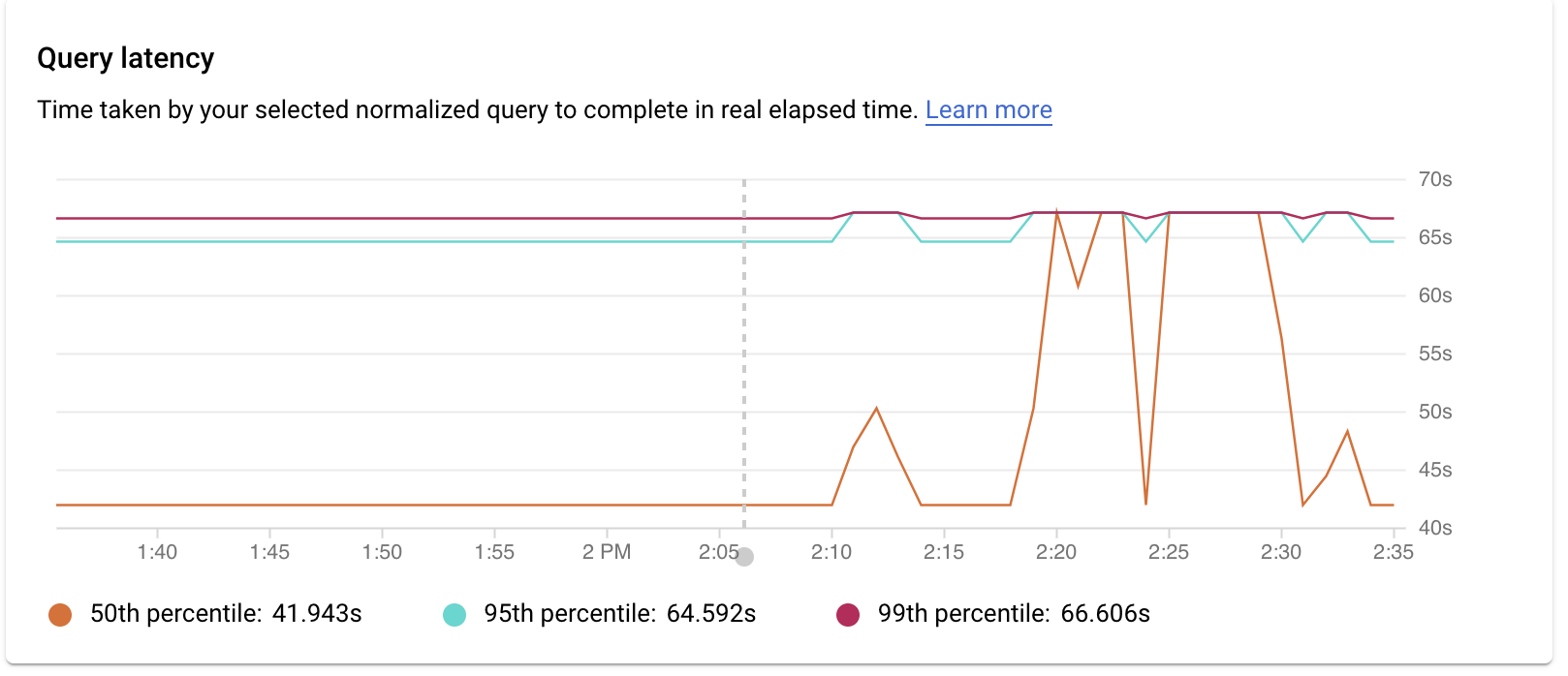
A latência das consultas paralelas é medida em tempo real, embora a carga da consulta possa ser superior para a consulta devido à utilização de vários núcleos para executar parte da consulta.
Tente restringir o problema analisando as seguintes questões:
- O que está a causar a carga elevada? Selecione opções para analisar a capacidade da CPU, a CPU e a espera da CPU, a espera de E/S ou a espera de bloqueio.
- Há quanto tempo é que a carga está elevada? Só está alto agora? Ou tem estado elevado durante muito tempo? Altere o intervalo de tempo para encontrar a data e a hora em que o carregamento começou a ter um desempenho fraco.
- Houve picos na latência? Altere o período para estudar a latência histórica da consulta normalizada.
Adicione etiquetas a consultas SQL
A etiquetagem de consultas SQL simplifica a resolução de problemas da aplicação. Pode usar o sqlcommenter para adicionar etiquetas às suas consultas SQL de forma automática ou manual.
Use o sqlcommenter com o ORM
Quando usa o ORM em vez de escrever diretamente consultas SQL, pode não encontrar código de aplicação que esteja a causar desafios de desempenho. Também pode ter problemas em analisar como o código da aplicação afeta o desempenho das consultas. Para resolver este problema, o Query Insights fornece uma biblioteca de código aberto denominada sqlcommenter. Esta biblioteca é útil para programadores e administradores que usam ferramentas ORM para detetar que código da aplicação está a causar problemas de desempenho.
Se estiver a usar o ORM e o sqlcommenter em conjunto, as etiquetas são criadas automaticamente. Não precisa de adicionar nem alterar código na sua aplicação.
Pode instalar o sqlcommenter no servidor de aplicações. A biblioteca de instrumentação permite que as informações da aplicação relacionadas com a sua estrutura MVC sejam propagadas para a base de dados juntamente com as consultas como um comentário SQL. A base de dados recolhe estas etiquetas e começa a registar e agregar estatísticas por etiquetas, que são ortogonais às estatísticas agregadas por consultas normalizadas. As estatísticas de consultas mostram as etiquetas para que saiba que aplicação está a causar a carga de consultas e possa encontrar o código da aplicação que está a causar problemas de desempenho.
Quando examina os resultados nos registos da base de dados SQL, estes aparecem da seguinte forma:
SELECT * from USERS /action='run+this', controller='foo%3', traceparent='00-01', tracestate='rojo%2'/
As etiquetas suportadas incluem o nome do controlador, a rota, a framework e a ação.
O conjunto de ferramentas ORM no sqlcommenter é suportado para as seguintes linguagens de programação:
| Python |
|
| Java |
|
| Ruby |
|
| Node.js |
|
| PHP |
|
Para mais informações sobre o sqlcommenter e como usá-lo na sua framework ORM, consulte a documentação do sqlcommenter.
Use o sqlcommenter para adicionar etiquetas
Se não estiver a usar o ORM, tem de adicionar manualmente etiquetas sqlcommenter ou comentários no formato de comentário SQL correto à sua consulta SQL. Também tem de aumentar cada declaração SQL com um comentário que contenha um par de chave-valor serializado. Use, pelo menos, uma das seguintes teclas:
action=''controller=''framework=''route=''application=''db driver=''
As estatísticas de consultas eliminam todas as outras chaves.
Desative as estatísticas de consultas
Consola
Para desativar as estatísticas de consultas para uma instância do Cloud SQL através da Google Cloud consola, siga estes passos:
-
Na Google Cloud consola, aceda à página Instâncias do Cloud SQL.
- Para abrir a página Vista geral de uma instância, clique no nome da instância.
- No mosaico Configuração, clique em Editar configuração.
- Na secção Opções de configuração, expanda Estatísticas de consultas.
- Desmarque a caixa de verificação Ativar estatísticas de consultas.
- Clique em Guardar.
gcloud
Para desativar as estatísticas de consultas para uma instância do Cloud SQL através de gcloud,
execute gcloud sql instances patch
com a flag --no-insights-config-query-insights-enabled da seguinte forma, após substituir INSTANCE_ID pelo ID da instância.
gcloud sql instances patch INSTANCE_ID \ --no-insights-config-query-insights-enabled
REST
Para desativar as estatísticas de consultas para uma instância do Cloud SQL através da API REST, chame o método instances.patch com queryInsightsEnabled definido como false da seguinte forma.
Antes de usar qualquer um dos dados do pedido, faça as seguintes substituições:
- project-id: o ID do projeto.
- instance-id: o ID da instância.
Método HTTP e URL:
PATCH https://sqladmin.googleapis.com/sql/v1beta4/projects/project-id/instances/instance-id
Corpo JSON do pedido:
{
"settings" : { "insightsConfig" : { "queryInsightsEnabled" : false } }
}
Para enviar o seu pedido, expanda uma destas opções:
Deve receber uma resposta JSON semelhante à seguinte:
{
"kind": "sql#operation",
"targetLink": "https://sqladmin.googleapis.com/sql/v1beta4/projects/project-id/instances/instance-id",
"status": "PENDING",
"user": "user@example.com",
"insertTime": "2021-01-28T22:43:40.009Z",
"operationType": "UPDATE",
"name": "operation-id",
"targetId": "instance-id",
"selfLink": "https://sqladmin.googleapis.com/sql/v1beta4/projects/project-id/operations/operation-id",
"targetProject": "project-id"
}
Desative as estatísticas de consultas para a edição Cloud SQL Enterprise Plus
Para desativar as estatísticas de consultas para a edição Cloud SQL Enterprise Plus, faça o seguinte:
-
Na Google Cloud consola, aceda à página Instâncias do Cloud SQL.
- Para abrir a página Vista geral de uma instância, clique no nome da instância.
- Clique em Edit.
- Na secção Personalize a sua instância, expanda Estatísticas de consultas.
- Desmarque a caixa de verificação Ativar funcionalidades do Enterprise Plus.
- Clique em Guardar.
O que se segue?
- Blogue de lançamento: Resolva gargalos da base de dados mais rapidamente com as estatísticas de consultas mais recentes para a edição Cloud SQL Enterprise Plus
- Consulte as Google Cloud métricas.
- Blogue: Melhore as suas competências de resolução de problemas de desempenho de consultas com o Cloud SQL Insights
- Vídeo: apresentação do Cloud SQL Insights
- Podcast: Cloud SQL Insights
- Codelab de estatísticas
- Otimize a utilização elevada da CPU
- Otimize a utilização elevada da memória
- Blogue: Apresentamos o Sqlcommenter: uma biblioteca de instrumentação automática de ORM de código aberto
- Blogue: Ative a etiquetagem de consultas com o Sqlcommenter