レプリケーションとは、Cloud SQL インスタンスまたはオンプレミス データベースのコピーを作成して、作業をそのコピーにオフロードする機能です。
はじめに
レプリケーションを使用する主な理由は、パフォーマンスを低下させることなく、データベース内のデータ使用をスケーリングすることです。
その他、次の理由があります。
- リージョン間でのデータ移行
- プラットフォーム間でのデータ移行
- オンプレミス データベースから Cloud SQL へのデータ移行
また、元のインスタンスが破損した場合にレプリカを昇格させることもできます。
Cloud SQL インスタンスを参照する場合、複製されるインスタンスは「プライマリ インスタンス」と呼ばれ、コピーは「リードレプリカ」と呼ばれます。プライマリ インスタンスとリードレプリカは Cloud SQL にあります。
オンプレミス データベースを指している場合、レプリケーション シナリオは「外部サーバーからのレプリケーション」と呼ばれます。このシナリオでは、複製されるデータベースは、ソース データベース サーバーです。Cloud SQL にあるコピーは Cloud SQL レプリカと呼ばれます。また、Cloud SQL のソース データベース サーバーを表すインスタンスもあります。このインスタンスをソース表現インスタンスといいます。
障害復旧のシナリオでは、レプリカを昇格させてプライマリ インスタンスに変換できます。このようにして、停止しているリージョンにあるインスタンスの代わりに使用できます。レプリカを昇格させて、破損したインスタンスと置換することもできます。
Cloud SQL は、次の種類のレプリカをサポートします。
- リードレプリカ
- クロスリージョン リードレプリカ
- リードレプリカのカスケード
- 外部リードレプリカ
- 外部サーバーから複製する場合の Cloud SQL レプリカ
コネクタの適用を使用すると、Cloud SQL インスタンスへの接続に、Cloud SQL Auth Proxy または Cloud SQL 言語コネクタのみを使用するように強制できます。コネクタの適用を使用すると、Cloud SQL によりデータベースへの直接接続が拒否されます。コネクタの適用が有効になっているインスタンスには、リードレプリカを作成できません。同様に、インスタンスにリードレプリカがある場合、そのインスタンスでコネクタの適用を有効にすることはできません。
Database Migration Service を使用して、ソース データベース サーバーから Cloud SQL に継続的にレプリケーションすることもできます。Cloud SQL は、2 台の外部サーバー間のレプリケーションをサポートしていません。ただし、Cloud SQL はグローバル トランザクション識別子(GTID)ベースのレプリケーションをサポートしています。GTID は、サーバーとレプリケーション設定内の各トランザクションを一意に識別します。各トランザクションには固有識別子があるため、MySQL サーバーは実行されたトランザクションを追跡できます。GTID は絶対座標を使用するため、Cloud SQL インスタンスのレプリカがそのプライマリ インスタンスを指すことができ、バイナリログのファイル名や CHANGE MASTER ステートメントでの位置を指定する必要はありません。レプリカとポイントインタイム リカバリで発生するエラーは少なくなります。これらのメリットのため、Cloud SQL では GTID ベースのレプリケーションを無効にできません。
リードレプリカ
リードレプリカを使用して Cloud SQL インスタンスから作業をオフロードします。リードレプリカとは、プライマリ インスタンスの正確なコピーです。プライマリ インスタンスのデータやその他の変更は、リードレプリカでほぼリアルタイムで更新されます。
リードレプリカは読み取り専用です。書き込みはできません。リードレプリカは、クエリ、読み取りリクエスト、アナリティクス トラフィックを処理し、プライマリ インスタンスの負荷を低減します。
レプリカの接続名と IP アドレスを使用して、レプリカに直接接続します。プライベート IP アドレスを使用してレプリカに接続している場合は、接続がプライマリ インスタンスから継承されるため、レプリカに追加の VPC プライベート接続を作成する必要はありません。
リードレプリカの作成方法の詳細については、リードレプリカの作成をご覧ください。リードレプリカの管理については、リードレプリカの管理をご覧ください。
プライマリ インスタンスで HA を使用する場合は、プライマリ インスタンスとは異なるゾーンにリードレプリカを配置することをおすすめします。これにより、プライマリ インスタンスが配置されたゾーンで障害が発生しても、リードレプリカのオペレーションを継続できます。詳細については、高可用性の概要をご覧ください。
適切なマシンタイプを選択する
リードレプリカの vCPU 数とメモリ容量は、プライマリ マシンタイプと異なる場合があります。CPU とメモリ使用量など、インスタンスの指標をモニタリングして、レプリカ インスタンスがワークロードに適したサイズになるようにしてください(特にプライマリ インスタンスよりも小さい場合)。レプリカ インスタンスのサイズが小さすぎると、メモリ不足(OOM)が頻繁に発生するなど、パフォーマンスが低下しやすくなります。
リードレプリカのストレージ容量
プライマリ インスタンスのサイズを変更すると、必要に応じて、更新されたプライマリ インスタンスのストレージ容量以上になるように、すべてのリードレプリカのサイズが変更されます。
クロスリージョン リードレプリカ
クロスリージョン レプリケーションでは、プライマリ インスタンスとは異なるリージョンにリードレプリカを作成できます。クロスリージョン リードレプリカは、リージョン内のレプリカを作成するで説明した方法で作成します。
クロスリージョン レプリカ:
- レプリカをアプリケーションのリージョンのより近くで利用できるようにすることで、読み取りパフォーマンスを向上させます。
- リージョンの障害から保護するために、追加の障害復旧機能を提供します。
- リージョン間でデータを移行できます。
クロスリージョン レプリカの詳細については、リージョン移行または障害復旧のためにレプリカを昇格させるをご覧ください。
リードレプリカのカスケード
カスケード レプリケーションでは、同じリージョンまたは別のリージョンの別のリードレプリカの下にリードレプリカを作成できます。次のシナリオは、カスケード レプリカを使用するユースケースです。
- 障害復旧: リードレプリカのカスケード階層を使用して、プライマリ インスタンスとそのリードレプリカのトポロジをシミュレートできます。サービスが停止している間も、選択したリードレプリカがプライマリに昇格し、新しいプライマリのリードレプリカのレプリケーションが継続して、使用可能な状態になります。
- パフォーマンスの改善: レプリケーション作業を複数のリードレプリカにオフロードすることで、プライマリ インスタンスの負担を軽減します。
- 読み取りのスケーリング: レプリカを増やして読み取りの負荷を軽減できます。
- コスト削減: 他のリージョンでクロスリージョン レプリケーションを含む単一のカスケード レプリカを使用すると、ネットワーク費用を削減できます。
用語
- カスケード レプリカ: 独自のレプリカを持つリードレプリカ。
- レベル: カスケード レプリカの階層内に、レプリカのレベルを作成できます。たとえば、インスタンスに 4 つのレプリカを追加すると、これらのレプリカは同じレベルになります。
- 兄弟インスタンス: 同じプライマリ インスタンスから複製された複数のレプリカ。兄弟要素は、レプリカ階層の同じレベルにあります。1 つのレプリカには最大 8 個の兄弟要素を設定できます。
- リーフレプリカ: 独自のレプリカがないリードレプリカ。 マルチレベルのレプリケーション階層で最後のレベルにあるのがリーフレプリカです。
- プロモート: 階層の任意レベルのレプリカをプライマリ インスタンスに変換するアクション。プロモートするときに、レプリカのカスケード レプリカ階層は保持されます。
カスケード レプリカを構成する
カスケード レプリカを使用すると、既存のレプリカにリードレプリカを追加できます。プライマリ インスタンスを含む、最大 4 レベルまでのレプリカを追加できます。レプリカをカスケード レプリカ階層の最上位に昇格させると、そのレプリカがプライマリ インスタンスになり、カスケード レプリカのレプリケーションが継続します。
構成を計画するには、リードレプリカの想定動作を確認する必要があります。次の 2 つのセクションでは、障害復旧とマルチリージョン レプリケーションの構成について説明します。
障害復旧
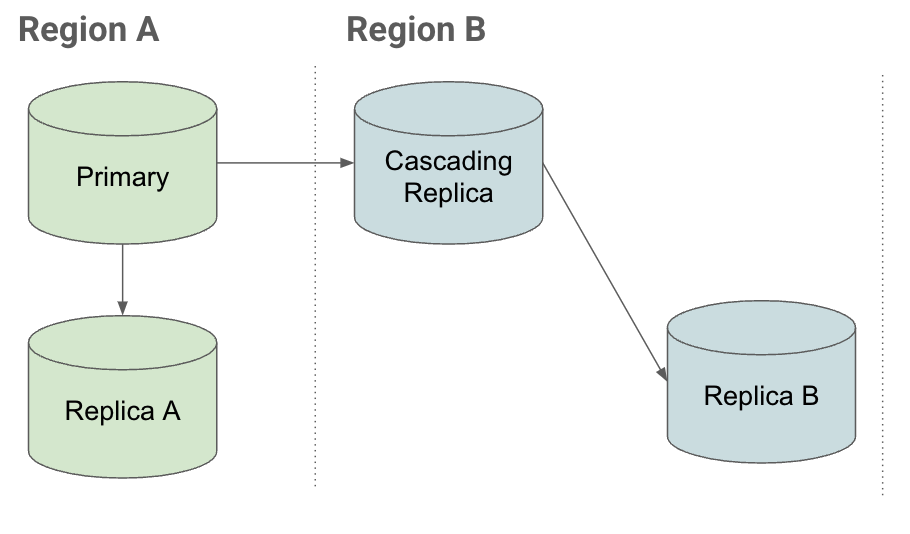
停止時にカスケード レプリカによって迅速に回復する仕組みを理解するには、次のレプリケーション シナリオを検討してください。
構成
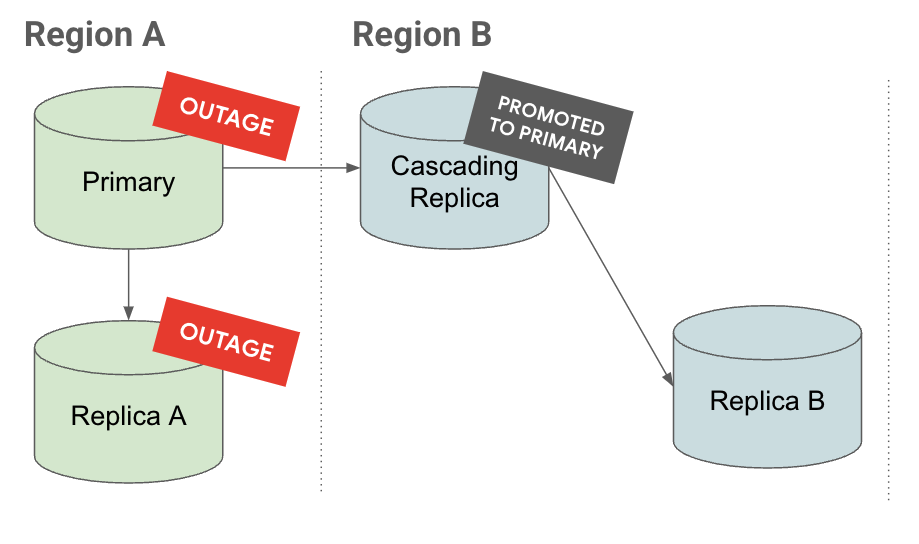
サービスの停止
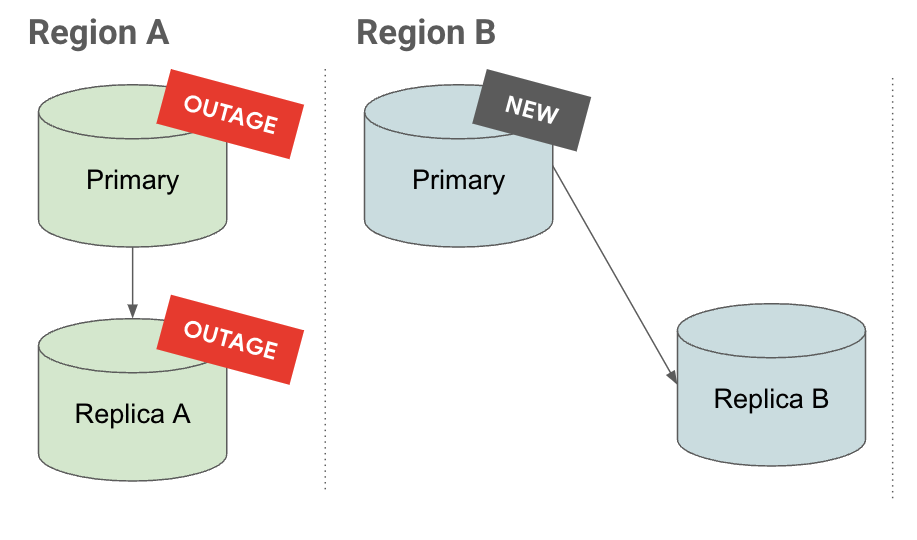
Promotion
障害復旧構成でリージョン B のインスタンスを使用し、次のレプリカがあるとします。
- プライマリ インスタンス(レプリカ A)に接続されている同じリージョン内のレプリカ
- プライマリに接続された他のリージョンのレプリカ(カスケード レプリカ)。
リージョン B のカスケード レプリカにリードレプリカを作成できます。
[サービスの停止] タブで、リージョン A でサービスが停止している場合、カスケード レプリカがプライマリ インスタンスに昇格されます。ここにはすでにリードレプリカが存在しているため、リカバリ時間目標(RTO)が短縮されています。
[プロモート] タブでカスケード レプリカが昇格すると、そのレプリカも昇格し、引き続きレプリケーションが実行されます。
マルチリージョンのレプリケーション
カスケード レプリカのもう 1 つのユースケースは、コスト効率の高い方法で読み取り容量を 2 番目のリージョンに分散することです。レプリカ B からレプリケーションするカスケード レプリカ C と D を作成できます。クライアントは、レプリカ B、C、D に読み取りクエリを分散して、各レプリカの負荷を軽減できます。クロスリージョン ネットワーク トラフィックの料金が発生するのは、プライマリ インスタンスからレプリカ B までの 1 回だけです。ユーザー B から C と D へのレプリケーションでは、無料のリージョン内ネットワーク転送が使用されます。
マルチリージョン レプリケーション用のカスケード レプリカを使用して、最大 4 つのインスタンスの階層を作成できます。
プライマリ A → レプリカ B → レプリカ C とレプリカ D
制限事項
- 下位にレプリカがあるレプリカは削除できません。レプリカを削除するには、リーフレプリカから始めて、階層の上を順に進む必要があります。
- リージョンの循環依存はサポートされていません。カスケード レプリカのレプリカをプライマリ インスタンスと同じリージョンに配置する場合は、カスケード レプリカも同じリージョンに配置する必要があります。
外部リードレプリカ
外部リードレプリカは、Cloud SQL プライマリ インスタンスを複製する外部 MySQL インスタンスです。たとえば、Compute Engine で実行される MySQL インスタンスは外部インスタンスとみなされます。
外部リードレプリカには次の制限があります。
- 外部レプリカのプライマリは Cloud SQL 読み取りレプリカにできません。
- 他のクラウド プラットフォームでホストされる MySQL インスタンスに複製できないことがあります。他のプロバイダのドキュメントを確認してください。たとえば、構成フィールド
replicate-ignore-dbの設定は必須であり、許可されていないクラウド プロバイダはサポートされていません。その他の必要な構成フィールドについては、外部レプリカの構成をご覧ください。 - ネットワークまたはサーバーの停止などによって複製が数時間中断された場合、レプリカはプライマリよりも古い状態のものになります。プライマリに再接続され、複製が再開されると、レプリカは最新状態になります。ただし、中断時間が Cloud SQL のレプリケーション ログの保存期間(7 つのバックアップ)よりも長かった場合は、レプリカを削除して新しく作成する必要があります。
- プライマリから外部レプリカに流れるデータは、アウトバウンド データ転送として課金されます。Cloud SQL インスタンス タイプのデータ転送料金については、料金ページをご覧ください。
インスタンスの外部リードレプリカを作成し、プライベート サービス アクセスが構成されているインスタンスに接続する際に Cloud SQL Auth Proxy または Cloud SQL 言語コネクタのみを使用するように強制する場合は、レプリカのサブネット範囲をプライマリ インスタンスの承認済みネットワークに追加する必要があります。すべての範囲を、Cloud SQL インスタンスの承認済みネットワークとして構成する必要があります。
gcloud
外部リードレプリカの IP アドレス範囲からのトラフィックを許可するようにインスタンスの IP 認可を設定するには、
gcloud sql instances patchコマンドを使用します。gcloud sql instances patch \ --authorized-networks=IP_ADDRESS_RANGE_1/24,IP_ADDRESS_RANGE_2/24
IP_ADDRESS_RANGE_1 と IP_ADDRESS_RANGE_2 は、外部リードレプリカの IP アドレス範囲に置き換えます。
REST
リクエストのデータを使用する前に、次のように置き換えます。
- PROJECT_ID: インスタンスが含まれている Google Cloud プロジェクトの ID またはプロジェクト番号
- INSTANCE_NAME: Cloud SQL インスタンスの名前
- IP_ADDRESS_RANGE_1: 外部リードレプリカの最初の IP アドレス範囲
- IP_ADDRESS_RANGE_2: 外部リードレプリカの 2 番目の IP アドレス範囲
HTTP メソッドと URL:
PATCH https://sqladmin.googleapis.com/v1/projects/PROJECT_ID/instances/INSTANCE_NAME
リクエストの本文(JSON):
{ "kind": "sql#instance", "name": INSTANCE_NAME, "project": PROJECT_ID, "settings": { "ipConfiguration": { "authorizedNetworks": [{"kind": "sql#aclEntry", "value": "IP_ADDRESS_RANGE_1/24"}, {"kind": "sql#aclEntry", "value": "IP_ADDRESS_RANGE_2/24"}]}, "kind": "sql#settings" } }リクエストを送信するには、次のいずれかのオプションを展開します。
次のような JSON レスポンスが返されます。
{ "kind": "sql#operation", "targetLink": "https://sqladmin.googleapis.com/v1/projects/PROJECT_ID/instances/INSTANCE_NAME", "status": "PENDING", "user": "user@example.com", "insertTime": "2020-01-16T02:32:12.281Z", "operationType": "UPDATE", "name": "OPERATION_ID", "targetId": "INSTANCE_NAME", "selfLink": "https://sqladmin.googleapis.com/v1/projects/PROJECT_ID/operations/OPERATION_ID", "targetProject": "PROJECT_ID" }
レプリケーションのユースケース
次のユースケースは、レプリケーションのタイプごとに適用されます。
| 名前 | プライマリ | レプリカ | 利点と使用例 | 詳細 |
|---|---|---|---|---|
| リードレプリカ | Cloud SQL インスタンス | Cloud SQL インスタンス |
|
|
| リージョン間リードレプリカ | Cloud SQL インスタンス | Cloud SQL インスタンス |
|
|
| 外部リードレプリカ | Cloud SQL スタンドアロン インスタンスまたはプライマリ インスタンス | Cloud SQL に対する外部 MySQL インスタンス |
|
|
| 外部サーバーからのレプリケーション | Cloud SQL に対する外部 MySQL インスタンス | Cloud SQL for MySQL インスタンス |
|
リードレプリカを作成するための前提要件
プライマリ Cloud SQL インスタンスのリードレプリカを作成するには、インスタンスが次の要件を満たしている必要があります。
- 自動バックアップが有効になっていること。
- バイナリ ロギングが有効になっていること。これには、ポイントインタイム リカバリが有効になっている必要があります。このログの影響についてはこちらをご確認ください。
- バイナリ ロギングを有効にした後に、少なくとも 1 つのバックアップが作成されていること。
外部レプリカの追加要件:
- レプリカの MySQL バージョンがプライマリ インスタンスの MySQL バージョン以降であること。詳細については、こちらをご覧ください。
- セキュリティ上、プライマリ インスタンスで SSL / TLS を構成すること。詳細については、こちらをご覧ください。
バイナリ ロギングを有効にした場合の影響
リードレプリカをサポートするには、ポイントインタイム リカバリを有効にして、プライマリ インスタンスのバイナリ ロギングを有効にする必要があります。その結果、次の影響があります。
- パフォーマンスのオーバーヘッド
Cloud SQL は、MySQL フラグ
sync_binlog=1とinnodb_support_xa=trueによる行ベースのレプリケーションを使用します。そのため、書き込みオペレーションのたびにディスクの fsync が余分に必要となり、パフォーマンスが低下します。 - ストレージのオーバーヘッド
バイナリログのストレージは、通常のデータと同じレートで課金されます。バイナリログは、最も古い自動バックアップの日付で自動的に切り捨てられます。Cloud SQL は、最新の 7 つの自動バックアップとすべてのオンデマンド バックアップを保持します。課金対象となるバイナリログのサイズはワークロードによって異なるため、請求される料金も異なります。たとえば、書き込み中心のワークロードでは、読み取り中心のワークロードよりも多くのバイナリログ容量を消費します。
バイナリログのサイズは、SHOW BINARY LOGS MySQL コマンドを使用して確認できます。
バックアップを作成すると、データと一緒にログがバックアップに保存されます。
リードレプリカのバイナリ ロギング
- バイナリ ロギングはリードレプリカ インスタンスでサポートされています(MySQL 5.7 および 8.0 のみ)。レプリカのバイナリ ロギングを有効にするには、プライマリ インスタンス名ではなくレプリカのインスタンス名を指定して、プライマリと同じ API コマンドを使用します。「
enable binary logging」と「enable point-in-time recovery」という用語は同じ意味で使用されています。sync_binlogフラグを使用して、レプリカ(プライマリではなく)のインスタンスのバイナリ ロギングの耐久性を設定できます。これにより、MySQL サーバーがバイナリログをディスクに同期する頻度を制御できます。プライマリのバックアップが無効になっている場合でも、レプリカでバイナリ ロギングを有効にできます。
この値を持つレプリカがスタンドアロン サーバーに昇格されている場合、設定はスタンドアロン サーバーで安全な値
1にリセットされます。
課金
- リードレプリカは、標準 Cloud SQL インスタンスと同じレートで課金されます。データ レプリケーションには課金されません。
- 外部レプリカの場合、プライマリから外部レプリカに流れるデータはデータ転送として課金されます。Cloud SQL インスタンス タイプのデータ転送料金については、料金ページをご覧ください。
- クロスリージョン リードレプリカの料金は、リージョン内で新しい Cloud SQL インスタンスを作成する場合と同じです。Cloud SQL インスタンスの料金を参照して、適切なリージョンを選択します。インスタンスに関連する通常のコストに加えて、クロスリージョン レプリカでは、プライマリ インスタンスからレプリカ インスタンスに送信されるレプリケーション ログに対してリージョン間のデータ転送料金が発生します。詳しくは、ネットワーク下り(外向き)の料金をご覧ください。
Cloud SQL リードレプリカのクイック リファレンス
| トピック | ディスカッション |
|---|---|
| バックアップ | レプリカのバックアップは構成できません。 |
| コア数とメモリ | リードレプリカでは、プライマリ インスタンスとは異なる数のコアやメモリ量を使用できます。 |
| プライマリ インスタンスの削除 | プライマリ インスタンスを削除するには、まずすべてのリードレプリカをスタンドアロン インスタンスに昇格するか、リードレプリカを削除する必要があります。 |
| レプリカの削除 | レプリカを削除しても、プライマリ インスタンスのステータスには影響しません。 |
| バイナリ ロギングの無効化 | プライマリ インスタンスのバイナリログを無効にするには、その前にすべてのリードレプリカを昇格または削除する必要があります。 |
| フェイルオーバー | プライマリ インスタンスは、レプリカが DR レプリカの場合にのみレプリカにフェイルオーバーできます。リードレプリカは停止時にフェイルオーバーできません。 |
| 高可用性 | リードレプリカによって、レプリカの高可用性を実現できます。 |
| 負荷分散 | Cloud SQL では、レプリカ間のロード バランシングを行いません。Cloud SQL インスタンスのロード バランシングを実装することもできます。また、接続プールを使用すると、ロード バランシング設定を使用してレプリカ間でクエリを分散し、パフォーマンスを向上させることができます。 |
| メンテナンスの時間枠 | リードレプリカはプライマリ インスタンスとメンテナンスの時間枠を共有します。リードレプリカは、メンテナンスの時間枠、スケジュール変更、メンテナンス拒否期間などのプライマリ インスタンスのメンテナンス設定に従います。メンテナンス中、Cloud SQL はすべてのリードレプリカを更新してから、プライマリ インスタンスを更新します。 |
| 複数のリードレプリカ | Cloud SQL はカスケード レプリカをサポートしています。その結果、単一のプライマリ インスタンスに対して最大で 10 個のレプリカを作成できます。また、プライマリ インスタンスを含む最大 4 つのレベルでこれらのレプリカのレプリカを作成できます。 |
| 並列レプリケーション | 並列レプリケーションを使用したパフォーマンスの向上については、並列レプリケーションの構成をご覧ください。 |
| プライベート IP | プライベート IP アドレスを使用してレプリカに接続している場合は、プライマリ インスタンスから継承されるため、レプリカに追加の VPC プライベート接続を作成する必要はありません。 |
| プライマリ インスタンスの復元 | レプリカのプライマリ インスタンスは、そのレプリカが存在する場合は復元できません。インスタンスをバックアップから復元する前や、インスタンスでポイントインタイム リカバリを実行する前に、すべてのレプリカを昇格または削除する必要があります。 |
| 設定 | root パスワード、ユーザー テーブルの変更などのプライマリ インスタンスの MySQL 設定は、レプリカに伝播されます。CPU とメモリの変更はレプリカに伝播されません。 |
| レプリカの停止 | レプリカの stop は実行できません。restart、delete、disable replication は可能ですが、プライマリ インスタンスで行うように停止することはできません。 |
| レプリカのアップグレード | リードレプリカでは、中断を伴うアップグレードが時間に関係なく行われる可能性があります。 |
| ユーザー テーブル | レプリカに変更を加えることはできません。すべてのユーザー変更は、プライマリ インスタンスで行う必要があります。 |
次のステップ
- リードレプリカの作成方法を確認する。
- 外部レプリカ構成を設定する方法を確認する。
- 外部サーバーからデータをレプリケートする方法を確認する。
- 外部サーバーの構成を設定する方法を確認する。
- MySQL でのレプリケーションについて確認する。
- インスタンスの高可用性を構成する方法を学習します。
- 高度な障害復旧(DR)について学習する