このページでは、Cloud SQL インスタンスの高可用性(HA)構成の概要を説明します。HA の新しいインスタンスを構成する、あるいは既存のインスタンスで HA を有効にするには、インスタンスでの高可用性の有効化と無効化を参照してください。
HA 構成の概要
HA 構成の目的は、ゾーンまたはインスタンスが利用できなくなったときのダウンタイムの削減です。これは、ゾーンの停止中やハードウェアに問題がある場合に発生する可能性があります。HA を使用すれば、クライアント アプリケーションで引き続きデータを使用できるようになります。
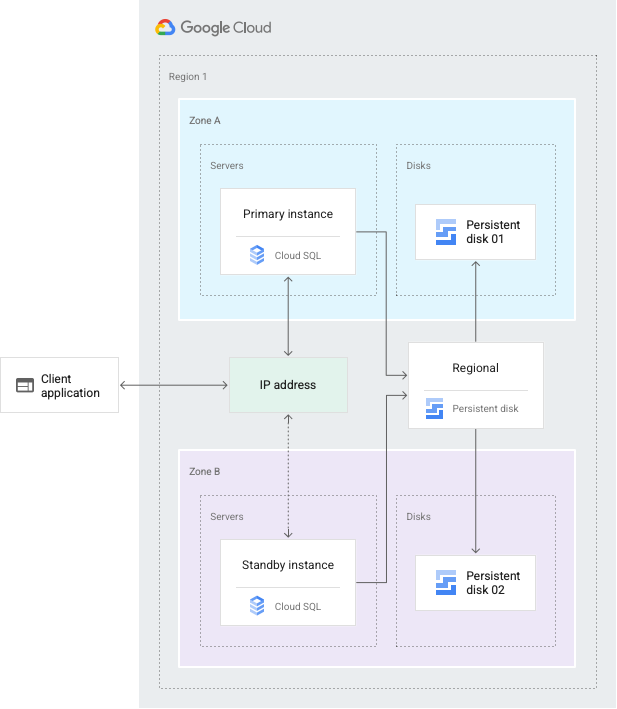
HA 構成では、データの冗長性が確保されます。HA 向けに構成された Cloud SQL インスタンスはリージョン インスタンスとも呼ばれ、構成されたリージョン*内にプライマリ ゾーンとセカンダリ ゾーンがあります。リージョン インスタンスはプライマリ インスタンスとスタンバイ インスタンスで構成されます。各ゾーンの永続ディスクへの同期レプリケーションにより、トランザクションが commit されたとしてレポートされる前に、プライマリ インスタンスへの書き込みのすべてが両方のゾーンのディスクに複製されます。インスタンスまたはゾーンに障害が発生した場合、スタンバイ インスタンスが新しいプライマリ インスタンスになります。ユーザーは新しいプライマリ インスタンスに再転送されます。このプロセスは、フェイルオーバーと呼ばれます。
フェイルオーバー後は、元のインスタンスが再びオンラインになっても、フェイルオーバーを受信したインスタンスがプライマリ インスタンスのままとなります。サービスが停止したゾーンまたはインスタンスが再び使用可能になると、元のプライマリ インスタンスは破棄され、再作成されます。その後、それが新しいスタンバイ インスタンスになります。将来、フェイルオーバーが発生した場合、新しいプライマリは元のゾーン内の元のインスタンスにフェイルオーバーします。
サービス停止が発生したゾーンのプライマリ インスタンスが必要な場合は、フェイルバックを実施できます。フェイルバックはフェイルオーバーと同じ手順を逆方向に実施し、トラフィックを元のインスタンスに再転送します。フェイルバックを実施するには、フェイルオーバーの開始で説明されている手順を行います。
1 つ以上の専用 CPU を持つ Cloud SQL HA 構成のリージョン永続ディスク サポートには、完全なサービスレベル契約(SLA)が適用されます。HA 用に構成されたインスタンスは、スタンドアロン インスタンスの 2 倍の費用がかかります。これには、CPU、RAM、およびストレージの料金が含まれます。詳細については、料金のページをご覧ください。
* リージョン固有の考慮事項の詳細については、地域とリージョンをご覧ください。
リードレプリカ
リードレプリカで可用性が問題になる場合は、レプリカで HA を有効にできます。このようなレプリカをプライマリ インスタンスにプロモートさせた場合、そのレプリカは高可用性インスタンスとしてすでに設定されています。
ゾーンでサービスが停止している間、そのゾーンのリードレプリカへのトラフィックは停止します。ゾーンが再び使用可能になると、ゾーン内のリードレプリカはプライマリ インスタンスからレプリケーションを再開します。サービスが停止しているゾーンにリードレプリカがない場合、スタンバイ インスタンスがプライマリ インスタンスになると、リードレプリカはスタンバイ インスタンスに接続します。
ベスト プラクティスとして、リードレプリカの一部をプライマリ インスタンスやスタンバイ インスタンスとは異なるゾーンに置くことを検討してください。たとえば、ゾーン A にプライマリ インスタンスが、ゾーン B にスタンバイ インスタンスがある場合、ゾーン C にリードレプリカを置いて信頼性を向上させます。これにより、プライマリ インスタンスのゾーンがダウンしても、リードレプリカが引き続き稼働します。また、リードレプリカが利用できないときは、プライマリ インスタンスに読み取りを送信するビジネス ロジックをクライアント アプリケーションに追加する必要もあります。
注: スタンバイ インスタンスは、読み取りクエリには使用できません。これは、Cloud SQL for MySQL の従来の HA 構成とは異なります。
フェイルオーバーの概要
HA 構成のインスタンスが応答しなくなると、Cloud SQL は自動的にスタンバイ インスタンスからデータを提供するように切り替えます。フェイルオーバーが発生したかどうかを確認するには、オペレーション ログのフェイルオーバー履歴を調べます。
ログ エクスプローラでクエリを作成する方法をご確認ください。オペレーションを実施したユーザーなど、オペレーションに関する詳細情報が必要な場合は、監査ロギングを有効にする必要があります。
各タブをクリックして、フェイルオーバーがインスタンスに与える影響を確認してください。
正常

フェイルオーバー

フェイルオーバー後

フェイルバック
プロセス
次のプロセスが発生します。
プライマリ インスタンスまたはゾーンで障害が発生します。
ハートビート システムは、プライマリ インスタンスが正常かどうかを 1 秒ごとに検出します。複数のハートビートが検出されない場合、フェイルオーバーを開始します。
スタンバイ インスタンスが再接続されて、データの提供を開始します。
スタンバイ インスタンスは、プライマリ インスタンスと共有する静的 IP アドレスを使用してセカンダリ ゾーンからデータを提供します。
要件
Cloud SQL がフェイルオーバーできるようにするには、次の要件を満たす構成が必要です。
- プライマリ インスタンスが通常の動作状態である(停止していない、メンテナンス中でない、バックアップなど長時間実行されている Cloud SQL インスタンス オペレーションがない)こと。
- セカンダリ ゾーンとスタンバイ インスタンスが、どちらも正常な状態であること。スタンバイ インスタンスが応答しない場合、フェイルオーバー オペレーションはブロックされます。Cloud SQL でスタンバイ インスタンスが修復され、セカンダリ ゾーンが使用可能になると、Cloud SQL でフェイルオーバーが可能になります。
バックアップと復元
高可用性インスタンス(リードレプリカを除く)では、自動バックアップとポイントインタイム リカバリを有効にする必要があります。
スタンドアロン インスタンスの復元オプション
Cloud SQL は、ゾーン停止からスタンドアロン インスタンスを自動的に復元しません。高可用性向けに構成されていないインスタンスを正常なゾーンに再確立するには、ゾーン インスタンスを手動で復元する必要があります。ゾーン停止からスタンドアロン インスタンスを手動で復元するには、次のいずれかのオプションを使用します。
そのインスタンスでポイントインタイム リカバリ(PITR)を実行して、新しいインスタンスを作成します。このオプションを使用するには、ゾーン停止前にゾーン インスタンスで PITR が有効になっている必要があります。インスタンスのトランザクション ログが Cloud Storage に保存されている必要があります。トランザクション ログがディスクに保存されている場合は、Cloud Storage に切り替えることができます。このオプションを使用するには、使用不能なインスタンスで PITR を実行するの手順に沿って操作します。
そのインスタンスのリードレプリカが別のゾーンにある場合は、そのリードレプリカをプロモートして、ゾーン停止が発生しているスタンドアロン インスタンスを置き換えることができます。このオプションを使用するには、レプリカをプロモートするの手順に沿って操作します。
どちらのオプションでも、次の点を考慮する必要があります。
プライマリ インスタンスで commit された最近のトランザクションの一部が、新しく復元されたインスタンスに表示されないことがあります。トランザクションが失われた可能性がある時間間隔が目標復旧時点(RPO)です。
- PITR 復元の RPO は通常 5 分以下です。
- リードレプリカのプロモーションの場合、RPO はデータベースのワークロードによって異なります。レプリケーション ラグをモニタリングして短縮する方法については、レプリケーション ラグをご覧ください。
どちらの復元オプションを実行した場合も、復元されたインスタンスは IP アドレスと接続名が異なるため、ゾーン停止が発生したインスタンスのクライアントを再構成する必要があります。
アプリケーションとインスタンス
HA インスタンスと非 HA インスタンスの使用方法に違いはありません。したがって、アプリケーションを特別な方法で構成する必要はありません。フェイルオーバーが発生すると、プライマリ インスタンスとリードレプリカへの既存の接続が切断されます。プライマリ インスタンスへの接続が再確立されるまでに約 60 秒かかります。アプケーションは再接続する際に同じ接続文字列または IP アドレスを使用するため、フェイルオーバー後にアプリケーションを更新する必要はありません。
アプリケーションがフェイルオーバーによってどのように影響されるかを正確に判断するには、手動でフェイルオーバーを開始します。
メンテナンスによるダウンタイム
メンテナンス イベントは、他のインスタンスと同様に、HA で構成されたプライマリ インスタンスに影響します。少しの間、プライマリ インスタンスが停止することが予測されます。メンテナンスが HA インスタンスに与える影響の詳細については、メンテナンスの仕組みをご覧ください。サービスへの影響を最小限に抑えるには、メンテナンスの設定を変更して、ダウンタイムが発生する時間帯を制御します。
パフォーマンス
リージョン永続ディスクのパフォーマンスは、多くの要因に左右されます。リージョン永続ディスクを使用すると、ゾーン永続ディスクと比較して 1 秒あたりの入出力オペレーション(IOPS)が低下する可能性があります。VM インスタンス タイプのサイズとワークロードの入出力がパフォーマンスに影響します。もう 1 つの指標は、SSD(ソリッド ステート ドライブ)を使用しているリージョン永続ディスクのレイテンシが、SSD を使用しているゾーン永続ディスクのレイテンシよりも高くなっているかどうかです。ワークロードがストリーミング ワークロードではなく、レイテンシの影響を受けやすい場合、SSD を使用しているゾーン永続ディスクよりも SSD を使用しているリージョン永続ディスクでレイテンシが高くなるので、ワークロードが IOPS の上限に達しないことになります。これは、リージョン永続ディスクに含まれる複数のゾーン間でデータの同期レプリケーションが行われ、リージョン内のゾーン間でデータのコピーが複数提供されるためです。
従来の MySQL の高可用性オプション
MySQL インスタンスに高可用性を付与する以前のプロセスでは、フェイルオーバー レプリカを使用します。 Google Cloud コンソールでは、以前の機能は使用できません。以前の構成: 高可用性向けに構成された新しいインスタンスを作成する、または以前の構成: 既存のインスタンスを高可用性向けに構成するをご覧ください。
次のステップ
- インスタンスの高可用性を有効または無効にする
- フェイルオーバーを開始する
- データベース接続の管理について学習する
- Cloud SQL のリージョンとゾーンについて学習する