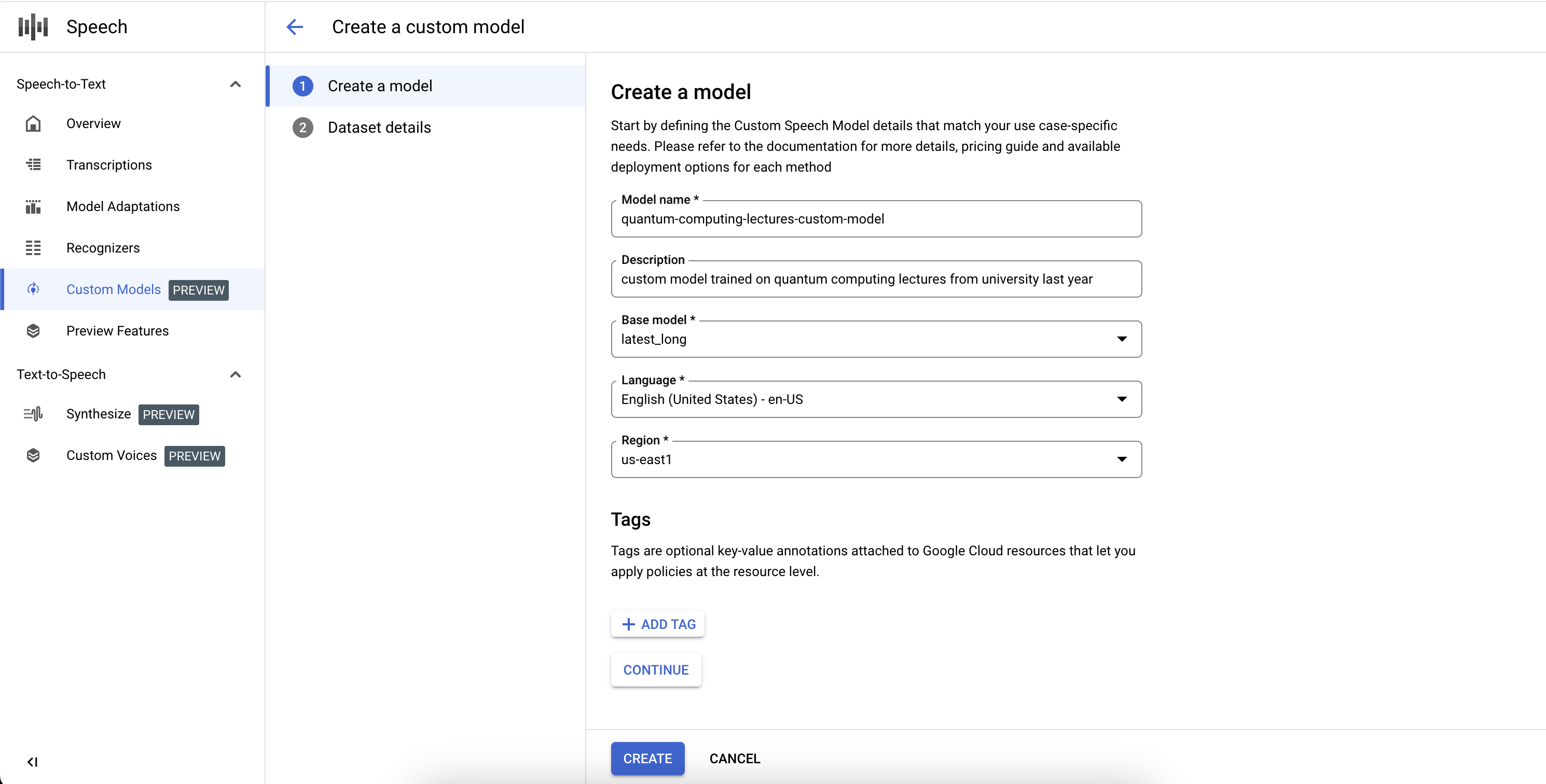
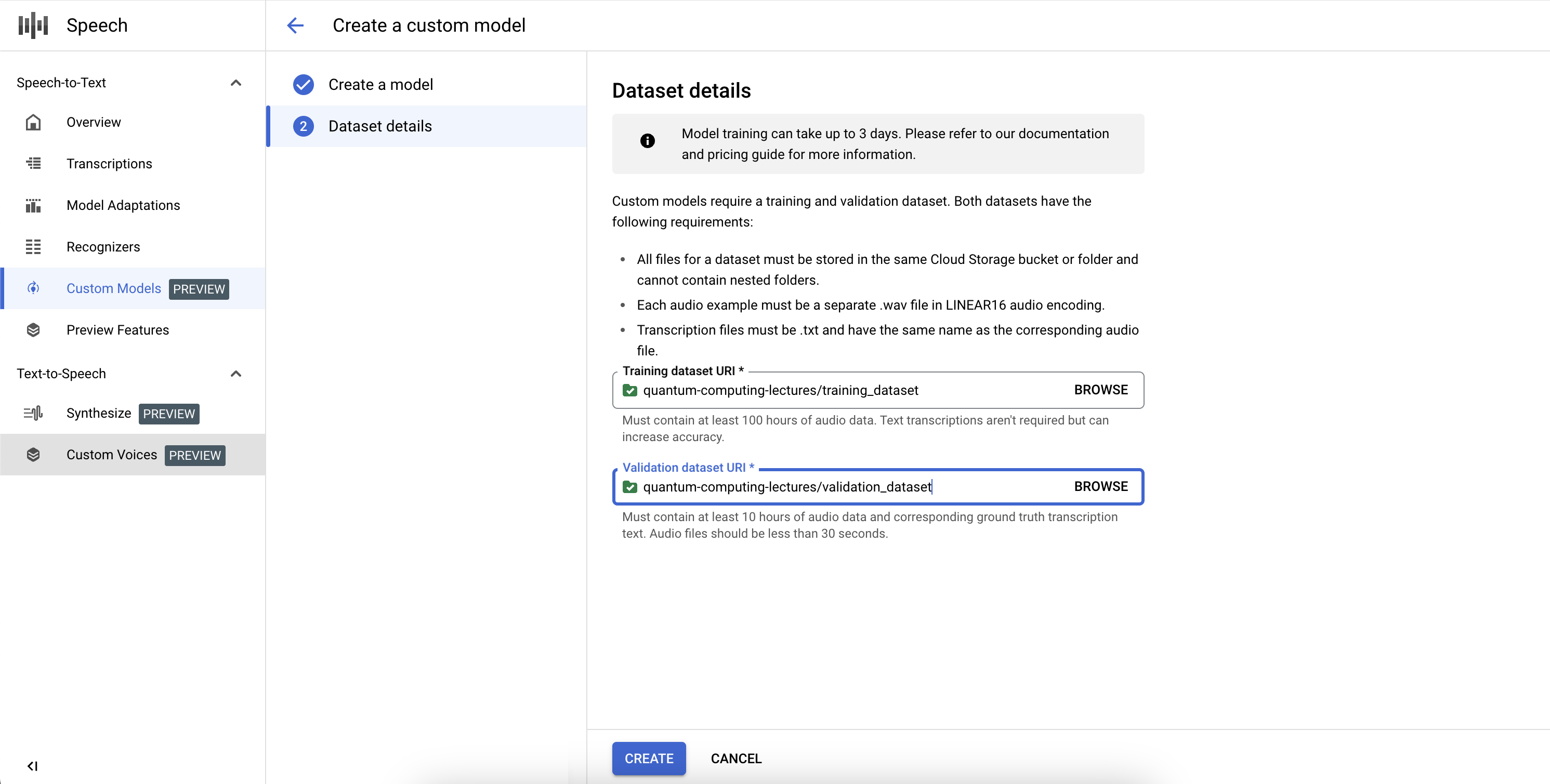
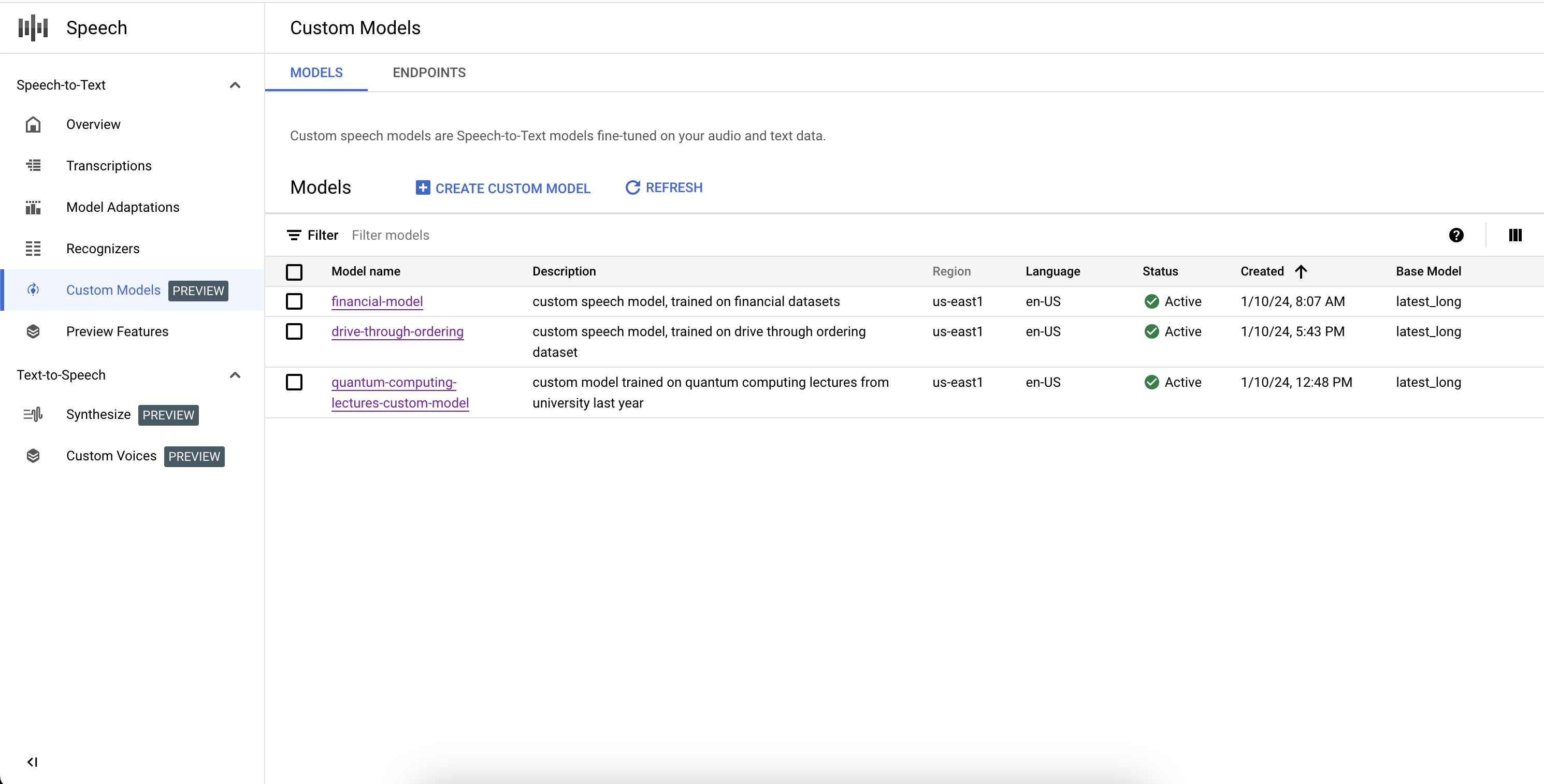
ML モデルと同様に、カスタム Speech-to-Text モデルのトレーニングは通常、反復的なものです。出発点としてベースモデルを選択し、テキスト データセットと音声データセットでファインチューニングしてから、モデルの認識品質をテストします。結果が期待どおりでない場合は、異なる組み合わせのデータで新しいモデルを再トレーニングするか、再度テストする、またはドメインで音声文字変換に直接使用します。
始める前に
Google Cloud アカウントに登録して Google Cloud プロジェクトを作成し、Speech-to-Text API を有効にしていることを確認してください。 Google Cloud コンソールで [Speech] を選択し、[Speech-to-Text API] に移動します。左側のナビゲーション バーの [カスタムモデル] セクションで操作します。
[[["わかりやすい","easyToUnderstand","thumb-up"],["問題の解決に役立った","solvedMyProblem","thumb-up"],["その他","otherUp","thumb-up"]],[["わかりにくい","hardToUnderstand","thumb-down"],["情報またはサンプルコードが不正確","incorrectInformationOrSampleCode","thumb-down"],["必要な情報 / サンプルがない","missingTheInformationSamplesINeed","thumb-down"],["翻訳に関する問題","translationIssue","thumb-down"],["その他","otherDown","thumb-down"]],["最終更新日 2025-09-04 UTC。"],[],[],null,["# Train and manage models\n\n| **Preview**\n|\n|\n| This feature is subject to the \"Pre-GA Offerings Terms\" in the General Service Terms section\n| of the [Service Specific Terms](/terms/service-terms#1).\n|\n| Pre-GA features are available \"as is\" and might have limited support.\n|\n| For more information, see the\n| [launch stage descriptions](/products#product-launch-stages).\n\nUsing the API, without any code, you can create and train a Custom Speech-to-Text model to improve recognition accuracy from an existing Speech-to-Text model. This fully managed service automatically provisions compute resources, executes the training application code, and ensures deletion of compute resources after the training job. You get a fully fine-tuned transcription model useful for any downstream application.\n\nSimilar to machine-learning models, training a Custom Speech-to-Text model is typically iterative and involves selecting a base model as a starting point, fine-tuning it with your text and audio datasets, then testing the recognition quality of the model. If the results are not what you expected, you retrain a new model with a different mixture of data, test again, or use it directly for transcription in your domain.\n\nBefore you begin\n----------------\n\nEnsure you have signed up for a Google Cloud account, created a Google Cloud project, and enabled the Speech-to-Text API: Go to **Speech** in the Google Cloud console, and navigate to the Speech-to-Text API. Operate in the **Custom Models** section of the navigation bar on the left.\n\nCreate a custom model\n---------------------\n\nStart by creating a custom Speech-to-Text model and defining its parameters, like base model and transcription language:\n\n1. Click **Create** to create a custom model.\n2. Enter a **Model name**, which will be used for the display and be referenced in your API requests and Google Cloud Speech console.\n3. Enter a **Description** for the model.\n4. Select a **Base model** that is suited best for your use case.\n5. Select the transcription **Language** of the model.\n6. Select the **Region** in which training should take place.\n7. Click **Continue**.\n\nTo complete the definition of the Custom Speech-to-Text model job and start the training, you will need to define the training and validation datasets.\n\n1. Select a **training dataset** , by providing a valid Cloud Storage directory URI. Ensure that only audio and text files are present and that the total duration of audio follows the [training dataset requirements](/speech-to-text/v2/docs/custom-speech-models/prepare-data#training_dataset_guidelines).\n2. Select a **validation dataset** , by providing a valid Cloud Storage directory URI. Ensure that only audio and text files are present and that the total duration of audio follows the [validation dataset requirements](/speech-to-text/v2/docs/custom-speech-models/prepare-data#validation_dataset_guidelines).\n3. Click **Create** to initiate the training process.\n\nIf not enough audio hours are indexed or the files don't follow the guidelines, the training job will fail.\n\nTraining jobs can be queued behind other jobs in our system, and training a model can take anywhere from a couple of hours to a few days depending on the dataset size. After the model training, its state will be flagged as **Active**.\n\nDelete a custom model\n---------------------\n\nBefore you start, make sure that there is no traffic routed to your Custom Speech-to-Text model through any endpoint, because deleting it will stop it from serving any requests.\n\n1. Navigate to the **Models** tab of the **Custom Models** section.\n2. Click to expand options and then click **Delete**. In a few moments the Custom Speech-to-Text model will be deleted, along with all of its endpoints, and will no longer serve any traffic.\n\nList your custom models\n-----------------------\n\nBy selecting the **Models** in the **Custom Models** section, you can also list all of your Custom Speech-to-Text models, including the ones that are training, active, and deleting.\n\nWhat's next\n-----------\n\nFollow the resources to take advantage of custom speech models in your application:\n\n- [Deploy and manage model endpoints](/speech-to-text/v2/docs/custom-speech-models/deploy-model).\n- [Use your custom models](/speech-to-text/v2/docs/custom-speech-models/use-model)\n- [Evaluate your custom models](/speech-to-text/v2/docs/custom-speech-models/evaluate-model)"]]