トレーニング済みのカスタム Speech-to-Text モデルを本番環境アプリケーションまたはベンチマーク ワークフローで使用します。モデルのデプロイと公開は、選択したリージョンにモデルをデプロイすることを目的に作成された専用のエンドポイントで行う必要があります。プログラムによるアクセス権は、認識ツール オブジェクトを介して自動的に付与されます。このオブジェクトは V2 API を介して直接使用することも、 Google Cloud コンソールで使用することもできます。トレーニングを行ったリージョンとは異なるリージョンにモデルをデプロイできますが、エンドポイントで指定されたリージョンにモデルのコピーが作成されます。
カスタム音声モデルを使用するには、専用のエンドポイントを使用してモデルをデプロイし、公開する必要があります。エンドポイントを作成することで、任意のリージョンにモデルをデプロイします。プログラムによるアクセス権は、認識ツール オブジェクトを介して自動的に付与されます。このオブジェクトは、V2 API を介して推論に直接使用することも、 Google Cloud コンソールで使用することもできます。
始める前に
Google Cloud アカウントに登録してプロジェクトを作成し、カスタム音声モデルのトレーニングが完了していることを確認します。
- Google Cloud コンソールで [Speech] を選択し、[Speech-to-Text] に移動します。
- 左側のナビゲーション バーの [カスタムモデル] セクションに移動します。
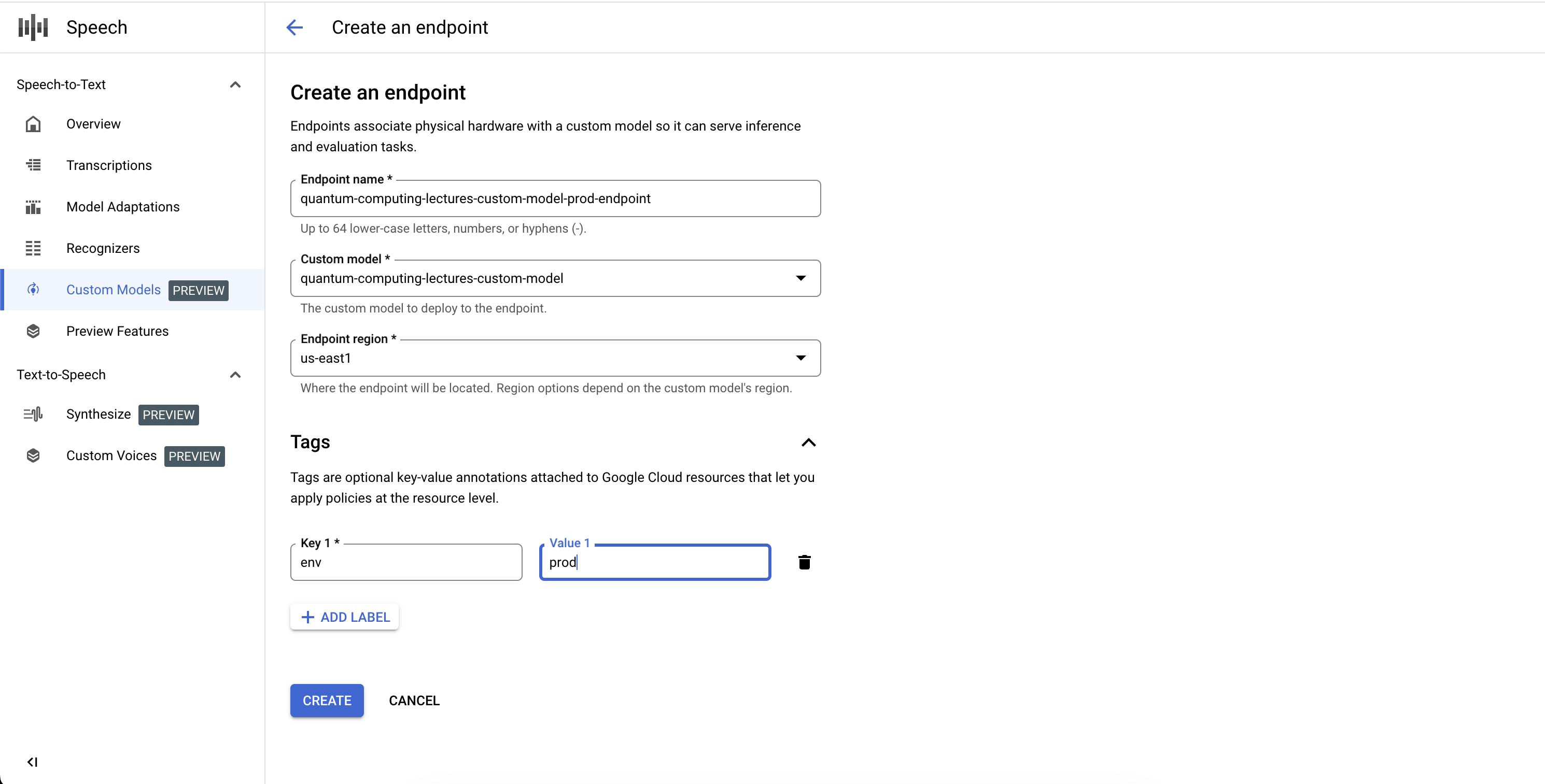
エンドポイントを作成する
- [カスタムモデル] セクションの [エンドポイント] タブに移動します。
- [新しいエンドポイント] をクリックします。
- エンドポイントの名前を定義します。これは、エンドポイント リソースの固有識別子として機能し、推論のためにカスタム音声モデルを呼び出す際に使用されます。
- カスタム音声モデルをデプロイするリージョンを定義します。エンドポイント構成で定義されているリージョンと異なるリージョンでモデルがトレーニングされている場合は、新しいモデルのコピーが自動的に作成されます。
- エンドポイントから公開するトレーニング済みのカスタム音声モデルを選択します。
- [作成] をクリックします。しばらくすると、カスタム音声モデルがエンドポイントにデプロイされ、推論とベンチマークで使用できる状態になります。
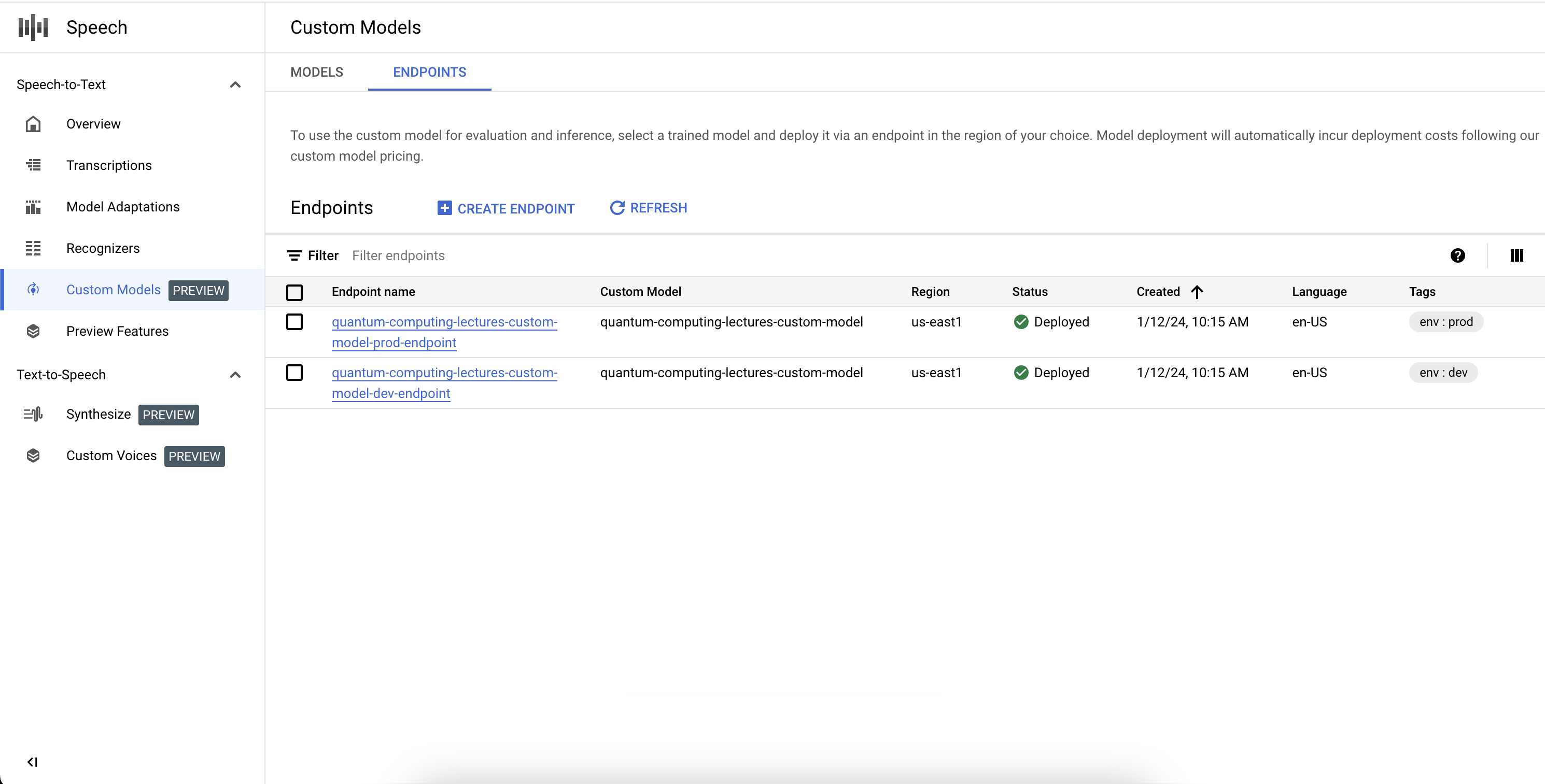
エンドポイントのリストを取得する
関連付けられたエンドポイントは、コンソールで [カスタムモデル] セクションの [エンドポイント] タブを選択することで管理できます。コンソールで作成したエンドポイントを、現在の状態と関連するカスタム Speech-to-Text モデルとともに一覧表示することもできます。
エンドポイントを削除する
まず、エンドポイントを介してルーティングされているトラフィックがないことを確認してください。エンドポイントを削除すると、リクエストが処理されなくなります。
- [カスタムモデル] セクションの [エンドポイント] タブに移動します。
- [エンドポイント] タブで、クリックしてオプションを開き、[削除] をクリックします。しばらくすると、エンドポイントが削除され、トラフィックが処理されなくなります。
モデルのベンチマークを行う
カスタム Speech-to-Text モデルとベンチマーク データセットを使用してモデルの精度を評価し、精度の測定と改善に関するガイドに沿って操作します。