Spanner est une base de données dotée d'une cohérence forte, distribuée et évolutive, conçue par les ingénieurs de Google pour soutenir certaines des applications les plus critiques de Google. Il reprend les idées fondamentales des communautés de bases de données et de systèmes distribués et les développe de manière nouvelle. Spanner propose ce service interne Spanner en tant que service accessible publiquement sur Google Cloud Platform.
Afin de pouvoir répondre aux exigences en termes de disponibilité et de mise à l'échelle imposées par les applications professionnelles critiques de Google, Spanner a été spécialement conçu pour devenir une base de données largement distribuée. En effet, le service peut être disponible sur plusieurs machines, centres de données et régions. Cette distribution permet de traiter de gros volumes de données et d'importantes charges de travail, tout en maintenant une très haute disponibilité. Nous avons également souhaité que Spanner fournisse les mêmes garanties de cohérence strictes que celles fournies par d’autres bases de données d’entreprise, car nous voulions offrir une expérience unique aux développeurs. Il est beaucoup plus facile de raisonner et d'écrire un logiciel pour une base de données avec une cohérence forte plutôt qu'une base de données garantissant une cohérence au niveau de la ligne, au niveau de l'entité voire n'ayant aucune garantie de cohérence.
Ce document présente en détail le fonctionnement des écritures et des lectures dans Spanner et la manière dont celui-ci garantit une cohérence forte.
Points de départ
Certains ensembles de données sont trop volumineux pour être traités par une seule machine. Il se peut également que l'ensemble de données soit petit, mais que la charge de travail soit trop lourde à traiter pour une machine. Il est alors nécessaire de trouver un moyen de fractionner les données en éléments distincts pouvant être stockés sur plusieurs machines. Notre approche consiste à partitionner les tables de base de données en plages de clés contiguës appelées partitions. Une seule machine peut diffuser plusieurs partitions et un service de recherche rapide permet de déterminer la ou les machines diffusant une plage de clés donnée. Les détails concernant la manière dont les données sont fractionnées et la ou les machines sur lesquelles elles se trouvent sont transparents pour les utilisateurs de Spanner. Cela permet d'obtenir un système capable de fournir des latences faibles pour les lectures et les écritures, même pour des charges de travail importantes, et à très grande échelle.
Nous souhaitons également nous assurer que les données sont accessibles malgré les défaillances. Pour ce faire, chaque partition est répliquée sur plusieurs machines dans des domaines de défaillance distincts. L'algorithme Paxos est chargé de faire en sorte que la réplication soit cohérente sur les différentes copies de la partition. Dans cet algorithme, tant que la majorité des instances dupliquées participant au vote pour cette partition sont actives, l'une d'entre elles peut être désignée comme variante optimale pour traiter les écritures et permettre aux autres instances dupliquées de diffuser les lectures.
Spanner fournit à la fois des transactions en lecture seule et des transactions en lecture-écriture. Les premières constituent le type de transaction préféré pour les opérations (y compris les instructions SQL SELECT) qui ne modifient pas vos données. Les transactions en lecture seule offrent une cohérence forte et fonctionnent par défaut sur la dernière copie de vos données. Mais elles sont également capables de fonctionner sans aucune forme de verrouillage interne, ce qui les rend plus rapides et plus adaptables. Les transactions en lecture-écriture sont utilisées pour les transactions qui insèrent, mettent à jour ou suppriment des données. Cela inclut les transactions qui effectuent des lectures suivies d'une écriture. Elles sont toujours très adaptables, mais les transactions en lecture-écriture introduisent un verrouillage et doivent être orchestrées par des variantes optimales Paxos. Notez que le verrouillage est transparent pour les clients Spanner.
De nombreux systèmes de bases de données distribuées antérieurs ont choisi de ne pas fournir de garantie en matière de cohérence forte en raison du coût de la communication généralement requise entre les machines. Spanner est en mesure de fournir des instantanés à cohérence forte sur l'ensemble de la base de données à l'aide d'une technologie développée par Google, appelée TrueTime. Comme le condensateur de flux dans une machine des années 1985, TrueTime est ce qui rend Spanner possible. Il s'agit d'une API qui permet à n'importe quelle machine d'un centre de données Google de connaître l'heure globale exacte avec un degré de précision élevé (de l'ordre de quelques millisecondes). Cela permet à différentes machines Spanner de s'accorder sur l'ordonnancement d'opérations transactionnelles (et de faire en sorte que cet ordre corresponde à celui observé par le client) souvent sans aucune communication. Google a dû équiper ses centres de données avec du matériel spécial (horloges atomiques!) afin d'assurer le fonctionnement de TrueTime. La précision temporelle et l'exactitude qui en résulte sont de loin plus élevées que celles pouvant être obtenues par d'autres protocoles (tels que NTP). Spanner attribue en particulier un horodatage à toutes les lectures et écritures. Il est garanti qu'une transaction à l'horodatage T1 reflète les résultats de toutes les écritures effectuées avant T1. Si une machine veut satisfaire à une lecture à l'horodatage T2, elle doit s'assurer que les données qu'elle affiche sont à jour au moins jusqu'à l'horodatage T2. En utilisant TrueTime, cette vérification est généralement très simple. Les protocoles permettant d'assurer la cohérence des données sont compliqués, mais ils sont décrits plus en détail dans la documentation d'origine de Spanner ainsi que dans la section du présent document concernant la cohérence avec Spanner.
Exemple pratique
Examinons quelques exemples pratiques pour voir comment tout cela fonctionne :
CREATE TABLE ExampleTable (
Id INT64 NOT NULL,
Value STRING(MAX),
) PRIMARY KEY(Id);
Dans cet exemple, nous avons une table avec une clé primaire de type entier simple.
| Partition | KeyRange |
|---|---|
| 0 | [-∞,3) |
| 1 | [3,224) |
| 2 | [224,712) |
| 3 | [712,717) |
| 4 | [717,1265) |
| 5 | [1265,1724) |
| 6 | [1724,1997) |
| 7 | [1997,2456) |
| 8 | [2456,∞) |
Étant donné le schéma de la table ExampleTable ci-dessus, l'espace de la clé primaire est partitionné en partitions. Par exemple, si une ligne est présente dans ExampleTable avec un Id de 3700, elle apparaîtra dans la partition 8. Comme indiqué ci-dessus, la partition 8 est elle-même répliquée sur plusieurs machines.
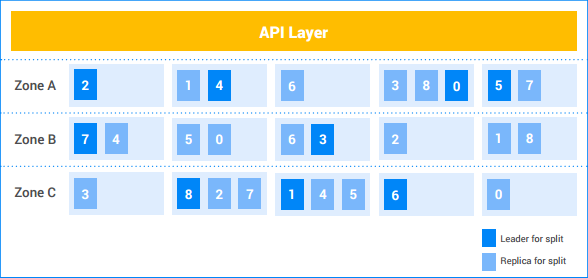
Dans cet exemple d'instance Spanner, le client dispose de cinq nœuds et l'instance est répliquée sur trois zones. Les neuf partitions sont numérotées de 0 à 8, les variantes optimales de Paxos pour chaque partition étant distinguées par une couleur plus foncée. Les partitions ont également des instances dupliquées dans chaque zone (légèrement grisées). La distribution des partitions entre les nœuds peut être différente dans chaque zone et les variantes optimales Paxos ne se trouvent pas toutes dans la même zone. Cette flexibilité permet à Spanner d’être plus robuste face à certains types de profils de chargement et de modes de défaillance.
Écriture sur une seule partition
Supposons que le client souhaite insérer une nouvelle ligne (7, "Seven") dans ExampleTable.
- La couche API recherche la partition qui possède la plage de clés contenant
7. Il s'agit de la partition 1. - La couche API envoie la demande d'écriture à la variante optimale de la partition 1.
- La variante optimale initie une transaction.
- La variante optimale tente d'obtenir un verrou en écriture sur la ligne
Id=7. Il s'agit d'une opération locale. Si une autre transaction de lecture-écriture simultanée lit actuellement cette ligne, cette transaction dispose d'un verrou en lecture et la transaction en cours se bloque jusqu'à ce qu'elle puisse acquérir le verrou en écriture.- Il est possible que la transaction A attende un verrou détenu par la transaction B et que la transaction B attende un verrou détenu par la transaction A. Étant donné qu'aucune de ces transactions ne libérera de verrou tant qu'elle n'aura pas obtenu tous les verrous dont elle a besoin, cela peut conduire à un blocage. Spanner utilise un algorithme standard "wound-wait" de prévention des blocages pour garantir l’avancement des transactions. Dans ce cas, une transaction "plus jeune" attendra le verrou bloqué par une transaction "plus ancienne", mais une transaction "plus ancienne" pourra "casser" (annuler) une transaction plus jeune détenant un verrou dont elle a besoin. Ainsi les situations de blocage dû aux verrouillages sont évitées.
- Une fois le verrou acquis, la variante optimale attribue un horodatage à la transaction basé sur TrueTime.
- Il est garanti que cet horodatage est ultérieur à celui de toute transaction précédemment validée concernant les données. C’est ce qui garantit que l'ordre des transactions (tel que perçu par le client) correspond à l'ordre des modifications apportées aux données.
- La variante optimale informe les instances dupliquées de la partition 1 de la transaction et de son horodatage. Une fois que la majorité de ces instances dupliquées ont stocké la mutation de la transaction dans un stockage stable (dans le système de fichiers distribué), la transaction est validée. Cela garantit que la transaction peut être récupérée, même si une défaillance survient sur une minorité de machines. (Les instances dupliquées n'appliquent pas encore les mutations à leur copie des données.)
La variante optimale attend jusqu'à ce qu'il soit certain que l'horodatage de la transaction s'est effectué en temps réel. Il suffit généralement de quelques millisecondes pour lever toute incertitude quant à l'horodatage TrueTime. C'est ce qui garantit une cohérence forte : une fois que le résultat d'une transaction est transmis au client, il est garanti que tous les autres lecteurs verront les effets de cette transaction. Cette "attente de commit" chevauche généralement le délai de communication à l'instance dupliquée mentionné à l'étape ci-dessus, ainsi le coût de latence réel est minimal. Plus de détails sont abordés dans cet article.
La variante optimale répond au client pour l'informer que la transaction a été validée, en indiquant éventuellement l'horodatage de validation de la transaction.
Parallèlement à cette réponse, les mutations de transaction sont appliquées aux données.
- La variante optimale applique les mutations à sa copie des données, puis libère ses verrous de transaction.
- La variante optimale informe également les autres instances dupliquées de la partition 1 qu'elles doivent appliquer la mutation à leur copie des données.
- Toute transaction en lecture-écriture ou en lecture seule qui doit voir les effets des mutations attend que celles-ci soient appliquées avant de tenter de lire les données. Pour les transactions en lecture-écriture, ceci est appliqué car la transaction doit être verrouillée en lecture. Pour les transactions en lecture seule, ceci est appliqué en comparant l'horodatage de la lecture avec celui de la dernière mise à jour des données.
Tout cela se produit généralement en quelques millisecondes. Cette écriture est le type d'écriture le moins coûteux effectué par Spanner, puisqu'une seule partition est impliquée.
Écriture sur plusieurs partitions
Si plusieurs partitions sont impliquées, une couche supplémentaire de coordination (utilisant l'algorithme de validation standard à deux phases) est nécessaire.
Supposons que la table contienne quatre mille lignes :
| 1 | "un" |
| 2 | "deux" |
| … | … |
| 4 000 | "quatre mille" |
Et supposons que le client veuille lire la valeur de la ligne 1000 et écrire une valeur dans les lignes 2000, 3000 et 4000 par une transaction. Il sera alors nécessaire de procéder à une transaction en lecture-écriture telle que ci-dessous :
- Le client commence une transaction en lecture-écriture, t.
- Le client envoie une demande de lecture pour la ligne 1 000 à la couche API et la marque comme faisant partie de t.
- La couche API recherche la partition propriétaire de la clé
1000. Il s'agit de la partition 4. La couche API envoie une demande de lecture à la variante optimale de la répartition 4 et la marque comme faisant partie de t.
La variante optimale de la partition 4 tente d'obtenir un verrou en lecture sur la ligne
Id=1000. Il s'agit d'une opération locale. Si une autre transaction simultanée dispose d'un verrou en écriture sur cette ligne, alors la transaction en cours reste bloquée jusqu'à ce qu'elle puisse acquérir le verrou. Toutefois, ce verrou en lecture n'empêche pas les autres transactions d'obtenir des verrous en lecture.- Comme dans le cas d'une seule division, le blocage est évité via l'algorithme "wound-wait".
La variante optimale recherche la valeur pour
Id1000("mille") et renvoie le résultat de la lecture au client.
Plus tard…Le client émet une demande de validation pour la transaction t. Cette demande de validation contient trois mutations :
[2000, "Dos Mil"],[3000, "Tres Mil"]et[4000, "Quatro Mil"].- Toutes les partitions impliquées dans une transaction deviennent les participants de la transaction. Dans ce cas, la partition 4 (qui diffuse la lecture pour la clé
1000), la partition 7 (qui gérera la mutation pour la clé2000) et la partition 8 (qui gérera les mutations pour les clés3000et4000) sont des participants.
- Toutes les partitions impliquées dans une transaction deviennent les participants de la transaction. Dans ce cas, la partition 4 (qui diffuse la lecture pour la clé
L'un des participants devient le coordinateur. Dans ce cas, il se peut que la variante optimale de la partition 7 devienne le coordinateur. Celui-ci a pour tâche de s'assurer que la transaction est validée ou annulée de manière atomique pour tous les participants. Cela signifie qu'il ne peut pas la valider pour un participant et l'annuler pour un autre.
- Le travail effectué par les participants et les coordinateurs est en réalité effectué par les machines maîtres de ces partitions.
Les participants acquièrent des verrous. (Il s'agit de la première phase d'une validation en deux phases.)
- La partition 7 acquiert un verrou en écriture sur la clé
2000. - La partition 8 acquiert un verrou en écriture sur les clés
3000et4000. - La partition 4 vérifie qu'elle maintient toujours un verrou en lecture sur la clé
1000(en d'autres termes, que le verrou n'a pas été perdu en raison d'un plantage de la machine ou de l'algorithme "wound-wait".) - Chaque participant enregistre ses verrous en les répliquant sur (au moins) une majorité de copies de partitions. Cela garantit le maintien des verrous même en cas de défaillance du serveur.
- Si tous les participants notifient au coordinateur que leurs verrous sont conservés, la transaction globale peut être validée. Cela garantit qu'il existe un moment où tous les verrous nécessaires à la transaction sont maintenus. Ce moment devient le point de validation de la transaction, garantissant que les effets de cette transaction sont ordonnés correctement par rapport à d'autres transactions, antérieures ou ultérieures.
- Il est possible que des verrous ne puissent pas être acquis (par exemple, s'il s'avère qu'il peut exister un blocage via l'algorithme "wound-wait"). Si l'un des participants indique qu'il ne peut pas valider la transaction, toute la transaction est annulée.
- La partition 7 acquiert un verrou en écriture sur la clé
Si tous les participants, ainsi que le coordinateur, arrivent à acquérir les verrous, le coordinateur (partition 7) décide de valider la transaction. Il attribue à la transaction un horodatage basé sur TrueTime.
- Cette décision de commit, ainsi que les mutations de la clé
2000, sont répliquées sur les membres de la partition 7. Une fois que la majorité des instances dupliquées de la partition 7 ont enregistré la décision de validation dans un stockage stable, la transaction est validée.
- Cette décision de commit, ainsi que les mutations de la clé
Le coordinateur communique le résultat de la transaction à tous les participants. (Il s'agit de la deuxième phase de commit en deux phases.)
- Chaque variante optimale du participant réplique la décision de validation sur les instances dupliquées de sa partition.
Si la transaction est validée, le coordinateur et tous les participants appliquent les mutations aux données.
- Comme dans le cas d'une seule partition, les lecteurs de données ultérieurs au niveau du coordinateur ou des participants doivent attendre que les données soient appliquées.
La variante optimale du coordinateur répond au client pour l'informer que la transaction a été validée, en affichant éventuellement l'horodatage de validation de la transaction.
- Comme dans le cas d'une seule division, le résultat est communiqué au client après une attente de validation pour s'assurer d'une cohérence forte.
Tout cela se produit généralement en quelques millisecondes, même si ce temps est un peu plus long que dans le cas d'une seule partition en raison de la coordination supplémentaire entre les partitions.
Lecture forte (multipartitionnement)
Imaginons que le client souhaite lire toutes les lignes où Id >= 0 et Id < 700 font partie d'une transaction en lecture seule.
- La couche API recherche les partitions qui possèdent des clés dans la plage
[0, 700). Ces lignes appartiennent aux partitions 0, 1 et 2. - Comme il s'agit d'une lecture forte sur plusieurs machines, la couche API choisit l'horodatage de lecture à l'aide de la valeur TrueTime actuelle. Cela garantit que les deux lectures affichent des données du même instantané de la base de données.
- D'autres types de lectures, telles que les lectures non actualisées, sélectionnent également un horodatage de lecture (celui-ci pouvant se situer dans le passé).
- La couche API envoie la demande de lecture à une instance dupliquée des partitions 0, 1 et 2. Elle inclut également l'horodatage de lecture sélectionné à l'étape précédente.
Pour les lectures fortes, le réplica de service émet généralement un RPC auprès du leader pour lui demander l'horodatage de la dernière transaction qu'il doit appliquer. La lecture peut alors se poursuivre une fois cette transaction appliquée. Si le réplica est le leader ou s'il détermine qu'il est suffisamment à jour pour répondre à la requête à partir de son état interne et de TrueTime, il diffuse directement la lecture.
Les résultats renvoyés par les instances dupliquées sont combinés et communiqués au client (via la couche API).
Notez que les lectures n'acquièrent aucun verrou dans les transactions en lecture seule. De plus, étant donné que les instances dupliquées à jour d'une partition donnée peuvent diffuser les lectures, le débit de lecture du système est potentiellement très élevé. Si le client est capable de tolérer des lectures obsolètes d'au moins dix secondes, le débit de lecture peut être encore plus élevé. Étant donné que la variante optimale met généralement à jour les instances dupliquées avec le dernier horodatage sécurisé toutes les dix secondes, les lectures à un horodatage obsolète peuvent éviter un RPC supplémentaire à la variante optimale.
Conclusion
Traditionnellement, les concepteurs de systèmes de bases de données distribuées ont constaté que les garanties transactionnelles fortes sont coûteuses, en raison de toutes les communications requises entre plusieurs machines. Avec Spanner, nous nous sommes concentrés sur la réduction du coût des transactions afin de les rendre réalisables à grande échelle et ce, malgré la distribution. La principale raison pour laquelle cela fonctionne est TrueTime, qui réduit la communication entre les machines pour de nombreux types de coordination. Au-delà de cela, une ingénierie minutieuse et un réglage des performances ont abouti à un système extrêmement performant, tout en offrant de solides garanties. Les équipes de Google ont constaté que le développement d'applications était considérablement facilité avec Spanner par rapport à d'autres systèmes de base de données présentant des garanties plus faibles. Lorsque les développeurs d'applications n'ont pas à s'inquiéter des conditions de concurrence ou des incohérences dans leurs données, ils peuvent se concentrer sur ce qui compte vraiment pour eux : créer et livrer une application de qualité.