Spanner es una base de datos escalable, distribuida y de coherencia sólida que crearon los ingenieros de Google para admitir algunas de sus aplicaciones más importantes. Toma ideas centrales de la base de datos y las comunidades de sistemas distribuidos y las expande de formas novedosas. Spanner expone este servicio interno de Spanner como un servicio de acceso público en Google Cloud Platform.
Debido a que Spanner debe manejar los exigentes requisitos de escalamiento y tiempo de actividad que imponen las aplicaciones empresariales más importantes de Google, compilamos Spanner desde cero para que sea una base de datos con un alto nivel de distribución; el servicio puede abarcar varias máquinas y varios centros de datos y regiones. Aprovechamos esta distribución para manejar enormes conjuntos de datos y gigantescas cargas de trabajo, a la vez que mantenemos una alta disponibilidad. También nos propusimos que Spanner proporcione las mismas garantías de coherencia estricta que proporcionan otras bases de datos de nivel empresarial, ya que queríamos crear una experiencia excelente para los desarrolladores. Es mucho más fácil razonar y escribir software destinado a una base de datos que admita la coherencia sólida que para una base de datos que solo admita la coherencia a nivel de fila, de entidad o que no cuenta con ninguna garantía de coherencia.
En este documento, describimos en detalle cómo funcionan las operaciones de escritura y de lectura en Spanner y cómo este garantiza la coherencia sólida.
Puntos de partida
Hay algunos conjuntos de datos que son demasiado grandes para caber en una sola máquina. También hay situaciones en las que el conjunto de datos es pequeño, pero la carga de trabajo es demasiado pesada para que una sola máquina pueda manejarla. Esto significa que debemos encontrar una manera de dividir nuestros datos en partes separadas que puedan almacenarse en varias máquinas. Nuestro enfoque consiste en particionar las tablas de la base de datos en rangos de claves contiguos llamados divisiones. Una sola máquina puede entregar varias divisiones, y hay un servicio de búsqueda rápida para determinar qué máquinas entregan un rango de claves determinado. Los detalles de cómo se dividen los datos y en qué máquinas residen son transparentes para los usuarios de Spanner. El resultado es un sistema que puede proporcionar latencias bajas para las lecturas y escrituras, incluso en grandes cargas de trabajo, a muy gran escala.
También queremos asegurarnos de que los datos sean accesibles a pesar de las fallas. Para garantizar esto, replicamos cada división en varias máquinas en distintos dominios con fallas. El algoritmo Paxos administra la replicación coherente en las diferentes copias de la división. En Paxos, siempre que la mayoría de las réplicas de votación para la división aumente, se puede elegir a una de esas réplicas como líder a fin de procesar las escrituras y permitir que otras réplicas entreguen lecturas.
Spanner proporciona transacciones de solo lectura y transacciones de lectura y escritura. Las primeras son el tipo de transacción preferida para las operaciones (lo que incluye las instrucciones SELECT de SQL) que no modifican los datos. Las transacciones de solo lectura aun proporcionan coherencia sólida y funcionan, de forma predeterminada, en la última copia de tus datos. Sin embargo, pueden ejecutarse sin necesidad de ningún tipo de bloqueo interno, lo que las hace más rápidas y escalables. Las transacciones de lectura y escritura se usan para transacciones que insertan, actualizan o borran datos, lo que incluye transacciones que realizan operaciones de lectura seguidas de una de escritura. Siguen siendo muy escalables, pero las transacciones de lectura y escritura presentan un bloqueo y deben ser organizadas por los líderes de Paxos. Ten en cuenta que el bloqueo es transparente para los clientes de Spanner.
Muchos sistemas de bases de datos distribuidas anteriores decidieron no proporcionar garantías de coherencia sólida debido a la costosa comunicación entre máquinas, algo que suele ser necesario. Spanner puede proporcionar instantáneas con coherencia sólida en toda la base de datos mediante una tecnología que desarrolló Google llamada TrueTime. Al igual que el condensador de flujo en una máquina del tiempo de alrededor de 1985, TrueTime es lo que hace que Spanner sea posible. Es una API que permite que cualquier máquina en los centros de datos de Google conozca la hora global exacta con un alto grado de precisión (es decir, en cuestión de pocos milisegundos). Esto permite que diferentes máquinas de Spanner razonen sobre el orden de las operaciones transaccionales (y hagan que ese orden coincida con lo que observó el cliente) a menudo sin ninguna comunicación. Google tuvo que equipar sus centros de datos con hardware especial (relojes atómicos) para hacer funcionar TrueTime. La exactitud y precisión del tiempo que se obtuvieron son mucho mayores que la que pueden obtener otros protocolos (como NTP). En particular, Spanner asigna una marca de tiempo a todas las lecturas y escrituras. Se garantiza que una transacción en la marca de tiempo T1 reflejará los resultados de todas las escrituras que hayan ocurrido antes de T1. Si se desea que una máquina satisfaga una lectura en T2, se debe garantizar que su vista de los datos esté actualizada, aunque sea, hasta T2. Gracias a TrueTime, esta determinación suele ser muy económica. Los protocolos para garantizar la coherencia de los datos son complicados, pero se analizan con más detalle en la página del informe de Spanner original y en este informe sobre Spanner y la coherencia.
Ejemplo práctico
Analicemos algunos ejemplos prácticos para ver cómo funciona todo:
CREATE TABLE ExampleTable (
Id INT64 NOT NULL,
Value STRING(MAX),
) PRIMARY KEY(Id);
En este ejemplo, tenemos una tabla con una clave primaria de número entero simple.
| División | KeyRange |
|---|---|
| 0 | [-∞,3) |
| 1 | [3,224) |
| 2 | [224,712) |
| 3 | [712,717) |
| 4 | [717,1265) |
| 5 | [1265,1724) |
| 6 | [1724,1997) |
| 7 | [1997,2456) |
| 8 | [2456,∞) |
De acuerdo con el esquema de la ExampleTable anterior, el espacio de la clave primaria se particiona en divisiones. Por ejemplo, si hay una fila en la ExampleTable con un Id de 3700, se alojará en la División 8. Como se detalló antes, la División 8 se replica en varias máquinas.
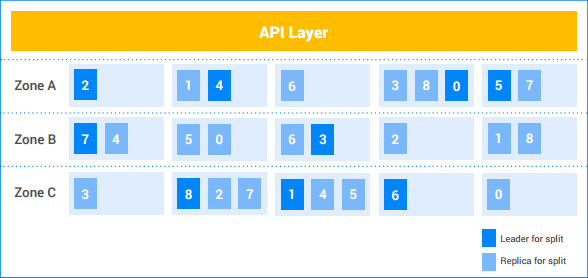
En esta instancia de Spanner de ejemplo, el cliente tiene cinco nodos y la instancia se replica en tres zonas. Las nueve divisiones están numeradas del 0 al 8, y los líderes de Paxos para cada división tienen un sombreado oscuro. Las divisiones también tienen réplicas en cada zona (sombreadas con color más claro). La distribución de las divisiones entre los nodos puede ser diferente en cada zona, y no todos los líderes de Paxos residen en la misma zona. Esta flexibilidad ayuda a Spanner a ser más sólido con ciertos tipos de perfiles de carga y modos de error.
Escritura de división única
Supongamos que el cliente desea insertar una fila nueva (7, "Seven") en la ExampleTable.
- La capa de la API busca la división que posee el rango de claves que contiene
7. Este se encuentra en la División 1. - La capa de la API envía la solicitud de escritura al líder de la División 1.
- El líder inicia una transacción.
- El líder intenta obtener un bloqueo de escritura en la fila
Id=7. Esta es una operación local. Si otra transacción de lectura y escritura simultánea está leyendo esta fila en ese momento, entonces la otra transacción tiene un bloqueo de lectura, y la transacción actual se bloquea hasta que pueda adquirir el bloqueo de la escritura.- Es posible que la transacción A esté esperando un bloqueo de la transacción B, y que la transacción B esté esperando un bloqueo de la transacción A. Como ninguna transacción libera ningún bloqueo hasta que adquiere todos los bloqueos, esto puede generar un interbloqueo. Spanner usa un algoritmo estándar de “prevención” de interbloqueos para garantizar que las transacciones progresen. En particular, una transacción “más nueva” esperará un bloqueo de una transacción “más antigua”, pero una transacción “más antigua” “sanará” (anulará) una transacción más nueva que contenga un bloqueo que solicitó la transacción anterior. Por lo tanto, nunca tenemos ciclos de interbloqueo de transacciones en espera de un bloqueo.
- Una vez que se adquiere el bloqueo, el líder asigna una marca de tiempo a la transacción de acuerdo con TrueTime.
- Se garantiza que esta marca de tiempo sea superior a cualquier transacción confirmada con anterioridad que haya estado en contacto con los datos. Esto es lo que garantiza que el orden de las transacciones (según la percepción del cliente) coincida con el orden de los cambios en los datos.
- El líder comunica a las réplicas de la División 1 sobre la transacción y su marca de tiempo. Una vez que la mayoría de esas réplicas haya almacenado la mutación de la transacción en un almacenamiento estable (en el sistema de archivos distribuido), la transacción se confirma. Esto garantiza que la transacción sea recuperable, incluso si hay una falla en una minoría de las máquinas. Las réplicas aún no aplican las mutaciones a su copia de datos.
El líder espera hasta que pueda estar seguro de que la marca de tiempo de la transacción se aprobó en tiempo real; esto suele tardar algunos milisegundos, de modo que podemos esperar cualquier incertidumbre en la marca de tiempo de TrueTime. Esto garantiza la coherencia sólida: una vez que el cliente conoce el resultado de una transacción, se garantiza que todos los demás lectores verán los efectos de la transacción. Por lo general, esta “espera por la confirmación” se superpone con la comunicación de la réplica en el paso anterior, por lo que su costo de latencia real es mínimo. En este informe, se tratan más detalles.
El líder responde al cliente para informarle que la transacción se ha confirmado y tiene la opción de informar la marca de tiempo de confirmación de la transacción.
De forma simultánea a la respuesta al cliente, se aplican las mutaciones de la transacción a los datos.
- El líder aplica las mutaciones a su copia de los datos y, luego, libera sus bloqueos de transacciones.
- El líder también informa a las otras réplicas de la División 1 que apliquen la mutación a sus copias de los datos.
- Cualquier transacción de solo lectura o lectura y escritura que deba ver los efectos de las mutaciones esperará a que se las aplique antes de intentar leer los datos. En el caso de las transacciones de lectura y escritura, esto se debe aplicar porque la transacción debe tener un bloqueo de lectura. Para las transacciones de solo lectura, esto se debe aplicar cuando se compara la marca de tiempo de la lectura con la de los últimos datos aplicados.
Todo esto suele ocurrir en un puñado de milisegundos. Esta escritura es el tipo de escritura más económico que hizo Spanner, ya que se trata de una sola división.
Escritura de división múltiple
Si se trata de varias divisiones, se necesita una capa de coordinación adicional (con el algoritmo de confirmación estándar en dos fases).
Supongamos que la tabla contiene cuatro mil filas:
| 1 | “uno” |
| 2 | “dos” |
| ... | ... |
| 4000 | “cuatro mil” |
Supongamos que el cliente desea leer el valor de la fila 1000 y escribir un valor en las filas 2000, 3000 y 4000 dentro de una transacción. Esto se ejecutará en una transacción de lectura y escritura de la siguiente manera:
- El cliente inicia una transacción de lectura y escritura, t.
- El cliente emite una solicitud de lectura para la fila 1000 de la capa de la API y la etiqueta como parte de t.
- La capa de la API busca la división que posee la clave
1000. Esta se encuentra en la División 4. La capa de la API envía una solicitud de lectura al líder de la División 4 y la etiqueta como parte de t.
El líder de la División 4 intenta obtener un bloqueo de lectura en la fila
Id=1000. Esta es una operación local. Si otra transacción simultánea tiene un bloqueo de escritura en esta fila, la transacción actual se bloquea hasta que pueda adquirir el bloqueo. Sin embargo, este bloqueo de lectura no impide que otras transacciones obtengan bloqueos de lectura.- Al igual que en el caso de división única, el interbloqueo se evita a través de la “prevención”.
El líder busca el valor del
Id1000(“Mil”) y muestra el resultado de lectura al cliente.
Luego…El cliente emite una solicitud de confirmación para la transacción t. Esta solicitud de confirmación contiene 3 mutaciones: (
[2000, "Dos Mil"],[3000, "Tres Mil"]y[4000, "Quatro Mil"]).- Todas las divisiones que participan en una transacción se convierten en participantes de la transacción. En este caso, los participantes son la División 4 (que entregó la lectura para la clave
1000), la División 7 (que manejará la mutación de la clave2000) y la División 8 (que manejará las mutaciones para las claves3000y4000).
- Todas las divisiones que participan en una transacción se convierten en participantes de la transacción. En este caso, los participantes son la División 4 (que entregó la lectura para la clave
Un participante se convierte en el coordinador. En este caso, quizás el líder de la División 7 se convierta en el coordinador. El trabajo del coordinador consiste en asegurarse de que la transacción se confirme o se anule de forma automática en todos los participantes. Es decir, no confirmará a un participante y anulará a otro.
- En realidad, el trabajo que realizan los participantes y los coordinadores lo realizan las máquinas líderes de esas divisiones.
Los participantes adquieren bloqueos. Esta es la primera fase de la confirmación en dos fases.
- La División 7 adquiere un bloqueo de escritura en la clave
2000. - La División 8 adquiere un bloqueo de escritura en las claves
3000y4000. - La División 4 verifica que aún tenga un bloqueo de lectura en la clave
1000(en otras palabras, que el bloqueo no se haya perdido por una falla de la máquina o por el algoritmo de prevención). - La división de cada participante registra su conjunto de bloqueos cuando los replica (al menos) en la mayoría de las réplicas de las divisiones. Esto garantiza que los bloqueos puedan conservarse, incluso en caso de fallas del servidor.
- Si todos los participantes notifican de forma correcta al coordinador que sus bloqueos funcionan, entonces, se puede confirmar la transacción general. Esto garantiza que haya un momento en el que todos los bloqueos que requiere la transacción funcionen, y ese momento se convertirá en el momento de la confirmación de la transacción, lo que garantiza que podamos ordenar de manera correcta los efectos de esta transacción ante las demás transacciones previas o posteriores.
- Es posible que no se puedan adquirir los bloqueos (por ejemplo, si descubrimos que puede haber un interbloqueo a través del algoritmo de prevención). Si algún participante dice que no puede confirmar la transacción, se anula toda la transacción.
- La División 7 adquiere un bloqueo de escritura en la clave
Si todos los participantes y el coordinador adquieren bloqueos con éxito, el coordinador (la División 7) decide confirmar la transacción. Esta asigna una marca de tiempo a la transacción en función de TrueTime.
- Esta decisión de confirmación, así como las mutaciones de la clave
2000, se replican en los miembros de la División 7. Una vez que la mayoría de las réplicas de la División 7 registran la decisión de confirmación en un almacenamiento estable, la transacción se confirma.
- Esta decisión de confirmación, así como las mutaciones de la clave
El coordinador comunica el resultado de la transacción a todos los participantes. Esta es la segunda fase de la confirmación en dos fases.
- Cada líder participante replica la decisión de confirmación en las réplicas de la división participante.
Si la transacción se confirma, el coordinador y todos los participantes aplican las mutaciones a los datos.
- Al igual que en el caso de la división única, los lectores de datos posteriores del coordinador o los participantes deben esperar hasta que se apliquen los datos.
El líder coordinador responde al cliente para informarle que la transacción se ha confirmado y tiene la opción de mostrar la marca de tiempo de confirmación de la transacción.
- Al igual que en el caso de división única, el resultado se comunica al cliente después de una espera de confirmación para garantizar la coherencia sólida.
Todo esto ocurre en un puñado de milisegundos, aunque suele tardar un poco más que en el caso de división única debido a la coordinación adicional entre divisiones.
Lectura sólida (multidivisión)
Supongamos que el cliente desea leer todas las filas en las que Id >= 0 y Id < 700 son parte de una transacción de solo lectura.
- La capa de la API busca divisiones que posean claves del rango
[0, 700). Estas filas son propiedad de la División 0, la División 1 y la División 2. - Como es una lectura sólida entre varias máquinas, la capa de la API elige la marca de tiempo de lectura mediante el TrueTime actual. Esto garantiza que ambas lecturas muestren datos de la misma instantánea de la base de datos.
- Otros tipos de lecturas, como las lecturas inactivas, también eligen una marca de tiempo para realizar operaciones de lectura (pero es posible que la marca de tiempo sea antigua).
- La capa de la API envía la solicitud de lectura a alguna réplica de la División 0, alguna réplica de la División 1 y alguna réplica de la División 2. También incluye la marca de tiempo de lectura que se seleccionó en el paso anterior.
En el caso de las operaciones de lectura sólidas, la réplica de publicación suele realizar una RPC al líder para solicitar la marca de tiempo de la última transacción que debe aplicar, y la operación de lectura puede continuar una vez que se aplica esa transacción. Si la réplica es la líder o determina que está lo suficientemente actualizada para entregar la solicitud desde su estado interno y TrueTime, entrega la operación de lectura directamente.
Los resultados de las réplicas se combinan y se muestran al cliente (a través de la capa de la API).
Ten en cuenta que las operaciones de lectura no adquieren ningún bloqueo en las transacciones de solo lectura. Además, como es posible que las lecturas se entreguen con cualquier réplica actualizada de una división determinada, la capacidad de procesamiento de lectura del sistema tiene un potencial muy alto. Si el cliente puede tolerar lecturas que están inactivas por al menos diez segundos, la capacidad de procesamiento de lectura puede ser aún mayor. Debido a que el líder suele actualizar las réplicas cada diez segundos con la marca de tiempo segura más reciente, las lecturas en una marca de tiempo inactiva pueden evitar una RPC adicional al líder.
Conclusión
En general, los diseñadores de sistemas de bases de datos distribuidas han descubierto que las fuertes garantías transaccionales son costosas, debido a toda la comunicación entre máquinas que se requiere. Con Spanner, nos hemos centrado en reducir el costo de las transacciones para que sean factibles a gran escala y a pesar de la distribución. Una razón clave de esto es TrueTime, que reduce la comunicación entre máquinas para muchos tipos de coordinación. Más allá de eso, la ingeniería detallada y el ajuste del rendimiento dieron como resultado un sistema que tiene un alto rendimiento, incluso mientras proporciona garantías sólidas. En Google, descubrimos que esto facilitó mucho más el desarrollo de aplicaciones en Spanner, en comparación con otros sistemas de bases de datos con garantías más débiles. Cuando los desarrolladores de aplicaciones no tienen que preocuparse por las condiciones de carrera o las inconsistencias en sus datos, pueden enfocarse en lo que en realidad les importa: compilar y entregar una aplicación excelente.