客户
Spanner 支持 SQL 查询。以下为一个示例查询:
SELECT s.SingerId, s.FirstName, s.LastName, s.SingerInfo
FROM Singers AS s
WHERE s.FirstName = @firstName;
结构 @firstName 是对查询参数的引用。您可以在任何可以使用字面量值的地方使用查询参数。强烈建议您在程序化 API 中使用参数。使用查询参数有助于避免 SQL 注入攻击,且生成的查询更有可能从各种服务器端缓存中受益。请参阅下文中的缓存。
在执行查询时,查询参数必须绑定一个值。例如:
Statement statement =
Statement.newBuilder("SELECT s.SingerId...").bind("firstName").to("Jimi").build();
try (ResultSet resultSet = dbClient.singleUse().executeQuery(statement)) {
while (resultSet.next()) {
...
}
}
Spanner 收到 API 调用后,会分析查询和绑定参数以确定应由哪个 Spanner 服务器节点处理查询。服务器将返回 ResultSet.next() 调用所使用的结果行流。
查询执行
查询执行从某个 Spanner 服务器收到“执行查询”请求开始。服务器会执行以下步骤:
- 验证请求
- 解析查询文本
- 生成初始查询代数
- 生成优化查询代数
- 生成可执行的查询计划
- 执行计划(检查权限、读取数据、对结果进行编码等)
解析
SQL 解析器分析查询文本并将其转化为抽象语法树。它会提取基本的查询结构 (SELECT …
FROM … WHERE …) 并执行语法检查。
代数
Spanner 的类型系统可以表示标量、数组、结构等。查询代数可为表扫描、过滤、排序/分组,以及各种联接、聚合等操作定义运算符。初始查询代数是根据解析器的输出构建的。使用数据库架构可分析解析树中的字段名称引用。此代码还可以检查语义错误(例如,参数数量不正确、类型不匹配等)。
下一步(“查询优化”)使用初始代数并生成更优化的代数。这可能更简单、更高效,或者更适合执行引擎的功能。例如,初始代数可能仅指定一个“联接”,而优化代数可指定“哈希联接”。
执行
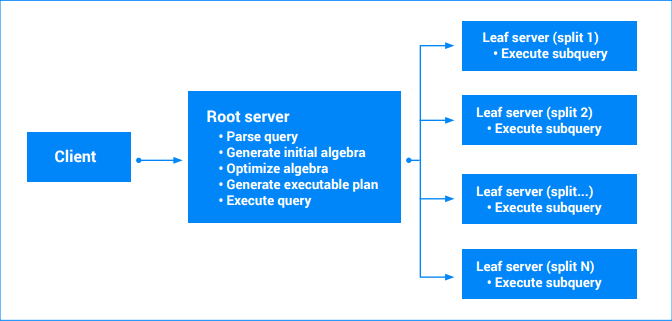
最终的可执行查询计划是根据重写的代数构建的。从根本上说,可执行计划是一个“迭代器”的有向无环图。每个迭代器公开一系列值。迭代器可能会使用输入来生成输出(例如,排序迭代器)。涉及单个分片的查询可以由单个服务器(保存数据的服务器)执行。服务器将扫描各种表的范围、执行联接、执行聚合,以及执行由查询代数定义的所有其他操作。
涉及多个分片的查询将被分解为多个部分。查询的某些部分将继续在主(根)服务器上执行。其他部分子查询会被传递给叶节点(那些拥有正被读取的分片的子节点)。这种传递可以递归地应用于复杂查询,从而生成一个服务器执行树。所有服务器均认同时间戳,因此查询结果是一致的数据快照。每个叶服务器返回部分结果流。对于涉及聚合的查询,返回结果可能是部分聚合的结果。查询根服务器会处理来自叶服务器的结果,并运行查询计划的其余部分。如需了解详情,请参阅查询执行计划。
如果查询涉及多个分块,Spanner 可以在多个分块上并行执行查询。并行度取决于查询扫描的数据范围、查询执行计划,以及数据在分块中的分布情况。Spanner 会根据查询的实例大小和实例配置(区域位置或多区域位置)自动设置查询的并行度上限,以实现最佳查询性能并避免过度占用 CPU。
缓存
查询处理的许多软件工件会被自动缓存并再次用于后续查询。这包括查询代数、可执行的查询计划等。缓存以查询文本、绑定参数的名称和类型等为基础。这就是在查询文本中使用绑定参数(如上述示例中的 @firstName)比使用字面量值更好的原因。无论实际的绑定值如何,前者均可以被缓存一次并再次使用。如需了解详情,请参阅优化 Spanner 查询性能。
错误处理
executeQuery 方法的结果行流可能会被中断,可能的原因如下:瞬时网络错误、从一个服务器到另一个服务器的分块转移(例如,负载均衡)、服务器重启(例如,升级到新版本)等等。为了帮助从这些错误中恢复,Spanner 会发送不透明的“恢复令牌”以及批量的部分结果数据。这些恢复令牌可以在重试查询时使用,以便从中断的地方继续查询。如果您正在使用 Spanner 客户端库,该步骤会自动完成;因此,客户端库的用户无需担心这种类型的瞬时故障。